前言
在上一章我們知道了什么是進程,并簡單了解了PCB。
本文我們將繼續深入學習進程概念相關知識點:
- 學習進程狀態,學會創建進程,掌握僵尸進程和孤兒進程,及其形成原因和危害
- 了解進程調度,Linux進程優先級,理解進程競爭性與獨立性,理解并行與并發
一、查看進程
查看進程一般有如下兩種方式:
- 使用ps指令查看進程
- 通過/proc系統目錄查看
0. 準備工作
- 編寫一個簡單的程序,如下:
#include<stdio.h>
#include<unistd.h>int main()
{while(1){printf("我是一個進程!\n");sleep(1);}return 0;
}
- 編寫Makefile
myprocess:myprocess.cgcc $^ -o $@
.PHONY:clean
clean:rm -rf myprocess
- 執行make命令,生成可執行程序myprocess
- 運行myprocess,這個時候myprocess就是一個進程
1. 使用ps指令查看進程
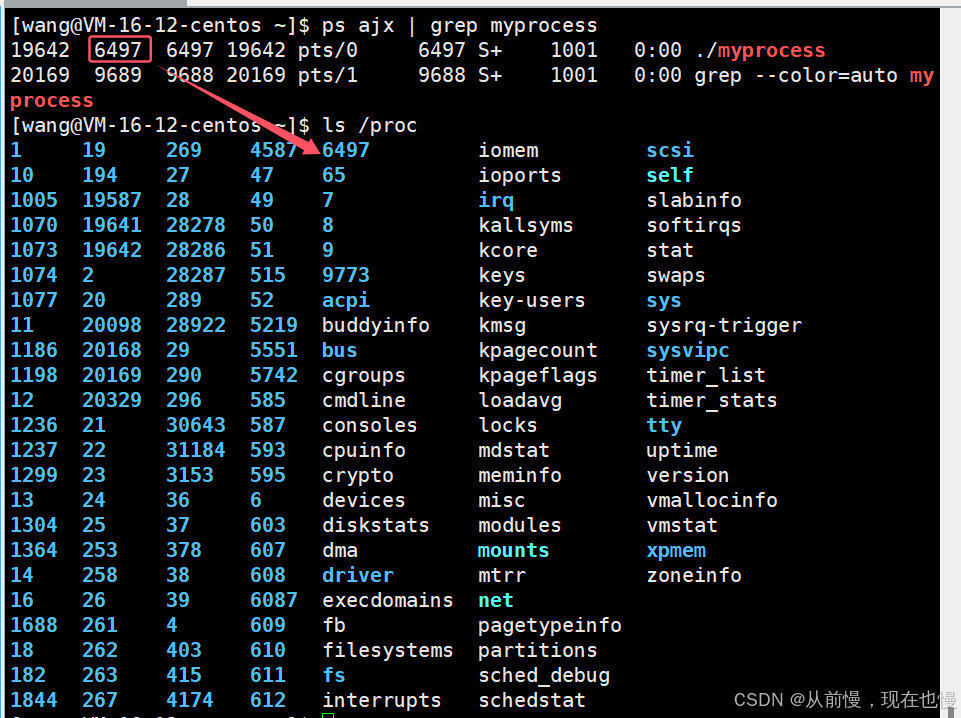
查看所有進程,指令如下:
ps ajx我們一般不單獨使用ps ajx,因為它會打印所有的進程。我們一般會使用grep篩選出我們想查看的進程,指令如下:
# 篩選包含myprocess關鍵字的所有進程 ps ajx | grep myprocess
問題1:為什么會出現grep的進程?——系統指令也是一個可執行程序,執行時當然也是一個進程!
問題2:如何只顯示myprocess進程,指令如下:ps ajx | grep myprocess | grep -v grep
問題3:這些列是什么意思,我們篩選進程之前先打印一下它的第一行列名稱,指令如下:ps ajx | head -1 && ps ajx | grep myprocess
- 想要執行多條指令,可以使用&&或分號;來連接執行(注意:1. 必須都執行成功,不能只執行成功一條指令;2. 執行順序從左到右。)
- PID:每一個進程在系統中要被管理起來,必須要有進程的id,即進程的唯一標識符(進程id并不是不變的,因為每重新啟動一次程序,重新分配進程id)
- PPID:父進程id
- COMMAND:這個進程運行的時執行的指令
tip:我們可以通過進程的PID,結束進程,指令如下:(ctrl+c也可以結束進程)kill -9 PID



2. 通過/proc目錄查看進程
在Linux系統中,/proc目錄是一個非常特殊的目錄,它是一個虛擬文件系統,主要用于提供系統運行時的進程信息和內核參數。/proc目錄的內容并不是存儲在磁盤上的,而是由內核動態生成的,反映了系統當前的運行狀態。
如下圖,我們ls查看/proc目錄:
如圖我們可以看到再proc中有很多文件,現在我們只關注藍色的文件。這些藍色的文件都是目錄,并且我們發現這些藍色文件的名稱基本都是數字!
這些數字是什么呢——這些數字就是當前進程的pid。
在proc目錄中默認給進程創建一個以它pid為名稱的目錄,這個目錄中保存該進程的大部分屬性!
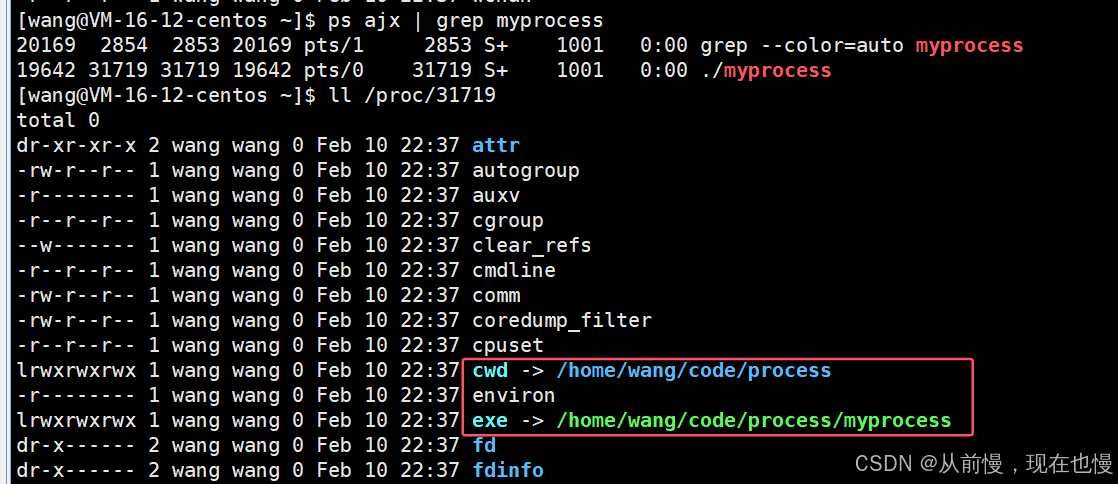
在這個目錄中保存了很多該進程的消息,如圖我們現在需要關注其中兩個消息:
- exe:exe鏈接文件指向當前進程的可執行文件路徑
- cwd:current work directory——當前進程的工作目錄。例如我們touch text,為什么就在當前目錄下創建了?——因為touch執行的時候也是一個進程,在進程中有cwd屬性,創建文件的時候會把cwd拼接到text前面,即cwd/text,所以touch創建的文件就在當前目錄下
注:當myprocess進程停止后,我們就不能再通過ll /proc/pid 查到它的進程
小結:
- 這里我們只需要記住proc目錄動態保存了系統中所有進程的信息。
- touch創建文件的時候,默認在當前目錄下創建,是因為進程中有一個cwd屬性(當前進程的工作目錄)

二、通過系統調用獲取進程標識符(進程id)
- 進程id(PID)
- 父進程id(PPID)
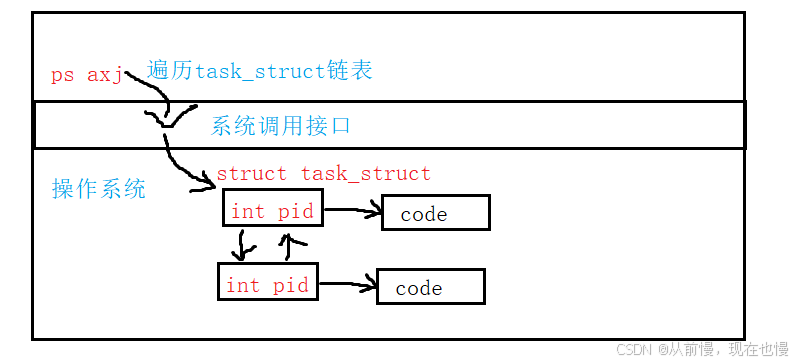
- ps ajx指令打印所有進程的相關常見屬性,其本質是遍歷task_struct雙向循環鏈表,將task_struct的相關屬性拿出來格式化打印
- 問題:我們怎樣可以自己拿到自己的進程id?
