
📋 目錄
- 引言:微服務性能挑戰
- 微服務架構性能瓶頸分析
- 可觀測性體系概述
- 鏈路追蹤技術深度解析
- 性能監控指標體系
- 日志聚合與分析
- 分布式追蹤系統實現
- 性能優化策略與實踐
- 自動化性能調優
- 故障診斷與根因分析
- 最佳實踐與案例研究
- 未來發展趨勢
引言
隨著微服務架構的廣泛采用,傳統的單體應用被分解為多個獨立的服務組件。這種架構模式帶來了更好的可擴展性、技術棧多樣性和團隊獨立性,但同時也引入了新的性能挑戰。
在微服務環境中,一個用戶請求可能需要經過多個服務的協同處理,形成復雜的調用鏈路。當系統出現性能問題時,定位問題根因變得異常困難。鏈路追蹤(Distributed Tracing)?和?可觀測性(Observability)?技術的出現,為解決這些挑戰提供了有效的解決方案。
本文將深入探討微服務架構下的性能優化策略,重點介紹如何構建完善的鏈路追蹤和可觀測性體系,幫助開發團隊更好地理解、監控和優化分布式系統的性能表現。
微服務架構性能瓶頸分析
常見性能瓶頸類型
1. 網絡延遲瓶頸?- 服務間通信開銷 - 網絡分區和抖動 - 負載均衡策略不當
2. 資源競爭瓶頸?- CPU資源爭用 - 內存泄漏和GC壓力 - I/O操作阻塞
3. 依賴鏈路瓶頸?- 關鍵路徑上的慢服務 - 級聯故障傳播 - 超時配置不合理
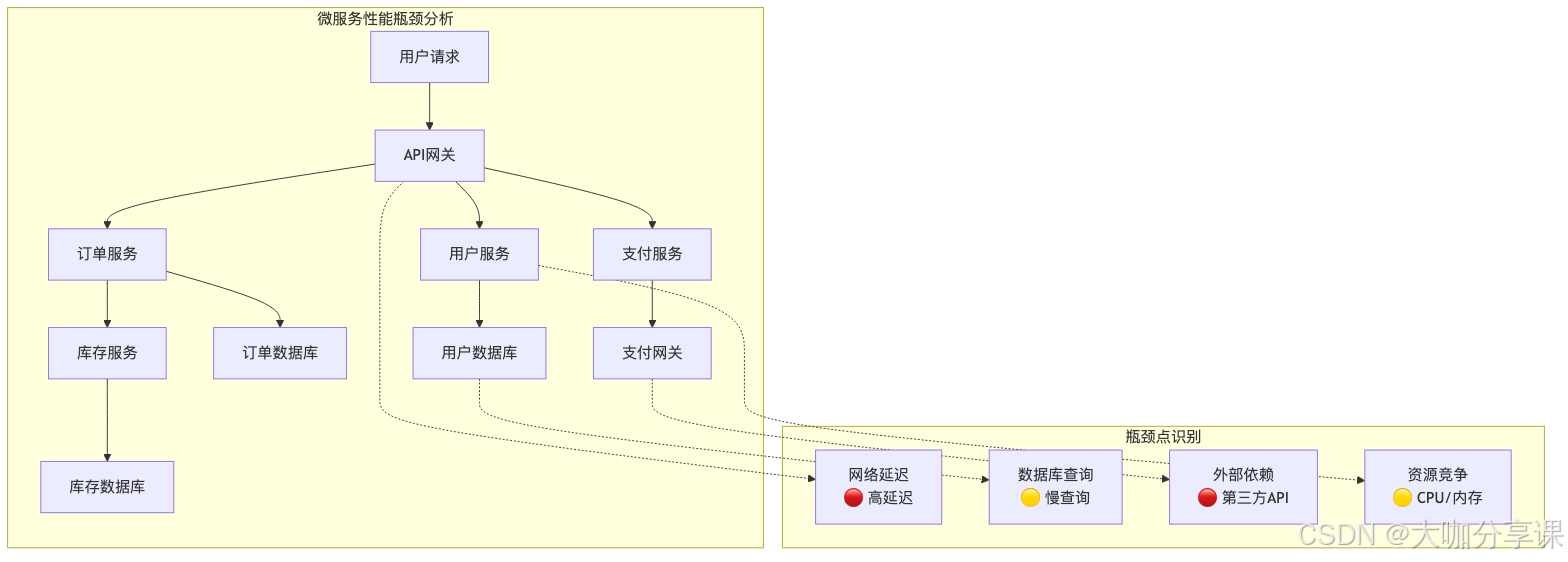
性能問題的挑戰
1. 問題定位困難?- 調用鏈路復雜,難以追蹤 - 異步處理增加排查復雜度 - 跨服務邊界的性能損耗
2. 可見性不足?- 缺乏統一的監控視圖 - 指標數據分散在各個服務 - 關聯分析能力薄弱
3. 影響面廣泛?- 單點故障影響整個系統 - 性能劣化的連鎖反應 - 用戶體驗直接受損
可觀測性體系概述
可觀測性三大支柱
可觀測性(Observability)建立在三大支柱之上:
1. 指標(Metrics)?- 系統性能的量化表示 - 時間序列數據 - 支持聚合和告警
2. 日志(Logs)?- 離散的事件記錄 - 詳細的上下文信息 - 支持全文搜索和分析
3. 鏈路追蹤(Traces)?- 請求在系統中的完整路徑 - 跨服務的調用關系 - 性能瓶頸的精確定位
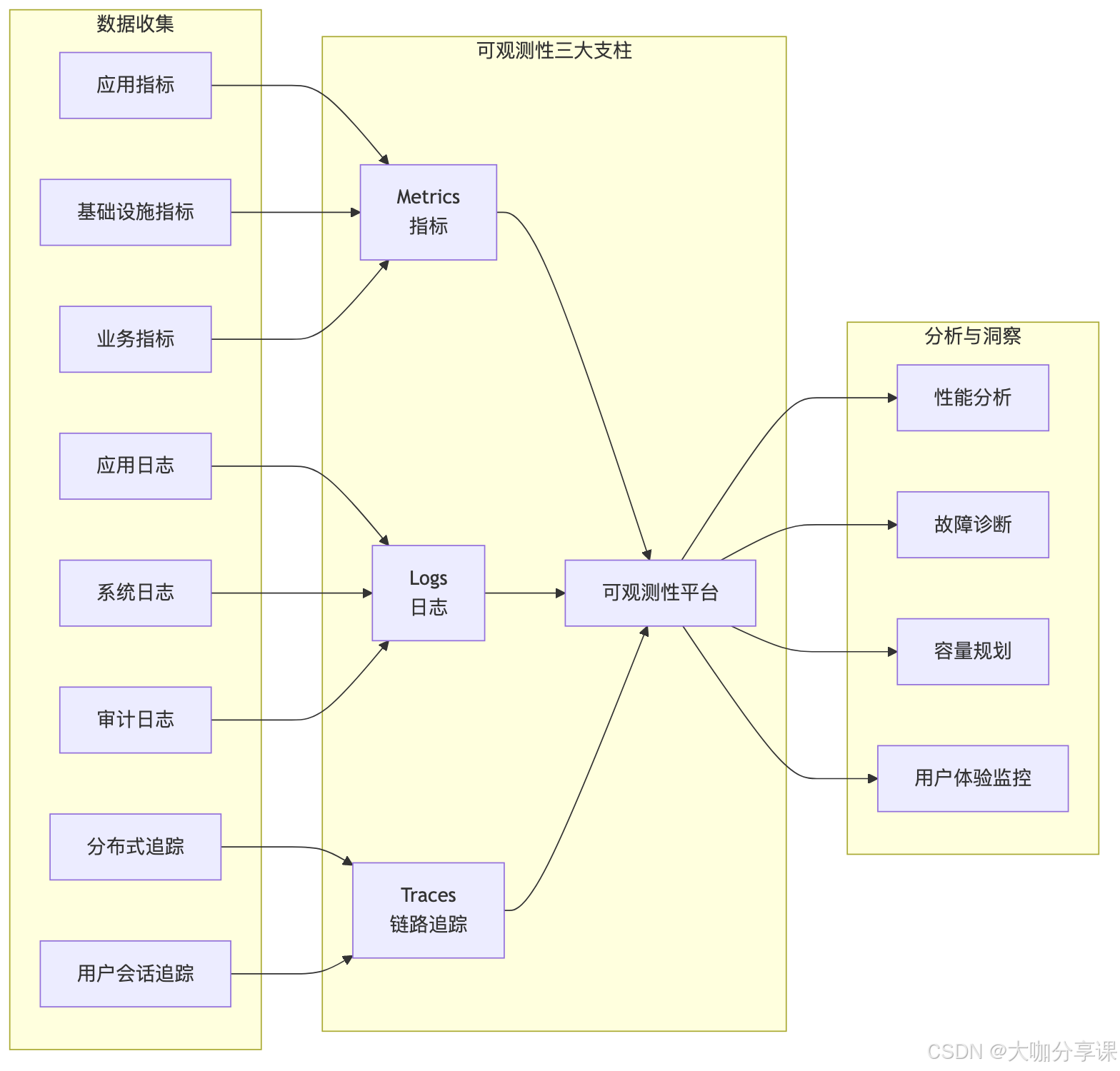
可觀測性成熟度模型
Level 0 - 基礎監控?- 基本的系統指標收集 - 簡單的日志記錄 - 被動的故障響應
Level 1 - 結構化監控?- 標準化的指標體系 - 結構化日志格式 - 主動的告警機制
Level 2 - 關聯分析?- 跨系統的指標關聯 - 鏈路追蹤的引入 - 根因分析能力
Level 3 - 智能運維?- AI驅動的異常檢測 - 自動化的故障處理 - 預測性的容量管理
Level 4 - 自適應系統?- 自動調優算法 - 智能負載調度 - 自愈能力
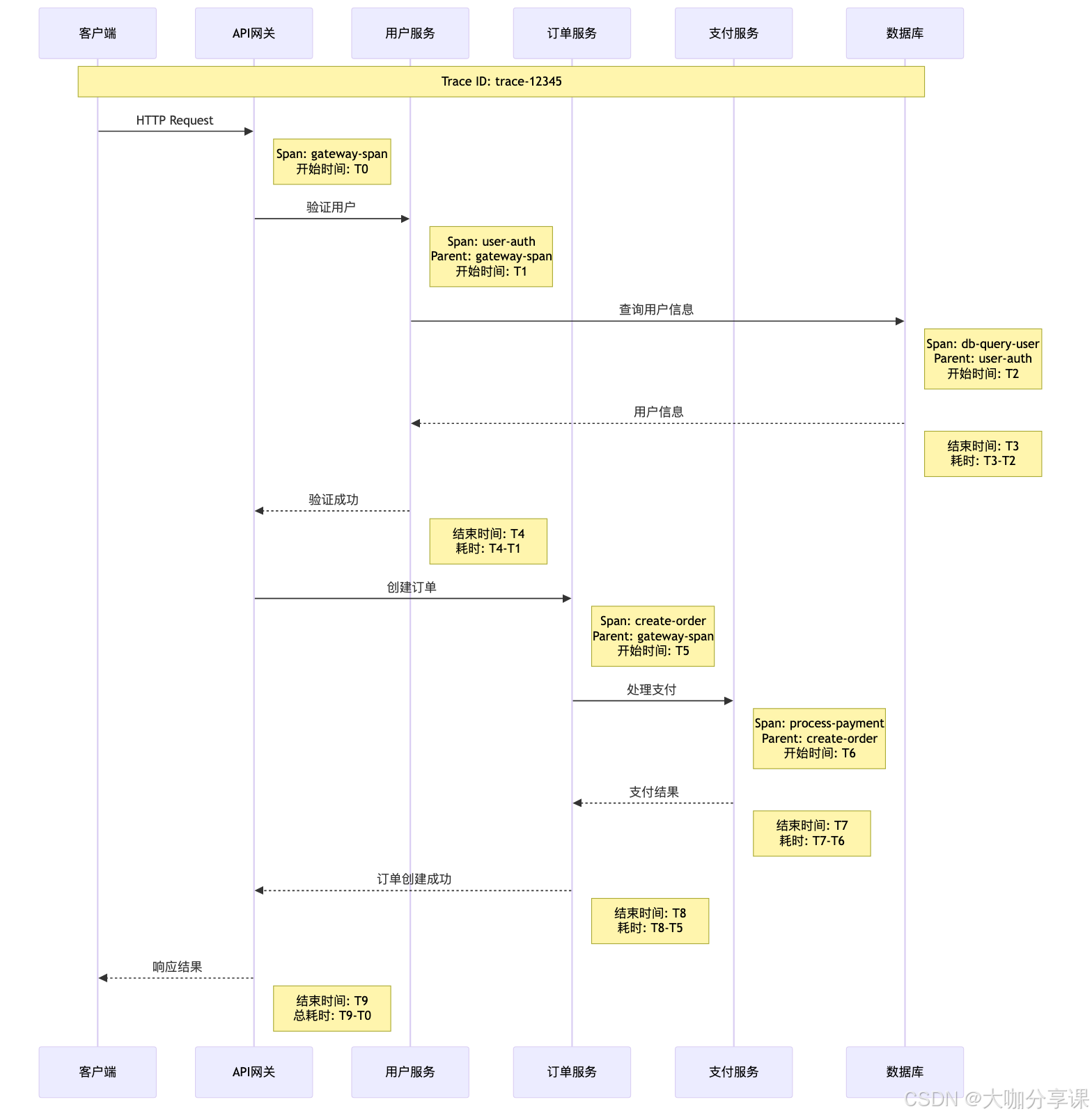
鏈路追蹤技術深度解析
分布式追蹤原理
分布式追蹤通過在請求處理過程中注入追蹤上下文,記錄請求在各個服務中的執行路徑和性能數據。
核心概念: -?Trace(追蹤):一個完整的請求處理過程 -?Span(跨度):追蹤中的一個操作單元 -?Context(上下文):跨服務傳遞的追蹤信息
主流追蹤系統對比
| 特性 | Jaeger | Zipkin | SkyWalking | Datadog APM |
|---|---|---|---|---|
| 開源性 | ? Apache 2.0 | ? Apache 2.0 | ? Apache 2.0 | ? 商業產品 |
| 語言支持 | 多語言 | 多語言 | Java重點 | 多語言 |
| 存儲后端 | 多種選擇 | 多種選擇 | 自帶存儲 | 托管服務 |
| UI界面 | 功能完善 | 基礎功能 | 功能豐富 | 專業界面 |
| 性能開銷 | 低 | 低 | 中等 | 低 |
| 學習曲線 | 中等 | 簡單 | 中等 | 簡單 |
OpenTelemetry標準
OpenTelemetry作為現代可觀測性的標準,提供了統一的API、SDK和工具鏈。
核心組件:
# OpenTelemetry Collector配置示例
receivers:otlp:protocols:grpc:endpoint: 0.0.0.0:4317http:endpoint: 0.0.0.0:4318jaeger:protocols:grpc:endpoint: 0.0.0.0:14250processors:batch:timeout: 5ssend_batch_size: 1024resource:attributes:- key: environmentvalue: productionaction: upsertexporters:jaeger:endpoint: http://jaeger:14268/api/tracesprometheus:endpoint: "0.0.0.0:8889"elasticsearch:endpoints: [http://elasticsearch:9200]logs_index: otel-logsservice:pipelines:traces:receivers: [otlp, jaeger]processors: [batch, resource]exporters: [jaeger]metrics:receivers: [otlp]processors: [batch, resource]exporters: [prometheus]logs:receivers: [otlp]processors: [batch, resource]exporters: [elasticsearch]應用集成實踐
Java應用集成示例:
// Spring Boot應用的OpenTelemetry配置
@Configuration
@EnableConfigurationProperties(TracingProperties.class)
public class TracingConfiguration {@Beanpublic OpenTelemetry openTelemetry(TracingProperties properties) {return OpenTelemetrySDK.builder().setTracerProvider(SdkTracerProvider.builder().addSpanProcessor(BatchSpanProcessor.builder(OtlpGrpcSpanExporter.builder().setEndpoint(properties.getEndpoint()).build()).build()).setResource(Resource.getDefault().merge(Resource.builder().put(ResourceAttributes.SERVICE_NAME, properties.getServiceName()).put(ResourceAttributes.SERVICE_VERSION, properties.getServiceVersion()).build())).build()).buildAndRegisterGlobal();}@Beanpublic Tracer tracer(OpenTelemetry openTelemetry) {return openTelemetry.getTracer("com.example.application");}
}// 業務代碼中的手動追蹤
@Service
public class OrderService {private final Tracer tracer;public OrderService(Tracer tracer) {this.tracer = tracer;}@Traced // 自動追蹤注解public Order createOrder(CreateOrderRequest request) {Span span = tracer.spanBuilder("create-order").setSpanKind(SpanKind.SERVER).startSpan();try (Scope scope = span.makeCurrent()) {// 添加自定義屬性span.setAttributes(Attributes.of(AttributeKey.stringKey("user.id"), request.getUserId(),AttributeKey.longKey("order.amount"), request.getAmount()));// 業務邏輯處理Order order = processOrder(request);// 記錄業務事件span.addEvent("order-validated", Attributes.of(AttributeKey.stringKey("order.id"), order.getId()));return order;} catch (Exception e) {span.recordException(e);span.setStatus(StatusCode.ERROR, e.getMessage());throw e;} finally {span.end();}}
}性能監控指標體系
分層監控模型
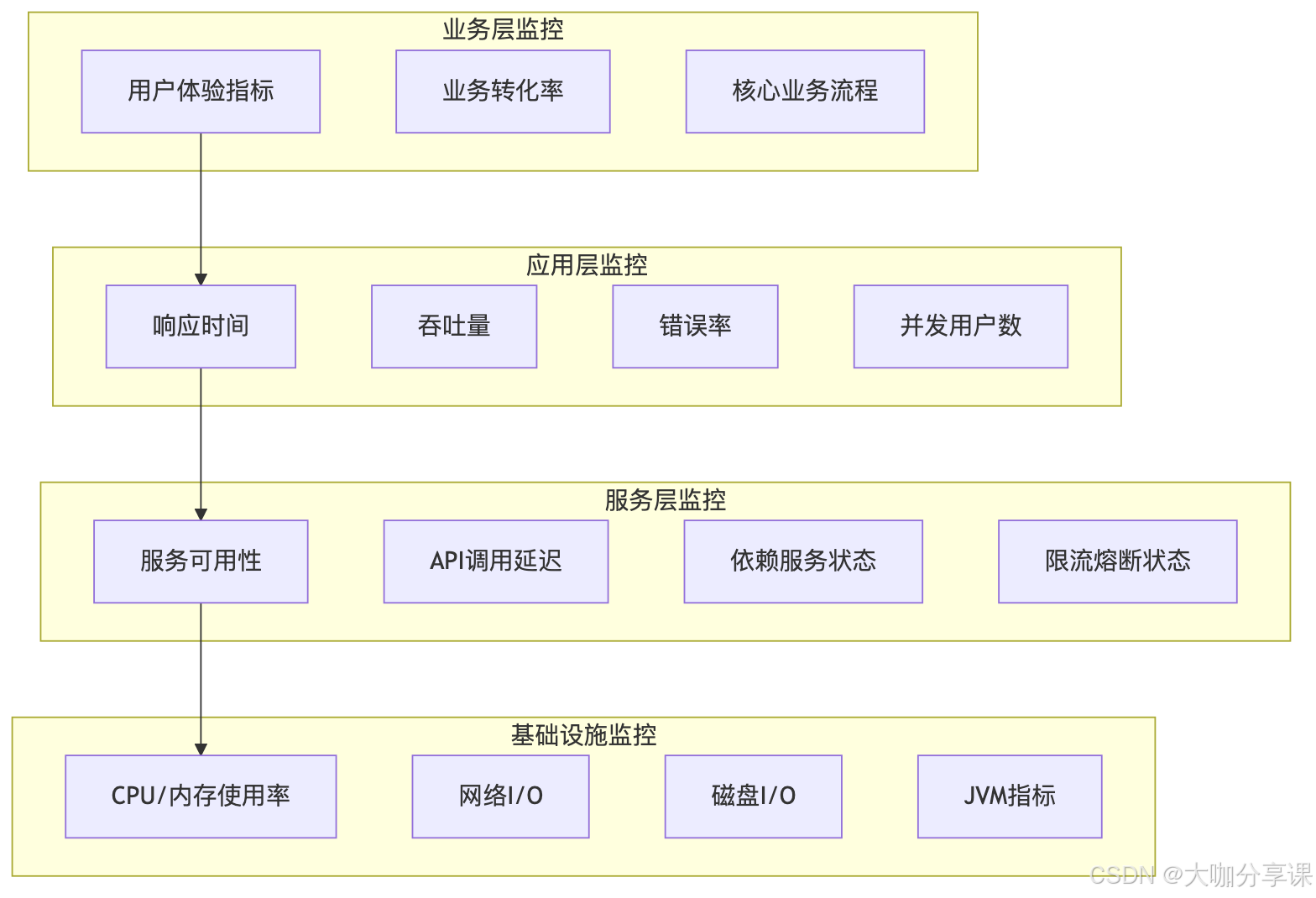
關鍵性能指標(KPI)
