一、安裝基礎環境
# 1、創建環境
conda create -n suna python==3.11.7# 2、激活虛擬環境
conda activate suna# 3、安裝jupyter和ipykernel
pip install jupyter ipykernel# 4、將虛擬環境添加到jupyter
# python -m ipykernel install --user --name=myenv --display-name="Python (myenv)"
python -m ipykernel install --user --name=suna二、安裝suna環境
切換到源碼路徑下
cd /Users/dcs/study/Suna修改后項目源碼/suna/backend然后使用pip install,安裝Suna項目依賴
pip install -r requirements.txt安裝完成后,我們進入項目前端文件夾(frontend)
然后使用npm install安裝前端依賴,
cd /Users/dcs/study/Suna修改后項目源碼/suna/frontendnpm install
三、配置Suna項目后端
Suna的后端配置總共需要完成以下四步,主要是進行此前介紹的部分核心組件的配置,
- 配置1、tavily API-KEY:開啟網絡搜索功能
- 配置2、firecrawl API-KEY:開啟網絡爬蟲功能
- 配置3、Daytona:開啟沙盒環境功能
- 配置4、supabase:開啟完整后端支持
配置1、tavily API-KEY:開啟網絡搜索功能
第一步需要獲取搜索引擎tavily的API KEY,我們需要登錄tavily官網( Tavily),完成注冊并獲取API-KEY,

然后進入Suna項目的后端(backend)文件夾,用文本編輯器打開.env文件,該文件是后端配置文件,

然后將剛剛復制的API-KEY寫入TAVILY_API_KEY中,記得要隨時保存。
配置2、firecrawl API-KEY:開啟網絡爬蟲功能
接下來繼續獲取網絡爬蟲firecrawl的API KEY,同樣需要登錄firecrawl官網( Firecrawl),完成注冊后在dashboard頁面復制API-KEY

然后同樣是在.env文件中寫入FIRECRAWL_API_KEY。
配置3、Daytona:開啟沙盒環境功能
繼續設置沙盒環境工具Daytona,Daytona的設置稍微比較復雜,我們需要先進入Daytona官網( Daytona - Secure Infrastructure for Running AI-Generated Code)并進行注冊;
然后Daytona需要搭配一個Suna鏡像才能順利運行,因此我們需要點擊左側的Image(鏡像)選項,然后點擊右上角的Create Image(創建鏡像),然后輸入既定的Image Name和Entrypoint,然后點擊創建。這段文本較為復雜,大家可以領取文字版課件后直接復制。

- Image name: kortix/suna:0.1.2
- Entrypoint: /usr/bin/supervisord -n -c /etc/supervisor/conf.d/supervisord.conf
然后等待鏡像導入完成即可。

接下來點擊左側Keys選項并創建API-Key

最后,將創建好的Daytona API-KEY寫入.env配置文件。到這里,第三項配置就完成了。
配置4、supabase:開啟完整后端支持
配置后端服務工具supabase。還是一樣,需要登錄supabase官網,并根據引導完成注冊和項目創建,
例如這里我創建了一個名為test的項目

然后在項目主頁左側選擇Project setting,然后點擊Data API,往下翻找到schemas選項,確保選擇了如圖所示的三種格式。

然后在當前頁面往上翻,找到如圖所示三項核心信息,并分別復制填入.env文件中箭頭所示這三個變量里。

然后保存.env文件并退出。
接下來回到后端文件夾的命令行中,輸入如下三項命令,第一條命令是是登陸supabase,輸入后會自動彈出確認登陸的網頁;
npx supabase login npx supabase link --project-ref <your-project-ref> npx supabase db push

