作者:來自 Elastic?Jhon Guzmán
了解如何將 Vertex AI 與 Elasticsearch 集成來創建 RAG 應用。按照本教程配置一個 Gemini 模型并在 Kibana 的 Playground 中使用它。
更多閱讀:
- Elasticsearch:在 Elastic 中玩轉 DeepSeek R1 來實現 RAG 應用
-
在本地電腦中部署阿里 Qwen3 大模型及連接到 Elasticsearch
想要獲得 Elastic 認證嗎?看看下一期 Elasticsearch Engineer 培訓什么時候開始!
Elasticsearch 擁有大量新功能,可以幫助你為你的用例構建最佳搜索解決方案。深入學習我們的示例 notebooks 以了解更多,開始免費的 cloud 試用,或者現在就在本地機器上嘗試 Elastic。
從 Elasticsearch 版本 9.1.0 開始,你可以集成 Vertex AI 模型(包括 Gemini),并在 Elasticsearch 中使用它們。這個最新版本在現有的 embedding 和 reranking 功能上新增了 completion 和 chat_completion 能力,因此你可以通過 AI connector 在模型中配置它們。
Vertex AI 允許你使用像 Gemini 2.5 Pro 和 Flash 這樣的模型,這些模型對 RAG 的推理和文本流很有用。此外,使用 Vertex AI 你還可以部署模型以進行更多自定義和微調。
我們選擇 gemini-2.5-flash-lite,因為它在價格和性能之間有最佳平衡,同時在推理基準中得分很高。它被評為最快和最便宜的模型之一,是一個很好的入門選擇。如果我們需要更強大性能,可以切換到 gemini-2.5-pro。Gemini 2.5-mini 非常適合低延遲、大數據量處理,比如我們要創建的這種 RAG 應用。
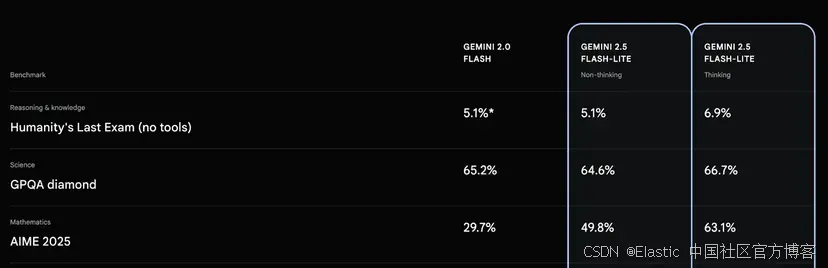
在這篇文章中,你將學習如何在 Elasticsearch 中配置一個基礎的 Vertex AI 模型,以便在 Kibana 的 Playground 中使用它。我們將設置 GCP Service Account,并配置 gemini-2.5-flash-lite 來用 Playground 創建一個 RAG 應用。
