背景
大語言模型在生成高質量文案方面表現優異,然而其巨大的計算資源消耗和存儲需求,使得實際應用尤其是在資源受限場景中的應用充滿挑戰。企業在尋求高效的文案生成時,常常面臨著在性能和資源之間權衡的困境。在這種背景下,模型蒸餾技術為解決這一問題提供了新的思路。模型蒸餾是一種優化技術,旨在通過將知識從大型復雜模型中提取并轉移到更小、計算更高效的模型中,使得這些小型模型能夠在保留大多數性能優勢的情況下顯著降低資源需求。這一技術在大模型文案生成領域的應用,不僅能夠保持生成質量接近原有大模型,還極大地減少了計算成本和部署難度。本文介紹如何使用EasyDistill算法框架以及PAI產品,實現基于模型蒸餾的大模型文案生成,通過這種方式節省人力成本,同時提高用戶體驗,推動業務的可持續增長。
部署教師大語言模型
部署模型服務
您可以按照以下操作步驟,部署教師大語言模型生成對應回復。
在PAI-Model Gallery選擇DeepSeek-V3模型或者其他教師大模型,在模型部署區域,系統已默認配置了模型服務信息和資源部署信息,您也可以根據需要進行修改,參數配置完成后單擊部署按鈕。以DeepSeek-V3為例,其模型卡片如下所示:
模型部署和調用
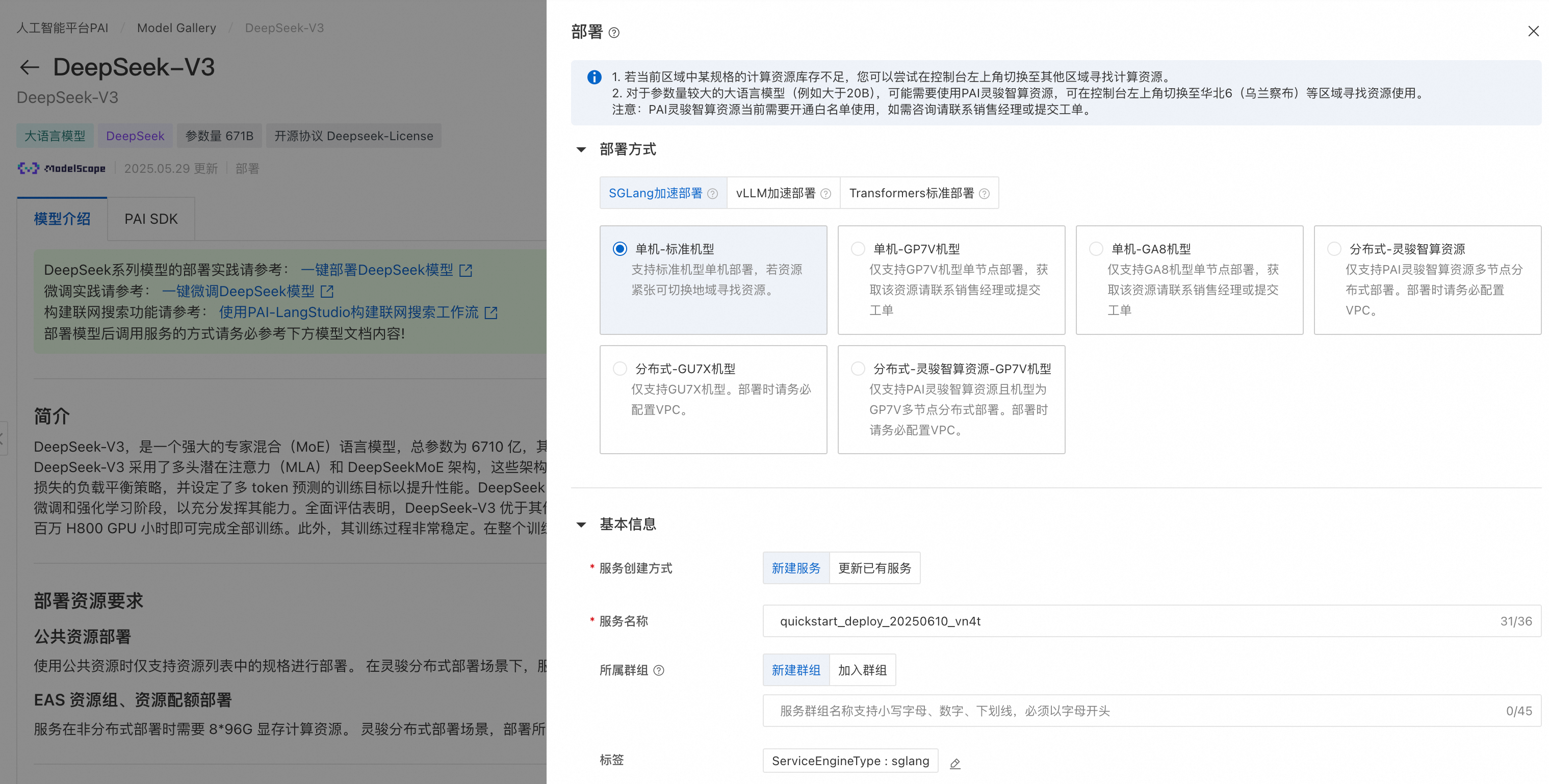
PAI 提供的DeepSeek-V3預置了模型的部署配置信息,可以選擇SGLang 部署/vLLM部署/Transformers部署,用戶僅需提供推理服務的名稱以及部署配置使用的資源信息即可將模型部署到PAI-EAS推理服務平臺。
推理服務同樣支持以OpenAI API兼容的方式調用,調用示例如下:
from openai import OpenAI##### API 配置 #####
openai_api_key = "<EAS API KEY>"
openai_api_base = "<EAS API Endpoint>/v1"client = OpenAI(api_key=openai_api_key,base_url=openai_api_base,
)models = client.models.list()
model = models.data[0].id
print(model)def main():stream = Truechat_completion = client.chat.completions.create(messages=[{"role": "user","content": [{"type": "text","text": "你好,介紹一下你自己,越詳細越好。",}],}],model=model,max_completion_tokens=1024,stream=stream,)if stream:for chunk in chat_completion:print(chunk.choices[0].delta.content, end="")else:result = chat_completion.choices[0].message.contentprint(result)if __name__ == "__main__":main()更多細節可以參考“一鍵部署DeepSeek-V3、DeepSeek-R1模型”。
構建訓練數據
構建SFT訓練數據
您可以按照以下操作步驟,構建SFT訓練數據。用戶可以根據如下輸入數據批量調用教師大模型,輸入數據格式如下所示:
[{"instruction": "xxx"},{"instruction": "xxx"},{"instruction": "xxx"}
]其中,instruction為調用大模型的prompt,由任務模版和實際輸入數據組成。這里,我們給出一個任務模版供您參考,實際內容可以根據業務場景和數據特征進行調整:
你是短視頻文案生成專家,專注于根據視頻原始標題、視頻內容,生成文案的標題和內容。
你的任務是確保文案與視頻核心內容高度匹配,并且吸引用戶點擊。要求
1: 信息匹配度:確保文案準確反映視頻核心看點,禁止出現視頻中未呈現的虛構內容。
2. 情緒契合度:文案情緒需與視頻內容保持一致。嚴肅悲傷類內容不要使用搞笑戲謔風格。
3. 內容規范度:確保句意表達清晰、完整、通順、連貫,沒有出現無意義字符。
4. 嚴格按照JSON格式輸出:
{"title": "","body": ""
}避免出現情況
1. 標題要求在10個漢字以內。
2. 內容要求在30個漢字以內。
3. 禁止標題黨,和過度夸張的表述。
4. 不得出現高敏感內容,或者低俗用語。請嚴格按照JSON格式輸出內容,不要在輸出中加入解析和說明等其他內容。視頻原始標題和視頻內容分別如下所示:給定上述輸入數據,我們可以批量調用教師大模型生成回復,示例代碼如下:
import json