首先我們知道進程id存在于task_struct,而task_struct存在于操作系統中,其次我們知道操作系統不可以直接訪問,必須通過系統調用接口。所以我們必須通過系統調用接口才能訪問進程id!
1. 通過系統調用接口獲取進程id
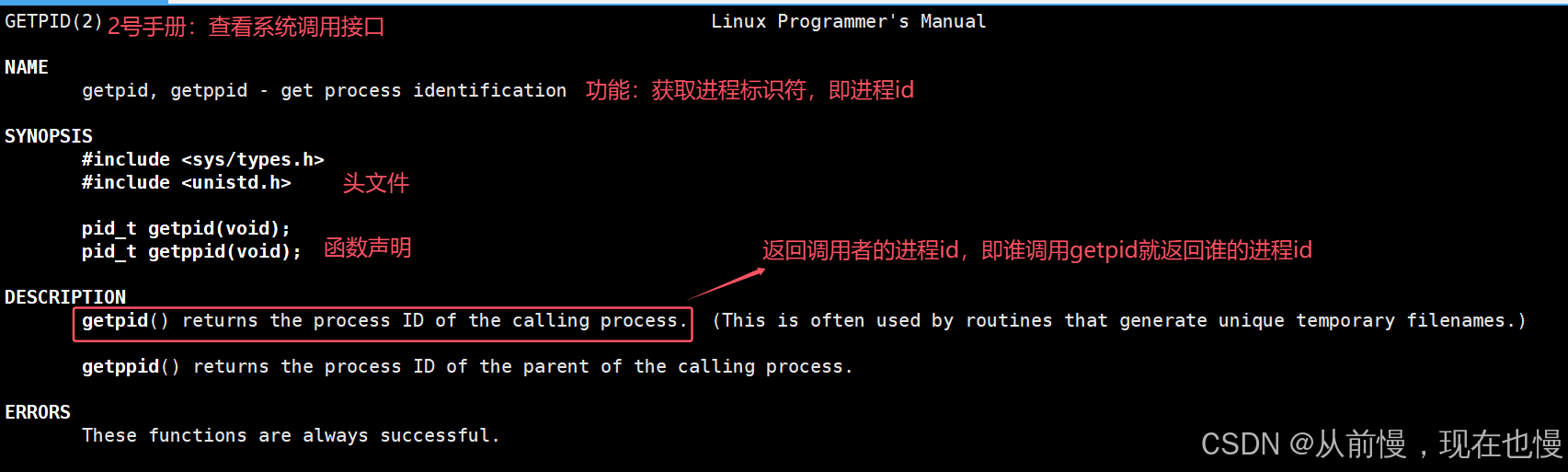
- getpid():系統調用接口,獲取進程id
- getppid():系統調用接口,獲取父進程id
- 我們可以通過man手冊查看getpid的使用說明:
man getpid
getpid的使用:
- 代碼示例:
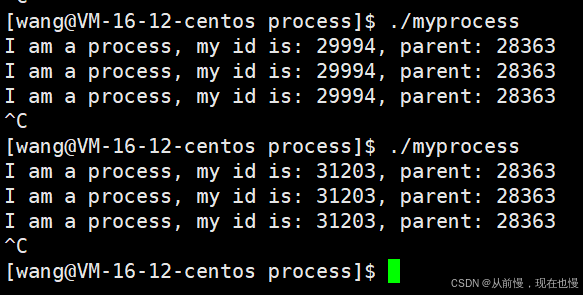
#include<stdio.h> #include<unistd.h> #include <sys/types.h>int main() {while(1){printf("I am a process, my id is: %d, parent: %d\n", getpid(), getppid());sleep(1);}return 0; }
- 監測腳本,每隔1s打印一次進程屬性,指令如下:
while : ; do ps ajx | head -1 ; ps ajx | grep myprocess | grep -v grep; echo "--------"; sleep 1; done
- 我們運行發現:每重新啟動一次程序,都要重新分配進程id,但是它的父進程id一直不變!(tip:每一次重新登錄xshell的時候,我們的系統會單獨再創建一個bash進程)
問題:這個父進程是什么?查看指令如下:ps ajx | head -1 && ps ajx | grep 28363
查看發現這個父進程就是bash命令行解釋器,命令行解釋器它的核心是獲取用戶的輸入,然后幫助用戶進行命令行解釋。
在命令行運行的所有指令都是進程,他們的父進程都是bash!
總結:
- 在我們登錄xshell的時候,系統會為我們創建一個bash進程,即幫我們創建好一個命令行解釋器的進程,幫我們在顯示器中打印對話框終端
- 我們在命令行中輸入的所有指令,最后都是bash進程的子進程
- bash進程只負責命令行解釋,具體執行出問題只會影響它的子進程,這就是為什么在終端中我們運行的進程他們的父進程id一直不變的原因。

2. 小結
- 進程關系重點維護父子進程,所以沒有母親進程,爺爺進程
- getpid獲取自己進程的id。getppid獲取父進程id
- 系統調用接口的使用和使用C接口一樣,直接調用即可
- task_struct屬性標識符(進程id):描述本進程的唯一標識符,用來區別其他進程
- 我們可以根據進程id殺掉一個進程(kill -9 pid)
- 在終端重新啟動程序,進程id會變化,但它的父進程id一般不變
- 在終端執行的所有指令他們的父進程都是bash!
三、通過系統調用創建進程-fork
- 問題:創建進程的方式有哪些?
