一、ORCA
1.1 ORCA 概覽
看下Continuous Batching 技術的開山之作ORCA,這個其實是融合的思路。
ORCA:把調度粒度從請求級別調整為迭代級別,并結合選擇性批處理(selective batching)來進行優化。
Sarathi[2] :利用Chunked Prefill策略通過將不同長度的prompts拆分成長度一致的chunks來進行prefill,同時利用這些chunks間隙進行decode 操作。
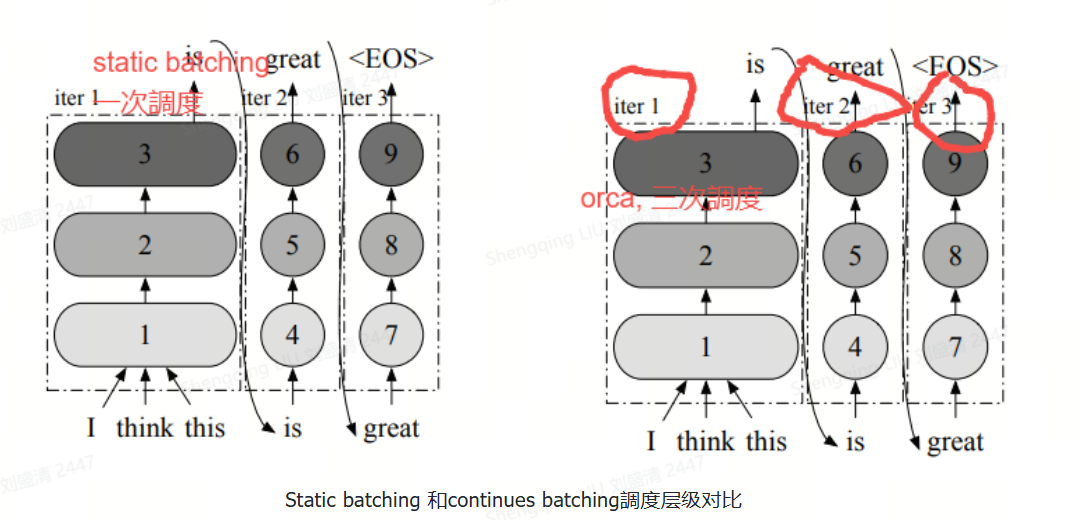
目前業界把依據ORCA思想實現的方案叫做Continuous Batching(連續批處理)。連續批處理是一種優化技術,它允許在生成過程中動態地調整批處理的大小。具體來說,一旦一個序列在批處理中完成生成,就可以立即用新的序列替代它,從而提高了GPU的利用率。這種方法的關鍵在于實時地適應當前的生成狀態,而不是等待整個批次的序列都完成。
與靜態批處理不同,連續批處理采用了迭代級別的調度。它并不等待每個序列在批次中完成生成后再進行下一個序列的處理。相反,調度程序在每個迭代中根據需要確定批次的大小。這意味著在每次迭代之前,調度程序檢查所有請求的狀態。一旦某個序列在批次中完成生成,就可以立即將一個新的序列插入到相同位置,同時刪除已完成的請求。
1.2 ORCA 具體實現說明
針對如何處理“提前完成和延遲加入的請求”這個挑戰,ORCA給出的解決方案是用迭代級調度減少空閑時間,即以迭代為粒度(iteration-level)控制執行,而不是請求級粒度(request-level),并結合選擇性批處理(selective batching)來進行優化。
迭代級調度的目標是:及時檢測出推理完畢的請求,將其從batch中移出,以便新請求可以填補到舊請求的位置上,這樣新請求和舊請求能接連不斷組成新的batch。
整體調度策略:
Orca是第一篇提到迭代級別調度(Iteration-Level Schedule)的論文。具體來說就是:一個batch中的所有請求每做完1次iteration(prefill或者decode),scheduler就和engine交互一次,去檢查batch中是否有做完推理的請求,以此決定是否要更新batch。這樣就可以在每次GPU推理的空隙,可以插入調度操作,實現Batch樣本的增刪和顯存的動態分配釋放。
下圖給出了請求粒度的調度和迭代粒度調度的區別。前者需在整批請求全部完成前對調度批次進行多次迭代,而對于ORCA,服務系統在調度任務時,每次只向 Execution Engine 提交一次迭代的計算,而非等到完成整個 Request才能處理。這樣 ORCA 就可以在每個迭代都動態更改要處理的請求,新請求只需等待單次迭代即可被處理,從而避免early-finish的請求等待其他請求的結束。通過迭代級調度,調度器能夠完全控制每個迭代中處理哪些請求以及處理數量。
