目錄
1、為什么 BERT 能 “懂” 語言?先看它的 “出身”
2、核心邏輯
2.1、“自學階段”—— 預訓練,像嬰兒學說話一樣積累語感
2.1.1、簡述
2.1.2、核心本事:“雙向注意力”,像人一樣 “聚焦重點”
2.2、“專項復習”—— 微調,針對任務 “量身定制”
BERT 為什么這么厲害?核心優勢總結
3、BERT+Transformer
3.1、?搭骨架:直接用 Transformer 的 “編碼器”
3.2、 練本事:雙向學習,靠 Transformer 突破單向局限
3.3、 兩步走:先 “自學” 再 “專項學”,全靠 Transformer 打底
4、詳解代碼和實驗結果
4.1、加載數據集
4.2、準備預訓練環境
4.3、激活詞元分析器
4.4、處理數據
4.5、防止模型對填充詞元進行注意力計算
4.6、拆分數據為訓練集和測試集
4.7、將所有數據轉換為torch張量
4.8、選擇批量大小并創建迭代器
4.9、BERT模型配置
關鍵配置參數說明
4.10、加載Hugging Face BERT uncased base模型
4.11、優化器分組參數
4.12、訓練循環的超參數
4.13、訓練循環
訓練循環的關鍵細節
4.13.1、?模式切換
4.13.2、 梯度清零
4.13.3、 內存優化
4.13.4、 學習率調度
訓練過程示例
4.14、對訓練進行評估
4.15、采用測試數據集進行預測和評估
4.15.1、數據準備
4.15.2、預測階段
?4.16、使用馬修斯相關系數進行評估
4.16.1、什么是 MCC?
4.16.2、MCC 的計算公式
4.16.3、公式解析與適用場景
4.16.4、如何計算 MCC?
4.16.5、詳細代碼?
4.17、整個數據集的馬修斯評估
5、完整版代碼
1、為什么 BERT 能 “懂” 語言?先看它的 “出身”
BERT 的全稱是Bidirectional Encoder Representations from Transformers,翻譯過來就是 “基于 Transformer 的雙向編碼器表示”。簡單說,它的 “大腦” 是Transformer 的編碼器(Transformer 是 2017 年提出的一種強大的語言處理框架),而 “雙向” 是它最關鍵的本事 —— 能同時看一個詞的前文和后文,真正理解這個詞在語境中的意思。
比如 “蘋果” 這個詞,在 “我吃了個蘋果” 和 “我用蘋果手機” 里意思完全不同。傳統模型可能只看前文或后文,容易理解錯,而 BERT 會同時結合前后文,準確判斷 “蘋果” 在這里指水果還是手機。
2、核心邏輯
2.1、“自學階段”—— 預訓練,像嬰兒學說話一樣積累語感
2.1.1、簡述
BERT 在正式 “工作” 前,會先在海量文本(比如維基百科、書籍等)上做兩件事,就像人小時候通過讀書、聽人說話積累語言感覺:
-
完形填空(Masked Language Model,MLM)
隨機 “遮住” 句子里 15% 的詞,讓 BERT 猜被遮住的是什么。比如把 “貓在 [MASK] 上睡覺” 中的 [MASK] 換成 “沙發”“床” 還是 “桌子”?通過億次級的 “猜詞練習”,BERT 慢慢學會了 “詞與詞的搭配規律”。 -
句子配對(Next Sentence Prediction,NSP)
給 BERT 兩句話,讓它判斷第二句是不是第一句的 “自然延續”。比如 “我今天去了超市” 和 “買了一箱牛奶” 是連貫的(選 “是”),但和 “月球繞著地球轉” 就不連貫(選 “否”)。這一步讓 BERT 學會了 “句子之間的邏輯關系”。
通過這兩個任務,BERT 相當于記住了人類語言的 “潛規則”:哪些詞經常一起出現,哪些句子搭配更合理,一個詞在不同語境下可能有哪些意思。
2.1.2、核心本事:“雙向注意力”,像人一樣 “聚焦重點”
BERT 能理解上下文的關鍵,是 Transformer 自帶的注意力機制,而且是 “雙向” 的。
可以把它想象成我們讀書時的狀態:看到一句話,不會平均分配注意力,而是會重點看和當前詞相關的部分。比如讀 “小明丟了鑰匙,他很著急”,“他” 顯然指 “小明”,BERT 的注意力會自動 “聚焦” 到 “小明” 上,從而理解 “他” 的含義。
這種 “雙向” 體現在:它不是先讀前半句再讀后半句,而是同時 “掃描” 整句話的所有詞,計算每個詞和其他詞的關聯度,最終搞清楚每個詞在當前語境下的準確意思。
2.2、“專項復習”—— 微調,針對任務 “量身定制”
預訓練后的 BERT 已經有了強大的 “語言基礎”,但具體到實際任務(如情感分析、機器翻譯、問答),還需要 “微調”:
給 BERT 輸入帶標簽的數據(比如 “這部電影太好看了!” 標簽為 “正面”),讓它在預訓練的基礎上,針對當前任務調整內部參數。就像學霸考完大考后,針對薄弱科目做專項練習,效率極高。
比如做 “問答任務” 時,給 BERT 一段文章和一個問題(如 “文章中提到的城市是哪里?”),它會通過微調學會從文章中定位答案的位置;做 “情感分析” 時,它能學會判斷一句話是表揚還是批評。
BERT 為什么這么厲害?核心優勢總結
- 雙向理解:突破傳統模型 “單向” 局限,真正像人一樣結合上下文;
- 遷移能力強:預訓練一次,就能通過微調適配幾十種語言任務,不用為每個任務從頭訓練;
- 語義理解深:能處理一詞多義、歧義句等復雜語言現象,比如區分 “打醬油” 是 “買醬油” 還是 “湊數”。
3、BERT+Transformer
BERT 的核心是用 Transformer 的 “注意力機制” 實現雙向理解,簡單說就是:借 Transformer 的本事同時看前后文,先海量 “刷題” 練語感,再針對任務調參數。
3.1、?搭骨架:直接用 Transformer 的 “編碼器”
Transformer 是個厲害的語言處理框架,它的 “編碼器” 擅長做一件事 ——注意力機制:處理句子時,每個詞都會 “關注” 到和它相關的其他詞。比如 “小明幫小紅拿了她的書”,“她” 指 “小紅”,Transformer 的注意力會讓 “她” 重點 “看” 向 “小紅”,搞清楚指代關系。
BERT 直接把這個 “編碼器” 拿來當骨架,所以天生就有這種 “抓重點” 的能力。
3.2、 練本事:雙向學習,靠 Transformer 突破單向局限
以前的模型要么只看前文(比如從左到右猜下一個詞),要么只看后文,理解容易跑偏。而 Transformer 的編碼器能同時處理整個句子,BERT 就借著這個能力實現 “雙向理解”:
比如 “我用蘋果手機拍蘋果”,BERT 會讓第一個 “蘋果” 重點 “關注”“手機”,第二個 “蘋果” 重點 “關注”“拍”,從而分清前者指品牌,后者指水果。
