Qwen團隊新發現:大模型推理能力的提高僅由少數高熵 Token 貢獻
不要讓低概率token主導了LLM的強化學習過程
一 低概率詞元問題
論文:Do Not Let Low-Probability Tokens Over-Dominate in RL for LLMs
在RL訓練過程中,低概率詞元(low-probability tokens)因其巨大的梯度幅值,在模型更新中產生了不成比例的主導效應。這種“梯度主導”現象會嚴重抑制對模型性能至關重要的高概率詞元的有效學習,從而阻礙了模型能力的進一步提升。
本文首先從理論上溯源了這一現象,揭示了其內在機理:對于一個典型的LLM,任何詞元在網絡中間層產生的梯度范數,其大小與( 1-兀)成正比,其中兀是該詞元的生成概率。這一關系清晰地表明,詞元概率越低,其梯度貢獻越大,反之則越小。
基于這一核心洞察,提出了兩種旨在恢復梯度平衡、簡單而高效的方法,以緩解低概率詞元的過度主導:
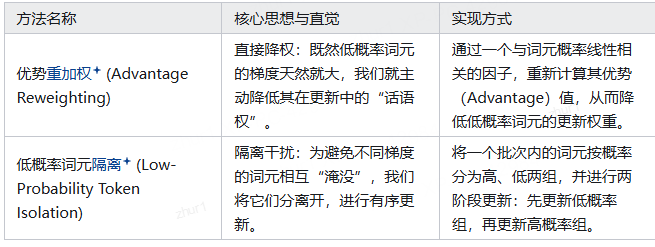
二 高熵token
論文:Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning
token 熵” 并不是針對于某個特定 token,而是在特定位置 t,對解碼不確定性的度量
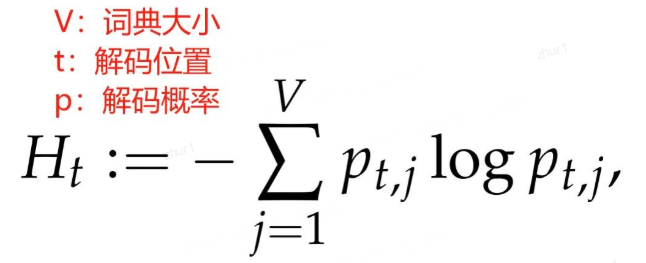
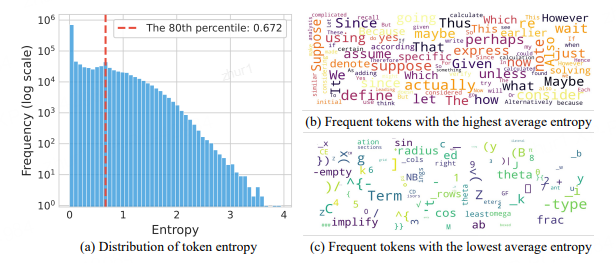
作者發現,生成推理鏈時每個位置的 token 熵值極度不均衡:只有少數 token 以高熵生成,而大多數 token 以低熵輸出。具體地,80% 的token 熵低于0.67
熵最高的 token 通常用于連接兩個連續推理部分之間的邏輯關系,比如wait、however 和 unless 等(對比或轉折),thus 和 also(遞進或補充),since 和 because (因果關系);在數學推導中,suppose、assume、given 和 define 等 token 頻繁出現,用于引入假設、已知條件或定義
熵最低的 token 則傾向于完成當前句子部分或結束單詞的構建,均表現出高度的確定性
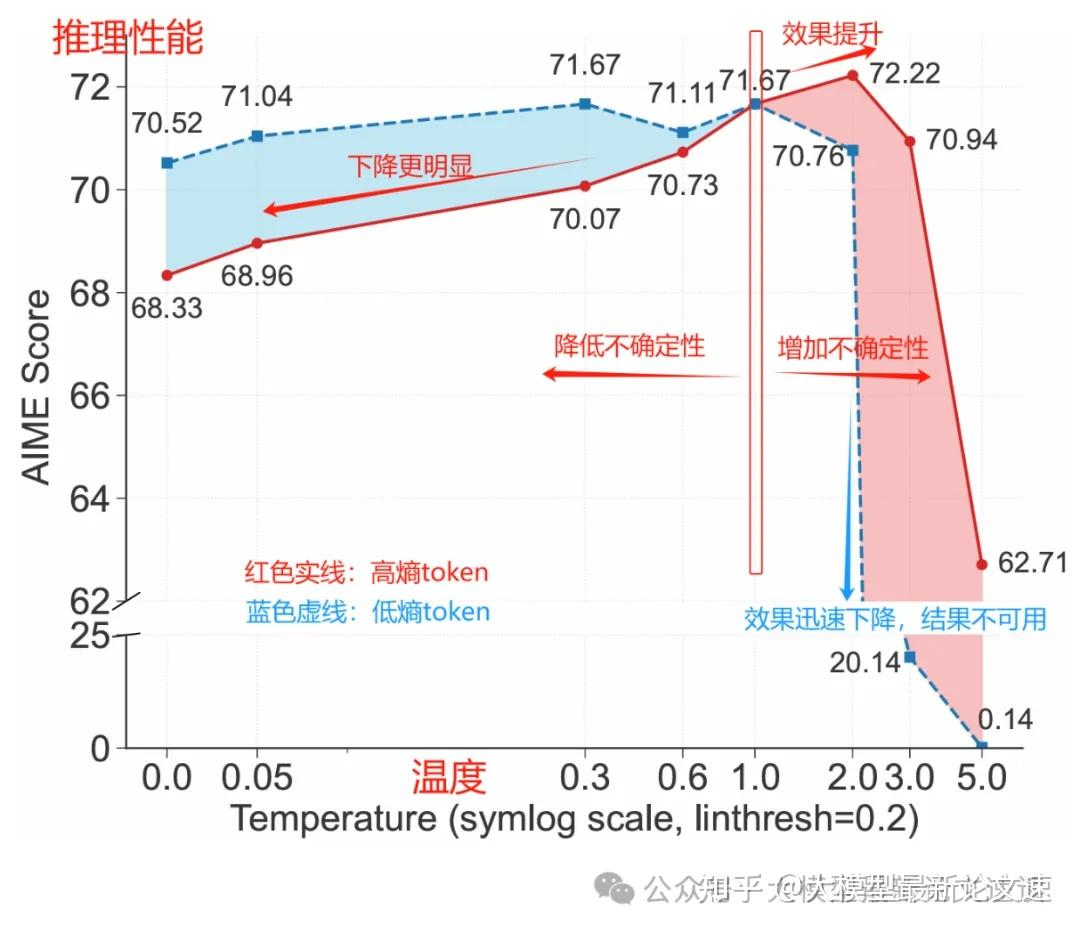
為了驗證高熵 token 對推理性能的關鍵作用,作者通過控制解碼溫度來調整這些 token 在生成過程中的隨機性。
結果表明,適當提高高熵 token 的熵值可以提高推理正確率;反之,強行降低其熵值則會顯著損害性能。這充分證明了在關鍵分叉 token 處保持較高的不確定性和探索度,對提高推理質量大有裨益。可見,少數高熵 token 確實是推理過程中應重點關注的“要害”
作者設計了這樣的實驗:利用 DAPO 算法訓練 Qwen3-14B 模型,保存不同訓練階段下的 checkpoint,分別在各種數學推理基準上進行采樣,識別各中間模型的高熵 token,然后分別計算這些它們與原始模型、訓練完畢后的模型對應的高熵 token 重疊率,結果如下
可見在 RL 訓練過程中,盡管與基礎模型的重疊逐漸減少,但在收斂時(第 1360 步),基礎模型的重疊率仍保持在 86% 以上,這表明 RL 訓練在很大程度上保留了基礎模型的高熵 token