下面是我們基礎配置的示意圖:
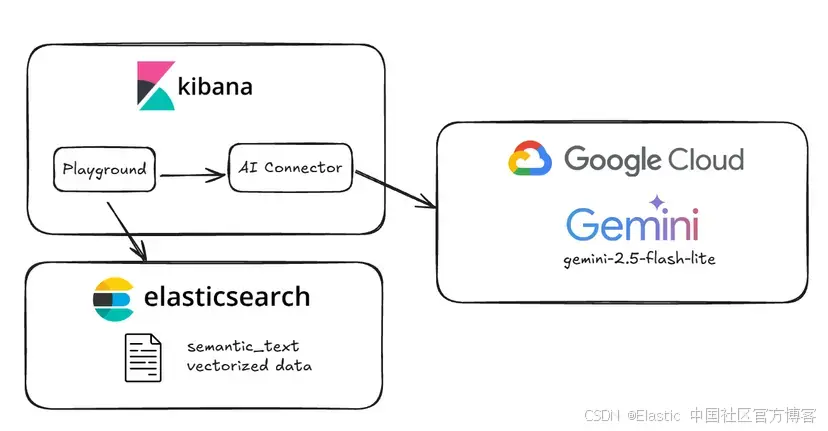
設置 AI Vertex Connector
第一步是在 GCP 中創建一個服務賬號以使用 Vertex AI 平臺。如果你已經有了,就跳過這一步,但要確保手頭有認證用的 JSON 文件,并且該賬號已分配 Vertex AI User 和 Service Account Token Creator 角色。
創建 GCP 服務賬號
要創建 GCP 服務賬號,你需要進入這個鏈接,選擇將要創建賬號的項目,然后點擊 “+ Create service account”。
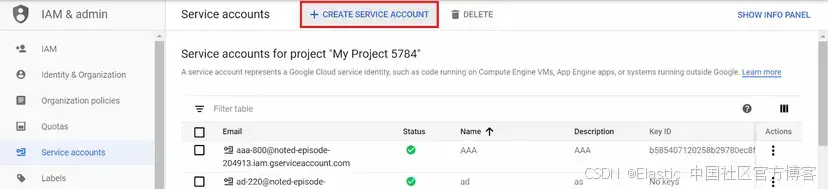
為服務賬號選擇一個名稱并點擊 “Create and continue”。在下一個菜單中,為其添加以下兩個角色的權限:
-
Vertex AI User
-
Service Account Token Creator:該角色允許賬號生成必要的訪問令牌。
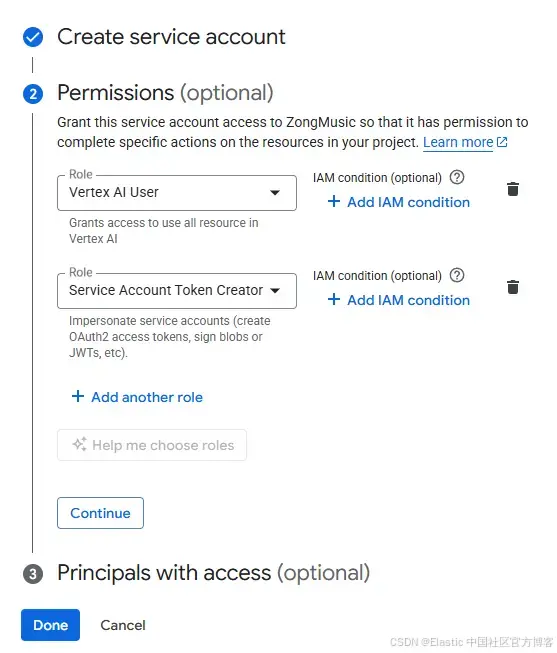
點擊 “Done”。
創建服務賬號后,你必須下載 JSON 訪問密鑰。在下一個鏈接中,選擇你剛創建的賬號。進入“Keys”,然后點擊 “Add key”,再點擊 “Create new key”。
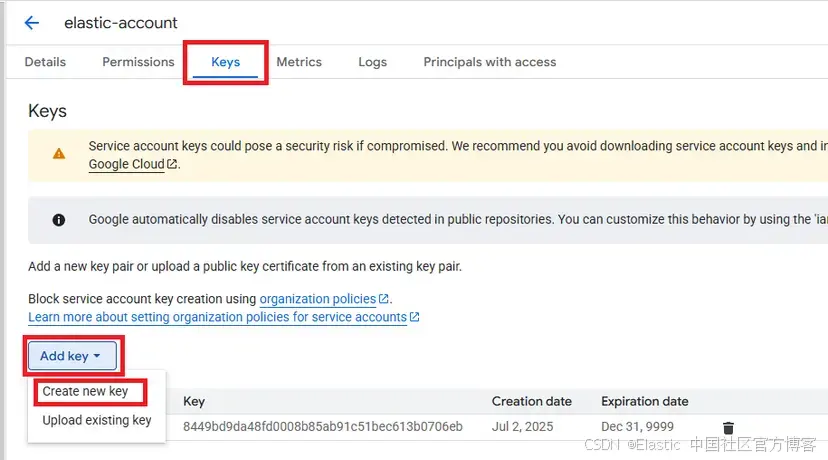
在彈出窗口中,確保將 JSON 標記為密鑰類型,然后點擊 “Create”。
這會下載一個 JSON 密鑰,你將在接下來的步驟中用到它。
創建 Elasticsearch 集群
為了使用 Vertex 模型,我們將在這里注冊并創建一個 Elastic Cloud Serverless 集群,但你可以選擇適合你需求的部署類型。對于本教程,我們將選擇 search 用例。
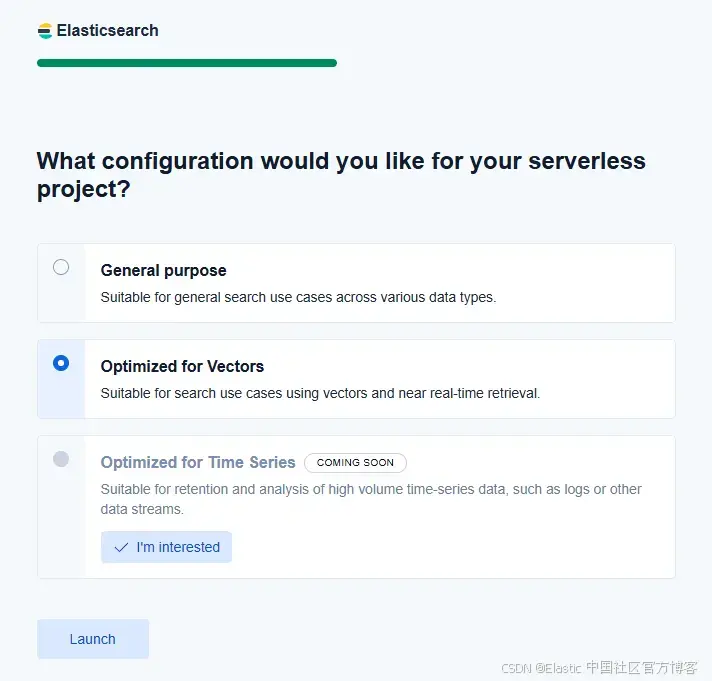
然后,表單會要求你選擇一個 cloud provider 和區域。接著,你需要選擇一個 “optimized for vectors” 的項目。這一步僅在 Serverless 部署中需要。