- bash創建進程:我們已經知道了在命令行執行指令,系統會為我們創建該指令的進程
- 自己手動創建進程:使用系統調用接口fork,自己手動創建進程
1. 自己手動創建進程-fork
使用man手冊,查閱fork,指令如下:
man fork
- 庫函數:#include<unistd.h>
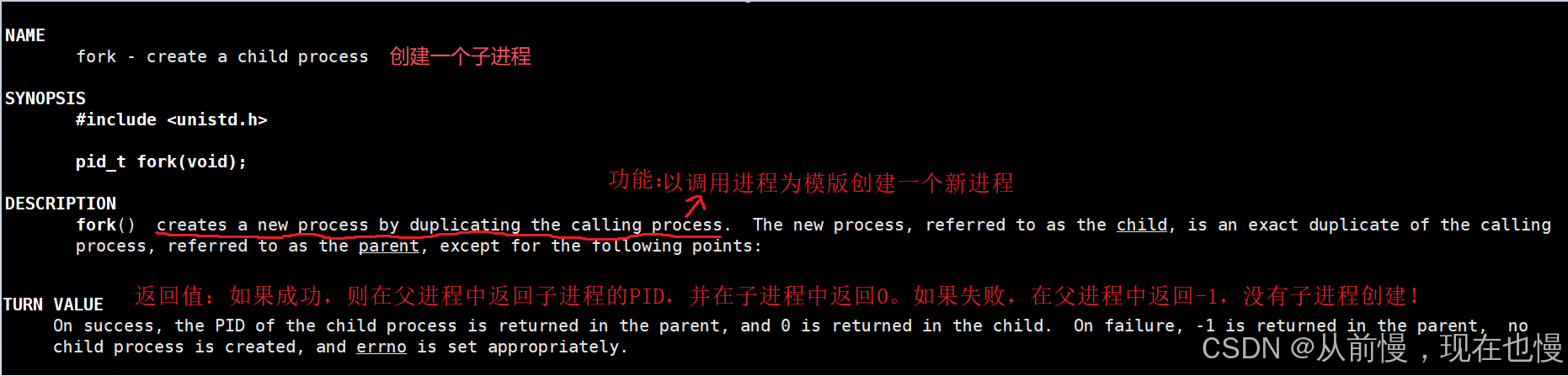
- 函數聲明:pid_t fork(void);
- 功能:以調用進程為模版創建一個新進程
- 返回值:如果成功,則在父進程返回子進程的pid,并在子進程中返回0;如果失敗,則在父進程中返回-1,沒有子進程創建。
fork的使用示例:
#include<stdio.h>
#include<unistd.h>
#include <sys/types.h>int main()
{printf("begin: 我是一個進程:pid: %d, ppid: %d\n",getpid(), getppid());//創建一個子進程pid_t id = fork();//如果創建成功,則在父進程中返回子進程的pid,并在子進程中返回0if(0 == id){//子進程while(1){printf("我是子進程,pid:%d, ppid: %d\n",getpid(), getppid());sleep(1);}}else if(id > 0){//父進程while(1){//父進程printf("我是父進程, pid: %d, ppid: %d\n",getpid(), getppid());sleep(1);}}else{//error}return 0;
}運行結果:
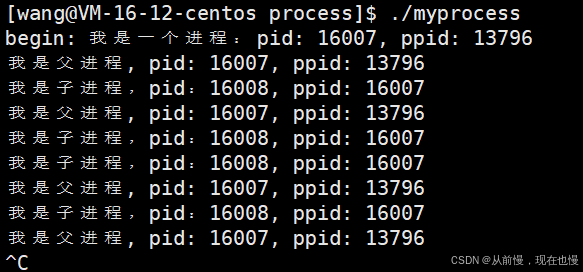
問題:按照我們之前所學的知識,代碼從上往下執行,如上代碼運行不應該一直打印id為0的代碼塊嗎,為什么實際運行結果是交叉打印子進程和父進程的代碼塊?
正常情況下我們的執行流是從上往下執行的,但調用fork之后,它會幫我們創建子進程,它會給子進程返回0,父進程中返回子進程id,所以fork之后代碼就變成了兩個執行流,一個執行流執行子進程的代碼,一個執行流執行父進程的代碼。
tip:fork以當前調用進程為模版創建一個子進程!
理解fork:我們需要解決以下幾個問題
問題1:fork函數,究竟在干什么?
- fork以父進程為模版創建一個子進程
- fork之后,父子進程代碼共享,數據不共享,采用寫時拷貝。
問題2:為什么fork要給子進程返回0,給父進程返回子進程pid?
- 返回值為什么不同:因為fork之后的代碼父子共享,所以fork返回不同的返回值,是為了區分,讓不同的執行流,執行不同的代碼塊。
- 為什么子進程返回0,父進程返回子進程pid:
- 父進程可以有多個子進程,而子進程只有一個父進程。例如:在現實生活中,一般一個父親可以有多個子女,而一個子女只有一個父親。
- 父進程將來要對子進程做控制,為了區分不同的子進程,所以在父進程中必須返回子進程的pid,用來標定子進程的唯一性。
- 而子進程不一樣,它的父進程只有一個通過getppid就可以獲取,所以只需要返回0知道子進程創建成功即可。
問題3:一個函數是如何做到返回兩次的?
- 一個函數在返回之前,它的核心工作一定都做完了,所以fork的return語句屬于父子進程共享的,父進程返回一次,子進程返回一次
問題4:一個變量怎么會有不同的內容?
- 因為一、fork之后,父子進程代碼共享;二、fork返回的時候,父子進程返回值不一樣,發生寫時拷貝。所以一個變量會有不同的內容!
補充:如果父子進程被創建好,fork之后,誰先運行?
- 誰先運行,由調度器決定,是不確定的
- 調度器讓每個進程公平的被調度


2. 小結
- fork創建子進程
- 父子進程代碼共享,數據不共享寫時拷貝
- fork之后通常要用if進行分流,讓父子進程做不同的事情
- bash通過fork創建子進程,fork之后,父進程負責命令行解釋,子進程負責解釋指令
四、進程狀態
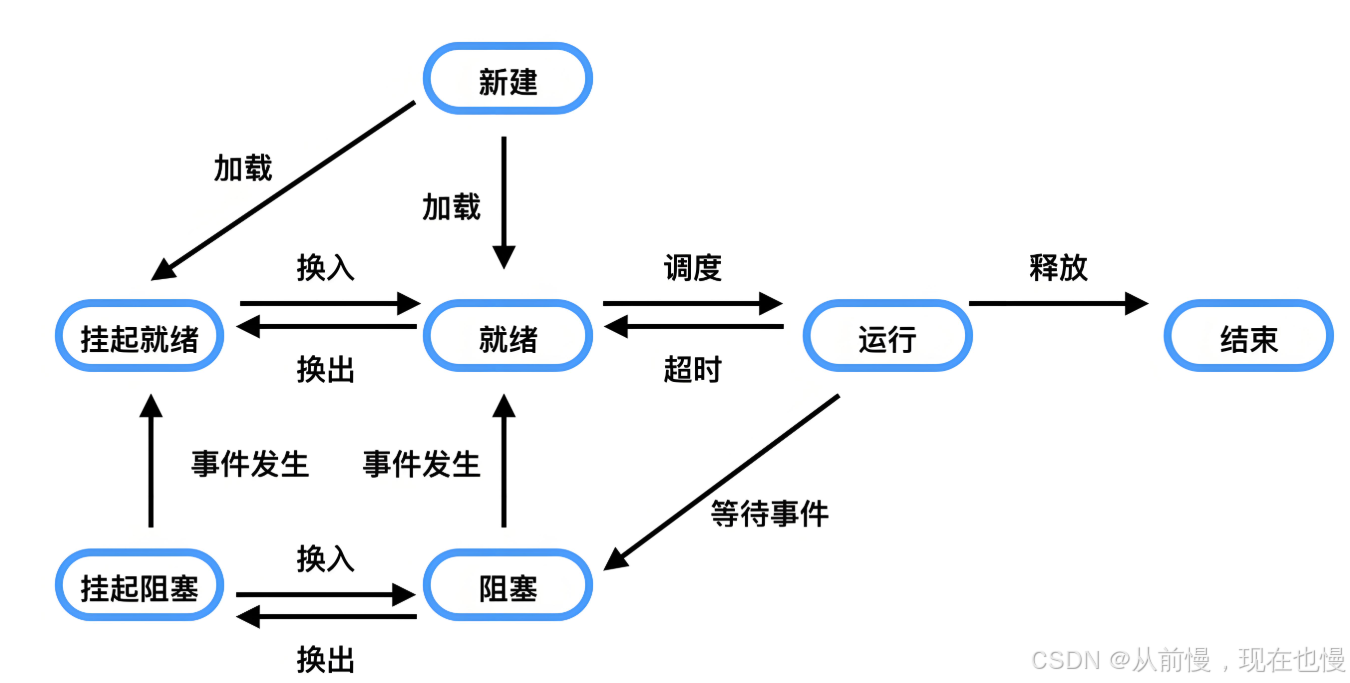
1. 操作系統的進程狀態
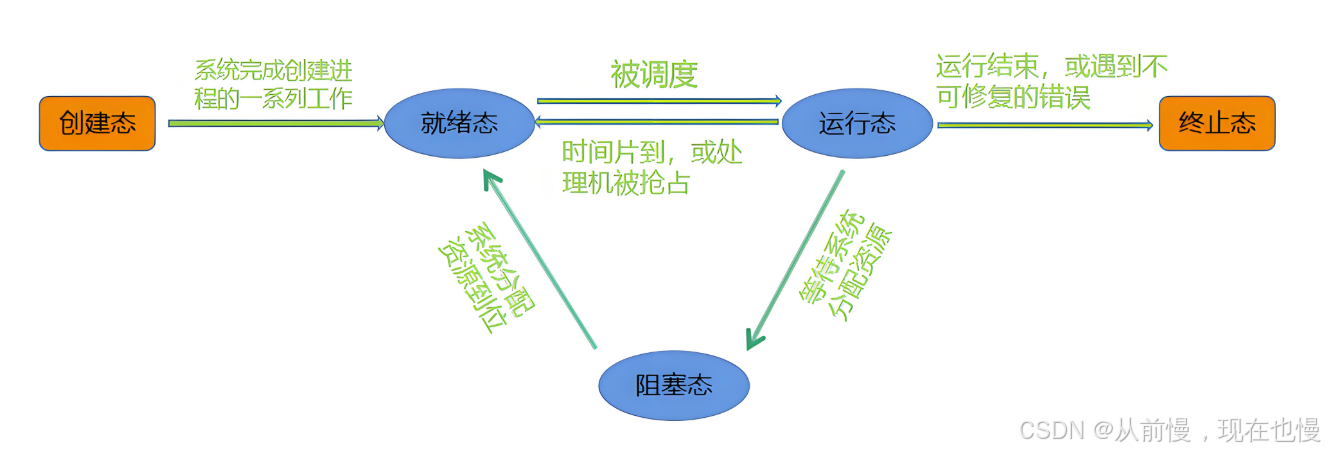
如下我們百度獲取的兩張進程狀態圖:
進程狀態:進程狀態反映進程執行過程的變化。這些狀態隨著進程的執行和外界條件的變化而轉換。
- 在三態模型中,進程狀態分為三個基本狀態,即運行態,就緒態,阻塞態。
- 在五態模型中,進程分為新建態、終止態,運行態,就緒態,阻塞態。
- 下面我們只重點學習運行、阻塞、掛起這三個狀態
1、運行態
- 對于操作系統,我們的任何進程運行時,都需要消耗CPU資源
- 所有運行在系統里的進程都以task_struct雙向鏈表的形式存在操作系統里
- 在操作系統中想要運行的進程是非常多的,而CPU資源是少的,所以進程需要去競爭CPU的資源,但調度器需要讓每一個進程都被合理的使用,所以每個CPU都需要維護一個運行隊列struct runqueue
- 只要鏈入運行隊列的進程,所處的狀態就叫做運行態(R態)。 理解:只要處于運行隊列的進程,都表示我已經準備好了,隨時可以被調度!
