簡介:
python其實沒有真正意義的多線程,因為有GIL鎖存在,但是python3.13去掉GIL鎖,有兩個版本,python3.13t和python3.13,python3.13去掉GIL鎖相當于python底層大規模改變,肯定會影響一些庫的使用,并且可能導致單線程速度變慢。原來的python多線程是單線程利用io等待去完成其它事務,造成多線程假象,其實并沒有對CPU資源造成影響。
本文介紹關于python爬蟲種的多線程,多進程,協程爬蟲。本文的案例僅供學習,切勿去壓測別人網站。若因個人不當行為引發問題,責任與本人無關。
1.多線程
舉個例子,python單線程
def func():time.time(5)if __name__ == '__main__':t = time.time()time.sleep(5)func()print(time.time() - t)一般來說這個時間耗時十秒
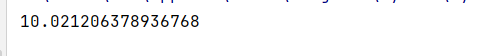
如果用多線程
from threading import Thread
import timedef func():time.sleep(5) # 線程睡眠5秒if __name__ == '__main__':start_time = time.time() # 記錄程序開始時間f = Thread(target=func) # 創建線程f.start() # 啟動線程time.sleep(5) # 主線程再睡眠5秒end_time = time.time() # 記錄程序結束時間print(end_time - start_time)?速度提高差不多一倍

沒有真正意思的多線程,主要利用等待時間去執行別的線程
from threading import Thread
def func():a = input('請輸入你要輸入的值\n')print('程序結束')
def func2():print('線程2開始\n')if __name__ == '__main__':f = Thread(target=func)#線程1f2 = Thread(target=func2) #線程2f.start()f2.start()print(11111111)print(11111111)print(11111111)print('等待子線程完成')f.join()print('主線程完成')
一般來說,單線程遇到io操作或者等待,也就是讀寫操作時會等待才對,但是這個程序并不會等待,主要原理就算多線程利用io等待時間運行別的事務。f.join()作用是等待子線程完成才會運行主線程也就是??print('主線程完成')

當io結束時,程序正式結束

?開啟線程傳參是這樣表示的
threading.Thread(target=get_movie_info, args=(page,))args必須為元組?
案例:豆瓣電影 Top 250豆瓣
注意:豆瓣是會封ip的,不要頻繁請求
import requests
import threading
from lxml import etree
import time
url = 'https://movie.douban.com/top250?start={}&filter='headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) ""AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36"
}def get_movie_info(page):response = requests.get(url.format(page * 25), headers=headers).texttree = etree.HTML(response)result = tree.xpath("//div[@class='hd']/a/span[1]/text()")print(result)if __name__ == '__main__':t = time.time()thread_obj_list = [threading.Thread(target=get_movie_info, args=(page,)) for page in range(10)]# 先啟動所有線程for thread_obj in thread_obj_list:thread_obj.start()# 再等待所有線程完成for thread_obj in thread_obj_list:thread_obj.join()print(time.time() - t)原理,先用循環為每一頁的請求創建一個線程,再用循環進行線程的開始,注意,如果要判斷時間,不要start就join一個,這樣跟單線程一樣,甚至比單線程還要慢。
耗時:
單線程自己去寫我直接給出時間 、
單線程就慢很多。?
2.線程池
python還提供了線程池功能. 可以一次性的創建多個線程, 并且, 不需要我們程序員手動去維護. 一切都交給線程池來自動管理.
# 線程池
def fn(name):for i in range(1000):print(name, i)if __name__ == '__main__':with ThreadPoolExecutor(10) as t:for i in range(100):t.submit(fn, name=f"線程{i}")輸出的值特別亂

?如果用來做計算
# 線程池
from concurrent.futures import ThreadPoolExecutor, as_completed
a = 1
def fn(name):for i in range(1000):print(a+i)if __name__ == '__main__':with ThreadPoolExecutor(10) as t:for i in range(100):t.submit(fn, name=f"線程{i}")也會很亂
 ?所以最好不要用多線程進行計算。
?所以最好不要用多線程進行計算。
如果要有返回值
方案一:future對象獲取返回值
# 線程池
from concurrent.futures import ThreadPoolExecutor, as_completedimport time
def func(name):return nameif __name__ == '__main__':with ThreadPoolExecutor(10) as t:names = [5, 2, 3]futures = [t.submit(func, page) for page in range(10)]for future in futures:print(future.result())?缺點:future對象獲取返回值會造成主線程堵塞

方案二:as_completed會立即返回處理完成的結果
# 線程池
from concurrent.futures import ThreadPoolExecutor, as_completedimport time
def func(name):return nameif __name__ == '__main__':with ThreadPoolExecutor(10) as t:names = [5, 2, 3]futures = [t.submit(func, page) for page in range(10)]# as_completed會立即返回處理完成的結果而不會堵塞主線程for future in as_completed(futures):print(future.result())缺點:返回結果順序亂?
