目錄
前言:
1.了解ultralytics工程與yolo模型
1.1 yolo11可以為我們做些什
1.2 yolo11模型的高性能
1.3 對于yolo11一些常見的問題
1.3.1 YOLO11 如何以更少的參數實現更高的精度?
1.3.2 YOLO11 可以部署在邊緣設備上嗎?
2. 深入了解yolo11的使用
2.1 yolo環境配置
2.2 yolo創建模型實例化
2.3 yolo的predict()方法
2.3.1 基本語法
2.3.2 核心參數
2.4 yolo的Results對象
2.4.1?Results對象方法實例
2.5 yolo的實例分割
2.5.1Results對象中的,masks屬性
2.5.2 Masks 的工作原理
2.5.3 實例分割示例
2.6 yolo的姿態估計
2.6.1 Results對象的Keypoint屬性
2.6.2?Keypoints 的數據集與標注規范
2.6.3 姿態檢測示例
結語
前言:
????????Ultralytics 是一個專注于計算機視覺領域的開源項目,以其高效的 YOLO (You Only Look Once) 系列目標檢測算法實現而聞。該項目不僅提供了預訓練模型,還包含了一套完整的工具鏈,支持從數據標注、模型訓練到推理部署的全流程工作。YOLO 系列算法從 v3 發展到最新的 v11,在模型結構、訓練策略、推理速度和精度上進行了持續優化。
在本文中我們就是通過yolo11系列去展開yolo功能詳解
1.了解ultralytics工程與yolo模型
這里給出ultralytics的官方文檔鏈接Ultralytics YOLO11 - Ultralytics YOLO 文檔?這里面有對該工程的詳細介紹,你想要的內容基本都會提及。
下面對于ultralytics工程和最新的yolo11模型我也做出簡要的總結
1.1 yolo11可以為我們做些什
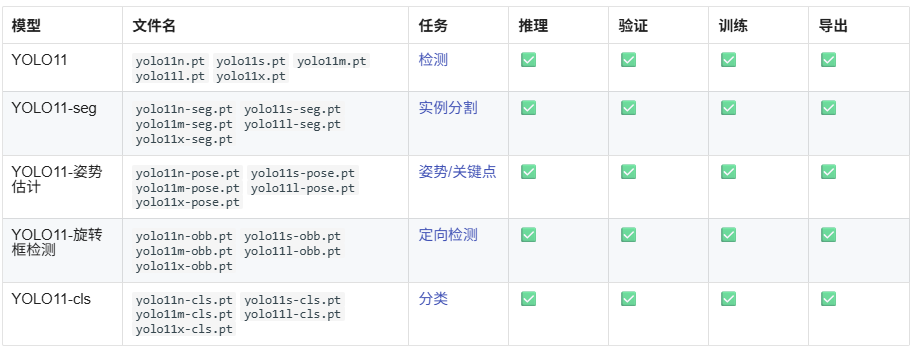
YOLO11 模型用途廣泛,支持各種計算機視覺任務,包括:
- 目標檢測:?識別和定位圖像中的目標。
- 實例分割:?檢測目標并描繪其邊界。
- 圖片分類:?將圖像分類為預定義的類別。
- 姿勢估計:?檢測和跟蹤人體上的關鍵點。
- 旋轉框檢測 (OBB):?檢測具有旋轉的對象,以獲得更高的精度。
 ?
?
具體功能我們將在后面用到
1.2 yolo11模型的高性能
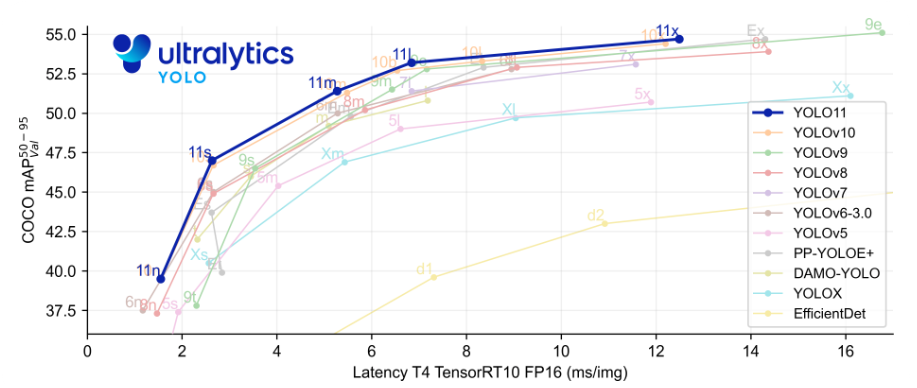
每一次yolo模型的更新在性能上都稱得上是一次質的飛躍,到現在最新的yolo11可以說是十分成熟的視覺模型。
 ?
?
