文章目錄
- 1.網絡
- 1.1 瀏覽器從輸入網址到展示頁面,描述下整個過程?
- 1.2 HTTP 502,503 和 504 是什么含義?區別以及如何排查?
- 1.3 HTTPS 通信過程為什么要約定加密密鑰 code,用非對稱加密不行嗎?
- 1.4 既然 HTTPS 通信是加密的,為什么抓包工具如 Fiddler 可以看到明文?
- 1.5 TCP 3 次握手的過程? 2 次或者 4 次行不行?
- 1.6 TCP 四次揮手的過程?
- 1.7 TCP 3 次揮手可以嗎?
- 1.8 為什么需要延遲確認?
- 1.9 服務端可以主動發起斷開連接嗎?
- 1.10 客戶端回復服務端斷開請求 ACK 報文后會進入什么狀態?
- 1.11 大量 TCP 連接狀態處于 TIME_WAIT 狀態會有什么問題?
- 2.數據庫
- 2.1 事務的四大特性是什么?
- 2.2 MySQL 是如何實現 MVCC 的?
- 2.3 MVCC 的 undo 日志是什么時候清理的?
- 2.4 MySQL 索引數據結構是什么?
- 2.5 MySQL 為什么用 B+ 樹,不用 B 樹?
- 2.6 什么情況下會導致索引失效?
- 2.7 手寫 SQL: 給定用戶表 user 和帖子表 post,獲取帖子數前十的用戶名?
- 3.Golang
- 3.1 Golang 的 GC 是怎么實現的?
- 3.2 為什么是三色標記,兩色不行嗎?
- 4.問題定位
- 4.1 如何定位服務器 CPU 占用率過高的問題?
- 5.設計題
- 5.1 如何限制用戶 1 分鐘只發送 5 個帖子?
- 5.2 使用計數器會有什么問題?有更好的辦法嗎?
- 6.編程題
- 6.1 找出 Top2 的數
- 6.2 找出比左邊大比右邊小的數
1.網絡
1.1 瀏覽器從輸入網址到展示頁面,描述下整個過程?
- URL 解析
輸入處理:瀏覽器解析你輸入的URL(如 https://www.example.com),判斷是搜索關鍵詞還是合法URL。
協議補充:若未指定協議(如http://或https://),瀏覽器會默認補全(通常為https)。
端口處理:若未指定端口,使用默認端口(HTTP為80,HTTPS為443)。
- DNS 查詢(域名解析)
- 檢查緩存:
瀏覽器緩存 → 系統緩存(如hosts文件) → 路由器緩存 → ISP的DNS緩存。
- 遞歸查詢(若緩存未命中):
瀏覽器向本地DNS服務器發起請求,依次查詢:
根域名服務器(.) → 頂級域名服務器(.com) → 權威域名服務器(example.com)。
最終獲取目標服務器的IP地址。
- 建立 TCP 連接
- 三次握手(針對HTTPS):
客戶端發送SYN包到服務器。
服務器回復SYN-ACK包。
客戶端發送ACK包,連接建立。
- TLS握手(HTTPS):
協商加密算法,交換密鑰,驗證證書(如CA機構簽發)。
- 發送 HTTP 請求
瀏覽器構造HTTP請求報文,例如:
http
GET / HTTP/1.1
Host: www.example.com
Connection: keep-alive
User-Agent: Chrome/...
附加請求頭(如Cookie、Accept-Encoding等)。
- 服務器處理請求
Web服務器(如Nginx/Apache)接收請求,可能轉發給應用服務器(如Node.js、Tomcat)。
后端處理:執行業務邏輯(數據庫查詢、API調用等),生成響應(HTML/JSON等)。
- 接收 HTTP 響應
- 服務器返回響應報文,例如:
HTTP/1.1 200 OK
Content-Type: text/html
Content-Length: 1234<!DOCTYPE html><html>...</html>
- 狀態碼(如200成功、404未找到)和響應頭(如Cache-Control、Set-Cookie)。
- 渲染頁面
解析HTML:瀏覽器構建DOM樹。
加載子資源:解析到,
構建CSSOM:解析CSS樣式。
執行JavaScript:可能阻塞渲染(除非標記async/defer)。
布局(Layout):計算元素位置和大小。
繪制(Paint):將像素輸出到屏幕。
- 連接終止
四次揮手(若為短連接):
- 客戶端發送FIN包。
- 服務器確認ACK。
- 服務器發送FIN包。
- 客戶端確認ACK,連接關閉。
關鍵優化點:
DNS預取:提前解析域名。
TCP復用:HTTP/1.1的keep-alive或HTTP/2多路復用。
CDN加速:靜態資源分發到邊緣節點。
緩存策略:Cache-Control、ETag減少重復請求。
1.2 HTTP 502,503 和 504 是什么含義?區別以及如何排查?
| 狀態碼 | 名稱 | 原因 |
|---|---|---|
| 500 | Internal Server Error | 服務器內部錯誤(如代碼異常、數據庫連接失敗)。 |
| 501 | Not Implemented | 服務器不支持請求的功能(如未實現的HTTP方法)。 |
| 502 | Bad Gateway | 網關或代理服務器從上游服務器收到了無效或無法解析的響應(如連接拒絕、響應中斷)。 |
| 503 | Service Unavailable | 服務不可用(如服務器過載、維護中)。 |
| 504 | Gateway Timeout | 網關或代理服務器等待上游服務器響應超時。 |
| 505 | HTTP Version Not Supported | 服務器不支持請求的HTTP協議版本(如客戶端使用HTTP/3但服務器僅支持HTTP/1.1)。 |
- 502(Bad Gateway)
問題出在代理與后端通信,但后端可能仍在運行,只是返回了錯誤數據。
典型場景:
后端服務崩潰(如PHP-FPM進程掛掉)。
代理配置錯誤(如Nginx的proxy_pass指向了錯誤的端口)。
后端返回了不完整的HTTP響應(如未發送完數據就斷開連接)。
排查方法:
檢查后端服務是否運行(systemctl status nginx)。
查看代理服務器日志(如Nginx的error.log)。
測試后端服務是否能直接訪問(curl http://backend-server:port)。
- 503(Service Unavailable)
后端主動告知不可用,通常用于臨時維護或過載保護。
典型場景:
服務器維護(如人工停機升級)。
流量激增觸發限流(如Cloudflare的Under Attack模式)。
自動擴縮容期間服務短暫不可用(如Kubernetes滾動更新)。
排查方法:
檢查是否有維護公告或運維操作。
查看后端服務的負載情況(top、htop)。
如果是云服務,檢查自動擴縮容策略(如AWS Auto Scaling)。
- 504(Gateway Timeout)
代理服務器等待后端響應超時,但后端可能仍在處理請求(只是太慢)。
典型場景:
后端處理時間過長(如復雜SQL查詢、大數據導出)。
網絡延遲或丟包(如跨國請求、服務器間網絡問題)。
代理服務器超時設置過短(如Nginx proxy_read_timeout 默認60秒)。
排查方法:
增加代理超時時間(Nginx調整proxy_read_timeout)。
優化后端性能(如數據庫索引優化、緩存加速)。
檢查網絡鏈路(ping、traceroute)。
1.3 HTTPS 通信過程為什么要約定加密密鑰 code,用非對稱加密不行嗎?
- 為什么需要約定密鑰?
HTTPS 使用 對稱加密(如AES) 傳輸數據,因為對稱加密的計算速度快,適合加密大量數據。
但對稱加密需要雙方持有相同的密鑰,因此必須通過安全的方式協商密鑰,這就是 密鑰交換(Key Exchange) 的作用。
- 為什么不能只用非對稱加密?
非對稱加密(如RSA、ECC)雖然可以加密數據,但存在以下問題:
(1) 性能問題
非對稱加密計算復雜度高,比對稱加密(如AES)慢 100-1000倍。
如果全程用非對稱加密,服務器和客戶端的CPU負載會極高,影響用戶體驗。
(2) 安全性問題
長期使用同一密鑰風險高:如果服務器長期使用同一個RSA私鑰加密數據,一旦私鑰泄露,所有歷史通信都可能被解密(不具備 前向安全性)。
密鑰管理復雜:非對稱加密的密鑰對需要嚴格保護,而對稱加密的會話密鑰可以定期更換。
- 密鑰交換的演進
(1) RSA 密鑰交換(舊方式)
客戶端生成對稱密鑰,用服務器的RSA公鑰加密后發送。
問題:不具備前向安全性(如果服務器私鑰泄露,歷史通信可被解密)。
(2) ECDHE(現代方式,推薦)
基于橢圓曲線迪菲-赫爾曼(ECDHE),雙方臨時生成密鑰對,通過數學計算得到共享密鑰。
優點:
每次會話密鑰不同(前向安全)。
即使私鑰泄露,歷史會話也無法解密。
結論:
HTTPS 采用 非對稱加密協商密鑰 + 對稱加密傳輸數據,既保證了安全性,又提升了性能。單純使用非對稱加密無法滿足實際需求。
1.4 既然 HTTPS 通信是加密的,為什么抓包工具如 Fiddler 可以看到明文?
HTTPS 通信本身是加密的,但抓包工具(如 Fiddler、Charles、Wireshark)能夠看到明文數據,是因為它們使用了 中間人攻擊(Man-in-the-Middle, MITM) 的方式,在客戶端和服務器之間充當了一個“代理”,從而解密 HTTPS 流量。以下是詳細解釋:
- HTTPS 加密的基本原理
HTTPS 使用 TLS/SSL 加密通信,確保數據在傳輸過程中不被竊聽或篡改。正常情況下:
客戶端 和 服務器 協商一個 對稱加密密鑰(如 AES),后續通信使用該密鑰加密。
中間人(如黑客) 無法直接解密數據,因為不知道密鑰。
- 為什么 Fiddler 能解密 HTTPS?
Fiddler 本質上是一個 HTTPS 代理,它通過以下方式解密流量:
(1) 安裝自定義根證書(CA 證書)
Fiddler 會在你的電腦上安裝一個 自簽名的根證書(CA 證書),并讓操作系統信任它。
這樣,Fiddler 可以 冒充目標網站,偽造 HTTPS 證書。
(2) 攔截 HTTPS 請求并重新加密
客戶端(瀏覽器) 發起 HTTPS 請求時,Fiddler 會攔截它,并 假裝自己是目標服務器。
Fiddler 用自己的 CA 證書 動態生成一個假的 HTTPS 證書 返回給客戶端。
客戶端信任 Fiddler 的 CA 證書,因此接受這個假證書,并和 Fiddler 建立加密連接。
Fiddler 再用真正的證書和服務器建立另一個 HTTPS 連接,解密客戶端的數據后,再加密轉發給服務器。
(3) 解密并顯示明文
Fiddler 同時知道 客戶端 ? Fiddler 和 Fiddler ? 服務器 的加密密鑰,因此可以解密所有流量,并顯示明文數據。
結論:
Fiddler 能解密 HTTPS 是因為你主動信任了它的 CA 證書,讓它成為“受信任的中間人”。
真正的 HTTPS 通信(如瀏覽器訪問銀行網站)仍然是安全的,因為外部攻擊者無法偽造證書。
如果你不想被監控,不要隨意安裝未知的 CA 證書。
1.5 TCP 3 次握手的過程? 2 次或者 4 次行不行?
- 3 次握手的過程?
TCP 使用 三次握手 建立可靠連接,確保雙方都能正常收發數據。過程如下:
- SYN(同步)
客戶端 → 服務器:發送 SYN=1, seq=x(隨機序號)。
含義:“我想建立連接,我的初始序號是 x。”
- SYN-ACK(同步確認)
服務器 → 客戶端:發送 SYN=1, ACK=1, seq=y, ack=x+1。
含義:“我同意連接,我的初始序號是 y,你的 x+1 我收到了。”
- ACK(確認)
客戶端 → 服務器:發送 ACK=1, seq=x+1, ack=y+1。
含義:“確認收到你的 y,我們可以通信了。”
握手完成后,連接建立,開始傳輸數據。
注意:第三次握手是可以攜帶數據的,前兩次握手不可以攜帶數據。
- 為什么不能是 2 次握手?
