溫馨提示:
本篇文章已同步至"AI專題精講" InstructBLIP:通過指令微調邁向通用視覺-語言模型
摘要
大規模預訓練和指令微調在構建通用語言模型方面取得了顯著成功。然而,構建通用視覺-語言模型仍然面臨挑戰,這主要源于由于視覺輸入所帶來的豐富輸入分布和任務多樣性。盡管視覺-語言預訓練已經被廣泛研究,視覺-語言指令微調仍然是一個未被充分探索的方向。本文基于預訓練的 BLIP-2 模型,對視覺-語言指令微調進行了系統且全面的研究。我們收集了 26 個公開數據集,涵蓋了廣泛的任務和能力,并將它們轉換為指令微調格式。此外,我們引入了一種感知指令的 Query Transformer,該模塊可根據給定的指令提取更具信息性的特征。在 13 個訓練數據集上訓練后,InstructBLIP 在所有 13 個未見數據集上實現了最先進的零樣本性能,顯著優于 BLIP-2 以及更大規模的 Flamingo 模型。我們的模型在單個下游任務上微調后也達到了 SOTA 性能(例如在包含圖像上下文的 ScienceQA 問題上達到 90.7% 的準確率)。此外,我們通過定性分析展示了 InstructBLIP 相較于當前多模態模型的優勢。所有 InstructBLIP 模型均已開源。
1 引言
人工智能研究的長期目標之一是構建一個能夠解決任意用戶指定任務的通用模型。在自然語言處理(NLP)領域,指令微調[46, 7] 已被證明是實現該目標的一種有前景的方法。通過在由自然語言指令描述的多種任務上微調大型語言模型(LLM),指令微調使模型能夠遵循任意指令。最近,指令微調后的 LLM 也開始被應用于視覺-語言任務。例如,BLIP-2 [20] 能夠有效地適配凍結的指令微調 LLM 來理解視覺輸入,并在圖像到文本生成任務中展現出初步的指令遵循能力。
與 NLP 任務相比,視覺-語言任務由于包含來自不同領域的視覺輸入而更加多樣化。這對統一模型的泛化能力提出了更高要求,尤其是在面對訓練過程中未見的多樣化視覺-語言任務時。以往的相關工作大致可以分為兩類:第一類是多任務學習方法 [6, 27],它將各種視覺-語言任務統一轉化為相同的輸入-輸出格式。但我們實證發現,缺乏指令的多任務學習方法(見表4)在泛化到未見數據集和任務時表現不佳。第二類方法 [20, 4] 則是在預訓練 LLM 的基礎上引入額外視覺模塊,并使用圖像描述數據對視覺模塊進行訓練。然而,這類數據過于有限,難以支持對需要超出視覺描述能力的視覺-語言任務的廣泛泛化。

為了解決上述挑戰,本文提出了 InstructBLIP,一個視覺-語言指令微調框架,使通用模型能夠通過統一的自然語言接口解決各種視覺-語言任務。InstructBLIP 利用多樣化的指令數據對多模態 LLM 進行訓練。具體而言,我們以預訓練的 BLIP-2 模型作為起點,該模型由圖像編碼器、LLM 和一個連接兩者的 Query Transformer(Q-Former)組成。在指令微調過程中,我們僅對 Q-Former 進行微調,圖像編碼器和 LLM 保持凍結狀態。
本文的主要貢獻如下:
- 我們對視覺-語言指令微調進行了全面系統的研究。我們將 26 個數據集轉化為指令微調格式,并劃分為 11 個任務類別。使用其中 13 個數據集進行訓練,其余 13 個數據集用于零樣本評估。此外,我們還保留了 4 個完整任務類別用于任務級別的零樣本評估。詳盡的定量與定性實驗結果展示了 InstructBLIP 在視覺-語言零樣本泛化方面的有效性。
- 我們提出了感知指令的視覺特征提取機制,這是一種新的機制,能夠根據給定指令靈活地提取信息性特征。具體來說,自然語言指令不僅被輸入給凍結的 LLM,也輸入給 Q-Former,從而使其能夠從凍結的圖像編碼器中提取與指令相關的視覺特征。同時,我們提出了一種平衡采樣策略,用于同步不同數據集間的學習進度。