下面是官方對最新yolo11的描述
- 增強的特征提取:?YOLO11 采用了改進的骨干網絡和頸部架構,增強了特征提取能力,從而實現更精確的目標檢測。
- 優化的效率和速度:?改進的架構設計和優化的訓練流程提供了更快的處理速度,同時保持了準確性和性能之間的平衡。
- 以更少的參數實現更高的精度:?YOLO11m 在 COCO 數據集上實現了更高的平均精度均值 (mAP),與 YOLOv8m 相比,參數減少了 22%,從而在不影響準確性的前提下提高了計算效率。
- 跨環境的適應性:?YOLO11 可以部署在各種環境中,包括邊緣設備、云平臺和支持 NVIDIA GPU 的系統。
- 廣泛支持的任務范圍:?YOLO11 支持各種計算機視覺任務,例如目標檢測、實例分割、圖像分類、姿勢估計和旋轉框檢測 (OBB)。
1.3 對于yolo11一些常見的問題
1.3.1 YOLO11 如何以更少的參數實現更高的精度?
通過模型設計和優化技術的進步,YOLO11 以更少的參數實現了更高的準確率。 改進的架構允許高效的特征提取和處理,從而在使用比 YOLOv8m 少 22% 的參數的同時,在 COCO 等數據集上實現更高的平均精度 (mAP)。 這使得 YOLO11 在計算上高效,同時又不影響準確性,使其適合部署在資源受限的設備上。
1.3.2 YOLO11 可以部署在邊緣設備上嗎?
是的,YOLO11 旨在適應各種環境,包括邊緣設備。其優化的架構和高效的處理能力使其適合部署在邊緣設備、云平臺和支持 NVIDIA GPU 的系統上。這種靈活性確保了 YOLO11 可用于各種應用,從移動設備上的實時檢測到云環境中的復雜分割任務。有關部署選項的更多詳細信息,請參閱導出文檔。
這里我要提到的是其實我們一些常用的視覺模塊k230,Jetson Nano,Coral TPU(谷歌),瑞芯微RKNN芯片:如RK3566、RK3588等邊緣設備都可以部署YOLO模型!后續會更新在這些設備上部署yolo。
2. 深入了解yolo11的使用
要了解yolo11的使用我們主要掌握predict()方法和Results對象
2.1 yolo環境配置
? ? Ultralytics 開源工程主要使用?Python?語言開發,該工程基于 PyTorch 深度學習框架,而 PyTorch 的主要接口和生態系統以 Python 為核心;
? ?我想表達的意思是使用yolo模型需要一個比較嚴格的python環境,這個復雜的過程在我另一篇博客中有詳細的過程,下面是博客鏈接(超詳細)yolo11機器視覺模型環境配置(附帶攝像頭識別測試)_yolo11環境配置-CSDN博客
2.2 yolo創建模型實例化
在官方的文檔中有下面一句話
PyTorch pretrained?*.pt?模型以及配置?*.yaml?文件可以傳遞給?YOLO()?類在 Python 中創建模型實例:
于是通過下面的代碼我們可以創建模型實例化,以及查看是否實例化成功,以及查看關于該模型的一些信息。
from ultralytics import YOLO #導入必要的庫
model = YOLO('yolo11n.pt') # 模型路徑# 檢查模型信息
print(f"模型類別數: {model.model.nc}")
print(f"模型類別名稱: {model.names}")# 獲取模型輸入尺寸
print(f"模型輸入尺寸: {model.model.args.get('imgsz', 640)}")我的pycharm控制臺輸出下面信息

可以看到我們這個模型可以識別80種物品,隨后打印出可以識別物品的類別以及編號。
2.3 yolo的predict()方法
2.3.1 基本語法
results = model.predict(source, **kwargs)-?返回值 :若輸入為單張圖像 / 單幀視頻,返回一個Results對象;若輸入為批量圖像 / 視頻流,返回Results對象的列表(或生成器,取決于stream參數)。
2.3.2 核心參數
| 參數名 | 類型 | 作用 | 默認值 | 實用場景 |
|---|---|---|---|---|
source | 多種類型 | 輸入源(推理對象) | 必需參數 | 支持:圖像路徑("img.jpg")、視頻路徑("video.mp4")、攝像頭 ID(0表示默認攝像頭)、RTSP 流("rtsp://...")、numpy 數組(cv2讀取的圖像)、PIL 圖像等。 |
conf | float | 置信度閾值 | 0.25 | 過濾低置信度目標(如conf=0.5表示只保留置信度≥50% 的結果)。值越高,結果越嚴格(誤檢少,但可能漏檢)。 |
iou | float | 非極大值抑制(NMS)的 IOU 閾值 | 0.45 | 解決目標框重疊問題(如多個框檢測同一目標)。值越高,允許的重疊度越大(可能保留重復框);值越低,會過濾更多重疊框。 |
classes | list[int] | 指定檢測的類別 | None(檢測所有類別) | 只檢測特定目標,如classes=[0](只檢測 “人”,0 是 COCO 數據集的 “人” 類別 ID)、classes=[2, 3](只檢測 “汽車” 和 “摩托車”)。 |
