機器學習+城市規劃第十四期:利用半參數地理加權回歸來實現區域帶寬不同的規劃任務
引言
在城市規劃中,如何根據不同地區的地理特征來制定有效的規劃方案是一個關鍵問題。不同區域的需求和規律是不同的,因此我們必須考慮到地理空間的差異性。本期博客將介紹如何結合機器學習方法,利用地理加權聚類(Geographically Weighted Clustering)和半參數地理加權回歸(Semi-Parametric Geographically Weighted Regression, SPGWR)來實現城市規劃中的區域帶寬不同的任務。
我們將通過代碼的形式一步步解構整個過程,結合真實的城市數據,幫助大家理解如何在規劃過程中處理區域帶寬差異問題,并最終實現個性化、優化的規劃方案。
地理加權聚類:為什么要加權?
1. 為什么要加權聚類?
傳統的聚類方法,如K-means等,通常會根據全局特征對數據進行聚類,而忽略了數據在地理空間上的異質性。而在城市規劃中,地理位置對于各類變量的影響至關重要。例如,一個城市的東部和西部,經濟發展水平、交通需求、環境污染等因素可能有顯著差異。因此,直接應用全局聚類算法可能無法準確地反映不同區域的實際需求。
地理加權聚類能夠更好地反映這些空間差異性。通過對每個數據點進行加權處理,我們可以根據每個點的實際因變量(如交通流量、空氣污染等)來調整聚類結果,使得相同簇中的數據點具有更強的相似性,并且不同簇之間的差異更加明顯。
2. 如何實現加權聚類?
我們使用了DBSCAN(密度基聚類算法),它能夠根據每個點的鄰域密度來進行聚類。在此基礎上,我們根據每個數據點的因變量進行加權復制,以反映不同地區的實際需求。接下來是代碼實現過程。
import pandas as pd
import numpy as np
from sklearn.cluster import DBSCAN
import matplotlib.pyplot as plt# ========== 中文字體設置 ==========
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# ========== 讀取數據 ==========
df = pd.read_csv('shuju bike.csv', header=None)
df.columns = ['latitude', 'longitude', 'dependent_var', 'independent_var']# 清洗數據
df['latitude'] = pd.to_numeric(df['latitude'], errors='coerce')
df['longitude'] = pd.to_numeric(df['longitude'], errors='coerce')
df['dependent_var'] = pd.to_numeric(df['dependent_var'], errors='coerce')
df['independent_var'] = pd.to_numeric(df['independent_var'], errors='coerce')
df.dropna(subset=['latitude', 'longitude', 'dependent_var', 'independent_var'], inplace=True)# ========== 權重復制(加權) ==========
df_weighted = df.loc[df.index.repeat(df['dependent_var'].astype(int))].reset_index(drop=True)# ========== 轉換為弧度坐標 ==========
coords = df_weighted[['latitude', 'longitude']].to_numpy()
coords_rad = np.radians(coords)# ========== 設置 DBSCAN 參數 ==========
kms_per_radian = 6371.0088
base_eps_km = 5 # 可調:基礎 eps,單位為 km
epsilon = base_eps_km / kms_per_radian# ========== 聚類 ==========
db = DBSCAN(eps=epsilon, min_samples=10, algorithm='ball_tree', metric='haversine')
cluster_labels = db.fit_predict(coords_rad)# ========== 聚類結果回填到原始 df ==========
df_weighted['cluster'] = cluster_labels# 按經緯度 + 因變量分組,避免數據重復
df_clustered = df_weighted.groupby(['latitude', 'longitude', 'dependent_var', 'independent_var'], as_index=False).agg({'cluster': 'first'})# ========== 合并回原始數據 ==========
df_result = pd.merge(df, df_clustered, on=['latitude', 'longitude', 'dependent_var', 'independent_var'], how='left')# ========== 保存 ==========
output_path = "加權聚類結果.csv"
df_result.to_csv(output_path, index=False, encoding='utf-8-sig')