???? ????
????
?方案三:直接用map進行任務分發
# 線程池
from concurrent.futures import ThreadPoolExecutor, as_completedimport time
def func(name):return nameif __name__ == '__main__':with ThreadPoolExecutor(10) as t:futures = t.map(func, list(range(10)))for r in futures:print("result", r)注意map第二個參數為列表?
缺點:跟方案1一樣?

?方案四:添加回調
# 線程池
from concurrent.futures import ThreadPoolExecutor, as_completedimport time
def func(name):return name
def do_callback(res):print(res.result())
if __name__ == '__main__':with ThreadPoolExecutor(10) as t:futures = [t.submit(func,page).add_done_callback(do_callback) for page in range(10)]
缺點:跟方案2一樣,并且維護難,靈活性低 。
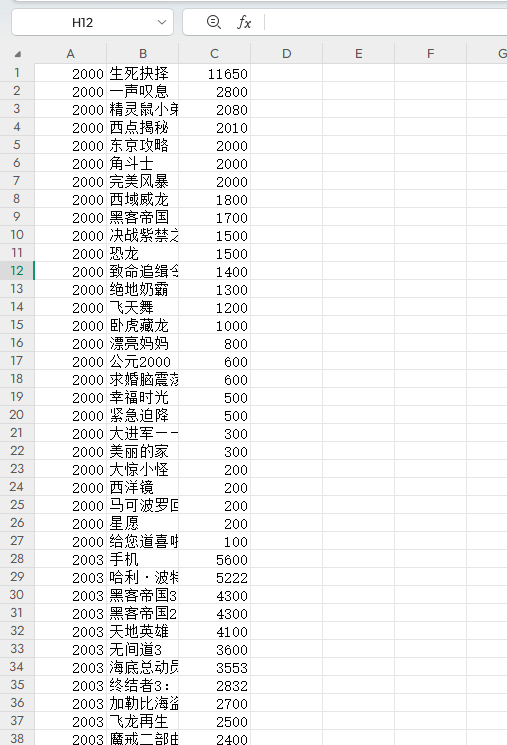
線程池案例:2024 中國票房 | 中國票房 | 中國電影票房排行榜
存入csv文件
第一步,封裝請求方法
def get_page_source(url):resp = requests.get(url)resp.encoding = 'utf-8'return resp.text第二步,封裝提取方法
def parse_html(html):try:tree = etree.HTML(html)trs = tree.xpath("//table/tbody/tr")[1:]result = []for tr in trs:year = tr.xpath("./td[2]//text()")year = year[0] if year else ""name = tr.xpath("./td[3]//text()")name = name[0] if name else ""money = tr.xpath("./td[4]//text()")money = money[0] if money else ""d = (year, name, money)if any(d):result.append(d)return resultexcept Exception as e:print(e) # 調bug專用第三步,封裝存儲csv方法,方法一和方法二在里面
def download_one(url, f):page_source = get_page_source(url)data = parse_html(page_source)for item in data:f.write(",".join(item))f.write("\n")?第四步,封裝主函數,線程池
def main():f = open("movie.csv", mode="w", encoding='utf-8')lst = [str(i) for i in range(1994, 2022)]with ThreadPoolExecutor(10) as t:# 方案一# for year in lst:# url = f"http://www.boxofficecn.com/boxoffice{year}"# # download_one(url, f)# t.submit(download_one, url, f)# 方案二t.map(download_one, (f"http://www.boxofficecn.com/boxoffice{year}" for year in lst), (f for i in range(len(lst))))注意,先打開文件
最后一步,啟動主函數
完整步驟如下:
import requests
from lxml import etree
from concurrent.futures import ThreadPoolExecutordef get_page_source(url):resp = requests.get(url)resp.encoding = 'utf-8'return resp.textdef parse_html(html):try:tree = etree.HTML(html)trs = tree.xpath("//table/tbody/tr")[1:]result = []for tr in trs:year = tr.xpath("./td[2]//text()")year = year[0] if year else ""name = tr.xpath("./td[3]//text()")name = name[0] if name else ""money = tr.xpath("./td[4]//text()")money = money[0] if money else ""d = (year, name, money)if any(d):result.append(d)return resultexcept Exception as e:print(e) # 調bug專用def download_one(url, f):page_source = get_page_source(url)data = parse_html(page_source)for item in data:f.write(",".join(item))f.write("\n")def main():f = open("movie.csv", mode="w", encoding='utf-8')lst = [str(i) for i in range(1994, 2022)]with ThreadPoolExecutor(10) as t:# 方案一# for year in lst:# url = f"http://www.boxofficecn.com/boxoffice{year}"# # download_one(url, f)# t.submit(download_one, url, f)# 方案二t.map(download_one, (f"http://www.boxofficecn.com/boxoffice{year}" for year in lst), (f for i in range(len(lst))))if __name__ == '__main__':main()
?結果如下:
?
