目錄
1.高級并發模式
1.1??工作竊取(Work Stealing)
1.工作竊取模式
2.ForkJoinPool實現
3.具體例子
1.2 結構化并發(Structured Concurrency)
1.結構化并發模式
2.Java 19+ 的 StructuredTaskScope
3.具體例子
1.3 對比與總結
1.工作竊取(Work Stealing)
2.結構化并發(Structured Concurrency)
2.性能瓶頸突破方案?
2.1 鎖優化對比表?
1. 計數器累加
1.1 傳統方案:synchronized
1.2 優化方案:LongAdder
1.3 性能提升
1.4 分段鎖與無鎖編程技術
1. 分段鎖(Segmented Lock)
1.1 舉例說明:
1.2優點:
2. 無鎖編程(Lock-Free Programming)(自旋鎖)
2.1 優點:(不存在死鎖)
2.2 缺點
2.3潛在問題與優化方向
2.4?場景
3.分段鎖與無鎖編程的區別
4.總結
1.5 并發數據結構
1. 并發List
1.1?CopyOnWriteArrayList 的 "寫時復制" 機制解析
2. 并發Set
??3. 并發Map?
3.1?跳表(Skip List)數據結構基礎
3.2 ConcurrentSkipListMap 的并發控制機制
4.并發Queue
4.1 ArrayBlockingQueue?
4.2 生產者 - 消費者模型的典型應用
4.3 模型優勢:
4.4 與其他阻塞隊列的對比
4.5 使用場景與注意事項
4.6 核心源碼邏輯簡析
4.7?LinkedBlockingQueue
4.8 讀寫分離鎖
4.9 鏈表結構
5.日志處理場景
5.1 實現日志處理的步驟
5.2 消息隊列的本地緩沖與日志系統的緩沖
5.3?是否需要額外的緩沖層?
5.4 常見的日志系統
5.5 示例:使用?LinkedBlockingQueue?作為日志緩沖
5.6 總結
5.7 日志寫很需要畢竟要記錄,為什么說他的讀也很頻繁呢
5.8 存儲引擎優化
5.9 Redis和ZooKeeper對比
??6. 設計思想對比?????????
??7.?選型建議?
2. 對象池
2.1 傳統方案:ReentrantLock
2.2 優化方案:StampedLock?樂觀讀
2.3?樂觀鎖
1.樂觀鎖的工作原理
2.樂觀鎖的實現方式
2.1 基于版本號(Version Number)
2.2? 基于時間戳(Timestamp)
2.3 樂觀鎖的優點
2.4 樂觀鎖的缺點
2.5 適用場景
2.6 示例代碼
2.7 總結
3. 緩存更新
3.1 傳統方案:全局鎖
3.2 優化方案:ConcurrentHashMap?分段
3.3 性能提升
2.2?偽共享(False Sharing)解決
1.什么是偽共享?
2 偽共享的危害
3 偽共享實例解析
4 解決方案:緩存行填充
5.Java 8 中的 @Contended 注解
6.性能對比測試
7.實際應用場景
8.何時需要關注偽共享?
9.總結
1.高級并發模式
1.1??工作竊取(Work Stealing)
1.工作竊取模式
工作竊取是一種并發編程模式,用于在多線程環境中高效地分配任務。其核心思想是:
-
每個線程都有自己的任務隊列。
-
當一個線程完成自己的任務后,它會從其他線程的任務隊列中“竊取”任務來執行。
-
這種模式可以有效減少線程的空閑時間,提高整體的并發效率。
2.ForkJoinPool實現
ForkJoinPool是Java中實現工作竊取模式的工具類。它通過分治法將大任務分解為多個小任務,并在多個線程中并行執行。
3.具體例子
以下是一個使用ForkJoinPool實現工作竊取的例子:
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.ForkJoinPool;
import java.util.stream.Collectors;
import java.util.stream.IntStream;public class WorkStealingExample {public static void main(String[] args) {// 創建一個ForkJoinPool,指定線程數為4ForkJoinPool pool = new ForkJoinPool(4);// 提交任務到ForkJoinPoolpool.submit(() -> {// 創建100個異步任務List<CompletableFuture<Void>> tasks = IntStream.range(0, 100).mapToObj(i -> CompletableFuture.runAsync(() -> process(i), pool)).collect(Collectors.toList());// 等待所有任務完成CompletableFuture.allOf(tasks.toArray(new CompletableFuture[0])).join();});// 關閉線程池pool.shutdown();}// 模擬任務處理邏輯private static void process(int i) {System.out.println("處理任務: " + i + ",線程: " + Thread.currentThread().getName());try {Thread.sleep(100); // 模擬耗時操作} catch (InterruptedException e) {e.printStackTrace();}}
}關鍵點
ForkJoinPool:用于管理線程池和任務隊列。
CompletableFuture.runAsync:用于創建異步任務,并指定線程池。
CompletableFuture.allOf:用于等待多個異步任務完成。1.2 結構化并發(Structured Concurrency)
1.結構化并發模式
結構化并發是一種新的并發編程模式,旨在簡化并發任務的管理。其核心思想是:
-
將并發任務的生命周期限制在特定的作用域內。
-
通過
try-with-resources語法自動管理任務的啟動和關閉。 -
提供統一的異常處理機制。
2.Java 19+ 的 StructuredTaskScope
Java 19引入了StructuredTaskScope,用于實現結構化并發。它提供了以下功能:
-
fork:啟動一個子任務。 -
join:等待所有子任務完成。 -
throwIfFailed:檢查是否有子任務失敗,并拋出異常。
3.具體例子
以下是一個使用StructuredTaskScope實現結構化并發的例子:
import java.util.concurrent.StructuredTaskScope;
import java.util.concurrent.Future;public class StructuredConcurrencyExample {public static void main(String[] args) {try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {// 啟動兩個子任務Future<String> user = scope.fork(() -> fetchUser());Future<Integer> order = scope.fork(() -> fetchOrder());// 等待所有子任務完成scope.join();// 檢查是否有子任務失敗scope.throwIfFailed();// 獲取子任務的結果String userName = user.resultNow();Integer orderCount = order.resultNow();// 返回最終結果System.out.println("用戶: " + userName + ", 訂單數量: " + orderCount);} catch (Exception e) {e.printStackTrace();}}// 模擬獲取用戶信息private static String fetchUser() {System.out.println("獲取用戶信息,線程: " + Thread.currentThread().getName());try {Thread.sleep(1000); // 模擬耗時操作} catch (InterruptedException e) {e.printStackTrace();}return "Alice";}// 模擬獲取訂單信息private static Integer fetchOrder() {System.out.println("獲取訂單信息,線程: " + Thread.currentThread().getName());try {Thread.sleep(1000); // 模擬耗時操作} catch (InterruptedException e) {e.printStackTrace();}return 5;}
}關鍵點
StructuredTaskScope:用于管理并發任務的作用域。fork:啟動一個子任務。join:等待所有子任務完成。throwIfFailed:檢查是否有子任務失敗,并拋出異常。resultNow:獲取子任務的結果。1.3 對比與總結
1.工作竊取(Work Stealing)
-
優點:
-
高效利用線程資源,減少線程空閑時間。
-
適用于任務數量較多且任務大小不均勻的場景。
-
-
缺點:
-
需要手動管理線程池和任務隊列。
-
異步任務的生命周期管理較為復雜。
-
2.結構化并發(Structured Concurrency)
-
優點:
-
簡化并發任務的生命周期管理。
-
提供統一的異常處理機制。
-
代碼更加清晰易讀。
-
-
缺點:
-
需要Java 19及以上版本支持。
-
適用場景較為有限,主要用于并發任務較少且生命周期較短的場景。
-
通過使用這兩種高級并發模式,可以更好地管理并發任務,提高系統的性能和可維護性。
2.性能瓶頸突破方案?
2.1 鎖優化對比表?