如果需要輸入驗證碼,從自動打開的網頁里面復制。

輸入賬號密碼即可。第二條link命令是在本地設置默認項目,需要關聯到supabase對應的項目ID;
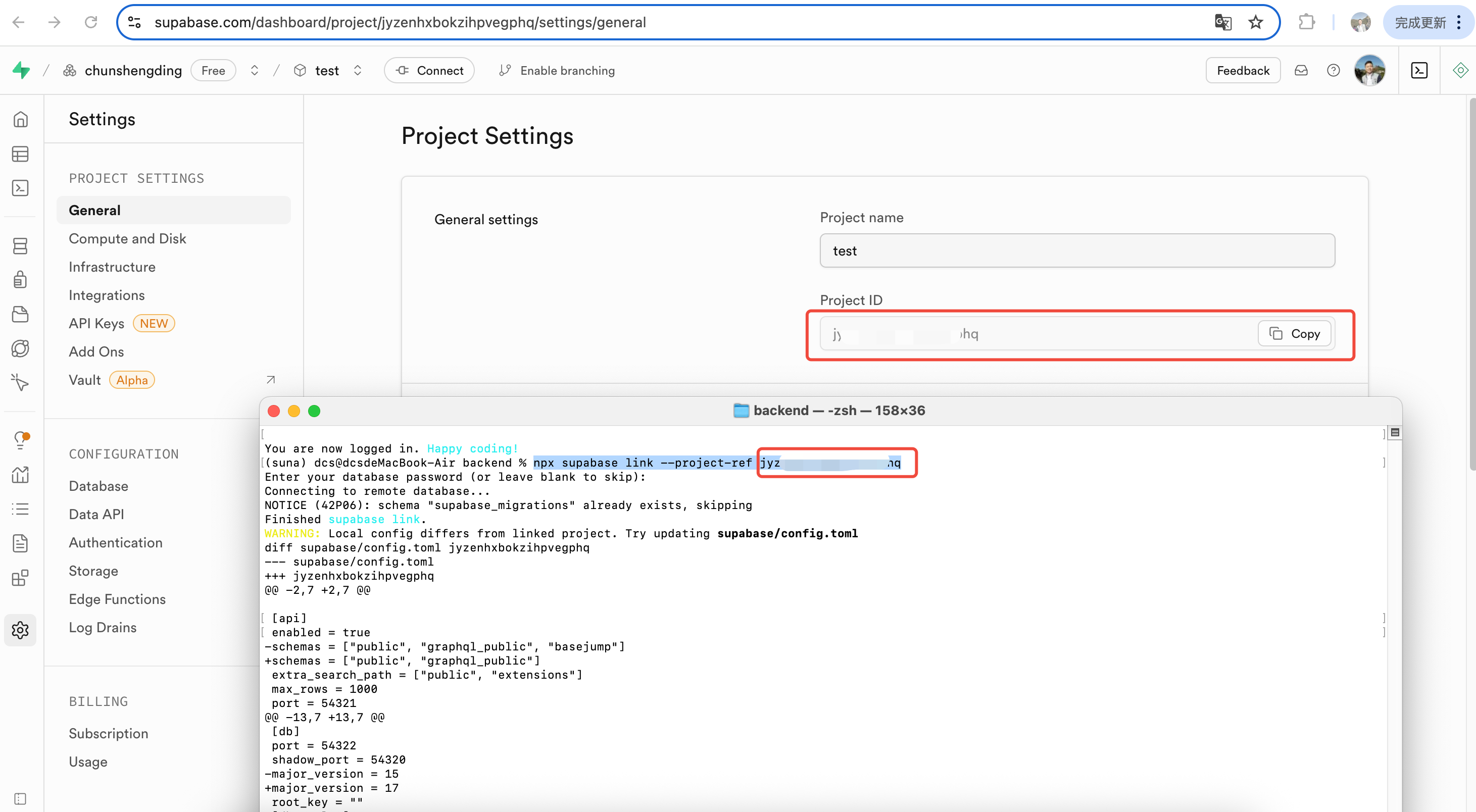
而第三條push命令則是將本地數據表格式同步到關聯的項目中。
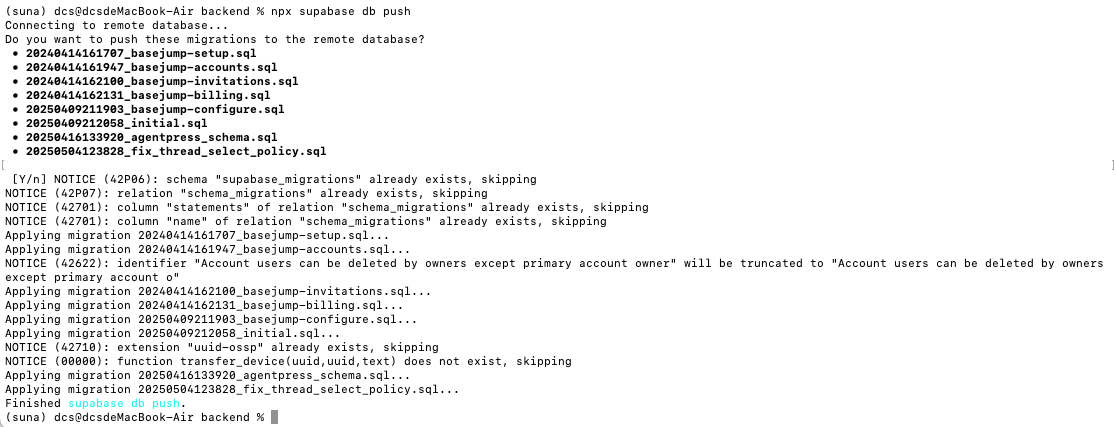
全部執行完后,Suna后端配置全部完成。
最終env文件