集群部署完成后,進入 Kibana 進行下一步操作。
創建 AI Connector
現在你的集群已經準備好,并且可以訪問 Vertex AI,你就可以創建 connector 了。在 Kibana 中,進入 Connectors 菜單(Management > Stack Management > Alerts and Insights > Connectors)。然后,創建一個 connector 并選擇 AI Connector。
使用以下參數配置 connector:
-
Connector name:Vertex AI
-
Service:Google Vertex AI
-
JSON Credentials:在這里,你需要復制/粘貼前面步驟中創建的訪問密鑰的完整內容
-
GCP Project:服務賬號和 Vertex AI 模型所在的項目 ID
-
GCP Region:模型所在的區域(us-central1 可訪問大多數 Gemini 模型)
-
Model ID:gemini-2.5-flash-lite
-
Task Type:chat_completion
你的 connector 應該看起來像這樣:
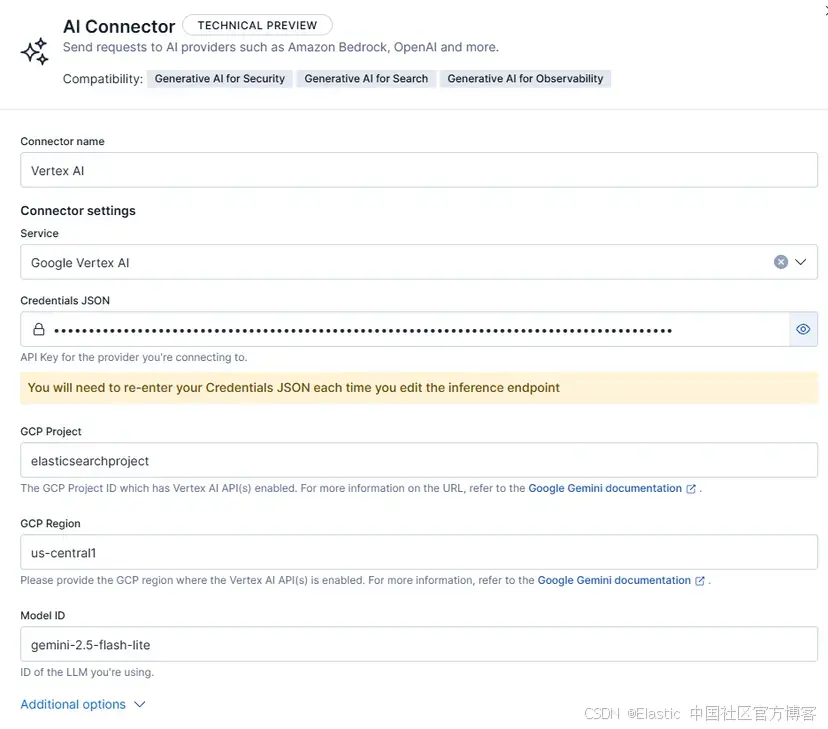
除了這個配置,你還有 “additional options”,可以定義模型和通過 connector 可用的推斷端點的關鍵屬性。
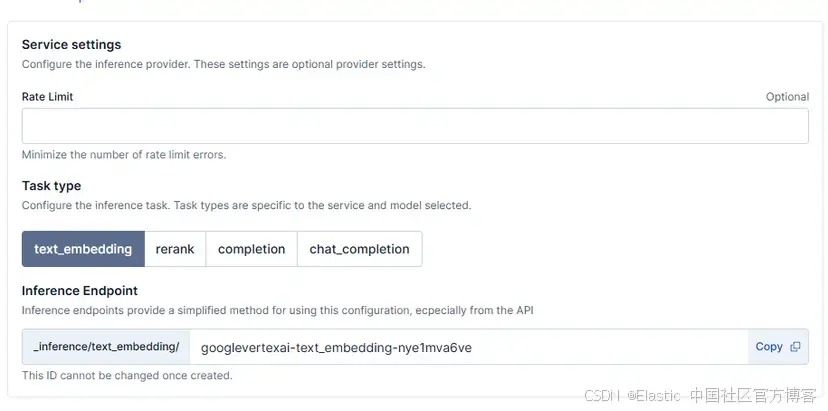
Rate limit:可選地定義每分鐘發送請求的最大數量。
Task type:使用模型執行的任務。這個新版本增加了 completion 和 chat_completion:
-
Completion:模型接收一個 prompt 并生成最可能的延續。沒有對話輪次、角色或任何對話結構。適用于簡單任務,如補全代碼、生成連續文本,或在沒有上下文的情況下回答直接問題。
-
Chat Completion:此模式以基于角色的結構(system、user、assistant)訓練模型,允許處理多輪交互。在內部,模型不僅預測下一個 token,還會基于對話意圖進行預測。