1. RED指標模型?-?Rate(速率):請求處理速率 -?Errors(錯誤):錯誤率統計 -?Duration(持續時間):響應時間分布
2. USE指標模型?-?Utilization(利用率):資源使用情況 -?Saturation(飽和度):資源飽和程度 -?Errors(錯誤):資源錯誤統計
3. 業務指標?-?用戶體驗指標:頁面加載時間、交互響應時間 -?轉化率指標:注冊轉化率、支付成功率 -?業務流程指標:訂單處理時間、用戶留存率
指標采集與存儲
Prometheus配置示例:
# prometheus.yml
global:scrape_interval: 15sevaluation_interval: 15srule_files:- "performance_rules.yml"scrape_configs:- job_name: 'microservices'static_configs:- targets: - 'user-service:8080'- 'order-service:8080'- 'payment-service:8080'metrics_path: /actuator/prometheusscrape_interval: 10s- job_name: 'kubernetes-pods'kubernetes_sd_configs:- role: podrelabel_configs:- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]action: keepregex: true- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]action: replacetarget_label: __metrics_path__regex: (.+)alerting:alertmanagers:- static_configs:- targets:- alertmanager:9093性能告警規則:
# performance_rules.yml
groups:- name: microservice.performancerules:# 高延遲告警- alert: HighLatencyexpr: histogram_quantile(0.95, http_request_duration_seconds_bucket) > 0.5for: 5mlabels:severity: warningannotations:summary: "服務 {{ $labels.service }} 延遲過高"description: "{{ $labels.service }} 的95%分位延遲超過500ms,當前值:{{ $value }}s"# 錯誤率告警- alert: HighErrorRateexpr: rate(http_requests_total{status=~"5.."}[5m]) / rate(http_requests_total[5m]) > 0.05for: 2mlabels:severity: criticalannotations:summary: "服務 {{ $labels.service }} 錯誤率過高"description: "{{ $labels.service }} 的錯誤率超過5%,當前值:{{ $value | humanizePercentage }}"# 內存使用率告警- alert: HighMemoryUsageexpr: process_resident_memory_bytes / 1024 / 1024 > 512for: 10mlabels:severity: warningannotations:summary: "服務 {{ $labels.service }} 內存使用過高"description: "{{ $labels.service }} 內存使用超過512MB,當前值:{{ $value }}MB"日志聚合與分析
結構化日志設計
日志標準格式:
{"timestamp": "2024-06-07T10:30:45.123Z","level": "INFO","service": "order-service","traceId": "abc123def456","spanId": "span789","userId": "user-12345","operation": "createOrder","message": "訂單創建成功","duration": 245,"status": "success","metadata": {"orderId": "order-67890","amount": 99.99,"currency": "CNY"},"error": null
}Java應用日志配置:
<!-- logback-spring.xml -->
<configuration><include resource="org/springframework/boot/logging/logback/defaults.xml"/><springProfile name="!local"><appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender"><encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder"><providers><timestamp/><logLevel/><loggerName/><mdc/><arguments/><message/><stackTrace/></providers></encoder></appender></springProfile><!-- 性能日志專用appender --><appender name="PERFORMANCE" class="ch.qos.logback.core.rolling.RollingFileAppender"><file>logs/performance.log</file><rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><fileNamePattern>logs/performance.%d{yyyy-MM-dd}.%i.gz</fileNamePattern><maxFileSize>100MB</maxFileSize><maxHistory>30</maxHistory></rollingPolicy><encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder"><providers><timestamp/><mdc/><message/></providers></encoder></appender><logger name="PERFORMANCE" level="INFO" additivity="false"><appender-ref ref="PERFORMANCE"/></appender><root level="INFO"><appender-ref ref="STDOUT"/></root>
</configuration>ELK Stack集成
Elasticsearch映射配置:
{"mappings": {"properties": {"timestamp": {"type": "date","format": "strict_date_optional_time"},"level": {"type": "keyword"},"service": {"type": "keyword"},"traceId": {"type": "keyword"},"spanId": {"type": "keyword"},"userId": {"type": "keyword"},"operation": {"type": "keyword"},"message": {"type": "text","analyzer": "standard"},"duration": {"type": "long"},"status": {"type": "keyword"},"metadata": {"type": "object","dynamic": true}}}
}Logstash處理配置:
# logstash.conf
input {beats {port => 5044}
}filter {if [fields][service] {mutate {add_field => { "service_name" => "%{[fields][service]}" }}}# 解析JSON日志json {source => "message"}# 提取性能指標if [operation] and [duration] {mutate {add_field => { "metric_type" => "performance" }convert => { "duration" => "integer" }}}# 錯誤日志特殊處理if [level] == "ERROR" {mutate {add_field => { "alert_required" => "true" }}}# 添加地理位置信息(如果有IP)if [clientIp] {geoip {source => "clientIp"target => "geoip"}}
