本文主要參考《大規模分布式存儲系統》
基本結構
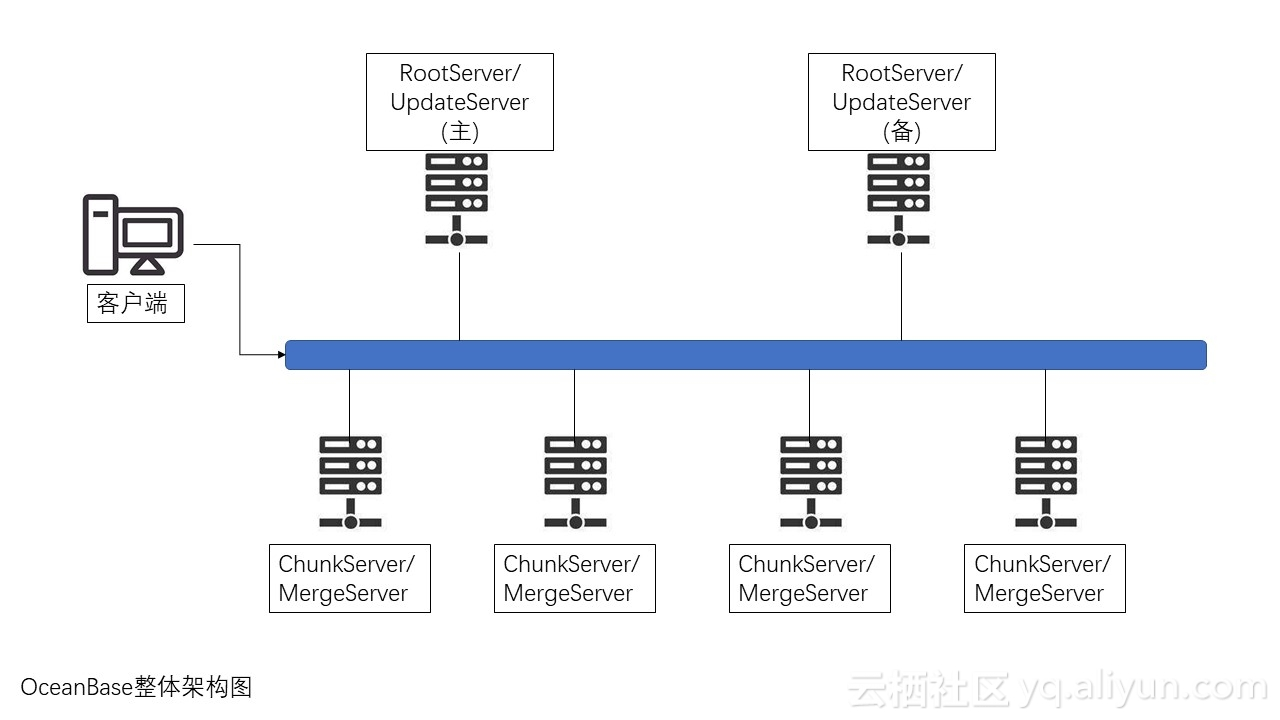
客戶端:發起請求。
RootServer:管理集群中的所有服務器,子表數據分布及副本管理,一般為一主一備,數據強同步。
UpdateServer:存儲增量變更數據,一般為一主一備,客戶端的寫入數據只更UpdateServer。
MergeServer:接收并解析SQL請求,進行詞法分析和查詢優化之后把請求轉發給ChunkServer查詢,并合并查詢后的結果。客戶端直接訪問MergeServer。
ChunkServer:存儲基線數據,一般存儲兩到三份。
上述組件可以構成一個OB集群,另外還可以在此基礎上部署多個集群,集群之間的數據同步通過主集群的UpdateServer向備集群同步來實現。
組件實現
RootServer
RootServer負責管理集群中所有的MergeServer,ChunkServer和UpdateServer,功能主要包括以下三點:
集群管理
RootServer通過心跳與其他組件連接。
保證一個集群內同一時刻只有一個UpdateServer提供服務,通過租約機制選擇唯一的主UpdateServer。
數據分布
中心表RootTable
使用主鍵對表格數據排序,按順序分布(和Hbase一樣)。把所有數據劃分為大致相等的數據范圍(Tablet),每個子表默認256MB。采用根表一級索引結構,即只有根表和子表兩層。
由于中心表RootTable的修改很少,直接使用有序數組實現,增加子表時通過CopyOnWrite的方式創建一個新的數據,對新的數據寫入和重新排序,然后吧指針指向新的RootTable。
子表分裂和合并
分裂:每臺ChunkServer采用同樣的分裂規則,根據子表的數據行數和子表大小設定分裂規則。
合并:先選擇若干連續范圍的子表,把它們遷移到相同的ChunkServer機器上,然后執行合并。只要有一個副本合并成功,就認為合并成功。
副本管理
每個子表一般包含3個副本,RootServer定期執行負載均衡,轉移子表到負載低的節點。
RootServer的主備之間數據強一致同步。
UpdateServer
集群中只有UpdateServer接收寫操作,更新時首先寫入內存,當內存表的數據量超過閾值時轉儲到磁盤。和Hbase一樣,為了保證可靠性,寫入數據前先寫入操作日志并同步到備UpdateServer。
由于只有一臺UpdateServer提供寫服務,很容易實現跨行跨表事務。
UpdateServer中的增量數據結構為一顆內存中的B+樹(Hbase為跳躍表),每個葉子結點對應一行數據,key為行主鍵,value為行操作鏈表的指針,每行按照時間順序構成一個行操作鏈表(更新、刪除)。
UpdateServer的主備節點各保存增量數據的一個副本,以此保證高可用。同步機制跟MySQL的主備同步一致基本一樣,主UpdateServer往備機推送操作日志,備UpdateServer接受線程接收日志并寫入全局日志緩沖區。
ChunkServer
ChunkServer是集群中實際存儲數據的節點,數據結構為B+樹。每個表格按主鍵組成一顆B+樹,每個葉子結點包含表格中某個主鍵范圍內的數據。每個葉子結點稱為一個子表(Tablet),包含一個或多個SSTable,每個SSTable由多個塊組成,支持布隆過濾器過濾。葉子結點是負載平衡和任務調度的基本單元。
ChunkServer中保存基線數據的2-3個副本,以此保證高可用。
ChunkServer的功能主要包括以下:
存儲多個子表
每個子表由1個SSTable組成,每個SSTable由多個塊組成,每個塊大小為4KB-64KB之間(和HBase一樣)。
支持兩種緩存:塊緩存和行緩存。
SSTable分為兩種格式:稀疏格式和稠密格式。稀疏格式的每一行只存儲包含實際值的列(列存儲),稠密格式每一行需要存儲所有列,但不需要存儲列名(行存儲)。
列存儲的好處有兩個:
- 在SQL語句只讀取部分列時,避免把完整行加載到內存中。
- 同一列數據在物理上存放到一起,提高壓縮率。
