摘要:文人結合自身微服務實踐,系統梳理從安裝適配、鏡像拉取,到運行配置、構建優化、多容器編排、數據持久化、監控運維等 Docker 全流程高頻踩坑點,給出可落地的解決方案,幫助讀者快速規避同類問題并提升容器化效率。
目錄
1.引言
2.Docker 初體驗:基礎搭建那些坑
2.1 安裝困境:不同系統的適配難題
2.2 鏡像拉取:速度與連接的雙重考驗
3.深入容器:運行與配置的挑戰
3.1 資源限制:容器間的 “資源戰爭”
3.2 端口映射:容器與外界的 “溝通障礙”
4.鏡像構建:細節決定成敗
4.1 鏡像臃腫:不必要的 “負擔”
4.2 安全隱患:秘密的 “泄露危機”
4.3 如何批量刪除沒有意義的鏡像【good】
5.多容器協作:docker - compose 的陷阱
5.1 配置語法:隱藏的語法 “地雷”
5.2 服務依賴:啟動順序的 “迷局”
6.數據管理:持久化與共享的難題
6.1 數據丟失:容器中的 “數據黑洞”
6.2 共享沖突:多容器數據共享的 “矛盾”
7.監控與維護:保障容器穩定運行
7.1 日志管理:信息獲取的 “困境”
1.Docker日志文件可以刪除嗎?
推薦做法(運行中容器)
小結
2.已經定位到 2 GB 的大日志文件
? 先確認容器狀態
? 容器在運行 → 用 truncate(推薦,親測有效)
?? 容器已停止 → 可安全刪除
一鍵腳本(通用)
7.2 容器清理:空間占用的 “煩惱”
8.總結與展望
1.引言

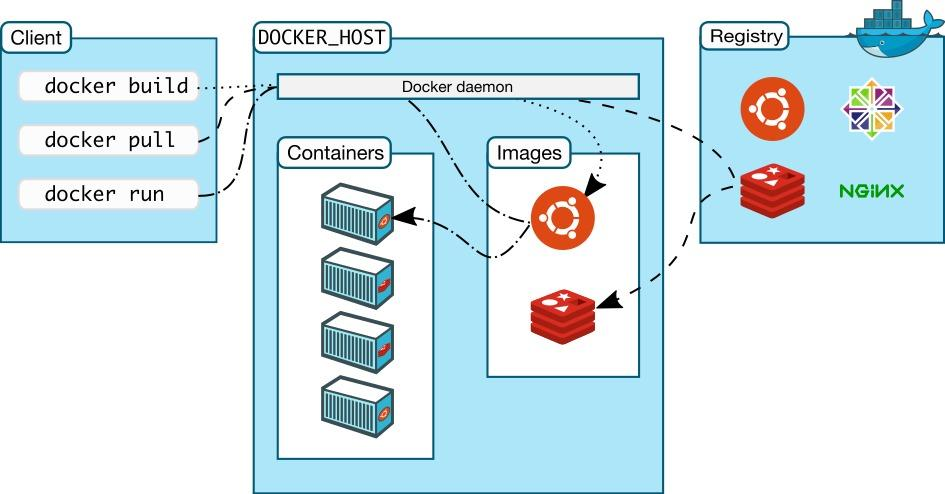
在當今云計算和容器化技術盛行的時代,Docker 無疑是其中的中流砥柱。它以 “一次構建,到處運行” 的理念,徹底改變了軟件交付和部署的方式,極大地提升了開發、測試和運維的效率,實現了應用程序及其依賴環境的高效打包和分發,在不同環境中保持一致性,讓開發者從繁瑣的環境配置中解脫出來。無論是初創公司還是大型企業,Docker 都成為了實現高效開發和部署的必備工具 ,在微服務架構、持續集成與持續部署(CI/CD)等場景中廣泛應用。
我在日常工作中,主要負責后端服務的開發與維護,項目采用微服務架構,各個服務都通過 Docker 進行容器化部署。在這個過程中,我深刻體會到了 Docker 帶來的便捷性,但也不可避免地遇到了各種各樣的 “坑”。這些問題有的耗費了我大量的時間去排查和解決,有的甚至影響到了項目的進度。我深知在技術探索的道路上,每一次遇到的問題都是寶貴的經驗積累。所以,我決定將這些在使用 Docker 過程中遇到的典型問題及解決方法分享出來,希望能幫助到正在使用或者即將使用 Docker 的朋友們,讓大家在容器化的道路上少走一些彎路。
Docker官網:https://www.docker.com/
Docker概念:Docker是一組平臺即服務(PaaS)的產品。它基于操作系統層級的虛擬化技術,將軟件與其依賴項打包為容器。托管容器的軟件稱為Docker引擎。Docker能夠幫助開發者在輕量級容器中自動部署應用程序,并使得不同容器中的應用程序彼此隔離,高效工作。該服務有免費和高級版本。它于2013年首次發布,由Docker, Inc.?開發。
2.Docker 初體驗:基礎搭建那些坑
2.1 安裝困境:不同系統的適配難題
Docker 的安裝過程雖然在官方文檔中有詳細說明,但在不同操作系統上實踐時,還是會遇到各種意想不到的問題。
在 Linux 系統中,以 Ubuntu 為例,安裝過程依賴于系統軟件包的更新和一系列依賴包的安裝。曾經在一次項目中,我在一臺全新的 Ubuntu 服務器上安裝 Docker,按照官方步驟,首先執行了系統軟件包更新命令sudo apt update和sudo apt upgrade -y ,一切看似順利。然而,在安裝依賴包時,卻出現了unable to locate package的錯誤,提示找不到某些依賴包。經過一番排查,發現是軟件源配置的問題,默認的軟件源在某些地區可能無法穩定訪問,導致依賴包下載失敗。解決辦法是更換為國內穩定的軟件源,如阿里云的軟件源,修改/etc/apt/sources.list文件,將軟件源地址替換為阿里云的地址,然后再次執行更新和安裝命令,問題得以解決。
對于 Windows 系統,安裝 Docker Desktop 時,需要滿足一定的系統要求,如 Windows 10 Pro 及以上版本,并且要開啟虛擬化功能。有一次,一位同事在 Windows 10 Home 版本的電腦上嘗試安裝 Docker,盡管按照網上的教程開啟了 WSL 2(Windows Subsystem for Linux 2),但在安裝過程中仍然報錯,提示虛擬化功能未啟用。后來發現,Windows 10 Home 版本的虛擬化功能需要通過特定的方式開啟,即通過管理員身份運行 PowerShell,執行wsl --install命令來安裝和啟用 WSL 2,并確保在 BIOS 設置中開啟虛擬化技術(VT-x/AMD-V)選項 ,之后重新安裝 Docker Desktop 才成功。
而在 MacOS 系統中,安裝 Docker Desktop 可能會遇到與系統兼容性或已安裝軟件沖突的問題。比如,當 MacOS 版本過低時,不滿足 Docker 的運行要求,會導致安裝失敗。另外,如果系統中已經安裝了如 VirtualBox 等虛擬化軟件,可能會與 Docker 產生沖突。我曾在一臺 MacBook 上安裝 Docker,當時系統中安裝了 VirtualBox,在安裝 Docker Desktop 時,一直出現啟動失敗的情況。通過卸載 VirtualBox,并清理相關殘留文件后,重新安裝 Docker Desktop,才成功解決了問題。