imgsz | int/tuple | 輸入圖像尺寸 | 640 | 模型推理時將輸入縮放到該尺寸(如640表示 640×640,(800, 600)表示寬 800× 高 600)。尺寸越大,精度可能越高,但速度越慢。 |
device | str/int | 推理設備 | 自動選擇(優先 GPU) | 指定用 CPU("cpu")或 GPU(0表示第 1 塊 GPU,"0,1"表示多 GPU)。測試時用 CPU 方便,批量處理用 GPU 加速。 |
stream | bool | 是否啟用流模式 | False | 處理視頻 / 攝像頭時建議設為True,通過生成器逐幀返回結果,大幅節省內存(尤其長視頻)。 |
save | bool | 是否自動保存結果 | False | 設為True時,自動將標注后的圖像 / 視頻保存到runs/detect/exp*目錄(可通過project和name參數自定義路徑)。 |
show | bool | 是否實時顯示結果 | False | 處理攝像頭 / 視頻時設為True,會彈出窗口實時顯示帶檢測框的畫面(需要 GUI 支持)。 |
下面我在origin目錄下放了一張包含人和狗的圖片(但是我讓他只識別人),然后識別后放在result/personanddog目錄下,
代碼如下
from ultralytics import YOLO
import os#如果文件夾不存在將創建文件夾
os.makedirs("result",exist_ok=True)#實例化模型
model = YOLO("yolo11n.pt")#執行預測
results = model.predict(source="origin/personandgod.jpg", #要識別的圖片路徑 conf = 0.5, #置信度設置(低于該置信度將不會被框選)classes = [0], #只需要識別人project = "result", #要保存的文件地址name = "personandgod_s", #保存在該名下save=True #確保文件被保存)
如上圖他只把任務框選出來了,那大家根據參數設置我們該如何做到只識別狗呢?嘗試一下這個小實驗。
下面做一個攝像頭實時識別實驗,還是讓他只識別人。其實不用yolo自帶的視頻實時顯示我問也可以使用python cv2庫中的方法實現視頻顯示,大家可以試試看。
from ultralytics import YOLO
import cv2model = YOLO("yolo11n.pt")results = model.predict(source=0, # 本地攝像頭show=True, # 實時顯示stream=True, # 流模式省內存classes = [0], #只識別人物conf=0.4, # 適中的置信度閾值imgsz=640 #尺寸大小
)
for r in results: # 逐幀處理if cv2.waitKey(1) & 0xFF == ord('q'): #按q退出break效果如下圖
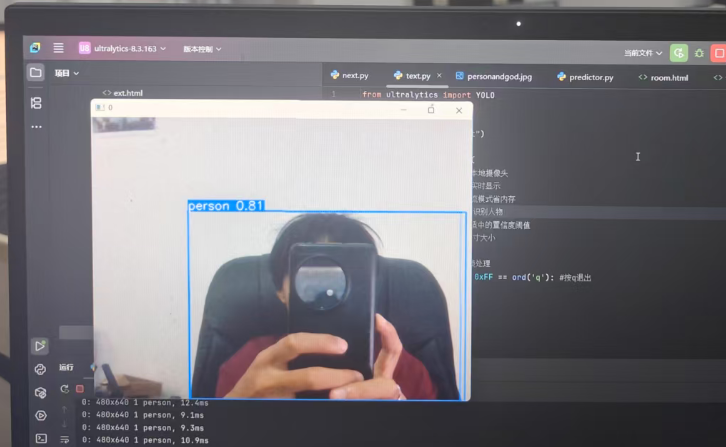
可以看到即使有遮擋物識別效果依舊精準!
2.4 yolo的Results對象
predict()?方法返回一個?Results?對象或?Results?對象列表,包含豐富的檢測信息。可以說Results是 YOLO 推理結果的 “容器”,封裝了從輸入到輸出的所有信息(原始圖像、檢測框、類別等)。對于目標檢測任務
1. 基礎屬性(通用信息):
| 屬性名 | 類型 | 含義 |
|---|---|---|
orig_img | numpy.ndarray | 原始輸入圖像(BGR 格式,可直接用cv2處理)。 |
orig_shape | tuple | 原始圖像的尺寸,格式為(height, width)(如(480, 640)表示高 480 像素,寬 640 像素)。 |
path | str | 輸入圖像 / 視頻幀的路徑(或攝像頭 ID)。 |
boxes | Boxes對象 | 檢測到的目標邊界框信息(核心屬性,下文詳細說明)。 |
2. 核心屬性:boxes(邊界框信息)
boxes是Results中最常用的屬性,類型為Boxes對象,封裝了所有檢測到的目標的邊界框、類別、置信度等信息。其常用子屬性如下:
| 子屬性 | 類型 | 含義 | 示例 |
|---|---|---|---|
xyxy | torch.Tensor | 目標框坐標(絕對坐標),格式為(x1, y1, x2, y2),其中(x1,y1)是左上角,(x2,y2)是右下角。 | 若box.xyxy = tensor([[100, 200, 300, 400]]),表示目標框左上角在 (100,200),右下角在 (300,400)。 |
xywh | torch.Tensor | 目標框坐標(絕對坐標),格式為(x_center, y_center, width, height)(中心坐標 + 寬高)。 | tensor([[200, 300, 200, 200]])表示中心在 (200,300),寬 200,高 200。 |