- Inference Endpoint:創建 connector 時,會生成一個推斷端點以識別配置任務的模型。我們可以定義一個 ID 并在推斷 API 和 Kibana 中使用它。
在 Kibana 的 Playground 中使用模型
上傳數據
要測試模型,我們需要一些數據,并確認 _inference API 可用。從 8.17 版本開始,機器學習功能是動態的,這意味著要下載并使用 E5 dense multilingual vector,只需使用該模型即可。
# find e5 model id
GET /_inference# trigger the download by using it
POST /_inference/text_embedding/.multilingual-e5-small-elasticsearch
{"input": "Warming up ML nodes!"
}當你生成 embeddings 時,模型會被下載,推斷端點會自動運行。
現在,讓我們上傳下面的文本作為 RAG 上下文:
Casa Tinta Bistro is a small, family-run restaurant located in the Chapinero neighborhood of Bogotá, Colombia. It was founded in 2019 by siblings Mariana and Lucas Herrera, who combined their love for traditional Colombian flavors with a modern twist. The bistro is best known for its creamy coconut ajiaco, mango-infused arepas, and handcrafted guava lemonade.The restaurant operates Tuesday through Sunday, from 12:00 PM to 9:30 PM, and closes on Mondays. They offer vegetarian and vegan options, and their menu changes slightly every season to