3.3、 兩步走:先 “自學” 再 “專項學”,全靠 Transformer 打底
-
預訓練(自學):用 Transformer 的注意力機制在海量文本上練兩個任務
- 完形填空:遮住 15% 的詞讓模型猜,練 “詞和詞的搭配”(比如 “雨停了,[MASK] 出來了” 該填 “太陽”)。
- 句子配對:判斷兩句話是否連貫,練 “句和句的邏輯”(比如 “我吃飯了” 和 “飽了” 是連貫的)。
這一步讓 BERT 吃透了語言規律,就像 Transformer 給了它 “理解的底子”。
-
微調(專項學):針對具體任務(如翻譯、問答),用 Transformer 的結構快速適配
比如做問答時,給 BERT 文章和問題,它會用注意力機制定位答案在哪;做情感分析時,會讓 “好”“棒” 這些詞重點 “影響” 正面判斷。
4、詳解代碼和實驗結果
數據集見資源綁定
4.1、加載數據集
"""查看數據集是否加載成功"""df = pd.read_csv("in_domain_train.tsv", delimiter='\t', header=None,names=['sentence_source', 'label', 'label_notes', 'sentence'])print(df.shape)print(df.sample(10))
4.2、準備預訓練環境
#創建句子、標注列表以及添加[CLS]和[SEP]詞元sentences = df.sentence.valuessentences = ["[CLS] " + sentence + " [SEP]" for sentence in sentences] #for sentence in sentences的作用是遍歷所有原始句子,為每個句子添加上 BERT 模型所需的特殊標記,從而讓處理后的句子符合 BERT 模型的輸入格式要求。labels = df.label.values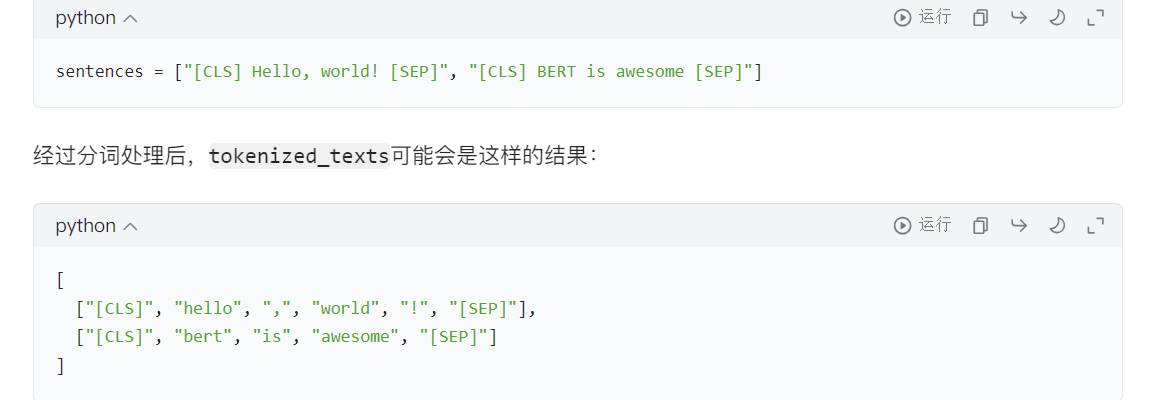
4.3、激活詞元分析器
# 加載BERT分詞器# BertTokenizer:它是 Hugging Face Transformers 庫中的一個類,專門用于處理 BERT 模型的分詞工作。# from_pretrained:這是一個類方法,能夠加載預訓練的分詞器配置和詞匯表。# 'bert-base-uncased':這里指定了要加載的預訓練模型的名稱。bert-base-uncased表示基礎版本的 BERT 模型,并且該模型使用的是小寫文本。# do_lower_case=True:此參數表明在分詞之前,需要先將所有文本轉換為小寫形式。這與bert-base-uncased模型的要求是相符的。tokenizer = BertTokenizer.from_pretrained('bert-base-uncased', do_lower_case=True)# 對文本進行分詞處理# tokenizer.tokenize(sent):該方法會把輸入的句子sent分割成 BERT 模型能夠識別的詞元(tokens)。# for sent in sentences:遍歷sentences列表中的每一個句子。# tokenized_texts:最終得到的結果是一個二維列表,列表的每個元素代表一個句子分詞后得到的詞元列表。tokenized_texts = [tokenizer.tokenize(sent) for sent in sentences]print("Tokenize the first sentence:")print(tokenized_texts[0])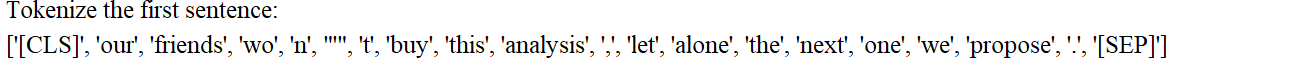
4.4、處理數據
MAX_LEN = 128 #設置了輸入序列的最大長度為 128 個詞元(tokens)# 將詞元轉換為 IDinput_ids = [tokenizer.convert_tokens_to_ids(x) for x in tokenized_texts]# 對序列進行填充和截斷,使所有序列的長度保持一致# maxlen=MAX_LEN:把所有序列的長度統一調整為 128。# dtype="long":將輸出的數據類型設置為長整型(對應 PyTorch 中的torch.long)。# truncating="post":如果某個序列的長度超過 128,就從序列的尾部進行截斷。# padding="post":如果某個序列的長度不足 128,就在序列的尾部填充 0input_ids = pad_sequences(input_ids, maxlen=MAX_LEN, dtype="long", truncating="post", padding="post")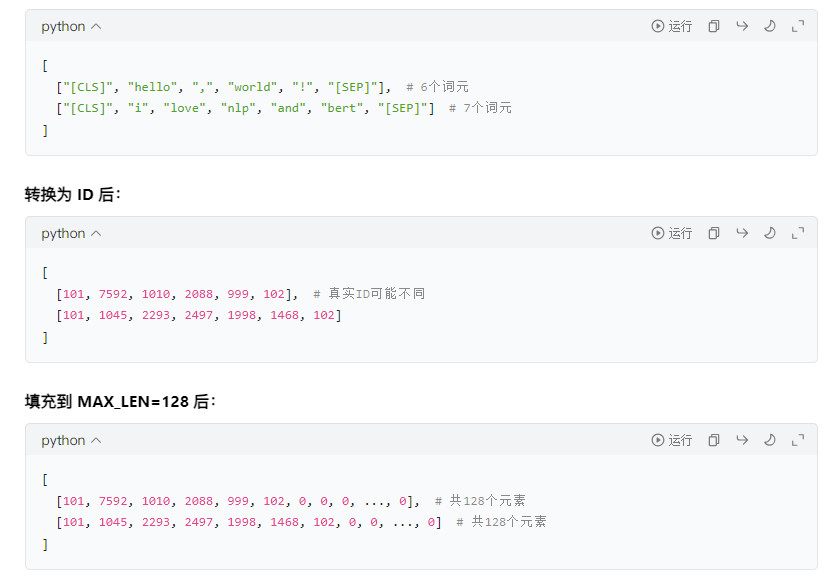
4.5、防止模型對填充詞元進行注意力計算
# 初始化注意力掩碼列表attention_masks = []# 遍歷每個序列(句子)for seq in input_ids:# 生成單個句子的掩碼# 這是一個列表推導式,作用是將seq中的每個 ID 轉換為掩碼值:# 若 IDi > 0(表示真實詞元,如[CLS]、[SEP]或普通詞元),則轉換為1.0(有效)。# 若 IDi = 0(表示填充的[PAD]標記),則轉換為0.0(無效)。# 結果seq_mask是一個與seq長度相同的列表,例如[1.0, 1.0, 0.0, 0.0, ..., 0.0]。seq_mask = [float(i > 0) for i in seq]# 保存掩碼到列表attention_masks.append(seq_mask)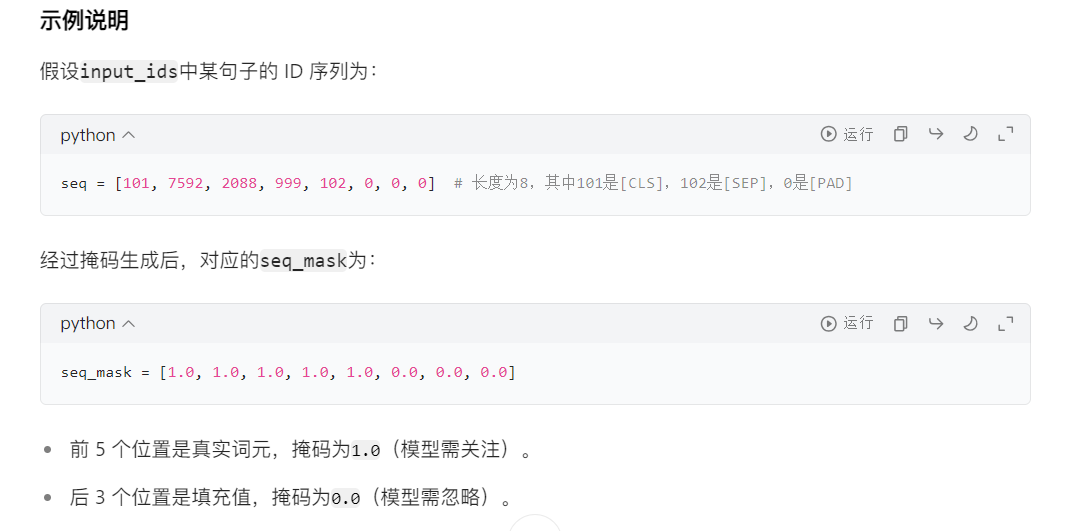
4.6、拆分數據為訓練集和測試集
