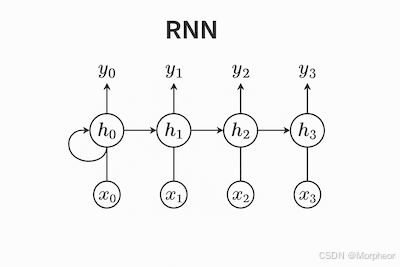
循環神經網絡(RNN)是一種專為處理序列數據設計的神經網絡,如時間序列、自然語言或語音。與傳統的全連接神經網絡不同,RNN具有"記憶"功能,通過循環傳遞信息,使其特別適合需要考慮上下文或順序的任務。它出現在Transformer之前,廣泛應用于文本生成、語音識別和時間序列預測(如股價預測)等領域。
RNN的數學基礎
核心方程
在每個時間步 t t t,RNN執行以下操作:
-
隱藏狀態更新:
h t = tanh ( W h h h t ? 1 + W x h x t + b h ) h_t = \text{tanh}(W_{hh}h_{t-1} + W_{xh}x_t + b_h) ht?=tanh(Whh?ht?1?+Wxh?xt?+bh?)- h t h_t ht?: 時間 t t t的新隱藏狀態(形狀:
[hidden_size]) - h t ? 1 h_{t-1} ht?1?: 前一個隱藏狀態(形狀:
[hidden_size]) - x t x_t xt?: 時間 t t t的輸入(形狀:
[input_size]) - W h h W_{hh} Whh?: 隱藏到隱藏的權重矩陣(形狀:
[hidden_size, hidden_size]) - W x h W_{xh} Wxh?: 輸入到隱藏的權重矩陣(形狀:
[hidden_size, input_size]) - b h b_h bh?: 隱藏層偏置項(形狀:
[hidden_size]) - tanh \text{tanh} tanh: 雙曲正切激活函數
- h t h_t ht?: 時間 t t t的新隱藏狀態(形狀:
-
輸出計算:
o t = W h y h t + b y o_t = W_{hy}h_t + b_y ot?=Why?ht?+by?- o t o_t ot?: 時間 t t t的輸出(形狀:
[output_size]) - W h y W_{hy} Why?: 隱藏到輸出的權重矩陣(形狀:
[output_size, hidden_size]) - b y b_y by?: 輸出偏置項(形狀:
[output_size])
- o t o_t ot?: 時間 t t t的輸出(形狀:
隨時間反向傳播(BPTT)
RNN使用BPTT進行訓練,它通過時間展開網絡并應用鏈式法則:
? L ? W = ∑ t = 1 T ? L t ? o t ? o t ? h t ∑ k = 1 t ( ∏ i = k + 1 t ? h i ? h i ? 1 ) ? h k ? W \frac{\partial L}{\partial W} = \sum_{t=1}^T \frac{\partial L_t}{\partial o_t} \frac{\partial o_t}{\partial h_t} \sum_{k=1}^t \left( \prod_{i=k+1}^t \frac{\partial h_i}{\partial h_{i-1}} \right) \frac{\partial h_k}{\partial W} ?W?L?=t=1∑T??ot??Lt???ht??ot??k=1∑t?(i=k+1∏t??hi?1??hi??)?W?hk??