incorporate fresh local ingredients. Casa Tinta also hosts monthly poetry nights, where local writers perform their work in front of a small crowd of regulars and newcomers alike.Although it remains a hidden gem for most tourists, Casa Tinta has a loyal base of local customers and consistently ranks high on community food blogs and private reviews.將文本保存為 .txt 文件,然后進入 Elasticsearch > Home > Upload a file
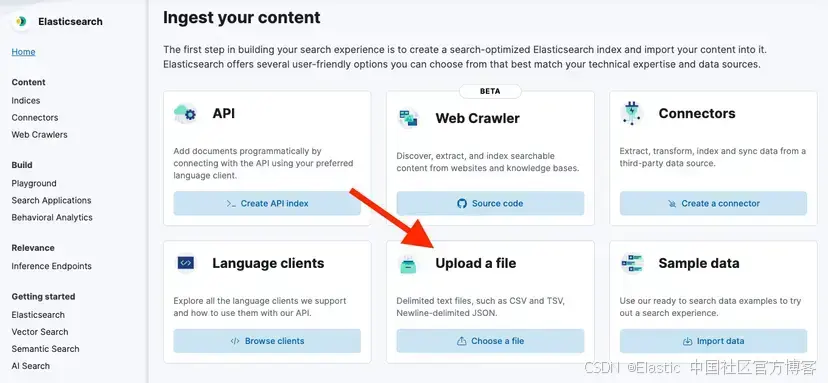
點擊按鈕或將文件拖放到 “Upload data” 框中。然后,點擊 Import。
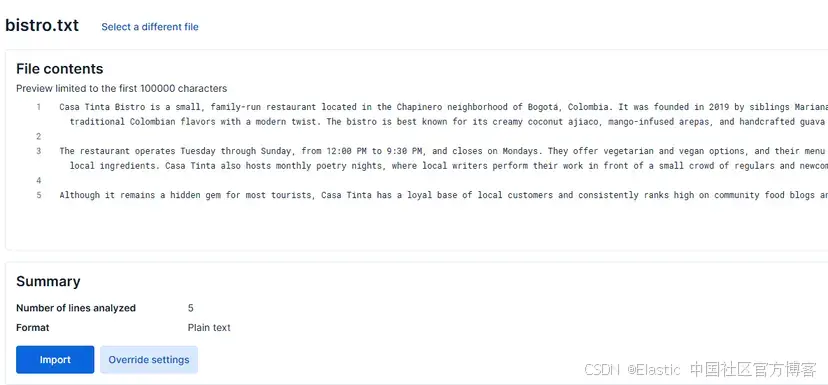
然后,選擇 “Advanced” 標簽,并將索引命名為 “bistro_restaurant1”。
接著,點擊 “Add additional field”,選擇 “Add semantic text field”。將推斷端點改為 “.multilingual-e5-small-elasticsearch”。配置應如下所示:
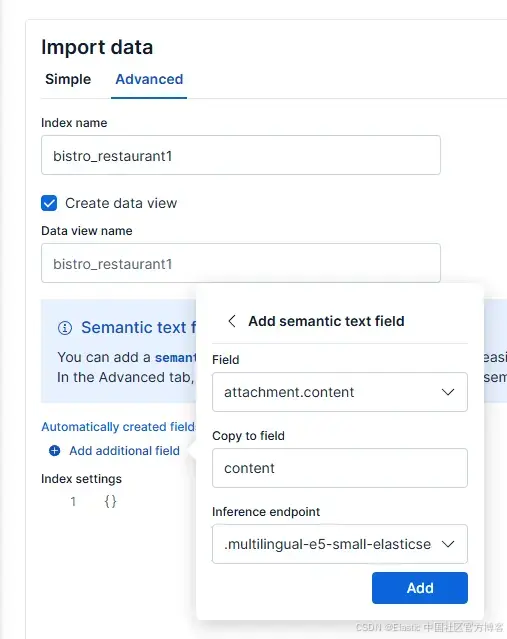
最后,點擊 “Add”,然后點擊 “Import”。
上傳完成后,我們可以在 Playground 中使用這些數據。
在 Playground 中測試 RAG
進入 Kibana 的 Elasticsearch > Playground。
在 Playground 頁面,你應該看到一個綠色對勾和消息 “LLM Connected”,表示我們剛創建的 Vertex connector 已存在。你可以查看這個鏈接獲取更深入的 Playground 指南。
點擊藍色按鈕 “Add data sources”,選擇我們剛創建的 bistro_restaurant 索引。