- 問題:一個進程只要把自己放到CPU上開始運行了,是不是就一直要執行完畢,才能自己放下來?
不是,因為每一個進程都有一個叫做時間片的概念,例如一個進程最多在CPU上運行10ms,時間到了,CPU就會把進程放下來!——并發執行:在一個時間段內,所有的進程都會被執行!- 進程切換:在CPU上有大量的把進程拿上去、放下來的動作
2、阻塞態
- 進程的阻塞狀態?是指進程因等待某些資源或事件而暫時無法繼續執行的狀態。例如:當進程執行I/O操作時,如果I/O設備忙,進程會進入阻塞狀態,等待I/O操作完成。
- 阻塞態的特點:
- 暫停執行?:處于阻塞狀態的進程會暫停執行,直到所等待的事件或資源變得可用。
- ?隊列管理?:通常,處于阻塞狀態的進程會被排成一個隊列,有的系統會根據阻塞原因的不同將進程排成多個隊列。?
- 每一個外設都有一個等待隊列,在等待隊列中的進程狀態我們叫做阻塞狀態
- 在阻塞狀態下,進程無法運行
3、掛起態
- 這是一種極端情況,通常發生在內存資源嚴重不足時,操作系統會將不常用的進程的代碼和數據移動到磁盤的Swap分區,僅保留PCB在內存中。?
- 掛起態的換出和換入:
- 換出:將進程的代碼和數據移動到磁盤的swap分區
- 換入:將進程的代碼和數據從swap中移動到操作系統
- 掛起態在保證進程的正常調度的情況下,節省了內存資源
- 一般現在的掛起都是阻塞掛起(也有其他掛起),一般掛起了都是阻塞的,但阻塞不一定是掛起的
- 系統中是否存在該進程,只取決于進程的PCB是否在內存中(理解:一個人是否是學生,不取決你是否在校,取決于你是否存在學校的學生系統中)
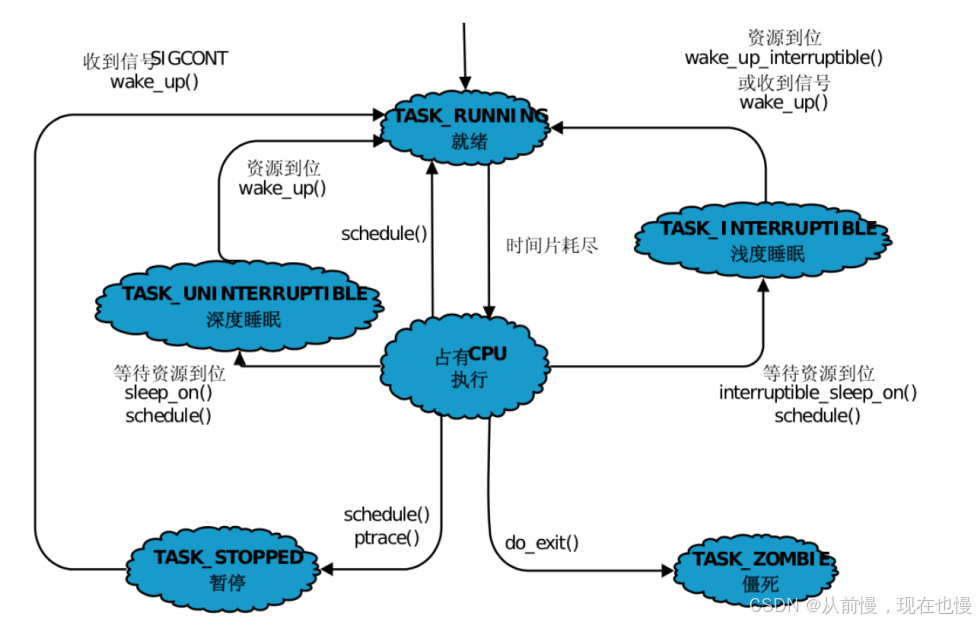
2. Linux操作系統的進程狀態
不同的進程狀態就決定了該進程當下要做什么事情。例如:
- 當前我是R狀態,我接下來就是要被調度運行了;
- 當前我是阻塞態,我接下來就要等條件就緒等設備準備好,設備準備好之后我要把我的狀態改為運行態投遞到運行隊列中,然后被CPU調度運行;
- 當前我是掛起態,我首先要做的就是將swap盤中的代碼和數據換入到內存
為了弄明白正在運行的進程是什么意思,我們需要知道進程的不同狀態。一個進程可以有幾個狀態(在Linux內核里,進程有時候也叫做任務)
在Linux內核源代碼中進程狀態具體分為如下幾種:/* * The task state array is a strange "bitmap" of * reasons to sleep. Thus "running" is zero, and * you can test for combinations of others with * simple bit tests. */ static const char * const task_state_array[] = { "R (running)", /* 0 */ "S (sleeping)", /* 1 */ "D (disk sleep)", /* 2 */ "T (stopped)", /* 4 */ "t (tracing stop)", /* 8 */ "X (dead)", /* 16 */ "Z (zombie)", /* 32 */ };Linux狀態變化圖:
2.1 R運行態
- R運行狀態(running):R狀態就是Linux中的運行狀態,運行狀態并不意味著進程一定在運行中,它表明進程要么是在運行中要么在運行隊列里。
- 注意:不要用你的感受去于CPU的速度做對比,因為CPU的速度太快了。
- 例如:我們寫一個C程序死循環打印,將其運行之后,猜測它是什么狀態
#include<stdio.h>int main()
{while(1){printf("hello\n");}return 0;
}
運行該程序后,我們查看該進程狀態:
以我們的感受,我們看到該進程一直在打印運行,但是查看該進程的狀態卻是S狀態,不是R狀態!這是為什么呢?