個人推薦Docker安裝三個方式:
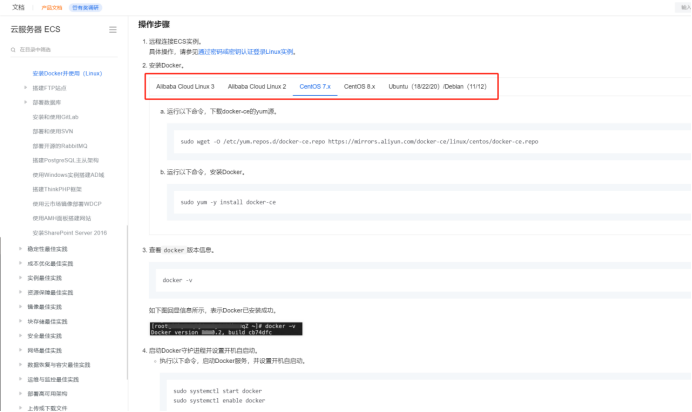
方式一(推薦):阿里云安裝docker,根據服務器類型選擇安裝,地址如下:
安裝Docker并使用鏡像倉庫ACR_云服務器 ECS(ECS)-阿里云幫助中心
方式二:
Windows10安裝Docker Desktop(大媽看了都會)_win10 docker desktop-CSDN博客
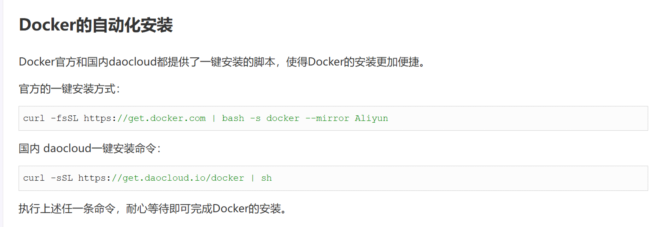
方式三:執行下面的命令。
2.2 鏡像拉取:速度與連接的雙重考驗
在完成 Docker 的安裝后,拉取鏡像成為了使用 Docker 的第一步,但這一步也常常會遇到各種問題。
網絡連接問題是導致鏡像拉取失敗的常見原因之一。由于 Docker 鏡像倉庫默認位于國外,在國內訪問時,網絡速度可能會非常慢,甚至出現連接超時的情況。在一次項目的測試環境搭建中,需要拉取一個較大的 MySQL 鏡像,使用默認的鏡像源拉取時,速度極慢,并且多次出現拉取中斷的情況。通過抓包分析,發現是網絡延遲過高導致的。為了解決這個問題,更換為國內的鏡像源,如阿里云鏡像源、網易云鏡像源等。具體操作是在 Docker 配置文件/etc/docker/daemon.json中添加鏡像源地址,例如:
{"registry-mirrors": ["https://docker.registry.cyou","https://docker-cf.registry.cyou","https://dockercf.jsdelivr.fyi","https://docker.jsdelivr.fyi","https://dockertest.jsdelivr.fyi","https://mirror.aliyuncs.com","https://dockerproxy.com","https://mirror.baidubce.com","https://docker.m.daocloud.io","https://docker.nju.edu.cn","https://docker.mirrors.sjtug.sjtu.edu.cn","https://docker.mirrors.ustc.edu.cn","https://mirror.iscas.ac.cn","https://docker.rainbond.cc","https://do.nark.eu.org","https://dc.j8.work","https://dockerproxy.com","https://gst6rzl9.mirror.aliyuncs.com","https://registry.docker-cn.com","http://hub-mirror.c.163.com","http://mirrors.ustc.edu.cn/","https://mirrors.tuna.tsinghua.edu.cn/","http://mirrors.sohu.com/"]
}
添加完成后,重啟 Docker 服務sudo systemctl daemon-reload && sudo systemctl restart docker ,再次拉取鏡像,速度得到了顯著提升。
另外,鏡像源不可用也是一個常見問題。有時候,某些鏡像源可能會因為維護、政策等原因無法正常使用。有一次,我使用的一個鏡像源突然無法拉取鏡像,報錯提示無法連接到鏡像源。經過查詢相關論壇和官方公告,發現該鏡像源由于違規被封禁。此時,只能及時更換其他可用的鏡像源,重新拉取鏡像。
還有一種情況是鏡像名稱或標簽錯誤,導致無法找到對應的鏡像。在一次部署新服務時,我誤將鏡像名稱中的字母寫錯,執行docker pull命令后,一直提示鏡像不存在。仔細檢查鏡像名稱后,修正錯誤,才成功拉取到鏡像。因此,在拉取鏡像時,一定要仔細核對鏡像名稱和標簽,確保準確無誤。
3.深入容器:運行與配置的挑戰
3.1 資源限制:容器間的 “資源戰爭”
在容器化的環境中,資源限制是一個至關重要的環節,但也是一個容易被忽視的 “坑”。如果不對容器的資源使用進行合理限制,當多個容器同時運行在同一臺宿主機上時,就可能會引發激烈的 “資源戰爭”。
我曾經遇到過這樣一個案例,在一個測試環境中,有多個微服務容器同時運行,其中一個數據分析服務的容器在處理大量數據時,由于沒有限制其 CPU 和內存的使用,它瘋狂地占用了宿主機幾乎所有的 CPU 資源和大量內存 。這導致其他容器中的服務因為資源不足而響應緩慢,甚至出現了服務崩潰的情況,整個測試環境陷入了癱瘓。從監控數據中可以看到,該數據分析服務容器的 CPU 使用率長時間保持在 99% 以上,內存使用率也遠遠超出了正常水平,而其他容器的資源使用率則急劇下降。
為了避免這種情況的發生,Docker 提供了--cpus和-m(或--memory)等參數來限制容器的資源使用。--cpus參數用于限制容器可以使用的 CPU 核心數,例如--cpus="1"表示容器最多只能使用 1 個 CPU 核心;-m參數用于限制容器的內存使用量,如-m 512m表示容器最多只能使用 512MB 的內存。在重新部署數據分析服務容器時,我添加了這些資源限制參數,將其 CPU 限制為 2 個核心,內存限制為 1GB,即docker run -d --cpus="2" -m 1g --name data-analysis-service data-analysis-image 。重新運行后,通過監控工具可以看到,各個容器的資源使用都處于合理范圍內,不再出現資源爭搶導致的服務異常情況。