這可能導致梯度消失/爆炸問題,LSTM和GRU架構可以解決這個問題。
GRU:門控循環單元
在深入翻譯示例之前,讓我們先了解GRU的數學基礎。GRU通過門控機制解決了標準RNN中的梯度消失問題。
GRU方程
在每個時間步 t t t,GRU計算以下內容:
-
更新門 ( z t z_t zt?):
z t = σ ( W z ? [ h t ? 1 , x t ] + b z ) z_t = \sigma(W_z \cdot [h_{t-1}, x_t] + b_z) zt?=σ(Wz??[ht?1?,xt?]+bz?)- z t z_t zt?: 更新門(形狀:
[hidden_size]) - W z W_z Wz?: 更新門的權重矩陣(形狀:
[hidden_size, hidden_size + input_size]) - b z b_z bz?: 更新門的偏置項(形狀:
[hidden_size]) - h t ? 1 h_{t-1} ht?1?: 前一個隱藏狀態
- x t x_t xt?: 當前輸入
- σ \sigma σ: Sigmoid激活函數(將值壓縮到0和1之間)
更新門決定保留多少之前的隱藏狀態。
- z t z_t zt?: 更新門(形狀:
-
重置門 ( r t r_t rt?):
r t = σ ( W r ? [ h t ? 1 , x t ] + b r ) r_t = \sigma(W_r \cdot [h_{t-1}, x_t] + b_r) rt?=σ(Wr??[ht?1?,xt?]+br?)- r t r_t rt?: 重置門(形狀:
[hidden_size]) - W r W_r Wr?: 重置門的權重矩陣(形狀:
[hidden_size, hidden_size + input_size]) - b r b_r br?: 重置門的偏置項(形狀:
[hidden_size])
重置門決定忘記多少之前的隱藏狀態。
- r t r_t rt?: 重置門(形狀:
-
候選隱藏狀態 ( h ~ t \tilde{h}_t h~t?):
h ~ t = tanh ( W ? [ r t ⊙ h t ? 1 , x t ] + b ) \tilde{h}_t = \text{tanh}(W \cdot [r_t \odot h_{t-1}, x_t] + b) h~t?=tanh(W?[rt?⊙ht?1?,xt?]+b)- h ~ t \tilde{h}_t h~t?: 候選隱藏狀態(形狀:
[hidden_size]) - W W W: 候選狀態的權重矩陣(形狀:
[hidden_size, hidden_size + input_size]) - b b b: 偏置項(形狀:
[hidden_size]) - ⊙ \odot ⊙: 逐元素乘法(哈達瑪積)
這表示可能使用的新隱藏狀態內容。
- h ~ t \tilde{h}_t h~t?: 候選隱藏狀態(形狀:
-
最終隱藏狀態 ( h t h_t ht?):
h t = ( 1 ? z t ) ⊙ h t ? 1 + z t ⊙ h ~ t h_t = (1 - z_t) \odot h_{t-1} + z_t \odot \tilde{h}_t ht?=(1?zt?)⊙ht?1?+zt?⊙h~t?- 最終隱藏狀態是前一個隱藏狀態和候選狀態的組合
- z t z_t zt?作為新舊信息之間的插值因子
GRU在翻譯中的優勢
-
更新門
- 在英中翻譯中,這有助于決定:
- 保留多少上下文(例如,保持句子的主語)
- 更新多少新信息(例如,遇到新詞時)
- 在英中翻譯中,這有助于決定:
-
重置門
- 幫助忘記不相關的信息
- 例如,在翻譯新句子時,可以重置前一個句子的上下文
-
梯度流動
- 最終隱藏狀態計算中的加法更新( + + +)有助于保持梯度流動
- 這對于學習翻譯任務中的長程依賴關系至關重要
簡單的RNN示例
這個簡化示例訓練一個RNN來預測單詞"hello"中的下一個字符。
-
模型定義:
nn.RNN處理循環計算- 全連接層(
fc)將隱藏狀態映射到輸出(字符預測)
-
數據:
- 使用"hell"作為輸入,期望輸出為"ello"(序列移位)
- 字符轉換為one-hot向量(例如,‘h’ → [1, 0, 0, 0])
-
訓練:
- 通過最小化預測字符和目標字符之間的交叉熵損失來學習
-
預測:
- 訓練后,模型可以預測下一個字符
import torch
import torch.nn as nnclass SimpleRNN(nn.Module):def __init__(self, input_size, hidden_size, output_size):super(SimpleRNN, self).__init__()self.hidden_size = hidden_sizeself.rnn = nn.RNN(input_size, hidden_size, batch_first=True)self.fc = nn.Linear(hidden_size, output_size)def forward(self, x, hidden):out, hidden = self.rnn(x, hidden)out = self.fc(out)return out, hiddendef init_hidden(self, batch_size):return torch.zeros(1, batch_size, self.hidden_size)# 超參數
input_size = 4 # 唯一字符數 (h, e, l, o)
hidden_size = 8 # 隱藏狀態大小
output_size = 4 # 與input_size相同
learning_rate = 0.01# 字符詞匯表
chars = ['h', 'e', 'l', 'o']
char_to_idx = {ch: i for i, ch in enumerate(chars)}
