分層強化學習(Hierarchical Reinforcement Learning, HRL)最早一般視為1993 年封建強化學習的提出.
一、HL的基礎理論
1.1 MDP
MDP(馬爾可夫決策過程):MDP是一種用于建模序列決策問題的框架,包含狀態(state)、動作(action)、轉移概率(transition probability)、獎勵(reward)等要素。它假設系統在每個時間步的狀態轉移是馬爾可夫的,即當前狀態和動作決定了下一個狀態的概率分布。MDP的時間步是固定的,每次狀態轉移都發生在相同的時間間隔內.
1.主要理論
- 馬爾可夫決策過程(MDP):強化學習的核心數學模型,包括狀態、動作、獎勵和轉移概率。
- 貝爾曼方程:用于計算價值函數和最優策略的遞推關系。
- 折扣因子與回報:通過折扣因子對未來的獎勵進行折現,以計算長期回報。
- 策略與價值函數:策略定義了在每個狀態下選擇動作的方式,價值函數評估狀態或動作的價值。
- 最優性與貝爾曼最優性方程:用于確定最優策略和最優價值函數
2. 算法分類
1.2 SMDP
SMDP(半馬爾可夫決策過程):SMDP是MDP的擴展,用于處理動作持續時間不固定的情況。在SMDP中,每個動作的執行時間(稱為停留時間)是一個隨機變量,狀態在這段時間內保持不變。SMDP的狀態轉移不僅取決于當前狀態和動作,還與動作的持續時間有關.
1. 定義
SMDP可以定義為一個五元組 (S,A,P,T,R):
- S:狀態集合。
- A:動作集合。
- P:狀態轉移概率,表示從狀態 s 執行動作 a 轉移到狀態 s′ 的概率。
- T:動作的停留時間分布,表示動作持續的時間步數。
- R:獎勵函數,表示在狀態 s 執行動作 a 獲得的即時獎勵
2. 關鍵公式
- 期望回報:SMDP的目標是在不同時間間隔的任務中最大化長期期望回報。其回報函數包括時間間隔的折扣:
R = ∑ t = 0 ∞ γ τ t r t R=\sum_{t=0}^{∞} \gamma^{\tau_t}r_t R=t=0∑∞?γτt?rt?
γ \gamma γ 是折扣因子, τ t \tau_t τt?? 是動作持續的時間間隔
- Bellman方程:SMDP的值函數可以通過Bellman方程擴展為半馬爾可夫形式。在給定策略 π 下,狀態 s 的值函數表示為:
V π ( s ) = E π [ r ( s , a ) + γ τ V π ( s ′ ) ] V^{\pi}(s) =\mathbb{E}_{\pi}[r(s,a)+\gamma^{\tau}V^{\pi}(s')] Vπ(s)=Eπ?[r(s,a)+γτVπ(s′)]
其中, r ( s , a ) r(s,a) r(s,a) 是在狀態 s 執行動作 a 的即時獎勵, τ \tau τ 是動作持續時間,s′ 是轉移后的狀態
- Q-learning擴展:SMDP中的Q-learning算法類似于標準的Q-learning,但需要考慮時間間隔的影響。其Q值更新公式為:
Q ( s , a ) ← Q ( s , a ) + α ( r + γ τ max ? a ′ Q ( s ′ , a ′ ) ? Q ( s , a ) ) Q(s,a) \leftarrow Q(s,a)+\alpha(r+\gamma^{\tau} \max_{a'} Q(s',a')-Q(s,a)) Q(s,a)←Q(s,a)+α(r+γτa′max?Q(s′,a′)?Q(s,a))
其中,α 是學習率
3. 分層架構
SMDP在分層強化學習中常用于建模高層策略和低層策略的不同時間尺度:
-
高層策略:負責選擇長期目標或子任務,這些目標可能需要多個時間步來完成
-
低層策略:在較短的時間步內執行具體動作,以實現高層策略設定的目標
1.3 MDP和SMDP的異同
| 特性 | MDP | SMDP |
|---|---|---|
| 時間步 | 時間步是固定的,每次狀態轉移的時間間隔相同 | 時間步是可變的,每個動作的持續時間是一個隨機變量 |
| 狀態轉移 | 轉移概率僅依賴于當前狀態和動作 | 轉移概率不僅依賴于當前狀態和動作,還與動作的持續時間有關 |
| 適用場景 | 適用于固定時間步的決策問題,如機器人每秒更新狀態 | 適用于動作持續時間不固定的復雜任務,如無人機在目標區域盤旋 |
| 復雜度 | 相對簡單,適合短時間跨度的任務 | 更復雜,適合長時間跨度或多步策略的任務 |
| 分層結構 | 通常不涉及分層 | 常用于分層強化學習,高層策略選擇長期目標,低層策略執行具體動作 |
二、HRL
分層強化學習 的核心是通過層次化分解復雜任務,以提高學習效率和策略泛化能力。
層次結構:分層強化學習中通常存在多個層次,每個層次負責不同粒度的決策。高層次負責抽象和長期規劃,而低層次負責具體操作和短期執行。
可提供的參考資料:
-
《一文看盡系列:分層強化學習(HRL)經典論文全面總結》 ,騰訊云文章
-
《分層強化學習(Hierarchical RL)》 ,華為云
-
【Hierarchical RL】不允許你不了解分層強化學習(總結篇) ,騰訊云
2.1 Options框架
-
定義:將動作序列抽象為“選項”(Option),每個選項包含三個部分:初始狀態集(Initiation Set)、內部策略(Policy)和終止條件(Termination Condition)。上層策略通過調用選項解決半馬爾可夫決策過程(semi-MDP)(SMDP)。
-
優勢:縮短時間步長,解決長序列任務的稀疏獎勵問題。例如,導航任務中“移動到某區域”可視為一個選項.