- 我們在兩類 LLM 基礎上評估并開源了一系列 InstructBLIP 模型:1)FlanT5 [7],一種在 T5 [34] 基礎上微調的編碼-解碼型 LLM;2)Vicuna [2],一種在 LLaMA [41] 基礎上微調的解碼器-only 型 LLM。InstructBLIP 模型在廣泛的視覺-語言任務上實現了最先進的零樣本性能。此外,當作為單個下游任務的初始化模型使用時,InstructBLIP 也能獲得最先進的微調表現。
2 視覺-語言指令調優
InstructBLIP 旨在解決 vision-language instruction tuning 中的獨特挑戰,并系統性地研究模型對未見數據和任務的泛化能力提升。在本節中,我們首先介紹 instruction tuning 數據的構建方式,隨后說明訓練與評估協議。接下來,我們從模型和數據的角度分別闡述兩種提升 instruction tuning 表現的技術。最后,我們給出實現細節。
2.1 任務與數據集
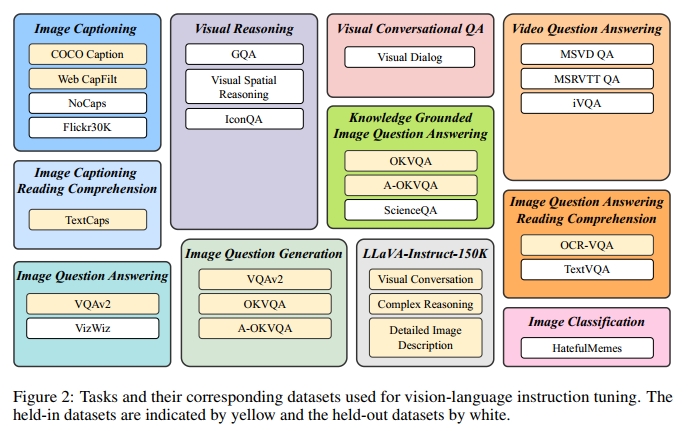
為了確保 instruction tuning 數據的多樣性,同時考慮其可獲取性,我們收集了一套全面的公開 vision-language 數據集,并將它們轉換為 instruction tuning 格式。如圖 2 所示,最終數據集合涵蓋 11 類任務與 26 個數據集,包括圖像描述(image captioning)[23, 3, 51]、帶閱讀理解的圖像描述 [38]、視覺推理(visual reasoning)[16, 24, 29]、圖像問答(image question answering)[11, 12]、基于知識的圖像問答(knowledge-grounded image question answering)[30, 36, 28]、帶閱讀理解的圖像問答 [31, 39]、圖像問句生成(從 QA 數據集改造而來)、視頻問答(video question answering)[47, 49]、多輪視覺問答(visual conversational question answering)[8]、圖像分類 [18] 和 LLaVA-Instruct-150K [25]。我們在附錄 C 中提供了每個數據集的詳細描述和統計信息。
針對每項任務,我們精心設計了 10 到 15 個不同的自然語言 instruction 模板。這些模板構成了 instruction tuning 數據的基礎,用于明確描述任務及其目標。對于那些本身傾向于輸出簡短回復的公開數據集,我們在部分指令模板中加入了“簡要”“簡短”等詞匯,以降低模型始終生成短文本的過擬合風險。至于 LLaVA-Instruct-150K 數據集,由于其本身已經采用 instruction 格式,因此我們未額外添加 instruction 模板。完整的 instruction 模板列表見附錄 D。
2.2 訓練與評估協議
為了確保 instruction tuning 與 zero-shot 評估中有充足的數據與任務,我們將 26 個數據集劃分為 13 個 held-in 數據集和 13 個 held-out 數據集,分別在圖 2 中以黃色和白色標示。我們使用 held-in 數據集的訓練集進行 instruction tuning,并使用其驗證集或測試集進行 held-in 評估。
對于 held-out 評估,我們的目標是理解 instruction tuning 如何提升模型在未見數據上的 zero-shot 表現。我們定義兩類 held-out 數據:1)模型在訓練過程中未接觸的某些數據集,但其任務類型已出現在 held-in 集合中;2)訓練過程中完全未見的數據集及其相關任務。第一類 held-out 評估面臨的主要挑戰是 held-in 與 held-out 數據集之間的數據分布差異。對于第二類,我們完全舍棄若干任務,包括視覺推理(visual reasoning)、視頻問答(video question answering)、多輪視覺問答(visual conversational QA)和圖像分類(image classification)。
