卷積神經網絡項目實戰
1.項目簡介
1.1項目名稱
? 基于CNN實現超市商品的混合顆粒度分類(500分類)
1.2 項目簡介
? 該項目旨在通過卷積神經網絡(CNN)實現超市商品的混合顆粒度分類,主要針對商品的不同種類進行分類,應用場景主要為大型超市的自助收銀臺,設備通過模型的嵌入快速識別商品種類并為顧客提供結賬操作,降低了超市的人力資源,以及提高人員流通性。
? 本項目引入深度學習中的CNN模型,構建一個專門用于超市常見商品分類的網絡架構,充分利用卷積層的局部特征提取能力以及深層網絡的高階特征融合能力,其包含了數據收集、數據預處理、模型訓練、模型評估、模型移植、可視化等步驟,使用RP2K數據集進行模型訓練,模型通過反復地特征學習提高分類精確度。同時,由于其中也包含部分細粒度難區分的類目(如不同水果、同種包裝的不同飲料),項目中使用了數據增強等技術手段提高模型的泛化能力,最終達到高精度地分類結果。
2.數據集
本次項目所使用的數據集為RP2K數據集
RP2K數據集
RP2K (Retail Product 2000K) 是一個用于零售場景的 大規模細粒度商品圖像分類數據集。
提出背景:在超市、便利店等零售場景中,存在數千上萬種商品,很多商品的外觀極其相似(比如不同口味的可樂、不同包裝的方便面),這使得計算機視覺中的 細粒度圖像分類(Fine-grained Image Classification, FGIC)成為一個關鍵挑戰。
RP2K數據集包含了2000+商品類別,數據總量超過 200 萬張商品圖片,圖片來源于真實零售場景(貨架拍攝、收銀臺、監控視頻幀)以及部分網絡采集,覆蓋了多角度(正面、側面、傾斜)、不同分辨率與清晰度、光照差異、遮擋(部分商品被擋住)等環境。
本項目節選了其中的500類數據作為該項目的數據集。
下載
官網:RP2K鏈接 – 品覽科技
下載的數據集已經被劃分好,無需自己手動進行數據清洗

3.模型訓練
3.1加載訓練集數據/數據預處理
(1)設置數據增強:包含了改變圖片大小、隨機裁剪、隨機水平翻轉、顏色改變、隨機翻轉、歸一化操作
transform = transforms.Compose([transforms.Resize((224, 224)), # 改變圖片大小transforms.RandomCrop((224, 224)), # 隨機裁剪transforms.RandomHorizontalFlip(), # 隨機水平翻轉transforms.ColorJitter(0.2, 0.2, 0.2, 0.1), # 改變顏色transforms.RandomRotation(10), # (-10°, 10°)隨機旋轉transforms.ToTensor(), # 歸一化transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])# 標準化
transforms.Compose() 是 PyTorch torchvision 中用于組合多個圖像預處理/增強操作的工具。它的作用就是把多個 transform 按順序串起來,讓圖像數據在加載時依次經過這些操作。
詳細參數介紹參考pytorch官方文檔:Illustration of transforms — Torchvision 0.23 documentation
(2)使用pytorch框架的ImageFolder加載訓練數據
data_train = ImageFolder(root='./data/train', transform=transform)
transform參數為(1)中的數據增強設置,即加載的每一張圖片都經過transform中的操作處理。
(3)使用數據加載器分批次加載數據
創建數據加載器對象:
train_loader = DataLoader(data_train, batch_size=32, num_workers=4, shuffle=True)
返回的train_loader是由數據包裝成的可迭代對象。
batch_size為每批次數據的數量大小,根據個人電腦GPU性能進行設置,一般設置為2n2^n2n。
num_workers為數據加載的子進程數,>0 表示用多進程加載,能加快訓練速度,一般設置為 0 或小于 CPU 核數。
shuffle決定是否打亂數據順序,一般在訓練時設置為True,測試時設置為False。
3.2模型選擇
這里我選擇了googlenet模型。我們的訓練思路是使用已經訓練好的模型參數,只對最后的輸出層進行訓練,也就是參數更新,具體操作如下。
加載預訓練參數
# 加載預訓練參數pretrained = googlenet(pretrained=True)pre_weights = pretrained.state_dict()pre_weights = {k: v.to(device) for k, v in pre_weights.items()}
state_dict()是模型通用方法,作用是返回參數字典
字典推導式的作用為遍歷原字典的每個鍵值對 (k,v),對每個 tensor v 調用 .to(device) 方法,把它移動到指定設備,device一般設置為:
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
參數和模型默認存放在CPU中,使用to(device)可將其轉移至GPU。
清除預訓練參數的最后一層:
# 清除預訓練參數最后一層數據pre_weights.pop('fc.weight')pre_weights.pop('fc.bias')
創建新模型:
# 創建模型model = googlenet(pretrained=False)num_classes = 500 # 分類類別數model.fc = nn.Linear(model.fc.in_features, num_classes)model = model.to(device)
? model.fc = nn.Linear(model.fc.in_features, num_classes)的作用是將原本網絡結構中的最后一層輸出(即類別數)改為500。
更新模型參數:
# 更新模型參數weigths = model.state_dict()weigths.update(pre_weights)model.load_state_dict(weigths)
將預訓練參數更新到模型中。
凍結層:
# 凍結層for name, param in model.named_parameters():if name != 'fc.weight' and name != 'fc.bias':param.requires_grad = False
將模型最后一層之前的參數的梯度計算禁用。
model.named_parameters() 是一個 生成器(generator),它會遍歷模型中的所有參數,并返回 (參數名, 參數張量) 這樣的鍵值對。
設置優化器:
# 優化器parameters = [x for x in model.parameters() if x.requires_grad]optimizer = opt.Adam(parameters, lr=1e-3)
優化器用于模型進行參數更新,這里我們只更新最后一層參數,并且使用的是Adam優化器。
設置損失函數:
# 損失函數criterion = nn.CrossEntropyLoss(reduction='sum')
選擇交叉熵損失函數作為多分類損失函數。reduction 參數,它決定了 批次(batch)里多個樣本的損失要如何合并,這里選擇的是進行求和。