3.多進程
因為在Python中存在GIL鎖,無法充分利用多核優勢。所以為了能夠提高程序運行效率我們也會采用進程的方式來完成代碼需求。多進程和多線程區別:多進程相當于多個程序. 多線程相當于在一個程序里多條任務同時執行.
基本使用
from multiprocessing import Process
import timedef func():print('1111')# 創建進程對象
p = Process(target=func)# 啟動進程
if __name__ == '__main__': p.start()# 等待子進程完成p.join()進程必須在?if __name__ == '__main__':在運行
多進程在爬蟲中的應用
如果遇到圖片抓取的時候, 我們知道圖片在一般都在網頁的img標簽中src屬性存放的是圖片的下載地址. 此時我們可以采用多進程的方案來實現, 一個負責瘋狂掃圖片下載地址. 另一個進程只負責下載圖片.
綜上, 多個任務需要并行執行, 但是任務之間相對獨立(不一定完全獨立). 可以考慮用多進程.
4.進程池
from concurrent.futures import ProcessPoolExecutor
from multiprocessing import cpu_count
def func():print('1111')# 啟動進程
if __name__ == '__main__':max_workers = cpu_count() # 使用 CPU 核心數作為最大并發數# max_workers = 4 # 進程數量默認為 4with ProcessPoolExecutor(max_workers=max_workers) as executor:# 提交任務到進程池futures = [executor.submit(func,) for i in (range(10))]# 等待所有任務完成for future in futures:future.result()?進程不是開越多越好,線程也一樣,進程一般以?max_workers = cpu_count() ?# 使用 CPU 核心數作為最大并發數。一般多線程搭配隊列Queue使用,在一個腳本里兩個進程必須通過隊列進行傳輸。比如一個腳本為一個進程,一般在scrapy運行多個腳本用多進程
scrapy運行案例:
from multiprocessing import Pool, cpu_count
from concurrent.futures import ProcessPoolExecutor
from scrapy import cmdline
def run_spider(name):cmdline.execute(f"scrapy crawl {name}".split())
if __name__ == '__main__':spider_names = ['spider1','spider2','spider3','spider4']max_workers = 4with ProcessPoolExecutor(max_workers=max_workers) as executor:# 提交任務到進程池futures = [executor.submit(run_spider, spider_name) for spider_name in spider_names]# 等待所有任務完成for future in futures:future.result()終極案例:進程結合線程使用
免費4K高清壁紙-電腦背景圖片-Mac壁紙網站「哲風壁紙」
這是個加解密網站,包括多進程,多線程。
先說怎么設計,只解釋進程線程,不解釋加解密
第一步肯定要導入隊列,因為多進程用隊列進行分享數據
from multiprocessing import Process,Queue第二步,開啟兩個進程
if __name__ == '__main__':q = Queue() # 兩個進程必須使用同一個隊列. 否則數據傳輸不了p1 = Process(target=get_img_src, args=(q,))#發送請求并獲取獲取圖片鏈接p2 = Process(target=download_img, args=(q,))#下載鏈接p1.start()p2.start()第三步設計p1進程多線程:
def get_img_src(q):"""進程1: 負責提取頁面中所有的img的下載地址將圖片的下載地址通過隊列. 傳輸給另一個進程進行下載進程1開啟多線程"""with ThreadPoolExecutor(10) as t:futures = [t.submit(get_req, i, q) for i in range(1, 11)]for future in as_completed(futures):future.result() # 等待任務完成并獲取結果q.put(None)?第四步線程設計,q.put(None)作用讓程序結束條件。為什么不能判斷q.empty(),因為隊列有好幾次為空狀態
def get_req(page,q):"""網站解密請求"""url = "https://haowallpaper.com/link/pc/wallpaper/getWallpaperList"js = execjs.compile(js_code)data = {"page": page, "sortType": 3, "isSel": "true", "rows": 9, "isFavorites": False, "wpType": 1}params = {"data": js.call('_', data)}response = requests.get(url, headers=headers, params=params)text = js.call('get_data', response.json()['data'])for img_id in text['list']:list_img = 'https://haowallpaper.com/link/common/file/getCroppingImg/' + img_id['fileId']q.put(list_img)response.close()?ok,第一條進程設計完畢
p2進程
第五步設計多線程,程序從這里跳出去,然后結束。