# 劃分輸入 ID 和標簽# 參數說明:# input_ids:經過填充處理的輸入詞元 ID(形狀:[樣本數, MAX_LEN])# labels:對應的標簽(如情感分類的 0/1 標簽)# random_state=2018:隨機種子,確保每次劃分結果一致(可復現)# test_size=0.1:驗證集占比 10%(訓練集占 90%)# 返回值:# train_inputs:訓練集的輸入 ID# validation_inputs:驗證集的輸入 ID# train_labels:訓練集的標簽# validation_labels:驗證集的標簽train_inputs, validation_inputs, train_labels, validation_labels = train_test_split(input_ids, labels,random_state=2018,test_size=0.1)# 劃分注意力掩碼train_masks, validation_masks, _, _ = train_test_split(attention_masks, input_ids,random_state=2018, test_size=0.1)4.7、將所有數據轉換為torch張量
# 轉換訓練集和驗證集的輸入 IDtrain_inputs = torch.tensor(train_inputs)validation_inputs = torch.tensor(validation_inputs)# 轉換訓練集和驗證集的標簽train_labels = torch.tensor(train_labels)validation_labels = torch.tensor(validation_labels)# 轉換訓練集和驗證集的注意力掩碼train_masks = torch.tensor(train_masks)validation_masks = torch.tensor(validation_masks)4.8、選擇批量大小并創建迭代器
# 預處理后的張量數據封裝成 PyTorch 的DataLoader,方便按批次加載數據進行模型訓練和驗證# 批次大小# 為何需要批次訓練:# 減少內存占用:若一次性輸入所有樣本(如 10000 個),可能超出 GPU/CPU 內存。# 加速訓練:批次計算可利用矩陣運算并行性,比單樣本逐個訓練更快。# 穩定梯度:批次梯度是單樣本梯度的平均值,可減少梯度波動,使訓練更穩定。batch_size = 32# 數據集封裝train_data = TensorDataset(train_inputs, train_masks, train_labels)validation_data = TensorDataset(validation_inputs, validation_masks, validation_labels)# 采樣器(Sampler):控制數據加載順序train_sampler = RandomSampler(train_data) #隨機打亂樣本順序validation_sampler = SequentialSampler(validation_data) #按原始順序讀取樣本# 數據加載器(DataLoader)# 按批次從數據集中讀取樣本,支持多線程加速train_dataloader = DataLoader(train_data, sampler=train_sampler, batch_size=batch_size)validation_dataloader = DataLoader(validation_data, sampler=validation_sampler, batch_size=batch_size)4.9、BERT模型配置
# 創建 BERT 配置對象configuration = BertConfig()# 根據配置初始化 BERT 模型model = BertModel(configuration)# 獲取模型的配置信息configuration = model.config# 打印配置信息print(configuration)BertConfig {
? "attention_probs_dropout_prob": 0.1,
? "classifier_dropout": null,
? "hidden_act": "gelu",
? "hidden_dropout_prob": 0.1,
? "hidden_size": 768,
? "initializer_range": 0.02,
? "intermediate_size": 3072,
? "layer_norm_eps": 1e-12,
? "max_position_embeddings": 512,
? "model_type": "bert",
? "num_attention_heads": 12,
? "num_hidden_layers": 12,
? "pad_token_id": 0,
? "position_embedding_type": "absolute",
? "transformers_version": "4.26.1",
? "type_vocab_size": 2,
? "use_cache": true,
? "vocab_size": 30522
}
關鍵配置參數說明
打印出的配置信息中,核心參數及其含義如下:
| 參數名稱 | 含義說明 |
|---|---|
hidden_size | 隱藏層維度,默認 768(bert-base),bert-large為 1024。 |
num_hidden_layers | 隱藏層數量,默認 12(bert-base),bert-large為 24。 |
num_attention_heads | 注意力頭數量,默認 12(bert-base),bert-large為 16,影響并行注意力能力。 |
intermediate_size | 前饋神經網絡中間層維度,默認 3072(bert-base),bert-large為 4096。 |
hidden_act | 激活函數,默認gelu(高斯誤差線性單元),是 BERT 的標準激活函數。 |
hidden_dropout_prob | 隱藏層 dropout 概率,默認 0.1,用于防止過擬合。 |
attention_probs_dropout_prob | 注意力層 dropout 概率,默認 0.1,增強注意力機制的穩健性。 |
vocab_size | 詞表大小,默認 30522(bert-base-uncased的詞表規模)。 |
max_position_embeddings | 最大序列長度,默認 512,超過此長度的文本會被截斷。 |
4.10、加載Hugging Face BERT uncased base模型
