目錄
數據聚合
聚合的種類
DSL實現聚合
桶聚合
度量聚合
RestAPI實現聚合
多條件聚合
自動補全
拼音分詞器
自定義分詞器
自動補全查詢
實現搜索框自動補全
數據同步
數據同步思路分析
實現elasticsearch與數據庫數據同步
集群
搭建ES集群
集群腦裂問題
集群故障轉移
集群分布式存儲
集群分布式查詢
數據聚合
聚合的種類
聚合可以實現對文檔數據的統計、分析、運算。聚合常見的有三類:
桶聚合:用來對文檔做分組
? ? ? ? ? ?TermAggregation:按照文檔字段值分組
? ? ? ? ? ?Date Histogram:按照日期階梯分組,例如一周為一組,或者一月為一組
度量聚合:用以計算一些值,比如:最大值、最小值、平均值等
? ? ? ? ? ?Avg:求平均值
? ? ? ? ? Max:求最大值
? ? ? ? ? Min:求最小值
? ? ? ? ? Stats:同時求max、min、avg、sun等
管道聚合:其它聚合結果為基礎做聚合
參與聚合的字段類型必須是:
keyword
數值
日期
布爾
DSL實現聚合
桶聚合

默認情況下,桶聚合會統計桶內的文檔數量,記為_count,并且按照_count 降序排序。我們可以修改結果排序方式:

?默認情況下,桶聚合是對索引庫的所有文檔做聚合,我們可以限定要聚合的文檔范圍,只要添加query條件即可:

度量聚合
例如,我們要求獲取每個品牌的用戶評分的min、max、avg等值.

RestAPI實現聚合
聚合請求的構造

聚合結果的解析

多條件聚合
多條件聚合構建
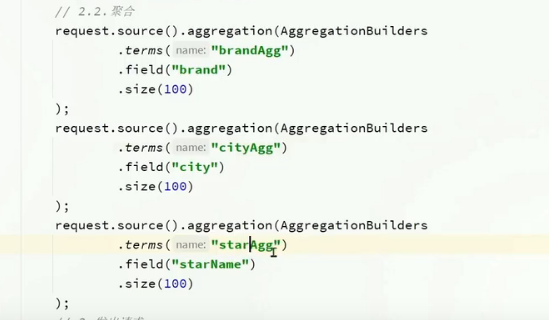
結果解析
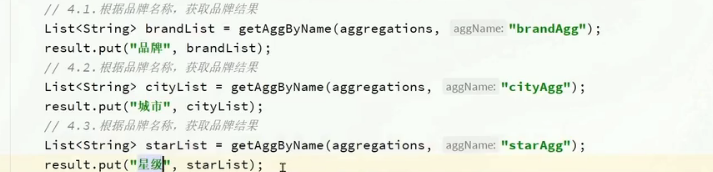
自動補全
拼音分詞器
使用拼音分詞
要實現根據字母做補全,就必須對文檔按照拼音分詞。插件:infinilabs/analysis-pinyin: 🛵 This Pinyin Analysis plugin is used to do conversion between Chinese characters and Pinyin.
下載完將壓縮包解壓到es的plugins目錄即可
自定義分詞器
Elasticsearch 中分詞器(Analyzer)的組成包含三部分:
-
Character Filters(字符過濾器)
-
在 Tokenizer 之前對原始文本進行預處理。
-
例如:刪除特殊字符、替換字符(如將?
&?替換為?and)。
-
-
Tokenizer(分詞器)
-
將文本按照特定規則切割成詞條(Term)。
-
例如:
-
keyword:不分詞,將整個文本作為一個詞條。 -
ik_smart:智能切分(粗粒度分詞)。
-
-
-
Token Filters(詞條過濾器)
-
對 Tokenizer 輸出的詞條進行進一步處理。
-
例如:大小寫轉換、同義詞處理、拼音處理等。
-
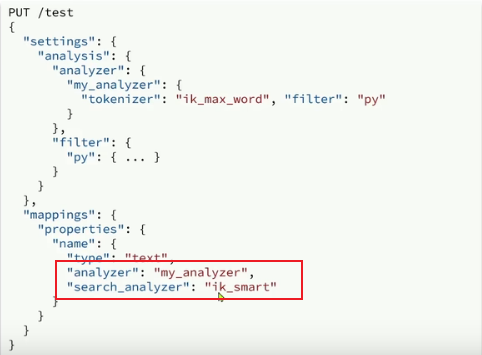
我們可以在創建索引庫時,通過setting來配置自定義的analyzer(分詞器):

自定義分詞器配置

拼音分詞器適合在創建倒排索引的時候使用,但不能在搜索的時候使用。
因此字段在創建倒排索引時應該用my_analyzer分詞器;字段在搜索時應該使用ik__smart分詞器;
自動補全查詢
es提供了Completion Suggerter查詢來實現自動補全功能。這個查詢會匹配以用戶輸入內容開頭的詞條并返回。為了提高補全查詢的效率,對于文檔中字段的類型有一些約束:
? 參與補全查詢的字段必須是completion類型。
??
字段的內容一般是用來補全的多個詞條形成的數組

查詢語法

實現搜索框自動補全
1.修改索引庫,設置自定義拼音分詞器
2.修改索引庫的name、all字段,使用自定義分詞器
3.索引庫添加一個新字段suggestion,類型為completion 字段,使用自定義分詞器
4.給實體類添加suggestion字段,內容包含所需要補詞的內容
5.重新導入數據
RestAPI實現自動補全