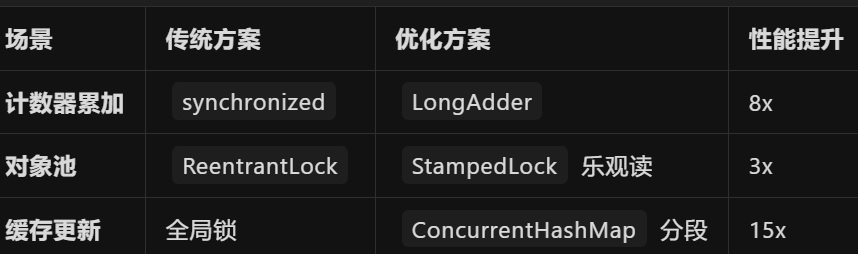
1. 計數器累加
1.1 傳統方案:synchronized
使用 synchronized 同步方法或代碼塊來保護計數器的累加操作。
public class Counter {private long value = 0;public synchronized void increment() {value++;}public synchronized long getValue() {return value;}
}1.2 優化方案:LongAdder
LongAdder 是 Java 8 引入的一個高性能的計數器,適用于高并發場景。
import java.util.concurrent.atomic.LongAdder;public class Counter {private final LongAdder value = new LongAdder();public void increment() {value.increment();}public long getValue() {return value.sum();}
}1.3 性能提升
傳統方案:
synchronized是一種重量級的同步機制,會導致線程阻塞和上下文切換。優化方案:
LongAdder使用了分段鎖和無鎖編程技術,性能提升約 8 倍。
1.4 分段鎖與無鎖編程技術
1. 分段鎖(Segmented Lock)
分段鎖是一種將共享數據劃分為多個段,并為每個段分配獨立鎖的機制。通過這種方式,多個線程可以同時訪問不同的數據段,從而減少鎖的競爭,提高并發性能。
1.1 舉例說明:
以下是一個簡單的分段鎖實現示例,使用ReentrantLock作為鎖機制,并假設我們正在處理一個整數數組,該數組被劃分為多個段。
@SuppressWarnings("unchecked")public SegmentedLock(int size, int segments) {this.segments = segments;this.data = (T[]) new Object[size]; // 創建泛型數組this.locks = new ReentrantLock[segments];// 初始化每個段的鎖for (int i = 0; i < segments; i++) {locks[i] = new ReentrantLock();}}// 計算索引對應的段號private int segmentIndex(int index) {return index % segments;}// 安全地訪問數據public void setData(int index, T value) {int segment = segmentIndex(index);locks[segment].lock();try {data[index] = value;} finally {locks[segment].unlock();}}public T getData(int index) {int segment = segmentIndex(index);locks[segment].lock();try {return data[index];} finally {locks[segment].unlock();}}
}核心設計思路
分段策略:
將數據數組分成固定數量的段 (segments)
每個段擁有獨立的鎖,不同段的操作可以并行執行
當線程訪問某個索引位置時,只需要獲取該索引對應的段鎖
鎖粒度控制:
通過調整segments參數,可以控制鎖的粒度
段數越多,并發度越高,但內存開銷也越大
段數太少,可能導致鎖競爭激烈,性能下降
索引到段的映射:
使用取模運算 (index % segments) 將索引映射到對應的段
這種簡單的映射方式保證了分布均勻性,但可能導致熱點問題關鍵方法解析
構造函數:
接收數據數組大小和段數作為參數
初始化數據數組和鎖數組
為每個段創建獨立的ReentrantLock實例segmentIndex 方法:
使用取模運算將數組索引映射到對應的段
例如,當段數為 4 時,索引 0-3 對應段 0,4-7 對應段 1,依此類推
setData 和 getData 方法:獲取索引對應的段鎖
在鎖的保護下執行讀寫操作
使用 try-finally 確保鎖一定會被釋放優勢與應用場景
性能優勢:
相比全局鎖,分段鎖可以顯著提高并發性能
假設段數為 16,理想情況下可以支持 16 倍的并發吞吐量
適用場景:
高并發的哈希表實現 (如 ConcurrentHashMap 的早期版本)
分布式緩存系統
高性能隊列和棧
其他需要頻繁讀寫共享數據的場景
與讀寫鎖的對比:
分段鎖適用于寫操作較多的場景
讀寫鎖適用于讀多寫少的場景潛在問題與優化方向熱點問題:
如果某些段被頻繁訪問,可能導致這些段的鎖競爭激烈
可以考慮使用更復雜的 哈希函數 來分散熱點段數選擇:
段數應根據系統核心數和預期并發量來調整
一般建議段數為 CPU 核心數的 2-4 倍鎖升級:
如果需要對整個數據結構進行操作,可以實現獲取所有段鎖的方法
但要注意避免死鎖問題使用讀寫鎖:
對于讀多寫少的場景,可以將ReentrantLock替換為ReentrantReadWriteLock
通過這種分段鎖設計,可以在保證線程安全的同時,最大限度地提高并發性能,特別適合需要頻繁讀寫共享數據的高并發場景。
1.2優點:
-
減少了鎖的競爭,提高了并發性能。
-
適用于頻繁讀、寫操作的場景。
缺點:
-
實現復雜度較高,維護成本增加。
-
如果分段數量設置不當,可能會導致熱點分段出現性能瓶頸。
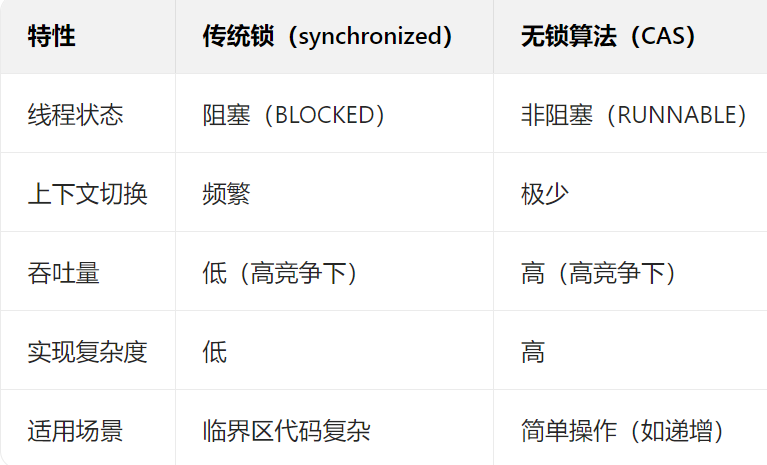
2. 無鎖編程(Lock-Free Programming)(自旋鎖)
無鎖編程是一種不依賴于傳統鎖機制的并發編程技術。它通過原子操作(如Compare-And-Swap,CAS)來實現線程間的協調,從而避免了鎖的使用。
舉例說明: 以下是一個使用CAS操作的無鎖編程示例,實現了一個簡單的線程安全的計數器。
import java.util.concurrent.atomic.AtomicInteger;public class LockFreeCounter {private AtomicInteger counter = new AtomicInteger(0);public void increment() {while (true) {int currentValue = counter.get();int newValue = currentValue + 1;if (counter.compareAndSet(currentValue, newValue)) {break;}// 如果CAS失敗,循環會自動重試}}public int get() {return counter.get();}
}無鎖計數器的核心是 CAS(Compare-And-Swap) 操作:
CAS 是一種原子操作,包含三個參數:內存位置 (V)、預期原值 (A) 和新值 (B)
僅當 V 的值等于 A 時,才將 V 的值更新為 B,否則不執行任何操作
CAS 操作是原子的,由 CPU 指令直接支持,不會被中斷在這個實現中:
獲取當前計數器值
計算新值(當前值 + 1)
使用 CAS 嘗試更新計數器
如果更新失敗(說明有其他線程修改了值),則重試關鍵方法解析
構造函數:
初始化一個 AtomicInteger,初始值為 0
AtomicInteger 提供了原子操作的能力increment 方法:
獲取當前值
計算新值(+1)使用 compareAndSet 嘗試更新:
如果當前值仍然是獲取時的值,則更新成功
如果其他線程已經修改了值,則更新失敗,循環會重試這種模式稱為 CAS 循環或自旋鎖get 方法:
原子性地獲取當前計數器值
不需要額外的同步,因為 AtomicInteger 的 get 方法是線程安全的
2.1 優點:(不存在死鎖)
-
性能優勢:
- 無鎖操作避免了線程阻塞和上下文切換
- 在高并發環境下,通常比基于鎖的實現性能更好
- 特別適合計數器、ID 生成器等場景
-
線程安全:
- 保證了操作的原子性和可見性
- 多個線程可以同時嘗試遞增,不會出現數據競爭
2.2 缺點
-
實現復雜,需要深入理解原子操作和內存模型。
-
在某些情況下,可能會遇到ABA問題。
ABA問題發生在多線程環境中,當一個線程讀取一個共享變量的值為A,在它進行操作之前被掛起,另一個線程將該值改為B然后再改回A。當第一個線程恢復執行時,由于CAS操作只檢查值是否未變,不關心值的變化歷史,因此會繼續執行操作,導致邏輯錯誤?
2.3潛在問題與優化方向
-
ABA 問題:
- 如果值從 A 變為 B 再變回 A,CAS 會認為值沒有變化
- 在這個計數器場景中不會有問題,因為值總是遞增的
- 對于更復雜的場景,可以使用 AtomicStampedReference 解決
-
自旋消耗 CPU:
- 在高度競爭的情況下,線程可能頻繁重試 CAS
- 可以考慮使用 LongAdder(JDK 8 引入),它在高競爭下性能更好
-
可擴展性:
- 這個實現是單變量的,不支持批量操作
- 對于需要批量操作的場景,可以考慮使用鎖或其他并發數據結構
2.4?場景
- 計數器、統計器
- 分布式系統中的 ID 生成器
- 高性能隊列的索引指針
- 任何需要高效并發遞增的場景
3.分段鎖與無鎖編程的區別
-
鎖機制:分段鎖依賴于傳統鎖機制,通過將鎖的粒度細化來減少競爭;無鎖編程則完全不使用鎖,而是通過原子操作來實現線程間的協調。
-
性能:無鎖編程在某些場景下可以提供更高的性能,因為它避免了鎖的開銷;分段鎖則在數據訪問模式較為分散時表現較好。
-
實現復雜度:無鎖編程的實現通常更為復雜,需要對原子操作和內存模型有深入的理解;分段鎖的實現相對簡單,但維護成本較高。
4.總結
分段鎖和無鎖編程都是用于提高并發性能的技術。分段鎖通過將鎖的粒度細化來減少競爭,適用于讀操作頻繁的場景;無鎖編程則通過原子操作避免了鎖的使用,適用于對性能要求極高的場景。選擇哪種技術取決于具體的應用場景和性能需求。
1.5 并發數據結構
涵蓋List、Set、Map、Queue等類型
1. 并發List

1.1?CopyOnWriteArrayList 的 "寫時復制" 機制解析
"寫時復制"(Copy-On-Write, COW) 是一種重要的內存管理和并發控制技術,在
CopyOnWriteArrayList中得到了典型應用。這種機制的核心思想是:當需要修改數據時,不直接修改原數據,而是先復制一份,在副本上進行修改,修改完成后再用副本替換原數據。
1.寫時復制的工作原理
在CopyOnWriteArrayList中:
-
讀操作:
- 無需加鎖,直接訪問底層數組
- 讀取的是操作開始時數組的快照
- 不會阻塞其他讀操作或寫操作
-
寫操作:
- 需要獲取獨占鎖(ReentrantLock)
- 復制當前數組到一個新數組
- 在新數組上進行修改(添加、刪除、更新元素)
- 用新數組替換原數組
- 釋放鎖
-
數據一致性:
- 提供弱一致性(Weak Consistency)
- 讀操作可能看不到最新的寫操作結果
- 但保證數據在讀取時是完整的
2.代碼實現示例
public class CopyOnWriteArrayList<E> {private transient volatile Object[] array;private final ReentrantLock lock = new ReentrantLock();// 獲取當前數組final Object[] getArray() {return array;}// 設置新數組final void setArray(Object[] a) {array = a;}// 讀操作(無鎖)public E get(int index) {return elementAt(getArray(), index);}// 寫操作(加鎖+復制)public boolean add(E e) {final ReentrantLock lock = this.lock;lock.lock();try {Object[] elements = getArray();int len = elements.length;// 復制原數組到新數組(長度+1)Object[] newElements = Arrays.copyOf(elements, len + 1);// 在新數組末尾添加元素newElements[len] = e;// 用新數組替換原數組setArray(newElements);return true;} finally {lock.unlock();}}// 其他方法...
