第三篇 深度學習探索:神經網絡的奧秘解析
從手工特征工程到自動特征學習,深度學習為什么能讓AI"看懂"圖片、"聽懂"語音?讓我們用開發者的視角揭開神經網絡的神秘面紗。
深度學習的"代碼革命"
還記得我們在第二篇中提到的特征工程嗎?傳統機器學習就像手寫DOM操作,而深度學習(機器學習的一種)就像現代前端框架——他可以讓機器自己學會提取特征。
從手工到自動:特征工程的進化
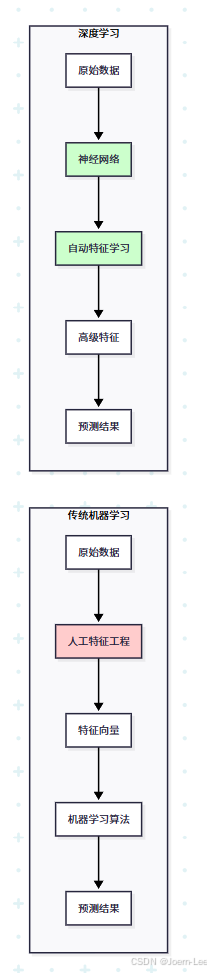
傳統機器學習的痛點:
# 傳統方式:手工提取圖像特征
def extract_image_features(image):features = {}# 需要人工設計大量特征features['brightness'] = calculate_brightness(image)features['edge_count'] = detect_edges(image)features['color_histogram'] = get_color_distribution(image)features['texture_pattern'] = analyze_texture(image)features['shape_descriptor'] = extract_shapes(image)# ... 需要專家知識設計幾十個特征return features# 然后用這些特征訓練傳統模型
model = RandomForestClassifier()
model.fit(manual_features, labels)
深度學習的突破:
# 深度學習方式:端到端自動學習
import torch
import torch.nn as nnclass ImageClassifier(nn.Module):def __init__(self):super().__init__()# 神經網絡自動學習特征self.feature_extractor = nn.Sequential(nn.Conv2d(3, 32, 3), # 自動學習邊緣特征nn.ReLU(),nn.Conv2d(32, 64, 3), # 自動學習形狀特征nn.ReLU(),nn.Conv2d(64, 128, 3), # 自動學習復雜特征nn.ReLU())self.classifier = nn.Linear(128, 10)def forward(self, x):# 直接從原始像素學習到最終分類features = self.feature_extractor(x)return self.classifier(features)# 直接用原始圖像數據訓練
model = ImageClassifier()
# 模型自己學會:像素 → 邊緣 → 形狀 → 物體
深度學習 = 自動化的特征工程師
// 類比:前端開發的進化
// 原生JS時代(傳統ML)
function updateUserList(users) {const listElement = document.getElementById('user-list');listElement.innerHTML = '';users.forEach(user => {const li = document.createElement('li');li.textContent = user.name;li.addEventListener('click', () => handleUserClick(user));listElement.appendChild(li);});
}// React時代(深度學習)
function UserList({ users, onUserClick }) {return (<ul>{users.map(user => <li key={user.id} onClick={() => onUserClick(user)}>{user.name}</li>)}</ul>);
}
深度學習就像React幫我們自動管理DOM一樣,幫我們自動管理特征提取。
神經網絡:代碼世界的"大腦"
神經元:最小的計算單元
從上面的第一個圖可以看到,一個神經元就像一個智能的計算函數:
def neuron(inputs, weights, bias):"""神經元的數學本質:加權求和 + 非線性激活就像一個會"思考"的計算器"""# 步驟1:加權求和(每個輸入都有不同的重要性)weighted_sum = sum(input_val * weight for input_val, weight in zip(inputs, weights))# 步驟2:加上偏置(調整觸發閾值)total_input = weighted_sum + bias# 步驟3:激活函數(決定是否"激活")output = activation_function(total_input)return output# 激活函數就像開關
def relu_activation(x):return max(0, x) # 小于0就關閉,大于0就原樣輸出def sigmoid_activation(x):return 1 / (1 + math.exp(-x)) # 輸出0-1之間的概率
神經網絡:智能計算的流水線
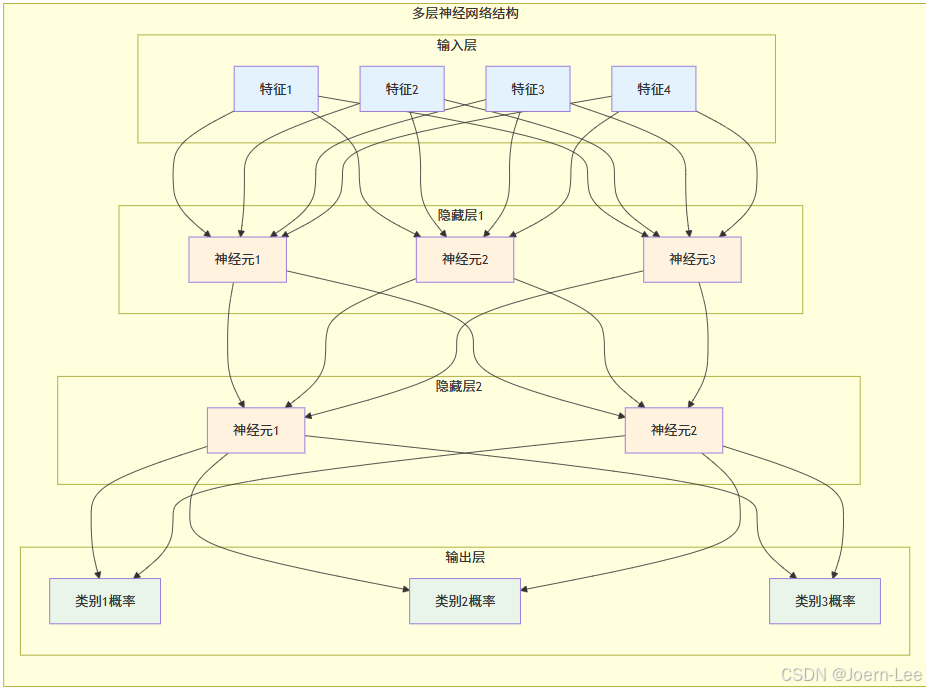
第二個圖展示了神經網絡的分層結構,每一層都在做不同的工作:
- 輸入層:接收原始數據(像API的請求參數)
- 隱藏層:提取和處理特征(像業務邏輯層)
- 輸出層:生成最終結果(像API的響應)
# 數據在網絡中的旅程
class NeuralNetworkJourney:def track_data_flow(self, input_data):print(f"📥 輸入層接收: {input_data}")# 第一層:基礎特征檢測layer1_output = self.layer1(input_data)print(f"🔍 隱藏層1提取: 邊緣、顏色等基礎特征")# 第二層:復雜特征組合layer2_output = self.layer2(layer1_output)print(f"🧩 隱藏層2組合: 形狀、紋理等復雜特征")# 輸出層:最終決策final_output = self.output_layer(layer2_output)print(f"🎯 輸出層判斷: 這是一只貓 (置信度: 87%)")return final_output
學習過程:錯誤中的智慧
第三個圖展示了神經網絡如何通過"犯錯誤"來學習,這個過程叫反向傳播:
# 學習過程就像不斷改進的程序員
def learning_process():for epoch in range(1000): # 重復學習1000次# 前向傳播:做預測prediction = neural_network.predict(input_data)# 計算錯誤:對比正確答案error = calculate_loss(prediction, correct_answer)# 反向傳播:調整參數# 就像debug后修改代碼neural_network.adjust_weights(error)if epoch % 100 == 0:print(f"第{epoch}輪學習,錯誤率: {error:.3f}")
類比理解- 神經網絡的學習就像一個新手程序員:
- 剛開始寫的代碼錯誤百出(隨機權重)
- 通過不斷調試修改代碼(反向傳播)
- 最終寫出正確的程序(訓練完成的模型)
這樣結合圖表和代碼,應該更容易理解神經網絡的工作原理了把
深度學習的三大"專業選手"
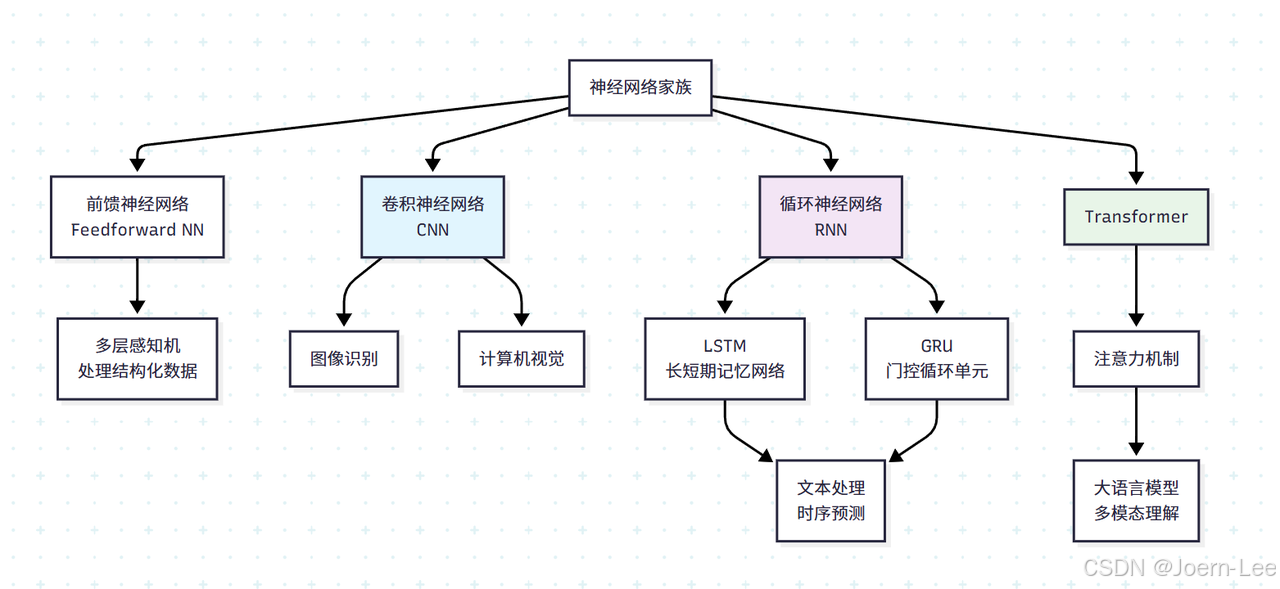
CNN:圖像處理的"視覺專家"
核心理念: 模仿人類視覺系統,從局部到整體逐步識別圖像
CNN就像一個專業的圖像分析師,它不會一下子看整張圖片,而是先關注局部細節(邊緣、紋理),然后逐步組合成復雜的圖案,最終識別出完整的物體。
# CNN的核心思想:卷積 + 池化 + 全連接
import torch.nn as nnclass SimpleCNN(nn.Module):def __init__(self):super().__init__()# 卷積層:提取圖像特征(像放大鏡看細節)self.conv_layers = nn.Sequential(nn.Conv2d(3, 32, kernel_size=3), # 32個"特征檢測器"nn.ReLU(), # 激活函數nn.MaxPool2d(2, 2), # 池化:壓縮信息nn.Conv2d(32, 64, kernel_size=3), # 檢測更復雜的特征nn.ReLU(),nn.MaxPool2d(2, 2))# 全連接層:做最終決策(像大腦綜合判斷)self.classifier = nn.Sequential(nn.Linear(64 * 6 * 6, 128),nn.ReLU(),nn.Linear(128, 10) # 10個類別)
工作流程: 輸入照片 → 檢測邊緣 → 識別形狀 → 組合特征 → 輸出"這是一只貓"
擅長場景: 圖像分類、人臉識別、醫療影像診斷、自動駕駛中的物體檢測
RNN/LSTM:序列處理的"記憶大師"
核心理念: 擁有"記憶"的神經網絡,能處理有時間順序的數據
RNN就像一個有記憶的翻譯官,它能記住前面的內容來理解當前的語境。但普通RNN記憶力有限,LSTM則像升級版,擁有選擇性記憶能力。
class SimpleLSTM(nn.Module):def __init__(self, vocab_size, embedding_dim, hidden_dim):super().__init__()# 詞嵌入:把單詞轉換成數字向量self.embedding = nn.Embedding(vocab_size, embedding_dim)# LSTM:核心的記憶單元self.lstm = nn.LSTM(embedding_dim, hidden_dim, batch_first=True)# 輸出層:基于記憶做預測self.output = nn.Linear(hidden_dim, vocab_size)def forward(self, x):# 處理序列數據的步驟embedded = self.embedding(x) # 單詞 → 向量lstm_out, (h, c) = self.lstm(embedded) # 序列處理 + 記憶更新return self.output(lstm_out) # 預測下一個詞
記憶機制: LSTM有三個"門"來控制記憶:
- 遺忘門: 決定忘記什么舊信息(“這個主語已經過時了”)
- 輸入門: 決定記住什么新信息(“這個新主語很重要”)
- 輸出門: 決定輸出什么信息(“現在該說動詞了”)
擅長場景: 機器翻譯、語音識別、股價預測、聊天機器人的上下文理解
Transformer:注意力機制的"全能選手"
核心理念: 拋棄循序處理,用"注意力"機制同時關注所有重要信息
Transformer就像一個能同時處理多線程的超級大腦,它不需要按順序讀取信息,而是能同時"注意"到句子中所有重要的詞匯和它們的關系。
class SimpleTransformer(nn.Module):def __init__(self, vocab_size, d_model, nhead, num_layers):super().__init__()# 詞嵌入 + 位置編碼self.embedding = nn.Embedding(vocab_size, d_model)self.pos_encoding = PositionalEncoding(d_model)# 多頭注意力機制:核心創新encoder_layer = nn.TransformerEncoderLayer(d_model=d_model, nhead=nhead, # 多個"注意力頭"batch_first=True)self.transformer = nn.TransformerEncoder(encoder_layer, num_layers)self.output = nn.Linear(d_model, vocab_size)
注意力機制的魔力:
# 注意力就像這樣工作:
sentence = "The cat sat on the mat"
# 當處理"sat"時,注意力會自動關注:
attention_weights = {"The": 0.1, # 不太重要"cat": 0.8, # 很重要!誰在坐?"sat": 0.2, # 當前詞"on": 0.4, # 重要!動作的方向"the": 0.1, # 不太重要"mat": 0.7 # 很重要!坐在哪里?