from openai import OpenAI##### API 配置 #####
openai_api_key = "<EAS API KEY>"
openai_api_base = "<EAS API Endpoint>/v1"client = OpenAI(api_key=openai_api_key,base_url=openai_api_base,
)# 獲取模型
models = client.models.list()
model = models.data[0].id
print(model)# 讀取輸入數據
def read_input_data(file_path):with open(file_path, 'r', encoding='utf-8') as file:return json.load(file)# 調用大模型獲取輸出
def get_model_output(instruction):chat_completion = client.chat.completions.create(messages=[{"role": "user","content": [{"type": "text","text": instruction,}],}],model=model,max_completion_tokens=1024,stream=False,)return chat_completion.choices[0].message.content# 處理輸入數據并生成輸出
def process_data(input_data):results = []for item in input_data:instruction = item.get("instruction")output = get_model_output(instruction)results.append({"instruction": instruction,"output": output})return results# 保存輸出數據到文件
def save_output_data(file_path, data):with open(file_path, 'w', encoding='utf-8') as file:json.dump(data, file, ensure_ascii=False, indent=2)def main(input_file_path, output_file_path):input_data = read_input_data(input_file_path)output_data = process_data(input_data)save_output_data(output_file_path, output_data)print("Data processing complete.")if __name__ == "__main__":# 指定你的輸入和輸出文件路徑input_file_path = "input.json"output_file_path = "output.json"main(input_file_path, output_file_path)當運行完上述代碼后,我們得到構造好的SFT訓練數據,格式如下:
[{"instruction": "xxx","output": "xxx"},{"instruction": "xxx","output": "xxx"},{"instruction": "xxx","output": "xxx"}
]為了保證SFT訓練數據集的高質量,我們建議采用如下設置:
- 訓練數據量至少應在3000條以上,而且需要盡可能覆蓋輸入視頻的各種主題;
- 生成文案的任務模版可以按照實際業務需求進行修改,需要根據明確的業務需求,用自然語言精確描述生成的文案要求達到的效果和避免出現的情況;
- 為了保證生成文案的高質量,使用的教師大模型底座參數量需要盡可能高,例如使用滿血版的DeepSeek-V3,一般不需要使用深度思考的模型,例如DeepSeek-R1或QwQ-32B;
- 在輸入中,視頻的內容可以通過OCR、ASR等多種途徑從原始視頻中抽取出來,需要保證抽取出來的內容具有較高的準確性;
- 建議在生成SFT訓練數據集后人工抽樣進行質量校驗,并且根據校驗結果,反復調整調用大模型的任務模版,以達到滿意的效果。
構建DPO訓練數據
如果您需要通過DPO算法繼續優化較小的學生模型,則需要構造用于DPO算法訓練的數據集。我們可以基于構造好的SFT訓練數據進行繼續構造流程。其中,DPO數據格式示例如下所示:
[{"prompt": "xxx","chosen": "xxx","rejected": "xxx"},{"prompt": "xxx","chosen": "xxx","rejected": "xxx"},{"prompt": "xxx","chosen": "xxx","rejected": "xxx"}
]其中,prompt對應SFT訓練數據集的instruction,chosen可以使用SFT訓練數據集的output字段,rejected為DPO算法中提供的低質量文案。在DPO算法的訓練過程中,我們鼓勵大模型生成高質量的chosen文案,懲罰大模型生成類似rejected的文案。因此,我們需要額外生成rejected文案。我們可以同樣采用教師大模型生成rejected文案,利用SFT訓練數據集作為輸入,我們需要改變上文使用的任務模版。這里我們給出一個示例供您參考:
你是視頻文案生成初學者,嘗試根據視頻原始標題、視頻內容生成不夠吸引人的文案標題和內容。
目標是生成邏輯不清、可能誤導、不夠吸引用戶點擊的文案。要求
1. 信息匹配度:不要求準確反映視頻核心看點,甚至可以與視頻內容無關。
2. 情緒契合度:文案情緒可以與視頻內容不一致。
3. 內容規范度:表達可以不清晰、不完整、不通順、不連貫,可以出現無意義字符。
4. 可不用嚴格按照JSON格式輸出。視頻原始標題和視頻內容分別如下所示:我們同樣給出一個批量推理的腳本,生成上述數據,我們假設輸入數據格式與SFT訓練數據集相同,但是instruction字段采用上文生成低質量文案的任務模版:
import json
from openai import OpenAI##### API 配置 #####
openai_api_key = "<EAS API KEY>"
openai_api_base = "<EAS API Endpoint>/v1"client = OpenAI(api_key=openai_api_key,base_url=openai_api_base,
)# 獲取模型
models = client.models.list()
model = models.data[0].id
print(model)# 讀取輸入數據
def read_input_data(file_path):with open(file_path, 'r', encoding='utf-8') as file:return json.load(file)# 調用大模型獲取低質量文案
def get_rejected_output(instruction):chat_completion = client.chat.completions.create(messages=[{"role": "user","content": [{"type": "text","text": instruction,}],}],model=model,max_completion_tokens=1024,stream=False,)return chat_completion.choices[0].message.content# 處理輸入數據并生成輸出
def process_data(input_data):results = []for item in input_data:instruction = item.get("instruction")chosen = item.get("output")rejected = get_rejected_output(instruction)results.append({"prompt": instruction,"chosen": chosen,"rejected": rejected})return results# 保存輸出數據到文件
def save_output_data(file_path, data):with open(file_path, 'w', encoding='utf-8') as file:json.dump([data], file, ensure_ascii=False, indent=2)def main(input_file_path, output_file_path):input_data = read_input_data(input_file_path)output_data = process_data(input_data)save_output_data(output_file_path, output_data)print("Data processing complete.")if __name__ == "__main__":# 指定你的輸入和輸出文件路徑input_file_path = "input.json"output_file_path = "output.json"main(input_file_path, output_file_path)為了保證DPO訓練數據集的高質量,我們建議采用如下設置:
- 訓練數據量至少應在1000條以上,而且需要盡可能覆蓋輸入視頻的各種主題;
- 生成rejected文案的任務模版可以按照實際業務需求進行修改,需要和chosen文案在質量上有明顯的差距,特別可以注重生成chosen文案中避免出現的情況(即負向樣本);
- 為了保證生成文案質量滿足要求,使用的教師大模型底座參數量需要盡可能高,例如使用滿血版的DeepSeek-V3,一般不需要使用深度思考的模型,例如DeepSeek-R1或QwQ-32B;
- 在輸入中,視頻的內容可以通過OCR、ASR等多種途徑從原始視頻中抽取出來,需要保證抽取出來的內容具有較高的準確性;
- 建議在生成DPO訓練數據集后人工抽樣進行質量校驗,并且根據校驗結果,反復調整調用大模型的任務模版,以達到滿意的效果。
通過SFT算法蒸餾訓練較小的學生模型
接下來我們使用EasyDistill算法框架,利用準備好的訓練數據,訓練學生模型。在PAI-DSW中,根據“阿里云人工智能平臺PAI開源EasyDistill框架助力大語言模型輕松瘦身”一文安裝EasyDistill算法包后使用如下命令進行SFT模型訓練:
python easydistill/kd/train.py --config=sft.json其中,sft.json為SFT蒸餾訓練的配置文件,示例如下:
{"job_type": "kd_black_box_api","dataset": {"labeled_path": "sft_train.json","template" : "chat_template_kd.jinja","seed": 42},"models": {"student": "model/Qwen/Qwen2.5-0.5B-Instruct/"},"training": {"output_dir": "result_sft/","num_train_epochs": 3,"per_device_train_batch_size": 1,"gradient_accumulation_steps": 8,"save_steps": 1000,"logging_steps": 1,"learning_rate": 2e-5,"weight_decay": 0.05,"warmup_ratio": 0.1,"lr_scheduler_type": "cosine"}
} 其中,sft_train.json為SFT訓練數據集,model/Qwen/Qwen2.5-0.5B-Instruct/為學生模型路徑,這里以Qwen2.5-0.5B-Instruct為示例,result_sft/為模型輸出路徑。您可以根據實際需要,在training字段中調整訓練使用的超參數。
通過DPO算法繼續優化較小的學生模型
由于SFT訓練過程中提供給學生模型唯一的正確答案,因此這種訓練存在兩個限制條件:一為模型的泛化能力有限,二為缺乏更加細粒度的模型對齊。DPO算法通過提供chosen和rejected的模型回復,進一步提升模型的對齊能力。根據準備好的DPO訓練數據,我們在SFT訓練完的模型Checkpoint基礎上,使用EasyDistill的如下命令,進行DPO模型訓練:
python easydistill/rank/train.py --config=dpo.json其中,dpo.json為DPO蒸餾訓練的配置文件,示例如下:
{"job_type": "rank_dpo_api","dataset": {"labeled_path": "dpo_train.json","template" : "chat_template_kd.jinja","seed": 42},"models": {"student": "result_sft/"},"training": {"output_dir": "result_dpo/","num_train_epochs": 3,"per_device_train_batch_size": 1,"gradient_accumulation_steps": 8,"save_steps": 1000,"logging_steps": 1,"beta": 0.1,"learning_rate": 2e-5,"weight_decay": 0.05,"warmup_ratio": 0.1,"lr_scheduler_type": "cosine"}
}其中,dpo_train.json為SFT訓練數據集,result_sft/為SFT訓練之后的學生模型路徑,result_dpo/為模型輸出路徑。您可以根據實際需要,在training字段中調整訓練使用的超參數。



進程的概念)



)






?)


)