結果解析

數據同步
數據同步問題分析
es中酒店數據來自于mysql數據庫,因此mysql數據發生改變時,es也必須跟著改變,這個就是es與mysql之間的數據同步。
數據同步思路分析
方案一:同步調用
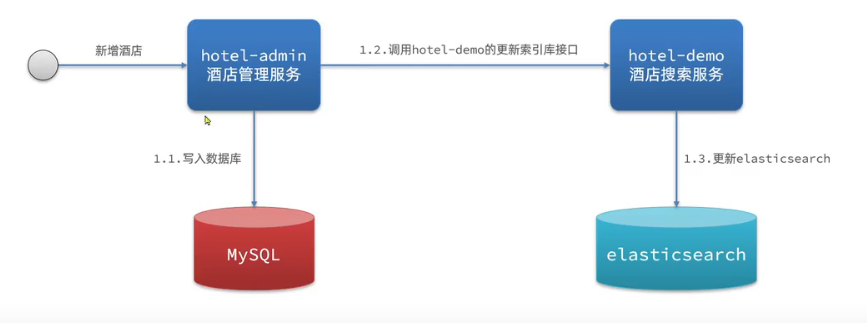
優點:實現簡單,粗暴
缺點:耦合度高
方案二:異步通知
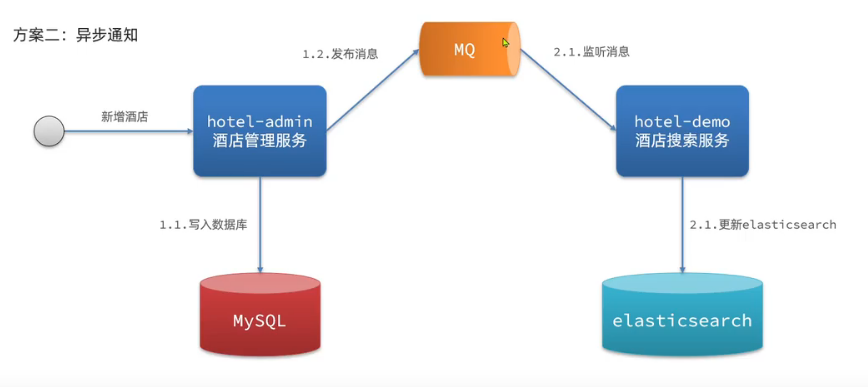
優點:低耦合,實現難度一般
缺點:依賴mq的可靠性
方案三:監聽binlog
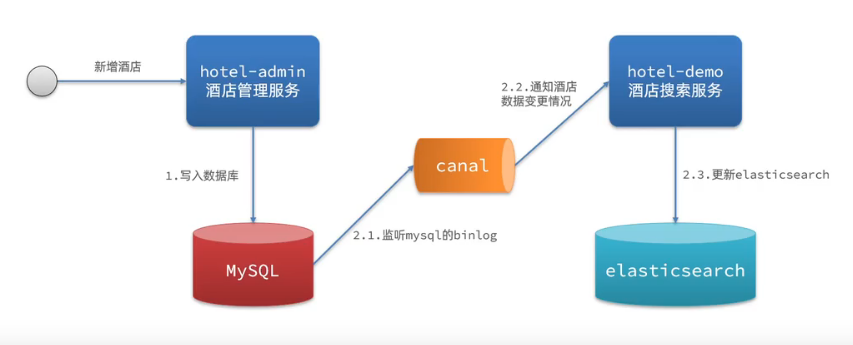
優點:完全接觸服務間耦合
缺點:開啟binlog增加數據庫負擔、實現復雜度高
實現elasticsearch與數據庫數據同步
利用MQ實現mysql與es數據同步
步驟:
導入數據
聲明exchange、queue、RoutingKey
完成數據庫中增、刪、改業務并完成消息發送
完成消息監聽并且更新es中數據
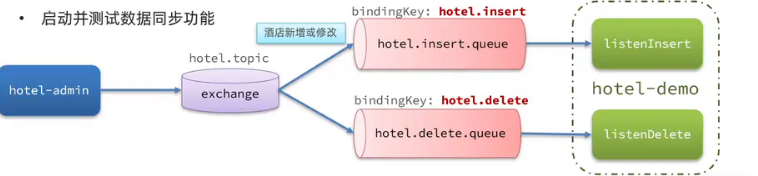
導入MQ依賴
配置MQ
集群
ES集群結構
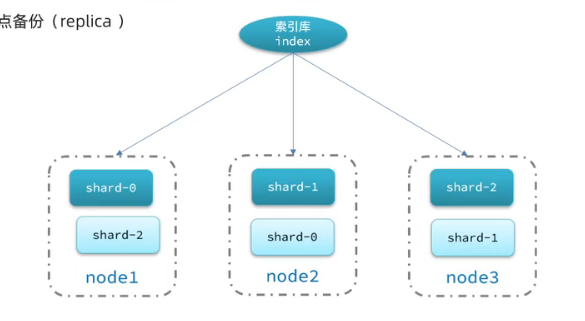
單機的es做數據存儲,必然面臨兩個問題:海量的數據存儲問題、單點故障問題。
海量數據存儲問題:將索引庫從邏輯上拆分為N個分片,存儲到多個節點
單點故障問題:將分片數據在不同節點備份
搭建ES集群
利用docker容器模擬3個es的節點。


)

)



文件語法詳解)





)