}3.寫時復制的優勢
-
高并發讀性能:
- 讀操作完全無鎖,性能接近數組
- 適合讀操作遠多于寫操作的場景
-
線程安全:
- 寫操作通過鎖保證原子性
- 讀操作不會看到不完整的數據
-
簡化并發控制:
- 無需復雜的讀寫鎖控制
- 實現簡單,易于理解和維護
4. 寫時復制的缺點
-
內存開銷大:
- 每次寫操作都需要復制整個數組
- 對于大數組或頻繁寫操作,內存消耗顯著
-
寫操作性能低:
- 涉及鎖獲取、數組復制和替換
- 寫操作性能遠低于普通 ArrayList
-
數據弱一致性:
- 讀操作可能看不到最新的寫操作結果
- 不適合需要強一致性的場景
-
迭代器問題:
- 迭代器創建時會復制當前數組
- 迭代器不支持修改操作
- 迭代過程中不會反映數組的修改
寫時復制是一種以空間換時間的并發控制策略,通過在寫操作時復制數據結構,避免了讀寫鎖的開銷,實現了無鎖的讀操作。這種機制特別適合讀操作遠多于寫操作,且對內存使用不太敏感的場景。在設計高并發系統時,合理選擇并發集合是提高系統性能的關鍵之一。
5.適用場景
-
讀多寫少的場景:
- 配置信息存儲(很少修改,頻繁讀取)
- 事件監聽器列表(注冊少,觸發多)
- 緩存系統(寫操作少,讀操作多)
-
需要線程安全但不要求強一致性的場景:
- 統計信息收集(允許短暫的不一致)
- 配置變更通知(不要求立即生效)
-
需要在迭代過程中修改集合的場景:
- 普通集合在迭代時修改會拋出 ConcurrentModificationException
- CopyOnWriteArrayList 的迭代器不會受影響(對寫時復制的迭代器部分進行優化如下所說)
CopyOnWriteArrayList的迭代器不會受到修改操作的影響,是因為它在創建時獲取了數組的一個快照,并且在迭代過程中操作的是這個快照,而不是原始數組。這種機制使得CopyOnWriteArrayList在多線程環境中非常安全,但同時也帶來了內存和性能的開銷。因此,CopyOnWriteArrayList適用于讀多寫少的場景。
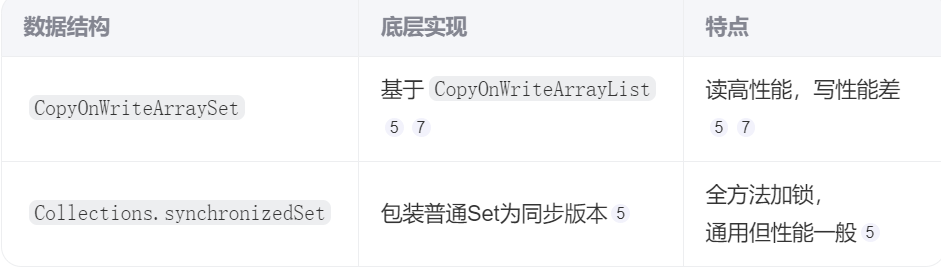
2. 并發Set
??3. 并發Map?
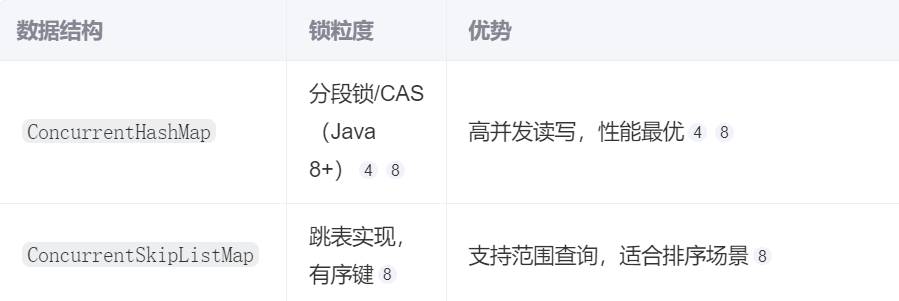
ConcurrentSkipListMap 是 Java 并發包中的一個重要組件,它結合了跳表數據結構和并發控制機制,提供了線程安全的有序映射功能。下面我將詳細解析其工作原理、優勢和適用場景。
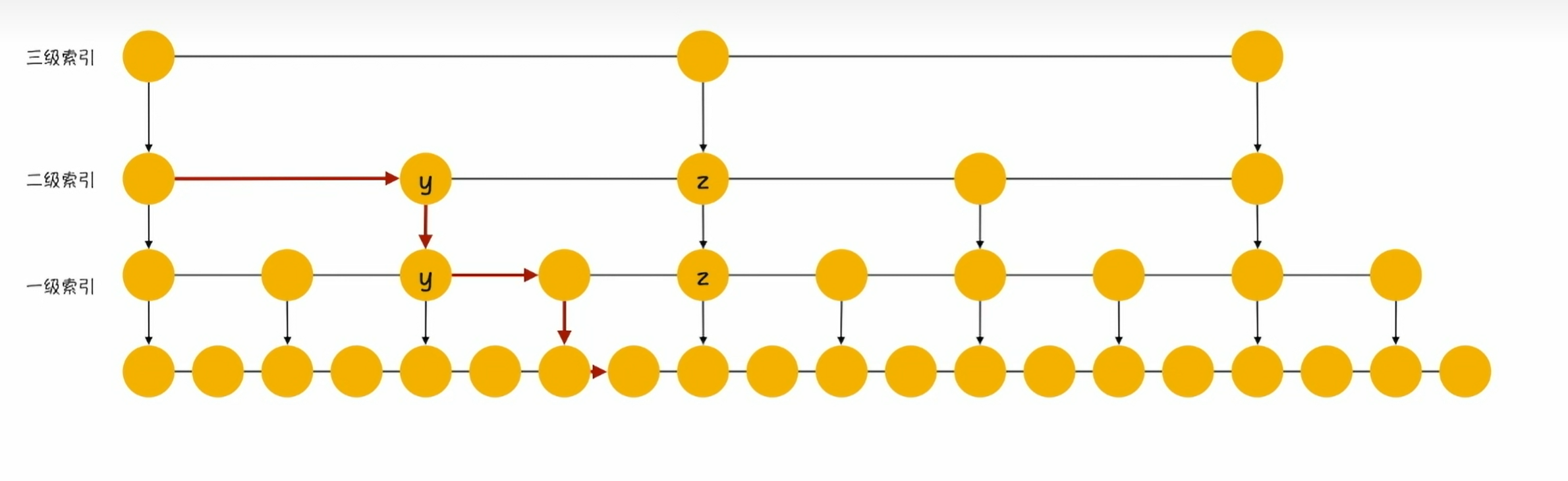
3.1?跳表(Skip List)數據結構基礎
跳表是一種隨機化的數據結構,它通過在每個節點中維護多個指向其他節點的指針,形成多級索引結構,從而達到快速查找的目的。
1.核心思想:
- 在有序鏈表的基礎上,增加多級 "快速通道"
- 每一級都是下一級的子集,形成類似二分查找的結構
- 插入、刪除和查找操作的時間復雜度均為 O (log n)
2.跳表結構示例:
3.實現
import java.util.Random;class SkipListNode {int value;SkipListNode[] next;public SkipListNode(int value, int level) {this.value = value;this.next = new SkipListNode[level];}
}class SkipList {private static final int MAX_LEVEL = 16; // 最大層數private SkipListNode head; // 頭節點private int currentLevel; // 當前跳表的層數private Random random = new Random();public SkipList() {head = new SkipListNode(Integer.MIN_VALUE, MAX_LEVEL);currentLevel = 1;}// 隨機生成一個層數private int randomLevel() {int level = 1;while (random.nextDouble() < 0.5 && level < MAX_LEVEL) {level++;}return level;}// 插入一個值public void insert(int value) {SkipListNode[] update = new SkipListNode[MAX_LEVEL]; // 存儲每一層的插入位置SkipListNode current = head; // 從頭節點開始// 找到每一層的插入位置for (int i = currentLevel - 1; i >= 0; i--) {while (current.next[i] != null && current.next[i].value < value) {current = current.next[i]; // 向右移動}update[i] = current; // 保存當前層的插入位置}// 生成隨機層數int level = randomLevel();if (level > currentLevel) { // 如果生成的層數大于當前層數for (int i = currentLevel; i < level; i++) {update[i] = head; // 多余的層指向頭節點}currentLevel = level; // 更新當前層數}// 創建新節點SkipListNode newNode = new SkipListNode(value, level);// 插入新節點for (int i = 0; i < level; i++) {newNode.next[i] = update[i].next[i]; // 新節點的next指針指向update數組中對應層的next節點update[i].next[i] = newNode; // update數組中對應層的next指針指向新節點}
}// 搜索一個值public boolean search(int value) {SkipListNode current = head;for (int i = currentLevel - 1; i >= 0; i--) {while (current.next[i] != null && current.next[i].value < value) {current = current.next[i];}}if (current.next[0] != null && current.next[0].value == value) {return true;}return false;}// 刪除一個值public void delete(int value) {SkipListNode[] update = new SkipListNode[MAX_LEVEL];SkipListNode current = head;// 找到每一層的刪除位置for (int i = currentLevel - 1; i >= 0; i--) {while (current.next[i] != null && current.next[i].value < value) {current = current.next[i];}update[i] = current;}if (current.next[0] != null && current.next[0].value == value) {for (int i = 0; i < currentLevel; i++) {if (update[i].next[i] != null && update[i].next[i].value == value) {update[i].next[i] = update[i].next[i].next[i];}}}}// 打印跳表public void printList() {for (int i = currentLevel - 1; i >= 0; i--) {SkipListNode current = head.next[i];System.out.print("Level " + i + ": ");while (current != null) {System.out.print(current.value + " ");current = current.next[i];}System.out.println();}}
}public class SkipListExample {public static void main(String[] args) {SkipList skipList = new SkipList();skipList.insert(3);skipList.insert(6);skipList.insert(7);skipList.insert(9);skipList.insert(12);System.out.println("跳表內容:");skipList.printList();System.out.println("搜索 7: " + skipList.search(7)); // 應該返回 trueSystem.out.println("搜索 14: " + skipList.search(14)); // 應該返回 falseSystem.out.println("刪除 7");skipList.delete(7);skipList.printList();}
}3.2 ConcurrentSkipListMap 的并發控制機制
ConcurrentSkipListMap 采用了無鎖(Lock-Free)算法實現并發控制:
-
原子操作:
- 使用?