-
細節: 將行動策略視為可選項(option),每個選項由三個部分組成:
- 初始集(Initiation Set):定義在哪些狀態下可以選擇該選項。
- 政策(Policy):定義在選項被激活期間如何進行行動選擇。
- 終止條件(Termination Condition):定義何時結束該選項。
-
理論支持:由于選項可能會持續不定長時間,因此分層強化學習常用SMDP來建模,這種模型允許動作(即選項)具有可變長度的持續時間。
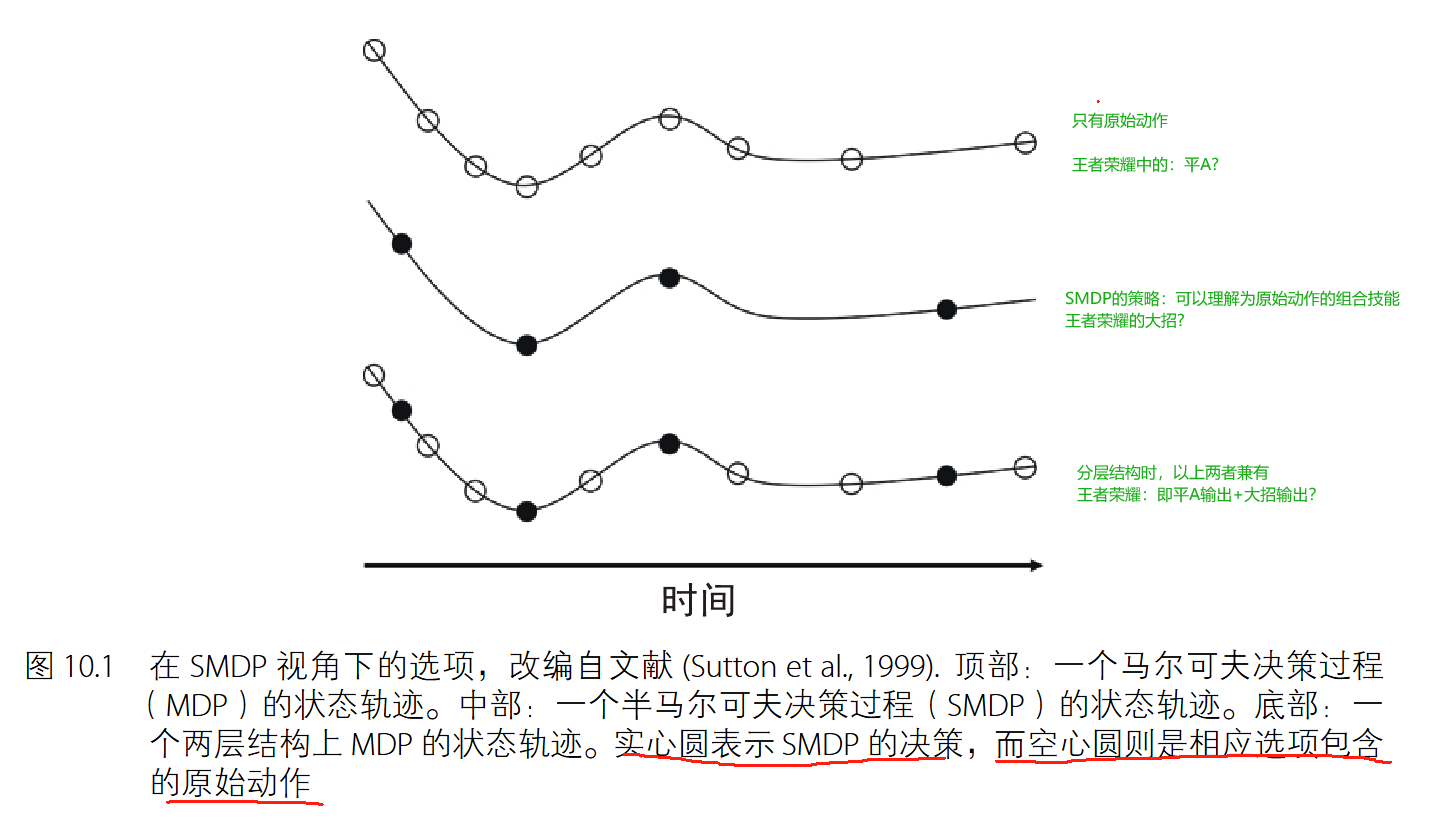
選項(Options),也被稱為技能 或者 宏操作,是一種具有終止條件的子策略。它觀察環境并輸出動作,直到滿足終止條件為止。終止條件是一類時序上的隱式分割點,來表示相應的子策略已經完成了自己的工作,且頂層的選項策略(Policy-Over-Action)需要切換至另一個選項。
給定一個狀態集為 S、動作集為 A 的 MDP,選項 ω ∈ ? ω ∈ ? ω∈?被定義為三元組 ( I ω , π ω , β ω ) (I_ω , π_ω , β_ω ) (Iω?,πω?,βω?),其中 I ω ? S I_ω ? S Iω??S 為一組初始狀態集, π ω : S × A → [ 0 , 1 ] π_ω : S × A → [0, 1] πω?:S×A→[0,1] 是一個選項內置策略,而 β ω : S → [ 0 , 1 ] β_ω : S → [0, 1] βω?:S→[0,1] 是一個通過伯努利分布提供隨機終止條件的終止函數。