}output {elasticsearch {hosts => ["elasticsearch:9200"]index => "microservice-logs-%{+YYYY.MM.dd}"template_name => "microservice-logs"}# 性能指標發送到專門的索引if [metric_type] == "performance" {elasticsearch {hosts => ["elasticsearch:9200"]index => "performance-metrics-%{+YYYY.MM.dd}"}}
}分布式追蹤系統實現
Jaeger部署架構
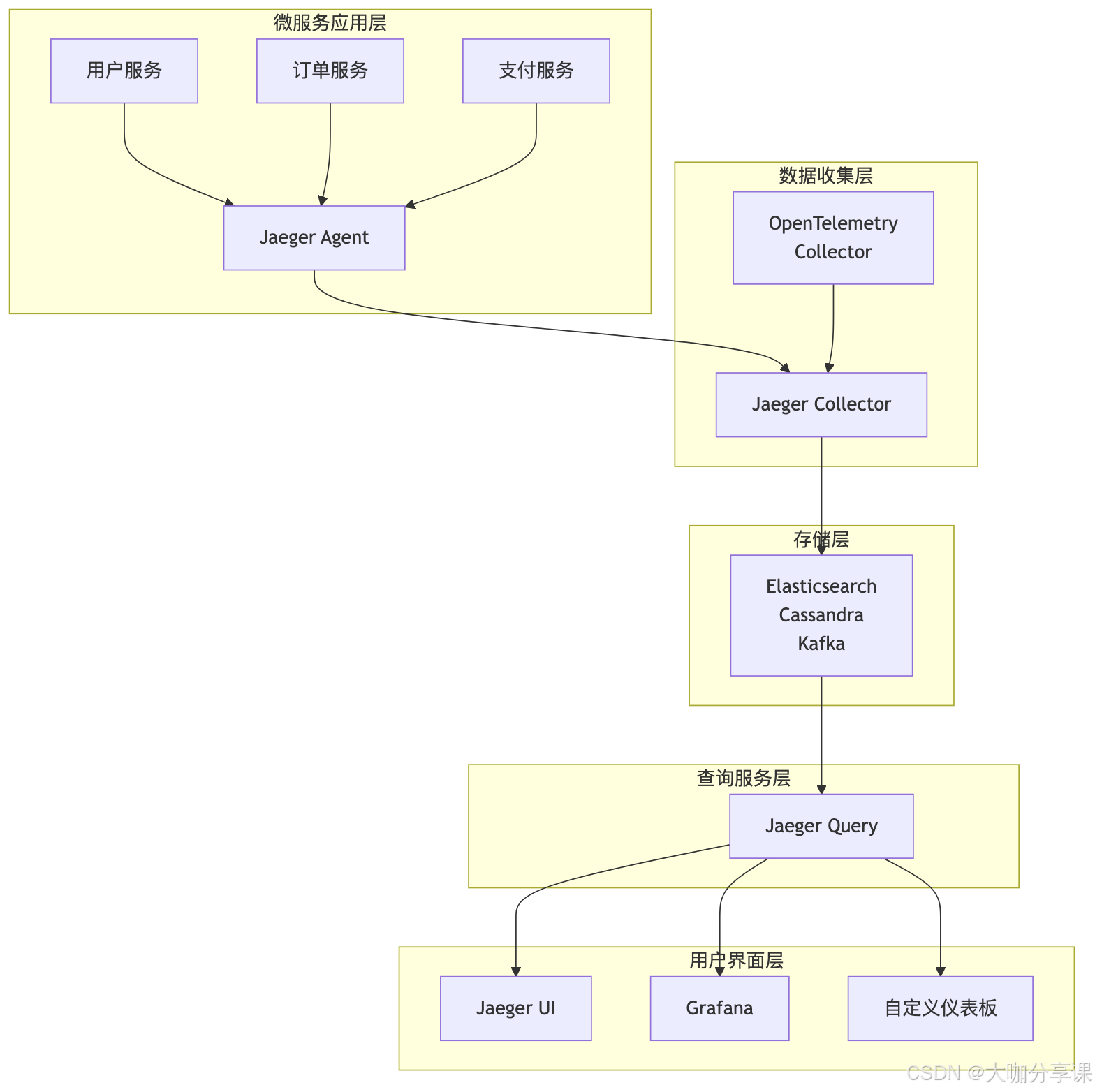
Kubernetes部署配置:
# jaeger-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: jaeger-all-in-onelabels:app: jaeger
spec:replicas: 1selector:matchLabels:app: jaegertemplate:metadata:labels:app: jaegerspec:containers:- name: jaegerimage: jaegertracing/all-in-one:1.41ports:- containerPort: 16686name: jaeger-ui- containerPort: 14268name: jaeger-http- containerPort: 14250name: jaeger-grpc- containerPort: 6831name: jaeger-udpenv:- name: COLLECTOR_ZIPKIN_HTTP_PORTvalue: "9411"- name: SPAN_STORAGE_TYPEvalue: "elasticsearch"- name: ES_SERVER_URLSvalue: "http://elasticsearch:9200"- name: ES_USERNAMEvalue: "elastic"- name: ES_PASSWORDvalueFrom:secretKeyRef:name: elasticsearch-secretkey: passwordresources:limits:memory: "512Mi"cpu: "500m"requests:memory: "256Mi"cpu: "250m"---
apiVersion: v1
kind: Service
metadata:name: jaeger-service
spec:selector:app: jaegerports:- name: jaeger-uiport: 16686targetPort: 16686- name: jaeger-httpport: 14268targetPort: 14268- name: jaeger-grpcport: 14250targetPort: 14250- name: jaeger-udpport: 6831targetPort: 6831protocol: UDP自定義追蹤數據分析
性能分析查詢示例:
# 使用Jaeger Python客戶端進行性能分析
from jaeger_client import Config
import requests
import pandas as pd
import matplotlib.pyplot as pltclass PerformanceAnalyzer:def __init__(self, jaeger_endpoint):self.jaeger_endpoint = jaeger_endpointdef get_trace_data(self, service_name, start_time, end_time):"""從Jaeger獲取追蹤數據"""url = f"{self.jaeger_endpoint}/api/traces"params = {'service': service_name,'start': start_time,'end': end_time,'limit': 1000}response = requests.get(url, params=params)return response.json()def analyze_performance_trends(self, traces_data):"""分析性能趨勢"""performance_data = []for trace in traces_data['data']:for span in trace['spans']:performance_data.append({'service': span['process']['serviceName'],'operation': span['operationName'],'duration': span['duration'],'start_time': span['startTime'],'tags': {tag['key']: tag['value'] for tag in span['tags']}})df = pd.DataFrame(performance_data)return self.generate_performance_report(df)def generate_performance_report(self, df):"""生成性能報告"""report = {'avg_response_time': df.groupby('service')['duration'].mean(),'p95_response_time': df.groupby('service')['duration'].quantile(0.95),'error_rate': df[df['tags'].str.contains('error', na=False)].groupby('service').size() / df.groupby('service').size(),'throughput': df.groupby('service').size() / (df['start_time'].max() - df['start_time'].min())}return report# 使用示例
analyzer = PerformanceAnalyzer('http://jaeger-query:16686')
traces = analyzer.get_trace_data('order-service', '1h', 'now')
report = analyzer.analyze_performance_trends(traces)實時性能監控
Grafana儀表板配置:
{"dashboard": {"title": "微服務性能監控","panels": [{"title": "服務響應時間趨勢","type": "graph","targets": [{"expr": "histogram_quantile(0.95, rate(http_request_duration_seconds_bucket[5m]))","legendFormat": "{{service}} - P95"},{"expr": "histogram_quantile(0.50, rate(http_request_duration_seconds_bucket[5m]))","legendFormat": "{{service}} - P50"}],"yAxes": [{"label": "響應時間 (秒)","min": 0}]},{"title": "服務吞吐量","type": "graph","targets": [{"expr": "rate(http_requests_total[5m])","legendFormat": "{{service}} - RPS"}]},{"title": "錯誤率","type": "singlestat","targets": [{"expr": "rate(http_requests_total{status=~\"5..\"}[5m]) / rate(http_requests_total[5m]) * 100","legendFormat": "錯誤率 %"}],"thresholds": "5,10","colorBackground": true}]}
}性能優化策略與實踐
應用層優化
1. 緩存策略優化
@Service
public class ProductService {@Autowiredprivate RedisTemplate<String, Object> redisTemplate;@Autowiredprivate ProductRepository productRepository;// 多級緩存策略@Cacheable(value = "products", key = "#id", condition = "#id != null")public Product getProduct(Long id) {// L1緩存:本地緩存(Caffeine)Product product = localCache.get(id);if (product != null) {return product;}// L2緩存:分布式緩存(Redis)product = (Product) redisTemplate.opsForValue().get("product:" + id);if (product != null) {localCache.put(id, product);return product;}// L3:數據庫查詢product = productRepository.findById(id).orElse(null);if (product != null) {// 寫回緩存redisTemplate.opsForValue().set("product:" + id, product, Duration.ofMinutes(30));localCache.put(id, product);}return product;}// 緩存預熱@EventListener(ApplicationReadyEvent.class)public void warmUpCache() {CompletableFuture.runAsync(() -> {List<Long> hotProductIds = getHotProductIds();hotProductIds.parallelStream().forEach(this::getProduct);});}