idx_to_char = {i: ch for i, ch in enumerate(chars)}# 輸入數據:"hell" 預測 "ello"
input_seq = "hell"
target_seq = "ello"# 轉換為one-hot編碼
def to_one_hot(seq):tensor = torch.zeros(1, len(seq), input_size) # [batch_size, seq_len, input_size]for t, char in enumerate(seq):tensor[0][t][char_to_idx[char]] = 1 # 批大小為1return tensor# 準備輸入和目標張量
input_tensor = to_one_hot(input_seq) # 形狀: [1, 4, 4]
print("輸入張量形狀:", input_tensor.shape)
target_tensor = torch.tensor([char_to_idx[ch] for ch in target_seq], dtype=torch.long) # 形狀: [4]# 初始化模型、損失函數和優化器
model = SimpleRNN(input_size, hidden_size, output_size)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)# 訓練循環
for epoch in range(100):hidden = model.init_hidden(1) # 批大小為1print("隱藏狀態形狀:", hidden.shape) # 應該是 [1, 1, 8]optimizer.zero_grad()output, hidden = model(input_tensor, hidden) # 輸出: [1, 4, 4], 隱藏: [1, 1, 8]loss = criterion(output.squeeze(0), target_tensor) # output.squeeze(0): [4, 4], target: [4]loss.backward()optimizer.step()if epoch % 20 == 0:print(f'輪次 {epoch}, 損失: {loss.item():.4f}')# 測試模型
with torch.no_grad():hidden = model.init_hidden(1)
英中翻譯示例
我們將使用PyTorch的GRU(門控循環單元)構建一個簡單的英中翻譯模型,GRU是RNN的一種變體,能更好地處理長程依賴關系。
1. 數據準備
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np# 樣本平行語料(英文 -> 中文)
english_sentences = ["hello", "how are you", "i love machine learning","good morning", "artificial intelligence"
]chinese_sentences = ["你好", "你好嗎", "我愛機器學習","早上好", "人工智能"
]# 創建詞匯表
eng_chars = sorted(list(set(' '.join(english_sentences))))
zh_chars = sorted(list(set(''.join(chinese_sentences))))# 添加特殊標記
SOS_token = 0 # 句子開始
EOS_token = 1 # 句子結束
eng_chars = ['<SOS>', '<EOS>', '<PAD>'] + eng_chars
zh_chars = ['<SOS>', '<EOS>', '<PAD>'] + zh_chars# 創建詞到索引的映射
eng_to_idx = {ch: i for i, ch in enumerate(eng_chars)}
zh_to_idx = {ch: i for i, ch in enumerate(zh_chars)}# 將句子轉換為張量
def sentence_to_tensor(sentence, vocab, is_target=False):indices = [vocab[ch] for ch in (sentence if not is_target else sentence)]if is_target:indices.append(EOS_token) # 為目標添加EOS標記return torch.tensor(indices, dtype=torch.long).view(-1, 1)
2. 模型架構
class Seq2Seq(nn.Module):def __init__(self, input_size, hidden_size, output_size):super(Seq2Seq, self).__init__()self.hidden_size = hidden_size# 編碼器(英文到隱藏狀態)self.embedding = nn.Embedding(input_size, hidden_size)self.gru = nn.GRU(hidden_size, hidden_size)# 解碼器(隱藏狀態到中文)self.out = nn.Linear(hidden_size, output_size)self.softmax = nn.LogSoftmax(dim=1)def forward(self, input_seq, hidden=None, max_length=10):# 編碼器embedded = self.embedding(input_seq).view(1, 1, -1)output, hidden = self.gru(embedded, hidden)# 解碼器decoder_input = torch.tensor([[SOS_token]], device=input_seq.device)decoder_hidden = hiddendecoded_words = []for _ in range(max_length):output, decoder_hidden = self.gru(self.embedding(decoder_input).view(1, 1, -1),decoder_hidden)output = self.softmax(self.out(output[0]))topv, topi = output.topk(1)if topi.item() == EOS_token:breakdecoded_words.append(zh_chars[topi.item()])decoder_input = topi.detach()return ''.join(decoded_words), decoder_hiddendef init_hidden(self):return torch.zeros(1, 1, self.hidden_size)
3. 訓練模型
# 超參數
hidden_size = 256
learning_rate = 0.01
n_epochs = 1000# 初始化模型
model = Seq2Seq(len(eng_chars), hidden_size, len(zh_chars))
criterion = nn.NLLLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate)# 訓練循環
for epoch in range(n_epochs):total_loss = 0for eng_sent, zh_sent in zip(english_sentences, chinese_sentences):# 準備數據input_tensor = sentence_to_tensor(eng_sent, eng_to_idx)target_tensor = sentence_to_tensor(zh_sent, zh_to_idx, is_target=True)# 前向傳播model.zero_grad()hidden = model.init_hidden()# 編碼器前向傳播embedded = model.embedding(input_tensor).view(len(input_tensor), 1, -1)_, hidden = model.gru(embedded, hidden)# 準備解碼器decoder_input = torch.tensor([[SOS_token]])decoder_hidden = hiddenloss = 0# 教師強制:使用目標作為下一個輸入for di in range(len(target_tensor)):output, decoder_hidden = model.gru(model.embedding(decoder_input).view(1, 1, -1),decoder_hidden)output = model.out(output[0])loss += criterion(output, target_tensor[di])decoder_input = target_tensor[di]# 反向傳播和優化loss.backward()optimizer.step()total_loss += loss.item() / len(target_tensor)# 打印進度if (epoch + 1) % 100 == 0:print(f'輪次 {epoch + 1}, 平均損失: {total_loss / len(english_sentences):.4f}')# 測試翻譯
def translate(sentence):with torch.no_grad():input_tensor = sentence_to_tensor(sentence.lower(), eng_to_idx)output_words, _ = model(input_tensor)return output_words# 示例翻譯
print("\n翻譯結果:")
print(f"'hello' -> '{translate('hello')}'")
print(f"'how are you' -> '{translate('how are you')}'")
print(f"'i love machine learning' -> '{translate('i love machine learning')}'")
4. 理解輸出
訓練后,模型應該能夠將簡單的英文短語翻譯成中文。例如:
-
輸入: “hello”
- 輸出: “你好”
-
輸入: “how are you”
- 輸出: “你好嗎”
-
輸入: “i love machine learning”
- 輸出: “我愛機器學習”
5. 關鍵組件解釋
-
嵌入層:
- 將離散的詞索引轉換為連續向量
- 捕捉詞與詞之間的語義關系
-
GRU(門控循環單元):
- 使用更新門和重置門控制信息流
- 解決標準RNN中的梯度消失問題
-
教師強制:
- 在訓練過程中使用目標輸出作為下一個輸入
- 幫助模型更快地學習正確的翻譯
-
束搜索:
- 可以用于提高翻譯質量
- 在解碼過程中跟蹤多個可能的翻譯
6. 挑戰與改進
-
處理變長序列:
- 使用填充和掩碼
- 實現注意力機制以獲得更好的對齊
-
詞匯表大小:
- 使用子詞單元(如Byte Pair Encoding, WordPiece)
- 實現指針生成網絡處理稀有詞
-
性能:
- 使用雙向RNN增強上下文理解
- 實現Transformer架構以實現并行處理
這個示例為使用RNN進行序列到序列學習提供了基礎。對于生產系統,建議使用基于Transformer的模型(如BART或T5),這些模型在機器翻譯任務中表現出色。
,用來清理git的master分支)


