一個選項 ω ω ω只有在 s ∈ I ω s ∈ I_ω s∈Iω? 時,才能用于狀態 s。
一個選項框架由兩層結構組成:底層的每個元素是一個選項,而頂層則是一個選項策略,用來在片段開始或上個選項終結時候選擇一個選項。選項策略從環境給出的獎勵信息學習,而選項可通過明確的子目標來學習。
2.2 經典算法:Option-Critic Architecture
參考資料:
- 《2 分層強化學習】Option-Critic》 ,知乎
- B站視頻《Option-Critic框架學習記錄》
- 論文《The Option-Critic Architecture》
- 分層強化學習博客園,含案例,合集似乎很牛逼啊
選項-批判者結構(Option-Critic Architecture)(Bacon et al., 2017) 將策略梯度定理擴展至選項,它提供一種端到端的對選項和選項策略的聯合學習。它直接優化了折扣化回報。我們考慮 選項-價值函數(1),狀態-選項對 (s, ω) 后執行某個動作的價值(2), 進入一個狀態 s′ 時,執行 ω 的價值(3)
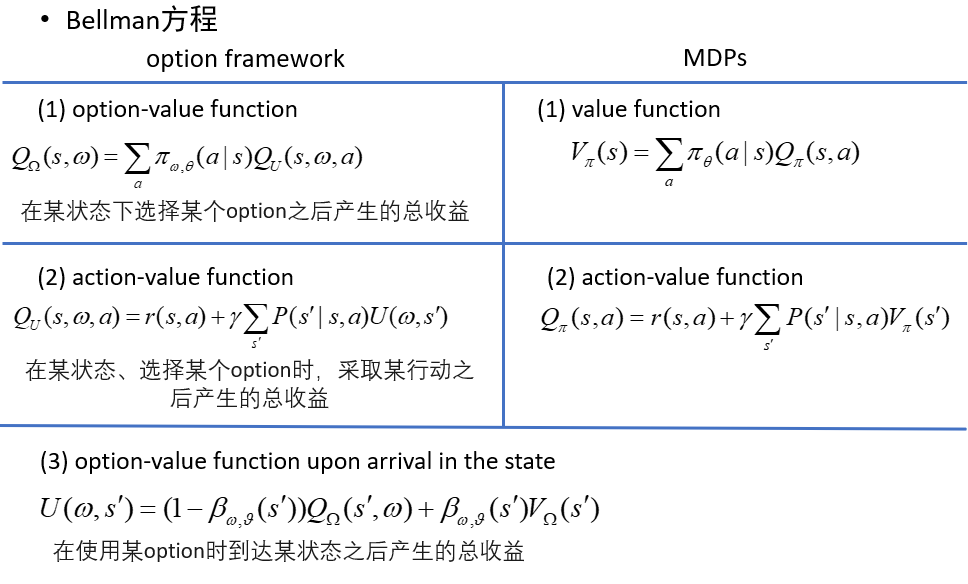

用于學習選項的隨機梯度下降算法的結構如圖 10.3 所示,其中梯度由定理 10.1 和定理 10.2給出,
