背景
開發過程中發現機器指標異常,端口也hang住無響應,端口返回為timeout,對應探活檢測也失敗了。
現象
在st測試環節,突然每隔一段時間新接口就hang住無響應,觀察機器監控也發現端口探活失敗,看機器指標也無上報。
原因
開發新注入了bean,導致metaspace超出分配區間,頻繁fullgc導致機器無響應。
解決
定位到時metaspace分配不足,通過調大分配空間解決。
定位過程
一般定位方向有兩個,通過看機器指標就可以發現:
- cpu方面:有死循環或線程過多,導致cpu被占用無法響應其他請求。
- 內存方面:內存泄露導致頻繁gc或fullgc。
- 查看機器指標:查看發現業務cpu占用無明顯升高,有些許降低,元空間占用情況升高。
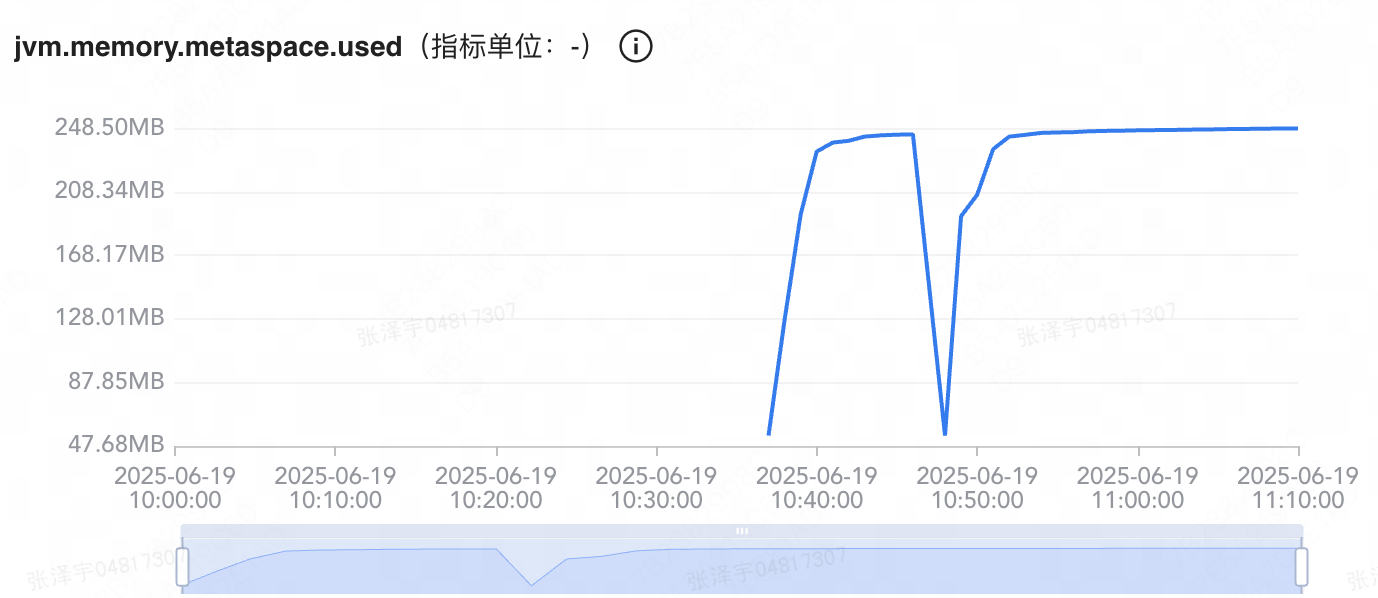
- 查看機器gc日志:發現機器一直在fullgc

- 查看機器堆棧dump信息:發現堆內存比分配的小得多,但gc日志顯示每次gc的減小量都很小。所以大概猜到是元空間的問題了。
- 查看應用的啟動參數,發現metaspace使用空間大于分配空間:應用啟動時會分配jvm的內存分配情況,參數是-XX:MaxMetaspaceSize=XXX。發現分配了256M,高的時候就占了250+M了,很明顯是新開發代碼新注入的bean導致的,通過增大元空間參數解決。
一些擴展知識
端口探活方式
- telnet <ip> <port>:telnet打通=端口通+網絡通。只能分析??服務是否起來 或? 網絡是否正常? 或? 是否有防火墻等類似問題。此時服務可能不可用,但端口是通的。
- nc -zv <ip> <port>:
-z?只掃描端口,不發送數據,-v?顯示詳細信息。端口存活會顯示 succeeded 或 open。 - 對于rpc框架,可以自定義端口的探活方式,通過服務端實現
healthCheck()?或ping()方法實現探活。
機器gc日志指標
- 開啟機器gc記錄的指令
jdk8之前:
-XX:+PrintGC
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-XX:+PrintGCTimeStamps
-Xloggc:/path/to/gc.logjdk8之后:
-Xlog:gc*:file=/path/to/gc.log:time,uptime,level,tags
- 機器gc日志存放位置:在Xloggc對應的路徑下
機器jvm內存使用情況
- 查看堆內存情況,每秒1次,輸出10次:jstat -heap <PID>?1000 10
- 查看metaspace情況:
jstat -gcmetacapacity <pid>
jstat內存輸出各指標含義:
| 指標 | 含義 |
|---|---|
| S0C | Survivor 0 區的容量(單位:KB) |
| S1C | Survivor 1 區的容量(單位:KB) |
| S0U | Survivor 0 區已使用空間(單位:KB) |
| S1U | Survivor 1 區已使用空間(單位:KB) |
| EC | Eden 區的容量(單位:KB) |
| EU | Eden 區已使用空間(單位:KB) |
| OC | Old 區(老年代)容量(單位:KB) |
| OU | Old 區(老年代)已使用空間(單位:KB) |
| PC | Perm 區(永久代)容量(單位:KB)(JDK8之前)或 Metaspace 容量(JDK8及以后,部分實現中) |
| PU | Perm 區(永久代)已使用空間(單位:KB)(JDK8之前)或 Metaspace 已用(JDK8及以后,部分實現中) |
| YGC | 從 JVM 啟動到采樣時發生的 Young GC(新生代GC)次數 |
| YGCT | 從 JVM 啟動到采樣時 Young GC 所用時間(單位:秒) |
| FGC | 從 JVM 啟動到采樣時發生的 Full GC(老年代GC)次數 |
| FGCT | 從 JVM 啟動到采樣時 Full GC 所用時間(單位:秒) |
| GCT | 從 JVM 啟動到采樣時 GC 總耗時(單位:秒),等于 YGCT + FGCT |
機器線程情況分析
堆棧dump指令,只能用來分析進程中的線程情況。
jstack -<PID>jstack的作用:jstack 是 JDK 自帶的一個非常重要的命令行工具,主要用于生成 Java 進程的線程快照(線程堆棧信息),幫助開發者排查和分析 Java 應用中的線程相關問題。但無法得到堆內存,元空間等內存信息。
metaspace
- 作用:是jdk8后取代永久代的空間,用于存放類的元數據(類結構,類方法,常量池等)。
- 監控的指令:
jmap -clstats <pid>jstat -gcmetacapacity <pid>





)






時報:證書過期 certificate has expired問題)