}2. 異步處理優化
@Service
public class OrderProcessingService {@Async("orderProcessingExecutor")@Tracedpublic CompletableFuture<Void> processOrderAsync(Order order) {try {// 異步處理訂單validateOrder(order);reserveInventory(order);processPayment(order);sendConfirmationEmail(order);return CompletableFuture.completedFuture(null);} catch (Exception e) {return CompletableFuture.failedFuture(e);}}// 批量處理優化@Scheduled(fixedDelay = 5000)public void processPendingOrders() {List<Order> pendingOrders = orderRepository.findPendingOrders(PageRequest.of(0, 100));// 并行處理,但控制并發度pendingOrders.parallelStream().limit(20) // 限制并發處理數量.forEach(order -> {try {processOrderAsync(order).get(30, TimeUnit.SECONDS);} catch (Exception e) {handleProcessingError(order, e);}});}
}// 線程池配置
@Configuration
@EnableAsync
public class AsyncConfiguration {@Bean("orderProcessingExecutor")public TaskExecutor orderProcessingExecutor() {ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();executor.setCorePoolSize(10);executor.setMaxPoolSize(50);executor.setQueueCapacity(200);executor.setThreadNamePrefix("order-processing-");executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());executor.initialize();return executor;}
}數據庫性能優化
1. 連接池優化
# application.yml
spring:datasource:hikari:maximum-pool-size: 20minimum-idle: 5connection-timeout: 30000idle-timeout: 600000max-lifetime: 1800000leak-detection-threshold: 60000jpa:properties:hibernate:jdbc:batch_size: 50order_inserts: trueorder_updates: truebatch_versioned_data: trueshow-sql: falseopen-in-view: false2. 查詢優化
@Repository
public class OrderRepository {@EntityManagerprivate EntityManager entityManager;// 批量查詢優化@Query("SELECT o FROM Order o JOIN FETCH o.items WHERE o.status = :status")List<Order> findOrdersWithItems(@Param("status") OrderStatus status);// 分頁查詢優化@Query(value = "SELECT * FROM orders WHERE created_at >= :startDate " +"ORDER BY created_at DESC LIMIT :limit OFFSET :offset",nativeQuery = true)List<Order> findRecentOrders(@Param("startDate") LocalDateTime startDate,@Param("limit") int limit,@Param("offset") int offset);// 使用索引提示優化@Query(value = "SELECT /*+ USE_INDEX(orders, idx_status_created) */ * " +"FROM orders WHERE status = :status AND created_at >= :date",nativeQuery = true)List<Order> findOrdersOptimized(@Param("status") String status,@Param("date") LocalDateTime date);
}網絡層優化
1. HTTP/2和連接復用
@Configuration
public class HttpClientConfiguration {@Beanpublic ReactorClientHttpConnector httpConnector() {HttpClient httpClient = HttpClient.create().protocol(HttpProtocol.H2C, HttpProtocol.HTTP11) // 支持HTTP/2.option(ChannelOption.CONNECT_TIMEOUT_MILLIS, 5000).option(ChannelOption.SO_KEEPALIVE, true).option(ChannelOption.TCP_NODELAY, true).responseTimeout(Duration.ofSeconds(30)).compress(true);return new ReactorClientHttpConnector(httpClient);}@Beanpublic WebClient webClient(ReactorClientHttpConnector connector) {return WebClient.builder().clientConnector(connector).codecs(configurer -> {configurer.defaultCodecs().maxInMemorySize(10 * 1024 * 1024); // 10MB}).build();}
}2. 負載均衡優化
@Component
public class SmartLoadBalancer {private final Map<String, ServiceMetrics> serviceMetrics = new ConcurrentHashMap<>();public ServiceInstance choose(List<ServiceInstance> instances) {if (instances.isEmpty()) {return null;}// 基于響應時間和成功率的智能負載均衡return instances.stream().min(Comparator.comparingDouble(this::calculateScore)).orElse(instances.get(0));}private double calculateScore(ServiceInstance instance) {ServiceMetrics metrics = serviceMetrics.get(instance.getInstanceId());if (metrics == null) {return 1.0; // 新實例給予中等權重}double responseTimeScore = metrics.getAvgResponseTime() / 1000.0; // 響應時間權重double errorRateScore = metrics.getErrorRate() * 10; // 錯誤率權重double activeRequestsScore = metrics.getActiveRequests() / 100.0; // 并發請求權重return responseTimeScore + errorRateScore + activeRequestsScore;}@EventListenerpublic void handleMetricsUpdate(ServiceMetricsEvent event) {serviceMetrics.put(event.getInstanceId(), event.getMetrics());}