def download_img(q):"""進程2: 將圖片的下載地址從隊列中提取出來. 進行下載.進程2:開啟多線程"""with ThreadPoolExecutor(10) as t:while 1:s = q.get()if s == None:breakt.submit(donwload_one, s)第六步設計下載方法
def donwload_one(s):# 單純的下載功能resp = requests.get(s, headers=headers)file_name = s.split("/")[-1]+'.jpg'# 請提前創建好img文件夾with open(f"img/{file_name}", mode="wb") as f:f.write(resp.content)print("一張圖片下載完畢", file_name)resp.close()設計完畢
完整代碼
from multiprocessing import Process,Queue
from concurrent.futures import ThreadPoolExecutor, as_completed
import requestsimport subprocess
from functools import partial
subprocess.Popen = partial(subprocess.Popen, encoding="utf-8")
import execjs
import requests
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36"
}
js_code = '''
var CryptoJS = require('crypto-js')
function _(W) {W = JSON.stringify(W)const me = CryptoJS.enc.Utf8.parse("68zhehao2O776519"), Ee = CryptoJS.enc.Utf8.parse("aa176b7519e84710"), Ye = CryptoJS.AES.encrypt(W, me, {iv: Ee,padding: CryptoJS.pad.Pkcs7}).ciphertext.toString();return CryptoJS.enc.Base64.stringify(CryptoJS.enc.Hex.parse(Ye))}function get_data(W) {Ee = CryptoJS.enc.Base64.parse(W).toString(CryptoJS.enc.Hex), je = CryptoJS.enc.Utf8.parse("68zhehao2O776519"), Ye = CryptoJS.enc.Utf8.parse("aa176b7519e84710"), Ct = CryptoJS.lib.CipherParams.create({ciphertext: CryptoJS.enc.Hex.parse(Ee)}), Lt = CryptoJS.AES.decrypt(Ct, je, {iv: Ye,padding: CryptoJS.pad.Pkcs7});me = CryptoJS.enc.Utf8.stringify(Lt).replace(/\0.*$/g, "")return JSON.parse(me)
}
'''
def get_req(page,q):"""網站解密請求"""url = "https://haowallpaper.com/link/pc/wallpaper/getWallpaperList"js = execjs.compile(js_code)data = {"page": page, "sortType": 3, "isSel": "true", "rows": 9, "isFavorites": False, "wpType": 1}params = {"data": js.call('_', data)}response = requests.get(url, headers=headers, params=params)text = js.call('get_data', response.json()['data'])for img_id in text['list']:list_img = 'https://haowallpaper.com/link/common/file/getCroppingImg/' + img_id['fileId']q.put(list_img)response.close()
def get_img_src(q):"""進程1: 負責提取頁面中所有的img的下載地址將圖片的下載地址通過隊列. 傳輸給另一個進程進行下載進程1開啟多線程"""with ThreadPoolExecutor(10) as t:futures = [t.submit(get_req, i, q) for i in range(1, 11)]for future in as_completed(futures):future.result() # 等待任務完成并獲取結果q.put(None)
def download_img(q):"""進程2: 將圖片的下載地址從隊列中提取出來. 進行下載.進程2:開啟多線程"""with ThreadPoolExecutor(10) as t:while 1:s = q.get()if s == None:breakt.submit(donwload_one, s)
def donwload_one(s):# 單純的下載功能resp = requests.get(s, headers=headers)file_name = s.split("/")[-1]+'.jpg'# 請提前創建好img文件夾with open(f"img/{file_name}", mode="wb") as f:f.write(resp.content)print("一張圖片下載完畢", file_name)resp.close()if __name__ == '__main__':q = Queue() # 兩個進程必須使用同一個隊列. 否則數據傳輸不了p1 = Process(target=get_img_src, args=(q,))#發送請求并獲取獲取圖片鏈接p2 = Process(target=download_img, args=(q,))#下載鏈接p1.start()p2.start()?結果如下:
 ??