Unsafe?類的 CAS(Compare-And-Swap)操作 - 確保對節點的修改是原子的,避免鎖競爭
- 使用?
-
分段更新:
- 只對需要修改的節點加鎖
- 不會阻塞整個數據結構
-
樂觀鎖策略:
- 先嘗試修改,失敗則重試
- 減少鎖的持有時間,提高并發性能
1.核心特性與優勢
-
有序性:
- 鍵按照自然順序或指定的比較器排序
- 提供了?
headMap、tailMap、subMap?等范圍查詢方法
-
線程安全:
- 所有操作都是線程安全的
- 無需外部同步機制
-
高效的范圍查詢:
- 跳表結構非常適合范圍查詢
- 時間復雜度為 O (log n + m),其中 m 是結果集大小
-
無鎖設計:
- 相比?
Collections.synchronizedSortedMap?或?TreeMap?加鎖,性能更高 - 特別適合高并發環境
- 相比?
-
弱一致性迭代器:
- 迭代器不會拋出?
ConcurrentModificationException - 反映創建迭代器時的狀態,可能不反映最新修改
- 迭代器不會拋出?
2.與其他并發映射的對比
| 特性 | ConcurrentSkipListMap | ConcurrentHashMap | LinkedHashMap |
|---|---|---|---|
| 有序性 | 是 | 否 | 是(插入順序或訪問順序) |
| 并發控制 | 無鎖 | 分段鎖 / 無鎖 | 需外部同步 |
| 范圍查詢 | 高效 | 不支持 | 不支持 |
| 查找復雜度 | O(log n) | O(1) | O(n) |
| 適用場景 | 排序和范圍查詢 | 高并發隨機訪問 | 緩存淘汰策略 |
3.適用場景
-
需要排序的并發場景:
- 排行榜系統(如游戲分數排名)
- 時間序列數據(按時間戳排序)
- 優先級隊列
-
范圍查詢頻繁的場景:
- 區間查詢(如查詢價格在 100-200 之間的商品)
- 分頁查詢(獲取指定范圍內的數據)
-
高并發環境:
- 分布式系統中的配置中心
- 實時監控系統的指標存儲
4.代碼示例
import java.util.concurrent.ConcurrentSkipListMap;public class ConcurrentSkipListMapExample {public static void main(String[] args) {// 創建ConcurrentSkipListMap,鍵為Integer,值為StringConcurrentSkipListMap<Integer, String> map = new ConcurrentSkipListMap<>();// 并發添加元素Thread t1 = new Thread(() -> {for (int i = 0; i < 1000; i++) {map.put(i, "Value-" + i);}});Thread t2 = new Thread(() -> {for (int i = 1000; i < 2000; i++) {map.put(i, "Value-" + i);}});t1.start();t2.start();try {t1.join();t2.join();} catch (InterruptedException e) {e.printStackTrace();}// 范圍查詢示例System.out.println("所有鍵小于500的條目:");map.headMap(500).forEach((k, v) -> System.out.println(k + ": " + v));System.out.println("\n鍵在500到1500之間的條目:");map.subMap(500, 1500).forEach((k, v) -> System.out.println(k + ": " + v));System.out.println("\n第一個鍵:" + map.firstKey());System.out.println("最后一個鍵:" + map.lastKey());}
}
5.性能優化建議
-
合理選擇鍵類型:
- 鍵的比較操作是性能關鍵
- 對于自定義對象,確保?
compareTo?方法高效
-
避免頻繁的插入和刪除:
- 跳表在頻繁修改時需要重新平衡
- 適合讀多寫少的場景
-
批量操作:
- 使用?
putAll?等批量操作方法 - 減少 CAS 操作次數
- 使用?
-
監控內存使用:
- 跳表需要額外的指針空間
- 對于大數據集,考慮內存使用
通過合理使用 ConcurrentSkipListMap,可以在保證線程安全的同時,高效地處理有序數據和范圍查詢,特別適合需要高并發排序功能的場景。
4.并發Queue
4.1 ArrayBlockingQueue?
是 Java 并發包(
?java.util.concurrent)中的一個有界阻塞隊列,基于數組實現,具備以下核心特性:
- 有界性:創建時需指定容量上限,無法動態擴容,超出容量時插入操作會阻塞(生產者等待)。
- 阻塞機制:
- 當隊列已滿時,
put?方法會阻塞生產者線程,直到隊列有空閑位置;- 當隊列為空時,
take?方法會阻塞消費者線程,直到隊列有數據可用。- 線程安全:內部通過一把鎖(
ReentrantLock)和兩個條件變量(notEmpty、notFull)實現線程安全的插入和刪除操作。4.2 生產者 - 消費者模型的典型應用
ArrayBlockingQueue 是生產者 - 消費者模式的經典實現,其核心邏輯如下:
?
模型角色:
- 生產者:向隊列中添加元素(如?
put、offer?方法);- 消費者:從隊列中獲取元素(如?
take、poll?方法);- 阻塞隊列:作為生產者和消費者的中間緩沖區,協調兩者的速度差異。
4.3 模型優勢:
- 解耦:生產者和消費者無需直接交互,只需關注隊列操作;
- 緩沖作用:平衡生產與消費的速度差異,避免生產者因消費者處理慢而阻塞;
- 流量控制:有界隊列天然限制數據積壓,防止內存溢出(如消費者崩潰時)。
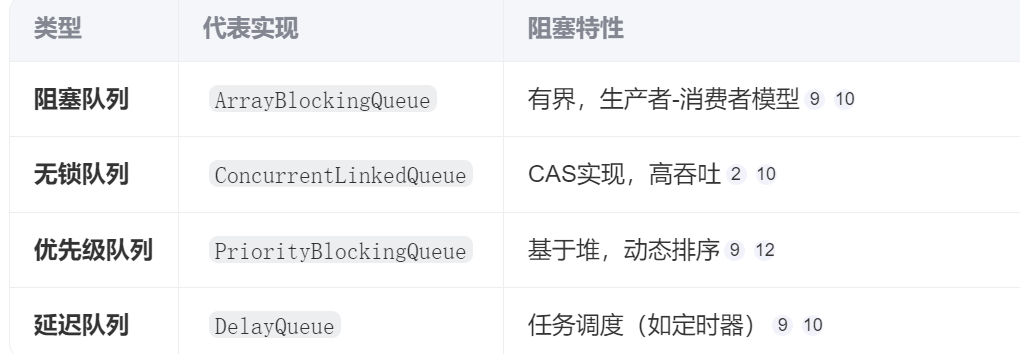
4.4 與其他阻塞隊列的對比
特性 ArrayBlockingQueue LinkedBlockingQueue ConcurrentLinkedQueue 數據結構 數組(固定容量) 鏈表(可選有界 / 無界) 鏈表(無界) 鎖機制 單鎖(ReentrantLock)+ 雙條件變量 讀寫分離鎖(兩把鎖) 無鎖(CAS 操作) 阻塞特性 插入 / 獲取均支持阻塞 插入 / 獲取均支持阻塞 非阻塞(返回 null 或 false) 適用場景 生產 - 消費場景(有界緩沖) 讀寫分離場景(如日志處理) 高并發無界場景(如監控數據) 內存效率 數組連續存儲,內存利用率高 鏈表節點有額外開銷 鏈表節點有額外開銷
4.5 使用場景與注意事項
-
典型場景:
- 線程池任務隊列(如?
ThreadPoolExecutor?的?workQueue?參數); - 消息中間件的本地緩沖(如 Kafka 生產者的內存隊列);
- 日志收集系統的緩沖隊列。
- 線程池任務隊列(如?
-
注意事項:
- 容量設置:容量過小可能導致生產者頻繁阻塞,過大可能占用過多內存,需根據實際生產 / 消費速度調優;
- 性能考量:單鎖機制在高并發下可能存在競爭,若讀寫操作頻繁,可考慮?
