在人工智能飛速發展的今天,大語言模型(如GPT系列)正改變著我們構建應用的方式。但如何將這些先進模型無縫集成到企業級Java應用中?這正是LangChain框架的強項——它簡化了語言模型的調用、鏈式處理和上下文管理,讓開發者專注于業務邏輯。本教程將帶您從零開始,實戰入門Java與LangChain的結合,一步步構建高效、可擴展的大語言模型應用。
在本教程中,我們將詳細探討 LangChain,一個用于開發基于語言模型的應用程序的框架。我們將首先了解語言模型的基礎概念,這些知識將對本教程有所幫助。
盡管 LangChain 主要提供 Python 和 JavaScript/TypeScript 版本,但也可以在 Java 中使用 LangChain。我們會討論 LangChain 作為框架的構建模塊,然后嘗試在 Java 中進行實驗。
2. 背景
在深入探討為什么需要一個用于構建基于語言模型的應用程序的框架之前,我們需要弄清楚語言模型是什么,并了解使用語言模型時可能遇到的一些典型復雜性。
2.1. 大型語言模型
語言模型是自然語言的概率模型,可以生成一系列單詞的概率。大型語言模型(LLM)則是以其規模龐大而著稱,通常包含數十億參數的人工神經網絡。
大型語言模型通常通過在大量未標記數據上進行預訓練,使用自監督學習和弱監督學習技術。之后,通過微調和提示詞工程等技術將預訓練模型適配于特定任務:
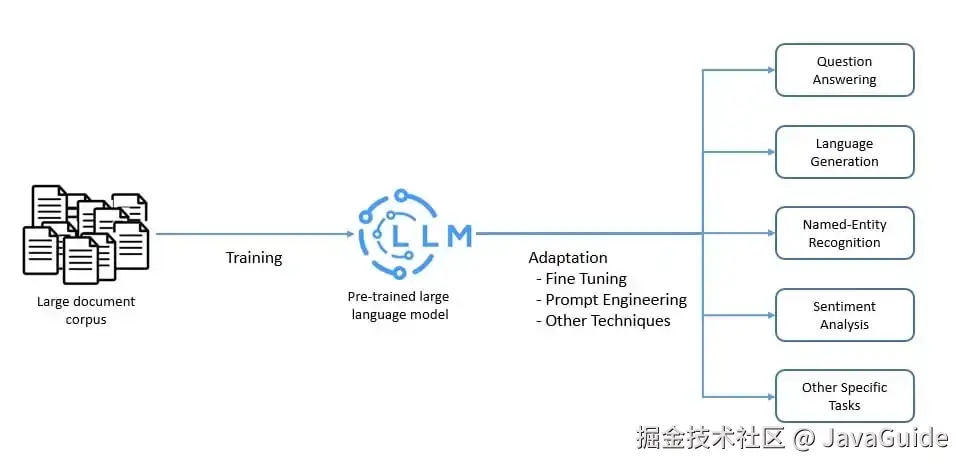
大型語言模型可以執行多種自然語言處理任務,如語言翻譯、內容摘要等。此外,它們還具備生成內容的能力,因此在回答問題等應用場景中非常有用。
幾乎所有主流云服務提供商都在其服務中引入了大型語言模型。例如,Microsoft Azure 提供了 Llama 2 和 OpenAI GPT-4,Amazon Bedrock 提供了 AI21 Labs、Anthropic、Cohere、Meta 和 Stability AI 的模型。
2.2. 提示詞工程
大型語言模型是一種基礎模型,經過大規模文本數據的訓練后,可以捕捉人類語言的語法和語義。然而,為了讓模型執行特定任務,它們需要進一步調整。
提示詞工程(Prompt engineering)是讓語言模型完成特定任務的最快捷方法之一。它通過結構化文本向模型描述任務目標,使其能夠理解并執行任務:

提示詞幫助大型語言模型執行上下文學習,這種學習是暫時的。通過提示詞工程,我們可以促進大型語言模型的安全使用,并構建新的功能,比如將領域知識和外部工具整合到模型中。
這一領域目前是一個活躍的研究方向,不斷涌現新的技術。然而,諸如 鏈式思維提示 等技術已經變得頗為流行。這種方法的核心是讓大型語言模型在給出最終答案之前,將問題分解為一系列中間步驟。
2.3. 詞向量
如前所述,大型語言模型能夠高效處理自然語言。如果我們將自然語言中的單詞表示為詞向量(Word Embeddings ),模型的性能將顯著提升。詞向量是能夠編碼單詞語義的實值向量。
詞向量通常通過算法生成,例如 Word2vec 或 GloVe。
GloVe 是一種無監督學習算法,在語料庫的全局詞共現統計上進行訓練:

在提示詞工程中,我們將提示轉換成詞向量,這使得模型更容易理解和響應提示。此外,它也對增強我們提供給模型的上下文非常有幫助,從而使模型能夠給出更具上下文意義的回答。
例如,我們可以從現有數據集中生成詞向量并將其存儲在向量數據庫中。然后,我們可以使用用戶提供的輸入在向量數據庫中執行語義搜索,并將搜索結果作為附加上下文提供給模型。
3. 使用 LangChain 構建 LLM 技術棧
正如我們已經了解的那樣,創建有效的提示詞是成功利用 LLM 的關鍵元素。這包括使與語言模型的交互具有上下文感知能力,并依賴語言模型進行推理。
為此,我們需要執行多項任務,例如為提示詞創建模板、調用語言模型,以及從多種來源提供用戶特定數據。為了簡化這些任務,我們需要一個像 LangChain 這樣的框架作為 LLM 技術棧的一部分:

該框架還幫助開發需要鏈式調用多個語言模型的應用程序,并能夠回憶起過去與語言模型過去交互的信息。此外,還有更復雜的用例,例如將語言模型用作推理引擎。
最后,我們可以執行日志記錄、監控、流式處理以及其他重要的維護和故障排除任務。LLM 技術棧正在快速發展以應對許多此類問題,而 LangChain 正迅速成為 LLM 技術棧的寶貴組成部分。
4. 面向 Java 的 LangChain
LangChain 于 2022 年作為開源項目推出,憑借社區支持迅速發展壯大。最初是由 Harrison Chase 開發的 Python 項目,后來成為 AI 領域增長最快的初創企業之一。
隨后,JavaScript/TypeScript 版本的 LangChain 于 2023 年初推出,并迅速流行起來,支持多個 JavaScript 環境,如 Node.js、瀏覽器、CloudFlare workers、Vercel/Next.js、Deno 和 Supabase Edge functions。
然而,目前沒有官方的 Java 版本 LangChain 可供 Java 或 Spring 應用使用。不過,社區開發了 Java 版本 LangChain,稱為 LangChain4j ,支持 Java 8 或更高版本,并兼容 Spring Boot 2 和 3。
LangChain 的各種依賴項可以在 Maven Central 上找到。根據我們使用的功能,可能需要在應用程序中添加一個或多個依賴項:
<dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j</artifactId> <version>0.23.0</version> </dependency>
5. LangChain 的構建模塊
LangChain 為我們的應用程序提供了多種價值主張,這些功能以模塊化組件的形式提供。模塊化組件不僅提供了有用的抽象,還包含了一系列操作語言模型的實現。接下來,我們將通過 Java 示例來討論其中的一些模塊。
5.1. 模型輸入/輸出(Models I/O)
在使用任何語言模型時,我們需要具備與其交互的能力。LangChain 提供了必要的構建模塊,例如模板化提示的能力,以及動態選擇和管理模型輸入的能力。此外,我們還可以使用輸出解析器從模型輸出中提取信息:

提示模板(Prompt Templates)是用于生成語言模型提示的預定義配方,可以包括指令、少樣本示例和特定上下文:
PromptTemplate promptTemplate = PromptTemplate .from("Tell me a {{adjective}} joke about {{content}}.."); Map<String, Object> variables = new HashMap<>(); variables.put("adjective", "funny"); variables.put("content", "computers"); Prompt prompt = promptTemplate.apply(variables);
5.2. 內存
通常,一個利用大型語言模型(LLM)的應用程序會有一個對話界面。對話的一個重要方面是能夠引用對話中先前的信息。這種存儲過去交互信息的能力稱為內存:

LangChain 提供了一些關鍵功能,可以為應用程序添加內存。例如,我們需要能夠從內存中讀取信息以增強用戶輸入,同時還需要將當前運行的輸入和輸出寫入內存:
ChatMemory chatMemory = TokenWindowChatMemory .withMaxTokens(300, new OpenAiTokenizer(GPT_3_5_TURBO)); chatMemory.add(userMessage("你好,我叫 Kumar")); AiMessage answer = model.generate(chatMemory.messages()).content(); System.out.println(answer.text()); // 你好 Kumar!今天我能為您做些什么? chatMemory.add(answer); chatMemory.add(userMessage("我叫什么名字?")); AiMessage answerWithName = model.generate(chatMemory.messages()).content(); System.out.println(answerWithName.text()); // 您的名字是 Kumar。 chatMemory.add(answerWithName);
在這里,我們使用 TokenWindowChatMemory 實現了固定窗口聊天內存,它允許我們讀取和寫入與語言模型交換的聊天消息。
LangChain 還提供更復雜的數據結構和算法,以便從內存中返回選定的消息, 而不是返回所有內容。例如,它支持返回過去幾條消息的摘要,或者僅返回與當前運行相關的消息。
5.3. 檢索(Retrieval)
大型語言模型通常是在大量的文本語料庫上進行訓練的。因此,它們在處理通用任務時表現得非常高效,但在處理特定領域任務時可能效果不佳。為了解決這一問題,我們需要在生成階段檢索相關的外部數據,并將其傳遞給語言模型。
這個過程被稱為檢索增強生成(Retrieval Augmented Generation,RAG)。RAG 有助于將模型的生成過程與相關且準確的信息結合,同時也讓我們更深入地了解模型的生成過程。LangChain 提供了構建 RAG 應用程序所需的核心組件:

首先,LangChain 提供了文檔加載器 FileSystemDocumentLoader,用于從存儲位置檢索文檔。然后,LangChain 還提供了轉換器,用于進一步處理文檔,例如將大型文檔分割成更小的塊:
Document document = FileSystemDocumentLoader.loadDocument("simpson's_adventures.txt"); DocumentSplitter splitter = DocumentSplitters.recursive(100, 0, new OpenAiTokenizer(GPT_3_5_TURBO)); List<TextSegment> segments = splitter.split(document);
在這里,我們使用 FileSystemDocumentLoader 從文件系統中加載文檔。然后使用 OpenAiTokenizer 將文檔分割成更小的段落。
為了提高檢索效率,這些文檔通常會被轉換成嵌入(embeddings),并存儲在向量數據庫中。LangChain 支持多種嵌入提供商和方法,并與幾乎所有主流的向量存儲集成:
EmbeddingModel embeddingModel = new AllMiniLmL6V2EmbeddingModel(); List<Embedding> embeddings = embeddingModel.embedAll(segments).content(); EmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>(); embeddingStore.addAll(embeddings, segments);
在這里,我們使用 AllMiniLmL6V2EmbeddingModel 為文檔段落創建嵌入,然后將嵌入存儲在內存中的向量存儲中。
現在,我們的外部數據已經以嵌入的形式存儲在向量存儲中,可以從中進行檢索。LangChain 支持多種檢索算法,例如簡單的語義搜索和更復雜的集成檢索器(ensemble retriever):
String question = "Who is Simpson?"; // 假設該問題的答案包含在我們之前處理的文檔中。 Embedding questionEmbedding = embeddingModel.embed(question).content(); int maxResults = 3; double minScore = 0.7; List<EmbeddingMatch<TextSegment>> relevantEmbeddings = embeddingStore .findRelevant(questionEmbedding, maxResults, minScore);
我們為用戶的問題生成嵌入,然后使用該問題的嵌入從向量存儲中檢索相關的匹配項。現在,我們可以將檢索到的相關內容作為上下文,添加到我們打算發送給模型的提示中。
6. LangChain 的復雜應用
到目前為止,我們已經了解了如何使用單個組件來創建一個基于語言模型的應用程序。LangChain 還提供了構建更復雜應用程序的組件。例如,我們可以使用鏈(Chains)和代理(Agents)來構建更加自適應、功能增強的應用程序。
6.1. 鏈(Chains)
通常,一個應用程序需要按特定順序調用多個組件。在 LangChain 中,這被稱為鏈(Chain)。鏈簡化了開發更復雜應用程序的過程,并使調試、維護和改進更加容易。
鏈還可以組合多個鏈來構建更復雜的應用程序,這些應用程序可能需要與多個語言模型交互。LangChain 提供了創建此類鏈的便捷方式,并內置了許多預構建鏈:
ConversationalRetrievalChain chain = ConversationalRetrievalChain.builder() .chatLanguageModel(chatModel) .retriever(EmbeddingStoreRetriever.from(embeddingStore, embeddingModel)) .chatMemory(MessageWindowChatMemory.withMaxMessages(10)) .promptTemplate(PromptTemplate .from("Answer the following question to the best of your ability: {{question}}\n\nBase your answer on the following information:\n{{information}}")) .build();
在這里,我們使用了預構建的鏈 ConversationalRetrievalChain,它允許我們將聊天模型與檢索器、內存和提示模板結合使用。現在,我們可以簡單地使用該鏈來執行用戶查詢:
String answer = chain.execute("Who is Simpson?");
該鏈提供了默認的內存和提示模板,我們可以根據需要進行覆蓋。創建自定義鏈也非常容易。鏈的能力使我們能夠更輕松地實現復雜應用程序的模塊化實現。
6.2. 代理(Agents)
LangChain 還提供了更強大的結構,例如代理(Agent)。與鏈不同,代理將語言模型用作推理引擎,以確定應該采取哪些操作以及操作的順序。我們還可以為代理提供訪問合適工具的權限,以執行必要的操作。
在 LangChain4j 中,代理作為 AI 服務(AI Services)提供,用于聲明性地定義復雜的 AI 行為。讓我們看看如何通過提供一個計算器工具,為 AI 服務賦能,從而使語言模型能夠執行計算。
首先,我們定義一個包含一些基本計算功能的類,并用自然語言描述每個函數,這樣模型可以理解:
public class AIServiceWithCalculator { static class Calculator { @Tool("Calculates the length of a string") int stringLength(String s) { return s.length(); } @Tool("Calculates the sum of two numbers") int add(int a, int b) { return a + b; } }
接下來,我們定義一個接口,用于構建我們的 AI 服務。這里的接口相對簡單,但也可以描述更復雜的行為:
interface Assistant { String chat(String userMessage); }
然后,我們使用 LangChain4j 提供的構建器工廠,通過定義的接口和工具創建一個 AI 服務:
Assistant assistant = AiServices.builder(Assistant.class) .chatLanguageModel(OpenAiChatModel.withApiKey(<OPENAI_API_KEY>)) .tools(new Calculator()) .chatMemory(MessageWindowChatMemory.withMaxMessages(10)) .build();
完成了!現在,我們可以向語言模型發送包含計算任務的問題:
String question = "What is the sum of the numbers of letters in the words \"language\" and \"model\"?"; String answer = assistant.chat(question); System.out.println(answer); // The sum of the numbers of letters in the words "language" and "model" is 13.
運行這段代碼后,我們會發現語言模型現在能夠執行計算。
需要注意的是,語言模型在執行某些任務時可能會遇到困難,例如需要時間和空間概念的任務或復雜的算術操作。然而,我們可以通過為模型提供必要的工具來解決這些問題。
7. 總結
在本教程中,我們探討了創建基于大型語言模型的應用程序的一些基本元素。此外,我們討論了將 LangChain 作為技術棧的一部分對開發此類應用程序的重要價值。
這使得我們能夠探索 LangChain 的 Java 版本 —— LangChain4j 的一些核心組件 。這些庫未來將快速發展,它們會讓開發由語言模型驅動的應用程序的過程變得更成熟和有趣!






)

插件生成ECharts圖片)





)

)

)