??
非常快 。
總的來說,兩個進程,一個負責請求獲取圖片鏈接。一個負責下載圖片。在請求或者文件寫入時也就是下載等于io等待,這時就可以用多進程了。
?5.協程
終于寫到協程了,累死我了。
協程和線程區別?
多線程由操作系統調度,線程切換涉及系統調用,開銷較大。協程由用戶態調度器調度,切換開銷小,由開發者控制,多線程受限于系統資源和 GIL,在 Python 中并發能力有限;協程可在一個線程中創建大量協程,適合高并發。
簡單總結,協程比線程快(線程切換),比線程開銷小。
基本語法
async def func():print("我是協程")if __name__ == '__main__':# print(func()) # 注意, 此時拿到的是一個協程對象, 和生成器差不多.該函數默認是不會這樣執行的coroutine = func()asyncio.run(coroutine) # 用asyncio的run來執行協程.# lop = asyncio.get_event_loop()# lop.run_until_complete(coroutine) # 這兩句頂上面一句明顯效果
import time
import asyncio# await: 當該任務被掛起后, CPU會自動切換到其他任務中
async def func1():print("func1, start")await asyncio.sleep(3)print("func1, end")async def func2():print("func2, start")await asyncio.sleep(4)print("func2, end")async def func3():print("func3, start")await asyncio.sleep(2)print("func3, end")async def run():start = time.time()tasks = [ # 協程任務列表asyncio.ensure_future(func1()), # create_task創建協程任務asyncio.ensure_future(func2()),asyncio.ensure_future(func3()),]await asyncio.wait(tasks) # 等待所有任務執行結束print(time.time() - start)if __name__ == '__main__':asyncio.run(run())效果如下:?

?asyncio.ensure_future() 用于將協程封裝成任務對象并排定在事件循環中執行,適用于在事件循環中并發運行多個任務。而 asyncio.run() 是運行異步程序的頂層入口點,用于啟動整個異步應用程序并阻塞當前線程直到完成。在實際應用中,通常在程序的入口處使用 asyncio.run() 啟動主協程,然后在主協程中使用 asyncio.ensure_future() 或 asyncio.create_task() 來創建和管理其他任務。
協程返回值
import asyncioasync def faker1():print("任務1開始")await asyncio.sleep(1)print("任務1完成")return "任務1結束"async def faker2():print("任務2開始")await asyncio.sleep(2)print("任務2完成")return "任務2結束"async def faker3():print("任務3開始")await asyncio.sleep(3)print("任務3完成")return "任務3結束"async def main():tasks = [asyncio.create_task(faker3()),asyncio.create_task(faker1()),asyncio.create_task(faker2()),]# 方案一, 用wait, 返回的結果在result中result, pending = await asyncio.wait(tasks)for r in result:print(r.result())# 方案二, 用gather, 返回的結果在result中, 結果會按照任務添加的順序來返回數據# return_exceptions如果任務在執行過程中報錯了. 返回錯誤信息. # result = await asyncio.gather(*tasks, return_exceptions=True)# for r in result:# print(r)if __name__ == '__main__':asyncio.run(main())asyncio.ensure_future() 和 asyncio.create_task() 都可以將協程封裝成一個 Task 對象并排定在事件循環中執行,作用基本一致。?