為了避免數據污染,我們在選擇數據集時非常謹慎,確保不同數據集中用于評估的樣本不會出現在 held-in 訓練集合中。在 instruction tuning 過程中,我們混合所有 held-in 訓練集,并對每個數據集均勻采樣指令模板。模型使用標準的語言建模損失函數進行訓練,直接根據指令生成響應。此外,對于包含場景文字(scene text)的數據集,我們在指令中加入 OCR token 作為輔助信息。
2.3 指令感知視覺特征提取
現有的 zero-shot 圖像到文本生成方法(如 BLIP-2)在提取視覺特征時通常不考慮指令(instruction-agnostic),導致無論任務為何,LLM 接收的始終是一組靜態的視覺表示。相比之下,instruction-aware 的視覺模型能夠根據任務指令進行適應,并生成對當前任務最有利的視覺表示。當我們期望對于同一輸入圖像有不同的任務指令時,這種方法顯然更具優勢。
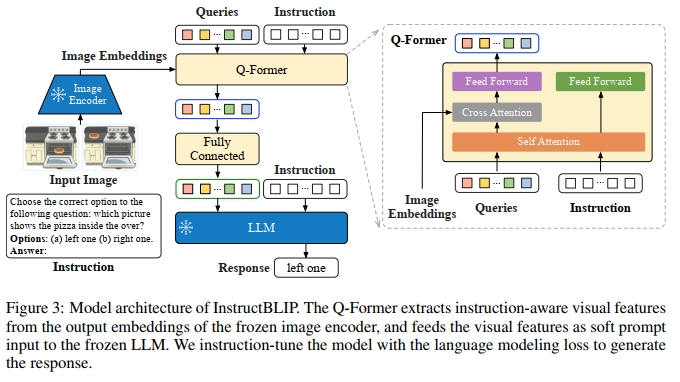
我們在圖 3 中展示了 InstructBLIP 的架構。與 BLIP-2 [20] 類似,InstructBLIP 使用一個 Query Transformer(Q-Former)從凍結的圖像編碼器中提取視覺特征。Q-Former 的輸入是一組可學習的 K 個查詢嵌入(query embedding),它們通過交叉注意力機制與圖像編碼器的輸出進行交互。Q-Former 的輸出是一組 K 個編碼后的視覺向量(每個查詢嵌入對應一個向量),這些向量經過線性映射后被輸入到凍結的 LLM 中。與 BLIP-2 一樣,Q-Former 在 instruction tuning 之前通過兩個階段的圖像-描述數據預訓練完成初始化:第一階段使用凍結的圖像編碼器對 Q-Former 進行 vision-language 表示學習;第二階段將 Q-Former 的輸出適配為 soft visual prompt,并輸入到凍結的 LLM 中用于文本生成。在預訓練完成后,我們對 Q-Former 進行 instruction tuning,此時 LLM 接收 Q-Former 輸出的視覺編碼與任務指令作為輸入。
2.4 平衡訓練數據集
在進行指令調優時,平衡訓練數據集是一項重要策略。通過對不同數據集進行適當的平衡采樣,可以避免某些數據集在訓練過程中占主導地位,從而確保模型能夠在多種任務上均衡地進行學習。這種方法特別有助于多任務學習場景,能夠促進不同任務之間的相互學習,從而提升模型在各種任務上的泛化能力。
由于訓練數據集數量龐大且每個數據集的規模差異顯著,若均勻混合這些數據集,可能會導致模型對較小數據集過擬合,對較大數據集欠擬合。為了解決這個問題,我們提出了按照數據集大小的平方根或訓練樣本數量來采樣數據集。一般來說,給定 D 個數據集,大小分別為{S1,S2,…,SD}\{ S _ { 1 } , S _ { 2 } , \ldots , S _ { D } \}{S1?,S2?,…,SD?},從數據集 d 中選取一個數據樣本的概率為:
pd=Sd∑i=1DSi\begin{array} { r } { p _ { d } = \frac { \sqrt { S _ { d } } } { \sum _ { i = 1 } ^ { D } \sqrt { S _ { i } } } } \end{array}pd?=∑i=1D?Si??Sd???? ,在此公式的基礎上,我們手動調整某些數據集的權重,以優化模型。這是由于數據集和任務之間存在固有差異,盡管它們的大小相似,但對訓練強度的需求不同。具體而言,我們降低了 A-OKVQA(多項選擇題)數據集的權重,并提高了 OKVQA(需要開放式文本生成)的權重。在表 2 中,我們展示了平衡數據集采樣策略在 held-in 評估和 held-out 泛化任務中的整體性能提升。