print("? 加權聚類結果已保存至:", output_path)# ========== 可視化 ==========
plt.figure(figsize=(10, 6))
scatter = plt.scatter(df_result['longitude'],df_result['latitude'],c=df_result['cluster'],cmap='tab20',s=df_result['dependent_var'] * 10, # 用大小體現因變量的嚴重程度alpha=0.7
)
plt.xlabel('Longitude')
plt.ylabel('Latitude')
plt.title('地理加權 DBSCAN 聚類(考慮因變量)')
plt.colorbar(scatter, label='Cluster ID')
plt.grid(True)
plt.show()
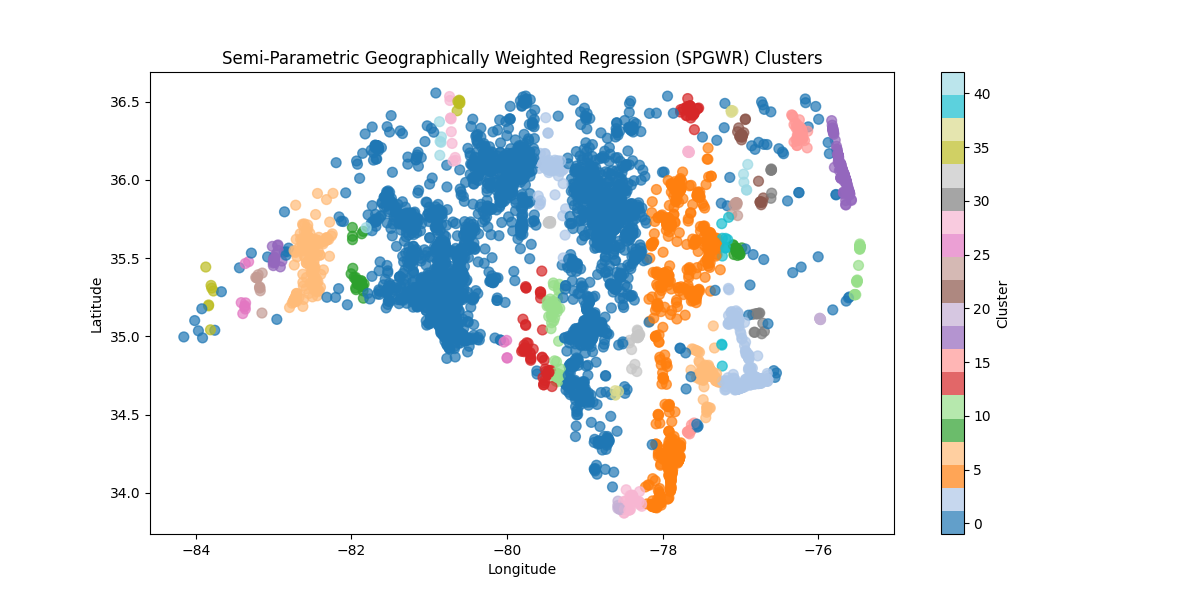
半參數地理加權回歸:引入帶寬的原因
1. 為什么引入半參數地理加權回歸?
在地理空間中,不同地區的數據特征之間可能存在顯著差異。例如,在城市的東部地區,溫度、濕度等環境變量可能與西部地區的關系完全不同。因此,采用全局回歸模型(例如普通最小二乘回歸)進行預測可能會忽略這些差異,導致不準確的結果。
半參數地理加權回歸(SPGWR)結合了傳統回歸和地理加權的優勢,通過在回歸中引入帶寬,使得每個區域內的數據點能夠根據其空間距離進行加權,從而有效捕捉區域差異。
2. 如何實現半參數地理加權回歸?
通過計算每個點與其周圍點的地理距離,并根據距離計算權重,我們能夠在每個簇內應用不同的回歸參數。這使得我們能夠根據不同區域的特征,制定個性化的規劃方案。
以下是半參數地理加權回歸的實現代碼:
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt
from scipy.spatial.distance import cdist
from sklearn.linear_model import LinearRegression
import geopandas as gpd
from shapely.geometry import Point# 讀取加權聚類數據
df = pd.read_csv('加權聚類結果.csv') # 假設加權聚類結果文件路徑# 處理數據:取出經緯度、因變量和自變量
df['latitude'] = pd.to_numeric(df['latitude'], errors='coerce')
df['longitude'] = pd.to_numeric(df['longitude'], errors='coerce')
df['dependent_var'] = pd.to_numeric(df['dependent_var'], errors='coerce')
df['independent_var'] = pd.to_numeric(df['independent_var'], errors='coerce')
df.dropna(subset=['latitude', 'longitude', 'dependent_var', 'independent_var'], inplace=True)# 標準化數據
scaler = StandardScaler()
df['dependent_var_scaled'] = scaler.fit_transform(df[['dependent_var']])
df['independent_var_scaled'] = scaler.fit_transform(df[['independent_var']])# Haversine距離函數
def haversine(lat1, lon1, lat2, lon2):R = 6371 # 地球半徑(公里)phi1, phi2 = np.radians(lat1), np.radians(lat2)delta_phi = np.radians(lat2 - lat1)delta_lambda = np.radians(lon2 - lon1)a = np.sin(delta_phi / 2) ** 2 + np.cos(phi1) * np.cos(phi2) * np.sin(delta_lambda / 2) ** 2c = 2 * np.arctan2(np.sqrt(a), np.sqrt(1 - a))return R * c# 計算地理坐標之間的距離矩陣
def compute_distance_matrix(coords):return cdist(coords, coords, metric='euclidean') # 使用歐幾里得距離計算地理距離# 半參數化地理加權回歸
def spgwr(coords, X, y, bandwidth):dist_matrix = compute_distance_matrix(coords)weights = np.exp(-dist_matrix ** 2 / (2 * bandwidth ** 2)) # 高斯權重weights = np.diagonal(weights) # 只選擇對角線元素model = LinearRegression()model.fit(X, y, sample_weight=weights)y_pred = model.predict(X)residuals = y - y_predRSS = np.sum(residuals ** 2)n = len(y)k = len(model.coef_)log_likelihood = -0.5 * np.sum(np.log(np.maximum(np.abs(residuals), 1e-10)) ** 2)AIC = 2 * k - 2 * log_likelihoodBIC = np.log(n) * k - 2 * log_likelihoodR2 = model.score(X, y)adj_R2 = 1 - (1 - R2) * (n - 1) / (n - k - 1)return {'RSS': RSS,'AIC': AIC,'BIC': BIC,'R2': R2,'Adj_R2': adj_R2,'params': model.coef_,'intercept': model.intercept_,'residuals': residuals}, model# 選擇帶寬(示例為平均距離)