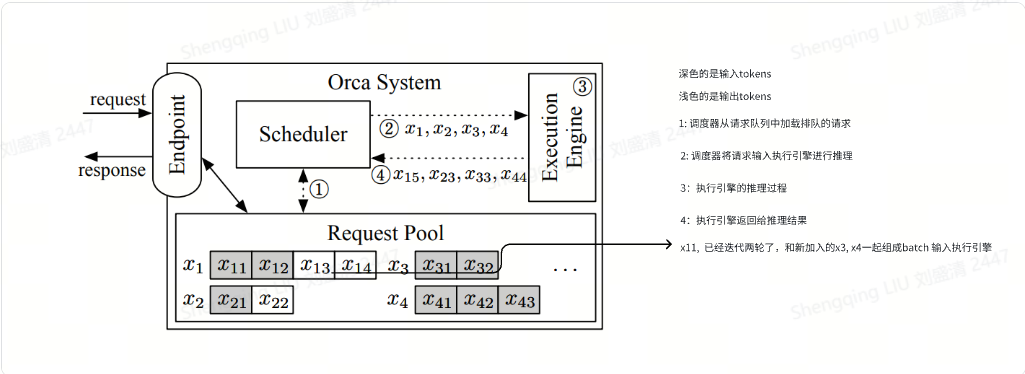
ORCA的系統框架圖
?
上圖展示了采用迭代級調度的ORCA系統架構和整體工作流程。ORCA系統包括如下模塊:
Endpoint(端點)。用于接收推理請求并發送響應。
Request Pool(請求池)。新到達的請求被放入請求池中,該組件負責管理系統中所有請求的生命周期。
Scheduler(調度器)。調度器監控請求池,負責以下任務:從池中選擇一組請求,調度執行引擎對這些請求執行模型迭代;接收執行引擎返回的執行結果(即輸出token),并將每個輸出token追加到對應請求中來更新請求池。
Execution Engine(執行引擎)。執行引擎是執行實際張量操作的抽象層,可在跨多個機器分布的多個GPU上并行化。
我們接下來看看下圖中的工作流程,其中,虛線表示組件之間的交互,交互發生在執行引擎的每次迭代中。xij是第i個請求的第j個token。陰影token表示從客戶端接收到的輸入token,而非陰影token由ORCA生成。例如,請求x1最初帶有兩個輸入標記(x11,x12),到目前為止已經運行了兩次迭代,其中第一次和第二次迭代分別生成了x13和x14。另一方面,請求x3只包含輸入標記x31,x32,請求x4包括x41,x42,x43,因為它們還沒有運行任何迭代。
工作流程分為如下幾步:
調度器與請求池交互,以決定下一步運行哪些請求。對應下圖標號?。
調度器調用引擎為所選定的四個請求(x1,x2,x3,x4)執行一次迭代。此時,因為x3和x4還沒有運行任何迭代,因此調度器為x3移交x31,x32給執行引擎,為x4移交x41,x42,x43給執行引擎。對應下圖標號?。
引擎對四個請求運行模型迭代,對應下圖標號?。
引擎把生成的輸出token(x15, x23, x33, x44)返回給調度器,對應下圖標號?。調度器在每次引擎返回,接收該迭代的執行結果之后會檢查請求是否完成。如果請求完成,請求池就會刪除已完成的請求,并通知端點發送響應,返回給客戶端。
對于新到達的請求,在當前迭代執行完畢后,它有機會開始處理(即調度器可能選擇新請求作為下一個執行對象)。因為新到達的請求只需等待一次迭代,從而顯著減少了排隊延遲。
ORCA對于中止請求(Canceled Requests)并沒有進行處理,實際上應該把這些請求會被及時從Batch中剔除并釋放相應顯存
ORCA的請求調度算法
下圖詳細描述如何在每次迭代中選擇請求的算法。
n_scheduled: micro-batch(微批)
micro-batch(微批) 是將一個完整的 batch 拆分成多個更小的子批次,用于提升硬件資源利用率,尤其在流水線并行(Pipeline Parallelism) 中非常常見。