提供讀取服務
MergeServer把請求發到子表所在的ChunkServer讀取基線數據,然后請求UpdateServer獲取增量數據并融合。
定期合并
把UpdateServer轉儲來的增量表和本地的基線數據執行多路合并,生成新的SSTable。
數據分發
凍結UpdateServer當前活躍的內存表,生成凍結內存表并緩存到ChunkServer中。
MergeServer
負責解析用戶的SQL請求、轉發到ChunkServer執行、合并結果并返回。
MergeServer中緩存子表信息以減少對RootServer的讀取。MergeServer本身是無狀態的,理論上在宕機后不會對使用者產生影響。
SQL執行
讀取
select c1, sum(c2)
from t1
where c3=10
group by c1
having sum(c2) >= 10
order by c1
limit 0, 20
執行順序依次為:
TableScan(table = t1, col = {c1, c2, c3}, filter = {c3 = 10}):讀取數據。
HashGroupBy(groupby = {c1}, aggr = {sum)(c2)}):分組并計算每個分組內c2的總和。
Filter(cond = {sum(c2) >= 10}):過濾。
Sort(col={c1}):排序。
Project(col = {c1, sum(c2}):返回指定列。
Limit(offset = 0, count = 20):返回限定行數。
select t1.c1, sum(t2.c3)
from t1, t2
where t1.c2 = t2.c2and t1.c3=10
group by t1.c1
having sum(t2.c3) >= 10
order by t1.c1
limit 0, 20
執行順序依次為:
TableScan(table = t1, col = {c1, c2, c3}, filter = {c3 = 10}) 和 TableScan(table = t2, col = {c1, c2, c3}, filter = {c3 = 10}) 分別讀取數據。
Sort(col={t1.c2) 和 Sort(col={t2.c2) 分別排序。
MergeJoin(cond = {t1.c2 = t2.c2}) 合并兩張表的結果。
… 后面和單表一樣。
寫入
REPLACE:直接寫入UpdateServer。
INSERT:讀取ChunkServer中的基線數據并發送到UpdateServer,如果行已存在則返回錯誤,不存在則執行插入操作。
UPDATE:如果行已存在則執行更新,否則什么也不做。
DELETE:如果行已存在則執行刪除,否則什么也不做。
多版本并發控制
寫操作的兩個步驟:
預提交:鎖住待更新行,把操作追加到該行的未提交行操作鏈表中,然后往提交任務隊列加入一個提交任務。
提交:線程從提交任務隊列中獲取提交任務,然后把任務的操作日志寫入到日志緩沖區中(緩沖區滿時寫入磁盤)。操作日志寫成功后,把未提交行操作鏈表追加到已提交行操作鏈表,釋放鎖。
默認情況的隔離級別為讀已提交。
單行只寫事務預提交時對單行加寫鎖;多行只寫事務預提交時對所有行加寫鎖;讀寫事務中的讀操作是讀取某個版本的快照。
允許用戶顯式鎖住某一行(select xxx for update),發生死鎖時超過指定時間自動回滾。
一些設計
- 驚群效應:N個線程同時讀取一行已失效的緩存,第一個線程在讀取時往緩存中加入fake標記,其他線程發現fake標記時先等待。
- LightyQueue:使用多個隊列分散讀寫請求。
- 雙緩存機制:分配當前和預讀兩個緩沖區,使用當前緩沖區讀取完成并返回上層計算之后,預讀緩沖區切換成當前緩沖區并異步讀取數據,原來的當前緩存區計算完之后清空內存并切換成預讀。
![[Element-plus]動態設置組件的語言](http://pic.xiahunao.cn/[Element-plus]動態設置組件的語言)


)