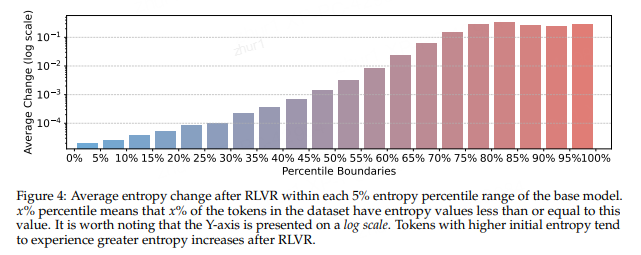
那么具體的熵值又是如何變化呢?下圖是作者的統計結果,可見基礎模型中初始熵較高的 token 在 RL 后往往表現出更大的熵增,這與三中的實驗結論不謀而合,表明 RL 帶來推理性能提升的原因之一,很可能就是因為高熵 token 的不確定性更強了,提高了大模型推理的靈活性


)





![樹莓派4B, ubuntu20.04, 安裝Ros Noetic[踩坑記錄]](http://pic.xiahunao.cn/樹莓派4B, ubuntu20.04, 安裝Ros Noetic[踩坑記錄])






![[密碼學實戰]C語言使用SDF庫構建國密算法RESTful服務(五)](http://pic.xiahunao.cn/[密碼學實戰]C語言使用SDF庫構建國密算法RESTful服務(五))

![push [特殊字符] present](http://pic.xiahunao.cn/push [特殊字符] present)

)