# 確定計算設備(CPU/GPU)device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 加載適用于分類任務的 BERT 模型# BertForSequenceClassification:Hugging Face 提供的 BERT 變體模型,專為序列分類任務設計(如情感分析、文本分類等)。# 基礎結構:在 BERT 編碼器(BertModel)的輸出層后,添加了一個分類頭(全連接層 + 激活函數),用于輸出分類概率。# from_pretrained("bert-base-uncased"):# 從 Hugging Face 倉庫加載預訓練權重,使用的是bert-base-uncased模型(基礎版、小寫處理的 BERT)。# 預訓練權重包含 BERT 編碼器的參數,分類頭的參數會隨機初始化(需通過微調訓練)。# num_labels=2:指定分類任務的類別數為 2(二分類任務,如 “正面 / 負面”“正確 / 錯誤”)。若為多分類,需修改此參數(如num_labels=3)。model = BertForSequenceClassification.from_pretrained("bert-base-uncased", num_labels=2)# 配置多 GPU 并行計算model = nn.DataParallel(model)# 將模型轉移到指定設備model.to(device)4.11、優化器分組參數
# 獲取模型所有參數及其名稱# 將模型參數分為兩組,一組應用權重衰減(0.1),另一組不應用(0.0),以提高模型泛化能力param_optimizer = list(model.named_parameters())# 定義不應用權重衰減的參數類型# 這是一個列表,指定了兩種不需要應用權重衰減的參數:# 'bias':所有偏置參數(參數名稱中包含bias)。# 'LayerNorm.weight':LayerNorm 層的權重參數(參數名稱中包含LayerNorm.weight)。no_decay = ['bias', 'LayerNorm.weight']# 分組參數并設置權重衰減率optimizer_grouped_parameters = [# 第一組:應用權重衰減(0.1){'params': [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)],'weight_decay_rate': 0.1},# 第二組:不應用權重衰減(0.0){'params': [p for n, p in param_optimizer if any(nd in n for nd in no_decay)],'weight_decay_rate': 0.0}]4.12、訓練循環的超參數
# 設置訓練輪次(epochs)# 為何設置為4?:BERT等預訓練模型微調時,通常不需要太多輪次(2 - 10輪),# 過多可能導致過擬合(在訓練集表現好,驗證集差)。具體需根據任務調整,# 可通過驗證集性能判斷是否需要增加。epochs = 4# 初始化優化器(AdamW)optimizer = AdamW(optimizer_grouped_parameters,lr=2e-5,eps=1e-8)# 計算總訓練步數# 訓練數據加載器的批次數量(每輪訓練的步數)total_steps = len(train_dataloader) * epochs# 配置學習率調度器scheduler = get_linear_schedule_with_warmup(optimizer,num_warmup_steps=0,num_training_steps=total_steps)關鍵參數說明:
| 參數 | 含義 | 為何這樣設置? |
|---|---|---|
optimizer_grouped_parameters | 前文定義的參數分組(含權重衰減策略) | 確保不同參數按分組應用權重衰減,提升訓練穩定性 |
lr=2e-5 | 初始學習率(2×10??) | BERT 微調的經驗值:預訓練模型參數已較優,需用小學習率避免破壞已有特征,通常在 1e-5~5e-5 之間 |
eps=1e-8 | 數值穩定性參數(防止除以零) | 避免訓練中因梯度或參數過小導致的數值 |
# 用于計算分類任務準確率的函數 flat_accuracy,它將模型預測結果與真實標簽進行比較,返回預測正確的樣本比例
def flat_accuracy(preds, labels):# 獲取預測的類別索引pred_flat = np.argmax(preds, axis=1).flatten()# 展平真實標簽labels_flat = labels.flatten()# 計算準確率return np.sum(pred_flat == labels_flat) / len(labels_flat)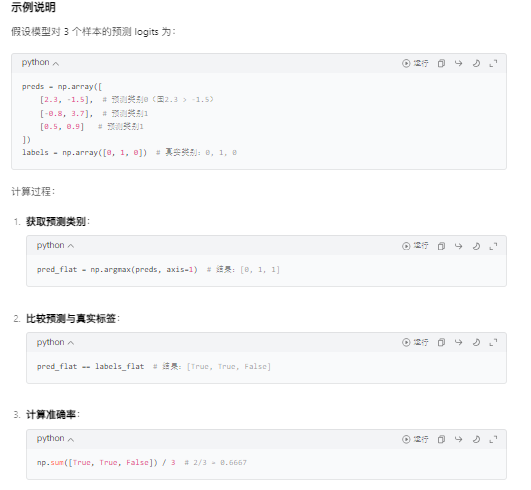
4.13、訓練循環
#初始化跟蹤變量t = [] # 存儲訓練過程中的時間戳或其他監控數據train_loss_set = []#記錄每個批次的訓練損失#外層循環:控制訓練輪次(Epochs)for _ in trange(epochs, desc="Epoch"):#訓練階段model.train()# 開啟訓練模式(啟用dropout等)tr_loss = 0 # 累積訓練損失nb_tr_examples, nb_tr_steps = 0, 0 # 樣本數和步數計數器#內層循環:批次處理流程for step, batch in enumerate(train_dataloader):#數據準備# 將批次數據轉移到 GPU/CPUbatch = tuple(t.to(device) for t in batch)b_input_ids, b_input_mask, b_labels = batch#前向傳播optimizer.zero_grad() # 清除上一步的梯度outputs = model(b_input_ids, token_type_ids=None, attention_mask=b_input_mask, labels=b_labels)loss = outputs['loss'] # 獲取損失值train_loss_set.append(loss.item())# 記錄當前批次損失#反向傳播與優化loss.backward()# 計算梯度optimizer.step()# 更新參數scheduler.step()# 更新學習率#統計訓練指標tr_loss += loss.item()nb_tr_examples += b_input_ids.size(0) # 累積樣本數nb_tr_steps += 1 # 累積步數print("Train loss: {}".format(tr_loss / nb_tr_steps))# 驗證階段model.eval()# 開啟評估模式(禁用dropout等)#數據準備eval_loss, eval_accuracy = 0, 0nb_eval_steps, nb_eval_examples = 0, 0for batch in