????????前一節學習了運輸層依賴于網絡層的主機到主機的通信服務,提供各種形式的進程到進程的通信。了解這種主機到主機通信服務的真實情況,是什么使得它工作起來的。
? ? ? ? 在本章和下一章,將學習網絡層實際是怎樣實現主機到主機的通信服務。與運輸層和應用層不同的是,在網絡中的每一臺主機和路由器中都有一個網絡層部分。
? ? ? ? 網絡層在協議棧中是最復雜的層次。網絡層可以被分為解為兩個相互作用的部分,即數據平面和控制平面。第四章將學習網絡層的數據平面功能,即網絡層中每臺路由器的功能,該數據平面功能決定到達路由器輸入鏈路之一的數據報(網絡層的分組)如何轉發到該路由器輸出鏈路之一。?將涉及傳統的 IP 轉發(轉發基于數據報的目的地址)和通用的轉發(可以使用數據報首部中的幾個不同域的值執行轉發和其他功能)。詳細學習 IPv4 和 IPv6 協議及其尋址。第五章中,涉及網絡層的控制平面功能,即網絡范圍的邏輯,控制數據報沿著從源主機到目的主機的端到端路徑中路由器之間的路由方式。將學習路由選擇算法,以及 OSPF 和 BGP 等路由選擇協議。傳統上,這些控制平面由路由選擇協議和數據平面轉發功能已經實現一個整體,位于一臺路由器中。軟件定義網絡(SDN)通過將這些控制平面功能作為一項單獨服務,明確地分離數據平面和控制平面,控制平面功能通常制與一臺遠程“ 控制器 ” 中。?
?4.1 網絡層概述
? ? ? ? 圖4-1?顯示了一個簡單網絡,其中有 H1 和 H2 兩臺主機,在 H1 與 H2 之間的路徑上有幾臺路由器。假設 Hl 正在向 H2 發送信息,考慮這些主機與中間路由器的網絡層所起的作用。H1 中的網絡層取得來自于 H1 運輸層的報文段,將每個報文段封裝成一個數據報,然后向相鄰路由器 R1 發送該數據報。在接收方主機 H2,網絡層接收來自相鄰路由器R2 的數據報,提取出運輸層報文段,并將其向上交付給 H2 的運輸層。每臺路由器的數據平面的主要作用是從其輸入鏈路向其輸出鏈路轉發數據報;控制平面的主要作用是協調這些本地的每路由器轉發動作,使得數據報沿著源和目的地主機之間的路由器路徑最終進行端到端傳送。注意到圖 4-1 中所示路由器具有截斷的協議棧、即沒有網絡層以上的部分,因為路由器不運行在應用層和運輸層協議。
?
?4.1.1 轉發和路由選擇:數據平面和控制平面
? ? ? ? 網絡層的作用從表面上看極為簡單,即將分組從一臺發送主機移動到一臺接收主機。需要使用兩種重要的網絡層功能:
? ? ? ? 轉發。當一個分組到達某路由器的一條輸入鏈路時,該路由器必須將該分組移動到適當的輸出鏈路。例如,在圖4-1 中來自主機 H1 到路由器 R1 的一個分組,必須向到達 H2 的路徑上的下一臺路由器轉發。如將看到的那樣,轉發是在數據平面中實現的唯一功能(盡管是最為常見和重要的功能)。在最為常見的場合(我們將在 4.4 節中討論) ,分組也可能被現有的路由器阻擋(例如,該分組來源于一個已知的惡意主機,或者該分組發向一個被禁止的目的主機) ,或者可能是冗余的并經過多條出鏈路發送。
????????路由選擇。當分組從發送方流向接收方時,網絡層必須決定這些分組所采用的路由或路徑。計算這些路徑的算法被稱為路由選擇算法 (routing algorithnl)。例如,在圖 4-1 中一個路由選擇算法將決定分組從 H1 到 H2 流動所遵循的路徑。路由選擇在網絡層的控制平面中實現。
? ? ? ? 轉發(forwarding)是指將分組從一個輸入鏈路接口轉移到只當的輸出鏈路接口的路由器本地動作。轉發發生的時間尺度很短(通常為幾納秒),因此通常用硬件來實現。路由選擇(routing)是指確定分組從源到目的地所采取的端到端路徑的網絡范圍處理過程。路由選擇發生的時間尺度長的多(通常為幾秒),常通過軟件實現。
