概述
在歷經半個月的間歇性開發后,RagflowPlus再次迎來一輪升級,正式發布v0.4.0。
開源地址:https://github.com/zstar1003/ragflow-plus
更新方法
下載倉庫最新代碼:
git clone https://github.com/zstar1003/ragflow-plus.git
使用docker啟動:
# cpu模式
docker compose -f docker/docker-compose.yml up -d
# gpu模式
docker compose -f docker/docker-compose_gpu.yml up -d
首次啟動會自動拉取最新版本鏡像。
新功能
1. 上傳文件支持文件夾
在此版本中,優化了上傳文件,目前支持選擇文件夾進行上傳。
系統會自動識別,將該文件夾及其子文件夾中所有文件提取上傳。
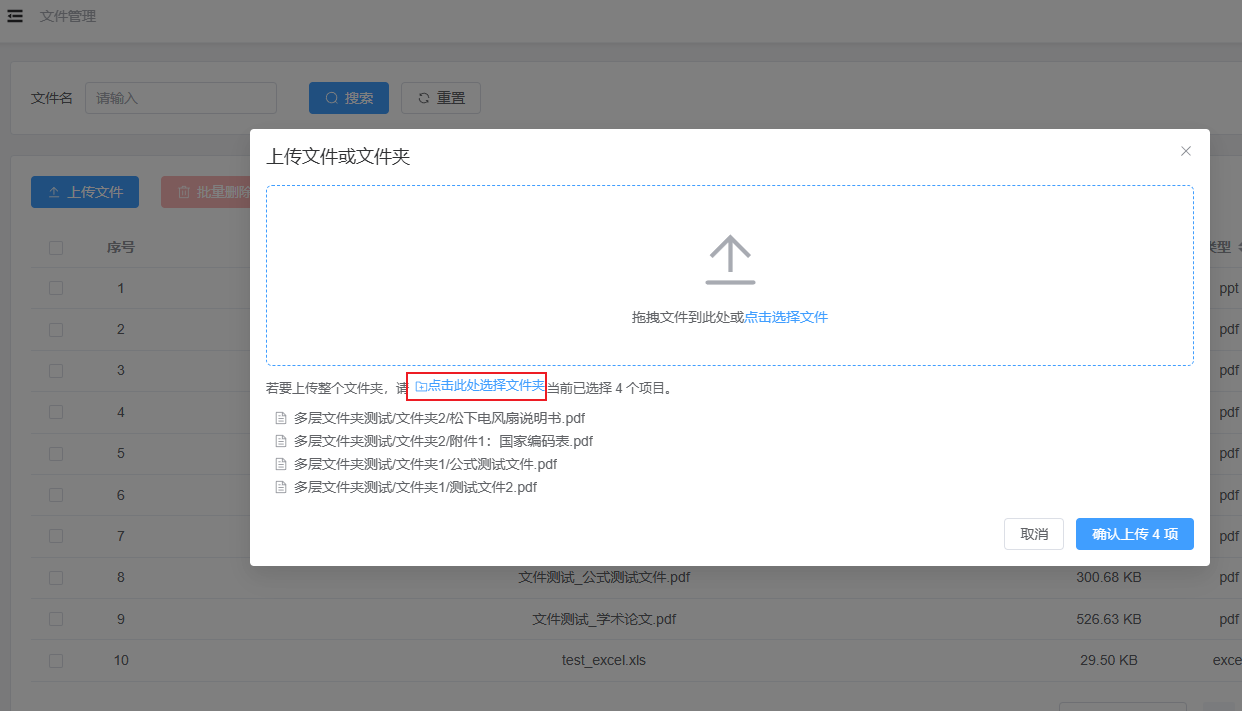
同時,該版本重新調整了文件上傳的請求通道,減少上傳超時的可能性。
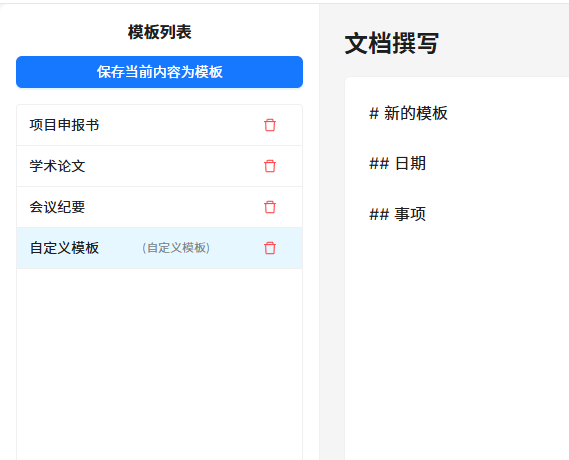
2. 文檔撰寫模式全新升級
此版本重點重構了文檔撰寫模塊,目前在此版本中,支持自定義模板,可將當前文檔內容保存為自定義名稱的模板,并可對現有模板進行調整刪除。
同時,文檔撰寫后端采用了獨立的響應通道,不再需要依賴助理設置進行輸出,響應速度大幅提升。
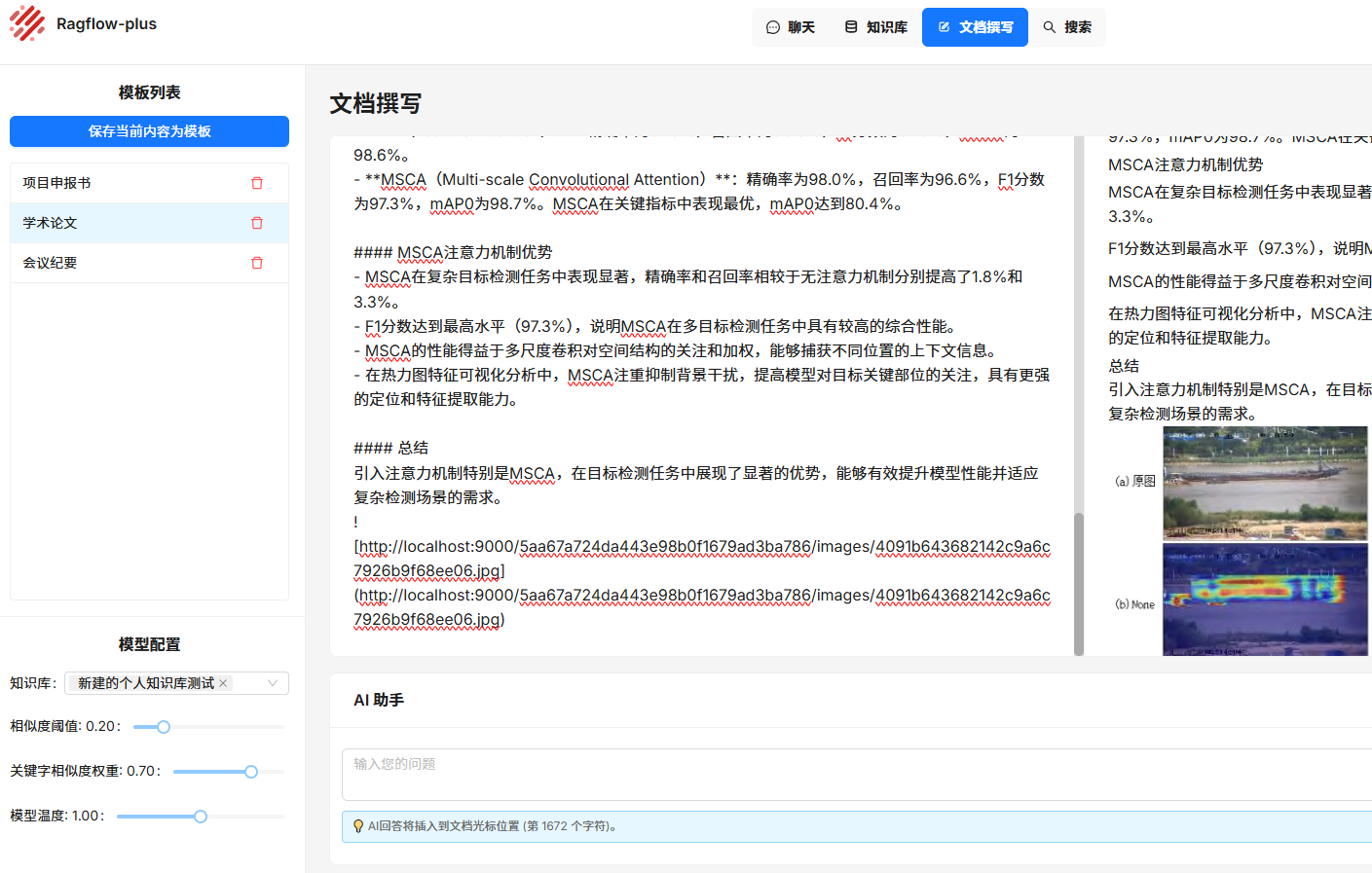
左下角增加配置選項,可以自由選擇一個或多個知識庫信息,同時可調節較為常用的三個搜索及模型參數。
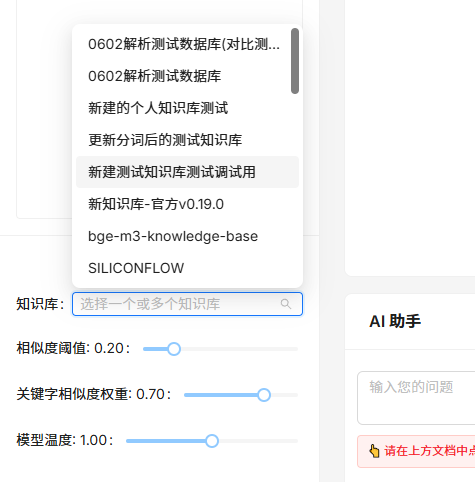
考慮到過多的文檔內容輸入,有超過模型輸入上限的風險。本版本對輸入模型的文本范圍進行重新優化,會自動選取光標位置上下文最多共4000個字符輸入到問答模型中。
功能優化
1. 解析邏輯調整
本版本重新調整了解析邏輯,在解析時增加了和搜索一致的分詞器,解決了上一版本中,做知識庫檢索時,關鍵詞相似度為0的情況。
具體細節可參考本系列第24篇文章:【Ragflow】24.Ragflow-plus開發日志:增加分詞邏輯,修復關鍵詞檢索失效問題
2. 知識庫創建人權限問題
在上一版本中,知識庫創建時,創建人選擇非初始用戶,問答時會出現報錯。
本版本修復了這一問題。
3. excel解析優化
本版本對excel類型的文件采用了單獨的解析管線,速度更快,效果更好。
具體細節可參考本系列第25篇文章:【Ragflow】25.Ragflow-plus開發日志:excel文件解析新思路/公式解析適配
4. Ollama解析接口調整
有群友提到(issue#65),使用ollama構建嵌入模型時,前臺接口采用的是api/embeddings,而上版本后端接口采用的是v1/embeddings,不同的接口返回值不一致,會造成向量相似度計算偏差較大。
下面寫了一個測試腳本,具體測試了一下這兩種接口的具體調用結果:
import requests
import time# Ollama配置