如果只有兩次握手(SYN → SYN-ACK),會引發歷史連接問題:
問題場景:
客戶端發送的 SYN 因網絡延遲,超時重傳了一個新 SYN。
如果服務器收到舊 SYN 后直接建立連接,但客戶端早已放棄,導致服務器一直等待無用連接。
三次握手解決:
客戶端通過第三次 ACK 確認自己真正需要連接,避免資源浪費。
- 為什么不能是 4 次握手?
四次握手其實也能夠可靠的同步雙方的初始化序號,但由于第二步和第三步可以優化成一步,所以就成了「三次握手」。
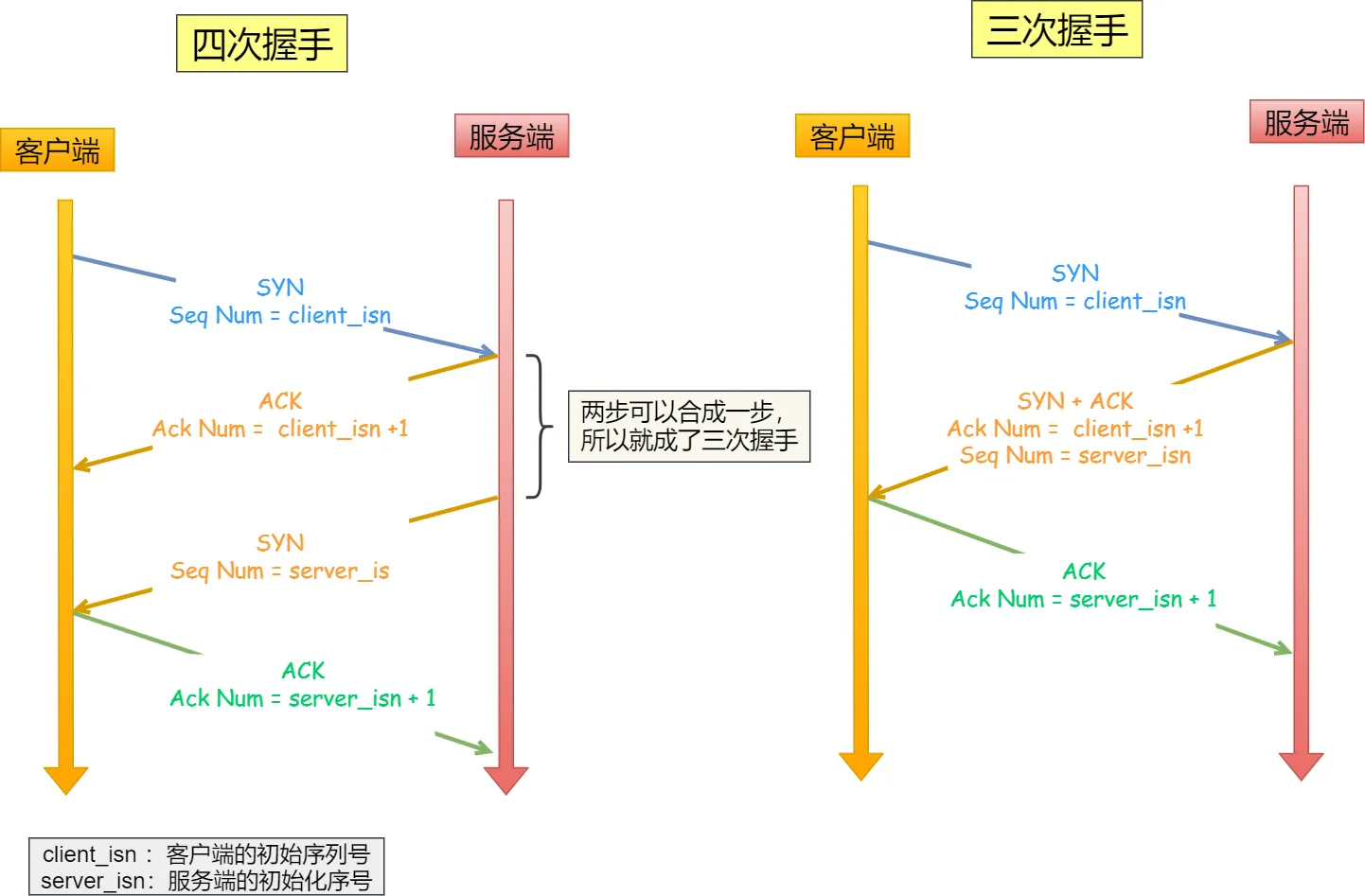
參見 4.1 TCP 三次握手與四次揮手面試題。
1.6 TCP 四次揮手的過程?
TCP 使用四次揮手安全關閉連接,確保雙方數據完整傳輸并釋放資源。以下是詳細流程(假設客戶端主動關閉):