?????????每臺網絡路由器中有一個關鍵元素是它的轉發表 (fonvarding table)。路由器檢查到達分組首部的一個或多個字段值,進而使用這些首部值在其轉發表中索引,通過這種方法來轉發分組。這些值對應存儲在轉發表項中的值,指出了該分組將被轉發的路由器的輸出鏈路接口。例如在圖 4-2 中, 一個首部字段值為 0111 的分組到達路由器。該路由器在它的轉發表中索引,并確定該分組的輸出鏈路接口是接口 2。該路由器則在內部將該分組轉發到接口 2。在 4.2 節中,深入路由器內部,更為詳細地研究這種轉發功能轉發是由網絡層的數據平面執行的主要功能。

? ? ? ? ?1.控制平面:傳統方法
? ? ? ? 路由器的轉發表一開始是如何配置的。它揭示了路由選擇和轉發間的重要相互作用關系。如圖 4-2 所示,路由選擇算法決定了插入該路由器轉發表的內容。在這個例子中,路由選擇算法運行在每臺路由器中,并且在每臺路由器中都包含轉發和路由選擇兩種功能。將在 5.3 節和 5.4 節中所見,在一臺路由器中的路由選擇算法與在其他路由器中的路由選擇算法通信,以計算出它的轉發表的值。這種通信是如何執行的呢?通過根據路由選擇協議交換包含路由選擇信息的路由選擇報文。
?????????通過考慮網絡中的假想情況(不真實的,但技術上是可行的) ,也就是說路由器中物理上存在的所有轉發表的內容是由人類網絡操作員直接配置的,進一步說明轉發和路由選擇功能的區別和不同目的。在這種情況下,不需要任何路由選擇協議!當然,這些人類操作員將需要彼此交互,以確保該轉發表的配置能使分組到達它們想要到達的目的地。出現下列現象也很可能:人工配置更容易出錯,并且對于網絡拓撲變化的響應比起路由選擇協議來更慢。
?????????2.控制平面:SDN 方法
????????圖4-2 中顯示的實現路由選擇功能的方法,是路由選擇廠商在其產品中采用的傳統方法。使用該方法,每臺路由器都有一個與其他路由器的路由選擇組件通信的路由選擇組件。然而,對人類能夠手動配置轉發表的觀察啟發我們, 對于控制平面功能來說,也許存在其他方式來確定數據平面轉發表的內容。
?????????圖4-3 顯示了從路由器物理上分離的另一種方法,遠程控制器計算和分發轉發表以供每臺路由器所使用。注意到圖 4-2 和圖 4-3 的數據平面組件是相同的。而在圖 4-3 中,控制平面路由選擇功能與物理的路由器是分離的,即路由選擇設備僅執行轉發,而遠程控制器計算并分發轉發表。程控制器可能實現在具有高可靠性和冗余的遠程數據中心中,并可能由 ISP 或某些第三方管理。路由器和遠程控制器是如何通信的呢?通過交換包含轉發表和其他路由選擇信息的報文。顯示在圖 4-3 中的控制平面方法是軟件定義網絡( Software-Defined N etworking , SDN) 的本質,因為計算轉發表并與路由器交互的控制器是用軟件實現的,故網絡是"軟件定義"的。將在 5.5 節中討論 SDN 控制平面。

4.1.2 網絡服務模型
? ? ? ? 當位于發送主機的運輸層向網絡傳輸分組時(在發送主機中將分組向下交給網絡層),運輸層能夠指望網絡層將該分組交付給目的地嗎??當發送多個分組時,它們會按發送順序按序交付給接收主機的運輸層嗎?發送兩個連續分組的時間間隔與接收到這兩個分組的時間間隔相同嗎?網絡層會提供關于網絡中擁塞的反饋信息嗎?在發送主機與接收主機中連接運輸層通道的抽象視圖(特性)是什么?對這些問題和其他問題的答案由網絡層提供的服務模型所決定。網絡服務模型 (networ servíce model) 定義了分組在發送與接收端系統之間的端到端運輸特性。
? ? ? ? 考慮網絡層能提供的某些可能的服務。這些服務包括:
? ? ? ? 確保交付。該服務確保分組將最終到達目的地。
????????具有時延上界的確保交付。該服務不僅確保分組的交付,而且在特定的主機到主機時延上界內(例如在 100ms 內)交付。
? ? ? ? 有序分組交付。該服務確保分組以他們發送的順序到達目的地。
? ? ? ? 確保最小帶寬。這種網絡層服務模仿在發送和接受主機之間一條特定比特率(例如 1Mbps)的傳輸鏈路行為。只要發送主機以低于特定比特率的速率傳輸比特(作為分組的組成成分),則所有分組最終會交付到目的主機。?
? ? ? ? 安全性。網絡層能夠在源加密所有數據報并在目的地解密這些分組,從而對所有運輸層報文段提供機密性。?