}
并行處理優勢: 不像RNN需要等前一個詞處理完,Transformer能同時處理整個句子,速度快得多。
擅長場景: 大語言模型(GPT、ChatGPT)、機器翻譯、文檔理解、代碼生成
三大選手對比總結
| 特性 | CNN | RNN/LSTM | Transformer |
|---|---|---|---|
| 最擅長 | 空間模式識別 | 時序模式記憶 | 復雜關系理解 |
| 處理方式 | 局部到整體 | 序列化處理 | 并行處理 |
| 核心優勢 | 空間不變性 | 長期記憶 | 注意力機制 |
| 典型應用 | 圖像識別 | 語音/文本序列 | 大語言模型 |
| 訓練速度 | 快 | 慢(串行) | 快(并行) |
現代趨勢: 越來越多的應用開始融合這三種架構,比如多模態大模型就同時用到了CNN(處理圖像)和Transformer(理解文本和圖像關系)。
你說得非常對!確實,"學習路徑"在第一篇已經有了整體規劃,第三篇重復確實有些冗余。"深度學習工具與流程"對開發者來說更實用,更符合這篇文章的定位。
讓我重新設計這個章節:
深度學習工具與流程
主流深度學習框架對比
PyTorch:開發者友好的"JavaScript"
# PyTorch的優勢:動態圖,調試友好
import torch
import torch.nn as nn# 就像寫普通Python代碼一樣直觀
x = torch.randn(1, 3, 224, 224)
model = nn.Sequential(nn.Conv2d(3, 64, 3),nn.ReLU(),nn.AdaptiveAvgPool2d(1)
)
output = model(x) # 可以隨時print調試
TensorFlow/Keras:生產級的"Java"
# TensorFlow的優勢:生產部署成熟
import tensorflow as tf# 更適合大規模部署
model = tf.keras.Sequential([tf.keras.layers.Conv2D(64, 3, activation='relu'),tf.keras.layers.GlobalAveragePooling2D(),tf.keras.layers.Dense(10, activation='softmax')
])# 一鍵導出為生產格式
model.save('my_model.savedmodel')
深度學習項目標準流程
階段1:環境準備 (30分鐘)
# 創建獨立環境(像Node.js的項目初始化)
conda create -n dl_project python=3.9
conda activate dl_project# 安裝依賴(像npm install)
pip install torch torchvision jupyter matplotlib
pip install tensorboard # 可視化訓練過程
階段2:數據準備 (1-2天)
# 數據加載和預處理(像前端的數據格式化)
from torch.utils.data import DataLoader
from torchvision import transforms# 數據增強:增加數據多樣性
transform = transforms.Compose([transforms.Resize((224, 224)),transforms.RandomHorizontalFlip(), # 隨機翻轉transforms.RandomRotation(10), # 隨機旋轉transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])train_loader = DataLoader(dataset, batch_size=32, shuffle=True)
階段3:模型開發 (2-3天)
# 模型定義(像寫API接口)
class MyModel(nn.Module):def __init__(self):super().__init__()# 使用預訓練模型(像使用成熟的庫)self.backbone = torchvision.models.resnet50(pretrained=True)self.backbone.fc = nn.Linear(2048, num_classes)def forward(self, x):return self.backbone(x)# 訓練配置(像webpack配置)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10)
階段4:訓練監控 (1-2天)
# 訓練循環(像啟動開發服務器)
for epoch in range(num_epochs):model.train()for batch_idx, (data, target) in enumerate(train_loader):optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()# 監控訓練狀態(像console.log調試)if batch_idx % 100 == 0:print(f'Epoch: {epoch}, Loss: {loss.item():.4f}')# 驗證性能(像單元測試)validate(model, val_loader)
必備開發工具推薦
開發環境:
- Jupyter Notebook:快速原型開發(像CodePen)
- PyCharm:完整項目開發
- Google Colab:免費GPU資源(像在線IDE)
可視化工具:
- TensorBoard:訓練過程可視化(像Chrome DevTools)
- Weights & Biases:實驗管理(像Git管理代碼)
- Matplotlib/Plotly:數據可視化
模型部署:
# 模型轉換為生產格式
torch.jit.save(torch.jit.script(model), 'model.pt')# 或者轉換為ONNX(跨平臺格式)
torch.onnx.export(model, dummy_input, 'model.onnx')
云平臺服務:
- AWS SageMaker:一站式ML平臺
- Google AI Platform:Google的ML服務
- Azure ML:微軟的ML平臺
從原型到生產的完整Pipeline
# 開發階段:快速驗證想法
def prototype_pipeline():# 小數據集 + 簡單模型 + 快速迭代model = SimpleModel()train_on_sample_data(model)# 優化階段:提升性能
def optimization_pipeline():# 數據增強 + 模型調優 + 超參數搜索model = AdvancedModel()hyperparameter_search(model)# 生產階段:穩定部署
def production_pipeline():# 模型壓縮 + 服務化 + 監控optimized_model = quantize_model(best_model)deploy_as_api(optimized_model)
深度學習實戰項目
項目1:智能代碼審查助手
import torch
import transformers
from transformers import AutoTokenizer, AutoModelclass CodeReviewAssistant:def __init__(self):# 使用預訓練的代碼理解模型self.tokenizer = AutoTokenizer.from_pretrained('microsoft/codebert-base')self.model = AutoModel.from_pretrained('microsoft/codebert-base')# 常見代碼問題模式self.issue_patterns = {'security': ['sql注入', '未轉義輸入', '硬編碼密碼'],'performance': ['循環嵌套過深', '未使用索引', '內存泄漏'],'maintainability': ['函數過長', '重復代碼', '魔法數字']}def analyze_code(self, code_snippet):"""分析代碼質量和潛在問題"""# 步驟1:代碼語義理解inputs = self.tokenizer(code_snippet, return_tensors='pt', truncation=True)outputs = self.model(**inputs)# 步驟2:問題檢測issues = self.detect_issues(code_snippet, outputs)# 步驟3:生成建議suggestions = self.generate_suggestions(issues)return {'code_quality_score': self.calculate_quality_score(outputs),'detected_issues': issues,'suggestions': suggestions,'complexity_analysis': self.analyze_complexity(code_snippet)}def detect_issues(self, code, embeddings):"""檢測代碼中的問題"""issues = []# 安全性檢查if 'SELECT * FROM' in code and 'WHERE' not in code:issues.append({'type': 'security','severity': 'high','message': '可能存在SQL注入風險','line': self.find_line_number(code, 'SELECT')})# 性能檢查if code.count('for') > 2 and 'break' not in code:issues.append({'type': 'performance', 'severity': 'medium','message': '嵌套循環可能影響性能','suggestion': '考慮使用更高效的算法'})return issuesdef generate_suggestions(self, issues):"""基于問題生成改進建議"""suggestions = []for issue in issues:if issue['type'] == 'security':suggestions.append({'title': '安全性改進','description': '使用參數化查詢防止SQL注入','example_code': 'cursor.execute("SELECT * FROM users WHERE id = ?", (user_id,))'})elif issue['type'] == 'performance':suggestions.append({'title': '性能優化','description': '考慮使用數據結構優化算法復雜度','example_code': '# 使用字典代替嵌套循環查找\nuser_dict = {user.id: user for user in users}'})return suggestions# 使用示例
reviewer = CodeReviewAssistant()
code = """
def get_user_orders(user_id):query = f"SELECT * FROM orders WHERE user_id = {user_id}"cursor.execute(query)return cursor.fetchall()
"""analysis = reviewer.analyze_code(code)
print(f"代碼質量評分: {analysis['code_quality_score']}")
for issue in analysis['detected_issues']:print(f"?? {issue['message']} (嚴重程度: {issue['severity']})")
項目2:智能用戶反饋分析系統