}自動化性能調優
基于機器學習的性能預測
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
from sklearn.preprocessing import StandardScaler
import joblibclass PerformancePredictor:def __init__(self):self.model = RandomForestRegressor(n_estimators=100, random_state=42)self.scaler = StandardScaler()self.feature_columns = ['cpu_usage', 'memory_usage', 'active_connections','request_rate', 'db_connections', 'cache_hit_rate']def prepare_features(self, metrics_data):"""準備特征數據"""df = pd.DataFrame(metrics_data)# 添加時間特征df['hour'] = pd.to_datetime(df['timestamp']).dt.hourdf['day_of_week'] = pd.to_datetime(df['timestamp']).dt.dayofweek# 添加滾動統計特征df['cpu_usage_ma5'] = df['cpu_usage'].rolling(window=5).mean()df['memory_usage_trend'] = df['memory_usage'].diff()# 添加交互特征df['cpu_memory_ratio'] = df['cpu_usage'] / (df['memory_usage'] + 1e-6)df['load_factor'] = df['request_rate'] * df['avg_response_time']return df[self.feature_columns].fillna(0)def train_model(self, historical_data):"""訓練性能預測模型"""features = self.prepare_features(historical_data)targets = historical_data['response_time']# 標準化特征features_scaled = self.scaler.fit_transform(features)# 訓練模型self.model.fit(features_scaled, targets)# 保存模型joblib.dump(self.model, 'performance_model.pkl')joblib.dump(self.scaler, 'feature_scaler.pkl')def predict_performance(self, current_metrics):"""預測性能指標"""features = self.prepare_features([current_metrics])features_scaled = self.scaler.transform(features)prediction = self.model.predict(features_scaled)[0]confidence = self.model.predict_proba(features_scaled)[0] if hasattr(self.model, 'predict_proba') else 0.8return {'predicted_response_time': prediction,'confidence': confidence,'feature_importance': dict(zip(self.feature_columns, self.model.feature_importances_))}def generate_optimization_suggestions(self, prediction_result):"""生成優化建議"""suggestions = []importance = prediction_result['feature_importance']# 基于特征重要性生成建議if importance['cpu_usage'] > 0.3:suggestions.append({'type': 'scaling','action': 'increase_cpu_resources','priority': 'high'})if importance['memory_usage'] > 0.25:suggestions.append({'type': 'optimization','action': 'optimize_memory_usage','priority': 'medium'})if importance['cache_hit_rate'] > 0.2:suggestions.append({'type': 'caching','action': 'improve_cache_strategy','priority': 'medium'})return suggestions自適應資源調整
# Kubernetes HPA配置
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:name: adaptive-hpa
spec:scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: order-serviceminReplicas: 2maxReplicas: 20metrics:- type: Resourceresource:name: cputarget:type: UtilizationaverageUtilization: 70- type: Resourceresource:name: memorytarget:type: UtilizationaverageUtilization: 80- type: Objectobject:metric:name: response_time_p95target:type: Valuevalue: "500m"behavior:scaleDown:stabilizationWindowSeconds: 300policies:- type: Percentvalue: 10periodSeconds: 60scaleUp:stabilizationWindowSeconds: 60policies:- type: Percentvalue: 50periodSeconds: 30- type: Podsvalue: 2periodSeconds: 30智能告警系統
class IntelligentAlertSystem:def __init__(self):self.anomaly_detector = IsolationForest(contamination=0.1)self.alert_history = []self.suppression_rules = {}def detect_anomalies(self, metrics_data):"""檢測性能異常"""features = self.extract_features(metrics_data)anomaly_score = self.anomaly_detector.decision_function([features])[0]is_anomaly = self.anomaly_detector.predict([features])[0] == -1return {'is_anomaly': is_anomaly,'anomaly_score': anomaly_score,'severity': self.calculate_severity(anomaly_score, features)}def should_trigger_alert(self, anomaly_result, service_name):"""智能告警觸發判斷"""# 檢查告警抑制規則if self.is_suppressed(service_name, anomaly_result):return False# 檢查告警頻率限制if self.is_rate_limited(service_name):return False# 基于歷史數據的動態閾值dynamic_threshold = self.calculate_dynamic_threshold(service_name)return abs(anomaly_result['anomaly_score']) > dynamic_thresholddef