?????????因特網的網絡層提供了單一的服務,稱為盡力而為服務( best-effort service)。使用盡力而為服務,傳送的分組既不能保證以它們發送的順序被接收,也不能保證它們最終交付;既不能保證端到端時延,也不能保證有最小的帶寬。盡力而為服務是根本無服務的一種委婉說法,即一個沒有向目的地交付分組的網絡也符合盡力而為交付服務的定義。其他的網絡體系結構已定義和實現了超過因特網盡力而為服務的服務模型。例如,ATM 網絡體系結構提供了確保按序時延、有界時延和確保最小帶寬。還有提議的對因特網體系結構的服務模型擴展 ,例如,集成服務體系結構的目標是提供端到端時延保證以及無擁塞通信。令人感興趣的是,盡管有這些研發良好的供選方案,但因特網的基本盡力而為服務模型與適當帶寬供給相結合已被證明超過"足夠好",能夠用于大量的應用,包括諸如 Netfix、IP 語音和視頻等流式視頻服務,以及諸如 Skype Facetime 等實時會議應用。
? ? ? ? 第 4 章概述
????????4.2 節中,將深入探討路由器的內部硬件操作,包括輸入和輸出分組處理、路由器的內部交換機制以及分組排隊和調度。4.3 節中,學習傳統的 IP 轉發,其中分組基于它們的目的 IP 地址轉發到輸出端口。 IP 尋址、IPv4 和 IPv6協議等。 4.4 節中,將涉及更為一般的轉發,此時分組可以基于大量首部值(即不僅基于目的 IP 地址)轉發到輸出端口。分組可能在路由器中受阻或冗余,或者可能讓某些首部字段重寫,即所有都在軟件控制之下完成。這種分組轉發的更為一般的形式是現代網絡數據平面的關鍵組件, 包括軟件定義網絡 (SDN) 中的數據平面。
? ? ? ? ?約定術語分組交換機是指一臺通用分組交換設備,它根據分組首部字段中的值,從輸入鏈路接口到輸出鏈路接口轉移分組。某些分組交換機稱為鏈路層交換機,基于鏈路層幀中的字段值做出轉發決定,這些交換機因此稱為鏈路層設備。其他分組交換機叫做路由器,基于網絡層數據報中的首部字段值做出轉發決定。路由器因此是網絡層設備。這里關注網絡層,主要使用術語路由器來替代交換機。
4.2 路由器工作原理
? ? ? ? 網絡層的轉發功能,即實際將分組從一臺路由器的入鏈路傳送到適當的出鏈路。
? ? ? ? 圖4-4 顯示了一個通用路由器體系結構的總體視圖,其中標識了一臺路由器的 4 個組件。

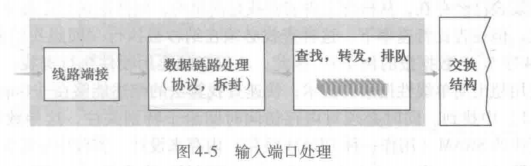
????????輸入端口。輸入端口 (input port)的執行幾項重要功能。它在路由器中執行終結入物理鏈路的物理層功能,這顯示了 4-4 中輸入端口部分最左側的方框與輸出端口部分最右側的方框中 。它還要與位于入鏈路遠端的數據鏈路層交互來執行數據鏈路層功能,這顯示在輸入與輸出端口部分中間的方框中。也許更為重要的是,在輸入端口還要執行查找功能,這顯示在輸入端口最右側的方框正是在這里,通過查詢轉發表決定路由器的輸出端口,到達的分組通過路由器的交換結構轉發到輸出端口。控制分組(如攜帶路由選擇協議信息的分組)從輸入端口轉發到路由選擇處理器。注意這里的"端口"一詞,指的是路由器的物理輸入和輸出接口。在實踐中,一臺路由器所支持的端口數量范圍較大,從企業路由器具有數量相對少的端口,到位于某 ISP 邊緣的路由器具有數以百計 10Gbps 端口(其中入線路的數量趨于最大)。
? ? ? ? 交換結構。交換結構將路由器的輸入端口連接到輸出端口。這種交換結構完全包含在路由器中,即它是一個網絡路由器中的網絡。?
? ? ? ? 輸出端口。輸出端口存儲從交換結構接受的分組,并通過執行必要的鏈路層和物理層功能在輸出鏈路上傳輸這些分組。當一條鏈路是雙向時(即承載兩個方向的流量),輸出端口通常與該鏈路的輸入端口成對出現在同一線路卡上。?
????????路由選擇處理器。路由選擇處理器執行控制平面功能。在傳統的路由器中,它執行路由選擇協議,維護路由選擇表與關聯鏈路狀態信息,并為該路由器計算轉發表。在 SDN 路由器中,路由選擇處理器(在其他活動中)負責與遠程控制器通信,目的是接收由遠程控制器計算的轉發表項,并在該路由器的輸入端口安裝這些表項。路由選擇處理器還執行網絡管理功能。?