class UserFeedbackAnalyzer:def __init__(self):# 多任務學習:同時處理情感、意圖、緊急程度self.sentiment_model = self.load_sentiment_model()self.intent_classifier = self.load_intent_model()self.urgency_detector = self.load_urgency_model()def analyze_feedback_batch(self, feedbacks):"""批量分析用戶反饋"""results = []for feedback in feedbacks:analysis = {'original_text': feedback['text'],'timestamp': feedback['timestamp'],'user_id': feedback['user_id'],# 情感分析'sentiment': self.analyze_sentiment(feedback['text']),# 意圖識別'intent': self.classify_intent(feedback['text']),# 緊急程度評估'urgency': self.assess_urgency(feedback['text']),# 關鍵詞提取'keywords': self.extract_keywords(feedback['text']),# 自動回復建議'auto_response': self.suggest_response(feedback['text'])}results.append(analysis)return self.generate_summary_report(results)def classify_intent(self, text):"""識別用戶意圖"""intents = {'bug_report': ['錯誤', '崩潰', '無法使用', '問題'],'feature_request': ['希望', '建議', '功能', '新增'],'complaint': ['不滿', '糟糕', '差勁', '投訴'],'praise': ['很好', '棒', '滿意', '贊'],'question': ['如何', '怎么', '為什么', '什么']}# 實際項目中使用訓練好的分類器intent_scores = self.intent_classifier.predict(text)return {'primary_intent': intent_scores.argmax(),'confidence': intent_scores.max(),'all_scores': intent_scores.tolist()}def suggest_response(self, text):"""基于分析結果建議回復"""sentiment = self.analyze_sentiment(text)intent = self.classify_intent(text)response_templates = {('negative', 'bug_report'): "非常抱歉您遇到的問題,我們技術團隊會優先處理...",('positive', 'praise'): "感謝您的認可,我們會繼續努力提供更好的服務...",('neutral', 'question'): "關于您的問題,我來為您詳細解答...",('negative', 'complaint'): "我們深表歉意,會立即調查并改進..."}key = (sentiment['label'], intent['primary_intent'])template = response_templates.get(key, "感謝您的反饋,我們會認真處理...")return {'suggested_response': template,'response_type': 'auto_generated','requires_human_review': sentiment['label'] == 'negative' and intent['primary_intent'] == 'complaint'}def generate_summary_report(self, analyses):"""生成分析匯總報告"""total_count = len(analyses)# 情感分布統計sentiment_stats = {}intent_stats = {}urgency_stats = {}for analysis in analyses:# 統計各項指標分布sentiment = analysis['sentiment']['label']sentiment_stats[sentiment] = sentiment_stats.get(sentiment, 0) + 1intent = analysis['intent']['primary_intent']intent_stats[intent] = intent_stats.get(intent, 0) + 1urgency = analysis['urgency']['level']urgency_stats[urgency] = urgency_stats.get(urgency, 0) + 1return {'summary': {'total_feedback_count': total_count,'sentiment_distribution': sentiment_stats,'intent_distribution': intent_stats,'urgency_distribution': urgency_stats},'insights': self.generate_insights(analyses),'action_items': self.generate_action_items(analyses),'detailed_analyses': analyses}def generate_insights(self, analyses):"""生成業務洞察"""insights = []# 識別主要問題模式negative_feedbacks = [a for a in analyses if a['sentiment']['label'] == 'negative']if len(negative_feedbacks) > len(analyses) * 0.3:insights.append({'type': 'warning','message': f'負面反饋占比{len(negative_feedbacks)/len(analyses):.1%},需要重點關注','impact': 'high'})# 發現熱點話題all_keywords = []for analysis in analyses:all_keywords.extend(analysis['keywords'])keyword_freq = {}for keyword in all_keywords:keyword_freq[keyword] = keyword_freq.get(keyword, 0) + 1hot_topics = sorted(keyword_freq.items(), key=lambda x: x[1], reverse=True)[:5]insights.append({'type': 'trend','message': f'用戶最關注的話題:{", ".join([topic[0] for topic in hot_topics])}','details': hot_topics})return insights# 使用示例
analyzer = UserFeedbackAnalyzer()sample_feedbacks = [{'text': '應用經常崩潰,影響工作效率', 'timestamp': '2024-01-01', 'user_id': 'user001'},{'text': '新功能很好用,界面也很美觀', 'timestamp': '2024-01-01', 'user_id': 'user002'},{'text': '希望能增加夜間模式', 'timestamp': '2024-01-01', 'user_id': 'user003'}
]report = analyzer.analyze_feedback_batch(sample_feedbacks)
print("=== 用戶反饋分析報告 ===")
print(f"總反饋數: {report['summary']['total_feedback_count']}")
print(f"情感分布: {report['summary']['sentiment_distribution']}")
for insight in report['insights']:print(f"💡 洞察: {insight['message']}")
寫在最后:深度學習的開發者思維
深度學習看似神秘,但本質上是一種自動化的特征工程工具。就像我們從手寫DOM操作進化到現代前端框架一樣,深度學習讓我們從手工設計特征進化到自動學習特征。
關鍵收獲:
- 深度學習 = 自動特征工程:讓機器自己學會提取有用信息
- 神經網絡 = 復雜函數組合:通過多層轉換逐步抽象數據
- 不同架構處理不同問題:CNN處理圖像,RNN處理序列,Transformer處理注意力
- 端到端學習:從原始數據直接學到最終結果
實踐建議:
- 從API開始:先學會調用,再理解原理
- 項目驅動:選擇具體問題,邊做邊學
- 工程思維:把深度學習當作工具,專注解決業務問題
- 持續迭代:模型像代碼一樣需要版本管理和持續優化
記住:深度學習不是魔法,而是一套強大的模式識別工具。掌握了它,你就能讓程序"看懂"圖像、"聽懂"語音、"理解"文本,為用戶創造更智能的體驗。
下期預告:《大模型時代:站在巨人肩膀上的學習革命》
在最后一篇中,我們將探索大模型如何改變整個AI應用開發范式,以及如何構建基于大模型的智能應用系統。
好的!我來按照我們討論的框架寫第四篇文章。
第四篇 大模型時代:開發者的AI應用新范式
從GPT-3到ChatGPT,從編程助手到智能應用,大模型不僅改變了AI的能力邊界,更重新定義了軟件開發的方式。作為開發者,我們如何理解這場革命,又該如何擁抱這個新時代?
大模型核心技術揭秘:為什么突然"智能涌現"了?
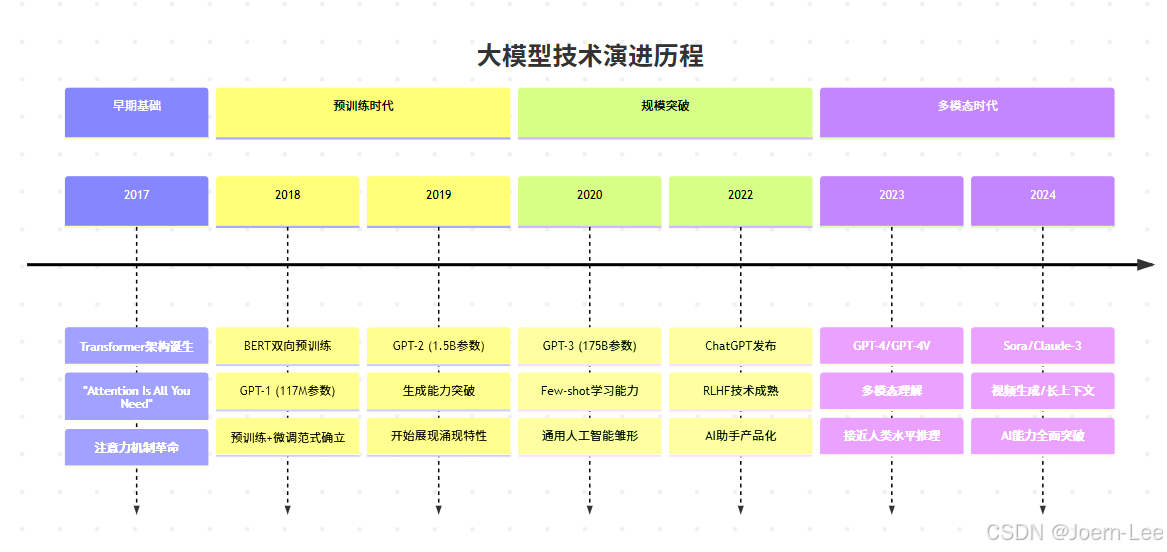
Transformer:改變游戲規則的架構革命
還記得我們在第三篇中提到的RNN需要串行處理序列數據嗎?Transformer的出現徹底改變了這一切。
# RNN的痛點:必須按順序處理
def rnn_process_sentence(sentence):hidden_state = initial_statefor word in sentence:hidden_state = rnn_cell(word, hidden_state) # 必須等前一個詞處理完return hidden_state# Transformer的突破:并行處理
def transformer_process_sentence(sentence):# 所有詞同時處理,通過注意力機制建立關系attention_weights = calculate_attention(sentence) # 并行計算return parallel_transform(sentence, attention_weights)
注意力機制的魔力:
// 類比:前端事件處理的進化
// 舊方式:串行處理事件
function handleEventsSequentially(events) {for (let event of events) {processEvent(event); // 必須等上一個處理完}
}// 新方式:并行處理 + 智能關聯
function handleEventsWithAttention(events) {const relationships = calculateEventRelationships(events); // 分析事件關系return Promise.all(events.map(event => processEvent(event, relationships) // 并行處理,但考慮關聯));
}
預訓練革命:從"定制開發"到"基礎平臺"
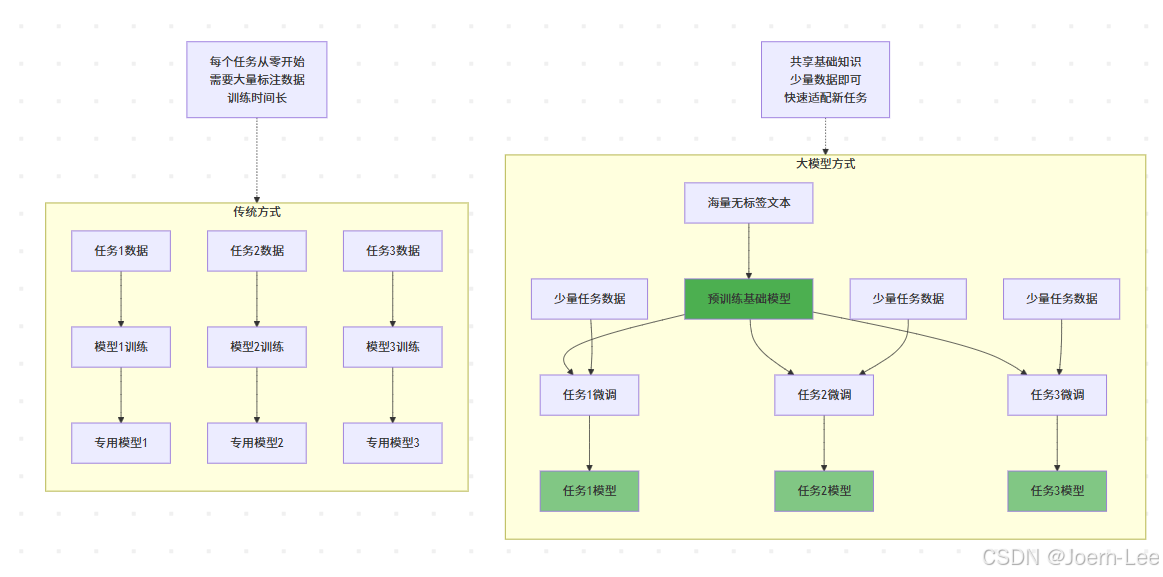
這就像從為每個項目單獨搭建基礎設施,轉向使用云平臺 + 微服務的模式。
規模效應:量變引起質變
參數規模的指數級增長:
GPT-1 (2018): 1.17億參數 → 能完成簡單文本生成
GPT-2 (2019): 15億參數 → 能寫連貫的段落
GPT-3 (2020): 1750億參數 → 能進行復雜推理
GPT-4 (2023): ~1萬億參數 → 能處理多模態任務
涌現能力的神奇現象:
# 當模型規模達到臨界點時,突然"學會"了新能力
class ModelCapabilities:def __init__(self, parameter_count):self.params = parameter_countdef emergent_abilities(self):abilities = ["基礎文本生成"]if self.params > 1e9: # 10億參數abilities.append("邏輯推理")if self.params > 1e11: # 1000億參數abilities.append("代碼編寫")abilities.append("數學計算")if self.params > 1e12: # 1萬億參數abilities.append("多模態理解")abilities.append("復雜規劃")abilities.append("創意寫作")return abilities# 這種現象類似軟件開發中的"復雜度臨界點"
def system_complexity_effects(codebase_size):if codebase_size < 1000:return "簡單腳本"elif codebase_size < 100000:return "小型應用,架構簡單"elif codebase_size < 1000000:return "中型系統,需要架構設計"else:return "大型系統,需要微服務、分布式等復雜架構"
多模態融合:從單一到全能
# 傳統方式:各種模態分別處理
class TraditionalMultiModal:def __init__(self):self.text_model = BertModel()self.image_model = ResNetModel()self.audio_model = WaveNetModel()def process_content(self, text=None, image=None, audio=None):results = {}if text:results['text'] = self.text_model.process(text)if image:results['image'] = self.image_model.process(image)if audio:results['audio'] = self.audio_model.process(audio)return results# 大模型方式:統一處理多模態
class UnifiedMultiModal:def __init__(self):self.unified_model = GPT4VisionModel()def process_content(self, inputs):# 一個模型理解所有模態的內容和關系return self.unified_model.understand(inputs)def example_usage(self):# 能理解圖片+文字的組合含義result = self.process_content({"image": "screenshot.png","text": "這個界面有什么問題?","context": "這是我們的登錄頁面"})return result # 輸出:綜合分析界面設計問題
為什么模型突然"聰明"了,稱之為大模型了 ?