當大模型被劃分為多個階段并分布在不同 GPU 上時,如果直接處理整個 batch,會導致部分 GPU 處于空閑等待狀態。為了解決這個問題,我們將 batch 拆分成多個 micro-batch,并讓它們像“流水線”一樣在各階段依次推進。這樣,每個階段的 GPU 都可以同時處理不同的 micro-batch,大幅提高并行度和吞吐量,減少資源浪費。
舉個例子,如果一個 batch 有 64 個樣本,可以被拆成 8 個 micro-batch,每個包含 8 個樣本,在模型各階段中交錯處理,從而避免 GPU 空轉,提高執行效率。每個階段表示模型中一部分連續的層,由一個 GPU 負責計算。例如,在一個 12 層的 Transformer 模型中,若使用 4 個 GPU,則每個階段可能包含 3 層。

核心功能實現:
實現了動態的選擇新的序列構成batch,實現了continuous batching
實現了將已經推理結束的序列刪除和資源釋放。
此算法中對KV Cache釋放時機控制得不是很理想。在請求生成結束時就立即釋放其K/V Cache。在多輪對話場景中,這個機制會導致冗余計算,即“上一輪對話生成K/V Cache → 釋放K/V Cache顯存 → 通過本輪對話的Prompt生成 之前的K/V Cache”。這樣會惡化后續幾輪對話的First Token Time(產生第一個Token的時延)指標。
1.3 selective batching
核心作用
Selective Batching將注意力計算從 Batching 中解耦。即為了提高計算效率,需要想辦法讓引擎能夠以批處理方式處理任何選定的請求集。
問題分析
在前面分析中,我們其實做了一個簡化的假設,即所有請求序列具有相同的長度。這是因為GPU的特殊性,如果想批量執行多個請求,每個請求的執行應該包含相同的操作,且消耗形狀相同的輸入張量。然而,在現實中,請求序列的長度是不同的。誠然Padding+Masking的方法可以解決,但嚴重浪費算力和顯存,對于算力和顯存均有限的推理GPU是不利的。
當使用迭代級別調度時,上述挑戰會愈發加劇。因為:
請求池中的請求可能具有不同的特征。
prefill和decode的計算方式不同。
prefill過程是長序列并行計算的,decode過程是token by token的。
prefill過程不需要讀取KV cache,decode過程需要讀取KV cache。
對于prefill,各個請求的prompt長度是不一致的。
對于decode,不同請求的decode token的index不一樣,意味著它們計算attention的mask矩陣也不一樣。