xyxyn/xywhn | torch.Tensor | 歸一化坐標(相對圖像尺寸,范圍 0~1),用途同上(方便跨尺寸統一處理)。 | 若圖像寬 640,xyxyn中0.5表示 320 像素位置。 |
conf | torch.Tensor | 每個目標的置信度(0~1)。 | tensor([0.85])表示置信度 85%。 |
cls | torch.Tensor | 每個目標的類別 ID(對應model.names中的索引)。 | tensor([0.])表示類別 ID 為 0(通常是 “人”)。 |
id | torch.Tensor | 目標跟蹤 ID(僅在track()方法中存在,用于多幀關聯同一目標)。 | tensor([5.])表示該目標的跟蹤 ID 為 5。 |
len(boxes) | int | 檢測到的目標數量。 | len(result.boxes) = 3表示檢測到 3 個目標。 |
3.?Results對象的常用方法
| 方法 | 作用 | 示例 |
|---|---|---|
plot() | 生成帶檢測框的圖像(可視化結果),返回numpy.ndarray(BGR 格式)。 | annotated_img = result.plot(line_width=2, conf=True)(自定義線寬,顯示置信度)。 |
save(save_dir) | 保存帶檢測框的圖像到指定目錄。 | result.save("output_dir")(保存到output_dir文件夾)。 |
save_crop(save_dir) | 裁剪每個檢測到的目標并保存到指定目錄。 | result.save_crop("cropped_objects")(每個目標單獨存為一張圖)。 |
tojson() | 將結果轉換為 JSON 字符串(方便存儲和傳輸)。 | json_str = result.tojson()。 |
Results對象方法實在太多,其子屬性的子方法也是很多,下面代碼展示常用方法的使用
2.4.1?Results對象方法實例
下面的代碼是對工程目錄origin目錄下test.jpg圖片的識別,圖片中有兩個人物,具體作用看注釋
from ultralytics import YOLOmodel = YOLO("yolo11n.pt")
results = model.predict("origin/test.jpg", conf=0.5) # 單張圖像推理# 取第一個結果(單張圖像只有一個Results對象)
result = results[0]# 1. 基礎信息
print(f"原始圖像尺寸: {result.orig_shape}") # 輸出 (高度, 寬度)
print(f"圖像路徑: {result.path}")
print(f"檢測到的目標數量: {len(result.boxes)}")# 2. 遍歷所有檢測到的目標
for i, box in enumerate(result.boxes):# 邊界框坐標(轉換為列表方便處理)x1, y1, x2, y2 = box.xyxy[0].tolist() # 絕對坐標# 類別與置信度cls_id = int(box.cls[0]) # 類別IDcls_name = model.names[cls_id] # 類別名稱(如"person")conf = float(box.conf[0]) # 置信度# 輸出信息print(f"目標{i + 1}:")print(f" 類別: {cls_name} (ID: {cls_id})")print(f" 置信度: {conf:.2f}")print(f" 邊界框: 左上角({x1:.1f}, {y1:.1f}), 右下角({x2:.1f}, {y2:.1f})")# 3. 實例化并保存結果
annotated_img = result.plot(line_width=3, # 邊界框線寬font_size=10, # 字體大小conf=True, # 顯示置信度labels=True # 顯示類別名稱
)
result.save("result/test.jpg") # "路徑"
# 或手動用cv2保存
import cv2cv2.imwrite("result/custom_result.jpg", annotated_img)下面是打印信息
檢測到的目標數量: 2
目標1:
? 類別: person (ID: 0)
? 置信度: 0.63
? 邊界框: 左上角(4.3, 212.8), 右下角(1178.8, 1276.9)
目標2:
? 類別: person (ID: 0)
? 置信度: 0.56
? 邊界框: 左上角(768.6, 42.2), 右下角(1705.0, 1276.1)?
可以看到結果也是符合我們預期,也是在result文件夾中保存了兩張識別后的圖片,下面是識別結果(花是我后期加的)。

最后提一句
遍歷順序和規則,按檢測置信度降序排列(默認行為)!