- 并行計算能力:Transformer讓訓練效率提升數十倍
- 數據規模:互聯網文本數據的爆炸式增長
- 計算資源:GPU集群和云計算的成熟
- 算法優化:注意力機制、殘差連接等關鍵技術突破
大模型如何重新定義軟件開發?
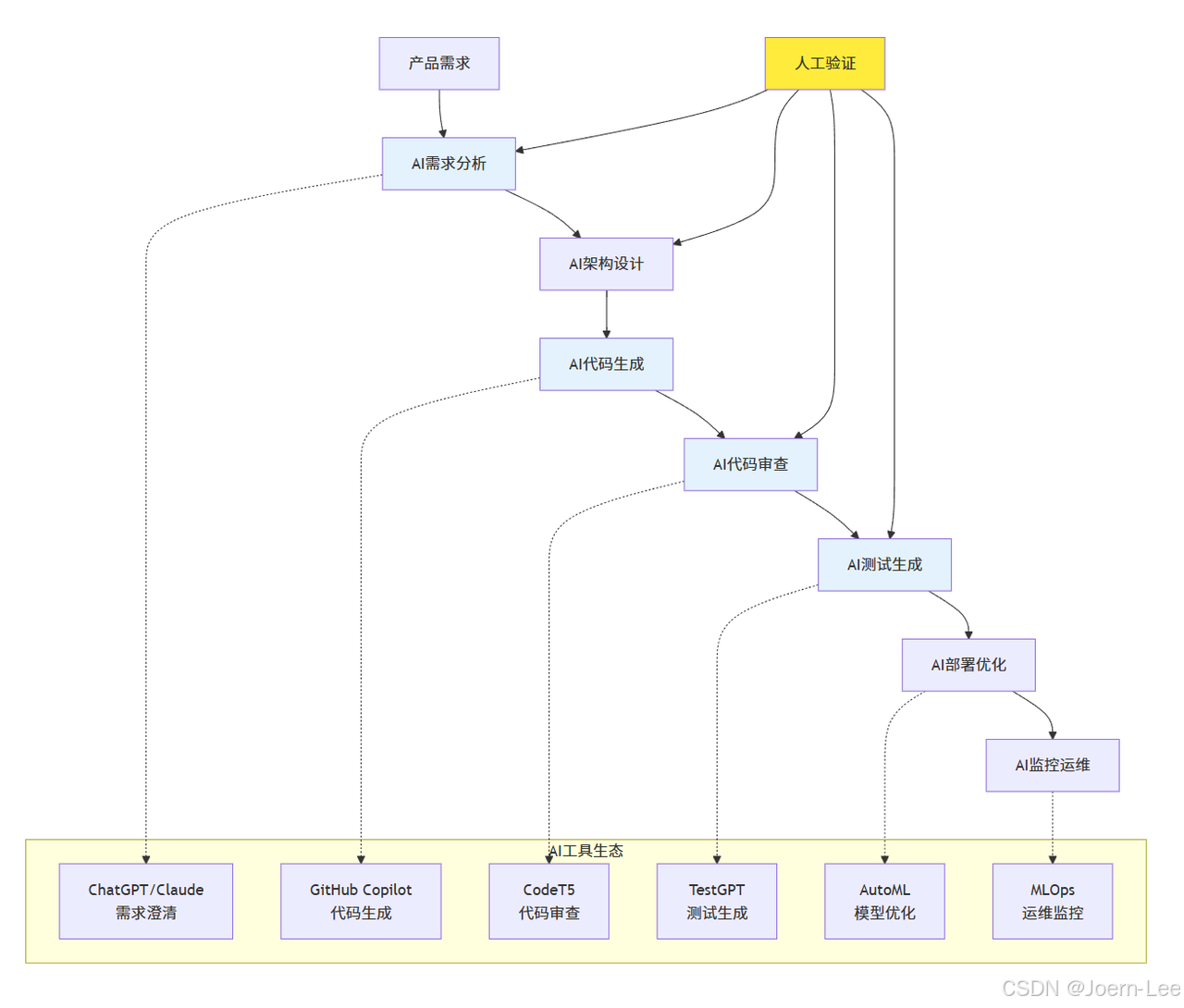
從"編寫代碼"到"描述需求"
// 傳統開發流程
function traditionalDevelopment() {const requirements = analyzeRequirements();const architecture = designArchitecture(requirements);const code = writeCode(architecture);const tests = writeTests(code);return deployApp(code, tests);
}// AI輔助開發流程
function aiAssistedDevelopment() {const requirements = describeInNaturalLanguage();const code = generateCodeFromDescription(requirements);const optimizedCode = refactorWithAI(code);const tests = generateTests(optimizedCode);const bugs = findBugsWithAI(optimizedCode);return deployApp(optimizedCode, tests);
}
開發生命周期的AI增強
需求分析階段:
# AI助手幫助澄清和完善需求
class RequirementsAI:def analyze_user_story(self, user_story):"""輸入:用戶故事輸出:詳細需求分析 + 潛在問題識別"""prompt = f"""分析以下用戶故事,指出:1. 核心功能需求2. 非功能性需求3. 潛在的邊界情況4. 可能的技術挑戰用戶故事:{user_story}"""return self.llm.generate(prompt)# 使用示例
ai_analyst = RequirementsAI()
analysis = ai_analyst.analyze_user_story("作為一個用戶,我希望能夠快速搜索商品,以便找到我想要的產品"
)
架構設計階段:
class ArchitectureAI:def suggest_architecture(self, requirements, constraints):"""AI推薦技術架構"""prompt = f"""基于以下需求和約束條件,推薦合適的技術架構:需求:{requirements}約束:{constraints}請提供:1. 推薦的技術棧2. 系統架構圖描述3. 關鍵技術選型理由4. 潛在風險和解決方案"""return self.llm.generate(prompt)
編碼階段:
class CodingAI:def generate_code(self, specification):"""根據規格說明生成代碼"""return f"""// AI生成的代碼示例class UserSearchService {{constructor(searchEngine, productRepository) {{this.searchEngine = searchEngine;this.productRepository = productRepository;}}async searchProducts(query, filters = {{}}) {{// 搜索邏輯實現const searchResults = await this.searchEngine.search(query);const filteredResults = this.applyFilters(searchResults, filters);return this.formatResults(filteredResults);}}}}"""def review_code(self, code):"""AI代碼審查"""prompt = f"""審查以下代碼,檢查:1. 潛在的bug2. 性能問題3. 安全漏洞4. 代碼規范5. 改進建議代碼:{code}"""return self.llm.generate(prompt)
AI驅動的新開發模式
測試驅動開發 → AI輔助測試生成
# 傳統TDD
def test_user_registration():# 手動編寫所有測試用例assert register_user("valid@email.com", "password123") == Trueassert register_user("invalid-email", "password123") == False# ... 需要想到所有邊界情況# AI增強TDD
def ai_generate_tests(function_signature, requirements):prompt = f"""為以下函數生成全面的測試用例:函數簽名:{function_signature}需求:{requirements}包括:正常用例、邊界情況、異常情況、安全測試"""return ai_model.generate(prompt)# 自動生成全面的測試套件
test_suite = ai_generate_tests("register_user(email: str, password: str) -> bool","用戶注冊功能,需要驗證郵箱格式和密碼強度"
)
提示工程:開發者的新核心技能
提示工程的技術原理
# 提示工程就像設計API接口
class PromptEngineering:def __init__(self):self.llm = LanguageModel()def basic_prompt(self, task):"""基礎提示:直接描述任務"""return f"請幫我{task}"def structured_prompt(self, task, context, format_requirements):"""結構化提示:提供上下文和格式要求"""return f"""任務:{task}上下文:{context}輸出格式:{format_requirements}請按照要求完成任務。"""def few_shot_prompt(self, task, examples):"""少樣本提示:提供示例"""examples_text = "\n".join([f"輸入:{ex['input']}\n輸出:{ex['output']}" for ex in examples])return f"""任務:{task}示例:{examples_text}現在請處理新的輸入:"""def chain_of_thought_prompt(self, problem):"""思維鏈提示:引導逐步推理"""return f"""問題:{problem}請按以下步驟分析:1. 理解問題的核心2. 識別需要考慮的因素3. 逐步推理分析4. 得出結論讓我們一步步思考:"""
代碼生成的高級提示技巧
class CodeGenerationPrompts:def generate_function_with_context(self, function_description, existing_code, requirements):"""為特定上下文生成函數"""prompt = f"""現有代碼上下文:```python{existing_code}```需求:{requirements}請實現函數:{function_description}要求:1. 與現有代碼風格保持一致2. 使用適當的錯誤處理3. 添加必要的類型注解4. 包含docstring文檔5. 考慮性能和安全性生成的代碼:"""return promptdef debug_with_ai(self, buggy_code, error_message):"""AI輔助調試"""prompt = f"""以下代碼出現了錯誤:```python{buggy_code}```錯誤信息:{error_message}請分析:1. 錯誤的根本原因2. 修復方案3. 修復后的完整代碼4. 如何避免類似問題分析和修復:"""return promptdef refactor_legacy_code(self, legacy_code, modern_requirements):"""重構遺留代碼"""prompt = f"""需要重構以下遺留代碼:```python{legacy_code}```現代化要求:{modern_requirements}請提供:1. 重構計劃和步驟2. 重構后的代碼3. 性能和可維護性改進說明4. 測試建議重構方案:"""return prompt
系統設計的提示模板
class SystemDesignPrompts:def design_api(self, service_description, requirements):"""API設計提示"""prompt = f"""需要設計一個{service_description}的API。功能需求:{requirements}請提供:1. RESTful API設計2. 請求/響應格式3. 錯誤處理策略4. 認證授權方案5. 性能考慮6. OpenAPI規范文檔API設計:"""return promptdef architecture_consultation(self, problem, constraints):"""架構咨詢提示"""prompt = f"""架構問題:{problem}約束條件:{constraints}請作為架構師提供:1. 問題分析2. 多種解決方案對比3. 推薦方案及理由4. 實施計劃5. 風險評估6. 技術選型建議架構建議:"""return prompt# 實際使用示例
design_prompts = SystemDesignPrompts()
api_prompt = design_prompts.design_api("用戶管理服務","注冊、登錄、個人信息管理、權限控制"
)
基于大模型的應用架構設計
RAG系統:讓AI擁有專業知識
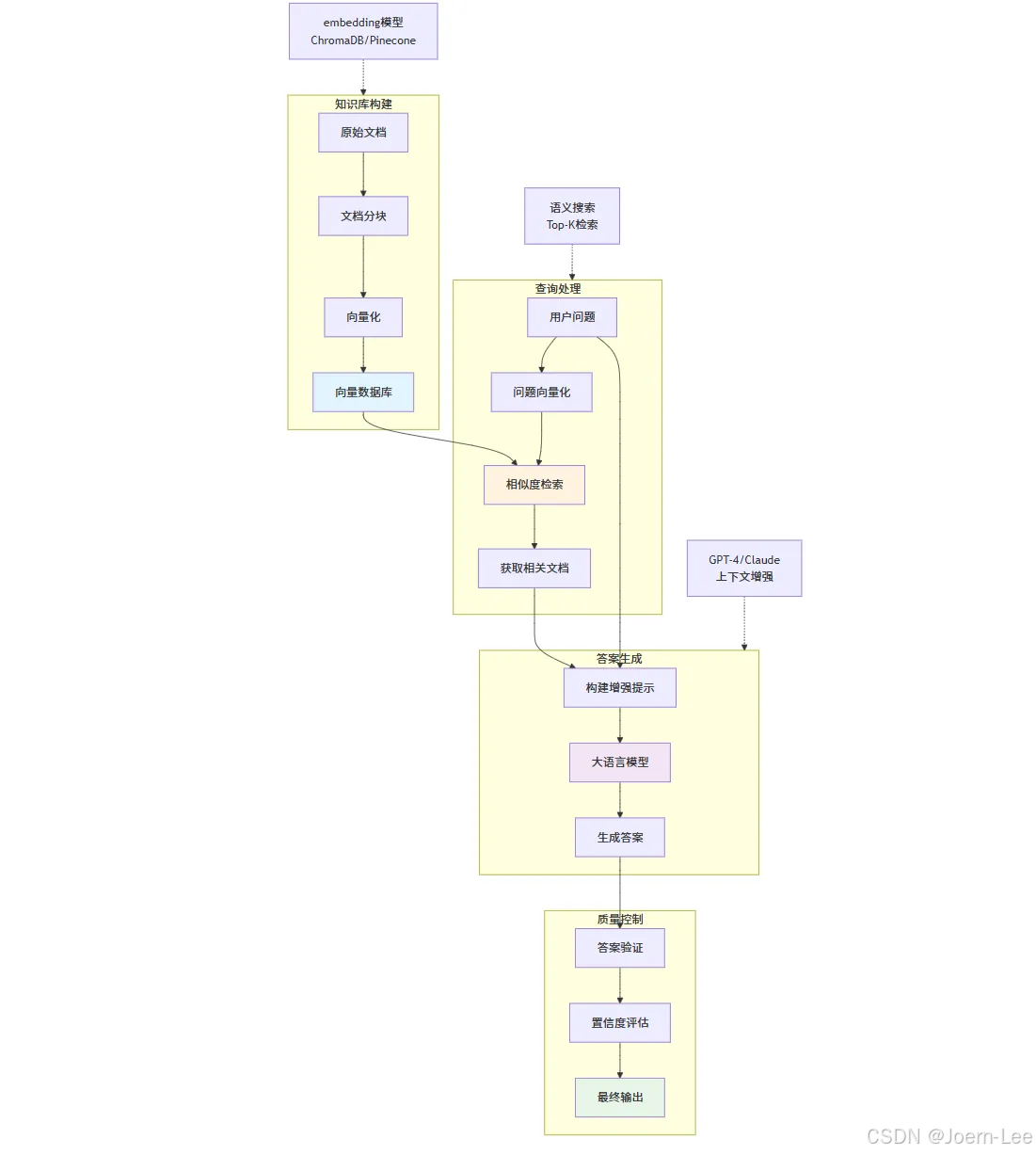
# RAG (Retrieval-Augmented Generation) 架構
class RAGSystem:def __init__(self):self.vector_db = VectorDatabase()self.embedding_model = SentenceTransformer('all-MiniLM-L6-v2')self.llm = OpenAIGPT4()def index_documents(self, documents):"""將文檔轉換為向量并存儲"""for doc in documents:# 文檔分塊chunks = self.chunk_document(doc)for chunk in chunks:# 生成嵌入向量embedding = self.embedding_model.encode(chunk.text)# 存儲到向量數據庫self.vector_db.insert({'id': chunk.id,'text': chunk.text,'embedding': embedding,'metadata': chunk.metadata})def answer_question(self, question):"""基于知識庫回答問題"""# 1. 將問題轉換為向量question_embedding = self.embedding_model.encode(question)# 2. 檢索相關文檔relevant_docs = self.vector_db.search(question_embedding, top_k=5)# 3. 構建增強提示context = "\n".join([doc['text'] for doc in relevant_docs])prompt = f"""基于以下上下文回答問題:上下文:{context}問題:{question}請基于上下文提供準確的答案,如果上下文中沒有相關信息,請明確說明。"""# 4. 生成回答return self.llm.generate(prompt)# 實際應用:代碼知識庫問答
class CodebaseQA(RAGSystem):def __init__(self, codebase_path):super().__init__()self.index_codebase(codebase_path)def index_codebase(self, codebase_path):"""索引代碼庫"""code_files = self.extract_code_files(codebase_path)documents = []for file_path in code_files:with open(file_path, 'r') as f:content = f.read()# 提取函數和類functions = self.extract_functions(content)classes = self.extract_classes(content)for func in functions:documents.append({'text': func['code'],'type': 'function','name': func['name'],'file': file_path,'docstring': func['docstring']})self.index_documents(documents)def ask_about_code(self, question):"""詢問代碼相關問題"""return self.answer_question(question)# 使用示例