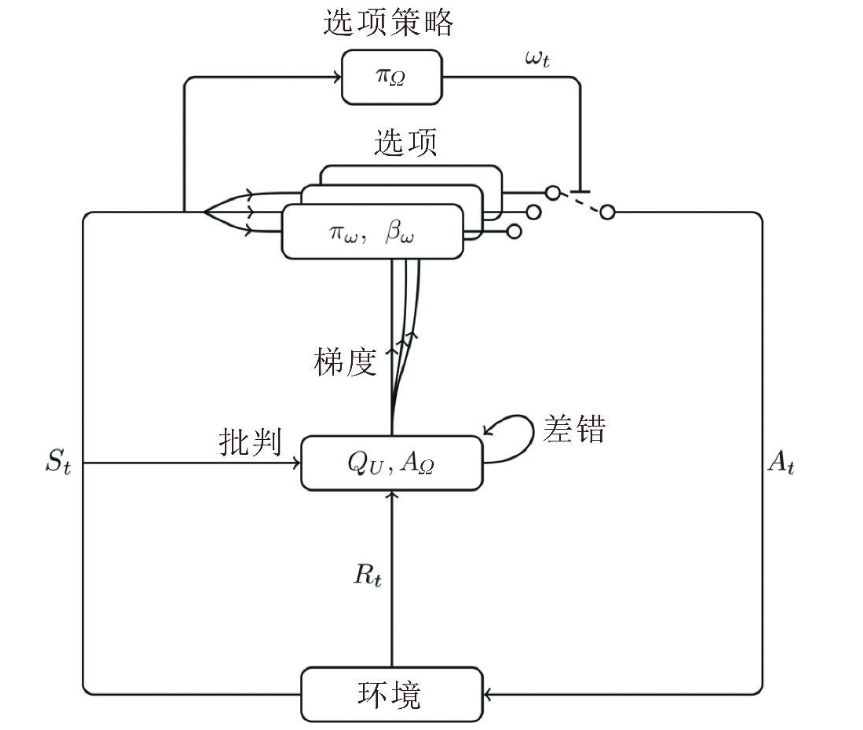
圖的解析:
- π Ω \pi_{\Omega} πΩ? 表示最頂層的策略,確定選擇哪個option
- π ω \pi_{\omega} πω? 內置函數, β ω \beta_{\omega} βω?終止函數(停止當前的option選項)
critic結構中的參數+上面3個參數都是需要學習的~- 在option-critic 結構中,對于 s t s_t st?由 π Ω \pi_{\Omega} πΩ?選定option,由critic對其評估。當選定一個option,由其輸出動作at. at與Environment交互,一方面返回即時獎勵rt和下一狀態 s t + 1 s_{t+1} st+1?
- critic通過gradients指導option內的( π ω \pi_{\omega} πω?和 β ω \beta_{\omega} βω?)的更新。

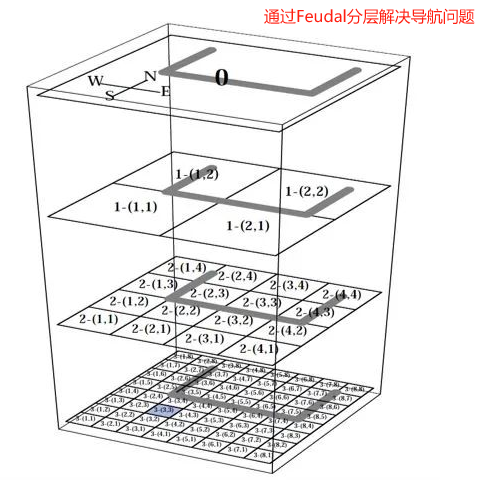
2.3 Feudal Reinforcement Learning(封建強化學習)
封建制網絡(Feudal Networks,FuNs)是一個完全可微模塊化的 FRL 神經網絡,它有兩個模塊:管理者和工作者。管理者在一個潛在狀態空間中更低的時間分辨率上設定目標,而工作者則學習如何通過內在獎勵達到目標.