不過也可以更改排序,這里不在多說
2.5 yolo的實例分割
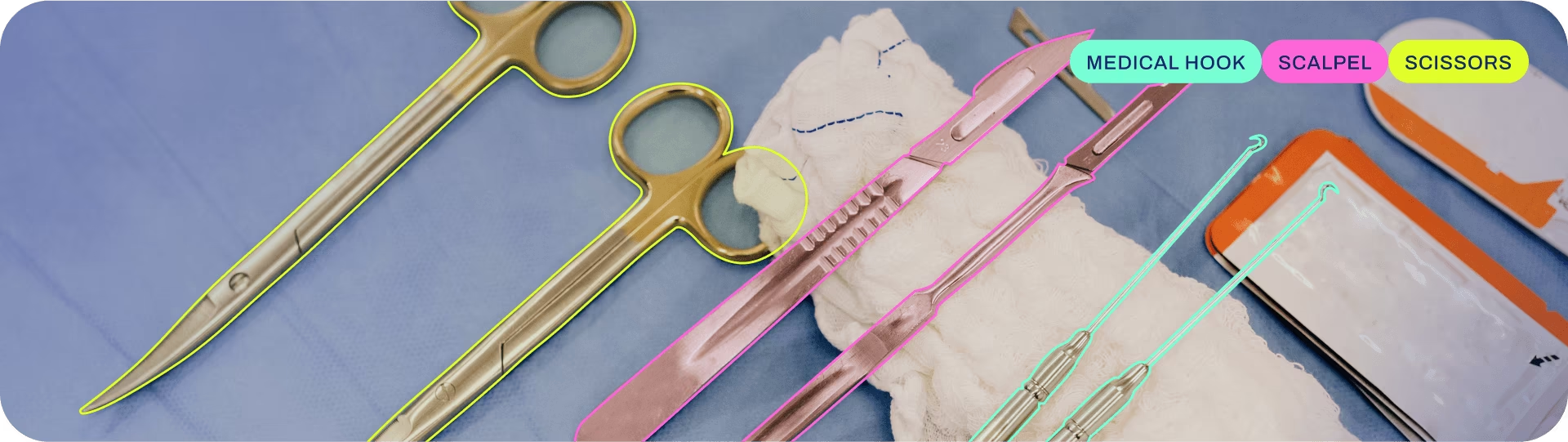
實例分割結合了目標檢測(在哪里,是什么)和語義分割(每個像素屬于什么)。它不僅需要識別出圖像中的每個物體并確定其邊界框,還要精確地勾勒出每個物體的像素級輪廓。這意味著同一類別的不同實例會被區分開來。
實例分割模型的輸出是一組掩碼或輪廓,它們勾勒出圖像中每個對象,以及每個對象的類別標簽和置信度分數。 當您不僅需要知道對象在圖像中的位置,還需要知道它們的精確形狀時,實例分割非常有用。
2.5.1Results對象中的,masks屬性
在YOLO-seg等模型中(后綴帶seg),執行實例分割預測后,會返回一個Results對象,其中包含的masks屬性就是關鍵。它包含了模型分割出的所有實例的掩碼信息。
Masks對象通常包含以下重要屬性:
| 屬性名 | 數據類型 | 描述 |
|---|---|---|
data | torch.Tensor | 最核心的屬性,存儲了所有實例的掩碼張量,形狀通常為?(n, H, W),其中?n?是實例數量,H和W是掩碼的高度和寬度。 |
xy | List[ndarray] | 一個列表,每個元素是一個ndarray,表示一個實例掩碼的輪廓坐標點(相對于圖像原圖)。 |
xyn | List[ndarray] | 類似xy,但坐標是經過歸一化(Normalized)的,值在0到1之間。 |
-
data?(Tensor):
這是最核心的掩碼數據。它是一個三維張量,形狀通常為?(n, H, W),其中:n?是檢測到的實例數量。H?和?W?是掩碼的高度和寬度(通常是原圖經過模型處理后的輸出尺寸,如160x160,而非原圖尺寸)。這個張量中的每個值通常在0到1之間,表示該像素屬于該實例的概率。通過設置一個閾值(如0.5),可以將其轉換為二值掩碼。 -
xy?(List[ndarray]):
這是一個列表,列表中的每個元素是一個NumPy數組(ndarray),表示一個實例掩碼的輪廓坐標點。這些坐標是相對于原始圖像尺寸的絕對坐標,格式通常是[[x1, y1], [x2, y2], ..., [xn, yn]]。這非常有用,例如可以直接用cv2.polylines在原圖上繪制輪廓。 -
xyn?(List[ndarray]):
與xy類似,但坐標是歸一化(Normalized)?的,值在0到1之間。適合某些需要相對坐標的計算場景。
2.5.2 Masks 的工作原理
YOLO的實例分割模型(如YOLACT/YOLOv5/8-seg)其核心思想是將復雜的實例分割任務分解為兩個并行的子任務:
-
生成原型掩碼 (Prototype Masks):一個全卷積網絡(FCN)分支(稱為Protonet)接收主干網絡的特征,輸出一組k個圖像大小的“原型掩碼”(prototype masks)。這些原型掩碼是類別無關的,它們負責編碼圖像中各種可能的形狀、邊緣和紋理等基礎特征。
-
預測掩碼系數 (Mask Coefficients):在目標檢測分支(預測邊界框和類別)上,額外為每個檢測到的錨點(anchor)預測一個k維的“掩碼系數”向量。這個向量定義了如何將那些原型掩碼線性組合起來,以形成當前實例獨有的掩碼1。
最終實例掩碼的生成,就是通過將原型掩碼與該實例對應的掩碼系數進行線性組合(通常是矩陣乘法)。
2.5.3 實例分割示例
????????下面這段代碼還用到了python的os庫(一些文件目錄操作),opencv庫(一些文件操作),numpy庫(是 Python 中用于科學計算和數值分析的核心庫,也是整個 Python 數據科學、機器學習、工程計算生態的基礎。它的主要作用是提供高性能的多維數組對象和一系列用于數組操作的工具,解決了 Python 原生數據結構(如列表)在數值計算中的效率問題。)要完全理解還需要一點語法知識。
from ultralytics import YOLO
import cv2
import numpy as np
import os # 添加os模塊用于創建目錄# 創建result目錄(如果不存在)
os.makedirs('result', exist_ok=True)model = YOLO('yolo11n-seg.pt') # 注意模型后綴-seg# 對圖像進行預測
results = model('origin/testmasks.jpg',classes = [0]) # 圖片路徑
result = results[0] # 獲取圖片結果# 檢查是否檢測到任何實例
if result.masks is not None:# 獲取Masks對象masks = result.masks# 方法1: 獲取所有掩碼的張量數據 (n, H, W)masks_data = masks.data # torch.Tensorprint(f"檢測到 {len(masks_data)} 個實例")print(f"掩碼張量形狀: {masks_data.shape}")# 方法2: 獲取每個實例的輪廓坐標(絕對坐標)masks_xy = masks.xyprint(f"第一個實例的輪廓坐標點:\n {masks_xy[0]}")# 方法3: 獲取每個實例的輪廓坐標(歸一化坐標)masks_xyn = masks.xynprint(f"第一個實例的歸一化輪廓坐標點:\n {masks_xyn[0]}")# 讀取原始圖像img = cv2.imread('origin/testmasks.jpg')img_copy = img.copy()# 為不同的實例隨機生成顏色colors = [tuple(np.random.randint(0, 255, 3).tolist()) for _ in range(len(masks_data))]# 方法1: 使用輪廓坐標在原圖上繪制輪廓for i, mask_points in enumerate(masks.xy):# 將點轉換為整數類型points = np.array(mask_points, dtype=np.int32)# 繪制多邊形輪廓cv2.polylines(img_copy, [points], isClosed=True, color=colors[i], thickness=2)# (設置透明度)overlay = img.copy()cv2.fillPoly(overlay, [points], color=colors[i])alpha = 0.3 # 透明度img_copy = cv2.addWeighted(overlay, alpha, img_copy, 1 - alpha, 0)# 保存繪制輪廓的圖像到result目錄cv2.imwrite('result/contours_filled.jpg', img_copy)# 顯示結果cv2.imshow('Mask Visualization', img_copy)cv2.waitKey(0)cv2.destroyAllWindows()# 方法2: 直接使用掩碼數據(需要調整到原圖大小)if masks_data is not None:# 獲取原圖尺寸orig_h, orig_w = img.shape[:2]# 獲取模型輸出掩碼的尺寸mask_h, mask_w = masks_data.shape[1:]for i, mask_tensor in enumerate(masks_data):# 將掩碼張量轉換為NumPy數組,并調整到原圖大小mask_resized = cv2.resize(mask_tensor.cpu().numpy(), (orig_w, orig_h))# 二值化處理_, binary_mask = cv2.threshold(mask_resized, 0.5, 255, cv2.THRESH_BINARY)binary_mask = binary_mask.astype(np.uint8)# 在原圖上應用掩碼masked_region = cv2.bitwise_and(img, img, mask=binary_mask)# 保存每個實例的掩碼區域到result目錄cv2.imwrite(f'result/instance_{i}_mask.jpg', masked_region)# 顯示每個實例的掩碼區域(這里只是示例,實際可能需要組合顯示)cv2.imshow(f'Instance {i} Mask', masked_region)cv2.waitKey(0)cv2.destroyAllWindows()# 創建一個黑色背景,用于放置摳出的實例for i, mask_tensor in enumerate(masks_data):# 調整掩碼大小至原圖尺寸orig_h, orig_w = img.shape[:2]mask_resized = cv2.resize(mask_tensor.cpu().numpy(), (orig_w, orig_h))# 創建二值掩碼_, binary_mask = cv2.threshold(mask_resized, 0.5, 255, cv2.THRESH_BINARY)binary_mask = binary_mask.astype(np.uint8)# 使用二值掩碼從原圖中摳出實例segmented_obj = cv2.bitwise_and(img, img, mask=binary_mask)# (可選) 將背景設置為黑色以外的顏色,例如白色white_bg = np.full_like(img, 255)segmented_obj_white_bg = cv2.bitwise_or(white_bg, white_bg, mask=cv2.bitwise_not(binary_mask))segmented_obj_white_bg = cv2.bitwise_or(segmented_obj, segmented_obj_white_bg)# 保存摳出的實例到result目錄cv2.imwrite(f'result/instance_{i}.png', segmented_obj_white_bg)print(f"實例 {i} 已保存為 result/instance_{i}.png")
else:print("未檢測到任何實例。")實驗結果我這里因為篇幅問題也只放出結果圖,其實圖中的滑板也是可以作為檢測目標的大家可以試一試。

最后講一講我對于掩碼這個專業術語的理解,把掩碼比作一個由0,1組成的二維矩陣,我們認為為1的像素點組成的一片區域就是我們要檢測的目標。把這一片“1”的區域提取出來就是每個目標的實例掩碼。

2.6 yolo的姿態估計

姿勢估計是一項涉及識別圖像中特定點的位置的任務,這些點通常稱為關鍵點。關鍵點可以代表對象的各個部分,例如關節、地標或其他獨特特征。關鍵點的位置通常表示為一組 2D?[x, y]?或 3D?[x, y, visible]?坐標。
姿勢估計模型的輸出是一組點,這些點代表圖像中對象上的關鍵點,通常還包括每個點的置信度分數。當您需要識別場景中對象的特定部分及其彼此之間的位置時,姿勢估計是一個不錯的選擇。
2.6.1 Results對象的Keypoint屬性
在YOLO-pose等模型中(后綴帶pose),執行實例姿態估計預測后,會返回一個Results對象,其中包含的keypoints屬性就是關鍵。它包含了模型分割出的所有實例的掩碼信息。
Keypoints 對象的構成:
YOLO 中每個 Keypoint(單個關鍵點)通常由 3 個核心參數組成,而一個目標的 Keypoints 則是這些單個關鍵點的集合:
1. 坐標(x, y)
表示關鍵點在圖像中的位置,通常為歸一化坐標(即相對于圖像寬高的比例,范圍 [0,1]),也可轉換為像素坐標(x = x_norm × 圖像寬度,y = y_norm × 圖像高度)。
例如:(0.5, 0.3) 表示關鍵點位于圖像水平中線、垂直方向 30% 的位置。
2. 置信度(confidence)
表示模型對該關鍵點 "存在性" 的信任程度(范圍 [0,1])。
置信度越高,說明模型認為該位置確實存在一個關鍵點;若低于閾值(如 0.5),通常會被過濾掉。
3. 可見性(visibility,可選)
部分版本中會包含該參數,用于標識關鍵點是否被遮擋:
0:完全不可見(被遮擋);
1:部分可見;
2:完全可見。
2.6.2?Keypoints 的數據集與標注規范
在官方的文檔中我們可以找到這樣一段重要內容!