3.2 端口映射:容器與外界的 “溝通障礙”
端口映射是實現容器與外界通信的關鍵,但在實際操作中,也常常會遇到各種問題,導致容器與外界之間出現 “溝通障礙”。
端口映射錯誤的一個常見表現就是無法訪問容器內的服務。有一次,我在部署一個 Web 應用容器時,按照常規操作使用docker run -d -p 8080:80 --name web-app web-app-image命令將容器的 80 端口映射到宿主機的 8080 端口 ,但在瀏覽器中訪問http://localhost:8080時,卻一直顯示連接超時。經過仔細排查,發現是端口沖突導致的問題。原來,宿主機上已經有另一個服務占用了 8080 端口,通過使用netstat -ano | findstr 8080命令(在 Windows 系統中)或netstat -anp | grep 8080命令(在 Linux 系統中),找到了占用該端口的進程,并將其停止后,再次啟動 Web 應用容器,才成功訪問到了容器內的 Web 服務。
除了端口沖突,映射配置錯誤也是一個常見原因。比如,在映射端口時,將宿主機端口和容器端口的順序寫錯,寫成了docker run -d -p 80:8080 --name web-app web-app-image ,這樣就會導致實際映射關系錯誤,外界無法通過正確的端口訪問到容器內的服務。解決辦法就是仔細檢查映射配置,確保端口順序正確。
另外,在一些復雜的網絡環境中,如在云服務器上使用 Docker,還需要注意安全組規則的配置。如果安全組沒有開放相應的端口,即使端口映射配置正確,也無法從外部訪問容器服務。例如,在使用阿里云服務器時,需要在阿里云控制臺的安全組配置中,添加允許外部訪問映射端口的規則,如添加一條入方向規則,允許來自任意 IP 地址的 TCP 協議訪問 8080 端口 ,這樣才能確保外部可以正常訪問容器內的 Web 服務。
4.鏡像構建:細節決定成敗
4.1 鏡像臃腫:不必要的 “負擔”
在鏡像構建過程中,一個常見且容易被忽視的問題就是鏡像臃腫。臃腫的鏡像就像是一個背負著沉重包袱的行者,在分發、部署和運行過程中,都會帶來諸多不便和性能損耗。
大鏡像的分發往往面臨著困難。在網絡傳輸過程中,較大的鏡像文件需要更長的時間來完成下載和上傳,這對于帶寬有限的環境來說,無疑是一個巨大的挑戰。曾經在一次項目的生產環境部署中,由于使用了一個體積較大的 Java 應用鏡像,在從鏡像倉庫拉取到服務器的過程中,花費了將近 30 分鐘的時間,嚴重影響了部署的效率。而且,大鏡像占用的存儲空間也更大,無論是在本地開發環境還是在生產服務器上,都需要更多的磁盤空間來存儲這些鏡像。隨著項目中鏡像數量的增加,磁盤空間很快就會被占滿,導致服務器運行緩慢甚至出現故障。
為了優化鏡像大小,我們可以采取一系列有效的措施。選擇合適的基礎鏡像是關鍵的第一步。許多常用的基礎鏡像,如 Alpine,是輕量級的 Linux 發行版,其體積相比傳統的 Ubuntu、CentOS 等鏡像要小得多。以一個 Python 項目為例,使用python:3.9-slim作為基礎鏡像,相比使用python:3.9,鏡像體積可以減少約 100MB。在構建鏡像時,要注意排除不必要的文件和目錄。可以使用.dockerignore文件,類似于.gitignore,來指定哪些文件和目錄不需要被包含在鏡像構建的上下文中。例如,在一個 Node.js 項目中,node_modules目錄在部署時可以通過npm install重新安裝,因此可以將其添加到.dockerignore文件中,避免將其打包進鏡像,從而減小鏡像體積。
另外,合理合并RUN指令也能有效減少鏡像層數,進而減小鏡像大小。每個RUN指令都會在鏡像中創建一個新的層,如果指令過多且不合理,就會導致鏡像層數過多,體積增大。例如,在安裝多個軟件包時,將多個RUN指令合并為一個,如RUN apk add --no-cache git curl,而不是寫成RUN apk add --no-cache git和RUN apk add --no-cache curl兩條指令 ,這樣可以減少一層鏡像,使鏡像更加緊湊。
4.2 安全隱患:秘密的 “泄露危機”
在鏡像構建過程中,安全問題不容忽視,其中一個常見的風險就是在鏡像中嵌入密鑰等機密信息,這就像是在自家門口埋下了一顆隨時可能引爆的炸彈,一旦鏡像被泄露或惡意利用,機密信息就會面臨 “泄露危機”。
許多開發者在構建鏡像時,為了方便,可能會將一些敏感信息,如數據庫連接密碼、API 密鑰、SSH 密鑰等,直接硬編碼在 Dockerfile 中或復制到鏡像中。這種做法看似簡單快捷,但卻存在著巨大的安全風險。如果鏡像被上傳到公共鏡像倉庫或被未經授權的人員獲取,這些機密信息就會完全暴露在他人面前。曾經有一個開源項目,開發者在鏡像中嵌入了 AWS 的訪問密鑰,后來該鏡像被惡意下載,攻擊者利用這些密鑰在 AWS 上創建了大量資源,導致該項目遭受了嚴重的經濟損失。