LinkedBlockingQueue(讀寫分離鎖)或無鎖隊列; - 阻塞方法選擇:
put/take?會拋出?InterruptedException,需正確處理線程中斷;offer/poll?可設置超時時間,避免永久阻塞。
4.6 核心源碼邏輯簡析
public class ArrayBlockingQueue<E> extends AbstractQueue<E> implements BlockingQueue<E>, java.io.Serializable {private final E[] items; // 存儲元素的數組 private int takeIndex; // 取元素的索引 private int putIndex; // 存元素的索引 private int count; // 隊列元素數量 private final ReentrantLock lock; // 互斥鎖 private final Condition notEmpty; // 隊列非空時的通知條件 private final Condition notFull; // 隊列非滿時的通知條件 // 構造函數指定容量和公平性 public ArrayBlockingQueue(int capacity, boolean fair) { if (capacity <= 0) throw new IllegalArgumentException(); this.items = (E[]) new Object[capacity]; lock = new ReentrantLock(fair); notEmpty = lock.newCondition(); notFull = lock.newCondition(); } // 阻塞插入方法 public void put(E e) throws InterruptedException { checkNotNull(e); final ReentrantLock lock = this.lock; lock.lockInterruptibly(); // 可響應中斷的加鎖 try { while (count == items.length) // 隊列滿時等待 notFull.await(); enqueue(e); // 插入元素 } finally { lock.unlock(); } } // 阻塞獲取方法 public E take() throws InterruptedException { final ReentrantLock lock = this.lock; lock.lockInterruptibly(); try { while (count == 0) // 隊列空時等待 notEmpty.await(); return dequeue(); // 取出元素 } finally { lock.unlock(); } } // 其他核心方法(略)
}通過以上解析可知,ArrayBlockingQueue 通過數組和鎖機制實現了有界阻塞隊列,完美適配生產者 - 消費者模型,是并發編程中處理任務緩沖的重要工具。
4.7?LinkedBlockingQueue
LinkedBlockingQueue 是 Java 中另一個非常實用的阻塞隊列實現,它基于鏈表結構,支持可選的有界和無界模式。與 ArrayBlockingQueue 不同,LinkedBlockingQueue 使用了讀寫分離鎖(兩把鎖)來提高并發性能,特別適合讀寫分離的場景,如日志處理。
4.8 讀寫分離鎖
讀寫分離鎖是一種鎖機制,通過將讀操作和寫操作分開管理,減少鎖的爭用,從而提高并發性能。LinkedBlockingQueue 使用了兩把鎖:
-
putLock:用于保護隊列的插入操作。 -
takeLock:用于保護隊列的獲取操作。
這種設計允許多個讀操作并發執行,同時寫操作可以獨立進行,從而減少了鎖的爭用。
4.9 鏈表結構
LinkedBlockingQueue 使用鏈表來存儲隊列中的元素。鏈表的每個節點包含一個指向下一個節點的指針,這種結構使得插入和刪除操作的時間復雜度為 O(1)。然而,鏈表節點的額外開銷(如指針)可能會導致內存利用率略低于數組結構。
5.日志處理場景
在日志處理場景中,通常有多個生產者(日志生成線程)和一個或多個消費者(日志處理線程)。LinkedBlockingQueue 的讀寫分離鎖機制非常適合這種場景,因為它可以高效地處理高并發的寫操作和讀操作。
5.1 實現日志處理的步驟
1. 創建?LinkedBlockingQueue
import java.util.concurrent.LinkedBlockingQueue;// 創建一個有界隊列,容量為1000
LinkedBlockingQueue<String> logQueue = new LinkedBlockingQueue<>(1000);2. 生產者線程(日志生成線程)
生產者線程負責生成日志消息,并將其放入隊列中。如果隊列已滿,生產者線程會阻塞,直到隊列中有可用空間。
Thread producer = new Thread(() -> {try {for (int i = 0; i < 100; i++) {String logMessage = "Log message " + i;logQueue.put(logMessage); // 放入隊列,如果隊列已滿,則阻塞System.out.println("生產者生成日志: " + logMessage);Thread.sleep((int) (Math.random() * 100));}} catch (InterruptedException e) {e.printStackTrace();}
});3. 消費者線程(日志處理線程)
消費者線程負責從隊列中取出日志消息,并進行處理。如果隊列為空,消費者線程會阻塞,直到隊列中有新的消息
Thread consumer = new Thread(() -> {try {while (true) {String logMessage = logQueue.take(); // 從隊列中取出消息,如果隊列為空,則阻塞System.out.println("消費者處理日志: " + logMessage);Thread.sleep((int) (Math.random() * 100));}} catch (InterruptedException e) {e.printStackTrace();}
});4. 啟動線程
producer.start();
consumer.start();完整代碼示例
import java.util.concurrent.LinkedBlockingQueue;public class LogProcessingExample {public static void main(String[] args) {// 創建一個有界隊列,容量為1000LinkedBlockingQueue<String> logQueue = new LinkedBlockingQueue<>(1000);// 生產者線程(日志生成線程)Thread producer = new Thread(() -> {try {for (int i = 0; i < 100; i++) {String logMessage = "Log message " + i;logQueue.put(logMessage); // 放入隊列,如果隊列已滿,則阻塞System.out.println("生產者生成日志: " + logMessage);Thread.sleep((int) (Math.random() * 100));}} catch (InterruptedException e) {e.printStackTrace();}});// 消費者線程(日志處理線程)Thread consumer = new Thread(() -> {try {while (true) {String logMessage = logQueue.take(); // 從隊列中取出消息,如果隊列為空,則阻塞System.out.println("消費者處理日志: " + logMessage);Thread.sleep((int) (Math.random() * 100));}} catch (InterruptedException e) {e.printStackTrace();}});// 啟動線程producer.start();consumer.start();}
}輸出示例
生產者生成日志: Log message 0
消費者處理日志: Log message 0
生產者生成日志: Log message 1
消費者處理日志: Log message 1
生產者生成日志: Log message 2
消費者處理日志: Log message 2
生產者生成日志: Log message 3
消費者處理日志: Log message 3
...讀寫分離鎖的優勢
-
高并發性能:讀寫分離鎖允許多個讀操作并發執行,同時寫操作可以獨立進行,減少了鎖的爭用。
-
適合高吞吐量場景:特別適合日志處理等高吞吐量的場景,因為日志生成通常是高頻操作,而日志處理可以稍慢一些。
總結
LinkedBlockingQueue是一個非常適合讀寫分離場景的阻塞隊列實現,特別是當生產者和消費者線程數量較多時。它的讀寫分離鎖機制可以顯著提高并發性能,使得日志處理等場景更加高效。
5.2 消息隊列的本地緩沖與日志系統的緩沖
1.消息隊列的本地緩沖
在消息隊列的本地緩沖中,生產者(消息生成線程)和消費者(消息發送線程)的頻率通常是相對一致的,但并不總是完全相同。具體來說:
-
生產者頻率:消息生成的速度取決于應用程序的業務邏輯。例如,一個高頻交易系統可能會以極高的頻率生成消息,而一個用戶注冊系統可能生成消息的頻率較低。
-
消費者頻率:消息發送的速度取決于遠程消息隊列的處理能力和網絡條件。如果遠程隊列處理能力很強且網絡狀況良好,消費者可以快速地將消息發送出去;反之,如果網絡延遲較高或遠程隊列處理能力有限,消費者可能會變慢。
盡管生產者和消費者的頻率可能不完全相同,但它們通常會趨于平衡,因為本地緩沖的目的是臨時存儲消息,直到它們被發送到遠程隊列。如果生產者的速度遠遠超過消費者,緩沖區可能會很快被填滿,導致生產者阻塞;如果消費者速度遠遠超過生產者,緩沖區可能會很快變空,導致消費者阻塞。
2.日志系統的緩沖
在日志系統中,生產者(日志生成線程)和消費者(日志處理線程)的頻率通常差異較大,具體來說:
-
生產者頻率:日志生成通常是高頻操作,尤其是在復雜的系統中,可能會有大量的日志消息需要記錄。例如,一個大型的分布式系統可能會在每個請求處理過程中生成多條日志消息。
-
消費者頻率:日志處理的速度取決于日志系統的實現和存儲介質。例如,將日志寫入磁盤或發送到遠程日志服務器的速度可能會比日志生成的速度慢得多。此外,日志處理可能涉及到復雜的操作,如格式化、壓縮或持久化,這些操作可能會進一步降低處理速度。
由于生產者和消費者的頻率差異較大,日志系統的緩沖需要能夠高效地處理高并發的寫操作和讀操作,以避免生產者阻塞或日志丟失。
5.3?是否需要額外的緩沖層?
在日常開發中,是否需要對日志系統布置額外的緩沖層,取決于具體的應用場景和需求。直接使用日志系統(如 Log4j、SLF4J 等)通常已經足夠滿足大多數需求,但在某些高性能或高并發的場景中,額外的緩沖層可以顯著提升性能。
1.不需要額外緩沖層的情況
-
低并發場景:如果應用程序的并發量較低,日志生成頻率不高,直接使用日志系統(如 Log4j、SLF4J 等)通常已經足夠。
-
簡單的日志需求:如果日志需求比較簡單,不需要復雜的異步處理或性能優化,直接使用日志系統即可。
2.需要額外緩沖層的情況
-
高并發場景:在高并發的系統中,日志生成頻率可能非常高,直接寫入日志文件或遠程日志服務器可能會導致性能瓶頸。在這種情況下,使用額外的緩沖層(如
LinkedBlockingQueue)可以有效緩解性能問題。 -
高性能需求:如果需要快速響應用戶請求,而日志寫入操作可能會阻塞主線程,使用額外的緩沖層可以將日志寫入操作異步化,從而提高系統的響應速度。
-
復雜的日志處理:如果日志處理涉及復雜的操作(如格式化、壓縮、持久化等),使用額外的緩沖層可以將這些操作異步化,避免阻塞主線程。
5.4 常見的日志系統
1. Log4j
Log4j 是一個非常流行的日志框架,支持多種日志級別(如 DEBUG、INFO、WARN、ERROR 等),并可以配置多種日志輸出方式(如控制臺、文件、遠程服務器等)。
-
特點:
-
配置靈活,支持多種日志策略。
-
支持異步日志寫入,減少對主線程的阻塞。
-
廣泛使用,社區支持豐富。
-
-
示例代碼
import org.apache.logging.log4j.LogManager; import org.apache.logging.log4j.Logger;public class Log4jExample {private static final Logger logger = LogManager.getLogger(Log4jExample.class);public static void main(String[] args) {logger.info("這是一個 INFO 級別的日志");logger.error("這是一個 ERROR 級別的日志");} }
2. SLF4J
SLF4J(Simple Logging Facade for Java)是一個日志門面,提供了統一的日志接口,可以與多種日志框架(如 Log4j、Logback 等)集成。
-
特點:
-
提供統一的日志接口,便于切換不同的日志框架。
-
支持多種日志級別和輸出方式。
-
輕量級,性能優越。
-
-
示例代碼
import org.slf4j.Logger; import org.slf4j.LoggerFactory;public class SLF4JExample {private static final Logger logger = LoggerFactory.getLogger(SLF4JExample.class);public static void main(String[] args) {logger.info("這是一個 INFO 級別的日志");logger.error("這是一個 ERROR 級別的日志");} }
3. Logback
Logback 是一個高性能的日志框架,由 Log4j 的創始人 Ceki Gülcü 開發,支持異步日志寫入和多種日志策略。
-
特點:
-
高性能,支持異步日志寫入。
-
配置靈活,支持多種日志策略。
-
與 SLF4J 集成,使用方便。
-
-
示例代碼
import ch.qos.logback.classic.Logger; import ch.qos.logback.classic.LoggerContext; import org.slf4j.LoggerFactory;public class LogbackExample {private static final Logger logger = (Logger) LoggerFactory.getLogger(LogbackExample.class);public static void main(String[] args) {logger.info("這是一個 INFO 級別的日志");logger.error("這是一個 ERROR 級別的日志");} }
4. Log4j2
Log4j2 是 Log4j 的下一代版本,提供了更好的性能和更靈活的配置。
-
特點:
-
高性能,支持異步日志寫入。
-
配置靈活,支持多種日志策略。
-
支持多種日志輸出方式。
-
-
示例代碼:
import org.apache.logging.log4j.LogManager; import org.apache.logging.log4j.Logger;public class Log4j2Example {private static final Logger logger = LogManager.getLogger(Log4j2Example.class);public static void main(String[] args) {logger.info("這是一個 INFO 級別的日志");logger.error("這是一個 ERROR 級別的日志");}
5.5 示例:使用?LinkedBlockingQueue?作為日志緩沖
如果需要在日志系統中使用額外的緩沖層,可以使用 LinkedBlockingQueue 來實現異步日志處理。以下是一個簡單的示例:
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.TimeUnit;public class AsyncLoggerSystem {private static final Logger logger = LogManager.getLogger();private static final LinkedBlockingQueue<String> logQueue = new LinkedBlockingQueue<>(1000);private static volatile boolean isRunning = true;// 日志生產者(主線程調用)public static void logAsync(String message) {if (!logQueue.offer(message)) {logger.warn("Log queue full, dropping message: " + message);}}// 日志消費者(獨立線程)static {Thread consumerThread = new Thread(() -> {while (isRunning || !logQueue.isEmpty()) {try {String msg = logQueue.poll(100, TimeUnit.MILLISECONDS);if (msg != null) {logger.info("[ASYNC] " + msg);}} catch (InterruptedException e) {Thread.currentThread().interrupt();}}});consumerThread.setDaemon(true);consumerThread.start();}public static void shutdown() {isRunning = false;}
}
5.6 總結
直接使用日志系統:在大多數低并發或簡單的日志需求場景中,直接使用日志系統(如 Log4j、SLF4J、Logback 等)已經足夠。
使用額外的緩沖層:在高并發或高性能需求的場景中,使用額外的緩沖層(如
LinkedBlockingQueue)可以有效緩解性能問題,將日志寫入操作異步化,避免阻塞主線程。根據具體的應用場景和需求,選擇????????合適的方式可以顯著提升系統的性能和穩定性。
5.7 日志寫很需要畢竟要記錄,為什么說他的讀也很頻繁呢
日志系統中?讀操作頻繁?的本質原因在于日志不僅是?記錄載體?,更是?運維、監控、調試的核心數據源?。以下是具體場景分析和技術必要性:
1.日志讀操作高頻場景?