2.5 Inference Methods
在推理階段,我們根據不同數據集采用兩種略有不同的生成方法進行評估。對于大多數數據集,如圖像描述和開放式 VQA,我們直接提示 instruction-tuned 模型生成響應,然后與真實答案進行比較以計算評估指標。另一方面,對于分類任務和多項選擇 VQA 任務,我們采用詞匯排序方法,這一方法參考了之前的研究 [46, 22, 21]。具體來說,我們仍然提示模型生成答案,但將其詞匯限制在候選列表中。接著,我們計算每個候選答案的對數似然(log-likelihood),并選擇對數似然值最大的候選作為最終預測。該排序方法應用于 ScienceQA、IconQA、A-OKVQA(多項選擇)、HatefulMemes、Visual Dialog、MSVD 和 MSRVTT 數據集。此外,對于二分類任務,我們將正負標簽擴展為稍廣泛的詞匯集合,以便利用自然文本中的詞頻(例如,正類使用 yes 和 true,負類使用 no 和 false)。
對于視頻問答任務,我們對每個視頻均勻采樣四幀。每幀分別通過圖像編碼器和 Q-Former 處理,提取的視覺特征被連接在一起,然后輸入到 LLM 中。
2.6 實現細節
Architecture
得益于 BLIP-2 模塊化架構設計的靈活性,我們可以迅速將模型適配到各種 LLM。在我們的實驗中,我們采用了四種不同的 BLIP-2 變體,使用相同的圖像編碼器(ViT-g/14 [10]),但使用不同的凍結 LLM,包括 FlanT5-XL(3B)、FlanT5-XXL(11B)、Vicuna-7B 和 Vicuna-13B。FlanT5 [7] 是基于編碼器-解碼器 Transformer T5 [34] 的 instruction-tuned 模型。而 Vicuna [2] 是最近發布的僅解碼器 Transformer,從 LLaMA [41] 上進行了 instruction-tuning。在視覺-語言 instruction tuning 過程中,我們從預訓練的 BLIP-2 檢查點初始化模型,并且只對 Q-Former 的參數進行微調,保持圖像編碼器和 LLM 不變。由于原始 BLIP-2 模型沒有提供 Vicuna 的檢查點,我們使用與 BLIP-2 相同的過程進行 Vicuna 的預訓練。
Training and Hyper-parameters
我們使用 LAVIS 庫 [19] 進行實現、訓練和評估。所有模型均在最多 60K 步中進行 instruction-tuning,每 3K 步驗證一次模型性能。對于每個模型,選擇一個最佳的檢查點,并用于所有數據集的評估。我們為 3B、7B 和 11/13B 模型分別采用了 192、128 和 64 的批量大小。優化器使用 AdamW [26],其中 β1=0.9,β2=0.999β_1 = 0.9,β_2 = 0.999β1?=0.9,β2?=0.999,權重衰減為 0.05。此外,我們在初始的 1,000 步中應用了學習率的線性預熱,從 10?810^{-8}10?8 增加到 10?510^{-5}10?5,然后使用余弦衰減,最低學習率為 0。所有模型在 16 臺 Nvidia A100(40G)GPU 上進行訓練,整個訓練過程在 1.5 天內完成。
3. 實驗結果與分析
3.1 Zero-shot 評估
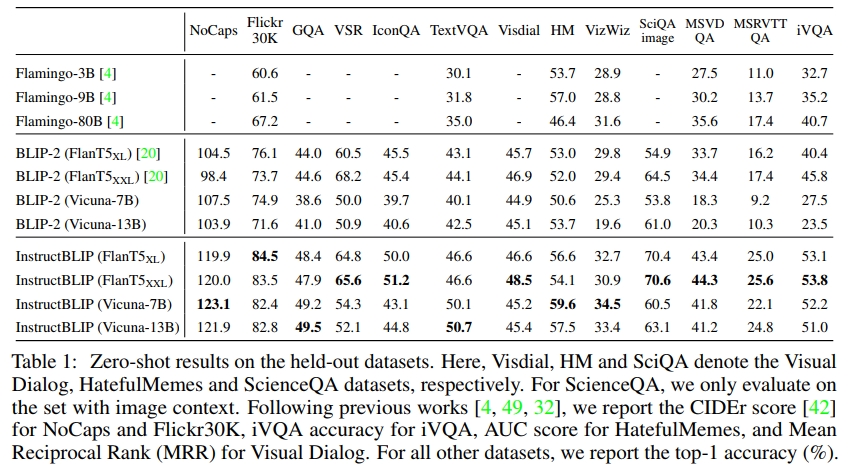