generate_alert(self, anomaly_result, service_name, metrics_data):"""生成智能告警"""alert = {'id': f"alert-{int(time.time())}",'service': service_name,'severity': anomaly_result['severity'],'title': f"{service_name} 性能異常",'description': self.generate_alert_description(anomaly_result, metrics_data),'suggestions': self.generate_remediation_suggestions(anomaly_result, metrics_data),'timestamp': datetime.now().isoformat(),'auto_resolve_enabled': True}self.send_alert(alert)self.alert_history.append(alert)return alertdef generate_remediation_suggestions(self, anomaly_result, metrics_data):"""生成修復建議"""suggestions = []if metrics_data.get('cpu_usage', 0) > 80:suggestions.append({'action': '增加CPU資源或優化CPU密集型操作','impact': '高','estimated_time': '5-10分鐘'})if metrics_data.get('memory_usage', 0) > 85:suggestions.append({'action': '檢查內存泄漏或增加內存限制','impact': '高','estimated_time': '10-30分鐘'})if metrics_data.get('response_time', 0) > 1000:suggestions.append({'action': '檢查數據庫查詢性能或網絡延遲','impact': '中','estimated_time': '15-45分鐘'})return suggestions故障診斷與根因分析
故障診斷流程
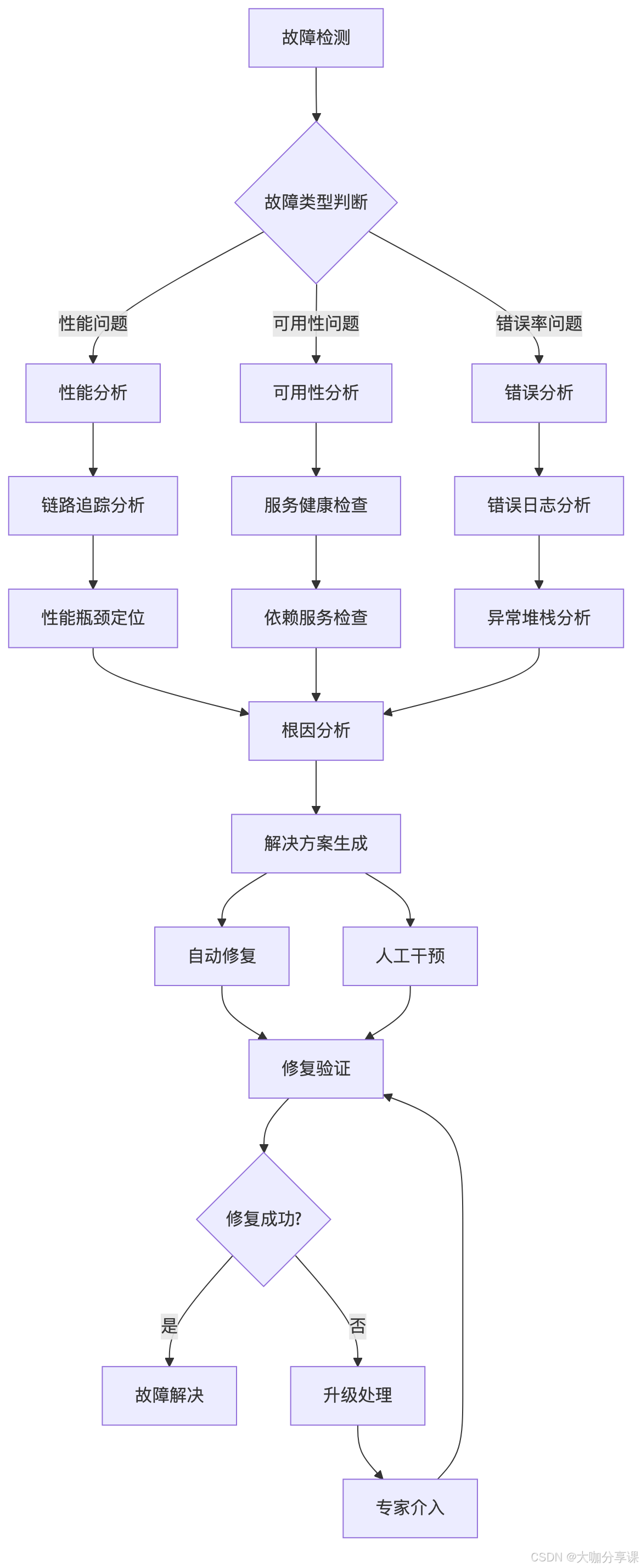
根因分析算法
class RootCauseAnalyzer:def __init__(self):self.dependency_graph = self.build_dependency_graph()self.correlation_analyzer = CorrelationAnalyzer()def analyze_failure(self, incident_data):"""分析故障根因"""affected_services = incident_data['affected_services']timeline = incident_data['timeline']symptoms = incident_data['symptoms']# 1. 構建故障傳播圖propagation_graph = self.build_propagation_graph(affected_services, timeline)# 2. 分析時間序列相關性correlations = self.correlation_analyzer.analyze(symptoms, timeline)# 3. 依賴關系分析dependency_impact = self.analyze_dependency_impact(affected_services)# 4. 綜合分析得出根因root_causes = self.identify_root_causes(propagation_graph, correlations, dependency_impact)return {'root_causes': root_causes,'confidence_score': self.calculate_confidence(root_causes),'impact_analysis': self.analyze_impact(root_causes),'remediation_steps': self.generate_remediation_steps(root_causes)}def build_propagation_graph(self, affected_services, timeline):"""構建故障傳播圖"""graph = nx.DiGraph()# 按時間順序添加故障事件for event in sorted(timeline, key=lambda x: x['timestamp']):service = event['service']graph.add_node(service, **event)# 找出可能的故障傳播路徑for upstream in self.get_upstream_services(service):if upstream in affected_services:graph.add_edge(upstream, service, weight=self.calculate_propagation_probability(upstream, service))return graphdef identify_root_causes(self, propagation_graph, correlations, dependency_impact):"""識別根本原因"""candidates = []# 查找故障起源點(入度為0的節點)origins = [node for node in propagation_graph.nodes() if propagation_graph.in_degree(node) == 0]for origin in origins:score = self.calculate_root_cause_score(origin, propagation_graph, correlations, dependency_impact)candidates.append({'service': origin,'type': 'origin','score': score,'evidence': self.collect_evidence(origin, propagation_graph)})# 查找關鍵節點(移除后大幅減少故障傳播的節點)for node in propagation_graph.nodes():impact_score = self.calculate_removal_impact(node, propagation_graph)if impact_score > 0.7: # 高影響閾值candidates.append({'service': node,'type': 'critical_node','score': impact_score,'evidence': self.collect_evidence(node, propagation_graph)})# 按得分排序返回top候選return sorted(candidates, key=lambda x: x['score'], reverse=True)[:3]自動化故障修復
@Component
public class AutoHealer {@EventListenerpublic void handlePerformanceAnomaly(PerformanceAnomalyEvent event) {HealingStrategy strategy = determineHealingStrategy(event);executeHealing(strategy, event);}private HealingStrategy determineHealingStrategy(PerformanceAnomalyEvent event) {AnomalyType type = event.getAnomalyType();Severity severity = event.getSeverity();return switch (type) {case HIGH_RESPONSE_TIME -> severity == Severity.CRITICAL ? HealingStrategy.IMMEDIATE_SCALE_OUT : HealingStrategy.GRADUAL_OPTIMIZATION;case HIGH_ERROR_RATE -> HealingStrategy.CIRCUIT_BREAKER_ACTIVATION;case MEMORY_LEAK -> HealingStrategy.RESTART_PROBLEMATIC_INSTANCES;case DATABASE_SLOW -> HealingStrategy.QUERY_OPTIMIZATION;default -> HealingStrategy.MONITORING_ENHANCEMENT;};}private void executeHealing(HealingStrategy strategy, PerformanceAnomalyEvent event) {switch (strategy) {case