validation_dataloader:batch = tuple(t.to(device) for t in batch)b_input_ids, b_input_mask, b_labels = batch#前向傳播(不計算梯度)with torch.no_grad():# 不計算梯度,節省內存和計算資源logits = model(b_input_ids, token_type_ids=None, attention_mask=b_input_mask)#計算驗證準確率logits = logits['logits'].detach().cpu().numpy()# 轉為NumPy數組label_ids = b_labels.to('cpu').numpy()tmp_eval_accuracy = flat_accuracy(logits, label_ids) # 使用前文定義的準確率函數eval_accuracy += tmp_eval_accuracynb_eval_steps += 1print("Validation Accuracy: {}".format(eval_accuracy / nb_eval_steps))訓練循環的關鍵細節
4.13.1、?模式切換
model.train():啟用訓練模式,激活 dropout 和 batch normalization 等訓練專用機制。model.eval():啟用評估模式,禁用 dropout 等,確保結果可復現。
4.13.2、 梯度清零
optimizer.zero_grad():清除上一步的梯度(PyTorch 默認累積梯度,需手動清零)。
4.13.3、 內存優化
with torch.no_grad():驗證階段不計算梯度,大幅減少內存占用。.detach().cpu().numpy():將張量從 GPU 移到 CPU 并轉為 NumPy 數組,釋放 GPU 內存。
4.13.4、 學習率調度
scheduler.step():每更新一次參數,學習率按線性策略衰減,有助于模型穩定收斂。
訓練過程示例
假設訓練集有 900 個樣本,batch_size=32,epochs=4,則:
- 每輪訓練步數:
900 ÷ 32 ≈ 29(向上取整)。 - 總訓練步數:
29 × 4 = 116。 - 學習率從
2e-5開始,每步線性衰減,最終降至 0。
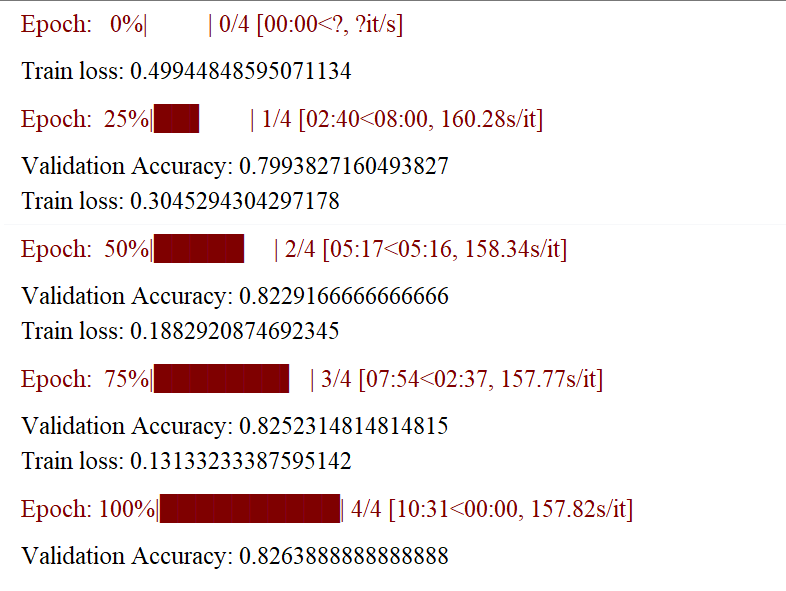
4.14、對訓練進行評估
plt.figure(figsize=(15,8))
plt.title("Training loss")
plt.xlabel("Batch")
plt.ylabel("Loss")
plt.plot(train_loss_set)
plt.show()
4.15、采用測試數據集進行預測和評估
4.15.1、數據準備
"""數據準備"""# 讀取數據df = pd.read_csv("out_of_domain_dev.tsv", delimiter='\t', header=None,names=['sentence_source', 'label', 'label_notes', 'sentence'])sentences = df.sentence.valuessentences = ["[CLS] " + sentence + " [SEP]" for sentence in sentences]labels = df.label.values# 分詞處理tokenized_texts = [tokenizer.tokenize(sent) for sent in sentences]# 轉換為 ID 并填充MAX_LEN = 128input_ids = [tokenizer.convert_tokens_to_ids(x) for x in tokenized_texts]input_ids = pad_sequences(input_ids, maxlen=MAX_LEN, dtype="long", truncating="post", padding="post")# 創建注意力掩碼attention_masks = []for seq in input_ids:seq_mask = [float(i > 0) for i in seq]attention_masks.append(seq_mask)# 轉換為 PyTorch 張量prediction_inputs = torch.tensor(input_ids)prediction_masks = torch.tensor(attention_masks)prediction_labels = torch.tensor(labels)# 創建數據加載器batch_size = 32prediction_data = TensorDataset(prediction_inputs, prediction_masks, prediction_labels)prediction_sampler = SequentialSampler(prediction_data)prediction_dataloader = DataLoader(prediction_data, sampler=prediction_sampler, batch_size=batch_size)4.15.2、預測階段
# 切換模型為評估模式model.eval()# 初始化跟蹤變量predictions, true_labels = [], []# 預測循環 批量預測for batch in prediction_dataloader:batch = tuple(t.to(device) for t in batch)b_input_ids, b_input_mask, b_labels = batch# 無梯度計算的前向傳播with torch.no_grad():logits = model(b_input_ids, token_type_ids=None, attention_mask=b_input_mask)# 結果處理# 將logits和預測標注從GPU移到CPUlogits = logits['logits'].detach().cpu().numpy()label_ids = b_labels.to('cpu').numpy()predictions.append(logits) #存儲模型預測的 logits(原始分數)true_labels.append(label_ids)#存儲對應的真實標簽?4.16、使用馬修斯相關系數進行評估
4.16.1、什么是 MCC?