qa_system = CodebaseQA("/path/to/project")
answer = qa_system.ask_about_code("這個項目的用戶認證是怎么實現的?")
向量數據庫集成
# 不同向量數據庫的集成
class VectorDBManager:def __init__(self, db_type="chroma"):if db_type == "chroma":self.db = self.setup_chroma()elif db_type == "pinecone":self.db = self.setup_pinecone()elif db_type == "weaviate":self.db = self.setup_weaviate()def setup_chroma(self):"""ChromaDB - 本地開發友好"""import chromadbclient = chromadb.Client()collection = client.create_collection("documents")return collectiondef setup_pinecone(self):"""Pinecone - 云端高性能"""import pineconepinecone.init(api_key="your-api-key", environment="us-west1-gcp")index = pinecone.Index("document-index")return indexdef semantic_search(self, query, top_k=5):"""語義搜索"""query_embedding = self.embedding_model.encode(query)if isinstance(self.db, chromadb.Collection):results = self.db.query(query_embeddings=[query_embedding.tolist()],n_results=top_k)return results['documents'][0]elif hasattr(self.db, 'query'): # Pineconeresults = self.db.query(vector=query_embedding.tolist(),top_k=top_k,include_metadata=True)return [match['metadata']['text'] for match in results['matches']]
大模型應用的性能優化
class LLMOptimization:def __init__(self):self.cache = {}self.rate_limiter = RateLimiter()def cached_generation(self, prompt, cache_key=None):"""緩存機制減少重復調用"""if cache_key is None:cache_key = hashlib.md5(prompt.encode()).hexdigest()if cache_key in self.cache:return self.cache[cache_key]result = self.llm.generate(prompt)self.cache[cache_key] = resultreturn resultdef batch_processing(self, prompts):"""批量處理提高效率"""with self.rate_limiter:results = []batch_size = 10for i in range(0, len(prompts), batch_size):batch = prompts[i:i+batch_size]batch_results = self.llm.batch_generate(batch)results.extend(batch_results)return resultsdef streaming_response(self, prompt):"""流式響應改善用戶體驗"""for chunk in self.llm.stream_generate(prompt):yield chunkdef cost_optimization(self, prompt, max_tokens=None):"""成本優化策略"""# 1. 選擇合適的模型if len(prompt) < 1000 and "code" not in prompt.lower():model = "gpt-3.5-turbo" # 便宜的模型else:model = "gpt-4" # 復雜任務用好模型# 2. 優化token使用if max_tokens is None:max_tokens = min(1000, len(prompt) * 2) # 動態調整# 3. 使用壓縮提示compressed_prompt = self.compress_prompt(prompt)return self.llm.generate(compressed_prompt, model=model,max_tokens=max_tokens)
開發者在AI時代的技能進化
從"寫代碼"到"設計AI工作流"
# 傳統開發者技能樹
class TraditionalDeveloper:skills = {'programming_languages': ['Python', 'JavaScript', 'Java'],'frameworks': ['React', 'Django', 'Spring'],'databases': ['PostgreSQL', 'MongoDB'],'tools': ['Git', 'Docker', 'Kubernetes'],'practices': ['TDD', 'CI/CD', 'Agile']}# AI時代開發者技能樹
class AIEraeDeveloper:skills = {# 傳統技能仍然重要'core_programming': ['Python', 'JavaScript', 'TypeScript'],'traditional_tools': ['Git', 'Docker', 'Kubernetes'],# 新增AI技能'ai_integration': ['API調用和管理','提示工程設計','向量數據庫操作','RAG系統構建'],'ai_tools': ['LangChain/LlamaIndex','Pinecone/Chroma','OpenAI/Anthropic APIs','Hugging Face'],'ai_workflow_design': ['AI任務分解','多模型協同','人機協作設計','AI系統監控']}def design_ai_workflow(self, business_requirement):"""設計AI工作流"""workflow = {'input_processing': self.design_input_handler(business_requirement),'ai_pipeline': self.design_ai_pipeline(business_requirement),'output_formatting': self.design_output_formatter(business_requirement),'human_in_loop': self.design_human_oversight(business_requirement)}return workflow
傳統技能的AI增強
class EnhancedDevelopmentSkills:def debugging_with_ai(self, error_log, codebase):"""AI增強的調試能力"""# 1. AI分析錯誤日志error_analysis = self.ai_analyzer.analyze_error(error_log)# 2. AI搜索相關代碼relevant_code = self.code_search.find_related_code(error_analysis.keywords, codebase)# 3. AI生成調試建議debug_suggestions = self.ai_debugger.suggest_fixes(error_analysis, relevant_code)return {'error_analysis': error_analysis,'related_code': relevant_code,'suggestions': debug_suggestions}def architecture_design_with_ai(self, requirements):"""AI輔助架構設計"""# 1. AI分析需求復雜度complexity_analysis = self.ai_architect.analyze_complexity(requirements)# 2. AI推薦技術棧tech_stack = self.ai_architect.recommend_stack(complexity_analysis,self.get_team_skills(),self.get_constraints())# 3. AI生成架構圖architecture_diagram = self.ai_architect.generate_architecture(requirements,tech_stack)return {'complexity': complexity_analysis,'recommended_stack': tech_stack,'architecture': architecture_diagram}def code_review_with_ai(self, pull_request):"""AI增強的代碼審查"""ai_review = self.ai_reviewer.review_code(pull_request.diff)human_review_focus = self.ai_reviewer.suggest_human_focus_areas(ai_review,pull_request.complexity)return {'ai_findings': ai_review.issues,'ai_suggestions': ai_review.improvements,'human_review_needed': human_review_focus}
新興職業機會
class NewAIRoles:class AIEngineer:"""AI工程師:構建AI系統的專家"""responsibilities = ["設計和實現AI應用架構","優化模型性能和成本","構建AI數據管道","集成多種AI服務"]def build_ai_application(self, requirements):return {'model_selection': self.select_optimal_models(requirements),'data_pipeline': self.design_data_pipeline(requirements),'inference_optimization': self.optimize_inference(requirements),'monitoring_setup': self.setup_monitoring(requirements)}class PromptEngineer:"""提示工程師:AI交互專家"""responsibilities = ["設計高效的提示模板","優化AI輸出質量","構建提示管理系統","訓練團隊提示技巧"]def optimize_prompt_for_task(self, task, current_prompt, performance_metrics):# A/B測試不同提示版本prompt_variants = self.generate_prompt_variants(current_prompt)best_prompt = self.test_prompts(prompt_variants, task, performance_metrics)return {'optimized_prompt': best_prompt,'performance_improvement': self.calculate_improvement(),'recommended_usage': self.generate_usage_guidelines()}class AIProductManager:"""AI產品經理:AI產品策略專家"""responsibilities = ["定義AI產品功能","評估AI能力與業務需求匹配度","管理AI產品路線圖","協調技術團隊和業務團隊"]def evaluate_ai_feasibility(self, product_idea):return {'technical_feasibility': self.assess_technical_feasibility(product_idea),'data_requirements': self.analyze_data_needs(product_idea),'cost_estimation': self.estimate_development_cost(product_idea),'timeline': self.create_development_timeline(product_idea)}
AI技術選型指南:什么場景用什么技術?