OLLAMA_HOST = "http://localhost:11434" # 默認Ollama地址
MODEL_NAME = "bge-m3" # 使用的embedding模型
TEXT_TO_EMBED = "測試文本"# 定義接口URL和對應的請求體結構
ENDPOINTS = {"api/embeddings": {"url": f"{OLLAMA_HOST}/api/embeddings", # 原生API路徑"payload": {"model": MODEL_NAME, "prompt": TEXT_TO_EMBED}, # 原生API用prompt字段},"v1/embeddings": {"url": f"{OLLAMA_HOST}/v1/embeddings", # OpenAI兼容API路徑"payload": {"model": MODEL_NAME, "input": TEXT_TO_EMBED}, # OpenAI兼容API用input字段},
}headers = {"Content-Type": "application/json"}def test_endpoint(endpoint_name, endpoint_info):"""測試單個端點并返回結果"""print(f"\n測試接口: {endpoint_name}")url = endpoint_info["url"]payload = endpoint_info["payload"]try:start_time = time.time()response = requests.post(url, headers=headers, json=payload)response_time = time.time() - start_timeprint(f"狀態碼: {response.status_code}")print(f"響應時間: {response_time:.3f}秒")try:data = response.json()# 處理不同接口的響應結構差異embedding = Noneif endpoint_name == "api/embeddings":embedding = data.get("embedding") # 原生API返回embedding字段elif endpoint_name == "v1/embeddings":embedding = data.get("data", [{}])[0].get("embedding") # OpenAI兼容API返回data數組中的embeddingif embedding:print(f"Embedding向量長度: {len(embedding)}")return {"endpoint": endpoint_name,"status_code": response.status_code,"response_time": response_time,"embedding_length": len(embedding),"embedding": embedding[:5],}else:print("響應中未找到'embedding'字段")return {"endpoint": endpoint_name, "status_code": response.status_code, "error": "No embedding field in response"}except ValueError:print("響應不是有效的JSON格式")return {"endpoint": endpoint_name, "status_code": response.status_code, "error": "Invalid JSON response"}except Exception as e:print(f"請求失敗: {str(e)}")return {"endpoint": endpoint_name, "error": str(e)}def compare_endpoints():"""比較兩個端點的性能"""results = []print("=" * 50)print(f"開始比較Ollama的embeddings接口,使用模型: {MODEL_NAME}")print("=" * 50)for endpoint_name, endpoint_info in ENDPOINTS.items():results.append(test_endpoint(endpoint_name, endpoint_info))print("\n" + "=" * 50)print("比較結果摘要:")print("=" * 50)successful_results = [res for res in results if "embedding_length" in res]if len(successful_results) == 2:if successful_results[0]["embedding_length"] == successful_results[1]["embedding_length"]:print(f"兩個接口返回的embedding維度相同: {successful_results[0]['embedding_length']}")else:print("兩個接口返回的embedding維度不同:")for result in successful_results:print(f"- {result['endpoint']}: {result['embedding_length']}")print("\nEmbedding前5個元素示例:")for result in successful_results:print(f"- {result['endpoint']}: {result['embedding']}")faster = min(successful_results, key=lambda x: x["response_time"])slower = max(successful_results, key=lambda x: x["response_time"])print(f"\n更快的接口: {faster['endpoint']} ({faster['response_time']:.3f}秒 