為了避免這種風險,我們應該采用更加安全的方式來處理機密信息。依賴環境變量是一種常用且有效的方法。在容器運行時,可以通過-e參數或在 Kubernetes 的Deployment配置中設置環境變量,將機密信息傳遞給容器內的應用程序。例如,在運行容器時,可以使用docker run -d -e DB_PASSWORD=your_password --name my-db my-db-image命令將數據庫密碼以環境變量的形式傳遞給容器 。在應用程序中,可以通過讀取環境變量來獲取這些機密信息,如在 Python 中,可以使用os.getenv('DB_PASSWORD')來獲取數據庫密碼。
另外,使用秘密管理器也是一種更高級、更安全的解決方案。像 HashiCorp Vault、AWS Secrets Manager、Google Cloud Secret Manager 等秘密管理器,提供了安全的密鑰存儲和管理功能。這些工具可以生成、存儲和管理密鑰,并通過安全的接口將密鑰傳遞給需要的容器或應用程序。以 HashiCorp Vault 為例,首先需要在 Vault 中創建一個密鑰存儲路徑,并將機密信息存儲在其中。然后,在容器啟動時,通過 Vault 的客戶端庫或 API,在運行時動態地獲取所需的機密信息,并將其注入到容器的環境變量中,從而實現機密信息的安全管理,避免在鏡像構建過程中直接嵌入密鑰帶來的安全風險。
4.3 如何批量刪除沒有意義的鏡像【good】
要批量刪除Docker中沒有意義或無用的鏡像,您可以采用以下幾種方法:
- 刪除所有未使用的鏡像(懸空鏡像):
您可以使用docker images -q --filter "dangling=true"命令列出所有未使用的鏡像ID,然后通過管道操作符|和xargs命令來批量刪除這些鏡像:【親測有效】bash
docker images -q --filter "dangling=true" | xargs docker rmi這將刪除所有未使用的鏡像,也就是那些沒有被任何容器引用的鏡像。
- 刪除特定前綴的鏡像: 如果您想要刪除所有以某個特定前綴開頭的鏡像,可以使用
grep命令來過濾這些鏡像,然后使用docker rmi命令刪除:bash
docker rmi $(docker images | grep '特定前綴' | awk '{print $3}')其中
特定前綴是您要刪除的鏡像的共同前綴。
- 使用腳本自動化刪除過程: 您可以創建一個shell腳本來自動化刪除過程,例如:
bash
#!/bin/bash # 設置鏡像前綴 PREFIX="test" # 刪除所有以指定前綴開頭的鏡像 docker rmi $(docker images | grep "$PREFIX" | awk '{print $3}') echo "刪除鏡像完成。"保存這個腳本為
delete_images.sh,然后通過chmod +x delete_images.sh命令給予執行權限,并執行./delete_images.sh來運行腳本。
- 使用
docker image prune命令: Docker提供了docker image prune命令,可以用來刪除未使用的鏡像。這個命令非常簡便,但需要注意的是,它會刪除所有未被使用的鏡像,如果不加篩選條件,可能會刪除掉一些您并不想刪除的鏡像:bash
docker image prune -a在此命令中,
-a選項表示刪除所有未使用的鏡像,而不僅僅是懸空的鏡像(dangling images)。請在執行刪除操作之前確保您沒有正在運行的容器依賴于這些鏡像,以避免意外刪除正在使用的鏡像導致服務中斷。同時,定期清理鏡像庫是保持Docker系統健康和高效運行的重要部分。
5.多容器協作:docker - compose 的陷阱
5.1 配置語法:隱藏的語法 “地雷”
在使用 Docker 進行多容器協作時,docker-compose無疑是一個強大的工具,它通過一個docker-compose.yml配置文件,就能輕松定義和管理多個相關的 Docker 容器。然而,這個配置文件的語法卻隱藏著不少 “地雷”,稍有不慎就會引發各種問題。
docker-compose.yml文件采用 YAML 格式,而 YAML 對縮進、空格和大小寫都非常敏感。比如,在定義服務時,縮進必須保持一致,通常建議使用兩個或四個空格,絕對不能使用制表符。像下面這個錯誤示例:
services:
web:image: nginx:latest由于web服務的縮進錯誤,就會導致配置解析失敗。正確的格式應該是:
services:web:image: nginx:latest另外,鍵值對的格式也必須正確,冒號后面一定要有一個空格。例如:
# 錯誤示例,冒號后缺少空格
environment:KEY:value
# 正確示例
environment:KEY: value如果不注意這些細節,在執行docker-compose up等命令時,就會報錯提示語法錯誤,讓容器無法正常啟動。而且,這種語法錯誤往往很難排查,因為錯誤信息可能并不會直接指出具體是哪個縮進或鍵值對格式有問題,需要我們仔細檢查整個配置文件。
除了縮進和鍵值對格式,docker-compose.yml文件中的指令也必須準確無誤。不同的docker-compose版本支持的功能和指令有所差異,所以在編寫配置文件時,一定要根據使用的docker-compose版本來選擇合適的指令,并了解其特性和限制。比如,在version: '3'的配置文件中,deploy部分用于定義服務的部署相關配置,像資源限制、副本數量等。如果在低版本中使用了deploy指令,就會導致配置文件無法解析。在使用一些自定義的擴展指令時,也要確保其在當前版本中是被支持的,否則也會引發語法錯誤。
5.2 服務依賴:啟動順序的 “迷局”
