一、Redis數據過多引發的五大隱患(附系統交互圖)
1. 內存溢出(OOM)與碎片化
- 內存分配機制:Redis使用jemalloc分配內存,當內存碎片率(
mem_fragmentation_ratio)>1.5時需警惕 - 淘汰策略對比:
| 策略 | 適用場景 | 風險 |
|---|---|---|
noeviction | 不允許數據丟失 | 寫入拒絕 |
allkeys-lru | 緩存場景 | 可能淘汰熱Key |
volatile-ttl | 帶過期時間的會話數據 | 可能誤刪未過期數據 |
- 運維方案:
- 監控命令:
INFO MEMORY查看used_memory和mem_fragmentation_ratio - 碎片整理:設置
activedefrag yes啟用自動碎片整理
2. 大Key與熱Key的阻塞機制(附時序圖)
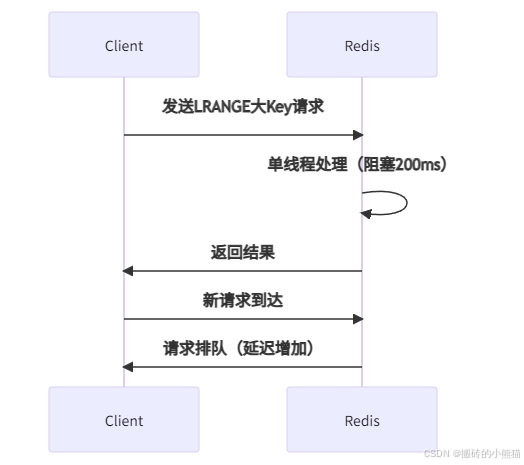
- 大Key判定標準:
- String > 10KB
- Hash/List/Set/ZSet > 5000元素
- 熱Key解決方案:
# 熱Key拆分示例
original_key = "hot:product:1001"
shard_id = random.randint(0, 9)# 隨機選擇分片
sharded_key = f"{original_key}:{shard_id}"
redis.get(sharded_key)
3. 過期鍵清理瓶頸
- 雙重刪除機制:
- 惰性刪除:訪問時檢查過期(可能阻塞請求)
- 定期刪除:10hz頻率掃描(每次最多25ms)
- 優化方案:
- 分散過期時間:
EXPIRE key 3600 + rand(0,600)添加隨機偏移 - 手動清理:低峰期執行
SCAN+DEL分批刪除
4. 持久化壓力(附RDB/AOF對比圖)
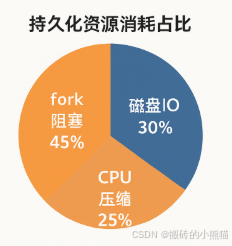
- RDB優化:
- 禁用自動生成:
save ""關閉默認配置 - 手動觸發:低峰期執行
bgsave
- 禁用自動生成:
- AOF重寫:
- 調整閾值:
auto-aof-rewrite-percentage 100+auto-aof-rewrite-min-size 1gb - 混合持久化:
aof-use-rdb-preamble yes減少文件體積
- 調整閾值:
5. 集群數據傾斜
- 分片不均檢測:
redis-cli --cluster check 10.0.0.1:6379
# 查看各節點內存分布
- 再平衡方案:
redis-cli --cluster rebalance \
--cluster-threshold 1 \
--cluster-use-empty-masters 10.0.0.1:6379
二、查詢性能影響深度分析
- O(1)操作穩定性(如GET/SET)
- 底層原理:基于哈希表直接尋址(
dictEntry),時間復雜度恒定。 - 性能表現:內存訪問約0.1ms,吞吐量可達10萬+ QPS(2核4G環境)。
- 典型場景:單Key讀寫、
HGET指定字段、ZSCORE獲取分數。
- O(n)操作線性風險(如LRANGE/HGETALL)