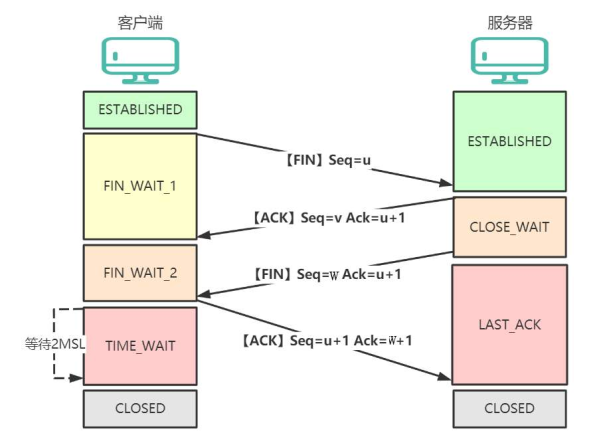
第一次揮手:客戶端主動調用關閉連接的函數,發送 FIN 報文,客戶端進入 FIN_WAIT_1 狀態。
第二次揮手:服務端收到了 FIN 報文,然后馬上回復一個 ACK 報文,服務端進入 CLOSE_WAIT 狀態。
第三次揮手:服務端應用程序發送完數據后,調用關閉連接的函數發一個 FIN 報文,服務端進入 LAST_ACK 狀態。
第四次揮手:客戶端接收到服務端的 FIN 包,并發送 ACK 確認報文給服務端,此時客戶端將進入 TIME_WAIT 狀態。
服務端收到 ACK 確認報文后,就進入了最后的 CLOSED 狀態。
客戶端經過 2MSL 時間之后,也進入 CLOSED 狀態。
1.7 TCP 3 次揮手可以嗎?
可以。
四次揮手把同意對方請求跟自身請求分離開。是因為在客戶端請求斷開時(客戶端發送端->服務器接收端),服務器可能還有數據未發完,所以需要分開操作。
如果服務器端收到客戶端的FIN后,服務器并沒有數據需要發送,可以把ACK和FIN合并到一起發送,節省了一個報文,變成了“三次揮手”。
當被動關閉方(上圖的服務端)在 TCP 揮手過程中,「沒有數據要發送」并且「開啟了 TCP 延遲確認機制」,那么第二和第三次揮手就會合并傳輸,這樣就出現了三次揮手。
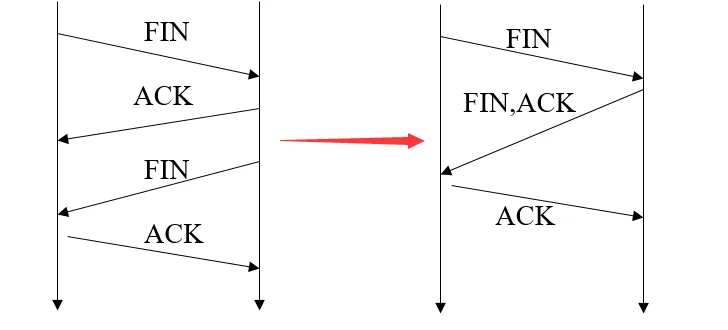
注意:然后因為 TCP 延遲確認機制是默認開啟的,所以導致我們抓包時,看見三次揮手的次數比四次揮手還多。
4.22 TCP 四次揮手,可以變成三次嗎? - 小林coding
1.8 為什么需要延遲確認?
- 基本概念
TCP 延遲確認(Delayed ACK)是一種優化技術,通過推遲發送確認報文(ACK),減少網絡中小數據包的數量,從而提高傳輸效率。其核心邏輯是:
不立即回復 ACK,而是等待一段時間(通常 200ms),看是否有數據需要捎帶(Piggybacking)一起發送。
如果在等待期間有數據要發送,則 ACK 會附帶在數據包中,避免單獨發送 ACK 報文。
- 減少小包問題
每個 ACK 報文至少占用 40 字節(IPv4 + TCP 頭),單獨發送 ACK 會導致網絡充斥小包,降低效率。
利用捎帶確認:
如果接收方有數據要回復(如 HTTP 響應),可以將 ACK 和數據合并發送,節省帶寬。
適應交互式應用:
如 SSH、數據庫查詢等場景,請求和響應成對出現,延遲 ACK 能自然合并報文。
- 延遲確認的工作機制
- 默認延遲時間:通常為 200ms(Linux 默認值,Windows 可能為 100ms)。
- 觸發條件:
- 每接收 2 個數據包 必須發送一個 ACK(RFC 1122 規定)。
- 如果延遲期間有數據要發送,則 ACK 捎帶在數據包中。
- 超時(如 200ms)后仍未發送數據,則單獨發送 ACK。
示例場景:
- 客戶端發送數據包 Seq=100。
- 服務器收到后不立即回復 ACK,而是等待:
- 若 200ms 內服務器需發送數據(如 Seq=200),則合并為 ACK=101 + Seq=200。
- 若超時,則單獨發送 ACK=101。
- 延遲確認與 Nagle 算法的關系
- Nagle 算法:發送端的優化,緩沖小數據包,等待 ACK 或足夠數據再發送。
- 交互問題:
若發送端啟用 Nagle,接收端啟用延遲 ACK,可能導致 死鎖:
○ 發送方等 ACK 才發下一包,接收方等數據才捎帶 ACK。
○ 解決方案:禁用其中之一(如 HTTP 服務通常禁用 Nagle)。
- 總結
● 延遲確認是 TCP 的性能優化,通過合并 ACK 減少小包,但可能增加延遲。
● 默認延遲 200ms,每 2 個數據包必須確認一次。
● 實時場景需謹慎:可禁用延遲確認或調整超時時間。
● 與 Nagle 算法可能沖突,需根據業務場景權衡配置。
關鍵點:延遲確認體現了 TCP 在可靠性和效率之間的平衡,理解其機制有助于優化高并發或低延遲網絡服務。
1.9 服務端可以主動發起斷開連接嗎?
可以。
“TCP 連接是雙向的,服務端和客戶端都能主動發 FIN 斷開。只不過在 HTTP 等協議中,客戶端通常先發起關閉,但服務端在長連接超時或維護時也會主動斷開。”
關鍵點:TCP 設計上沒有主從之分,誰先調 close() 誰先發 FIN。
1.10 客戶端回復服務端斷開請求 ACK 報文后會進入什么狀態?
當客戶端收到服務端的 FIN 并回復 ACK 后,會進入 TIME_WAIT 狀態(等待 2MSL 時間后才徹底關閉)。
為什么需要 TIME_WAIT?
這么做有兩個原因:
- 確保最后一個 ACK 可靠到達(防止連接異常終止)
問題:如果主動關閉方(客戶端)發送的最終 ACK 丟失,被動關閉方(服務端)會因未收到確認而重傳 FIN。
作用:TIME_WAIT 期間,客戶端保留連接狀態,可以重新接收并響應服務端重傳的 FIN(再次發送 ACK),避免服務端一直卡在 LAST_ACK 狀態,導致資源無法釋放。
- 丟棄舊連接延遲報文
讓舊連接報文從網絡中消失,避免被后面相同四元組的新連接錯誤地接收收到舊連接的報文。
如果不等 2MSL,釋放的端口可能會重新與服務器建立連接,這樣依然存活在網絡里的舊連接 TCP 報文可能與新連接報文沖突,造成數據混亂。
為什么 TIME_WAIT 是 2MSL?