IMMEDIATE_SCALE_OUT:scaleOutService(event.getServiceName(), event.getMetrics());break;case CIRCUIT_BREAKER_ACTIVATION:activateCircuitBreaker(event.getServiceName());break;case RESTART_PROBLEMATIC_INSTANCES:restartUnhealthyInstances(event.getServiceName());break;case QUERY_OPTIMIZATION:optimizeDatabaseQueries(event.getServiceName());break;default:enhanceMonitoring(event.getServiceName());}// 記錄自愈操作recordHealingAction(strategy, event);// 驗證修復效果scheduleHealingVerification(event.getServiceName(), Duration.ofMinutes(5));}@Asyncpublic void scaleOutService(String serviceName, MetricsSnapshot metrics) {try {// 計算所需實例數int currentInstances = kubernetesClient.getCurrentReplicas(serviceName);int targetInstances = calculateTargetReplicas(metrics, currentInstances);// 執行擴容kubernetesClient.scaleDeployment(serviceName, targetInstances);// 監控擴容效果monitorScalingEffect(serviceName, targetInstances);} catch (Exception e) {logger.error("自動擴容失敗: {}", serviceName, e);alertManager.sendAlert(AlertType.AUTO_HEALING_FAILED, serviceName, e.getMessage());}}
}最佳實踐與案例研究
電商平臺案例研究
背景介紹:某大型電商平臺擁有200+微服務,日均處理訂單量超過100萬筆,需要保證99.9%的可用性。
面臨挑戰: - 復雜的服務依賴關系 - 高并發場景下的性能瓶頸 - 故障定位困難,平均修復時間(MTTR)過長 - 缺乏統一的性能監控視圖
解決方案實施:
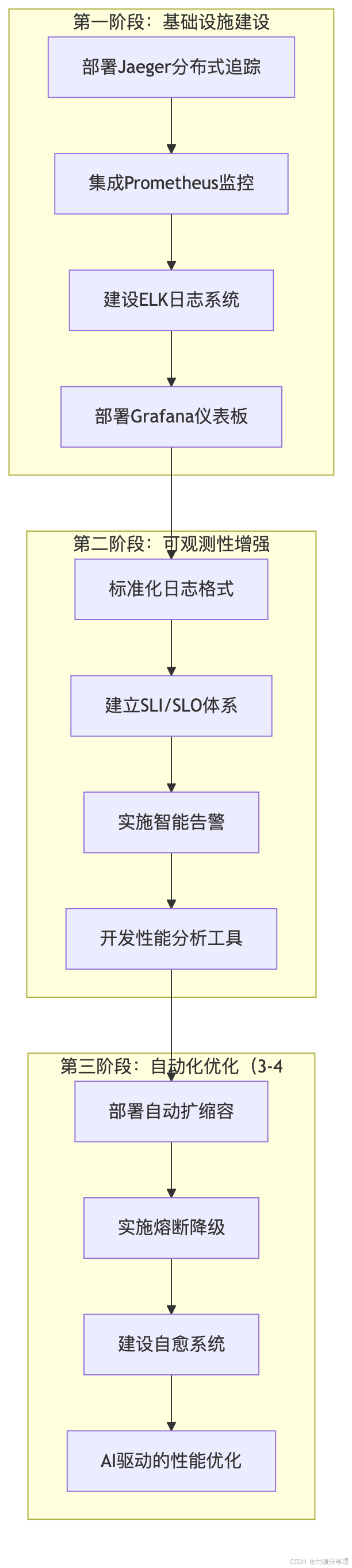
關鍵成果:
| 指標 | 優化前 | 優化后 | 改善幅度 |
|---|---|---|---|
| 平均響應時間 | 800ms | 350ms | ↓ 56% |
| P95響應時間 | 2.1s | 800ms | ↓ 62% |
| 故障檢測時間 | 15分鐘 | 2分鐘 | ↓ 87% |
| 故障修復時間 | 45分鐘 | 12分鐘 | ↓ 73% |
| 可用性 | 99.5% | 99.92% | ↑ 0.42% |
金融科技平臺案例
特殊要求: - 嚴格的監管合規要求 - 低延遲交易處理 - 高安全性要求 - 完整的審計追蹤
關鍵實踐:
// 金融級鏈路追蹤增強
@Component
public class FinancialTracingEnhancer {@EventListenerpublic void enhanceFinancialTrace(SpanStartEvent event) {Span span = event.getSpan();// 添加監管合規標簽span.setTag("compliance.regulation", "PCI-DSS");span.setTag("data.classification", determineDataClassification(span));// 記錄審計信息if (isFinancialTransaction(span)) {span.setTag("audit.required", "true");span.setTag("retention.period", "7years");// 加密敏感信息encryptSensitiveSpanData(span);}// 性能SLA監控String slaLevel = determineSLALevel(span.getOperationName());span.setTag("sla.level", slaLevel);span.setTag("sla.threshold", getSLAThreshold(slaLevel));}private void encryptSensitiveSpanData(Span span) {// 加密賬戶號碼、交易金額等敏感信息Map<String, Object> tags = span.getTags();for (Map.Entry<String, Object> entry : tags.entrySet()) {if (isSensitiveField(entry.getKey())) {String encryptedValue = encryptionService.encrypt(entry.getValue().toString());span.setTag(entry.getKey() + ".encrypted", encryptedValue);span.setTag(entry.getKey(), "[ENCRYPTED]");}}}
}實施最佳實踐總結
1. 漸進式實施策略?- 從核心服務開始,逐步擴展到全系統 - 建立試點項目驗證方案可行性 - 制定詳細的實施計劃和回滾方案
2. 團隊協作與培訓?- 建立跨職能的可觀測性團隊 - 定期進行技術培訓和知識分享 - 建立最佳實踐文檔和操作手冊
3. 工具選型原則?- 優先選擇開源和標準化解決方案 - 考慮與現有技術棧的兼容性 - 評估長期維護成本和學習曲線
4. 性能基準建立?- 建立詳細的性能基準線 - 定期進行性能回歸測試 - 持續優化和改進監控指標
未來發展趨勢
技術發展方向
1. eBPF技術在可觀測性中的應用
// eBPF程序示例:監控HTTP請求延遲
#include <linux/bpf.h>
#include <linux/ptrace.h>
#include <linux/tcp.h>struct http_event {u64 timestamp;u32 pid;u32 duration;char method[8];char url[128];u16 status_code;
};BPF_PERF_OUTPUT(http_events);
BPF_HASH(start_times, u32, u64);// HTTP請求開始時記錄時間戳
int trace_http_start(struct pt_regs *ctx) {u32 pid = bpf_get_current_pid_tgid();u64 ts = bpf_ktime_get_ns();start_times.update(&pid, &ts);return 0;
}// HTTP請求結束時計算延遲并發送事件
int trace_http_end(struct pt_regs *ctx) {u32 pid = bpf_get_current_pid_tgid();u64 *start_ts = start_times.lookup(&pid);if (start_ts) {u64 end_ts = bpf_ktime_get_ns();u32 duration = (end_ts - *start_ts) / 1000000; // 轉換為毫秒struct http_event event = {};event.timestamp = end_ts;event.pid = pid;event.duration = duration;// 提取HTTP方法和URL(簡化示例)bpf_probe_read_str(event.method, sizeof(event.method), (void*)PT_REGS_PARM1(ctx));bpf_probe_read_str(event.url, sizeof(event.url), (void*)PT_REGS_PARM2(ctx));http_events.perf_submit(ctx, &event, sizeof(event));start_times.delete(&pid);}return 0;
}2. AI驅動的智能運維