?????????路由器的輸入端口、輸出端口和交換結構幾乎總是用硬件實現,如圖 4-4 所示。為了理解為何需要用硬件實現,考慮具有 10Gbps 輸入鏈路和 64 字節的 IP 數據報 ,其輸入端口在另一個數據報到達前僅有 51.2ns 來處理數據報。如果 N 個端口結合在一塊線路卡上(因為實踐中常常這樣做) ,數據報處理流水線必須以 N 倍速率運行,這遠快過軟件實現的速率。轉發硬件既能夠使用路由器廠商自己的硬件設計來實現,也能夠使用購買的商用硅片的硬件設計來實現。
? ? ? ? ?當數據平面以納秒時間尺度運行時,路由器的控制功能以毫秒或秒時間尺度運行,這些控制功能包括執行路由選擇協議、對上線或下線的連接鏈路進行響應、與遠程控制器通信(在SDN場合)和執行管理功能。因而這些控制平面的功能常用軟件實現并在路由選擇處理器(一種傳統的CPU)上執行。
????????在深入探討路由器的內部細節之前,轉向本章開頭的那個類比,其中分組轉發好比汽車進入和離開立交橋,假定該立交橋是環狀交叉路,在汽車進入該環狀交叉路前需要做一點處理。考慮一下對于這種處理需要什么信息。
????????基于目的地轉發。假設汽車停在一個入口站上并指示它的最終目的地(并非在本地環狀交叉路,而是其旅途的最終目的地)入口站的一名服務人員查找最終目的地.決定通向最后目的地的環狀交叉路的出口,并告訴駕駛員要走哪個出口。
????????通用轉發。除了目的地之外,服務人員也能夠基于許多其他因素確定汽車的出口匝道。例如,所選擇的出口匝道可能與該汽車的起點如發行該車牌照的州有關。來自某些州的汽車可能被引導使用某個出口應道(經過一條慢速道路通向目的地) ,而來自其他州的汽車可能被引導使用一個不同的出口匝道(經過一條高速路通向目的地) 基于汽車的模型、品牌和壽命,可能做出相同的決定。或者認為不適合上路的汽車可能被阻止并且不允許通過環狀交叉路。就通用轉發來說,許多因素都會對服務人員為給定汽車選擇出口匝道產生影響。?

4.2.1 輸入端口處理和基于目的地轉發
? ? ? ? 圖 4-5?中顯示了一個更詳細的輸入處理的視圖。如前面討論的那樣,輸入端口的線路端接功能與鏈路層處理實現了用于各個輸入鏈路的物理層和鏈路層。在輸入端口中執行的查找對于路由器運行是至關重要的。正是在這個地方,路由器使用轉發表來查找輸出端口,使得到達的分組能經過交換結構轉發到該輸出端口。轉發表是由路由選擇處理器計算和更新的(使用路由選擇協議與其他網絡路由器中的路由選擇處理器進行交互),或者轉發表接收來自遠程 SDN 控制器的內容。轉發表從路由選擇處理器經過獨立總線(例如一個 PCI 總線)復制到線路卡, 在圖 4-4 中該總線由從路由選擇處理器到輸入線路卡的虛線所指示。使用在每個輸入端口的影子副本, 轉發決策能在每個輸入端口本地做出,無須基于每個分組調用集中式路由選擇處理器,因此避免了集中式處理的瓶頸。
?
? ? ? ? 來考慮 “ 最簡單 ” 的情況,一個入分組基于該分組的目的地址交換到輸出端口。在 32 比特 IP 地址的情況下,轉發表的蠻力實現將針對每個目的地址有一個表項。因為有超過 40 億個可能的地址,選擇這種方法總體上是不可行的。?
?
????????使用這種風格的轉發表,路由器用分組目的地址的前綴( prefix ) 與該表中的表項進行匹配;如果存在一個匹配項,則路由器向與該匹配項相關聯的鏈路轉發分組。例如,假設分組的目的地址是 11001000 00010111 00010110 10100001 因為該地址的 21 比特前綴匹配該表的第一項, 所以路由器向鏈路接口 0 轉發該分組。如果一個前綴不匹配前 3 項中的任何一項,則路由器向鏈路接口3 轉發該分組。盡管聽起來足夠簡單,但這里還是有重要的微妙之處。你可能已經注意到一個目的地址可能與不止一個表項相匹配。例如,地址1100100000010111 00011000 10101010 的前 24 比特與表中的第二項匹配, 而該地址的前21 比特與表中的第三項匹配。當有多個匹配時,該路由器使用最長前綴匹配規則( longesl?prefIx malching rule) ;即在該表中尋找最長的匹配項 ,并向與最長前綴匹配相關聯的鏈路接口轉發分組。當在 4.3 節中詳細學習因特網編址時,我們將完全明白使用這種最長前匹配規則的理由。?