在多容器應用中,服務之間往往存在著復雜的依賴關系,而docker-compose中的depends_on參數用于定義服務之間的依賴關系,確保依賴的服務先啟動。然而,depends_on只能保證服務的啟動順序,卻不能保證依賴的服務已經完全就緒并可以正常提供服務。
以一個典型的 Web 應用架構為例,Web 服務通常依賴于數據庫服務。在docker-compose.yml文件中,可能會這樣定義:
version: '3'
services:web:image: mywebapp:1.0depends_on:- dbdb:image: mysql:8.0.26當執行docker-compose up時,docker-compose會先啟動db服務,然后再啟動web服務。但是,如果db服務啟動后,還需要一些時間來初始化數據庫、加載數據等操作,而此時web服務已經開始嘗試連接db服務,就可能會因為db服務尚未完全就緒而導致連接失敗,最終使web服務啟動失敗。從web服務的日志中,我們可能會看到類似 “Connection refused to mysql” 的錯誤信息,提示無法連接到數據庫。
為了解決這個問題,可以結合使用healthcheck和depends_on中的condition參數。healthcheck用于定義容器的健康檢查規則,通過定期執行檢查命令,判斷容器是否正常運行。例如,對于上述的db服務,可以添加如下健康檢查配置:
version: '3'
services:web:image: mywebapp:1.0depends_on:- db:condition: service_healthydb:image: mysql:8.0.26healthcheck:test: ["CMD", "mysqladmin", "ping", "-h", "localhost"]interval: 10stimeout: 5sretries: 5在這個配置中,db服務會每隔 10 秒執行一次mysqladmin ping -h localhost命令來檢查數據庫是否正常運行。如果在 5 次重試內,每次檢查都能成功(即命令返回值為 0),則認為db服務是健康的。web服務的depends_on中設置了condition: service_healthy,表示只有當db服務健康時,web服務才會啟動,從而避免了因依賴服務未就緒而導致的啟動失敗問題。
另外,還可以通過編寫自定義的啟動腳本來處理服務依賴。在容器啟動時,先執行一個腳本,該腳本會不斷嘗試連接依賴的服務,直到連接成功后,再啟動容器內的實際服務。比如,在web服務的容器中,可以編寫一個start.sh腳本:
#!/bin/bash
while! nc -z db 3306; dosleep 1
done
echo "Database is ready"
# 啟動Web服務的命令
python app.py然后在docker-compose.yml文件中,將web服務的command指定為這個腳本:
version: '3'
services:web:image: mywebapp:1.0depends_on:- dbcommand: /start.shdb:image: mysql:8.0.26這樣,web服務在啟動時,會先等待數據庫服務就緒,然后再啟動自身的應用程序,有效解決了服務依賴導致的啟動順序問題。
6.數據管理:持久化與共享的難題
6.1 數據丟失:容器中的 “數據黑洞”
在 Docker 的世界里,容器的設計初衷是具有臨時性和可重復性的,這使得容器在運行過程中產生的數據面臨著丟失的風險。如果將數據直接存儲在容器的可寫層中,一旦容器被刪除,這些數據就會像掉進了 “數據黑洞” 一樣,永遠消失不見。
我曾經參與過一個數據處理項目,其中有一個數據清洗的容器,它會從外部數據源讀取數據,經過一系列的清洗和轉換后,將處理后的數據存儲在容器內的一個目錄中。在一次測試過程中,由于需要重新配置容器的一些參數,我停止并刪除了這個數據清洗容器,準備重新啟動一個新的容器。然而,當我重新啟動容器后,卻發現之前處理好的數據全部丟失了。這是因為在刪除容器時,容器內的可寫層也被一并刪除,存儲在其中的數據自然也就不復存在了。
為了避免這種數據丟失的情況,我們需要使用數據卷(Volumes)和數據容器(Data Volume Containers)來實現數據的持久化存儲。數據卷是一個可供一個或多個容器使用的特殊目錄,它繞過了 Union File System,能夠提供一些用于持久化或共享數據的特性。我們可以在創建容器時,使用-v參數將數據卷掛載到容器內的指定目錄。例如,要將一個名為my-volume的數據卷掛載到nginx容器的/usr/share/nginx/html目錄,可以使用以下命令:
docker run -d
-p 80:80
--name my-nginx
-v my-volume:/usr/share/nginx/html nginx這樣,即使my-nginx容器被刪除,my-volume數據卷中的數據依然會保留在宿主機上,當重新創建容器并掛載相同的數據卷時,容器就可以訪問到之前存儲的數據。
另外,數據卷容器是一種特殊的容器,它的主要作用是專門用來提供數據卷供其他容器掛載。通過使用--volumes-from參數,一個容器可以掛載另一個數據卷容器中的數據卷。例如,先創建一個數據卷容器dbdata:
docker run -it -v /dbdata --name dbdata centos然后創建另一個容器db1,并使用--volumes-from參數掛載dbdata容器的數據卷:
docker run -it --volumes-from dbdata --name db1 centos這樣,db1容器就可以共享dbdata容器的數據卷,實現數據的持久化和共享。而且,即使db1容器被刪除,dbdata容器中的數據卷依然存在,其他容器還可以繼續掛載使用 。
6.2 共享沖突:多容器數據共享的 “矛盾”
在多容器協作的場景中,多個容器同時讀寫同一個數據卷是很常見的需求,但這也容易引發數據沖突的問題,就像多個人同時修改同一個文件,很容易導致數據的不一致和混亂。
以一個電商系統為例,其中訂單服務和庫存服務都需要訪問同一個數據庫的數據卷。當訂單服務接收到一個新訂單時,它會讀取庫存數據卷中的商品庫存信息,判斷庫存是否足夠,如果足夠則更新庫存并生成訂單。同時,庫存服務可能也在對庫存數據進行統計分析,或者進行庫存的補充操作。如果這兩個服務同時對數據卷進行寫入操作,就可能會出現數據沖突。比如,訂單服務在更新庫存時,庫存服務也在更新庫存,可能會導致其中一個更新操作被覆蓋,從而使庫存數據出現錯誤。
為了預防和解決這種數據沖突問題,我們可以采取以下策略:
- 使用分布式鎖:在應用程序層面引入分布式鎖機制,如 Redis 的分布式鎖。當一個容器需要對共享數據進行寫入操作時,先獲取分布式鎖,只有獲取到鎖的容器才能進行寫入操作,其他容器需要等待鎖的釋放。例如,在 Python 中使用redis-py庫實現分布式鎖:
import redis from redis.lock import Lockr = redis.Redis(host='redis-server', port=6379, db=0) lock = Lock(r, "data-volume-lock")try:if lock.acquire(blocking=True, timeout=10):# 進行數據寫入操作pass finally:lock.release() - 優化讀寫操作:盡量減少多容器同時寫入的情況,將一些讀寫操作進行優化。例如,對于一些只讀操作,可以使用緩存來減少對數據卷的直接讀取;對于寫入操作,可以采用異步寫入的方式,將寫入請求先放入消息隊列中,然后由一個專門的服務按照順序從消息隊列中讀取請求并寫入數據卷,這樣可以避免多個容器同時寫入導致的沖突。
- 數據版本控制:在數據卷中引入版本控制機制,每次對數據進行寫入操作時,更新數據的版本號。當其他容器讀取數據時,同時讀取數據的版本號,在進行寫入操作前,先比較版本號,如果版本號不一致,則說明數據已經被其他容器修改過,需要重新讀取最新的數據,然后再進行寫入操作,以此來保證數據的一致性。
7.監控與維護:保障容器穩定運行
7.1 日志管理:信息獲取的 “困境”
在容器化的應用環境中,日志管理是確保系統穩定運行和故障排查的關鍵環節,但也面臨著諸多挑戰,就像在一個龐大的信息迷宮中尋找關鍵線索,充滿了困難和復雜性。
容器日志分散是一個常見的問題。在一個由多個容器組成的分布式系統中,每個容器都產生自己的日志,這些日志分散在不同的容器實例中。例如,一個電商系統可能包含用戶服務、訂單服務、支付服務等多個微服務容器,每個容器都會記錄各自的業務操作日志、錯誤日志等。當出現問題時,要從這些分散的日志中快速定位問題根源,就如同大海撈針一般困難。曾經在一次線上故障中,用戶反饋無法完成支付操作,為了排查問題,我需要查看支付服務容器、訂單服務容器以及相關數據庫容器的日志。然而,由于這些容器分布在不同的服務器上,且日志格式和存儲位置各不相同,我花費了大量的時間在各個服務器和容器之間切換,才收集到了相關的日志信息。
而且,容器日志難以檢索也是一個突出的問題。傳統的日志管理方式在容器環境下往往顯得力不從心。Docker 默認的日志驅動是json-file,它將日志以 JSON 格式寫入文件,雖然這種格式便于機器解析,但對于人工檢索來說并不友好。當日志量較大時,使用普通的文本搜索工具很難快速找到關鍵信息。比如,在一個高并發的 Web 應用中,每天產生的日志量可能達到幾十 GB 甚至更多,在這些海量的日志中查找某個特定時間點的錯誤信息,使用簡單的grep命令往往效率低下,需要耗費大量的時間和計算資源。
為了解決這些問題,我們可以采用掛載日志卷的方式,將容器內的日志文件掛載到宿主機的指定目錄,這樣就可以在宿主機上集中管理和查看日志。例如,在運行容器時,可以使用-v參數進行日志卷掛載:
docker run -d -v /host/logs:/container/logs --name my-container my-image這樣,容器內/container/logs目錄下的日志文件就會被同步到宿主機的/host/logs目錄,方便我們直接在宿主機上查看和處理日志。
此外,使用專業的日志管理工具也是一個有效的解決方案。像 ELK Stack(Elasticsearch、Logstash、Kibana)和 Fluentd 等工具,可以實現日志的集中收集、存儲、索引和可視化。以 ELK Stack 為例,Logstash 負責從各個容器收集日志數據,然后將其發送到 Elasticsearch 進行存儲和索引,Kibana 則提供了一個友好的用戶界面,用于搜索和可視化日志數據。通過配置 ELK Stack,我們可以在 Kibana 的界面上根據時間范圍、關鍵字、容器名稱等條件進行靈活的日志查詢和分析,大大提高了日志檢索的效率和準確性 。
1.Docker日志文件可以刪除嗎?