定義訓練輪次:
epochs = 50
設置學習率調度器:
# 學習率調度器scheduler = opt.lr_scheduler.CosineAnnealingLR(optimizer, T_max=epochs, eta_min=1e-5)
這里選擇的是余弦學習率調度器,目的是對每輪訓練的學習率進行更新,讓學習率從 高學習率非線性地逐漸減小到低學習率。
3.3訓練
acc = []best_acc = 0# 訓練for epoch in range(epochs):acc_total = 0loss_total = 0for i, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)output = model(data)main_out = output[0] # 主輸出aux1_out = output[1] # 輔助輸出1aux2_out = output[2] # 輔助輸出2# 選取最大值作為分類結果,返回的pred為標簽下標pred = torch.argmax(main_out, dim=1)acc_total += torch.sum(pred == target).item()# 梯度清零optimizer.zero_grad()# 計算綜合損失loss = criterion(main_out, target) + 0.3 * (criterion(aux1_out, target) + criterion(aux2_out, target))loss_total += loss# 反向傳播loss.backward()# 參數更新optimizer.step()# 學習率更新scheduler.step()# 將當前輪次模型準確率記錄在acc中acc.append(acc_total / len(data_train))current_acc = acc[epoch]# 判斷當前輪次參數準確率是否為最佳,若為最佳則保存該參數if current_acc > best_acc:# 更新最佳準確率best_acc = current_acctorch.save(model.state_dict(), './model/model.pth')# 打印每輪訓練結果print(f'epoch--->{epoch + 1},'f'loss---> {loss_total.item() / len(data_train):.4f},'f' acc---> {acc_total / len(data_train):.4f}')acc用于保存每輪訓練后的參數,best_acc用于保存歷史最高準確率- 由于Googlenet模型內置有輔助選擇器,所以其輸出結果為一個元組,為一個主要輸出和兩個輔助輸出,在進行損失函數計算的過程中,需要考慮輔助分類的損失,通過分配不同權重比得到最終的損失函數。
- 判斷當前準確率是否為歷史最佳準確率,若為最佳準確率則保存參數,方便后續進行模型遷移。
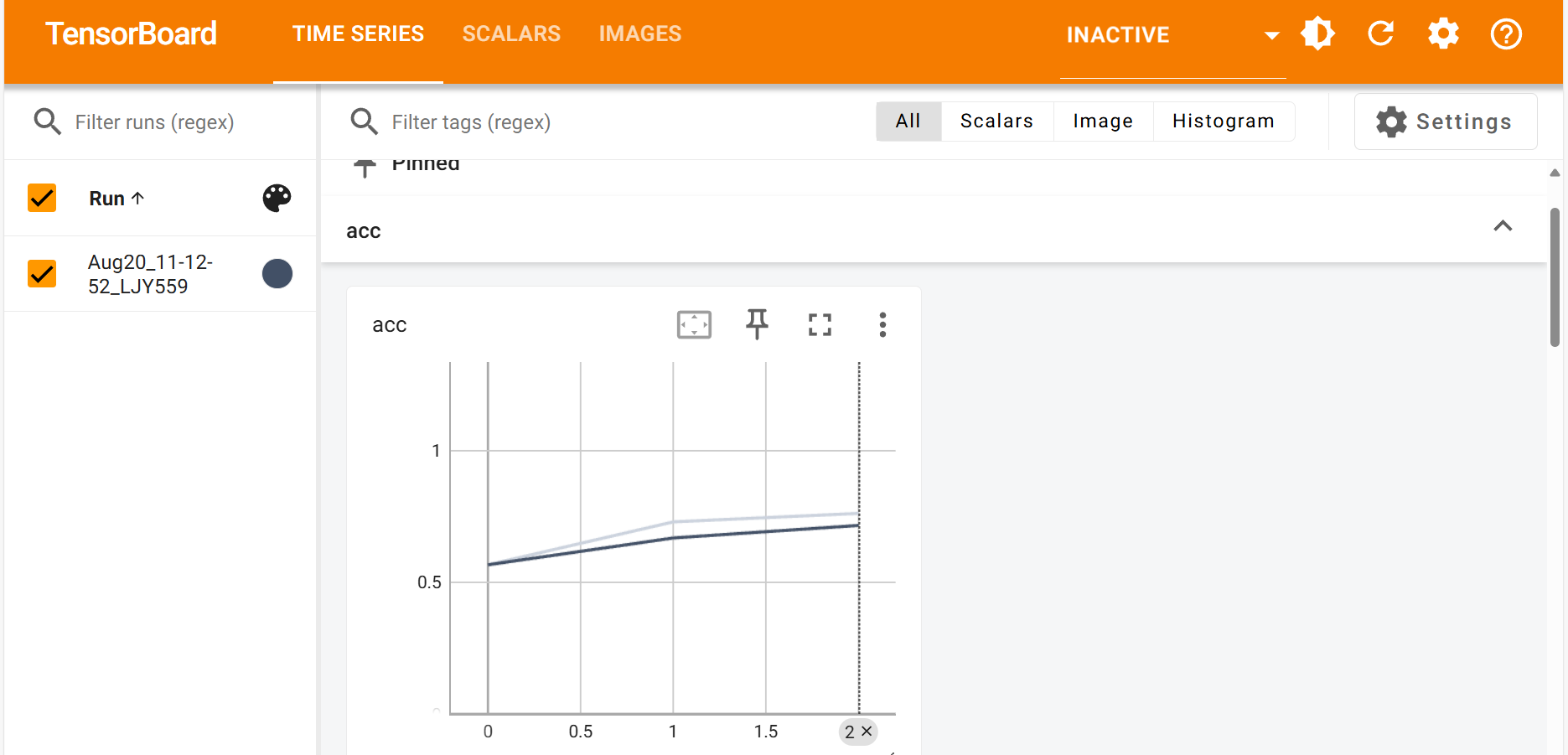
3.4訓練過程可視化
使用tensorboard模塊將訓練過程可視化:
from torch.utils.tensorboard import SummaryWriter
創建tensorboard對象:
# 創建tensorboard對象writer = SummaryWriter()
SummaryWriter(log_dir=tbpath)log_dir為tensorboard日志保存路徑,未設置保存路徑會保存至當前文件夾下自動創建的runs文件夾下。
繪制過程曲線:
writer.add_scalar('loss', loss_total, epoch)writer.add_scalar('acc', acc_total / len(data_train), epoch)
顯示數據增強后的圖片:
if i % 100 == 0:img_grid = torchvision.utils.make_grid(data)writer.add_image(f'r_m_{epoch}', img_grid, i)
運行后會在runs文件夾內生成可視化的文件。
接下來打開終端,輸入命令:
tensorboard --logdir=runs
也可將runs改為指定路徑。
隨后點擊生成的本地網站即可查看繪制的曲線圖以及圖片:
4.模型評估
4.1加載預測集數據
同加載訓練集類似,只不過在數據增強時一般只進行重新設置圖片大小和標準化以及歸一化操作,因為模型預測是在真實數據分布下的表現,因此我們 不能引入隨機性,而resize圖片大小是為了讓數據的shape和模型的輸入shape一致。
# 加載預測數據集
transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
data_test = ImageFolder(root='./data/test', transform=transform)
test_loader = DataLoader(data_test, batch_size=32, shuffle=False)
4.2加載模型
加載之前訓練好的模型參數
# 加載訓練好的模型
model = googlenet(pretrained=False)
model.fc = nn.Linear(model.fc.in_features, 500)
model = model.to(device)
weights = torch.load('./model/model.pth')
model.load_state_dict(weights)
4.3結果預測
首先將模型切至驗證模式:
# 驗證模式
model.eval() # 關閉 Dropout 和輔助分類器
注意:這一步至關重要,模型默認會處于訓練模式下,這會使得google網絡結構中的輔助分類和Dropout沒有關閉,dropout未關閉會導致預測時神經元丟失,影響最終結果。
進行驗證:
with torch.no_grad():acc = 0for data, label in test_loader:data, label = data.to(device), label.to(device)output = model(data)# 選取最大值作為分類結果,返回的pred為標簽下標pred = torch.argmax(output, dim=1)acc += torch.sum(pred == label).item()
with torch.no_grad():作用:關閉參數梯度計算,加速預測,節省內存。
4.4預測評估
打印結果:
acc = acc / len(data_test)
print(f"acc:{acc:.5f}")
4.5預測結果可視化
可引入numpy和pandas將預測的數據轉變成excel表格(csv格式文件),具體操作如下:
創建一個列數為502的numpy空二維數組:
data_csv = np.empty((0, 502))
因為模型的輸出為每個類別下所對應的輸出值,取最大的輸出值的類別作為分類結果,所以需要500列存放模型輸出值,1列存放預測標簽,1列存放實際標簽。
將每一批次訓練的數據存入numpy數組:
output_csv = output.cpu().detach().numpy()