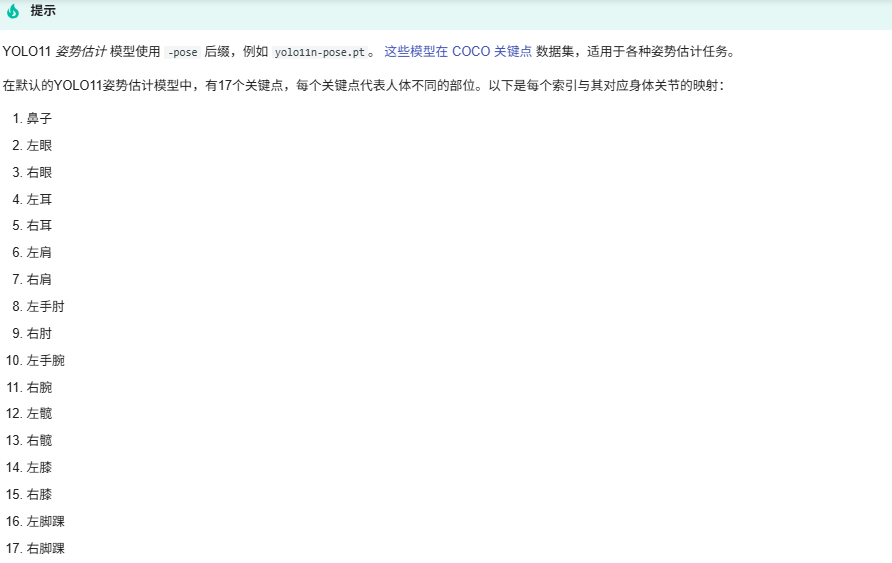
簡單解釋就是
Keypoints 的定義依賴于數據集的標注規范,不同數據集對關鍵點的數量和含義有不同約定:COCO(Common Objects in Context):
人體姿態:17 個關鍵點(如 0 - 鼻子、1 - 左眼、2 - 右眼、3 - 左耳、4 - 右耳、5 - 左肩、6 - 右肩等);標注格式:每個目標對應一個長度為 3×N 的數組(N 為關鍵點數量),依次存儲 (x1, y1, c1, x2, y2, c2, ..., xN, yN, cN),其中 c 為置信度 / 可見性。
MPII Human Pose:人體姿態:16 個關鍵點(側重四肢細節,如腳踝、膝蓋、髖關節等)。
自定義數據集:可根據任務需求定義關鍵點(如手勢估計中的 5 個手指端點)。
2.6.3 姿態檢測示例
import cv2
from ultralytics import YOLO# 實例化模型
model = YOLO('yolo11n-pose.pt') # 注意模型后綴-pose
# 實例化對象
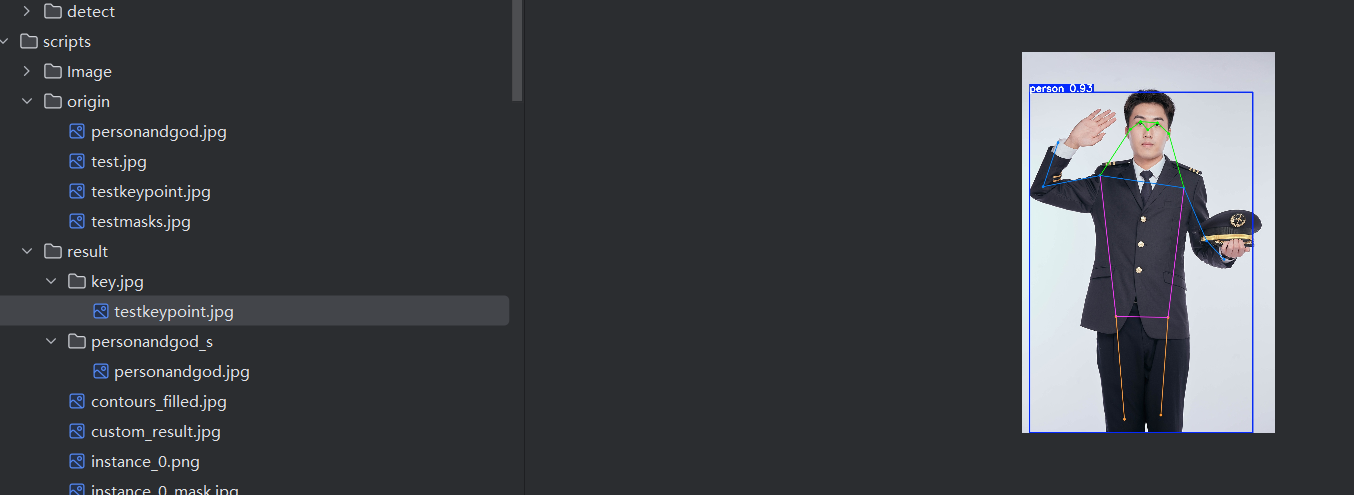
results = model('origin/testkeypoint.jpg',show = True,save = True,project = 'result',name = 'key.jpg') # 圖片路徑# 獲取結果
result = results[0] # 因為這里只推理了一張圖片,所以取第一個結果# 獲取原圖尺寸,用于將歸一化坐標轉換回像素坐標
img_height, img_width = result.orig_shape# 可視化結果(可選,Ultralytics 自帶繪圖功能,但這里我們手動繪制以理解過程)
# result.show() # 最簡單的方法,直接顯示帶注釋的圖片# 手動處理 Keypoints 數據
# 復制一份原圖用于繪制
annotated_img = result.orig_img.copy()# 定義關鍵點名稱(COCO數據集的關鍵點順序)
keypoint_names = ["nose", "left_eye", "right_eye", "left_ear", "right_ear","left_shoulder", "right_shoulder", "left_elbow", "right_elbow","left_wrist", "right_wrist", "left_hip", "right_hip","left_knee", "right_knee", "left_ankle", "right_ankle"
]# 遍歷每一個被檢測到的人
for person_idx, person in enumerate(result):# 獲取該人的所有關鍵點數據 (Tensor形狀為 [17, 3])keypoints = person.keypoints.data[0] # 取出當前人的關鍵點數據# 遍歷每一個關鍵點 (共17個)for i, (x, y, conf) in enumerate(keypoints):# 將歸一化坐標轉換為像素坐標x_pixel = int(x * img_width)y_pixel = int(y * img_height)# 