可以,但要分“場景”和“時機”:
場景
能否直接
rm刪除后果/注意點
容器正在運行
? 不要直接
rm日志文件被 dockerd 打開,刪除后磁盤空間不會立即釋放(文件句柄仍在),還可能觸發
device busy或容器寫日志報錯。容器已停止
? 可以
rm無風險,空間立即釋放。
所有容器已停止或已刪除
? 可以整目錄
rm -rf /var/lib/docker/containers/*/*-json.log徹底清空。
推薦做法(運行中容器)
- 先截斷(立即釋放空間,容器不停)
sudo truncate -s 0 /var/lib/docker/containers/<容器ID>/<容器ID>-json.log
- 或者 輪轉(長期根治)
docker run --log-opt max-size=100m --log-opt max-file=3 ...
小結
- 容器在跑 ? 用
truncate或 配置 log-opts。- 容器停了 ?
rm隨便刪,安全。2.已經定位到 2 GB 的大日志文件
你已經定位到 2 GB 的大日志文件,對應容器目錄是:
/var/lib/docker/containers/f826db7c9ef6d3258283de7c6f46fd87e467f4a3febd9474763d31d967b9bb2c/
? 先確認容器狀態
docker ps -a --filter "id=f826db7c9ef6" --format "table {{.Names}}\t{{.Status}}"
- 如果容器是
Exited→ 直接刪日志安全- 如果容器是
Up xxx→ 不要rm,用truncate清空間,不影響運行
? 容器在運行 → 用 truncate(推薦,親測有效)
sudo truncate -s 0 /var/lib/docker/containers/f826db7c9ef6d3258283de7c6f46fd87e467f4a3febd9474763d31d967b9bb2c/*-json.log
- 秒級釋放 2 GB 空間
- 容器不停、日志繼續寫,無風險
?? 容器已停止 → 可安全刪除
sudo rm /var/lib/docker/containers/f826db7c9ef6d3258283de7c6f46fd87e467f4a3febd9474763d31d967b9bb2c/*-json.log
- 刪除后磁盤空間立即回收
- 重啟容器時 Docker 會自動重新創建空日志文件
一鍵腳本(通用)
CID=f826db7c9ef6 LOG=/var/lib/docker/containers/$CID/*-json.log docker ps -q --filter id=$CID | grep -q $CID \&& sudo truncate -s 0 $LOG \|| sudo rm $LOG執行完再用
df -h看一眼磁盤即可確認空間已釋放。
7.2 容器清理:空間占用的 “煩惱”
在 Docker 的日常使用中,如果不及時清理無用的容器、鏡像和卷,就會導致磁盤空間被大量占用,就像一個雜亂無章的倉庫,堆滿了無用的雜物,不僅浪費空間,還會影響系統的性能。
無用容器占用空間是一個常見的問題。當我們停止并退出一個容器后,如果不及時刪除它,這個容器仍然會占用一定的磁盤空間。隨著時間的推移,大量停止的容器會逐漸積累,占用越來越多的磁盤空間。例如,在開發和測試過程中,我們可能會頻繁地創建和運行容器進行各種實驗,這些容器在使用完畢后,如果沒有及時清理,就會在系統中留下大量的 “垃圾”。曾經在一個開發環境中,由于長時間沒有清理容器,磁盤空間被大量占用,導致新的容器無法正常運行,系統提示磁盤空間不足。通過使用docker ps -a命令查看所有容器,發現有數百個已經停止的容器,這些容器占用了數十 GB 的磁盤空間。
未使用的鏡像也是磁盤空間的 “吞噬者”。每次拉取或構建新的鏡像時,如果不清理舊的未使用的鏡像,鏡像文件會不斷累積,占用大量的磁盤空間。而且,一些大的鏡像文件本身就占用較大的存儲空間,如果不及時清理,會對系統的磁盤空間造成很大的壓力。比如,在一個項目中,我們需要頻繁更新 Java 應用的鏡像,由于沒有及時清理舊的鏡像,導致鏡像倉庫中積累了大量不同版本的 Java 應用鏡像,這些鏡像占用了數百 GB 的磁盤空間,嚴重影響了系統的正常運行。
另外,未清理的卷也會占用磁盤空間。數據卷是用于持久化存儲數據的,但當與之關聯的容器被刪除后,如果不及時清理無用的卷,這些卷仍然會占用磁盤空間。特別是在一些數據量較大的應用中,如數據庫應用,數據卷占用的空間可能會非常大。例如,一個 MySQL 數據庫容器使用的數據卷,在容器被刪除后,如果沒有清理該數據卷,其中存儲的數據庫文件仍然會占用大量的磁盤空間。