- 問題本質:數據量與耗時正比增長。例如:
- 百萬元素List執行
LRANGE 0 -1可能阻塞線程數百毫秒。 - 大Hash的
HGETALL引發CPU突增和網絡傳輸延遲。 - 雪崩風險:阻塞期間其他請求排隊,觸發查詢超時甚至連接池耗盡。
- 內存碎片 → 分配延遲的傳導路徑
-
碎片成因:
-
Jemalloc按固定大小(8B/16B/32B)分配內存,小于申請空間時產生碎片。
-
頻繁修改數據導致空間重用效率降低(如Hash字段動態增減)。
-
性能衰減:碎片率(
mem_fragmentation_ratio)>1.5時,內存分配延遲顯著上升,影響寫入速度。 -
實測延遲對比:
| 數據量 | O(1)操作 | O(n)操作 |
|---|---|---|
| 1萬Key | 0.12ms | 2.5ms |
| 100萬Key | 0.15ms | 250ms |
| 1億Key | 0.2ms | >2s |
三、系統性解決方案(附架構圖)
1. 大Key治理流程
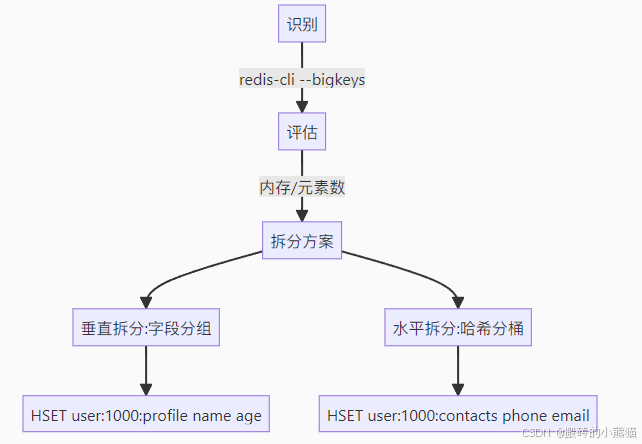
2. 熱Key應對體系
- 三級防護:
- 客戶端緩存:GuavaCache做本地緩存
- 代理層分流:Nginx+Redis分片
- 服務層防護:Sentinel自動故障轉移
3. 集群動態擴展
# 增加節點
redis-cli --cluster add-node 10.0.0.10:6379 10.0.0.1:6379
# 遷移槽位
redis-cli --cluster reshard --cluster-from node-id1 --cluster-to node-id2 --cluster-slots 1000
四、監控與預防體系
核心監控指標
| 指標 | 命令 | 閾值 |
|---|---|---|
| 內存使用率 | INFO memory | >80%告警 |
| Key淘汰數 | INFO stats | 持續>100/秒 |
| 復制延遲 | INFO replication | lag>5 |
| 碎片率 | INFO memory | >1.5 |
自動化運維鏈路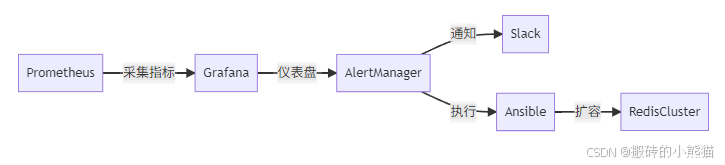
五、總結:規避風險的黃金法則
- 容量規劃
- 單實例內存控制在10GB內
- 預留30%內存緩沖
- 架構設計原則
┌─────────────┐┌─────────────┐
│Client│───? │Proxy│
└─────────────┘└─────────────┘
▼▼
┌─────────────┐┌─────────────┐
│ Local Cache ││ Redis集群│
└─────────────┘└─────────────┘
- 持續優化閉環
監控 → 分析 → 拆分 → 擴容 → 驗證
關鍵認知:Redis的瓶頸不在數據量本身,而在于數據形態和訪問模式。通過分布式架構改造(如分片集群)、存儲結構調整(如Hash分桶)和訪問路徑優化(如本地緩存),TB級Redis集群仍可保持毫秒級響應。
安全運維工程師)
)



)


)

)

 E1 (二分答案求中位數))






)