?????????假定轉發表已經存在,從概念上講表查找是簡單的,硬件邏輯只是搜索轉發表查找最長前綴匹配。但在幾比特速率下,這種查找必須在納秒級執行(回想前面 10Gbps路和一個 64 字節 IP 數據報的例子)。因此,不僅必須要用硬件執行查找,而且需要對大型轉發表使用超出簡單線性搜索的技術。同時必須對內存訪問時間給予特別關注,這導致用嵌入式片上 DRAM 和更快的 SRAM(用作一種 DRAM 緩存)內存來設計。實踐中也經常使用三態內容可尋址存儲器(TenruγContent Address Memory , TCAM) 來查找。使用 TCAM,一個 32 比特 IP 地址被放入內存, TCAM 在基本常數時間內返回對該地址的轉發表項的內容。
????????一且通過查找確定了某分組的輸出端口 ,則該分組就能夠發送進入交換結構。在某些設計中,如果來自其他輸入端口的分組當前正在使用該交換結構,一個分組可能會在進入交換結構時被暫時阻塞。因此,一個被阻塞的分組必須要在輸入端口處排隊,并等待稍后被及時調度以通過交換結構。稍后將仔細觀察分組(位于輸入端口與輸出端口中)的阻塞、排隊與調度。盡管" 查找 "在輸入端口處理中可認為是最為重要的動作,但必須采取許多其他動作:① 必須出現物理層和鏈路層處理,如前面所討論的那樣;② 必須檢查分組的版本號、檢驗和以及壽命字段,并且重寫后兩個字段;③ 必須更新用于網絡管理的計數器(如接收到的 IP 數據報的數目)。
?????????在結束輸入端口處理的討論之前,注意到輸入端口查找目的 IP 地址 (" 匹配 " ) ,然后發送該分組進入交換結構( "動作)的步驟是一種更為一般的" 匹配加動作 " 抽象的特定情況,這種抽象在許多網絡設備中執行,而不僅在路由器中。在鏈路層交換機中,除了發送幀進入交換結構去往輸端口外,還要查找鏈路層目的地址,并采取幾個動作。在防火墻中,首部匹配給定準則(例如源/目的 IP 地址和運輸層端口號的某種組合)的入分組可能被阻止轉發,而防火墻是一種過濾所選擇的入分組的設備。在網絡地址轉換器(NAT ,在 4. 節討論)中,一個運輸層端口號匹配某給定值的入分組,在轉發(動作)前其端口號將被重寫。的確,"匹配加動作" 抽象不僅作用大, 而且在網絡設備中無所不在,并且對于我們將在 4.4 節中學習的通用轉發是至關重要的。
4.2.2 交換
? ? ? ? 交換結構位于一臺路由器的核心部位,正是通過這種交換結構,分組才能實際地從一個輸入端口交換(即轉發)到一個輸出端口。交換可以通過許多方式完成,如圖 4-6 所示。
?
? ? ? ? ① 經內存交換
????????最簡單、 最早的路由器是傳統的計算機,在輸入端口與輸出端口之間的交換是在 CPU ( 路由選擇處理器 ) 的直接控制下完成的。輸入與輸出端口的功能就像在傳統操作系統中的 I/O 設備 。一個分組到達一個輸入端口時,該端口會先通過中斷方式向路由選擇處理器發出信號。于是,該分組從輸入端口處被復制到處理器內存中。路由選擇處理器則從其首都中提取目的地址、在轉發表中找出適當的輸出端口,并將該分組復制到輸出端口的緩存中。在這種情況下,如果內存帶寬為每秒可寫進內存或從內存讀出最多 B 個分組,則總的轉發吞吐量(分組從輸入端口被傳送到輸出端口的總速率)必然小于 B/2。也要注意到不能同時轉發兩個分組,即使它們有不同的目的端口,因為經過共享系統總線一次僅能執行一個內存讀/寫。
? ? ? ? 許多現代路由器通過內存進行交換。然而,與早期路由器的一個主要差別是,目的地址的查找和將分組存儲(交換)進適當的內存存儲位置是由輸入線路卡來處理的。在某些方面,經內存交換的路由器看起來很像共享內存的多處理器,用一個線路卡上的處理將分組交換(寫)進適當的輸出端口的內存中。
? ? ? ? ② 經總線交換
????????在這種方法中,輸入端口經一根共享總線將分組直接傳送到輸出端口,不需要路由選擇處理器的干預。通常按以下方式完成該任務:讓輸入端口為分組預先計劃一個交換機內部標簽(首部) ,指示本地輸出端口,使分組在總線上傳送和傳輸到輸出端口。該分組能由所有輸出端口收到,但只有與該標答匹配的端口才能保存該分組。然后標簽在輸出端口被去除,因為其僅用于交換機內部來跨越總線。如果多個分組同時到達路由器,每個位于不同的輸出端口,除了一個分組外所有其他分組必須等待,因為一次只有一個分組能夠跨越總線。因為每個分組必須跨過單一總線,故路由器的交換帶寬受總線速率的限制;在環狀交叉路的類比中,這相當于環狀交叉路一次僅包含一輛汽車。盡管如此,對于運行在小型局域網和企業網中的路由器來說,通過總線交換通常足夠用了。
? ? ? ? ③ 經互聯網絡交換
?????????克服單一、共享式總線帶寬限制的一種方法是,使用一個更復雜的互聯網絡,例如過去在多處理器計算機體系結構中用來互聯多個處理器的網絡。縱橫式交換機就是一種由 2N 條總線組成的互聯網絡。它連接 N 個輸入端口與 N 個輸出端口,如圖 4-6 所示,每條垂直的總線在交叉點與每條水平的總線交叉,交叉點通過交換結構控制器(其邏輯是交換結構自身的一部分)能夠在任何時候開啟和閉合。當某分組到達端口 A,需要轉發到端口 Y 時,交換機控制器閉合總線 A 和 Y 交叉部位的交叉點,然后端口 A 在其總線上發送該分組,該分組僅由總線 Y 接收。注意到來自端口 B的一個分組在同一時間能夠轉發到端口 X,因為 A到Y 和 B到X?的分組使用不同的輸入和輸出總線。因此,與前面兩種交換方法不同,縱橫式網絡能夠并行轉發多個分組。縱橫式交換機是非阻塞的,即只要沒有其他分組當前被轉發到該輸出端口,轉發到輸出端口的分組將不會被到達輸出端口的分組阻塞。然而,如果來自兩個不同輸入端口的兩個分組其目的地為相同的輸出端口,則一個分組必須在輸入端等待,因為在某個時刻經給定總線僅能夠發送一個分組。
?????????更為復雜的互聯網絡使用多級交換元素,以使來自不同輸入端口的分組通過交換結構同時朝著相同的輸出端口前行。Cisco CRS 利用一種三級非阻塞交換策略,路由器的交換能力也能夠通過并行運行多種交換結構進行擴展。在這種方法中,輸入端口和輸出端口被連接到并行運行的 N 個交換結構。一個輸入端口將一個分組分成 K 個較小的塊,并且通過 N 個交換結構中的 K個發送這些塊到所選擇的輸出端口,輸出端口再將 K 個塊裝配還原成初始的分組。
4.2.3 輸出端口處理
?????????如圖4-7 所示,輸出端口處理取出已經存放在輸出端口內存中的分組并將其發送到輸出鏈路上。這包括選擇和取出排隊的分組進行傳輸,執行所需的鏈路層和物理層傳輸功能。
?