class AIPerformanceOptimizer:def __init__(self):self.reinforcement_agent = self.build_rl_agent()self.performance_predictor = self.build_predictor_model()self.action_space = self.define_action_space()def build_rl_agent(self):"""構建強化學習智能體"""from stable_baselines3 import PPOfrom gym import spaces# 定義狀態空間(系統指標)observation_space = spaces.Box(low=0, high=1, shape=(20,), # CPU、內存、延遲等20個指標dtype=np.float32)# 定義動作空間(優化操作)action_space = spaces.Discrete(10) # 10種優化動作return PPO('MlpPolicy', observation_space=observation_space,action_space=action_space,learning_rate=0.0003)def optimize_performance(self, current_metrics):"""AI驅動的性能優化"""# 1. 預測未來性能趨勢future_metrics = self.performance_predictor.predict(current_metrics)# 2. 強化學習智能體決策state = self.normalize_metrics(current_metrics)action = self.reinforcement_agent.predict(state)[0]# 3. 執行優化動作optimization_result = self.execute_optimization_action(action, current_metrics)# 4. 收集反饋并學習reward = self.calculate_reward(current_metrics, optimization_result)self.reinforcement_agent.learn(state, action, reward)return optimization_resultdef execute_optimization_action(self, action, metrics):"""執行優化動作"""actions = {0: self.scale_up_replicas,1: self.scale_down_replicas,2: self.adjust_cache_size,3: self.tune_connection_pool,4: self.optimize_gc_parameters,5: self.adjust_thread_pool,6: self.update_load_balancer_weights,7: self.enable_circuit_breaker,8: self.optimize_database_queries,9: self.no_action}return actions[action](metrics)3. 混沌工程與可觀測性結合
class ChaosObservabilityFramework:def __init__(self):self.chaos_experiments = []self.observability_stack = ObservabilityStack()self.experiment_analyzer = ExperimentAnalyzer()def run_chaos_experiment(self, experiment_config):"""運行混沌實驗并收集可觀測性數據"""# 1. 建立基線指標baseline_metrics = self.collect_baseline_metrics(experiment_config['duration'])# 2. 開始監控增強enhanced_monitoring = self.enable_enhanced_monitoring(experiment_config['target_services'])# 3. 執行混沌實驗experiment_result = self.execute_chaos_experiment(experiment_config)# 4. 收集實驗期間的可觀測性數據experiment_metrics = self.collect_experiment_metrics(experiment_config['duration'], experiment_config['target_services'])# 5. 分析系統韌性resilience_analysis = self.analyze_system_resilience(baseline_metrics, experiment_metrics, experiment_result)# 6. 生成改進建議improvement_suggestions = self.generate_improvements(resilience_analysis)return {'experiment_id': experiment_result['id'],'resilience_score': resilience_analysis['score'],'weak_points': resilience_analysis['weak_points'],'improvements': improvement_suggestions,'observability_insights': self.extract_observability_insights(experiment_metrics)}def analyze_system_resilience(self, baseline, experiment_data, chaos_result):"""分析系統韌性"""resilience_metrics = {}# 計算恢復時間resilience_metrics['recovery_time'] = self.calculate_recovery_time(baseline, experiment_data, chaos_result['injection_time'])# 計算影響范圍resilience_metrics['blast_radius'] = self.calculate_blast_radius(experiment_data, chaos_result['target_services'])# 計算服務降級程度resilience_metrics['degradation_level'] = self.calculate_degradation_level(baseline, experiment_data)# 綜合韌性得分resilience_score = self.calculate_resilience_score(resilience_metrics)return {'score': resilience_score,'metrics': resilience_metrics,'weak_points': self.identify_weak_points(resilience_metrics)}標準化發展
1. OpenTelemetry生態成熟?- 更完善的自動instrumentation - 標準化的語義約定 - 云原生平臺的深度集成
2. 可觀測性即代碼?- 基礎設施即代碼的擴展 - 版本控制的監控配置 - GitOps工作流程集成
3. 隱私保護與合規?- 端到端的數據加密 - 細粒度的訪問控制 - 自動化的合規檢查
新興技術趨勢
1. 邊緣計算可觀測性?- 邊緣節點的性能監控 - 邊云協同的鏈路追蹤 - 分布式可觀測性架構
2. 量子計算影響?- 量子安全的追蹤協議 - 量子算法優化的性能分析 - 量子網絡的監控需求
3. 綠色可觀測性?- 低碳排放的監控方案 - 能耗優化的性能調優 - 可持續發展的運維實踐
總結
微服務架構的性能優化是一個持續演進的過程,鏈路追蹤與可觀測性建設為解決復雜分布式系統的性能挑戰提供了強有力的技術支撐。通過本文的深入分析,我們可以得出以下核心結論:
關鍵價值
1. 端到端可見性?- 完整的請求處理路徑追蹤 - 跨服務的性能瓶頸定位 - 實時的系統健康狀態監控
2. 數據驅動決策?- 基于真實數據的性能優化 - 科學的容量規劃和擴容策略 - 精確的故障根因分析
3. 自動化運維?- 智能的異常檢測和告警 - 自適應的性能調優 - 快速的故障恢復機制
實施要點
1. 統一標準?- 采用OpenTelemetry等行業標準 - 建立一致的監控指標體系 - 制定標準化的操作規范
2. 分層建設?- 從基礎設施到業務層的全棧監控 - 逐步完善可觀測性能力 - 持續優化和改進監控策略
3. 智能化發展?- 引入AI/ML技術提升自動化水平 - 建設預測性的運維能力 - 實現自愈的系統架構
未來展望
隨著云原生技術的不斷發展和AI技術的深度融合,微服務性能優化將朝著更加智能化、自動化的方向發展。eBPF等新興技術將提供更高效的數據收集能力,而強化學習等AI技術將實現更智能的優化決策。
企業在建設可觀測性體系時,應該:
- 制定長遠規劃:考慮技術演進趨勢,選擇可擴展的技術方案
- 重視團隊建設:培養具備可觀測性技能的人才隊伍
- 持續實踐改進:在實踐中不斷完善和優化監控體系
- 關注標準發展:跟蹤行業標準和最佳實踐的發展
通過系統性的可觀測性建設,企業能夠更好地應對微服務架構帶來的復雜性挑戰,實現高性能、高可用的分布式系統,為業務發展提供堅實的技術保障。
關鍵詞:微服務, 性能優化, 鏈路追蹤, 可觀測性, 分布式系統, Jaeger, OpenTelemetry, 監控告警









)
)


:Spring Boot + AI + DeepSeek + Redis 實現聊天應用上下文記憶功能(附完整源碼))





:Spring Boot + AI + DeepSeek 打造智能成語接龍游戲(附完整源碼))