Matthews 相關系數(Matthews Correlation Coefficient,簡稱 MCC)?是衡量二分類或多分類模型預測結果與實際標簽相關性的指標,取值范圍為 [-1, 1]:
- 1 表示預測完全正確;
- 0 表示預測結果與隨機猜測無異;
- -1 表示預測完全錯誤。
MCC 的優勢在于對不平衡數據不敏感,即使正負樣本比例懸殊,也能客觀反映模型性能,因此在醫療診斷、欺詐檢測等領域尤為常用。
4.16.2、MCC 的計算公式
MCC 的計算基于混淆矩陣的四個核心指標:
- 真陽性(TP):實際為正例且被正確預測為正例的樣本數;
- 真陰性(TN):實際為負例且被正確預測為負例的樣本數;
- 假陽性(FP):實際為負例但被錯誤預測為正例的樣本數;
- 假陰性(FN):實際為正例但被錯誤預測為負例的樣本數。
公式如下:
4.16.3、公式解析與適用場景
為更直觀理解 MCC 的計算邏輯,可結合其與其他指標的對比:
| 指標 | 計算公式 | 特點 | 適用場景 |
|---|---|---|---|
| MCC | 綜合考慮所有混淆矩陣元素,抗不平衡性強 | 不平衡數據集、二分類 / 多分類 | |
| 準確率(Accuracy) | 易受不平衡數據影響 | 平衡數據集 | |
| F1 分數 | 聚焦正例的精確率和召回率平衡 | 關注正例識別的場景 |
- 當數據平衡時,MCC 與準確率、F1 分數可能趨勢一致;
- 當數據不平衡(如正例占比 1%),準確率可能因 “全預測為負例” 而高達 99%,但 MCC 會接近 0,更真實反映模型無效。
4.16.4、如何計算 MCC?
在實際應用中,可直接調用工具庫計算:
- Python 的
sklearn庫:from sklearn.metrics import matthews_corrcoef,輸入真實標簽和預測標簽即可。
from sklearn.metrics import matthews_corrcoef
y_true = [1, 0, 1, 1, 0]
y_pred = [1, 0, 1, 0, 0]
print(matthews_corrcoef(y_true, y_pred)) # 輸出約0.63
4.16.5、詳細代碼?
"""使用馬修斯相關系數進行評估"""# 初始化結果列表# 包含每一批次數據的 MCC 值。matthews_set = []# 遍歷每一批次數據for i in range(len(true_labels)):# 計算當前批次的 MCC# true_labels[i]:當前批次的真實標簽(一維數組)。# np.argmax(predictions[i], axis=1).flatten():# np.argmax(predictions[i], axis=1):從預測 logits 中獲取最大分數對應的類別索引(即預測類別)。# .flatten():確保結果是一維數組(與真實標簽形狀一致)。# matthews_corrcoef MCCmatthews = matthews_corrcoef(true_labels[i], np.argmax(predictions[i], axis=1).flatten())# 存儲結果matthews_set.append(matthews)print(matthews_set)[0.049286405809014416,
?-0.29012942659282975,
?0.4040950971038548,
?0.41179801403140964,
?0.44440090347500916,
?0.6777932975034471,
?0.37084202772044256,
?0.47519096331149147,
?0.8320502943378436,
?0.7530836820370708,
?0.7679476477883045,
?0.7419408268023742,
?0.8150678894028793,
?0.7141684885491869,
?0.3268228676411533,
?0.6625413488689132,
?0.0]
4.17、整個數據集的馬修斯評估
"""整個數據集的馬修斯評估"""flat_predictions = [item for sublist in predictions for item in sublist]flat_predictions = np.argmax(flat_predictions, axis=1).flatten()flat_true_labels = [item for sublist in true_labels for item in sublist]print(matthews_corrcoef(flat_true_labels, flat_predictions))![]()
5、完整版代碼
"""
文件名: BERT+Transformer
作者: 墨塵
日期: 2025/7/27
項目名: llm_finetune
備注:
"""
import os
os.environ['TF_ENABLE_ONEDNN_OPTS'] = '0' # 禁用 oneDNN 優化
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com" # 使用國內鏡像
from transformers import BertTokenizer
import tensorflow as tf
import torch
import torch.nn as nn
from torch.utils.data import TensorDataset, DataLoader, RandomSampler, SequentialSampler
#March 2023 update
#from keras.preprocessing.sequence import pad_sequences
# from tensorflow.keras.utils import pad_sequences
from keras.preprocessing.sequence import pad_sequences
from sklearn.model_selection import train_test_split
from transformers import BertModel,BertTokenizer, BertConfig
from torch.optim import AdamW
from transformers import BertForSequenceClassification, get_linear_schedule_with_warmup
from tqdm import tqdm, trange
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import requests
from sklearn.metrics import matthews_corrcoef
# 用于計算分類任務準確率的函數 flat_accuracy,它將模型預測結果與真實標簽進行比較,返回預測正確的樣本比例
def flat_accuracy(preds, labels):# 獲取預測的類別索引pred_flat = np.argmax(preds, axis=1).flatten()# 展平真實標簽labels_flat = labels.flatten()# 計算準確率return np.sum(pred_flat == labels_flat) / len(labels_flat)if __name__ == '__main__':"""查看數據集是否加載成功"""df = pd.read_csv("in_domain_train.tsv", delimiter='\t', header=None,names=['sentence_source', 'label', 'label_notes', 'sentence'])print(df.shape)print(df.sample(10))"""準備預訓練環境"""#創建句子、標注列表以及添加[CLS]和[SEP]詞元sentences = df.sentence.valuessentences = ["[CLS] " + sentence + " [SEP]" for sentence in sentences] #for sentence in sentences的作用是遍歷所有原始句子,為每個句子添加上 BERT 模型所需的特殊標記,從而讓處理后的句子符合 BERT 模型的輸入格式要求。labels = df.label.values"""激活詞元分析器"""# 加載BERT分詞器# BertTokenizer:它是 Hugging Face Transformers 庫中的一個類,專門用于處理 BERT 模型的分詞工作。# from_pretrained:這是一個類方法,能夠加載預訓練的分詞器配置和詞匯表。# 'bert-base-uncased':這里指定了要加載的預訓練模型的名稱。bert-base-uncased表示基礎版本的 BERT 模型,并且該模型使用的是小寫文本。# do_lower_case=True:此參數表明在分詞之前,需要先將所有文本轉換為小寫形式。這與bert-base-uncased模型的要求是相符的。tokenizer = BertTokenizer.from_pretrained('bert-base-uncased', do_lower_case=True)# 對文本進行分詞處理# tokenizer.tokenize(sent):該方法會把輸入的句子sent分割成 BERT 模型能夠識別的詞元(tokens)。# for sent in sentences:遍歷sentences列表中的每一個句子。