聯邦學習中常見的模型聚合操作,具體用于對來自多個客戶端的模型更新進行聚合,以得到全局模型。在聯邦學習框架下,多個客戶端在本地訓練各自的模型后,會將模型更新(通常是模型的權重)發送到中央服務器,中央服務器需要對這些本地更新進行合并,生成一個新的全局模型。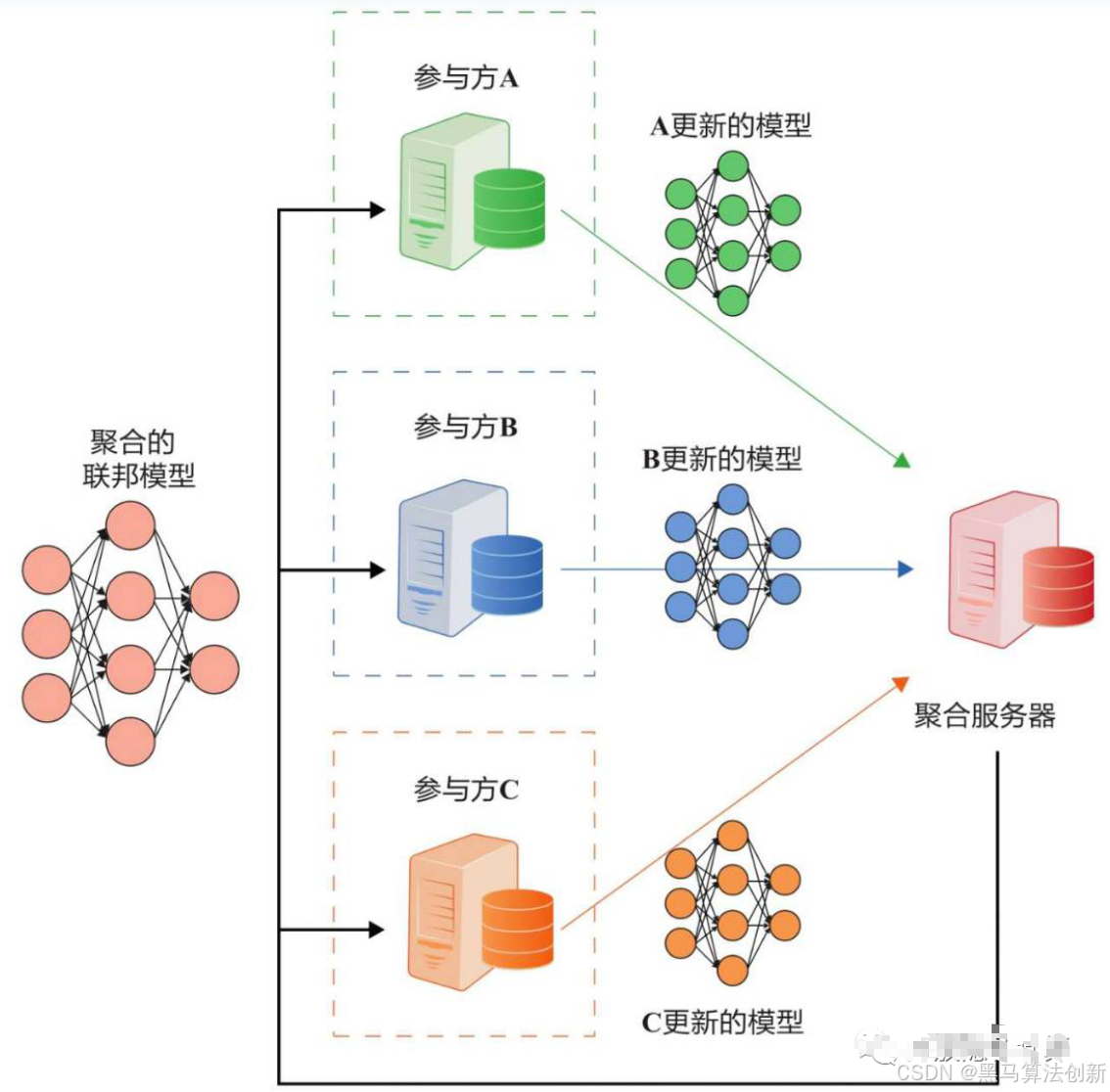
1.?初始化方法?__init__:
- 該方法接受一個參數?