修改代碼,我們不再打印,僅僅是一個空語句死循環。此時我們再運行程序,查看進程狀態就是R狀態了。
需要一直打印的進程狀態是S,不需要打印的進程狀態是R,這是為什么——不要用我們的感受去揣測CPU的速度,因為打印是需要訪問顯示器設備的,當需要一直打印的時候他就需要頻繁的去訪問顯示器,顯示器可能并不是可以直接寫入的狀態,所以進程有很大的概率都是在等待顯示器就緒,所以進程狀態大概率是阻塞態S
tip:
- 我們看到R+后面有一個+,這表示我們當前進程在前臺運行。(前臺:我們此時運行了的程序,我們的bash解釋器就不再運行了,輸指令沒有反應了)
- 運行程序的時候在后面空格加&,就代表進程在后臺運行。注意:處于后臺運行的進程【ctrl + C】就不能結束進程了,只能通過kill -9 pid結束進程。

2.2 S睡眠狀態&D磁盤休眠狀態
S睡眠狀態(sleeping): 意味著進程在等待事件完成(這里的睡眠有時候也叫做可中斷睡眠(interruptible sleep))。
因為CPU的速度很快,所以大多數進程狀態都處于等待事件完成,即S態。
在Linux操作系統中的S態對應的就是操作系統中的阻塞狀態。
在Linux操作系統中阻塞狀態不僅僅有S這樣的淺度睡眠狀態,還有D這樣的深度睡眠狀態!
D磁盤休眠狀態(Disk sleep)有時候也叫不可中斷睡眠狀態(uninterruptible sleep),在這個狀態的進程通常會等待IO的結束。
淺度睡眠:可以被喚醒!——理解:隨時可以響應外部的變化。例如可以被kill -9 pid殺掉
深度睡眠:磁盤休眠,讓進程在等待磁盤寫入完畢期間,要保證這個進程不能被任何人殺掉!例如:現在有一個進程,假設他要向磁盤寫1GB數據,此時磁盤需要花時間將這1GB數據寫入,在這一段時間里進程一直在等待磁盤寫入完畢返回響應,響應寫入成功或寫入失敗。問題:假設此時OS壓力很大,內存嚴重不足,OS會殺掉一些它認為不重要的進程,這會OS發現有一個進程一直在等待磁盤寫入,自己一點事不干,就把它殺掉了。但是這會出問題了磁盤寫入數據失敗,返回響應的時候進程又被殺掉了,數據就被丟失了。那數據丟失是誰的責任,找誰負責——1、找OS?OS有管理軟硬件資源權力,并且OS是在內存嚴重不足的情況下殺掉的進程,所以數據丟失與OS無關,OS的職責就是保證系統不掛,并不是保證數據不丟失!2、找磁盤?磁盤就是一個跑腿的,磁盤的工作模式就是如此,磁盤寫數據的時候,就是需要進程等待磁盤返回響應。所以數據丟失不關磁盤,磁盤的工作模式就是如此。3、找進程?進程是被OS殺掉的,不是進程自己跑路了,不在哪里等待的,所以丟失數據也不關進程的事。
淺度睡眠,可以接收外部請求可以被殺死;深度睡眠,不接收任何外部請求不可以被殺死!
當用戶都可以查看到D狀態時,說明操作系統的壓力很大了,快要崩潰了!
2.3 停止/暫停狀態-T/t
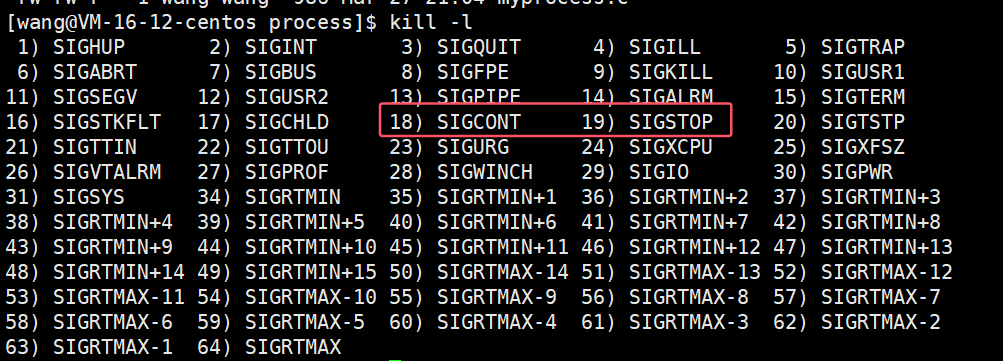
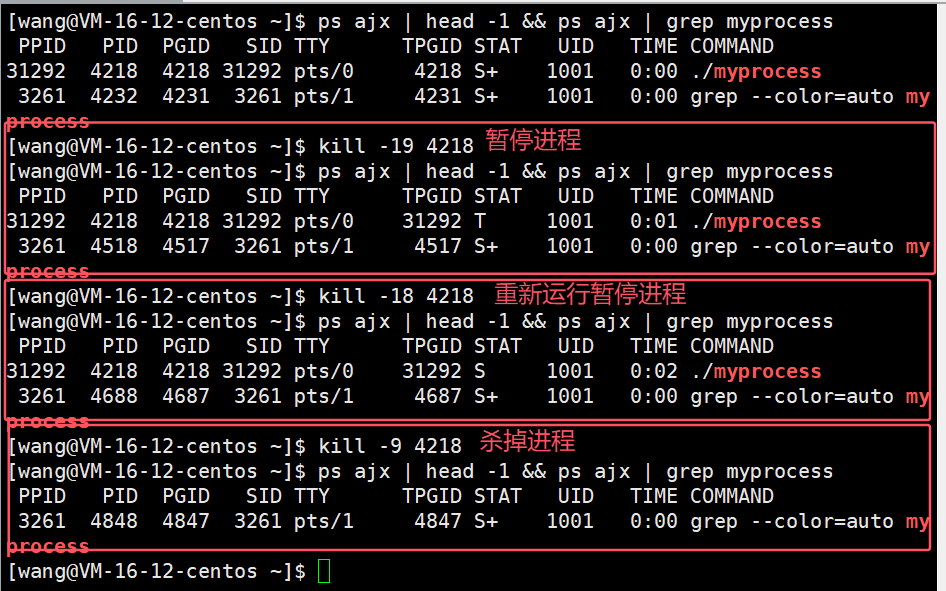
T: 可以通過發送 SIGSTOP 信號給進程來停止(T)進程。這個被暫停的進程可以通過發送 SIGCONT 信號讓進程繼續運行。
進程中有一個概念叫做信號,在之前我們就使用過9號信號殺掉進程,我們可以通過以下指令查看進程信號有哪些:kill -l
我們可以使用19號信號暫停進程,如果想重新將暫停的進程運行起來可以使用18號信號。
暫停進程及恢復進程,進程會變成后臺進程。
S休眠狀態和T暫停狀態有區別嗎——有,S一定是在等待某種資源,但T可能在等待某種資源也可能并沒有等待某種資源只是單純的控制進程暫停
gdb控制進程暫停——gdb調試
2.4 X死亡狀態
X死亡狀態(dead):這個狀態只是一個返回狀態,你不會在任務列表里看到這個狀態。因為當進程結束時,CPU會回收其資源,包括進程控制塊(PCB)和代碼數據等?