# tokenized_texts:最終得到的結果是一個二維列表,列表的每個元素代表一個句子分詞后得到的詞元列表。tokenized_texts = [tokenizer.tokenize(sent) for sent in sentences]print("Tokenize the first sentence:")print(tokenized_texts[0])"""處理數據"""MAX_LEN = 128 #設置了輸入序列的最大長度為 128 個詞元(tokens)# 將詞元轉換為 IDinput_ids = [tokenizer.convert_tokens_to_ids(x) for x in tokenized_texts]# 對序列進行填充和截斷,使所有序列的長度保持一致# maxlen=MAX_LEN:把所有序列的長度統一調整為 128。# dtype="long":將輸出的數據類型設置為長整型(對應 PyTorch 中的torch.long)。# truncating="post":如果某個序列的長度超過 128,就從序列的尾部進行截斷。# padding="post":如果某個序列的長度不足 128,就在序列的尾部填充 0input_ids = pad_sequences(input_ids, maxlen=MAX_LEN, dtype="long", truncating="post", padding="post")"""防止模型對填充詞元進行注意力計算"""# 初始化注意力掩碼列表attention_masks = []# 遍歷每個序列(句子)for seq in input_ids:# 生成單個句子的掩碼# 這是一個列表推導式,作用是將seq中的每個 ID 轉換為掩碼值:# 若 IDi > 0(表示真實詞元,如[CLS]、[SEP]或普通詞元),則轉換為1.0(有效)。# 若 IDi = 0(表示填充的[PAD]標記),則轉換為0.0(無效)。# 結果seq_mask是一個與seq長度相同的列表,例如[1.0, 1.0, 0.0, 0.0, ..., 0.0]。seq_mask = [float(i > 0) for i in seq]# 保存掩碼到列表attention_masks.append(seq_mask)"""拆分數據為訓練集和測試集"""# 劃分輸入 ID 和標簽# 參數說明:# input_ids:經過填充處理的輸入詞元 ID(形狀:[樣本數, MAX_LEN])# labels:對應的標簽(如情感分類的 0/1 標簽)# random_state=2018:隨機種子,確保每次劃分結果一致(可復現)# test_size=0.1:驗證集占比 10%(訓練集占 90%)# 返回值:# train_inputs:訓練集的輸入 ID# validation_inputs:驗證集的輸入 ID# train_labels:訓練集的標簽# validation_labels:驗證集的標簽train_inputs, validation_inputs, train_labels, validation_labels = train_test_split(input_ids, labels,random_state=2018,test_size=0.1)# 劃分注意力掩碼train_masks, validation_masks, _, _ = train_test_split(attention_masks, input_ids,random_state=2018, test_size=0.1)"""將所有數據轉換為torch張量"""# 轉換訓練集和驗證集的輸入 IDtrain_inputs = torch.tensor(train_inputs)validation_inputs = torch.tensor(validation_inputs)# 轉換訓練集和驗證集的標簽train_labels = torch.tensor(train_labels)validation_labels = torch.tensor(validation_labels)# 轉換訓練集和驗證集的注意力掩碼train_masks = torch.tensor(train_masks)validation_masks = torch.tensor(validation_masks)"""選擇批量大小并創建迭代器"""# 預處理后的張量數據封裝成 PyTorch 的DataLoader,方便按批次加載數據進行模型訓練和驗證# 批次大小# 為何需要批次訓練:# 減少內存占用:若一次性輸入所有樣本(如 10000 個),可能超出 GPU/CPU 內存。# 加速訓練:批次計算可利用矩陣運算并行性,比單樣本逐個訓練更快。# 穩定梯度:批次梯度是單樣本梯度的平均值,可減少梯度波動,使訓練更穩定。batch_size = 32# 數據集封裝train_data = TensorDataset(train_inputs, train_masks, train_labels)validation_data = TensorDataset(validation_inputs, validation_masks, validation_labels)# 采樣器(Sampler):控制數據加載順序train_sampler = RandomSampler(train_data) #隨機打亂樣本順序validation_sampler = SequentialSampler(validation_data) #按原始順序讀取樣本# 數據加載器(DataLoader)# 按批次從數據集中讀取樣本,支持多線程加速train_dataloader = DataLoader(train_data, sampler=train_sampler, batch_size=batch_size)validation_dataloader = DataLoader(validation_data, sampler=validation_sampler, batch_size=batch_size)"""BERT模型配置"""# 創建 BERT 配置對象configuration = BertConfig()# 根據配置初始化 BERT 模型model = BertModel(configuration)# 獲取模型的配置信息configuration = model.config# 打印配置信息print(configuration)"""加載Hugging Face BERT uncased base模型"""# 確定計算設備(CPU/GPU)device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 加載適用于分類任務的 BERT 模型# BertForSequenceClassification:Hugging Face 提供的 BERT 變體模型,專為序列分類任務設計(如情感分析、文本分類等)。# 基礎結構:在 BERT 編碼器(BertModel)的輸出層后,添加了一個分類頭(全連接層 + 激活函數),用于輸出分類概率。# from_pretrained("bert-base-uncased"):# 從 Hugging Face 倉庫加載預訓練權重,使用的是bert-base-uncased模型(基礎版、小寫處理的 BERT)。# 預訓練權重包含 BERT 編碼器的參數,分類頭的參數會隨機初始化(需通過微調訓練)。# num_labels=2:指定分類任務的類別數為 2(二分類任務,如 “正面 / 負面”“正確 / 錯誤”)。若為多分類,需修改此參數(如num_labels=3)。model = BertForSequenceClassification.from_pretrained("bert-base-uncased", num_labels=2)# 配置多 GPU 并行計算model = nn.DataParallel(model)# 將模型轉移到指定設備model.to(device)"""優化器分組參數"""# 獲取模型所有參數及其名稱# 將模型參數分為兩組,一組應用權重衰減(0.1),另一組不應用(0.0),以提高模型泛化能力param_optimizer = list(model.named_parameters())# 定義不應用權重衰減的參數類型# 這是一個列表,指定了兩種不需要應用權重衰減的參數:# 'bias':所有偏置參數(參數名稱中包含bias)。# 'LayerNorm.weight':LayerNorm 層的權重參數(參數名稱中包含LayerNorm.weight)。no_decay = ['bias', 'LayerNorm.weight']# 分組參數并設置權重衰減率optimizer_grouped_parameters = [# 第一組:應用權重衰減(0.1){'params': [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)],'weight_decay_rate': 0.1},# 第二組:不應用權重衰減(0.0){'params': [p for n, p in param_optimizer if any(nd in n for nd in no_decay)],'weight_decay_rate': 0.0}]"""訓練循環的超參數"""# 設置訓練輪次(epochs)# 為何設置為4?:BERT等預訓練模型微調時,通常不需要太多輪次(2 - 10輪),# 過多可能導致過擬合(在訓練集表現好,驗證集差)。具體需根據任務調整,# 可通過驗證集性能判斷是否需要增加。