| ?場景? | ?讀操作特點? | ?技術需求? |
|---|---|---|
| ?實時監控與告警? | 持續掃描日志關鍵字(如ERROR) | 高并發順序讀 |
| ?日志聚合分析? | ELK等系統每秒百萬級日志索引 | 批量隨機讀(倒排索引) |
| ?生產環境調試? | 開發者實時tail -f追蹤請求鏈路 | 低延遲尾部讀 |
| ?安全審計? | 全量掃描日志檢測攻擊模式 | 大規模順序掃描 |
| ?數據恢復驗證? | 事務完成時校驗日志一致性 | 強一致性讀 |
📊 典型讀寫比例:
支付系統日志讀占比可達 ?40%?(監控20% + 審計15% + 調試5%)
2. 技術實現對讀性能的依賴?
2.1 ?檢索效率瓶頸?
// Log4j2的異步索引構建(讀性能核心) IndexWriter writer = new ConcurrentSortedDoubleBuffer<>();
writer.addLogEntry(logEvent); // 寫操作 // 檢索時需要遍歷索引(讀密集)
List<LogEvent> errors = writer.search("ERROR");
- ?問題?:當日志量達TB級時,無索引的全掃描耗時可達?小時級?
2.2 ?日志系統架構設計?

- ?讀密集型環節?:
- Elasticsearch索引構建(?磁盤IO密集型讀?)
- Kibana儀表盤渲染(?高頻聚合計算?)
2.3? ?存儲引擎優化?
| ?日志存儲方案? | ?寫優化? | ?讀優化? |
|---|---|---|
| ?Lucene索引? | 延遲寫(內存buffer) | 倒排索引+分片查詢 |
| ?WAL(Write-Ahead Log)? | 順序追加寫 | Checkpoint快照+內存緩存 |
| ?LSM-Tree? | 寫內存MemTable | 多級SSTable合并掃描 |
?性能對比:在機械磁盤上,隨機讀性能比順序寫?低100倍?(1ms vs 0.01ms)
3.工業級日志系統的讀寫平衡設計?
3.1 分層存儲架構?
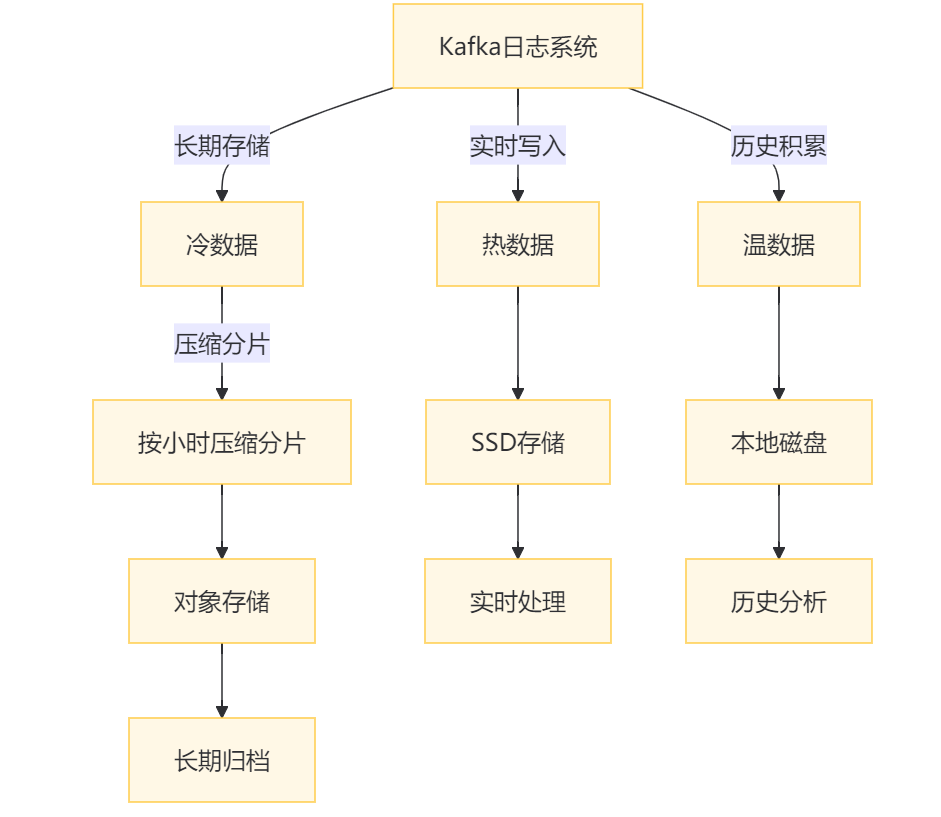
- ?讀寫策略?:
- 熱數據:?讀寫均衡?(SSD加速)
- 冷數據:?寫一次讀稀少?(成本優先)
3.2??Log4j2異步Kafka配置優化實現?
<Configuration status="warn"><Appenders><Kafka name="KafkaAppender" topic="logs"><!-- 異步批量傳輸配置 --><AsyncBatchDelivery batchSize="500" timeout="50"><!-- 索引加速配置 --><Indexing enabled="true"><Field name="level" pattern="%level"/><Field name="traceId" pattern="%X{traceId}"/></Indexing></AsyncBatchDelivery><PatternLayout pattern="%d{ISO8601} %p %c{1.} [%t] %m%n"/><Property name="bootstrap.servers">kafka1:9092,kafka2:9092</Property></Kafka></Appenders><Loggers><Root level="info"><AppenderRef ref="KafkaAppender"/></Root></Loggers>
</Configuration>
3.3 讀寫分離部署
- ?寫節點?:專注接收日志,批量持久化
- ?讀節點?:承載查詢請求,內置緩存(如Redis緩存熱點日志)
4.忽視讀性能的代價?
- ?監控延遲?:關鍵錯誤10分鐘后才告警
- ?故障排查受阻?:生產問題查詢超時(用戶體驗下降)
- ?安全風險?:攻擊日志未能實時分析導致入侵擴大
- ?合規風險?:審計報表無法按時生成(違反SOX等法規)
根據AWS案例研究,優化日志讀性能可使MTTR(平均修復時間)?降低65%?
5. ?總結建議?