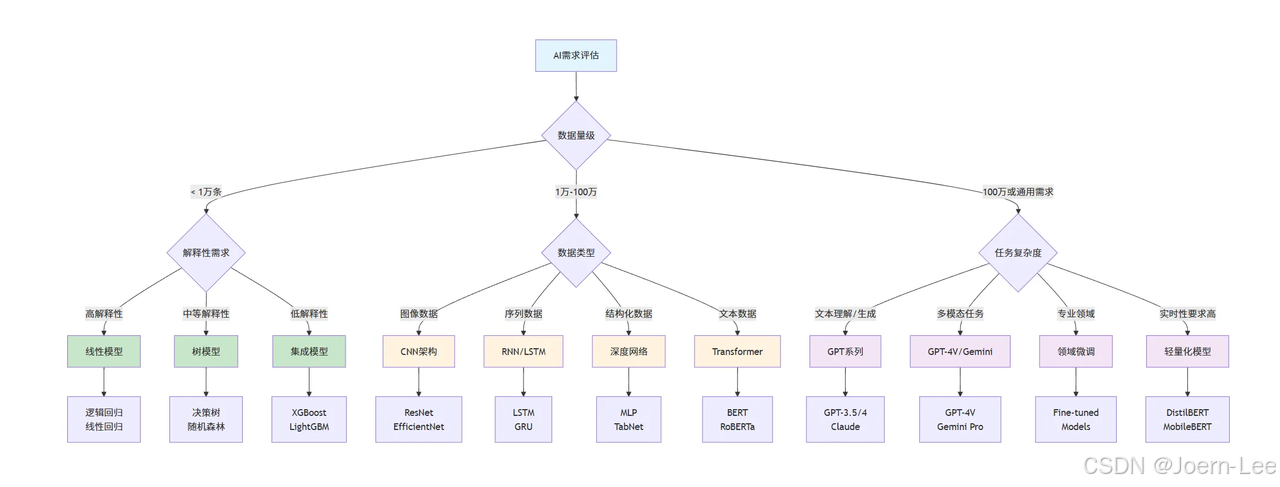
詳細技術選型矩陣
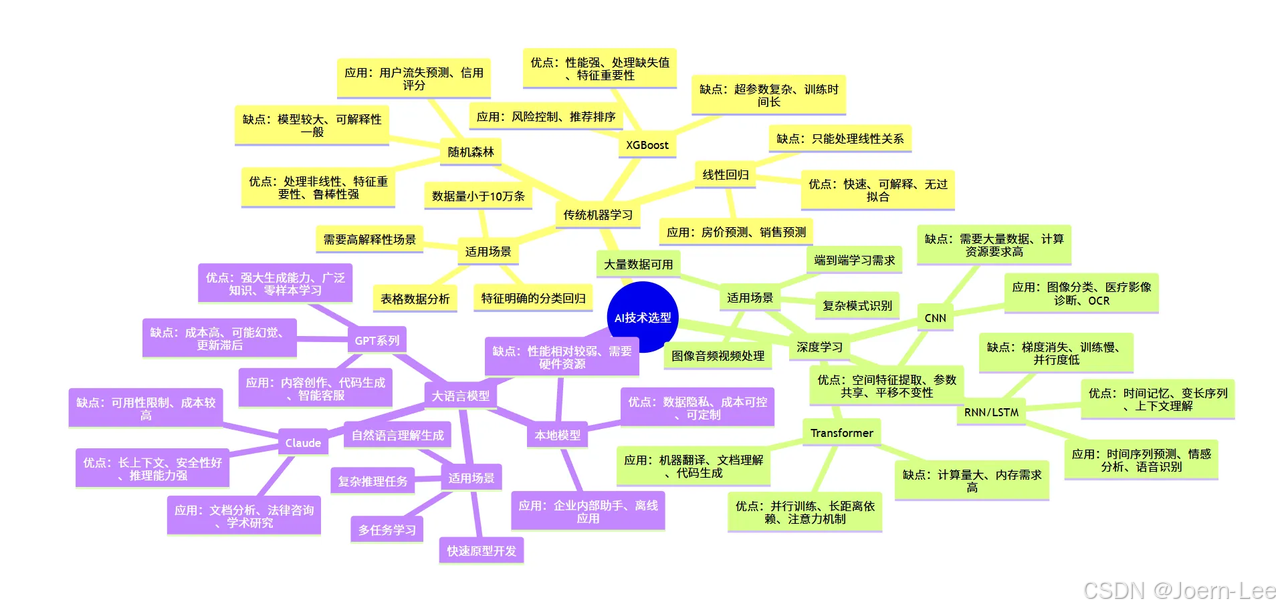
class TechnologySelector:def __init__(self):self.selection_matrix = {'traditional_ml': {'best_for': ['表格數據分析','特征明確的分類/回歸','需要高解釋性的場景','數據量<10萬條'],'algorithms': {'linear_regression': {'use_case': '簡單回歸預測','pros': ['快速', '可解釋', '無過擬合風險'],'cons': ['只能處理線性關系'],'example': '房價預測、銷售預測'},'random_forest': {'use_case': '復雜分類問題','pros': ['處理非線性', '特征重要性', '魯棒性強'],'cons': ['模型較大', '可解釋性一般'],'example': '用戶流失預測、信用評分'},'xgboost': {'use_case': '競賽級表格數據','pros': ['性能強', '處理缺失值', '特征重要性'],'cons': ['超參數復雜', '訓練時間長'],'example': '風險控制、推薦排序'}}},'deep_learning': {'best_for': ['圖像/音頻/視頻處理','復雜模式識別','大量數據可用','端到端學習需求'],'architectures': {'cnn': {'use_case': '計算機視覺任務','pros': ['空間特征提取', '參數共享', '平移不變性'],'cons': ['需要大量數據', '計算資源要求高'],'example': '圖像分類、醫療影像診斷、OCR'},'rnn_lstm': {'use_case': '序列數據處理','pros': ['時間記憶', '變長序列', '上下文理解'],'cons': ['梯度消失', '訓練慢', '并行度低'],'example': '時間序列預測、情感分析、語音識別'},'transformer': {'use_case': 'NLP和多模態任務','pros': ['并行訓練', '長距離依賴', '注意力機制'],'cons': ['計算量大', '內存需求高'],'example': '機器翻譯、文檔理解、代碼生成'}}},'large_language_models': {'best_for': ['自然語言理解/生成','復雜推理任務','多任務學習','快速原型開發'],'models': {'gpt_family': {'use_case': '通用文本生成和理解','pros': ['強大的生成能力', '廣泛的知識', '零樣本學習'],'cons': ['成本高', '可能幻覺', '更新滯后'],'example': '內容創作、代碼生成、智能客服'},'claude': {'use_case': '長文檔分析和推理','pros': ['長上下文', '安全性好', '推理能力強'],'cons': ['可用性限制', '成本較高'],'example': '文檔分析、法律咨詢、學術研究'},'local_models': {'use_case': '私有化部署需求','pros': ['數據隱私', '成本可控', '可定制'],'cons': ['性能相對較弱', '需要硬件資源'],'example': '企業內部助手、離線應用'}}}}def recommend_technology(self, requirements):"""基于需求推薦技術方案"""data_size = requirements.get('data_size', 0)data_type = requirements.get('data_type', 'structured')performance_requirement = requirements.get('performance', 'medium')interpretability_need = requirements.get('interpretability', 'medium')budget = requirements.get('budget', 'medium')latency_requirement = requirements.get('latency', 'medium')recommendations = []# 基于數據量初步篩選if data_size < 10000:category = 'traditional_ml'elif data_size < 1000000 and data_type in ['image', 'audio', 'sequence']:category = 'deep_learning'else:category = 'large_language_models'# 詳細推薦邏輯if category == 'traditional_ml':if interpretability_need == 'high':recommendations.append({'technology': 'Linear Regression/Logistic Regression','reason': '高可解釋性,適合需要理解模型決策的場景','implementation_effort': 'Low','cost': 'Low'})else:recommendations.append({'technology': 'XGBoost/Random Forest','reason': '平衡性能和復雜度,適合表格數據','implementation_effort': 'Medium','cost': 'Low'})elif category == 'deep_learning':if data_type == 'image':recommendations.append({'technology': 'CNN (ResNet/EfficientNet)','reason': '圖像處理的最佳選擇','implementation_effort': 'High','cost': 'Medium'})elif data_type == 'text':recommendations.append({'technology': 'Transformer (BERT/RoBERTa)','reason': '文本理解的強大架構','implementation_effort': 'High','cost': 'Medium'})else: # large_language_modelsif budget == 'high' and performance_requirement == 'high':recommendations.append({'technology': 'GPT-4/Claude-3','reason': '最強性能,適合復雜任務','implementation_effort': 'Low','cost': 'High'})else:recommendations.append({'technology': 'GPT-3.5/Local Models','reason': '性價比平衡,適合大多數場景','implementation_effort': 'Low','cost': 'Medium'})return recommendations
實際案例分析
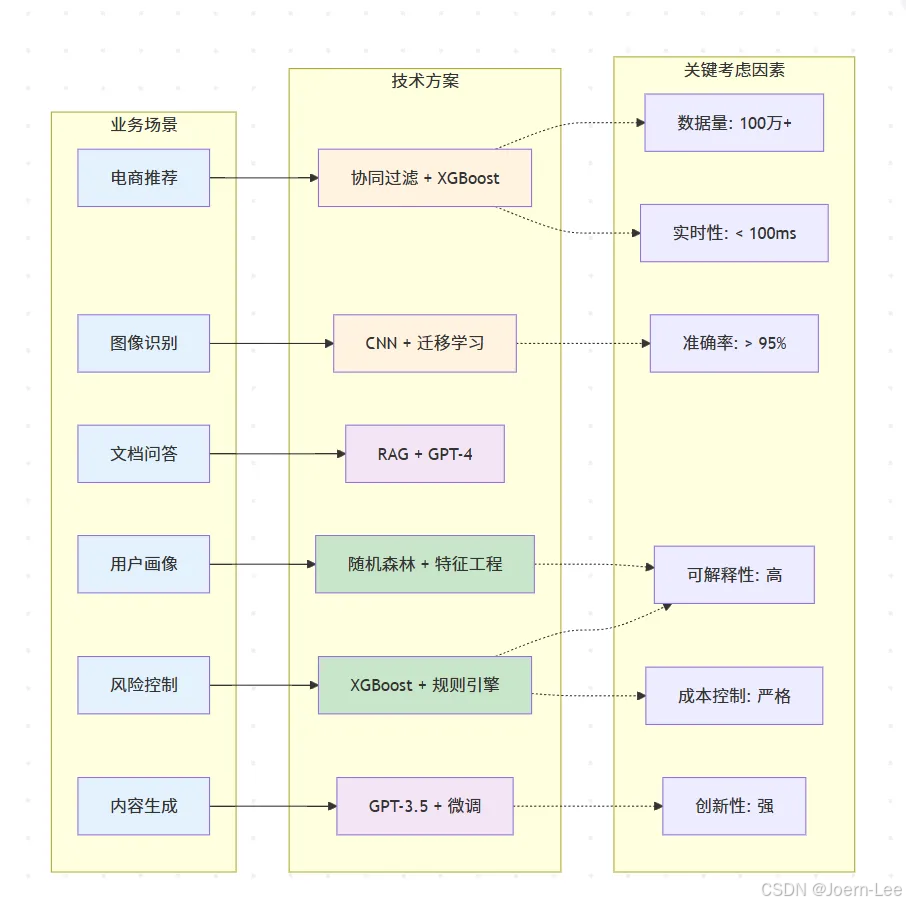
class EcommerceAISelector:def __init__(self):self.platform_scenarios = {'product_recommendation': {'description': '個性化商品推薦系統','data_characteristics': {'user_behavior_logs': '每日100萬+條','product_catalog': '50萬商品','user_profiles': '1000萬用戶','interaction_matrix': '稀疏矩陣,填充率<1%'},'business_requirements': {'accuracy': '點擊率提升30%以上','latency': '<100ms響應時間','scalability': '支持雙11流量峰值','interpretability': '需要解釋推薦理由'}},'image_search': {'description': '商品圖像搜索與識別','data_characteristics': {'product_images': '500萬張高清圖片','user_uploads': '每日10萬張搜索圖片','categories': '3000個細分類目','attributes': '顏色、款式、材質等多維屬性'},'business_requirements': {'accuracy': '圖像匹配準確率>90%','speed': '圖像檢索<200ms','coverage': '支持所有商品類目','user_experience': '支持拍照搜索功能'}},'customer_service': {'description': '智能客服問答系統','data_characteristics': {'historical_qa': '100萬條客服對話記錄','product_knowledge': '商品詳情、政策文檔','daily_inquiries': '5萬條客戶咨詢','languages': '中英文雙語支持'},'business_requirements': {'resolution_rate': '80%問題自動解決','response_time': '<3秒響應','accuracy': '答案準確率>95%','escalation': '復雜問題無縫轉人工'}},'price_optimization': {'description': '動態定價策略優化','data_characteristics': {'historical_sales': '2年銷售數據','competitor_prices': '競品價格監控','market_factors': '季節性、促銷、庫存等','user_segments': '不同用戶群體價格敏感度'},'business_requirements': {'profit_optimization': '毛利率提升5%','market_competitiveness': '保持價格競爭力','real_time': '實時價格調整','compliance': '符合定價法規'}},'fraud_detection': {'description': '交易欺詐檢測系統','data_characteristics': {'transaction_records': '每日200萬筆交易','fraud_samples': '0.1%欺詐率(極不平衡)','user_behavior': '登錄、瀏覽、購買行為','device_info': '設備指紋、IP地址等'},'business_requirements': {'recall_rate': '欺詐檢出率>99%','false_positive': '誤報率<1%','real_time': '交易時實時判斷','explainability': '風控決策可解釋'}}}def