result, pending = await asyncio.wait(tasks)?result:包含所有已完成的 Task 對象。這些任務已經執行完畢,可以通過調用它們的.result() 方法來獲取任務的返回值。
pending:包含尚未完成的 Task 對象。這些任務可能仍在執行中或者尚未開始執行。
當你調用 await asyncio.wait(tasks) 時,當前協程會將控制權交還給事件循環,事件循環會繼續執行其他可以運行的任務。
asyncio.run(): 是運行異步程序的頂層入口點,通常用于啟動整個異步應用程序。它會創建一個新的事件循環,并在該循環中運行指定的協程。
aiohttp模塊基本使用
?requests是python中的同步網絡爬蟲庫,并不能直接使用asyncio運行。所以我們使用asyncio中的run_in_executor方法創建線程池完成并發。用aiohttp請求
案例 明朝那些事兒-明朝那些事兒全集在線閱讀
如何設計:
第一步,導入三個異步庫
import asyncio
import aiohttp
import aiofiles?第二步,請求得到鏈接和標題
def get_chapter_info(url):resp = requests.get(url)resp.encoding = 'utf-8'page_source = resp.textresp.close()result = []# 解析page_sorucetree = etree.HTML(page_source)mulus = tree.xpath("//div[@class='main']/div[@class='bg']/div[@class='mulu']")for mulu in mulus:trs = mulu.xpath("./center/table/tr")title = trs[0].xpath(".//text()")chapter_name = "".join(title).strip()chapter_hrefs = []for tr in trs[1:]: # 循環內容hrefs = tr.xpath("./td/a/@href")chapter_hrefs.extend(hrefs)result.append({"chapter_name": chapter_name, "chapter_hrefs": chapter_hrefs})return result
這一步是最先執行的,不需要異步
第二步,創建異步下載方法?
async def download_one(name, href):async with aiohttp.ClientSession() as session:async with session.get(href) as resp:hm = await resp.text(encoding="utf-8", errors="ignore")# 處理hmtree = etree.HTML(hm)title = tree.xpath("//div[@class='main']/h1/text()")[0].strip()content_list = tree.xpath("//div[@class='main']/div[@class='content']/p/text()")content = "\n".join(content_list).strip()async with aiofiles.open(f"{name}/{title}.txt", mode="w", encoding="utf-8") as f:await f.write(content)print(title)第三步創建事件循環
async def download_all(chapter_info):tasks = []for chapter in chapter_info:name = f"./小說/{chapter['chapter_name']}"if not os.path.exists(name):os.makedirs(name)for url in chapter['chapter_hrefs']:task = asyncio.create_task(download_one(name, url))tasks.append(task)await asyncio.wait(tasks)第四步,創建main方法,執行函數 ,運行異步程序的頂層入口點,通常用于啟動整個異步應用程序。
def main():url = "http://www.mingchaonaxieshier.com/"# 獲取每一篇文章的名稱和url地址chapter_info = get_chapter_info(url)# 可以分開寫. 也可以合起來寫.# 方案一,分開寫:# for chapter in chapter_info:# asyncio.run(download_chapter(chapter))# 方案e,合起來下載:asyncio.run(download_all(chapter_info))?完整步驟:
import asyncio
import aiohttp
import aiofiles
import requests
from lxml import etree
import osdef get_chapter_info(url):resp = requests.get(url)resp.encoding = 'utf-8'page_source = resp.textresp.close()result = []# 解析page_sorucetree = etree.HTML(page_source)mulus = tree.xpath("//div[@class='main']/div[@class='bg']/div[@class='mulu']")for mulu in mulus:trs = mulu.xpath("./center/table/tr")title = trs[0].xpath(".