如果關鍵點置信度高于閾值,則繪制它if conf > 0.3: # 置信度閾值,可調整color = (0, 255, 0) # 綠色點cv2.circle(annotated_img, (x_pixel, y_pixel), 5, color, -1) # 畫實心圓# 可選:添加關鍵點索引標簽cv2.putText(annotated_img, str(i), (x_pixel+5, y_pixel), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 1)# 繪制骨骼連接線# 定義需要連接的骨骼對 (使用上面提到的關鍵點索引)skeleton = [(5, 6), (5, 7), (7, 9), (6, 8), (8, 10), # 手臂和肩膀(5, 11), (6, 12), (11, 12), # 身體軀干(11, 13), (13, 15), (12, 14), (14, 16) # 腿和臀部]for start_idx, end_idx in skeleton:# 獲取起始點和結束點的坐標和置信度start_kpt = keypoints[start_idx]end_kpt = keypoints[end_idx]# 提取坐標和置信度x1, y1, conf1 = start_kptx2, y2, conf2 = end_kpt# 轉換為像素坐標x1_pix = int(x1 * img_width)y1_pix = int(y1 * img_height)x2_pix = int(x2 * img_width)y2_pix = int(y2 * img_height)# 如果兩個點的置信度都足夠高,才繪制這條骨骼線if conf1 > 0.3 and conf2 > 0.3:cv2.line(annotated_img, (x1_pix, y1_pix), (x2_pix, y2_pix), (255, 0, 0), 2) # 藍色線,粗細為2# 顯示手動繪制后的圖像
cv2.imwrite('result/keypoint.jpg', annotated_img) # 保存識別后的圖片
cv2.waitKey(0) # 按任意鍵關閉窗口
cv2.destroyAllWindows()# 打印詳細的數值信息
print(f"檢測到 {len(result)} 個人")
for i, person in enumerate(result):print(f"\n--- 第 {i+1} 個人 ---")print(f"邊界框置信度: {person.boxes.conf.item():.2f}")keypoints = person.keypoints.data[0]for j, (x, y, conf) in enumerate(keypoints):# 使用預定義的關鍵點名稱而不是模型名稱print(f"關鍵點 {j} ({keypoint_names[j]}): X={x:.2f}, Y={y:.2f}, Conf={conf:.2f}")這段代碼注釋已經比較詳細,最后直接展示識別效果。
結語
最后到這里也就結束了,相信你看完一定驚嘆于yolo的強大了,還有旋轉角檢測沒有去做了。
如果有需要代碼資源或者軟件資源的可以直接找我。。

)



文件語法詳解)





)