迭代級調度方法可能導致同一個批處理中的不同請求的處理進度不一樣,即輸入張量的形狀會因為已處理的token數量不同而不一致。
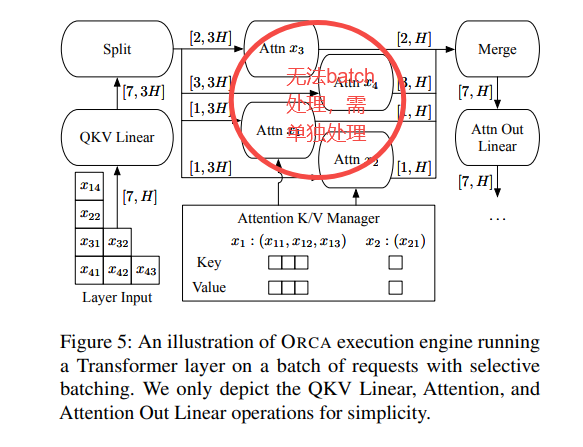
我們用上面架構圖作為例子來進行分析,來看看即使對于一對請求(xi,xj),也不能保證它們的下一次迭代可以合并、替換為批處理版本。有三種情況導致請求對不能合并批處理:
兩個請求都處于初始化階段,但輸入token數量不同(如下圖中的x3和x4)或者說輸入張量的“長度”維度不相等,因此無法將兩個請求進行批處理。
兩個請求都處于增量階段,但各自處理的token索引不同(如x1和x2)。由于每個請求處理的token索引不同,導致注意力鍵和值的張量形狀不同,因此也不能合并批處理。
請求處于不同階段:有的處于初始化階段,有的處于增量階段(如x1和x3)。由于不同階段的迭代輸入token數量不同(初始化階段迭代并行處理所有輸入token以提高效率,而增量階段每次迭代僅處理一個token),因此無法合并批處理。
上述關于批處理的主要問題在于,前述三種情況對應于形狀不規則的輸入(或狀態)張量,這些張量無法合并成一個大的張量并輸入到批處理操作中。因此,并非所有的請求都能在任意Iteration被Batching到一起。僅當兩個選定請求處于同一階段,且(在初始化階段)具有相同數量的輸入token或(在增量階段)具有相同的token索引時,批處理才適用。這一限制大大降低了在實際工作負載中執行批處理的可能性,因為調度器需要同時找到兩個符合批處理條件的請求。
問題解決
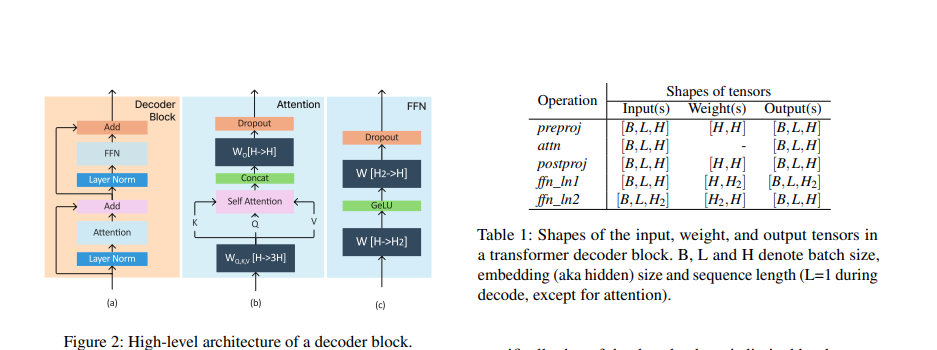
解決這些問題的一個好思路是:盡量找到這些請求計算時的共同之處,使得計算能最大化合并。對于有差異的部分再單獨處理。我們先以一個transformer decode block為例,回顧一下序列要經過哪些計算。下圖是decoder block的各種計算類型。可以看到,Transformer decoder block 在計算上可以看做六個操作的總和:pre-proj,attn,post-proj,ffn_ln1,ffn_ln2,others(比如 layer normalization,activation functions,residual connection)。Transformer 輸出一個形狀為 [B, L, H] 的張量。其中 B 是 batch size,L 是 input tokens length,H 是模型的 embedding size。每個 token 的 KV Cache 大小均為 [1, H]。
論文SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills對transform 模塊進行了分析。
?