//text()")chapter_name = "".join(title).strip()chapter_hrefs = []for tr in trs[1:]: # 循環內容hrefs = tr.xpath("./td/a/@href")chapter_hrefs.extend(hrefs)result.append({"chapter_name": chapter_name, "chapter_hrefs": chapter_hrefs})return resultasync def download_one(name, href):async with aiohttp.ClientSession() as session:async with session.get(href) as resp:hm = await resp.text(encoding="utf-8", errors="ignore")# 處理hmtree = etree.HTML(hm)title = tree.xpath("//div[@class='main']/h1/text()")[0].strip()content_list = tree.xpath("//div[@class='main']/div[@class='content']/p/text()")content = "\n".join(content_list).strip()async with aiofiles.open(f"{name}/{title}.txt", mode="w", encoding="utf-8") as f:await f.write(content)print(title)# 方案一
# async def download_chapter(chapter):
# chapter_name = chapter['chapter_name']
#
# if not os.path.exists(chapter_name):
# os.makedirs(chapter_name)
# tasks = []
# for href in chapter['chapter_hrefs']:
# tasks.append(asyncio.create_task(download_one(chapter_name, href)))
# await asyncio.wait(tasks)# 方案二
async def download_all(chapter_info):tasks = []for chapter in chapter_info:name = f"./小說/{chapter['chapter_name']}"if not os.path.exists(name):os.makedirs(name)for url in chapter['chapter_hrefs']:task = asyncio.create_task(download_one(name, url))tasks.append(task)await asyncio.wait(tasks)def main():url = "http://www.mingchaonaxieshier.com/"# 獲取每一篇文章的名稱和url地址chapter_info = get_chapter_info(url)# 可以分開寫. 也可以合起來寫.# 方案一,分開寫:# for chapter in chapter_info:# asyncio.run(download_chapter(chapter))# 方案e,合起來下載:asyncio.run(download_all(chapter_info))if __name__ == '__main__':main()
?效果如下:

6.總結:
在 Python 爬蟲開發中,協程、多線程和多進程是三種常用的并發技術,用于提高爬蟲的效率和性能。它們各自有不同的適用場景和優缺點。以下總結時是AI給的。
1.?協程
-
定義:協程是通過
async和await實現的異步編程模型,屬于用戶態的并發機制。 -
優點:
-
高效利用 CPU:在 I/O 操作(如網絡請求)時,不會阻塞整個線程,而是切換到其他協程繼續執行,充分利用 CPU 時間。
-
高并發能力:可以在單個線程中創建大量協程,適合處理大量 I/O 密集型任務。
-
低資源消耗:協程的上下文切換開銷較小,占用內存少。
-
缺點:
-
單線程限制:盡管可以在單線程中并發執行協程,但整體受制于單個線程,不適合 CPU 密集型任務。
-
實現復雜:需要使用異步編程模型,代碼可讀性稍差,調試難度較高。
-
應用場景:主要用于爬取大量網頁時的網絡請求,尤其是在 I/O 等待時間較長的情況下。
2.?多線程
-
定義:多線程通過
threading模塊實現,是操作系統支持的一種并發機制。 -
優點:
-
簡單易用:編程模型相對直觀,代碼易于理解和維護。
-
適合 I/O 密集型任務:在 I/O 操作時,線程會阻塞,但其他線程仍然可以運行,適合處理網絡請求等任務。
-
缺點:
-
GIL 的限制:在 CPython 中,全局解釋器鎖(GIL)會限制同一時刻只有一個線程執行 Python 字節碼,導致多線程在 CPU 密集型任務中效率低下。
-
資源消耗大:每個線程都有獨立的棧空間,占用較多內存資源。
-
應用場景:適用于爬取少量網頁時的網絡請求任務,尤其是當爬取的網站數量不多時。
3.?多進程
-
定義:多進程通過
multiprocessing模塊實現,每個進程可以獨立運行一個 Python 解釋器實例。 -
優點:
-
繞過 GIL:多個進程可以在多核 CPU 上并行運行,充分利用多核 CPU 的計算能力。
-
高并發能力:可以創建多個進程,每個進程獨立運行,適合處理 CPU 密集型任務。
-
缺點:
-
資源消耗大:每個進程都有獨立的內存空間,占用較大的系統資源。
-
進程間通信復雜:進程間通信需要通過隊列、管道等機制實現,編程復雜度較高。
-
應用場景:適合處理計算密集型的爬蟲任務,如解析大量數據、運行復雜的算法等。
4.?總結與建議
-
I/O 密集型任務:
-
首選協程:如果爬蟲主要涉及大量的網絡請求,協程是最佳選擇,因為它可以在單個線程內高效地處理大量并發任務。
-
其次多線程:如果任務數量較少,且對并發要求不高,多線程也是一個不錯的選擇。
-
CPU 密集型任務:
-
首選多進程:如果爬蟲需要處理大量的數據解析或計算任務,多進程可以充分利用多核 CPU 的優勢。
-
混合場景:
-
線程 + 協程:在某些場景下,可以結合使用多線程和協程,例如在每個線程中運行多個協程,以充分利用線程和協程的優點。
-
多進程 + 協程:對于復雜的爬蟲任務,可以使用多進程來處理 CPU 密集型任務,同時在每個進程中運行協程來處理 I/O 密集型任務




)
概述)








)