clusters = df['cluster'].unique()
results = []for cluster in clusters:cluster_data = df[df['cluster'] == cluster]coords = cluster_data[['latitude', 'longitude']].to_numpy()X = cluster_data[['independent_var_scaled']].to_numpy()y = cluster_data['dependent_var_scaled'].to_numpy()dist_matrix = compute_distance_matrix(coords)bandwidth = np.mean(dist_matrix)model_results, model = spgwr(coords, X, y, bandwidth)df.loc[df['cluster'] == cluster, 'MGWR_coef_Temperature'] = model_results['params'][0]df.loc[df['cluster'] == cluster, 'MGWR_residuals'] = model_results['residuals']cluster_results = {'cluster': cluster,'bandwidth': bandwidth,'RSS': model_results['RSS'],'AIC': model_results['AIC'],'BIC': model_results['BIC'],'R2': model_results['R2'],'Adj_R2': model_results['Adj_R2'],'params': model_results['params'],'intercept': model_results['intercept'],'mse': mean_squared_error(y, model.predict(X))}results.append(cluster_results)# 輸出結果
results_df = pd.DataFrame([{'Cluster': result['cluster'],'Bandwidth': result['bandwidth'],'RSS': result['RSS'],'AIC': result['AIC'],'BIC': result['BIC'],'R2': result['R2'],'Adj_R2': result['Adj_R2'],'MSE': result['mse']
} for result in results])# 創建 GeoDataFrame
geometry = [Point(xy[1], xy[0]) for xy in zip(df['longitude'], df['latitude'])]
geo_df = gpd.GeoDataFrame(df, geometry=geometry, crs="EPSG:4326")# 可視化聚類結果
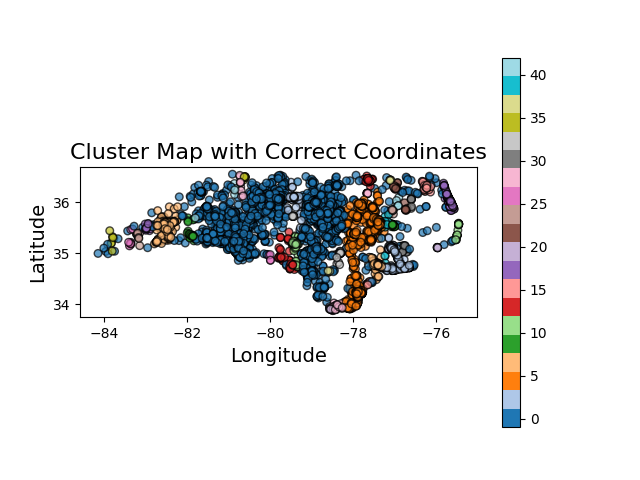
plt.figure(figsize=(12, 6))
geo_df.plot(column='cluster', cmap='tab20', legend=True, markersize=30, alpha=0.7, edgecolor='k')
plt.title('Cluster Map with Correct Coordinates', fontsize=16)
plt.xlabel('Longitude', fontsize=14)
plt.ylabel('Latitude', fontsize=14)
plt.show()# 保存為 GeoJSON 文件
output_geojson_path = 'spgwr_clusters_corrected.geojson'
geo_df.to_file(output_geojson_path, driver='GeoJSON')print(f"GeoJSON 文件已保存:{output_geojson_path}")
print(results_df)
總結
通過使用地理加權聚類和半參數地理加權回歸,我們可以有效地考慮到地理空間上的差異性。在城市規劃中,這意味著我們可以為不同區域制定更為精準的規劃方案,充分利用地理特征來優化資源分配和決策支持。通過這種方法,我們實現了具有不同區域帶寬的個性化規劃任務,讓城市規劃更加科學和合理。
希望大家通過本篇博客,能夠深入理解并掌握這些技術,運用在實際的城市規劃任務中,提升規劃的精準度與效果!
原創聲明:本教程由課題組內部教學使用,利用CSDN平臺記錄,不進行任何商業盈利。














)
 市場份額分析報告)