-
TCP 是全雙工協議:需要確保雙向(客戶端→服務端 + 服務端→客戶端)的報文均被清除。
-
1MSL 只能覆蓋單向:例如,服務端的 FIN 可能在第 1 個 MSL 內到達,但客戶端的 ACK 可能在第 2 個 MSL 內才徹底消失。
1.11 大量 TCP 連接狀態處于 TIME_WAIT 狀態會有什么問題?
如果客戶端(主動發起關閉連接)存在大量 TIME_WAIT 狀態連接,會占用端口資源,導致新建 TCP 連接出錯,報address already in use : connect異常。
如果服務端(主動發起關閉連接)存在大量 TIME_WAIT 狀態連接,并不會導致端口資源受限,因為服務端只監聽一個端口,而且由于一個四元組唯一確定一個 TCP 連接,因此理論上服務端可以建立很多連接。
但是 TCP 連接過多,會占用系統資源,比如文件描述符、內存資源、CPU 資源、線程資源等。
如何解決?
(1)調整內核參數(Linux)復用處于 TIME_WAIT 的 socket 為新的連接所用。
# 允許復用 TIME_WAIT 狀態的端口(需時間戳支持)
echo 1 > /proc/sys/net/ipv4/tcp_tw_reuse# 增大可用端口范圍
echo "1024 65535" > /proc/sys/net/ipv4/ip_local_port_range# 減少 TIME_WAIT 超時時間(不建議,可能影響可靠性)
echo 30 > /proc/sys/net/ipv4/tcp_fin_timeout # 單位:秒
(2)優化應用設計
- 使用長連接:
- HTTP/1.1 啟用 Keep-Alive
- 使用 HTTP/2 多路復用
- 數據庫連接使用連接池
- 連接復用:客戶端復用連接而不是頻繁創建新連接
2.數據庫
2.1 事務的四大特性是什么?
事務的四大特性是 ACID:
- 原子性(Atomicity):事務要么全成功,要么全失敗。
- 一致性(Consistency):數據符合完整性約束。
- 隔離性(Isolation):并發事務互不干擾。
- 持久性(Durability):提交后修改永久生效。
MySQL 如何實現 ACID?
- 原子性:Undo Log
- 持久性:Redo Log
- 隔離性:MVCC + 鎖機制
- 一致性
- 通過應用程序和數據庫約束(如主鍵、外鍵、唯一約束等)共同保證。
- 數據庫自身的完整性檢查機制。
- 原子性、隔離性和持久性的共同作用來保證一致性。
2.2 MySQL 是如何實現 MVCC 的?
MVCC (Multi-Version Concurrency Control,多版本并發控制) 是 MySQL 實現高并發的重要技術,主要被 InnoDB 存儲引擎使用。
核心組件:
-
隱藏字段:
- DB_TRX_ID:6字節,記錄最近修改該行記錄的事務ID
- DB_ROLL_PTR:7字節,指向該行記錄在回滾段(undo log)中的指針
- DB_ROW_ID:6字節,隱藏的自增ID(當表沒有主鍵時自動生成)
-
Undo Log:
- 存儲數據被修改前的多個版本
- 形成版本鏈,通過 DB_ROLL_PTR 指針可以找到歷史版本
-
ReadView:
- 快照讀時生成的一致性視圖
- 包含:m_ids(活躍事務ID列表)、min_trx_id(最小活躍事務ID)、max_trx_id(預分配的下一個事務ID)、creator_trx_id(創建該ReadView的事務ID)
工作流程:
-
SELECT 操作:
- 創建 ReadView
- 檢查行記錄的 DB_TRX_ID:
- 如果小于 min_trx_id:可見(事務已提交)
- 如果在 m_ids 中:不可見(事務未提交)
- 如果大于等于 max_trx_id:不可見(事務在ReadView之后開始)
- 通過 DB_ROLL_PTR 在 undo log 中查找可見的版本
-
INSERT/DELETE/UPDATE 操作:
- INSERT:新插入的行 DB_TRX_ID 為當前事務 ID。
- DELETE:在行記錄上設置刪除標記,DB_TRX_ID 為當前事務 ID。
- UPDATE:先標記原記錄為刪除,再插入新記錄。
隔離級別實現差異:
-
READ UNCOMMITTED:不適用MVCC,直接讀取最新記錄
-
READ COMMITTED:每次 SELECT 都生成新的 ReadView
-
REPEATABLE READ:第一次SELECT時生成ReadView,后續復用
-
SERIALIZABLE:退化為基于鎖的并發控制
優點:
- 讀操作不加鎖,讀寫不沖突
- 通過版本鏈實現非阻塞讀
- 提高了并發性能
MVCC 是 MySQL 實現高并發的重要技術,通過維護數據的多個版本,實現了讀操作不需要等待寫操作完成,大大提高了數據庫的并發性能。
2.3 MVCC 的 undo 日志是什么時候清理的?
Undo 日志是 MVCC 實現多版本控制的關鍵組件,它的清理時機直接影響數據庫性能和存儲空間利用率。以下是 Undo 日志清理的主要時機和規則:
核心清理時機:
- 事務提交時不會立即清理
- 即使事務已經提交,對應的 Undo 日志也不會立即刪除
- 因為可能還有其他事務需要通過這些 Undo 日志訪問舊版本數據
- 當沒有任何活躍事務需要該版本時
- 當系統中沒有比 Undo 日志關聯的事務更早的活躍事務時
- 通過 ReadView 的 m_ids 列表和 min_trx_id 判斷
具體清理規則:
-
通過 purge 線程異步清理
- InnoDB 有專門的 purge 線程負責清理不再需要的 Undo 日志
- 避免同步清理影響事務性能
-
基于系統活躍事務列表判斷
- 維護一個全局活躍事務列表
- 當某個 Undo 日志關聯的事務 ID 小于當前所有活躍事務的最小 ID 時,該 Undo 日志可被清理
-
長事務會阻止 Undo 清理
-如果有長時間運行的事務存在,它會阻止比它晚的事務的 Undo 日志被清理- 這是長事務導致數據庫存儲膨脹的主要原因
相關參數控制:
- innodb_purge_threads:控制 purge 線程數量
- innodb_max_purge_lag:當 purge 滯后時的最大延遲
- innodb_purge_batch_size:每次 purge 操作處理的數量
特殊情況處理:
-
回滾段重用
- 當 Undo 日志被清理后,對應的回滾段空間會被標記為可重用
- 但物理空間不會立即釋放給操作系統
-
系統表空間中的 Undo
- MySQL 8.0 之前,系統表空間中的 Undo 日志即使被清理,空間也不會收縮
- MySQL 8.0+ 支持獨立的 Undo 表空間,可以單獨收縮
最佳實踐:
- 避免長事務,減少 Undo 日志堆積
- 監控 history_list_length 指標,了解待清理的 Undo 日志數量
- 在 MySQL 8.0+ 中使用獨立的 Undo 表空間便于管理
Undo 日志的清理是 InnoDB 自動管理的,但理解其機制有助于優化數據庫性能和存儲使用。
2.4 MySQL 索引數據結構是什么?
MySQL 主要使用 B+樹 作為索引的基礎數據結構,但根據不同的存儲引擎和索引類型,也會使用其他數據結構。
B+樹索引(最核心的索引結構)
- 使用場景:InnoDB/MyISAM 的默認索引類型,適用于主鍵索引和二級索引
- 結構特點:
- 多叉平衡樹,所有數據都存儲在葉子節點
- 非葉子節點只存儲鍵值和子節點指針
- 葉子節點通過指針連接形成有序鏈表
- 優勢:
- 適合范圍查詢(>、<、BETWEEN)
- 查詢效率穩定(O(log n))
- 支持全鍵值、鍵值范圍和前綴查找
還有哪些數據結構可以作為索引?
- 哈希索引
- 使用場景:Memory 存儲引擎的默認索引,InnoDB 的自適應哈希索引
- 結構特點:
- 基于哈希表實現
- 精確匹配效率極高(O(1))
- 限制:
- 不支持范圍查詢
- 不支持排序
- 存在哈希沖突問題
- 全文索引(FULLTEXT)
- 使用場景:文本內容的搜索
- 實現方式:
- InnoDB 使用倒排索引
- MyISAM 也支持全文索引
- R-Tree(空間索引)
- 使用場景:地理空間數據(GIS)
- 支持函數:ST_Contains(), ST_Within() 等
2.5 MySQL 為什么用 B+ 樹,不用 B 樹?
核心差異對比:
| 特性 | B 樹 | B+ 樹 |
|---|---|---|
| 數據存儲位置 | 所有節點都可能存儲數據 | 只有葉子節點存儲完整數據 |
| 非葉子節點內容 | 存儲鍵值和數據指針 | 只存儲鍵值和子節點指針 |
| 葉子節點連接 | 不連接 | 通過指針連接成有序鏈表 |
| 查找穩定性 | 不穩定(可能在非葉子節點找到) | 穩定(必須查找到葉子節點) |
| 范圍查詢效率 | 較低 | 極高 |
選擇 B+ 樹的六大關鍵原因:
- 更優的磁盤 I/O 性能
-
B+ 樹的非葉子節點不存儲數據,所以每個節點可以容納更多的鍵值
-
相同數據量下,B+ 樹比 B 樹更"矮胖",通常只需要 3-4 層就能存儲大量數據
-
減少磁盤 I/O 次數(每次 I/O 讀取一個節點)
- 更高效的范圍查詢
-
葉子節點形成有序鏈表,范圍查詢只需找到起始點然后順序遍歷
-
B 樹做范圍查詢需要在不同層級的節點間來回跳轉,效率低下
-
例如查詢 WHERE id BETWEEN 100 AND 300,B+ 樹性能顯著優于 B 樹
- 更穩定的查詢性能
-
B+ 樹所有查詢都要走到葉子節點,時間復雜度穩定為 O(log n)
-
B 樹可能在中間節點就找到數據,導致查詢時間不穩定
- 更高的緩存命中率
B+ 樹的非葉子節點只存索引鍵,可以緩存更多非葉子節點在內存中
例如 16KB 的頁大小,B+ 樹能緩存更多索引鍵,減少磁盤訪問
- 更適合數據庫場景
數據局部性原理:B+ 樹將實際數據集中在葉子節點,相鄰數據物理上也更接近
全表掃描效率:B+ 樹只需遍歷葉子節點鏈表即可完成全表掃描,而 B 樹需要遍歷整棵樹
- 更低的維護成本
B+ 樹的插入和刪除操作更簡單,因為數據只在葉子節點修改
B 樹可能在任意節點修改數據,導致更復雜的樹結構調整
何時 B 樹更合適?
雖然 B+ 樹更適合數據庫索引,但 B 樹在某些場景仍有優勢:
- 內存數據庫(如 Redis):不需要考慮磁盤 I/O,B 樹的隨機訪問優勢更明顯
- 鍵值存儲系統:如果只做單點查詢,B 樹的平均查找路徑可能更短
MySQL 的選擇體現了工程上的權衡:B+ 樹在磁盤存儲、范圍查詢和穩定性方面的優勢,使其成為關系型數據庫索引的理想數據結構。
2.6 什么情況下會導致索引失效?