我們把上面的介紹稍作提煉,得到如下重要信息:Transformer 層中的操作可以分為兩種類型: Attention 和 non-Attention,這兩種模塊的算子特點不同。
preproj/postproj/FFN1/FFN2:這幾個模塊中主要是Add、Linear、GeLU等算子,這些算子的特點是:不需要區分 token 來自于哪個請求。因此,雖然它們是
token-wise的,但可以使用批處理實現。和輸入序列長度無關。這意味著我們可以把一個batch中所有的tokens都展平成一行進行計算(維護好各自的位置向量就好, 便于從結果中取出對應的值),這樣不同長度的輸入也可以組成batch,從而進行計算。例如,上述x3和x4的輸入張量可以組合成一個二維張量[ΣL,H] = [5,H],而不需要明確的批處理維度。
需要從顯存讀取模型權重。讀取模型權重意味著我們應該盡量增大batch size,使得一次讀取能就可以造福更多請求,以此減少IO次數。
attention: 該模塊的特點是:
由于計算受各個序列的差異性影響(例如不同序列的mask矩陣不同、是否需要讀取KV cache),因此需要將序列拆分開獨立處理,即batch維度是重要的。
對于注意力操作, 無論是
token-wise還是request-wise的 batching 都無法執行。不對Attention層進行批處理對效率的影響較小,因為Attention層的操作不涉及到模型參數的重復使用,無法通過批處理來減少GPU內存讀取。
方案
總結上述思路:Transformer Layer里,并非所有的算子都要求組成批次的輸入具有相同的形狀。基于上述思路,Orca 提出了第二點核心技術: Selective batching(選擇性批處理),它不是對構成模型的所有張量操作(注意力和非注意力)都進行批處理, 而是有選擇地將批處理僅應用于少數非注意力操作,即對于不同類型的請求應用于不同類型的操作來解決問題,具體如下:
單獨處理每個注意力操作。即對于必須有相同Shape才能Batching的算子(例如Attention)會對不同的輸入進行單獨的計算。
對其他層(例如MLP層)則進行批處理。
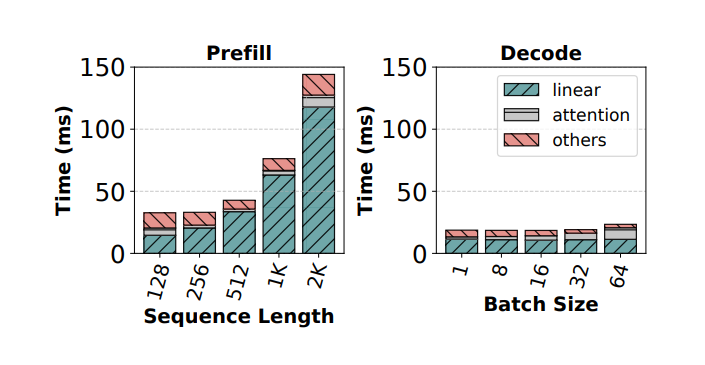
圖片來源:Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve?
 ?
?
二、引用文獻
[1] Orca: A distributed serving system for transformer-based generative models https://www.usenix.org/system/files/osdi22-yu.pdf
[2] SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills https://arxiv.org/pdf/2308.16369
[3] DeepSpeed-FastGen: High-throughput Text Generation for LLMs via MII and DeepSpeed-Inference https://arxiv.org/pdf/2401.08671
[4] Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve
https://arxiv.org/pdf/2403.02310
[5] Splitwise: Efficient generative LLM inference using phase splitting
https://arxiv.org/abs/2311.18677
[6] DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving
https://arxiv.org/abs/2401.09670
[7] https://zhuanlan.zhihu.com/p/1928005367754884226
?
CA1區域(dCA1)的時空聯合細胞對NLP中的深層語義分析的積極影響和啟示)
)
問題解決方法)


安裝 docker + ollama+ deepseek-r1:7b + Open WebUI(內含一鍵安裝腳本))

和ArrayList<>()的區別)