- 結構:模仿封建等級制度,上層智能體(Manager)設定子目標,下層智能體(Worker)執行具體動作。特征是“獎賞隱藏”和“信息隱層”,即下層僅關注局部狀態.
2.4 MAXQ值函數分解
《Hierarchical Reinforcement Learning with the MAXQ Value Function Decomposition》

方法:將任務分解為子任務三元組(動作、終止狀態、專屬獎勵函數),通過遞歸分解實現層次化策略。例如,導航任務可分解為“避開障礙”和“尋找獎勵”子任務
2.5 HAM(分層抽象機)
HAM 全程 Hierarchical of abstraction machine
- 機制:通過狀態轉換機簡化MDP,分為行為狀態(執行動作)、調用狀態(啟動子任務)、選擇狀態(選擇子任務)和停止狀態
2.6 現代擴展方法
- HIRO:通過離線策略修正解決層次間非平穩性問題
- FuN(封建網絡) :自動發現子目標,結合LSTM處理長期依賴
HRL與gridworld實踐
三、GridWorld環境設計
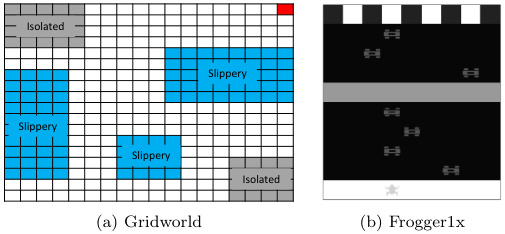
3.1 地圖生成規則
- 網格結構:采用10x10網格,水平和垂直墻壁隨機生成,保證地圖連通性(任意兩點存在可達路徑)
- 障礙物生成:使用泊松圓盤采樣算法生成非均勻分布的障礙物,確保障礙物之間最小間距為2格,避免死胡同
- 獎勵機制:設置3個獎勵點(+5、+3、+1),分布在障礙物稀疏區域,且不與起點重疊
- 動態要素:每局游戲隨機初始化起點位置,若智能體進入獎勵點后,該點獎勵重置為0,防止重復刷分
- 參考地圖,來源于文獻
3.2 狀態與動作空間
- 狀態表示:包含坐標(x,y)、周圍8格障礙物掩碼(0/1)、最近獎勵點方向向量( Δ x , Δ y \Delta x,\Delta y Δx,Δy)。
- 動作空間:基礎動作為{上,下,左,右},引入30%概率的動作噪聲(如執行"上"可能實際向左偏移)。
- 觀測限制:部分可觀測設定,智能體僅能感知周圍5x5區域內的狀態
四、分層強化學習(HRL)算法設計
4.1 分層架構設計
| 層級 | 輸入 | 輸出 | 更新頻率 | 算法選擇 |
|---|---|---|---|---|
| Manager | 全局地圖特征(Flatten后) | 子目標坐標 ( g x , g y ) (g_x,g_y) (gx?,gy?) | 每10步 | PPO (Actor-Critic) |
| Worker | 局部觀測+子目標相對坐標 | 基礎動作 | 每步 | DQN (Dueling Network) |
核心機制:
- 子目標修正:Manager通過 g t = c l i p ( g t ? 1 + Δ g , 0 , 9 ) g_t = clip(g_{t-1} + Δg, 0, 9) gt?=clip(gt?1?+Δg,0,9)動態調整子目標,避免突變。
- 內在獎勵:Worker獲得與子目標距離成反比的獎勵 ,加速子任務完成
- 動態層次:當Worker連續5次未完成子目標時,Manager強制生成新子目標,防止局部震蕩
4.2 獎勵函數分解
- 全局獎勵: R g l o b a l = ∑ r e x t ? 0.01 × t ( 到達獎勵點 + 時間懲罰 ) R_{global} =\sum r_{ext} -0.01 \times t(到達獎勵點+時間懲罰) Rglobal?=∑rext??0.01×t(到達獎勵點+時間懲罰)
- 分層獎勵:
R M a n a g e r = λ 1 R g l o b a l + λ 2 I g o a l r e a c h e d R_{Manager} =\lambda_1 R_{global}+\lambda_2 \mathbb{I}_{goal_reached} RManager?=λ1?Rglobal?+λ2?Igoalr?eached?
R W o r k e r = r i n t ? 0.1 × I c o l l i s i o n R_{Worker}=r_{int}-0.1 \times \mathbb{I}_{collision} RWorker?=rint??0.1×Icollision?
其中, λ 1 = 0.7 , λ 2 = 0.3 \lambda_1=0.7,\lambda_2=0.3 λ1?=0.7,λ2?=0.3為權重系數。





)


)

)
)



)