索引失效會導致查詢性能急劇下降,以下是導致 MySQL 索引失效的主要情況和具體示例:
- 最左前綴違規
復合索引(a,b,c),但查詢WHERE b=1
- 對索引列計算
WHERE age+1>20 或 YEAR(date_col)=2023
- 類型不匹配
字符串字段用數字查:WHERE varchar_col=123
- LIKE左模糊
WHERE name LIKE ‘%張’(右模糊’張%'可用索引)
- 使用不等于(!= / <> / NOT IN)
WHERE status!=1 或 id NOT IN(1,2,3)
- OR條件混用
WHERE id=1 OR unindexed_col=2(全失效)
優化方式:
-- 改為UNION ALL
SELECT * FROM table WHERE id = 1
UNION ALL
SELECT * FROM table WHERE name = '張三'
- NULL判斷
WHERE col IS NULL(數據量大時可能失效)
- 優化器放棄
數據量少或需返回>30%數據時,直接全表掃描更快
🔍 檢查方法:EXPLAIN查看執行計劃,出現ALL就是全表掃描。
2.7 手寫 SQL: 給定用戶表 user 和帖子表 post,獲取帖子數前十的用戶名?
方案一:使用 JOIN 和 GROUP BY。
SELECT u.username,COUNT(p.id) AS post_count
FROM post p
JOIN user u ON p.user_id = u.id
GROUP BY u.id, u.username
ORDER BY post_count DESC
LIMIT 10;
方案二:使用子查詢(MySQL 8.0+ 推薦)
WITH user_post_counts AS (SELECT user_id,COUNT(*) AS post_countFROM postGROUP BY user_idORDER BY post_count DESCLIMIT 10
)
SELECT u.username,upc.post_count
FROM user_post_counts upc
JOIN user u ON upc.user_id = u.id
ORDER BY upc.post_count DESC;
- 先計算帖子數再關聯用戶表,性能可能更好
- 使用了 CTE (Common Table Expression),需要 MySQL 8.0+ 支持
3.Golang
3.1 Golang 的 GC 是怎么實現的?
Go 語言的垃圾回收器 (Garbage Collector, GC) 是一個并發、三色標記清除 (concurrent tri-color mark-sweep) 的收集器,以下是其核心實現原理:
核心設計特點:
- 并發執行:大部分 GC 工作與用戶程序并行運行
- 三色標記法:基于對象可達性分析的標記算法
- 非分代:不像 Java 那樣分新生代/老年代
- 寫屏障 (Write Barrier):保證并發標記的正確性
- 混合回收策略:結合標記-清除和復制算法優點
三色標記算法詳解:
- 三色抽象:
- 白色:未被訪問的對象(待回收)
- 灰色:已訪問但子對象未完全檢查
- 黑色:已訪問且所有子對象已檢查
- 標記過程
初始狀態:所有對象為白色
將根對象(棧/全局變量等)標記為灰色for 灰色對象不為空 {取出一個灰色對象將其引用的白色對象標記為灰色將該對象標記為黑色
}清除階段:回收所有白色對象
并發實現關鍵:
- 寫屏障技術:
-
在并發標記期間,當對象引用關系發生變化時
-
寫屏障會捕獲這些修改,確保標記正確性
-
示例屏障代碼:
// 偽代碼:寫屏障操作
func writePointer(src, dst *Object) {shade(src) // 標記源對象為灰色*src = dst // 實際指針寫入
}
- 三階段設計:
- 標記準備:STW (Stop-The-World) 很短(通常 <1ms)
- 并發標記:與用戶程序并行(占用約25%CPU)
- 標記終止:短暫 STW 完成標記
GC 觸發條件:
- 自動觸發:堆內存達到上次GC后存活對象的倍數(默認2倍,由 GOGC 環境變量控制)。
- 手動觸發:調用 runtime.GC()。
- 系統監控:超過 2 分鐘未觸發 GC 時強制觸發。
性能優化特性:
- 逃逸分析:在編譯期決定對象分配在棧還是堆
- GC 調參:
// 設置GC百分比(默認100)
debug.SetGCPercent(100)// 設置并行標記使用的CPU核心數
debug.SetMaxThreads(4)
演進歷史:
- Go 1.5:引入并發GC,STW從秒級降到毫秒級
- Go 1.8:STW優化到亞毫秒級別(<1ms)
- Go 1.12:優化內存釋放延遲
- Go 1.14:進一步減少STW時間
- Go 1.18:優化大型堆的表現
與 Java GC 對比:
| 特性 | Go GC | Java GC |
|---|---|---|
| 并發性 | 完全并發 | 部分并發 |
| 分代 | 無 | 有 |
| STW時間 | 亞毫秒級 | 通常較長 |
| 調優復雜度 | 簡單(參數少) | 復雜(多種收集器) |
Go 的 GC 設計追求簡單性和低延遲,適合需要快速響應的服務端應用,但吞吐量可能不如分代式GC。
3.2 為什么是三色標記,兩色不行嗎?
Go 的垃圾回收器采用三色標記算法而非傳統的兩色標記,主要是為了解決并發標記過程中的對象狀態一致性問題。
引入灰色作為中間狀態:
- 白色:未掃描
- 灰色:已發現但未掃描其引用
- 黑色:已完全掃描
結合寫屏障的解決方案:
// 寫屏障偽代碼
func writePointer(src, dst *Object) {if src是黑色 && dst是白色 {dst標記為灰色 // 保存這個可能丟失的對象}*src = dst // 執行實際寫操作
}
強三色不變式:
- 強制約束:黑色對象不能直接指向白色對象。
- 通過寫屏障維護這個不變式。
為什么不能只用兩色?
- 缺乏中間狀態:
- 兩色系統無法區分"已發現但未處理"和"已處理完"的對象
- 導致必須STW(Stop-The-World)來保證一致性
- Go 的設計目標:
- 追求低延遲(亞毫秒級暫停)
- 需要支持高并發
- 這些目標使得兩色標記完全不適用
三色標記通過引入灰色這個"中間狀態",配合寫屏障機制,使Go能在極短STW的情況下實現并發垃圾回收,這是 Go GC 設計的精髓所在。
4.問題定位
4.1 如何定位服務器 CPU 占用率過高的問題?