四、配置Suna底層大模型
最后第三個階段,讓我們設置Suna的基礎模型配置。這里強烈推薦大家分別為Suna的前端和后端配置不同的模型,能夠大幅加快Suna的響應速度。
- 配置Suna后端大模型API:Claude 3.7模型
- 配置Suna前端大模型API:DeepSeek模型
首先在后端配置中,推薦使用Claude 3.7模型,這是目前Agent能力最強的模型,同時也是Suna的默認模型。我們可以直接在某寶上購買Claude官方API-KEY,也可以自行注冊,然后在后端的配置文件.env文件中寫入Claude API-KEY即可。

此外,也可以輸入OpenRouter的API-KEY,來調用包括DeepSeek模型在內的各項主流模型。
緊接著,我們用文本編輯器打開前端配置文件.env.local;

然后如圖所示,把部分后端配置復制寫入前端配置文件中,并在最后一行OPENAI_API_KEY一欄寫入DeepSeek官方的API-KEY,這就是全部的前端配置了。
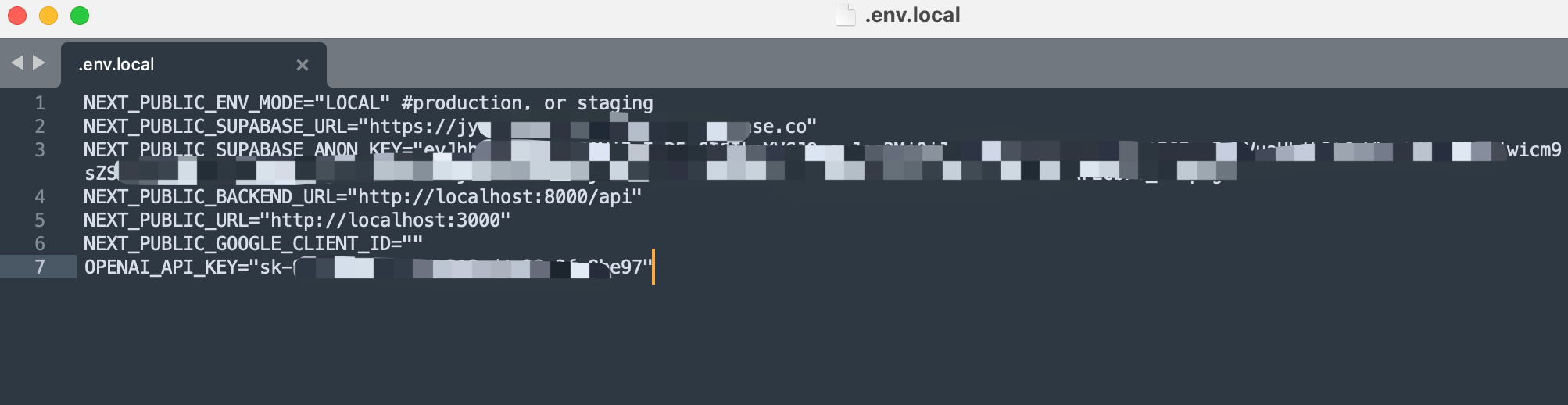
然后記得保存并退出。
至此,準備工作全部完成,接下來即可按照如下流程啟動Suna了!
- 第一步:借助docker啟動Redis
- 第二步:啟動Suna后端
- 第三步:啟動Suna前端
激動人心的時刻來了,首先需要借助docker啟動Redis。我們需要確保之前安裝的docker已經啟動,然后在后端文件夾中打開命令行,輸入Redis啟動命令。
docker compose up redis
然后同樣在后端文件夾中再打開一個命令行,輸入如下命令開啟Suna的后端服務。
cd /Users/dcs/study/Suna修改后項目源碼/suna/backend python api.py

最后,在前端文件夾中打開命令行,輸入如下命令開啟Suna前端。
cd /Users/dcs/study/Suna修改后項目源碼/suna/frontend npm run dev # 注意:如果提示沒權限/suna/frontend/node_modules/.bin/next: Permission denied, # 請賦予權限 chmod +x /Users/dcs/study/Suna修改后項目源碼/suna/frontend/node_modules/.bin/next

前端啟動后,我們就能本地瀏覽器輸入localhost:3000,即可使用Suna了!使用前會要求先注冊,使用任意郵箱注冊即可;