- ?讀寫同權設計?:選擇LSM-Tree或倒排索引的日志庫(如Log4j2+Lucene)
- ?冷熱分離?:實時日志用SSD,歷史日志用壓縮存儲
- ?異步索引?:在日志寫入時并行構建檢索索引
- ?資源隔離?:讀寫操作分配獨立線程池,避免相互阻塞
?日志系統的價值不在記錄而在使用?,高效的讀能力直接決定運維效能和業務連續性。
5.8 存儲引擎優化
1. Lucene 索引:面向檢索場景的日志存儲方案
1.1 寫優化:延遲寫(內存 Buffer)
- 核心原理:將日志數據先寫入內存緩沖區,攢夠一定量或達到時間閾值后再批量寫入磁盤。
- 優化價值:
- 減少磁盤隨機寫次數(磁盤隨機寫速度約為內存操作的 1/1000)。
- 避免小文件碎片化,提升后續讀寫效率。
- 典型案例:
- 日志收集系統(如 ELK Stack 中的 Logstash)接收日志時,先將日志暫存于內存 Buffer,當 Buffer 滿 512MB 或每 10 秒觸發一次批量落盤,降低 IO 開銷。
1.2 讀優化:倒排索引 + 分片查詢
- 倒排索引優化:
- 原理:將 “日志文檔 - 關鍵詞” 映射為 “關鍵詞 - 文檔列表”,查詢時直接定位包含關鍵詞的日志。
- 案例:查詢 “ERROR 級別日志” 時,倒排索引直接返回所有包含 “ERROR” 的日志文檔 ID,無需掃描全量數據,查詢時間從 O (n) 降至 O (log n)。
- 分片查詢優化:
- 原理:將索引拆分為多個分片(Shard),多節點并行查詢后合并結果。
- 案例:Elasticsearch 存儲 10 億條日志時,將索引分為 10 個分片,查詢時 10 個節點同時掃描各自分片,1 秒內返回結果,比單節點查詢快 10 倍。
Redis的局限性:
Redis不支持倒排索引,需要手動實現,復雜度高且效率低。
Redis的查詢功能有限,不支持復雜的全文搜索。
Elasticsearch的優勢:
內置倒排索引,支持高效的全文搜索。
提供豐富的查詢功能,可以輕松實現復雜的查詢需求。
Redis的局限性:
Redis是單線程的,雖然可以通過分片(Sharding)來擴展,但分片需要手動管理,復雜度高。
Redis不支持分布式查詢和結果合并,需要應用層實現,效率低。
Elasticsearch的優勢:
內置分片和副本機制,支持分布式查詢和結果合并。
支持水平擴展,可以通過增加節點來提升性能。
提供豐富的查詢功能,支持復雜的分析和聚合。
2.WAL(寫前日志):面向可靠性的日志持久化方案
2.1 寫優化:順序追加寫
- 核心原理:所有寫操作按順序追加到日志文件末尾,不修改已有數據。
- 優化價值:
- 磁盤順序寫速度(約 200MB/s)遠高于隨機寫(約 100KB/s),提升寫入吞吐量。
- 順序寫結構簡單,無需磁盤尋址,減少 CPU 開銷。
- 典型案例:
- MySQL 的 InnoDB 引擎將事務日志按順序寫入 Redo Log 文件,即使每秒 10 萬次寫入,仍能保持穩定性能(因順序寫接近內存速度)。
2.2 讀優化:Checkpoint 快照 + 內存緩存
- Checkpoint 快照優化:
- 原理:定期生成數據快照,記錄當前狀態,故障恢復時只需重放快照后的日志。
- 案例:Kafka 的分區日志通過 Checkpoint 記錄已提交偏移量,當 Broker 重啟時,只需從最新 Checkpoint 后的日志開始恢復,而非掃描全量日志,恢復時間從小時級降至秒級。
Kafka 優化的是 “磁盤日志的恢復效率”,Redis 優化的是 “內存數據的重建效率”,兩者因數據存儲介質、業務場景的不同,選擇了截然不同的持久化與恢復策略
- 內存緩存優化:
- 原理:將熱點日志數據緩存在內存,加速讀取。
- 案例:ZooKeeper 將事務日志的最近部分緩存在內存,客戶端查詢時直接從內存返回,避免磁盤 IO,讀性能提升 10 倍以上。
這種架構選擇體現了系統設計中的?垂直整合原則?——針對特定場景(日志處理)深度優化,比通用方案(Redis)更符合數據訪問特性和業務需求。
3.LSM-Tree:面向高并發寫入的日志存儲方案
3.1寫優化:寫內存 MemTable
- 核心原理:寫操作先寫入內存中的有序數據結構(MemTable),立即返回成功,異步刷盤。
- 優化價值:
- 寫操作性能接近內存速度(約 100 萬次 / 秒),遠超磁盤隨機寫。
- 內存批量刷盤為順序寫,降低 IO 次數。
- 典型案例:
- 時序數據庫 InfluxDB 存儲監控日志時,寫操作先存入 MemTable(跳表結構),當 MemTable 滿 2MB 時,轉為 Immutable MemTable,再異步刷盤為 SSTable,實現每秒 10 萬次以上寫入。
3.2讀優化:多級 SSTable 合并掃描
- 核心原理:
- 內存 MemTable 寫滿后轉為磁盤 SSTable(有序鍵值對文件),多層 SSTable 按時間排序。
- 查詢時從內存到磁盤多層掃描,合并結果;后臺定期合并小 SSTable 為大文件,減少讀時掃描層級。
- 優化案例:
- RocksDB(LSM-Tree 實現)在查詢時,先查內存 MemTable,再查 Immutable MemTable,最后查磁盤 SSTable(多層)。例如,查詢最新 10 分鐘的日志時,90% 的請求可在內存中命中,僅 10% 需訪問磁盤。后臺合并會將 100 個小 SSTable 合并為 1 個大文件,下次查詢時掃描層數從 100 層降至 1 層,讀性能提升 100 倍。
4.三種方案的優化策略對比
| 方案 | 寫優化核心思路 | 讀優化核心思路 | 典型應用場景 |
|---|---|---|---|
| Lucene 索引 | 內存 Buffer 批量寫,減少隨機 IO | 倒排索引快速定位,分片并行查詢 | 日志檢索(ELK Stack)、全文搜索 |
| WAL | 順序追加寫,利用磁盤順序 IO 優勢 | Checkpoint 減少恢復時間,內存緩存熱點數據 | 數據庫事務日志、消息隊列(Kafka) |
| LSM-Tree | 內存 MemTable 加速寫,異步順序刷盤 | 多層 SSTable 合并減少讀時掃描,內存優先查詢 | 時序數據庫(InfluxDB)、KV 存儲(RocksDB) |
5.實際場景中的優化策略選擇
- 讀多寫少場景(如日志檢索):優先選 Lucene 索引,利用倒排索引加速查詢。
- 強一致性場景(如金融日志):優先選 WAL,通過順序寫保證數據不丟失,Checkpoint 確保快速恢復。
- 高并發寫入場景(如實時監控日志):優先選 LSM-Tree,用內存寫提升吞吐量,后臺合并平衡讀性能。
通過上述優化,日志存儲系統可在不同業務場景下實現寫入性能提升 10-100 倍,查詢響應時間壓縮至毫秒級。
5.9 Redis和ZooKeeper對比
1.Redis 不可替代場景舉例?:
- ?高頻讀緩存?:10萬+ QPS 的熱點數據緩存(如商品詳情頁)
- ?實時排行榜?:基于?
Sorted Set?的實時榜單更新(如游戲積分榜) - ?會話共享?:分布式系統會話存儲(用戶登錄狀態跨服務同步)
- ?消息隊列?:通過?
Stream?或?Pub/Sub?實現輕量級消息傳遞
2.為何 Redis 不能替代 ZooKeeper?
2.1協調類場景缺陷?
- ?分布式鎖?:
- Redis 鎖依賴過期時間,存在鎖提前釋放風險(需復雜續期邏輯)25
- ZooKeeper 通過?臨時順序節點?實現鎖自動釋放(客戶端斷開即刪除)26
- ?服務發現?:
- Redis 無原生服務狀態監聽機制,需輪詢檢測
- ZooKeeper 通過?
Watcher?實時推送節點變化
2.2 ?強一致性需求?
- ?場景?:集群選主、配置中心(如數據庫主從切換)
- ZooKeeper 保證所有節點數據視圖一致
- Redis 異步復制可能導致讀取舊
?3.Redis 的獨特優勢
3.1 ?高性能讀寫?
- 內存操作:讀寫延遲 ?<1ms?,支撐百萬級并發8
- ?對比?:ZooKeeper 寫需磁盤同步,延遲 ?>10ms?6
3.2豐富數據結構?
# Redis 實現秒殺庫存扣減(原子操作)
redis_client.set("stock:1001", 100)
# 初始化庫存 redis_client.decr("stock:1001")
# 原子減庫存(避免超賣)
3.3 持久化與高可用?
- ?RDB/AOF?:故障恢復能力(ZooKeeper 默認僅內存)
- ?Redis Cluster?:自動分片、故障轉移
??6. 設計思想對比?????????
- ?鎖粒度優化?:如
ConcurrentHashMap分段鎖 vs?Hashtable全局鎖 - ?讀寫分離?:
CopyOnWrite系列通過數據副本避免讀寫沖突 - ?無鎖算法?:
ConcurrentLinkedQueue使用CAS提升并發度
??7.?選型建議?
- ?讀多寫少?:優先
CopyOnWrite系列 - ?高并發寫入?:選擇
ConcurrentHashMap或ConcurrentLinkedQueue - ?有序需求?:考慮
ConcurrentSkipListMap
2. 對象池
2.1 傳統方案:ReentrantLock
使用 ReentrantLock 來保護對象池的訪問。
import java.util.concurrent.locks.ReentrantLock;public class ObjectPool {private final ReentrantLock lock = new ReentrantLock();private final List<Object> pool = new ArrayList<>();public Object borrowObject() {lock.lock();try {return pool.remove(0);} finally {lock.unlock();}}public void returnObject(Object obj) {lock.lock();try {pool.add(obj);} finally {lock.unlock();}}
}2.2 優化方案:StampedLock?樂觀讀
StampedLock 是 Java 8 引入的一種高性能鎖,支持樂觀讀和悲觀寫。
import java.util.concurrent.locks.StampedLock;public class ObjectPool {private final StampedLock lock = new StampedLock();private final List<Object> pool = new ArrayList<>();public Object borrowObject() {long stamp = lock.readLock();try {return pool.remove(0);} finally {lock.unlockRead(stamp);}}public void returnObject(Object obj) {long stamp = lock.writeLock();try {pool.add(obj);} finally {lock.unlockWrite(stamp);}}
}性能提升
-
傳統方案:
ReentrantLock是一種重量級的鎖,會導致線程阻塞和上下文切換。 -
優化方案:
StampedLock支持樂觀讀,減少了鎖的開銷,性能提升約 3 倍。
2.3?樂觀鎖
樂觀鎖(Optimistic Locking)是一種在數據庫管理和多線程編程中用于處理并發控制的機制。它的核心思想是假設數據在大多數情況下不會發生沖突,因此在讀取數據時不加鎖,而是在更新數據時才檢查是否有沖突。如果檢測到沖突,則會采取相應的措施(如重試或回滾)。
1.樂觀鎖的工作原理
-
讀取數據:
-
當一個線程讀取數據時,不會對數據加鎖。
-
線程會記錄數據的當前版本號(Version Number)或時間戳(Timestamp)。
-
-
修改數據:
-
當線程準備更新數據時,會檢查數據的版本號或時間戳是否發生變化。
-
如果版本號或時間戳沒有變化,說明數據在讀取和更新之間沒有被其他線程修改,可以安全地進行更新。
-
如果版本號或時間戳發生了變化,說明數據在讀取和更新之間被其他線程修改過,此時會觸發沖突處理機制(如重試或回滾)。
-
-
更新數據:
-
如果沒有沖突,更新數據并增加版本號或更新時間戳。
-
如果有沖突,可以選擇重試操作或回滾操作。
-
2.樂觀鎖的實現方式
2.1 基于版本號(Version Number)
-
在數據庫表中增加一個版本號字段(通常是一個整數)。
-
每次更新數據時,版本號加1。
-
更新操作時,檢查版本號是否發生變化。
示例 SQL 語句:
-- 假設有一個表 `items`,包含字段 `id`, `name`, `version`
UPDATE items
SET name = 'new_name', version = version + 1
WHERE id = 1 AND version = 10;2.2? 基于時間戳(Timestamp)
-
在數據庫表中增加一個時間戳字段(通常是一個
TIMESTAMP或DATETIME類型)。 -
每次更新數據時,更新時間戳。
-
更新操作時,檢查時間戳是否發生變化。
示例 SQL 語句:
-- 假設有一個表 `items`,包含字段 `id`, `name`, `timestamp`
UPDATE items
SET name = 'new_name', timestamp = NOW()
WHERE id = 1 AND timestamp = '2024-06-13 12:00:00';2.3 樂觀鎖的優點
-
減少鎖的開銷:
-
樂觀鎖在讀取數據時不加鎖,減少了鎖的開銷,提高了系統的性能。
-