快速診斷流程:
- 確認 CPU 負載情況
top -c # 實時查看進程CPU占用(按P排序)
htop # 更友好的交互式查看(需安裝)
mpstat -P ALL 1 # 查看每個CPU核心的使用情況
sar -u 1 3 # 查看CPU歷史利用率(需安裝sysstat)
- 識別問題進程
ps -eo pid,user,%cpu,%mem,cmd --sort=-%cpu | head -n 10
深入分析工具:
- 針對 Golang 應用
- 使用 go tool pprof 分析 CPU 和內存的性能數據,如內存泄露,協程泄露等。
# 獲取運行中程序的性能數據(無需重啟)
curl http://localhost:6060/debug/pprof/profile?seconds=30 > cpu.pprof
- 針對 Linux 通用進程
# 查看線程級CPU占用
pidstat -t -p <pid> 1 5# 系統調用分析
strace -p <pid> -c -T
perf top -p <pid> # 性能分析
- 容器環境
# 查看容器進程
docker stats
docker top <container_id># 進入容器分析
docker exec -it <container_id> /bin/bash
常見問題場景診斷:
- Goroutine 泄露
// 在代碼中定期輸出goroutine數量
go func() {for {log.Printf("goroutine count: %d", runtime.NumGoroutine())time.Sleep(5 * time.Second)}
}()
- 死循環/熱路徑
# 使用perf定位熱點
perf record -p $(pidof your_app) -g -- sleep 30
perf report -n --stdio
- 鎖競爭
import _ "net/http/pprof"// 在main.go中導入pprof包后,訪問:
// http://localhost:6060/debug/pprof/mutex
5.設計題
5.1 如何限制用戶 1 分鐘只發送 5 個帖子?
分布式環境下使用 Redis + Lua 原子自增性和線程安全即可輕松實現。Redis 的 TTL(Time to Live) 特性完美的滿足了計數器過期這一要求,將時間窗口設置為 Key 的有效時間,然后將 key 的值每次請求+1即可。
固定窗口計數器設計如下:
格式:rate_limit:{資源}:{用戶標識}:{時間窗口標識}示例:
rate_limit:post:user_12345:202308151230 (年月日時分)
rate_limit:api:ip_1.2.3.4:171543 (分鐘數取模)
// 1.判斷是否存在該key
if(EXIST(key)){// 1.1 自增后判斷是否大于最大值,并返回結果if(INCR(key) > maxPermit){return false;}return true;
}// 2.不存在 key 則設置 key 初始值為 1,失效時間為 1 秒
SET(key, 1);
EXPIRE(key, 1);
5.2 使用計數器會有什么問題?有更好的辦法嗎?
固定窗口計數器實現簡單但存在窗口邊界突增問題。
在 Redis 中實現滑動窗口限流,有序集合(ZSET)來存儲帖子 ID,score 為秒級時間戳。
以下為 Lua 版本。
local key = KEYS[1]
local limit = tonumber(ARGV[1])
local window = tonumber(ARGV[2])
local now = tonumber(ARGV[3])
local id = ARGV[4]-- 移除時間窗口外的記錄
redis.call('ZREMRANGEBYSCORE', key, 0, now - window)-- 獲取當前請求數
local count = redis.call('ZCARD', key)if count >= limit thenreturn 0 -- 限流
end-- 添加新記錄
redis.call('ZADD', key, now, id)
redis.call('EXPIRE', key, window/1000 + 1) -- 設置稍長的TTLreturn 1 -- 允許
6.編程題
6.1 找出 Top2 的數
給定一個無序整數數組(可能重復),不使用額外空間和額外變量,且不能修改數組中的數,找出 Top2 的數。
如果沒有找到,返回 error。
// 返回 5 和 4
5 4 3 2 1// 返回 5 4
4 5// 返回 error
5
思路:
- 如果數組長度小于 2 返回 error。
- 使用數組前兩個位置來存儲 Top2 的數。
- 遍歷后續所有的數,與 Top2 數做比較。
- 對于每個元素:
- 如果大于 nums[0],則先將 nums[0] 與 nums[1]交換,然后 nums[0] 與元素交換。
- 如果大于 nums[1],則 nums[1] 與元素交換。
- 最終返回 nums[0] 和 nums[1]。
實現示例:
// Top2Nums 找出無序數組中的 Top2 的數。
// 不使用額外空間和額外變量,且不能修改數組中的數。
func Top2Nums(nums []int) (int, int, error) {if len(nums) < 2 {return 0, 0, errors.New("array length must be at least 2")}// 確保 nums[0] >= nums[1]if nums[0] < nums[1] {nums[0], nums[1] = nums[1], nums[0]}// 從第三個元素開始遍歷for i := 2; i < len(nums); i++ {if nums[i] > nums[0] {// 交換 nums[0] 和 nums[1]nums[0], nums[1] = nums[1], nums[0]// 交換 nums[0] 和當前元素nums[0], nums[i] = nums[i], nums[0]} else if nums[i] > nums[1] {// 交換 nums[1] 和當前元素nums[1], nums[i] = nums[i], nums[1]}}return nums[0], nums[1], nil
}// top2nums_test.go
func TestTop2Nums(t *testing.T) {type args struct {nums []int}tests := []struct {name stringargs argswant intwant1 intwantErr bool}{{"1",args{[]int{1, 2, 3, 4, 5},},5,4,false,},{"2",args{[]int{1, 2},},2,1,false,},{"3",args{[]int{1},},0,0,true,},}for _, tt := range tests {t.Run(tt.name, func(t *testing.T) {got, got1, err := Top2Nums(tt.args.nums)if (err != nil) != tt.wantErr {t.Errorf("Top2Nums() error = %v, wantErr %v", err, tt.wantErr)return}if got != tt.want {t.Errorf("Top2Nums() got = %v, want %v", got, tt.want)}if got1 != tt.want1 {t.Errorf("Top2Nums() got1 = %v, want %v", got1, tt.want1)}})}
}
6.2 找出比左邊大比右邊小的數
算法: 給定一個數組,找到所有比左邊大,比右邊小的數? 時間復雜度 O(n)。
參見 找出無序數組中比左邊大比右邊小的數。


















)