epochs = 4# 初始化優化器(AdamW)optimizer = AdamW(optimizer_grouped_parameters,lr=2e-5,eps=1e-8)# 計算總訓練步數# 訓練數據加載器的批次數量(每輪訓練的步數)total_steps = len(train_dataloader) * epochs# 配置學習率調度器scheduler = get_linear_schedule_with_warmup(optimizer,num_warmup_steps=0,num_training_steps=total_steps)"""訓練循環"""#初始化跟蹤變量t = [] # 存儲訓練過程中的時間戳或其他監控數據train_loss_set = []#記錄每個批次的訓練損失#外層循環:控制訓練輪次(Epochs)for _ in trange(epochs, desc="Epoch"):#訓練階段model.train()# 開啟訓練模式(啟用dropout等)tr_loss = 0 # 累積訓練損失nb_tr_examples, nb_tr_steps = 0, 0 # 樣本數和步數計數器#內層循環:批次處理流程for step, batch in enumerate(train_dataloader):#數據準備# 將批次數據轉移到 GPU/CPUbatch = tuple(t.to(device) for t in batch)b_input_ids, b_input_mask, b_labels = batch#前向傳播optimizer.zero_grad() # 清除上一步的梯度outputs = model(b_input_ids, token_type_ids=None, attention_mask=b_input_mask, labels=b_labels)loss = outputs['loss'] # 獲取損失值train_loss_set.append(loss.item())# 記錄當前批次損失#反向傳播與優化loss.backward()# 計算梯度optimizer.step()# 更新參數scheduler.step()# 更新學習率#統計訓練指標tr_loss += loss.item()nb_tr_examples += b_input_ids.size(0) # 累積樣本數nb_tr_steps += 1 # 累積步數print("Train loss: {}".format(tr_loss / nb_tr_steps))# 驗證階段model.eval()# 開啟評估模式(禁用dropout等)#數據準備eval_loss, eval_accuracy = 0, 0nb_eval_steps, nb_eval_examples = 0, 0for batch in validation_dataloader:batch = tuple(t.to(device) for t in batch)b_input_ids, b_input_mask, b_labels = batch#前向傳播(不計算梯度)with torch.no_grad():# 不計算梯度,節省內存和計算資源logits = model(b_input_ids, token_type_ids=None, attention_mask=b_input_mask)#計算驗證準確率logits = logits['logits'].detach().cpu().numpy()# 轉為NumPy數組label_ids = b_labels.to('cpu').numpy()tmp_eval_accuracy = flat_accuracy(logits, label_ids) # 使用前文定義的準確率函數eval_accuracy += tmp_eval_accuracynb_eval_steps += 1print("Validation Accuracy: {}".format(eval_accuracy / nb_eval_steps))plt.figure(figsize=(15, 8))plt.title("Training loss")plt.xlabel("Batch")plt.ylabel("Loss")plt.plot(train_loss_set)plt.show()"""采用測試數據集進行預測和評估""""""數據準備"""# 讀取數據df = pd.read_csv("out_of_domain_dev.tsv", delimiter='\t', header=None,names=['sentence_source', 'label', 'label_notes', 'sentence'])sentences = df.sentence.valuessentences = ["[CLS] " + sentence + " [SEP]" for sentence in sentences]labels = df.label.values# 分詞處理tokenized_texts = [tokenizer.tokenize(sent) for sent in sentences]# 轉換為 ID 并填充MAX_LEN = 128input_ids = [tokenizer.convert_tokens_to_ids(x) for x in tokenized_texts]input_ids = pad_sequences(input_ids, maxlen=MAX_LEN, dtype="long", truncating="post", padding="post")# 創建注意力掩碼attention_masks = []for seq in input_ids:seq_mask = [float(i > 0) for i in seq]attention_masks.append(seq_mask)# 轉換為 PyTorch 張量prediction_inputs = torch.tensor(input_ids)prediction_masks = torch.tensor(attention_masks)prediction_labels = torch.tensor(labels)# 創建數據加載器batch_size = 32prediction_data = TensorDataset(prediction_inputs, prediction_masks, prediction_labels)prediction_sampler = SequentialSampler(prediction_data)prediction_dataloader = DataLoader(prediction_data, sampler=prediction_sampler, batch_size=batch_size)"""預測階段"""# 切換模型為評估模式model.eval()# 初始化跟蹤變量predictions, true_labels = [], []# 預測循環 批量預測for batch in prediction_dataloader:batch = tuple(t.to(device) for t in batch)b_input_ids, b_input_mask, b_labels = batch# 無梯度計算的前向傳播with torch.no_grad():logits = model(b_input_ids, token_type_ids=None, attention_mask=b_input_mask)# 結果處理# 將logits和預測標注從GPU移到CPUlogits = logits['logits'].detach().cpu().numpy()label_ids = b_labels.to('cpu').numpy()predictions.append(logits) #存儲模型預測的 logits(原始分數)true_labels.append(label_ids)#存儲對應的真實標簽"""使用馬修斯相關系數進行評估"""# 初始化結果列表# 包含每一批次數據的 MCC 值。matthews_set = []# 遍歷每一批次數據for i in range(len(true_labels)):# 計算當前批次的 MCC# true_labels[i]:當前批次的真實標簽(一維數組)。# np.argmax(predictions[i], axis=1).flatten():# np.argmax(predictions[i], axis=1):從預測 logits 中獲取最大分數對應的類別索引(即預測類別)。# .flatten():確保結果是一維數組(與真實標簽形狀一致)。# matthews_corrcoef MCCmatthews = matthews_corrcoef(true_labels[i], np.argmax(predictions[i], axis=1).flatten())# 存儲結果matthews_set.append(matthews)"""各批量的分數"""print(matthews_set)"""整個數據集的馬修斯評估"""flat_predictions = [item for sublist in predictions for item in sublist]flat_predictions = np.argmax(flat_predictions, axis=1).flatten()flat_true_labels = [item for sublist in true_labels for item in sublist]print(matthews_corrcoef(flat_true_labels, flat_predictions))








)


--字符指針變量,數組指針變量,二維數組傳參的本質,函數指針變量,函數指針數組)





流程)