4.2.4 何處出現排隊
? ? ? ? 考慮顯式在圖 4-6 中的輸入和輸出端口功能及其配置,下列情況是一目了然的:在輸入端口和輸出端口處都可以形成分組隊列,就像在環狀交叉路的類比中討論過的情況,即汽車可能等待在流量交叉點的入口和出口。排隊的位置和程度(或在輸入端口排隊,或者輸出端口排隊)將取決于流量負載、交換結構的相對速率和線路速率。在更為詳細一點考慮這些隊列,因為隨著隊列的增長,路由器的緩存空間最終會耗盡,并且當無內存可用于存儲到達的分組時將會出現丟包。分組“ 在網絡中丟失 ” 或 “被路由器丟棄”。正是在一臺路由器的這些隊列中,這些分組被實際丟棄或丟失。
?????????假定輸入線路速度與輸出線路速度(傳輸速率)是相同的,均為 Rline(單位為每秒分組數),并且有 N 個輸入端口和 N個輸出端口。為進一步簡化討論,假設所有分組具有相同的固定長度,分組以同步的方式到達輸入端口。這就是說,在任何鏈路發送分組的時間等于在任何鏈路接收分組的時間,在這樣的時間間隔內,在以一個輸入鏈路上能夠到達 0 或 1 個分組。定義交換結構傳送速率 Rswitch 為從輸入端口到輸出端口能夠移動分組的速率。如果 Rswitch 比 Rline 快 N 倍,則在輸入端口處僅會出現微不足道的排隊。這是因為即使在最壞情況下,所有 N 條輸入線路都在接收分組,并且所有的分組將被轉發到相同的輸出端口,每批 N 個分組(每個輸入端口一個分組)也能夠在下一批到達前通過交換結構處理完畢。
? ? ? ? 1. 輸入排隊
? ? ? ? 如果交換結構不能快得(相對于輸入線路速度而言)使所有到達分組無時延地通過它傳送,會發生什么情況?這種情況下,在輸入端口也將出現分組排隊,因為到達的分組必須加入輸入端口隊列中,以等待通過交換結構傳送到輸出端口。舉例說明這種排隊的重要后果,考慮縱橫式交換結構,并假定:① 所有鏈路速度相同 ② 一個分組能夠以一條輸入鏈路接受一個分組所用的相同的時間量,從任意一個輸入端口傳送到給定的輸出端口。③ 分組按照?FCFS 方式,從一指定輸入隊列移動到其要求的輸出隊列中。只要其輸出端口不同,多個分組可以被并行傳送。然而,如果位于兩個輸入隊列前端的兩個分組是發往同一輸出隊列的,則其中的一個分組將被阻塞,且必須在輸入隊列中等待,因為交換結構一次只能傳送一個分組到某指定端口。
?????????圖4-8 顯示了一個例子 ,其中在輸入隊列前端的兩個分組(帶深色陰影)要發往同一個右上角輸出端口。假定該交換結構決定發送左上角隊列前端的分組。在這種情況下,左下角隊列中的深色陰影分組必須等待。但不僅該分組要等待,左下角隊列中排在該分組后面的淺色陰影分組也要等待。即使右中側輸出端口(淺色陰影分組的目的地)中無競爭。這種現象叫作輸入排隊交換機中
的線路前部(HOL)阻塞,即在一個輸入隊列中排隊的分組必須等待通過交換結構發送(即使輸出端口是空閑的),因為它被位于線路前部的另一個分組所阻塞。由于 HOL 阻塞,只要輸入鏈路上的分組到達速率達到其容量的 58%,在某些假設前提下,輸入隊列長度就將無限制地增大。(不嚴格的講,等同于說將出現大量的丟包)。

? ? ? ? 2.輸出排隊?