然后即可登錄到對話頁面,開始進行對話了!suna支持普通對話聊天,也可以執行各類復雜任務,大家現在看到的就是一個完整的復雜任務執行任務流程,整個過程Suan會先進行任務規劃,然后一步步執行,執行過程中能夠調用命令行、操作瀏覽器、編寫Python代碼、并且還能在沙盒環境中創建和編寫相關文件等等等等。

五、功能介紹
簡單來說,Suna就是一個全能型AI助手,它可以通過自然對話的方式幫你完成各種實際任務。它不僅僅是個聊天機器人,而是能真正幫你解決問題、自動化工作流程的數字伙伴。
最棒的是,它完全開源!
Git地址: https://github.com/kortix-ai/suna

以下是Suna四個主要組件:
后端API
Python/FastAPI服務,負責處理REST端點、線程管理,以及通過LiteLLM與OpenAI、Anthropic和其他LLM進行集成。
前端
Next.js/React應用程序,提供響應式用戶界面,包括聊天界面、儀表板等。
Agent Docker
為每個代理提供的隔離執行環境 - 具有瀏覽器自動化、代碼解釋器、文件系統訪問、工具集成和安全功能。
Supabase數據庫
處理數據持久化,包括認證、用戶管理、對話歷史、文件存儲、代理狀態、分析和實時訂閱。
Suna能做什么?
- Suna就像你的私人助理,擁有一系列強大的功能:
- 瀏覽器自動化:可以自動瀏覽網頁、提取數據
- 文件管理:創建和編輯文檔
- 網絡爬蟲:收集網絡信息
- 擴展搜索:幫你找到需要的信息
- 命令行執行:處理系統任務
- 網站部署:簡化網站上線流程
- API集成:連接各種服務和平臺
這些功能不是單獨存在的,而是完美協作,讓Suna能通過簡單的對話就幫你解決復雜問題。
實際應用案例
說實話,Suna的能力真的很強大,下面是官方的例子:
- 市場競爭分析
你只需對Suna說:“分析英國醫療行業市場,告訴我主要競爭者、市場規模、優勢和劣勢,以及他們的網站鏈接。完成后,生成PDF報告。”
Suna就會幫你完成這整個過程!從搜索到整理,再到生成報告,全自動完成。
- 尋找投資機會
如果你需要找風投,可以這樣說:“根據管理資產規模,給我列出美國最重要的風險投資基金清單。提供他們的網站URL,如果可能的話,還有聯系郵箱。”
- 人才招聘輔助
招人難?試試這樣:“去LinkedIn上找10個當前可用的初級軟件工程師候選人,他們應該位于德國慕尼黑,至少有計算機科學或相關專業的學士學位,以及任何領域1年的工作經驗。”
- 公司旅行規劃
計劃團建?就說:“為我的公司生成一個去加州的路線計劃。我們有8人,4月21日從法國巴黎出發,行程為期7天。檢查未來幾天的天氣預報和溫度,據此安排室內外活動。”
- Excel數據整理
數據處理也不在話下:“幫我建立一個Excel表格,包含所有意大利彩票游戲(Lotto、10eLotto和Million Day)的信息。基于此,生成并發送給我一個包含所有基本公開信息的電子表格。”
- 活動演講嘉賓尋找
想辦活動?試試:“找出20位過去一年在會議上發言的歐洲AI倫理演講者。抓取會議網站信息,交叉引用LinkedIn和YouTube,輸出聯系信息和演講摘要。”
- 科學論文總結與比較
做研究更輕松:“研究并比較過去5年討論酒精對人體影響的科學論文。生成一份關于這一主題最重要科學論文的報告。”
- 潛在客戶研究
市場營銷更精準:“在LinkedIn上研究我的潛在B2B客戶,他們應該在清潔技術行業。找到他們的網站和電子郵件地址。然后,根據公司簡介,生成一封個性化的首次聯系郵件,介紹我的公司為清潔技術公司提供的利潤最大化和成本降低咨詢服務。”
- SEO分析
網站優化不再難:“基于我的網站suna.so,生成SEO分析報告,按關鍵詞集群找出排名靠前的頁面,并識別我缺失的主題。”
- 個人旅行規劃
旅行計劃更輕松:“為我規劃一次從曼谷到倫敦的個人旅行,5月1日出發,行程10天。在倫敦市中心找一個Google評分至少4.5分的住宿。找出旅途中有趣的戶外活動。生成詳細的行程計劃。”










:樂鑫發布與火山引擎扣子聯名 AI 智能體開發板)