Linux中的X死亡態對應操作系統中的終止態。
2.5 Z僵尸狀態
2.5.1 僵尸進程
一個進程在死亡之后,并不會直接進入X死亡狀態,而是進入Z僵尸狀態
僵死狀態(Zombies)是一個比較特殊的狀態。當進程退出并且父進程(使用wait()系統調用,后面講)沒有讀取到子進程退出的返回代碼時就會產生僵死(尸)進程
理解:在電影之中我們看到發生命案的時候,都是首先警察來查明死因,是正常死亡還是非正常死亡,確認了死因之后才能通知家屬來把人帶走。
查明死因這個時間段所處的狀態就是僵尸狀態,確定死因進入回收所處的狀態就是死亡狀態。
僵死進程會以Z僵尸狀態保持在進程表中,并且會一直在等待父進程讀取退出狀態代碼。
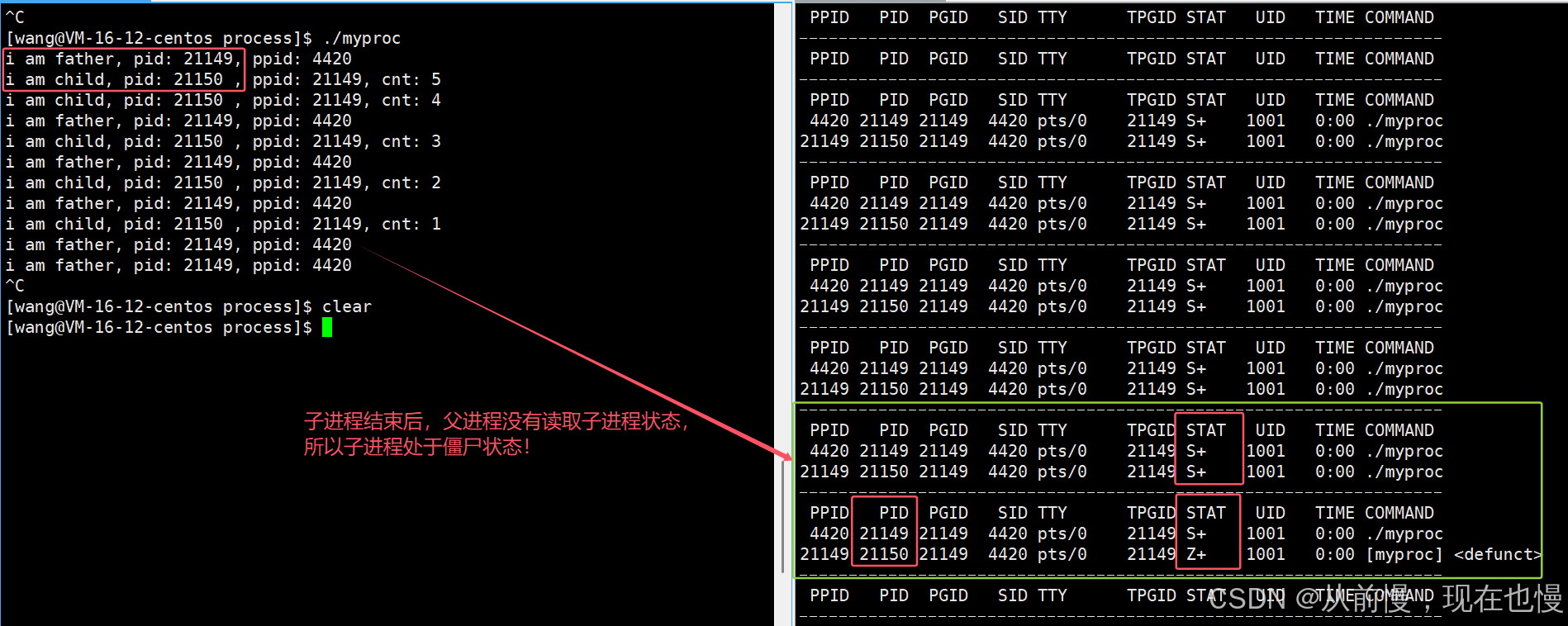
所以,只要子進程退出,父進程還在運行,但父進程沒有讀取子進程狀態,子進程進入Z狀態
僵尸進程代碼示例:
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>int main()
{pid_t id = fork();//子進程結束后,父進程沒有主動回收子進程信息if(id == 0){int cnt = 5;while(cnt--){printf("i am child, pid: %d, ppid: %d, cnt: %d\n",getpid(), getppid(), cnt);sleep(1);}exit(0);}else{while(1){printf("i am father, pid: %d, ppid: %d\n", getpid(), getppid());sleep(1);}}return 0;
}
監測進程狀態:
while : ; do ps ajx | head -1 ; ps ajx | grep myprocess | grep -v grep; echo "--------"; sleep 1; done
進程一般退出的時候,如果父進程沒有主動回收子進程信息,子進程會一直讓自己處于Z狀態,進程的相關資源尤其是task_struct結構體不能被釋放!
2.5.2 僵尸進程的危害
- 進程的退出狀態必須被維持下去,因為他要告訴關心它的進程(父進程),你交給我的任務,我辦的怎么樣了。可父進程如果一直不讀取,那子進程就一直處于Z狀態!
- 維護退出狀態本身就是要用數據維護,也屬于進程基本信息,所以保存在task_struct(PCB)中,換句話說,Z狀態一直不退出,PCB一直都要維護!
- 那一個父進程創建了很多子進程,就是不回收,就會造成內存資源的浪費!因為數據結構對象本身就要占用內存,想想C中定義一個結構體變量(對象),是要在內存的某個位置進行開辟空間!
- 總結:如果進程一直處于僵尸狀態,那這個進程的資源會被一直占用,此時就會造成內存泄漏!
3. 孤兒進程
子進程處于僵尸狀態,殺掉父進程時,我們發現父子進程都查不到了。
問題1:父進程不僵尸狀態嗎?
- 不是,他被bash回收了,任何的父進程只對它的子進程負責。
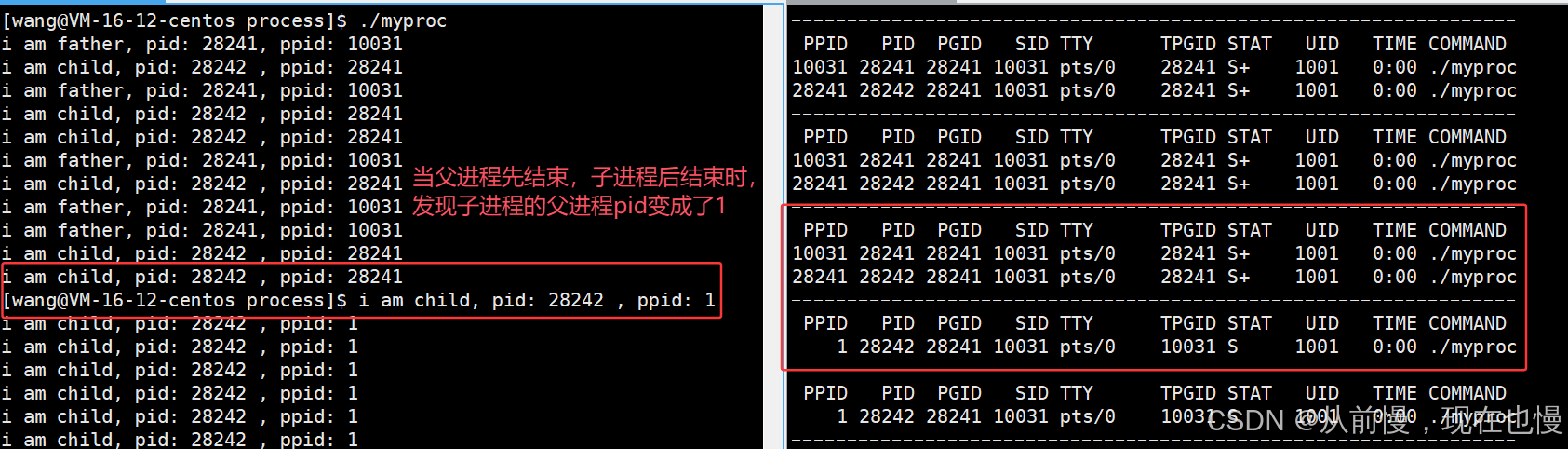
問題2:父進程如果提前退出,那么子進程后退出,進入Z之后,子進程如何處理呢?#include<stdio.h> #include<unistd.h> #include<stdlib.h>int main() {pid_t id = fork();//父進程提前結束,子進程后結束if(id == 0){int cnt = 100;while(cnt--){printf("我是子進程,pid:%d, ppid: %d\n", getpid(), getppid());sleep(1);}exit(0);}else{int cnt = 5;while(cnt--){printf("我是父進程,pid:%d, ppid: %d\n", getpid(), getppid());sleep(1);}}return 0; }
- 父進程先退出,子進程就稱之為“孤兒進程”
- 孤兒進程被1號init進程領養,當然要有init進程回收嘍。(1號進程就是我們操作系統本身)
父子進程,如果父進程先退出,子進程的父進程就會被改成1號進程(操作系統),父進程是1號進程——孤兒進程!該進程被系統領養!
