LLaMA的模型架構與GPT相同,采用了Transformer中的因果解碼器結構,并在此基礎上進行了多項關鍵改進,以提升訓練穩定性和模型性能。LLaMA的核心架構如圖?3.14?所示,融合了后續提出的多種優化方法,這些方法也在其他模型(如?PaLM)中得到了應用。
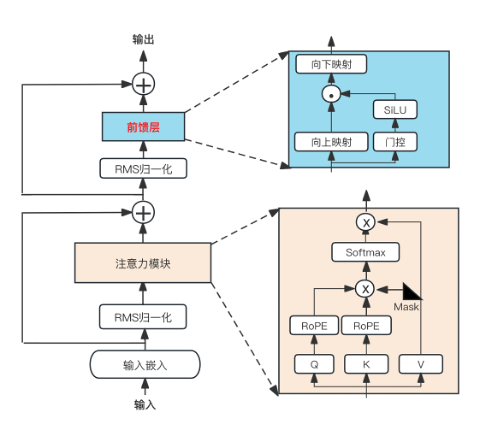
圖3.14 LLaMA的模型架構示意圖
模型有以下主要特點:
1.前置的歸一化層(Pre-Normalization):為增強訓練穩定性,LLaMA?采用前置歸一化策略,即在每個?Transformer?子層的輸入之前進行歸一化,而非傳統的后置歸一化。
2.SwiGLU激活函數和降維:在前饋層(FFN)中采用用SwiGLU激活函數,替代傳統的ReLU,提升了非線性表達能力和訓練穩定性。前饋層維度減少為2???4d,其表達式down(up(x))×SwiGLU(gate(x)),其中down、up、gate都是線性層。
3.旋轉式位置編碼(RoPE):在查詢(Q)和鍵(K)上應用旋轉式位置編碼,以增強模型對相對位置信息的感知能力。
前置歸一化層詳解
歸一化操作可以協調在特征空間上的分布,更好地進行梯度下降。在神經網絡中,特征經過線性組合后,還要經過激活函數,如果某個特征數量級過大,在經過激活函數時,就會提前進入它的飽和區間(例如sigmoid激活函數),即不管如何增大這個數值,它的激活函數值都在1附近,不會有太大變化,這樣激活函數就對這個特征不敏感。在神經網絡用SGD等算法進行優化時,不同量綱的數據會使網絡失衡,變得不穩定。
歸一化的方式主要包括以下幾種方法:批歸一化(BatchNorm)、層歸一化(LayerNorm)、實例歸一化(InstanceNorm)、組歸一化(GroupNorm)。歸一化的不同方法對比如圖3.15所示,圖中N表示批次,C表示通道,H,W表示空間特征。
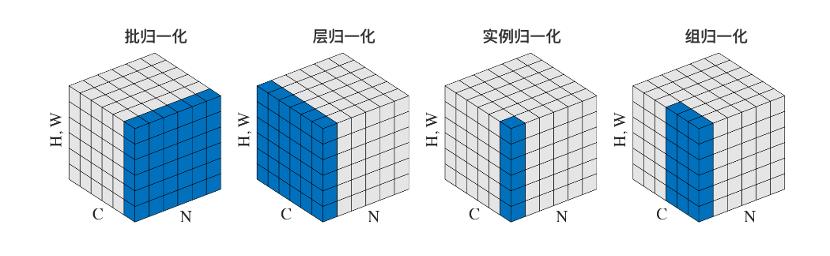
圖3.15 歸一化的不同方法對比
1.BatchNorm:在批次方向做歸一化,計算N×H×W的均值,BatchNorm的主要缺點是對批次的大小比較敏感,對小的批次大小效果不好;由于每次計算均值和方差是在一個批次上,所以如果批次太小,則計算的均值、方差不足以代表整個數據分布;同時,對于RNN來說,文本序列的長度是不一致的,即RNN的深度不是固定的,不同的時間步需要保存不同的統計特征,可能存在一個特殊序列比其他序列長很多的情況,這樣在訓練時計算很麻煩。
2.LayerNorm:在通道方向做歸一化,計算C×H×W的均值,LayerNorm中同層神經元輸入擁有相同的均值和方差,不同的輸入樣本有不同的均值和方差,所以,LayerNorm不依賴于批次的大小和輸入序列的深度,因此對于RNN的輸入序列進行歸一化操作很方便,而且作用明顯。
3.InstanceNorm:一個通道內做歸一化,計算H×W的均值,主要用在圖像的風格化遷移;因為在圖像風格化中,生成結果主要依賴于某個圖像實例,所以對整個批次歸一化不適合圖像風格化中,因而對H×W做歸一化,可以加速模型收斂,并且保持每個圖像實例之間的獨立。
4.GroupNorm:將通道方向分組,然后每個組內做歸一化,計算(C//G)HW的均值,G表示分組的數量;這樣與批次大小無關,不受其約束。當批次大小小于16時,可以使用這種歸一化。
5.SwitchableNorm:將BatchNorm、LayerNorm、InstanceNorm結合,賦予權重,讓網絡自己學習歸一化層應該使用什么方法。其使用可微分學習,為一個深度網絡中的每一個歸一化層確定合適的歸一化操作。
旋轉位置編碼詳解
旋轉位置編碼(RotaryPositionEmbedding,RoPE)是一種將相對位置信息融入自注意力機制的位置編碼方法,能夠提升Transformer架構的表達能力和外推性能。受GPTNeo的啟發,LLaMA放棄了傳統的絕對位置編碼,而采用旋轉位置編碼,這種方式已成為當前主流大模型中最常用的相對位置編碼方案之一。
ROPE的核心優勢在于提升模型外推能力——即在訓練與推理時輸入長度不一致的情況下仍具備良好的泛化性能。例如,若模型訓練時僅見過512個token的文本,傳統絕對位置編碼方法在推理超過該長度時可能性能驟降,而RoPE能自然延展到更長的輸入序列,適應長文本和多輪對話等任務。
旋轉位置編碼總結如下:
1.保持相對位置信息一致性:RoPE可以有效地保持位置信息的相對關系,即相鄰位置的編碼之間有一定的相似性,而遠離位置的編碼之間有一定的差異性。這樣可以增強模型對位置信息的感知和利用,而這正是其他絕對位置編碼方式(如正弦位置編碼、學習的位置編碼等)所不具備的。
2.具備強外推性:RoPE可以通過旋轉矩陣來生成超過預訓練長度的位置編碼,顯著提高模型的泛化能力和魯棒性。這是固定位置編碼方式(如正弦位置編碼、固定相對位置編碼等)難以實現的,因為它們只能表示預訓練長度內的位置,而不能表示超過預訓練長度的位置。
3.計算高效,兼容線性注意力:RoPE可以與線性注意力機制兼容,即不需要額外的計算或參數來實現相對位置編碼。RoPE?相較于Transformer-XL、XLNet等混合編碼方式,具有更低的計算與內存開銷。
RoPE?的實現流程簡述如下:對每個?token,先計算其查詢和鍵向量,再根據其位置信息生成對應的旋轉位置編碼。隨后將查詢和鍵的向量按照兩兩一組進行旋轉變換,最后通過內積計算自注意力分數。此外,RoPE?可從二維推廣至任意維度,進一步拓展其在復雜任務中的應用潛力。

全文引自《開啟智能對話新紀元:大規模語言模型的探索與實踐》

)



)