為了清理這些無用的資源,我們可以使用一系列的 Docker 命令。使用docker container prune命令可以刪除所有停止的容器;使用docker image prune命令可以刪除所有未被使用的鏡像;使用docker volume prune命令可以刪除所有未被使用的卷 。例如:
# 刪除所有停止的容器
docker container prune
# 刪除所有未被使用的鏡像
docker image prune -a
# 刪除所有未被使用的卷
docker volume prune此外,還可以使用docker system prune命令來一次性清理所有未使用的容器、鏡像和卷,加上-a參數可以清理所有未使用的資源,包括有標簽但未被引用的鏡像和容器卷 ,如docker system prune -a。通過定期執行這些清理命令,可以有效地釋放磁盤空間,保持系統的整潔和高效運行。
8.總結與展望

在使用 Docker 的過程中,我們從基礎搭建時的安裝適配和鏡像拉取問題,到深入容器運行時的資源限制、端口映射難題,再到鏡像構建的臃腫與安全隱患,多容器協作的配置語法和服務依賴困境,數據管理的數據丟失與共享沖突,以及監控維護的日志管理和容器清理煩惱,可謂是 “一路坎坷”。但正是這些問題,讓我們更加深入地理解了 Docker 的工作原理和機制,也積累了寶貴的實踐經驗。
Docker 作為容器化技術的佼佼者,未來的發展趨勢十分令人期待。隨著云計算的不斷普及和微服務架構的廣泛應用,Docker 將在更多的場景中發揮重要作用。它將與 Kubernetes 等容器編排工具更加緊密地結合,實現容器化應用的自動化部署、擴展和管理 ,為企業提供更加高效、可靠的解決方案。
希望我的這些經驗分享能夠幫助大家在使用 Docker 的過程中少走彎路。也歡迎各位讀者在評論區分享自己在使用 Docker 時遇到的問題和解決方法,讓我們共同學習,共同進步,一起在容器化的技術浪潮中乘風破浪。
15個關鍵字解說
Docker:開源容器引擎,把應用與依賴打包成輕量鏡像,實現一次構建、到處運行。
鏡像:只讀模板,含文件系統與元數據,容器啟動時以此為藍本。
容器:鏡像的運行實例,彼此隔離,秒級啟停,生命周期短暫。
Dockerfile:聲明式腳本,用指令逐層構建鏡像,決定體積與安全。
鏡像加速:國內源替換 Docker Hub,解決拉取慢、超時、斷流問題。
資源限制:利用--cpus、-m等參數給容器設上限,防止資源戰爭拖垮宿主機。
端口映射:-p 宿主機端口:容器端口,打通外部訪問,需避沖突與防火墻。
數據卷:獨立于容器的持久化目錄,刪容器不丟數據,支持多容器共享。
docker-compose:單機編排工具,用 YAML 描述多服務依賴、網絡與卷。
健康檢查:定義探針命令,確保依賴服務就緒后再啟動下游容器。
鏡像瘦身:選 Alpine、多階段構建、.dockerignore、合并 RUN 減少層。
密鑰泄漏:禁止把密碼、Token 寫進鏡像,應使用環境變量或 Vault 動態注入。
日志卷:把容器內日志目錄掛載到宿主機,集中收集,方便排查。
ELK:Elasticsearch+Logstash+Kibana 組合,用于大規模日志檢索與可視化。
定時清理:docker system prune、volume prune 等命令,定期釋放磁盤空間。
寫在最后:
? ? ?希望這篇博客能夠為你在Docker容器開發和部署項目中提供一些啟發和指導。如果你有任何問題或需要進一步的建議,歡迎在評論區留言交流。讓我們一起探索IT世界的無限可能!
博主還分享了本文相關文章,請各位大佬批評指正:
1、Intellij idea高效使用教程
2、AI編程工具合集
3、CodeGeeX一款基于大模型全能的智能編程助手
4、Git 代碼提交注釋管理規范
5、解釋 Git 的基本概念和使用方式。
6、postman介紹、安裝、使用、功能特點、注意事項
7、Windows10安裝Docker Desktop(大媽看了都會)
8、02-pycharm詳細安裝教程(大媽看了都會)
9、01-Python詳細安裝教程(大媽看了都會)
10、2024年最新版IntelliJ IDEA下載安裝過程(含Java環境搭建)
感謝以下文章提供參數:
1、最新IntelliJ IDEA下載安裝以及Java環境搭建教程(含Java入門教程)
2、https://kimi.moonshot.cn/
3、分享一下快速搭建IntelliJ IDEA開發環境的完整教程
4、JDK的環境配置(超詳細教程)
5、下載與安裝啟動(IntelliJ IDEA | JDK | Maven)
6、Java編程神器對決:飛算JavaAI單挑全球勁旅
理解VAE)

)

)



保姆級教學)




)





)