我們首先在 13 個 held-out 數據集上評估 InstructBLIP 模型,使用的指令見附錄 E。我們將 InstructBLIP 與之前的 SOTA 模型 BLIP-2 和 Flamingo 進行比較。如表 1 所示,我們在所有數據集上都取得了新的零-shot SOTA 結果。InstructBLIP 在所有 LLM 上都顯著超過了其原始的骨干網絡 BLIP-2,展示了視覺-語言 instruction tuning 的有效性。例如,InstructBLIP FlanT5XL 相比于 BLIP-2 FlanT5XL,平均相對提升了 15.0%。
此外,instruction tuning 提升了對未見任務類別(例如視頻 QA)的零-shot 泛化能力。盡管從未使用時序視頻數據進行訓練,InstructBLIP 在 MSRVTT-QA 數據集上仍取得了相較于之前 SOTA 最高 47.1% 的相對提升。最后,我們的最小 InstructBLIP FlanT5XL(4B 參數)在所有六個共享評估數據集上都超越了 Flamingo-80B,平均相對提升了 24.8%。
對于 Visual Dialog 數據集,我們選擇報告平均倒數排名(MRR)而不是標準化折扣累積增益(NDCG)指標。這是因為 NDCG 偏向于通用且不確定的回答,而 MRR 更傾向于準確的回答[32],因此 MRR 更符合零-shot 評估場景的需求。
3.2 指令調優技術的消融研究
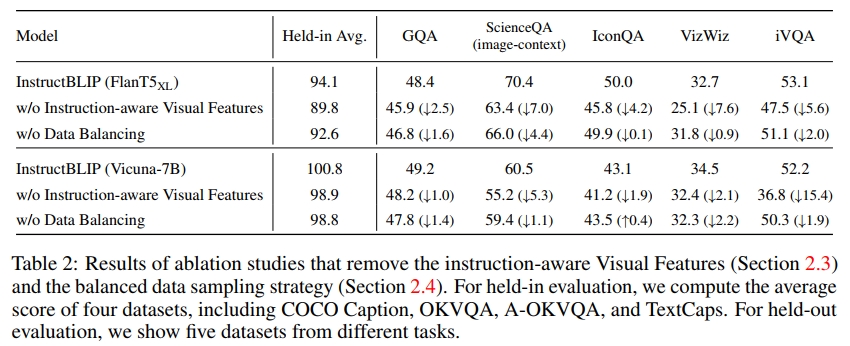
為了研究指令感知視覺特征提取(第2.3節)和數據集平衡采樣策略(第2.4節)的影響,我們在指令調優過程中進行了消融實驗。如表2所示,去除視覺特征中的指令感知會顯著降低所有數據集的性能。在涉及空間視覺推理(例如 ScienceQA)或時間視覺推理(例如 iVQA)的數據集上,性能下降尤為嚴重,因為輸入到 Q-Former 的指令可以引導視覺特征關注圖像中的重要區域。去除數據平衡策略會導致訓練不穩定和不均勻,因為不同數據集在訓練步驟上達到峰值的時機差異較大。多個數據集的進度不同步會損害整體性能。
3.3 定性評估
除了對公共基準的系統評估外,我們還進一步定性地檢查了 InstructBLIP 在更多樣的圖像和指令上的表現。如圖1所示,InstructBLIP 展現了其進行復雜視覺推理的能力。例如,它可以根據視覺場景合理推斷發生了什么,并根據場景的位置推測災難類型,基于如棕櫚樹等視覺證據進行外推。此外,InstructBLIP 能夠將視覺輸入與嵌入的文本知識相結合,并生成有信息量的響應,比如介紹一幅著名畫作。更重要的是,在描述整體氛圍時,InstructBLIP 展現了理解視覺圖像隱喻含義的能力。最后,我們展示了 InstructBLIP 可以進行多輪對話,在生成新回應時有效考慮對話歷史。
在附錄B中,我們定性地將 InstructBLIP 與同時期的多模態模型(GPT-4 [33]、LLaVA [25]、MiniGPT-4 [52])進行了比較。盡管所有模型都能夠生成長篇響應,但 InstructBLIP 的輸出通常包含更多恰當的視覺細節,并展示了邏輯上連貫的推理步驟。更重要的是,我們認為長篇回答并非總是最優。例如,在附錄的圖2中,InstructBLIP 通過自適應調整響應長度直接回應用戶意圖,而 LLaVA 和 MiniGPT-4 則生成了冗長且不太相關的句子。InstructBLIP 的這些優勢得益于多樣化的指令調優數據和有效的架構設計。
3.4 指令調優 vs. 多任務學習

溫馨提示:
閱讀全文請訪問"AI深語解構" InstructBLIP:通過指令微調邁向通用視覺-語言模型
![[python][flask]flask藍圖使用方法](http://pic.xiahunao.cn/[python][flask]flask藍圖使用方法)







![[ctfshow web入門]web99 in_array的弱比較漏洞](http://pic.xiahunao.cn/[ctfshow web入門]web99 in_array的弱比較漏洞)





)




)