?????????我們接下來考慮在交換機的輸出端口是否會出現排隊。再次假定 Rswit?h 比 Rline 快 N 倍,并且到達 N 個輸入端口的每個端口的分組,其目的地是相同的輸出端口。在這種情況下,在向輸出鏈路發送一個分組的時間內,將有 N 個新分組到達該輸出端口 (N 個輸入端口的每個都到達1 個)。因為輸出端口在一個單位時間(該分組的傳輸時間)內僅能傳輸一個分組,這 N 個到達分組必須排隊(等待)經輸出鏈路傳輸。在正好傳輸 N 個分組(這些分組是前面正在排隊的)之一的時間中,可能又到達 N 個分組, 等等。所以,分組隊列能夠在輸出端口形成,即使交換結構比端口線路速率快 N 倍,最終,排隊的分組數量能夠變得足夠大,耗盡輸出端口的可用內存。
?????????當沒有足夠的內存來緩存一個入分組時,就必須做出決定:要么丟棄到達的分組(采用一種稱為棄尾( drop-tail) 的策略),要么刪除一個或多個已排隊的分組為新來的分組騰出空間。在某些情況下,在緩存填滿之前便丟棄一個分組(或在其首部加上標記)的做法是有利的,這可以向發送方提供一個擁塞信號。已經提出和分析了許多分組丟棄與標記策略,這些策略統稱為主動隊列管理 (Active Queue Management , AQM) 算法。隨機早期檢測(RED)是得到最廣泛研究和實現的 AQM 算法之一。
?????????圖 4-9 中圖示了輸出端口的排隊情況。在時刻 t,每個入端輸入端口都到達了一個分組,每個分組都是發往最上側的輸出端口。假定線路速度相同,交換機以 3 倍于線路速度的速度運行,一個時間單位(即接受或發送一個分組所需的時間)以后,所有三個初始分組都被傳送到輸出端口,并排隊等待傳輸。在下一個時間單位中,這三個分組中的一個將通過輸出鏈路發送出去。這個例子中,又有兩個新分組已到達交換機的入端;這些分組之一要發往最上側的輸出端口。后果是,輸出端口的分組調度在這些排隊分組中選擇一個分組來傳輸。
? ? ? ? ?假定需要路由器緩存來吸收流量負載的波動,一個自然而然的問題是需要多少緩存。多年以來,用于緩存長度的經驗方法是,緩存數量(B)應當等于平均往返時延(RTT)乘以鏈路的容量(C)。這個結果是基于相對少量的 TCP 流的排隊動態性分析得到的。因此,一條具有 250ms RTT 的 10Gbps 鏈路需要的緩存量 等于 B=RTT*C=2.5Gb。然而,最近的理論表明,當有大量的 TCP 流(N條)流過一條鏈路時,緩存所需要的數量是 B=RTT*C/根號N。
?4.2.5 分組調度
????????現在轉而討論確定次序的問題,即排隊的分組如何經輸出鏈路傳輸的問題。 有一種是先來先服務( FCFS ,也稱之為先進先出(FIFO)。) 有些國家基于優先權運轉,即給一類等待客戶超越其他等待客戶的優先權服務,也有循環排隊,其中客戶也被劃分為類別(與在優先權隊列一樣) ,但每類用戶 、依次序提供服務。
?????????1. 先進先出
????????圖 4-10 顯示了對于先進先出( First-In-First-Out , FIFO) 鏈路調度規則的排隊模型的抽象。如果鏈路當前正忙于傳輸另一個分組,到達鏈路輸出隊列的分組要排隊等待傳輸。如果沒有足夠的緩存空間來容納到達的分組,隊列的分組丟棄策略則確定該分組是否將被丟棄(丟失)或者從隊列中去除其他分組以便為到達的分組騰出空間,如前所述。在下面討論中,忽視分組丟棄,當一個分組通過輸出鏈路完全傳輸(接收服務)時,從隊列中去除它。
?
?????????FIFO(也稱為先來先服務,FCFS)調度規則按照分組到達輸出鏈路隊列的相同次序來選擇分組在鏈路上傳輸。我們都很熟悉服務中心的 FIFO 排隊,在那里到達的顧客加入單一等待隊列的最后,保持次序,然后當他們到達隊伍的前面時就接受服務。
? ? ? ? 圖 4-11?顯示了運行中的 FIFO 隊列。分組的到達由上部時間線上帶編號的箭頭來指示,用編號指示了分組到達的次序。各個分組的離開表示在下部時間線的下面。分組在服務中(被傳輸)花費的時間是通過這兩個時間線之間的陰影矩形來指示的。假定在這個例子中傳輸每個分組用去 3 個單位時間。利用 FIFO 規則,分組按照到達的相同次序離開。注意在分組4 離開之后,在分組5 到達之前鏈路保持空閑(因為分組1~4 已經被傳輸并從隊列中去除).