analyze_scenario(self, scenario_name):scenario = self.platform_scenarios[scenario_name]if scenario_name == 'product_recommendation':return self.recommendation_system_analysis()elif scenario_name == 'image_search':return self.image_search_analysis()elif scenario_name == 'customer_service':return self.customer_service_analysis()elif scenario_name == 'price_optimization':return self.price_optimization_analysis()elif scenario_name == 'fraud_detection':return self.fraud_detection_analysis()def recommendation_system_analysis(self):return {'scenario': '個性化商品推薦系統','challenge': '從千萬級商品中為用戶推薦感興趣的商品','technology_options': {'traditional_ml': {'approach': '協同過濾 + XGBoost','pros': ['成熟穩定,易于理解','冷啟動問題有成熟解決方案','推薦理由可解釋','計算成本可控'],'cons': ['難以捕捉復雜用戶偏好','特征工程工作量大','對新用戶新商品效果有限'],'implementation': '''# 協同過濾 + 特征工程features = ['user_age', 'user_gender', 'purchase_history','category_preference', 'brand_preference','price_sensitivity', 'seasonal_pattern']model = XGBRanker()'''},'deep_learning': {'approach': 'Deep Crossing + Wide&Deep','pros': ['自動學習用戶商品交互','處理高維稀疏特征','捕捉非線性關系','支持多任務學習'],'cons': ['訓練復雜,需要GPU資源','黑盒模型,解釋性差','冷啟動仍是挑戰'],'implementation': '''# Wide&Deep 架構wide_part = linear_features # 記憶能力deep_part = dnn_features # 泛化能力output = wide_part + deep_part'''},'llm_enhanced': {'approach': 'LLM + RAG + 傳統推薦','pros': ['理解商品語義信息','生成個性化推薦理由','支持自然語言查詢','快速適配新場景'],'cons': ['API調用成本高','響應時間可能較長','需要商品知識庫建設'],'implementation': '''# 混合推薦架構candidates = traditional_recommender.get_candidates(user)enhanced_candidates = llm.enrich_with_reasons(candidates, user_profile)final_ranking = llm.personalized_ranking(enhanced_candidates)'''}},'recommended_solution': {'primary': 'Deep Learning (Wide&Deep)','reasoning': ['數據量充足,適合深度學習','用戶行為復雜,需要強特征學習能力','性能要求高,深度學習效果最優'],'architecture': '''用戶特征 + 商品特征 + 上下文特征↓Wide部分(線性組合) + Deep部分(DNN)↓融合層 + 排序層↓Top-K推薦結果''','fallback_strategy': '傳統協同過濾作為baseline和異常情況fallback'}}def image_search_analysis(self):return {'scenario': '商品圖像搜索與識別','challenge': '用戶上傳圖片搜索相似商品','technology_comparison': {'traditional_cv': {'approach': 'SIFT/ORB特征 + 傳統匹配','verdict': '? 不推薦','reason': '無法理解商品語義,只能做像素級匹配'},'cnn_architecture': {'approach': 'ResNet/EfficientNet + 向量檢索','verdict': '? 強烈推薦','reason': '圖像任務最佳選擇,性能和成本平衡'},'multimodal_llm': {'approach': 'GPT-4V + 商品描述生成','verdict': '?? 輔助使用','reason': '成本過高,但可用于商品屬性提取'}},'detailed_solution': {'core_architecture': 'CNN特征提取 + 向量數據庫','implementation_plan': ['1. 預訓練CNN模型在商品數據上微調','2. 提取所有商品圖像的特征向量','3. 構建高效的向量檢索系統','4. 用戶圖片實時特征提取和匹配','5. 結合商品屬性進行結果優化'],'technology_stack': {'model': 'EfficientNet-B4微調版本','vector_db': 'Faiss/Pinecone向量檢索','serving': 'TensorRT模型加速','caching': 'Redis緩存熱門搜索'},'performance_optimization': ['模型量化減少推理時間','特征向量預計算','多級檢索策略(粗篩+精排)','CDN加速圖片加載']}}def customer_service_analysis(self):return {'scenario': '智能客服問答系統','challenge': '自動回答客戶關于商品、訂單、售后的問題','evolution_path': {'v1_rule_based': {'approach': '關鍵詞匹配 + 決策樹','coverage': '30%問題覆蓋率','limitation': '無法理解復雜表達'},'v2_intent_classification': {'approach': 'BERT意圖分類 + 模板回復','coverage': '60%問題覆蓋率','limitation': '回復模板化,用戶體驗一般'},'v3_rag_enhanced': {'approach': 'RAG系統 + LLM生成','coverage': '85%問題覆蓋率','advantage': '自然對話,個性化回復'}},'recommended_architecture': {'system_design': '''用戶問題↓意圖識別(BERT) → 簡單問題直接回答↓知識檢索(RAG) → 獲取相關商品/政策信息↓LLM生成回答 → 基于檢索內容生成個性化回復↓置信度評估 → 低置信度轉人工客服''','knowledge_base': ['商品信息庫:詳細商品參數、使用說明','政策文檔庫:退換貨、配送、售后政策','常見問題庫:FAQ和標準回答','歷史對話庫:優質客服對話記錄'],'quality_control': ['多輪對話上下文理解','情感分析識別用戶情緒','敏感內容過濾','回答質量實時評分']}}def fraud_detection_analysis(self):return {'scenario': '交易欺詐檢測系統','challenge': '在極不平衡數據中識別欺詐交易','data_challenge': {'class_imbalance': '欺詐樣本僅占0.1%','feature_complexity': '用戶行為特征維度高','real_time_requirement': '毫秒級決策要求','cost_asymmetry': '漏檢成本遠高于誤報'},'solution_evolution': {'traditional_rules': {'approach': '基于專家經驗的規則引擎','pros': ['可解釋性強', '響應快'],'cons': ['規則維護困難', '容易被繞過'],'use_case': '基礎風控規則'},'ml_enhanced': {'approach': '特征工程 + XGBoost/Random Forest','pros': ['性能提升顯著', '特征重要性可解釋'],'cons': ['特征工程工作量大', '需要持續調優'],'use_case': '主要風控模型'},'deep_learning': {'approach': '深度神經網絡 + Embedding','pros': ['自動特征學習', '捕捉復雜模式'],'cons': ['黑盒模型', '解釋性差'],'use_case': '復雜欺詐模式檢測'},'llm_assisted': {'approach': 'LLM分析異常行為描述','pros': ['理解行為語義', '輔助規則生成'],'cons': ['成本高', '不適合實時'],'use_case': '案例分析和規則優化'}},'hybrid_architecture': {'real_time_layer': '輕量級規則 + 簡單ML模型(<10ms)','batch_analysis': '復雜特征工程 + 深度學習模型','llm_enhancement': 'LLM輔助新規則發現和案例分析','human_in_loop': '高風險案例人工審核','implementation': '''交易請求↓實時規則引擎 → 明顯欺詐直接攔截↓輕量ML模型 → 風險評分↓動態閾值判斷 → 通過/攔截/人工審核↓離線深度分析 → 模型持續優化'''}}