pred_csv = np.expand_dims(pred.cpu().detach().numpy(), axis=1)
label_csv = np.expand_dims(label.cpu().detach().numpy(), axis=1)
batch_csv = np.concatenate((output_csv, pred_csv, label_csv), axis=1)
data_csv = np.concatenate((data_csv, batch_csv), axis=0)
取出標簽:
labels = data_test.classes
將結果轉換為Datafream再導出為csv文件:
# 將結果轉為csv文件
column = [*labels, 'pred', 'label']
data_csv = pd.DataFrame(data=data_csv, columns=column)
data_csv.to_csv('./data_pred_result/result.csv', index=False)
同時把標簽存為csv文件:
# 將標簽存為csv文件
df = pd.DataFrame({"index": list(range(len(labels))), "label": [*labels]})
df.to_csv('./labels.csv', index=False)
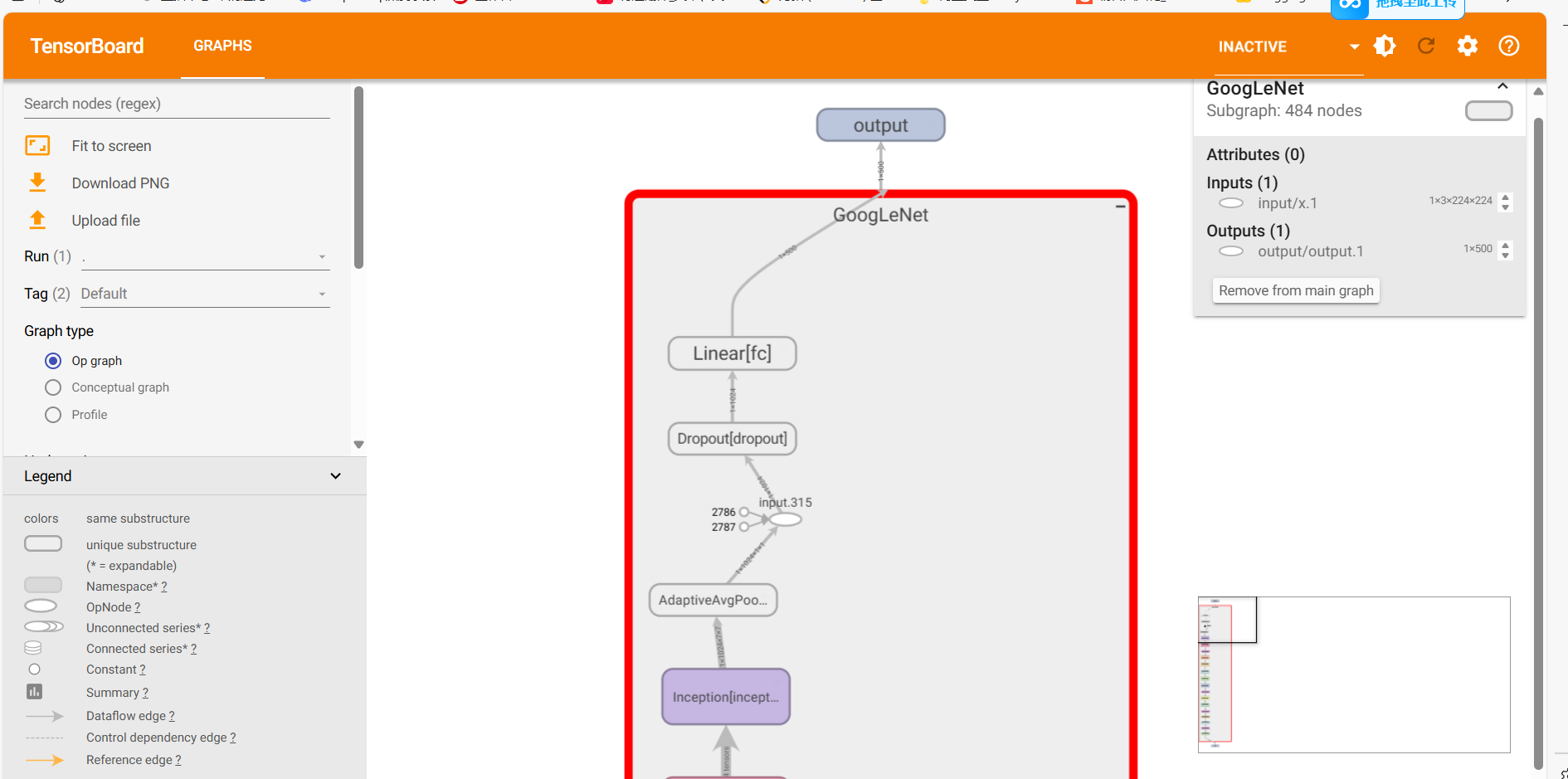
也可以將網絡結構進行可視化觀察網絡結構:
writer = SummaryWriter("./net_frame")
dummy_input = torch.randn(1, 3, 224, 224)
writer.add_graph(model, dummy_input.to(device))
writer.close()
同樣的用終端生成本地網站,進入網站查看可視化結果:
tensorboard --logdir=文件絕對路徑
4.6生成分類報告
導入matplotlib模塊和pandas模塊,讀到之前預測生成的csv文件,獲取標簽:
# csv文件地址
data_path = './data_pred_result/result.csv'
# 讀取csv數據
data = pd.read_csv(data_path)
# 獲取真實標簽
true_label = data["label"].values
# 獲取預測標簽
pred_label = data["pred"].values
接著導入sklearn.metrics模塊生成分類報告:
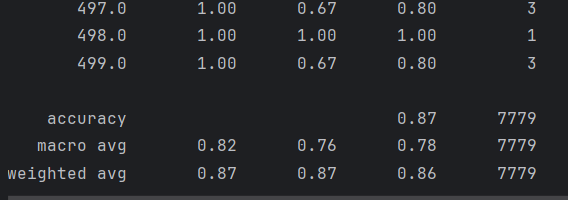
# 生成分類報告report = classification_report(true_label, pred_label)print(report)acc = accuracy_score(true_label, pred_label)precision = precision_score(true_label, pred_label, average='macro')recall = recall_score(true_label, pred_label, average='macro')f1 = f1_score(true_label, pred_label, average='macro')print(f"準確度:{acc:.6f}\n"f"精確度:{precision:.6f}\n",f"召回率:{recall:.6f}\n",f"f1:{f1:.6f}\n")
用matlplotlib生成混淆矩陣(由于原始數據的混淆矩陣太大,500分類即500*500矩陣,這里只生成前十分類的混淆矩陣作為演示):