? ? ? ? 2.優先權排隊
????????在優先權排隊( priority queuing ) 規則下,到達輸出鏈路的分組被分類放入輸出隊列中的優先權類,如圖 4-12 所示。在實踐中,網絡操作員可以配置一個隊列,這樣攜帶網絡管理信息的分組(例如,由源或目的 TCP/UDP 端口號所標識)獲得超過用戶流量的優先權;此外,基于 IP 的實時話音分組可能獲得超過非實時流量(如 SMTP 或 IMAP 電子郵件分組)的優先權。每個優先權類通常都有自己的隊列。當選擇一個分組傳輸時,優先權排隊規則將從隊列為非空(也就是有分組等待傳輸)的最高優先權類中傳輸一個分組。在同一優先權類的分組之間的選擇通常以 FIFO 方式完成。

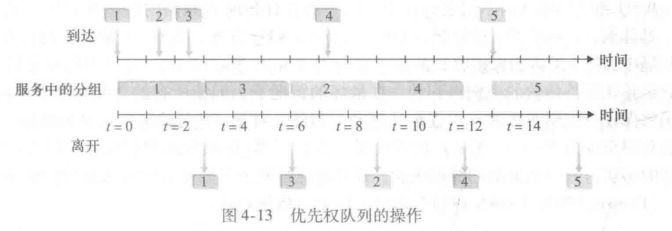
?????????圖4-13 描述了有兩個優先權類的一個優先權隊列的操作。分組1、3 和 4 屬于高優先權類,分組 2和5 屬于低優先權類。分組1 到達并發現鏈路是空閑的,就開始傳輸。在分組1 的傳輸過程中,分組2和分組3 到達,并分別在低優先權和高優先權隊列中排隊。在傳輸完分組1 后,分組3 (一個高優先權的分組)被選擇在分組2 (盡管它到達得較早,但它是一個低優先權分組)之前傳輸。在分組3 的傳輸結束后,分組2開始傳輸。分組4 (一個高優先權分組)在分組2 (一個低優先權分組)的傳輸過程中到達。在非搶占式優先權排隊( non-pree ltive priority queuing) 規則下,一旦分組開始傳輸,就不能打斷。在這情況下,分組 4 排隊等待傳輸,并在分組2 傳輸完成后開始傳輸。
?
? ? ? ? ?3. 循環和加權公平排隊
????????在循環排隊規則 (round robin queuing discipline) 下,分組像使用優先權排隊那樣被分類。然而,在類之間不存在嚴格的服務優先權,循環調度器在這些類之間輪流提供服務。在最簡單形式的循環調度中,類1 的分組被傳輸,接著是類2 的分組,接著又是類1的分組、再接著又是類2 的分組,等等。一個所謂的保持工作排隊(work - conserving queuing) 規則在有(任何類的)分組排隊等待傳輸時,不允許鏈路保持空閑。當尋找給定類的分組但是沒有找到時,保持工作的循環規則將立即檢查循環序列中的下一個類。
?????????圖4-14 描述了一個兩類循環隊列的操作。在這個例子中,分組1 2 和4 屬于第一類,分組 3和5 屬于第二類。分組1 一到達輸出隊列就立即開始傳輸。分組2 和3 在分組1的傳輸過程中到達,因此排隊等待傳輸。在分組1 傳輸后,鏈路調度器查找類2 分組,因此傳輸分組3。在分組3 傳輸完成后,調度器在找類1 的分組,因此傳輸分組2 。在分組2傳輸完成后,分組4 是唯一排隊的分組,因此在分組2 后立刻傳輸分組4。?

????????一種通用形式的循環排隊已經廣泛地實現在路由器中 ,它就是所謂的加權公平排隊( Weighted Fair Queuing , WFQ) 規則圖 4-15 對 WFQ 進行了描述。其中,到達的分組被分類并在合適的每個類的等待區域排隊。與使用循環調度一樣, WFQ 調度器也以循環的方式為各個類提供服務,即首先服務第 1 類,然后服務第2 類,接著再服務第3 類,然后(假設有3個類別)重復這種服務模式。WFQ 也是一種保持工作排隊規則,因此在發現一個空的類隊列時,它立即移向服務序列中的下一個類。?

????????WFQ 和循環排隊的不同之處在于,每個類在任何時間間隔內可能收到不同數量的服務。具體而言,每個類i 被分配一個權wi。使用 WFQ 方式,在類i 有分組要發送的任何時間間隔中,第 i 類將確保接收到的服務部分等于wi/w總,式中分母中的和是計算所有有分組排隊等待傳輸的類別得到的。在最壞的情況下,即使所有的類都有分組排隊,第i類仍然保證分配到帶寬的 wi/w總 部分。因此,對于一條傳輸速率為 R 的鏈路,第 i 類總能獲得至少為 R*wi/w總 的吞吐量。我們對 WFQ 的描述理想化了,因為沒有考慮這樣的事實:分組是離散的數據單元,并且不能打斷一個分組的傳輸來開始傳輸另一個分組。











:樂鑫發布與火山引擎扣子聯名 AI 智能體開發板)