問題:為什么要被領養?
因為孤兒進程未來也會退出,也要被釋放
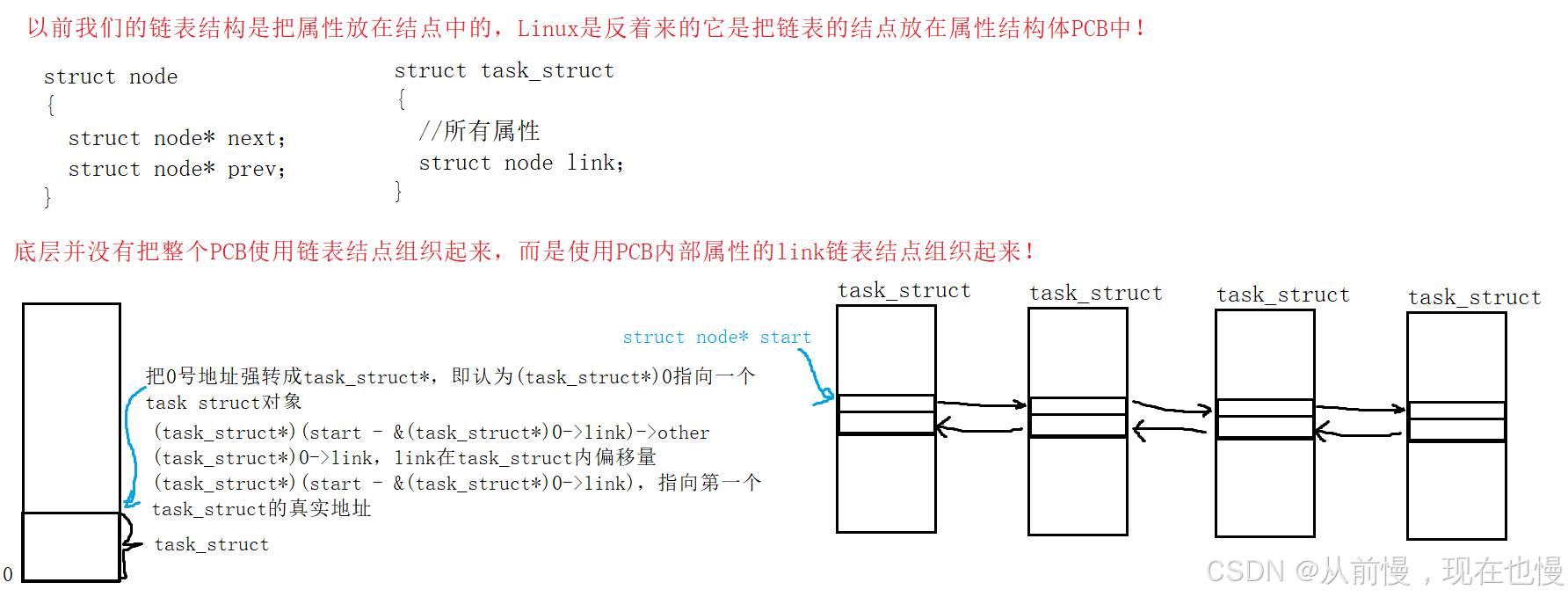
4. 補充:task_struct的組織
進程具有父子關系,一個父進程可以有多個子進程,所以Linux中進程PCB結構是一顆多叉樹。
Linux中對于PCB結構體的組織有多種,是怎么做的呢——在PCB結構體中添加鏈接屬性字段,例如雙向循環鏈表的組織
五、進程優先級
1. 基本概念
問題1:優先級是什么?
- 權限決定能不能,優先級是已經能了決定誰先誰后
- 優先級:對于資源的訪問,誰先訪問,誰后訪問
問題2:為什么要存在優先級?
- 因為資源是有限,進程是多個的,所以注定了進程之間是競爭關系!——競爭性
- 因為操作系統必須保證大家良性競爭,所以要確認優先級
- 如果我們進程長時間得不到CPU資源,那該進程的代碼長時間無法得到推進——進程的饑餓問題
總結:
- CPU資源分配的先后順序,就是指進程的優先權(priority)
- 優先權高的進程有優先執行權利。配置進程優先權對多任務環境的Linux很有用,可能改善系統性能(注:不要隨便改變進程的優先級,因為只有調度器可以最公平的幫你調度你的進程)
- 還可以把進程運行到指定的CPU上,這樣一來,把不重要的進程安排到某個CPU,可以大大改善系統整體性能
問題3:Linux優先級是怎么做的?
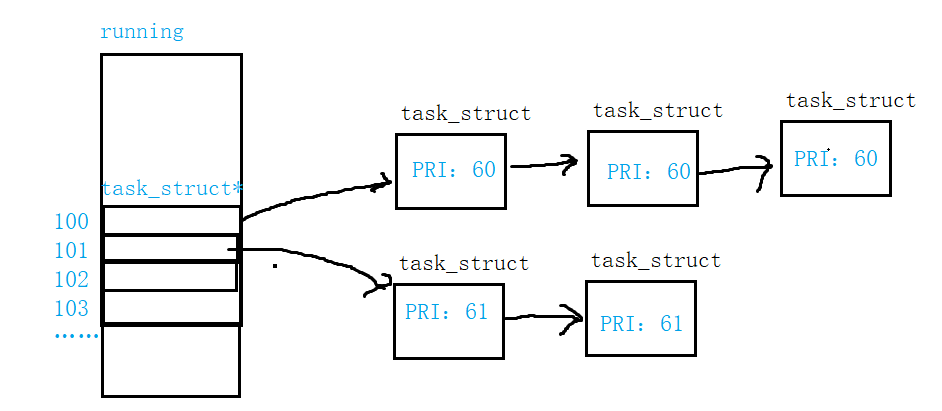
- 在運行隊列中定義了兩個類型為task_struct*的指針數組
- 這個指針數組的下標對應著進程的優先級,我們根據進程的優先級把進程的PCB鏈入到不同的子隊列中
- 這兩個數組一個為正在被調度的運行隊列,一個是空閑隊列。已經被調度的進程和增加的新進程就鏈入到空閑隊列中,運行隊列調度完了就交換調度空閑隊列。
- Linux內核的O(1)調度算法:通過位圖,位圖中的每一個比特位代表一個下標,所以我們只需判斷該比特位是否為01來判斷對應子隊列是否為空,該時間復雜度為O(1)
- 所有在運行隊列的進程都是R狀態,他們最終會根據優先級打散到我們數組的不同下標處,所以我們就可以使用數組下標的不同從上向下訪問遍歷出來的PCB就是根據優先級調度的進程,所以我們就能做到根據不同優先級先調度那個進程,所以調整優先級的本質就是把進程的PCB鏈入到運行隊列的對應下標處的子隊列
2. 查看進程優先級
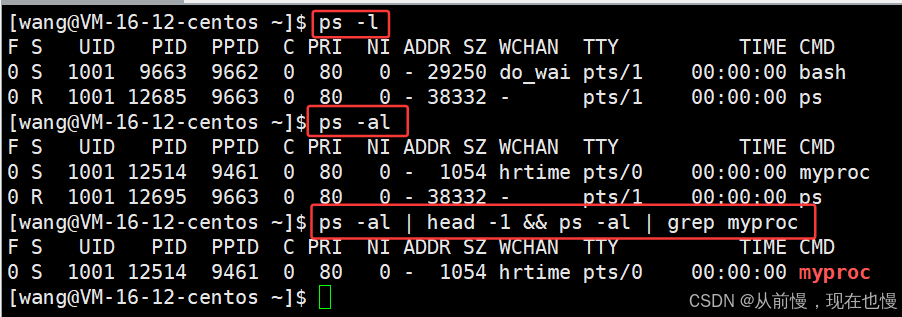
- 查看進程優先級
//查看當前終端下的進程優先級,不能查看其他終端的進程 ps -l //攜帶-a選項才能查看用戶啟用的所有進程,這就不僅能查看當前終端,還能查看其他終端了 ps -al //過濾其他干擾進程 ps -al | head -1 && ps -al | grep myproc
- 我們查出的進程屬性有很多,如下:
- UID:代表執行者的身份(ls攜帶-n選項可以看到文件擁有者的UID)
- PID:代表這個進程的代號
- PPID:代表這個進程是由哪個進程發展衍生而來的,即父進程的代號
- PRI(priority):代表這個進程可被執行的優先級,其值越小越早被執行
- NI:代表這個進程的nice值,是進程優先級的修正數據
vim批量化注釋:
- 命令模式下【ctrl+v】,左下角出現V-BLOCK
- 【h左j下k上l右】選中區域
- 【shift+i】進入插入模式,輸入//注釋
- 最后【ESC】
vim取消批量化注釋:
- 命令模式下【ctrl+v】,左下角出現V-BLOCK
- 【h左j下k上l右】選中區域
- 最后【d】
3. PRI 和 NI
- PRI也還是比較好理解的,即進程的優先級,或者通俗點說就是程序被CPU執行的先后順序,此值越小進程的優先級別越高
- 那NI呢?就是我們所要說的nice值了,其表示進程可被執行的優先級的修正數值
- PRI值越小越快被執行,那么加入nice值后,將會使得PRI變為:PRI(new)=PRI(old)+nice
- 這樣,當nice值為負值的時候,那么該程序將會優先級值將變小,即其優先級會變高,則其越快被執行
- 所以,調整進程優先級,在Linux下,就是調整進程nice值
- nice其取值范圍是-20至19,一共40個級別
小結:
- 進程的優先級可以被調整
- 雖然優先級可以被調整,但是為了每一個進程都被公平的調度,Linux不想過多的讓用戶參與優先級的調整,所以優先級的調整范圍nice為[-20,19]
- 進程默認的優先級為80,所以進程優先級范圍為[60,99]
注意:
- 普通用戶不能調整優先級
- 當我們的輸入nice修正值大于邊界值時取邊界值
- 每一次調整優先級,默認的PRI(old)都是80
4. 操作系統是如何根據優先級,開展的調度?