錯誤選擇的反面案例
class AntiPatterns:def llm_for_simple_tasks(self):"""反例:用大模型做簡單任務"""return {'bad_example': {'task': '判斷郵箱地址格式是否正確','bad_solution': '調用GPT-4 API判斷','problems': ['成本高:每次調用$0.03','延遲高:網絡請求+推理時間','不穩定:可能出現格式變化','過度復雜:殺雞用牛刀']},'good_solution': {'method': '正則表達式驗證','code': '''import redef validate_email(email):pattern = r'^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}$'return re.match(pattern, email) is not None''','benefits': ['成本:幾乎為0','延遲:微秒級','可靠:100%確定性','簡單:易于理解和維護']}}def traditional_ml_for_complex_nlp(self):"""反例:用傳統ML做復雜NLP"""return {'bad_example': {'task': '多輪對話理解和生成','bad_solution': '樸素貝葉斯+規則引擎','problems': ['上下文丟失:無法記住對話歷史','泛化能力差:無法處理新表達方式','維護噩夢:規則越來越復雜','用戶體驗差:回復生硬不自然']},'good_solution': {'method': '對話生成模型或LLM API','reason': '復雜NLP任務需要深度理解能力','implementation': '使用ChatGPT API或fine-tune對話模型'}}
好的!"未來展望"章節確實應該更多地用描述性語言來展示趨勢和愿景,我來重新改寫這部分:
未來展望:AI-First 的軟件開發
軟件開發范式的根本性轉變
我們正在經歷軟件開發歷史上的第四次重大范式轉變:從機器語言到匯編語言,從匯編到高級語言,從高級語言到框架/平臺化開發,現在進入AI-First的智能化開發時代。
在這個新時代,開發者的角色正在從"代碼編寫者"轉變為"AI工作流設計者" 。我們不再需要從零開始編寫每一行代碼,而是要學會如何設計和編排AI能力,讓機器成為我們的編程伙伴。
開發工具的智能化演進
智能代碼助手的進化路徑:
- 當前階段:代碼補全和生成(如GitHub Copilot)
- 近期發展:上下文感知的架構建議和重構方案
- 未來愿景:理解業務需求,自動生成完整的功能模塊
開發環境的變革: 傳統的IDE正在進化為AI增強的開發環境。想象一下,當你描述一個功能需求時,IDE不僅能生成代碼,還能自動進行測試、優化性能、檢查安全漏洞,甚至預測用戶體驗問題。
低代碼/無代碼平臺的AI化革命
AI技術正在讓低代碼平臺變得真正"智能":
自然語言編程成為現實: 開發者可以用自然語言描述復雜的業務邏輯,AI系統理解意圖后自動生成相應的工作流和代碼。這不是簡單的模板填充,而是真正理解業務語義的智能轉換。
可視化開發的新高度: AI可以理解設計稿、業務流程圖,甚至是草圖,自動生成對應的應用架構和實現代碼。設計到開發的鴻溝正在被AI填平。
開發團隊協作模式的演變
人機協作的新模式:
- AI作為初級開發者:處理重復性工作、代碼重構、測試用例生成
- 人類專注高價值工作:架構設計、產品創新、用戶體驗優化
- AI作為實時導師:提供最佳實踐建議、性能優化方案、安全檢查
代碼審查的智能化: AI不僅能檢查語法錯誤,還能理解代碼邏輯,提供架構層面的改進建議,甚至預測代碼的可維護性和擴展性問題。
軟件質量和安全的新標準
AI驅動的質量保證: 未來的軟件開發將默認集成AI質量檢查。從代碼編寫到部署上線,AI系統持續監控和優化軟件質量,自動發現和修復潛在問題。
智能化的安全防護: AI能夠理解代碼的業務邏輯,發現傳統靜態分析工具無法檢測的業務邏輯漏洞,為軟件安全提供更深層的保護。
開發者技能的重新定義
新的核心能力要求:
- AI工作流設計能力:如何有效組合AI工具解決復雜問題
- 提示工程精通度:與AI進行高效溝通的藝術
- 跨模態思維:整合文本、圖像、音頻等多種信息形式
- 業務理解深度:更多時間專注于理解和優化業務價值
持續學習的新模式: 在AI-First的時代,技術更新速度加快,開發者需要建立與AI協同的持續學習機制。AI不僅是工具,更是我們的學習伙伴和知識擴展器。
軟件產品形態的變革
AI-Native應用的崛起: 未來的軟件產品將天生具備AI能力,不再是"傳統軟件+AI功能"的組合,而是以AI為核心架構設計的全新產品形態。
個性化程度的極致提升: 每個用戶看到的界面、功能和交互方式都可能不同,AI根據用戶行為和偏好實時調整產品體驗。
這個AI-First的未來并不遙遠,它正在悄然改變我們的工作方式。作為開發者,擁抱這個變化,學會與AI協作,將是我們在新時代保持競爭力的關鍵。
寫在最后:擁抱AI,成為更好的開發者
這四篇文章帶我們走過了一段完整的AI學習之旅:
- 第一篇建立了AI的整體認知框架
- 第二篇深入理解了機器學習的實際應用
- 第三篇探索了深度學習的技術原理
- 第四篇展望了大模型時代的開發新范式
核心啟示:
- AI不是威脅,而是增強器:它讓我們從重復性工作中解放出來,專注于更有創造性的任務
- 技術選型要理性:不是所有問題都需要最先進的技術,選擇合適的技術才是最優解
- 學習永無止境:AI技術發展很快,保持好奇心和學習能力比掌握任何具體技術都重要
- 人機協作是未來:未來的開發者不是被AI替代,而是學會與AI協作的開發者
行動建議:
- 立即開始:選擇一個AI工具(如Cursor),在日常工作中使用
- 深入實踐:選擇一個項目,嘗試集成AI能力
- 持續學習:關注AI技術發展,定期嘗試新工具
- 分享交流:與團隊分享AI使用經驗,共同成長
記住:在AI時代,最重要的不是擔心被替代,而是 學會如何利用AI成為更強的自己。
讓我們一起擁抱這個激動人心的時代,用AI的力量創造更美好的數字世界!
系列完結
感謝陪伴我們走過這段AI學習之旅。愿每位開發者都能在AI時代找到屬于自己的位置,用技術的力量改變自己、團隊與世界。
st 的軟件開發
軟件開發范式的根本性轉變
我們正在經歷軟件開發歷史上的第四次重大范式轉變:從機器語言到匯編語言,從匯編到高級語言,從高級語言到框架/平臺化開發,現在進入AI-First的智能化開發時代。
在這個新時代,開發者的角色正在從"代碼編寫者"轉變為"AI工作流設計者" 。我們不再需要從零開始編寫每一行代碼,而是要學會如何設計和編排AI能力,讓機器成為我們的編程伙伴。
開發工具的智能化演進
智能代碼助手的進化路徑:
- 當前階段:代碼補全和生成(如GitHub Copilot)
- 近期發展:上下文感知的架構建議和重構方案
- 未來愿景:理解業務需求,自動生成完整的功能模塊
開發環境的變革: 傳統的IDE正在進化為AI增強的開發環境。想象一下,當你描述一個功能需求時,IDE不僅能生成代碼,還能自動進行測試、優化性能、檢查安全漏洞,甚至預測用戶體驗問題。
低代碼/無代碼平臺的AI化革命
AI技術正在讓低代碼平臺變得真正"智能":
自然語言編程成為現實: 開發者可以用自然語言描述復雜的業務邏輯,AI系統理解意圖后自動生成相應的工作流和代碼。這不是簡單的模板填充,而是真正理解業務語義的智能轉換。
可視化開發的新高度: AI可以理解設計稿、業務流程圖,甚至是草圖,自動生成對應的應用架構和實現代碼。設計到開發的鴻溝正在被AI填平。
開發團隊協作模式的演變
人機協作的新模式:
- AI作為初級開發者:處理重復性工作、代碼重構、測試用例生成
- 人類專注高價值工作:架構設計、產品創新、用戶體驗優化
- AI作為實時導師:提供最佳實踐建議、性能優化方案、安全檢查
代碼審查的智能化: AI不僅能檢查語法錯誤,還能理解代碼邏輯,提供架構層面的改進建議,甚至預測代碼的可維護性和擴展性問題。
軟件質量和安全的新標準
AI驅動的質量保證: 未來的軟件開發將默認集成AI質量檢查。從代碼編寫到部署上線,AI系統持續監控和優化軟件質量,自動發現和修復潛在問題。
智能化的安全防護: AI能夠理解代碼的業務邏輯,發現傳統靜態分析工具無法檢測的業務邏輯漏洞,為軟件安全提供更深層的保護。
開發者技能的重新定義
新的核心能力要求:
- AI工作流設計能力:如何有效組合AI工具解決復雜問題
- 提示工程精通度:與AI進行高效溝通的藝術
- 跨模態思維:整合文本、圖像、音頻等多種信息形式
- 業務理解深度:更多時間專注于理解和優化業務價值
持續學習的新模式: 在AI-First的時代,技術更新速度加快,開發者需要建立與AI協同的持續學習機制。AI不僅是工具,更是我們的學習伙伴和知識擴展器。
軟件產品形態的變革
AI-Native應用的崛起: 未來的軟件產品將天生具備AI能力,不再是"傳統軟件+AI功能"的組合,而是以AI為核心架構設計的全新產品形態。
個性化程度的極致提升: 每個用戶看到的界面、功能和交互方式都可能不同,AI根據用戶行為和偏好實時調整產品體驗。
這個AI-First的未來并不遙遠,它正在悄然改變我們的工作方式。作為開發者,擁抱這個變化,學會與AI協作,將是我們在新時代保持競爭力的關鍵。
寫在最后:擁抱AI,成為更好的開發者
這四篇文章帶我們走過了一段完整的AI學習之旅:
- 第一篇建立了AI的整體認知框架
- 第二篇深入理解了機器學習的實際應用
- 第三篇探索了深度學習的技術原理
- 第四篇展望了大模型時代的開發新范式
核心啟示:
- AI不是威脅,而是增強器:它讓我們從重復性工作中解放出來,專注于更有創造性的任務
- 技術選型要理性:不是所有問題都需要最先進的技術,選擇合適的技術才是最優解
- 學習永無止境:AI技術發展很快,保持好奇心和學習能力比掌握任何具體技術都重要
- 人機協作是未來:未來的開發者不是被AI替代,而是學會與AI協作的開發者
行動建議:
- 立即開始:選擇一個AI工具(如Cursor),在日常工作中使用
- 深入實踐:選擇一個項目,嘗試集成AI能力
- 持續學習:關注AI技術發展,定期嘗試新工具
- 分享交流:與團隊分享AI使用經驗,共同成長
記住:在AI時代,最重要的不是擔心被替代,而是 學會如何利用AI成為更強的自己。
讓我們一起擁抱這個激動人心的時代,用AI的力量創造更美好的數字世界!
系列完結
感謝陪伴我們走過這段AI學習之旅。愿每位開發者都能在AI時代找到屬于自己的位置,用技術的力量改變自己、團隊與世界。







)


)