n_classes,通常表示分類任務中的類別數目。初始化時將其存儲為類的一個成員變量,供后續使用。該參數的具體用途在代碼中未直接體現,但通常它與分類任務中的類別數量有關,可能用于處理某些特定的聚合操作(例如在處理分類層時可能涉及不同類別的權重更新)。
2.?agg_my?方法:
這個方法的作用是進行模型的聚合,即將多個客戶端的本地模型更新合并成一個全局模型。其輸入參數有:
w_local_models:包含所有客戶端本地模型更新的字典。global_model:當前全局模型的權重。width_list:該列表的作用是為每個客戶端指定一個權重,用于在聚合時加權不同客戶端的更新。
聚合過程的核心步驟如下:
3.?遍歷全局模型的各個參數:
在聯邦學習中,模型通常由多個層組成,每一層都有若干個參數(例如卷積層的權重或全連接層的權重)。keys = list(w_cur.keys()) 提取全局模型 w_cur 的所有層的名稱(即參數的鍵)。接下來,通過遍歷這些鍵來處理每一層的聚合。
4.?初始化聚合結果的臨時變量:
對于每一層的權重,首先初始化兩個張量 tmp 和 count,它們的形狀與當前全局模型中的權重相同。tmp 用于存儲該層的加權聚合結果,而 count 用于記錄每個客戶端對該層權重的貢獻次數。
5.?遍歷本地模型的更新:
接下來,對每個客戶端(w_local_models)進行遍歷,并進行以下操作:
- 獲取客戶端的權重寬度:
width = width_list[int(cur_clnt)]?表示為每個客戶端指定一個寬度,這可能與數據量或客戶端的權重有關。這個寬度將在后續的聚合過程中作為加權因素。 - 根據權重形狀選擇聚合策略:模型的不同層可能具有不同的形狀(如卷積層的權重是四維的,線性層是二維的等),因此在聚合時會根據權重的形狀選擇不同的聚合方法:
- 對于形狀為四維的權重(通常是卷積層的權重),調用?
agg_my_func_4?進行聚合。 - 對于形狀為二維的權重(通常是全連接層的權重),調用?
agg_my_func_2?進行聚合。 - 對于形狀為一維的權重,調用?
agg_my_func_1?進行聚合。 - 對于其他類型的權重,則直接使用本地客戶端的權重值。
- 對于形狀為四維的權重(通常是卷積層的權重),調用?
6.?加權聚合:
對于每個客戶端的權重更新,聚合時會使用該客戶端的“寬度”(width)來加權。如果某個客戶端的權重中沒有該層的參數(如某些特定的層在某些客戶端上沒有被更新),則會用零填充以避免影響聚合結果。
7.?處理客戶端數據缺失:
- 對于某些權重,在某些客戶端中可能沒有相應的更新(例如某個客戶端在某些層上的訓練不充分或者沒有更新該層的參數)。此時,該層的權重更新將用零填充。
count[count == 0] = 1?這一行的目的是防止在某些客戶端沒有貢獻時,出現除以零的情況。在聚合過程中,如果某個權重的更新次數為零,則將其計數置為1,避免在后續計算時出現除零錯誤。
8.?最終權重更新:
每一層的權重更新結果是通過累積所有客戶端的更新結果(即 tmp)并將其除以對應的計數(count)來實現的。這實際上是對每一層權重的加權平均,即全局模型的權重是由所有客戶端的加權貢獻形成的。
9.?返回新的全局模型:
最終,w_cur[k] = w_cur[k] / count 對全局模型的每一層進行更新,得到加權平均后的結果,最終返回更新后的全局模型。
:進階面試題與實戰演練)













)