def vision_martix(true_label, pred_label, num_classes=10):labels = [x for x in range(num_classes)]matrix = confusion_matrix(true_label, pred_label)print(matrix)plt.figure(figsize=(8, 8))plt.matshow(matrix[:10, :10], cmap=plt.cm.Greens, fignum=1)# 顯示顏色條plt.colorbar()# 顯示具體的數字的過程for i in range(len(matrix)):for j in range(len(matrix)):plt.annotate(matrix[i, j],xy=(j, i),horizontalalignment="center",verticalalignment="center",)# 美化的東西plt.xlabel("Pred labels")plt.ylabel("True labels")plt.xticks(range(len(labels)), labels, rotation=45)plt.yticks(range(len(labels)), labels)plt.title("訓練結果混淆矩陣視圖")plt.show()
效果:
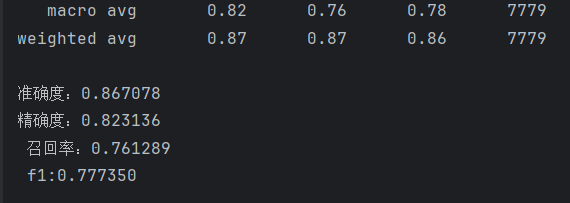
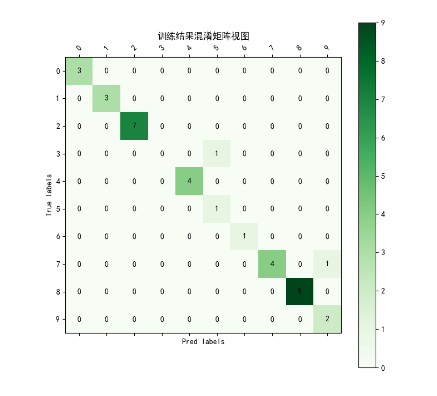
5.模型應用
首先讀取圖片,這里我導入了opencv模塊進行讀圖,并且將讀取到的圖片進行預處理操作:
# 讀圖處理img = cv.imread(img_path)img = cv.resize(img, (224, 224))transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5))])img = transform(img)img = torch.unsqueeze(img, 0).to(device)
加載訓練好的模型:
net = googlenet(pretrained=False)net.fc = nn.Linear(net.fc.in_features, 500)net.load_state_dict(torch.load("./model/model.pth"))net.to(device)
進行預測:
# 預測net.eval()output = net(img)output = torch.argmax(output, dim=1)print(output)
可以用Imagefolder導入訓練集或輸出集獲取標簽映射表,將標簽映射轉換為下標映射:
idx_to_class = {v: k for k, v in data.class_to_idx.items()}
print(idx_to_class[pred])
最后得到結果:

6.模型遷移
6.1導出onnx模型
首先需要提前在環境內安裝依賴包
pip install onnx
pip install onnxruntime
導入訓練好的模型:
# 導入訓練好的模型
net = googlenet(pretrained=False)
net.fc = nn.Linear(in_features=net.fc.in_features, out_features=500)
weight_path = "./model/model.pth"
net.load_state_dict(torch.load(weight_path))
創建一個實例輸入:
x = torch.randn(1, 3, 224, 224)
用torch.onnx.export導出onnx:
torch.onnx.export(net,x,onnx_path,verbose=True,input_names=['input'],output_names=['output']
)
6.2使用onnx推理
加載onnx模型:
# 加載onnx模型
onnx_path = './model_onnx/model.onnx'
session = rt.InferenceSession(onnx_path)
對要進行推理的圖片進行預處理:
def read_img(path):# 處理輸入圖片img = cv.imread(path)img = cv.resize(img, (224, 224))img = img.transpose((2, 0, 1))img = img.astype(np.float32) / 255.0 # 代替Totensor()操作img = np.expand_dims(img, axis=0)return imgimg_path = "./apply/1.jpg"
img1 = read_img(img_path)
進行推理:
# 獲取輸入輸出名
input_name = session.get_inputs()[0].name
output_name = session.get_outputs()[0].name# 推理
result = session.run([output_name], {input_name: img1})
得到結果并且將結果從下標值映射為標簽名:
# 取出分類標簽下標
result = np.argmax(result[0], axis=1)
print(result)# 讀取保存好的標簽csv文件建立 index->label 映射表
df = pd.read_csv("labels.csv")
idx2label = dict(zip(df["index"], df["label"]))
print(f"img的分類為:{idx2label[result.item()]}")
項目源代碼倉庫:卷積神經網絡項目實戰: 卷積神經網絡個人實戰項目
注意:訓練集以及生成文件夾需要自己手動創建,具體文件夾已在file_expression文檔中說明。
ply/1.jpg"
img1 = read_img(img_path)
進行推理:```python
# 獲取輸入輸出名
input_name = session.get_inputs()[0].name
output_name = session.get_outputs()[0].name# 推理
result = session.run([output_name], {input_name: img1})
得到結果并且將結果從下標值映射為標簽名:
# 取出分類標簽下標
result = np.argmax(result[0], axis=1)
print(result)# 讀取保存好的標簽csv文件建立 index->label 映射表
df = pd.read_csv("labels.csv")
idx2label = dict(zip(df["index"], df["label"]))
print(f"img的分類為:{idx2label[result.item()]}")
項目源代碼倉庫:卷積神經網絡項目實戰: 卷積神經網絡個人實戰項目
注意:訓練集以及生成文件夾需要自己手動創建,具體文件夾已在file_expression文檔中說明。
如果博主的文檔和源代碼對你有所幫助,也麻煩給博主點個收藏和贊噢,謝謝☆嚕~☆
)
)


-理解筆記4)













使用)
)