- 位圖就像位運算,其中的每一個比特位都有特定的含義,用01表示不同狀態
- 一般的位圖就是一串的01序列,用01表示不同的含義
- 位圖可能有很多比特位,所以位圖結構一般都是結構體里面套數組
//定義具有800比特位的位圖 struct bitmap {char bits[100]; } int main() {//找第N個比特位int i = N / (sizeof(char) * 8);int pos = N % (sizeof(char) * 8);bitmap b;b.bits[i] & pos; }
- 在前面我們知道了每一個CPU都要維護一個自己運行隊列,但并沒有講解運行隊列怎么根據不同的優先級調度進程?
- 在這個運行隊列中我們定義兩個類型為task_struct*的指針數組,這個指針數組的大小為140,下標[0,99]是給其他種類的進程用的,有特殊用途我們不考慮,而下標[100,139]對應我們上面學習的優先級范圍[66,99]
- 即這個指針數組不同的下標就對應進程不同的優先級,這個指針數組,我們只考慮下標[100,139]的區域
- 所有在運行隊列的進程都是R狀態,他們最終會根據優先級打散到我們數組的不同下標處,所以我們就可以使用數組下標的不同從上向下訪問遍歷出來的PCB就是根據優先級調度的進程,所以我們就能做到根據不同優先級先調度那個進程,所以調整優先級的本質就是把進程的PCB鏈入到運行隊列的對應下標處的子隊列
- 這兩個指針數組,一個為正在調度的運行隊列,一個為空閑隊列。
- 為什么要有一個空閑隊列——因為要解決在調度運行隊列的時候,已經調度過的進程和不斷新增的進程鏈入在哪里的問題——將調度過的進程和新到的進程鏈入到空閑的隊列中
- 一個運行隊列調度結束后再調度另一個空閑隊列——通過交換實現
- Linux內核的O(1)調度算法:通過位圖,位圖中的每一個比特位代表一個下標,所以我們只需判斷該比特位是否為01來判斷對應子隊列是否為空,該時間復雜度為O(1)
//運行隊列 struct runqueue {//定義一個指針數組,task_struct*指向一個存放進程PCB的地址//下標[0,99]是給其他種類的進程用的,有特殊用途我們不考慮//剛才上面我們學習了優先級的范圍是[66,99]是40個,而下標[100,139]也剛好是40,即優先級的范圍和下標一一對應[66,99] --> [100,139]//這個指針數組的下標就是進程的優先級//這個指針數組,我們只考慮下標[100,139]的區域task_struct *running[140];//問題:我們在調度運行隊列的時候,不僅要將已經調度過的隊列排到后面又會不斷地有新進程鏈入,該怎么解決呢?//1、添加一個鏡像指針數組,將調度過的進程個新到的進程鏈入到空閑的隊列中task_struct *waiting[140];//2、一個運行隊列調度結束和再調度另一個運行隊列——通過交換實現//指向running指針數組task_struct **run;//指向waiting鏡像指針數組task_struct **wait;//交換兩個指針,可以認為run一直指向運行隊列,wait一直指向空閑隊列swap(&run,&wait);//問題:判斷隊列是否為空,我們只能遍歷數組,但時間復雜度太高了,該怎么解決?//通過位圖,位圖中的每一個比特位代表一個下標,所以我們只需判斷該比特位是否為01來判斷對應子隊列是否為空,該時間復雜度為O(1)——Linux內核的O(1)調度算法!//小結:所有在運行隊列的進程都是R狀態,他們最終會根據優先級打散到我們數組的不同下標處,所以我們就可以使用數組下標的不同從上向下訪問遍歷出來的PCB就是根據優先級調度的進程,所以我們就能做到根據不同優先級先調度那個進程,所以調整優先級的本質就是把進程的PCB鏈入到運行隊列的對應下標處的子隊列
六、其他概念
競爭性:系統進程數目眾多,而CPU資源只有少量,甚至只有1個,所以進程之間是具有競爭屬性的。為了高效完成任務,更加合理競爭資源,便有了優先級。
獨立性:多進程運行,需要獨享各種資源,多進程運行期間互不干擾。
并行:多個進程在多個CPU下分別,同時運行,這稱為并行
并發:多個進程在一個CPU下采用進程切換的方式,在一段時間之內, 讓多個進程都得以推進,稱之為并發
- 進程切換為什么我們沒有感覺到?——》不要用我們人為的感知來衡量CPU的速度,如果你都能感知到進程切換了,那CPU也太差了!
- 一個進程被調度后,如果代碼一直沒有跑完會不會一直占用CPU資源?——》不會,因為操作系統不允許,所以每一個進程都有一個時間片的概念。
- 并發 = 進程切換 + 時間片,即并發是基于進程切換基于時間片輪轉的調度算法。
- 進程是如何切換的?
- CPU中包含各種寄存器,寄存器具有對數據臨時保存的能力。例如:函數的返回值是局部變量,函數銷毀的時候也會隨之銷毀,外部能拿到函數的返回值就是通過CPU的寄存器!
- 程序運行時,它怎么知道當前運行到了哪一行?系統如何得知我們的進程當前執行到哪一行代碼了?——》通過程序計數器(PC指針/eip指令指針):記錄當前進程正在執行指令的下一行指令的地址!
- CPU中寄存器有很多:通用寄存器(eax,ebx,ecx,edx)、棧幀寄存器(ebp,esp,eip)、狀態寄存器(status)……
- 為什么CPU中有這么多寄存器,他在其中扮演什么角色?——》提高效率,將進程高頻數據放到寄存器中——》CPU內寄存器保存進程相關數據!
- 即CPU寄存器保存進程的臨時數據——進程的上下文
- 進程在從CPU上離開的時候,要將自己的上下文數據保存好,甚至帶走!(保存的目的,就是為了未來的恢復!)
- 進程切換其實有兩個階段:一、保存上下文;二、恢復上下文。



)






?)


)