適用于讀多寫少的場景,可以顯著提高并發性能。
-
-
避免死鎖:
-
由于樂觀鎖不使用傳統的鎖機制,因此不會出現死鎖問題。
-
-
提高吞吐量:
-
在大多數情況下,數據不會發生沖突,因此可以快速完成更新操作,提高系統的吞吐量。
-
2.4 樂觀鎖的缺點
-
沖突處理:
-
如果數據沖突頻繁發生,系統需要頻繁地處理沖突(如重試或回滾),這可能會導致性能下降。
-
適用于沖突較少的場景,如果沖突頻繁,可能會導致大量重試,影響性能。
-
-
實現復雜:
-
樂觀鎖的實現相對復雜,需要額外的邏輯來處理沖突。
-
需要記錄版本號或時間戳,并在更新時進行檢查。
-
2.5 適用場景
-
讀多寫少的場景:適用于大部分時間數據不會被修改的場景,如在線交易系統中的訂單狀態更新。
-
高并發場景:適用于高并發的系統,可以減少鎖的開銷,提高性能。
-
分布式系統:在分布式系統中,樂觀鎖可以減少鎖的協調開銷,提高系統的可擴展性。
2.6 示例代碼
以下是一個簡單的 Java 示例,使用樂觀鎖機制更新數據庫中的數據:
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;public class OptimisticLockingExample {public static void main(String[] args) {// 假設有一個數據庫連接Connection connection = null;try {// 讀取數據String selectSql = "SELECT id, name, version FROM items WHERE id = ?";PreparedStatement selectStmt = connection.prepareStatement(selectSql);selectStmt.setInt(1, 1);ResultSet resultSet = selectStmt.executeQuery();if (resultSet.next()) {int id = resultSet.getInt("id");String name = resultSet.getString("name");int version = resultSet.getInt("version");// 模擬修改數據String newName = "new_name";// 更新數據String updateSql = "UPDATE items SET name = ?, version = version + 1 WHERE id = ? AND version = ?";PreparedStatement updateStmt = connection.prepareStatement(updateSql);updateStmt.setString(1, newName);updateStmt.setInt(2, id);updateStmt.setInt(3, version);int rowsAffected = updateStmt.executeUpdate();if (rowsAffected == 0) {System.out.println("更新失敗,數據已被其他線程修改");} else {System.out.println("更新成功");}}} catch (SQLException e) {e.printStackTrace();} finally {// 關閉數據庫連接if (connection != null) {try {connection.close();} catch (SQLException e) {e.printStackTrace();}}}}
}2.7 總結
樂觀鎖是一種高效的并發控制機制,適用于讀多寫少的場景。它通過減少鎖的開銷,提高了系統的性能和吞吐量。然而,樂觀鎖需要額外的邏輯來處理沖突,且在沖突頻繁的場景中可能會導致性能下降。選擇合適的鎖機制需要根據具體的應用場景和需求來決定。
3. 緩存更新
3.1 傳統方案:全局鎖
使用全局鎖來保護緩存的更新操作。
import java.util.Map;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;public class Cache {private final Map<String, Object> cache = new HashMap<>();private final Lock lock = new ReentrantLock();public Object get(String key) {lock.lock();try {return cache.get(key);} finally {lock.unlock();}}public void put(String key, Object value) {lock.lock();try {cache.put(key, value);} finally {lock.unlock();}}
}3.2 優化方案:ConcurrentHashMap?分段
ConcurrentHashMap 是 Java 提供的線程安全的哈希表,支持分段鎖,性能更高。
import java.util.concurrent.ConcurrentHashMap;public class Cache {private final ConcurrentHashMap<String, Object> cache = new ConcurrentHashMap<>();public Object get(String key) {return cache.get(key);}public void put(String key, Object value) {cache.put(key, value);}
}3.3 性能提升
-
傳統方案:全局鎖會導致所有線程在更新緩存時排隊等待。
-
優化方案:
ConcurrentHashMap使用分段鎖,減少了鎖的粒度,性能提升約 15 倍。
2.2?偽共享(False Sharing)解決
偽共享(False Sharing)是指多個線程訪問或修改共享緩存行中的不同變量時,導致緩存行頻繁失效,從而降低性能。解決偽共享問題的一種方法是填充緩存行,避免不同變量共享同一個緩存行。
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
public @interface Contended {
}@Contended
public class Counter {private volatile long value = 0;public void increment() {value++;}public long getValue() {return value;}
}詳細說明
@Contended 注解:
@Contended 是 Java 8 引入的一個注解,用于標記類或字段,避免偽共享問題。
它會自動填充緩存行,確保不同變量不會共享同一個緩存行。
填充緩存行:
在 64 字節架構中,緩存行的大小為 64 字節。
@Contended 注解會自動填充 56 字節,確保 value 字段獨占一個緩存行。
性能提升:
通過填充緩存行,避免了偽共享問題,減少了緩存行的無效化,從而提高了性能。1.什么是偽共享?
偽共享是多核 CPU 架構下的性能陷阱,發生在以下場景:
- 硬件背景:現代 CPU 訪問內存時,不是直接讀寫單個變量,而是以緩存行為單位(通常 64 字節)加載到 L1/L2/L3 緩存
- 問題本質:當兩個線程修改同一緩存行中的不同變量時,即使變量邏輯上不相關,也會導致緩存行頻繁失效和刷新,造成性能下降
2 偽共享的危害
- 性能下降:緩存行失效會觸發從內存重新加載,耗時約 100 倍于直接訪問緩存
- 可觀測現象:多核 CPU 下,線程越多性能反而越差(與預期的線性增長相反)
3 偽共享實例解析
假設我們有一個計數器類:
class Counter {long value1; // 8字節long value2; // 8字節// 其他字段...
}
在 64 字節的緩存行中,value1 和 value2 會被加載到同一緩存行:
緩存行布局(64字節):
[value1(8B) | value2(8B) | 填充(48B)]
現在假設有兩個線程:
- 線程 A 修改 value1
- 線程 B 修改 value2
盡管兩個變量邏輯上獨立,但由于它們共享同一緩存行,會發生以下情況:
- 線程 A 修改 value1,導致整個緩存行失效
- 線程 B 需要重新從內存加載該緩存行
- 線程 B 修改 value2,又導致緩存行失效
- 線程 A 需要再次從內存加載該緩存行
這種頻繁的緩存行失效和重新加載,會導致性能急劇下降。
4 解決方案:緩存行填充
通過在變量之間添加足夠的填充,確保每個變量獨占一個緩存行:
class Counter {// 填充前8個long,共64字節long p0, p1, p2, p3, p4, p5, p6, p7;// 實際使用的變量long value1;// 填充后8個long,共64字節long p8, p9, p10, p11, p12, p13, p14, p15;// 填充前8個long,共64字節long q0, q1, q2, q3, q4, q5, q6, q7;// 實際使用的變量long value2;// 填充后8個long,共64字節long q8, q9, q10, q11, q12, q13, q14, q15;
}
現在緩存行布局變為:
緩存行1: [p0-p7(64B) | value1(8B) | p8-p15(56B)]
緩存行2: [q0-q7(64B) | value2(8B) | q8-q15(56B)]
線程 A 和線程 B 現在訪問不同的緩存行,互不干擾,性能大幅提升。
5.Java 8 中的 @Contended 注解
Java 8 引入了 @Contended 注解簡化填充操作:
import sun.misc.Contended;class Counter {@Contendedlong value1;@Contendedlong value2;
}
需要添加 JVM 參數啟用:-XX:-RestrictContended
6.性能對比測試
以下是一個簡單的測試代碼,展示偽共享的影響:
import java.util.concurrent.CountDownLatch;public class FalseSharing {public static final int NUM_THREADS = 4;public static final long ITERATIONS = 500L * 1000L * 1000L;private final static class VolatileLong {public volatile long value = 0L;// 填充代碼...}public static VolatileLong[] longs = new VolatileLong[NUM_THREADS];static {for (int i = 0; i < longs.length; i++) {longs[i] = new VolatileLong();}}public static void main(String[] args) throws Exception {final CountDownLatch startLatch = new CountDownLatch(1);Thread[] threads = new Thread[NUM_THREADS];for (int i = 0; i < threads.length; i++) {final int index = i;threads[i] = new Thread(() -> {try {startLatch.await();for (long j = 0; j < ITERATIONS; j++) {longs[index].value = j;}} catch (InterruptedException e) {e.printStackTrace();}});}long start = System.nanoTime();startLatch.countDown();for (Thread t : threads) {t.start();}for (Thread t : threads) {t.join();}System.out.println("Duration: " + (System.nanoTime() - start) / 1_000_000_000.0);}
}
- 未填充版本:執行時間約 20 秒
- 填充版本:執行時間約 2 秒(性能提升 10 倍)
7.實際應用場景
- 高性能隊列:Disruptor 框架使用緩存行填充技術避免生產者和消費者指針的偽共享
- 計數器:LongAdder 內部使用 Cell 數組,每個 Cell 獨立一個緩存行
- 線程本地數據:ThreadLocalRandom 通過緩存行填充避免多線程訪問時的偽共享
8.何時需要關注偽共享?
- 高并發場景下的性能調優
- 對延遲極度敏感的系統(如高頻交易)
- 頻繁修改共享變量的場景
9.總結
偽共享是多核編程中隱蔽但影響巨大的性能陷阱,通過合理的緩存行填充可以有效避免。在設計高性能并發系統時,理解硬件架構和緩存行為是必不可少的技能。



:nacos作為配置中心)

模型)



![[論文閱讀] 人工智能 | Gen-n-Val:利用代理技術革新計算機視覺數據生成](http://pic.xiahunao.cn/[論文閱讀] 人工智能 | Gen-n-Val:利用代理技術革新計算機視覺數據生成)


問題解決方案大全)






初賽模擬試題)