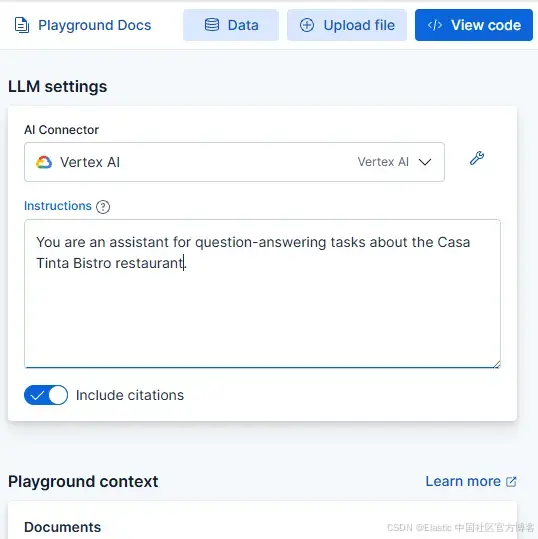
在 Playground 中,我們將模型的 prompt 定義為 “You are an assistant for question-answering tasks about the Casa Tinta Bistro restaurant。” 其余配置保持默認。
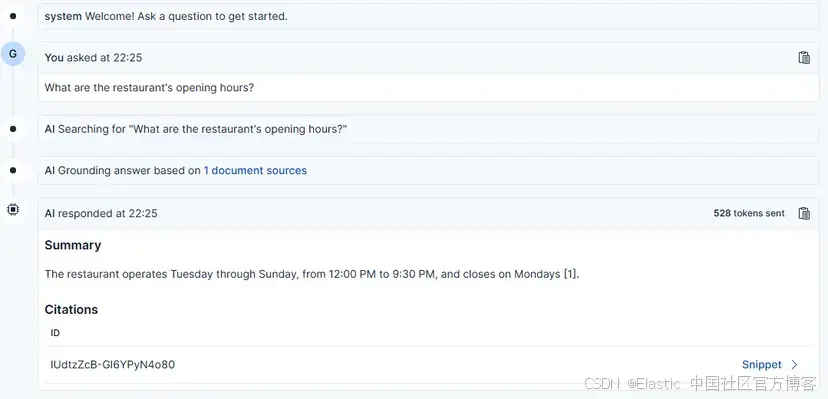
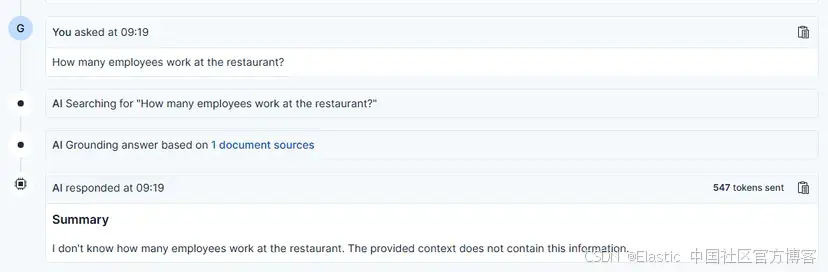
現在,我們可以向模型提出關于該餐廳的任何問題,它會查詢索引以提供合適的答案。
例如,我們可以詢問營業時間,模型會給出答案的 “sources”,這些指的是信息所在文檔的 ID。
當你提出與 RAG 上下文無關的問題時,模型會回復 “The provided context does not contain this information”,因為答案是基于數據的。
結論
通過新的 Vertex AI 集成,你可以輕松使用像 Gemini 這樣的模型,在 Playground 中創建基于索引數據提供答案的 RAG 應用。現在,邁出下一步,決定要索引哪些其他來源,選擇另一個 Vertex AI 模型,或者部署你自己的模型,讓 RAG 為你的特定用例工作。
原文:Exploring Vertex AI with Elasticsearch - Elasticsearch Labs
![[新啟航]白光干涉儀在微透鏡陣列微觀 3D 輪廓測量中的應用解析](http://pic.xiahunao.cn/[新啟航]白光干涉儀在微透鏡陣列微觀 3D 輪廓測量中的應用解析)
- Mediatek KMS實現mtk_drm_drv.c(Part.2))
)





)

)
Leetcode34. 在排序數組中查找元素的第一個和最后一個位置+74. 搜索二維矩陣)




)

![ruoyi_wvp流媒體[海康 大華 GB1812 onvif rtsp]](http://pic.xiahunao.cn/ruoyi_wvp流媒體[海康 大華 GB1812 onvif rtsp])
:有限馬爾可夫決策過程(一))