vs {slower['response_time']:.3f}秒)")else:print("至少有一個接口未返回有效的embedding數據")for result in results:if "error" in result:print(f"- {result['endpoint']} 錯誤: {result['error']}")if __name__ == "__main__":compare_endpoints()
輸出結果如下:
Embedding前5個元素示例:
- api/embeddings: [-1.6793335676193237, 0.28421875834465027, -0.3738324046134949, -0.12534970045089722, 0.22841963171958923]
- v1/embeddings: [-0.0640459, 0.0108394455, -0.014257102, -0.004780547, 0.008711396]更快的接口: api/embeddings (0.078秒 vs 0.091秒)
結果顯示,兩個接口返回維度相同(均為1024),但結果的確存在差異,同時api/embeddings接口的速度更快。
因此,本版本在后臺解析時,對于ollama模型,調用接口調整為api/embeddings,修復前后臺不一致的問題。
雜項
1. 前臺元素精簡
此版本在前臺移除Agent和文件管理,語言僅保留簡體中文、繁體中文、英語,界面更簡介清晰。
2. 后端代碼清理
實測發現,DeepWiki在解析代碼時,會輸出不少deepdoc代碼的細節,版本對其進行進一步解耦清理。
3. 封面優化
對后臺管理的界面圖標和前臺登陸頁的封面進行更換。
下版本計劃
下版本將繼續圍繞文件解析和交互進行優化,計劃改進點如下:
1. 聊天文件上傳
在聊天時,恢復原本的上傳文件交互按鈕,重構文件上傳處理邏輯。
2. chunk關聯圖片修改
在前臺知識庫界面,優化chunk和圖片的關聯顯示,并支持手動編輯調整關聯圖片信息。
3. 圖片輸出順序優化
問答輸出圖片時,進一步支持圖片在回答問題中進行顯示,而不是全放到末尾。
4. 關鍵詞顯性顯示
在知識庫預覽中,顯性顯示每一個chunk的自定義關鍵詞。
5. 中翻英適配
ragflow最新版提供了一個中文翻譯成英文,然后在知識庫中進行檢索的功能,但實現邏輯是通過聊天模型轉換,效率較低,考慮使用更輕量的方式進行實現。
總結
最近聽了好幾小時劉強東的采訪,當初,馬云問劉強東:“四通一達這么便宜,你為什么不用呢?”
出于多種原因,京東走上了自建物流的道路。
RagflowPlus的發展道路也非常相似,當現有的功能實現不夠好時,重構是必由選擇。
掌控算法細節,才能透過表象覺察到底層的本質原因。


![[深度學習]搭建開發平臺及Tensor基礎](http://pic.xiahunao.cn/[深度學習]搭建開發平臺及Tensor基礎)



——Oracle for Linux物理DG環境搭建(2))
)


- 定位元素工具)








