1 AI時代的架構革命
與傳統軟件開發和軟件架構師相比,AI架構師面臨著三重范式轉換:
1.1 技術維度,需處理異構算力調度與模型生命周期管理的復雜性;
1.2 系統維度,需平衡實時性與資源約束的矛盾;
1.3 價值維度,需建立技術指標與商業效果的可量化連接。
而這些轉變使得AI架構師成為技術棧最寬、能力維度最廣的角色之一
本文基于筆者從碼農到AI架構師(薪資3倍躍遷)的真實成長路徑,結合業界前沿實踐,系統性地解構AI架構師的素養模型、技術體系與進階路線,為致力于此領域的技術人員提供可落地的成長框架
2 素養模型:四維模型構建
2.1 技術維度:開發技術深度與工程廣度的融合
AI架構師首先需要建立縱貫式技術棧,在算法理論與工程實踐兩個維度達到專業水準。在算法層面,需深入掌握機器學習數學基礎(線性代數、概率論、優化方法),能夠推導主流模型(從傳統機器學習到Transformer/BERT等前沿網絡)的數學本質3。這種數理能力使架構師能準確評估算法選型的理論邊界,避免陷入“調參陷阱”。
在工程實現層面,需突破單點能力局限,構建覆蓋全鏈路的系統工程能力:
-
數據工程:設計支持特征回溯、版本管理的特征平臺,解決數據漂移問題
-
訓練優化:掌握混合精度訓練、分布式并行策略(數據/模型/流水線并行)
-
推理部署:構建服務網格(如KServe/Triton),實現模型灰度發布與自動回滾
-
資源調度:在GPU池化與彈性伸縮間取得成本與性能的平衡7
這種“算法洞察力+工程實現力”的融合,使AI架構師能在2024年某金融項目中規避因盲目采用新框架導致團隊學習成本激增40%的陷阱1。
2.2 架構維度:系統思維與架構重構能力
面對AI系統的復雜性,架構師需具備多層級抽象能力,將業務需求轉化為可擴展的技術方案。核心在于建立資源異構與智能服務協同的分層架構原則:
-
接入層:集成AuthN/AuthZ與速率限制,應對惡意提示詞攻擊
-
AI服務層:通過gRPC封裝模型,支持動態加載(如LoRA適配器)
-
向量層:分離結構化數據與向量存儲,優化高維索引查詢
-
算力層:抽象GPU/TPU/NPU資源,通過虛擬設備接口實現熱遷移7
在邊緣場景中,這種分層思維尤為重要。如英特爾至強6系統集成芯片通過專用I/O芯粒(Intel 4工藝)優化邊緣限制,支持-40°C~85°C寬溫運行,集成AMX指令集提升推理性能,在工業物聯網場景實現端到端AI工作流管理。
2.3 協同維度:技術領導與跨域協同力
AI項目的成功高度依賴多角色協同效能。架構師需具備“技術布道”能力,構建統一認知框架:
-
面向管理者:量化模型指標與商業價值(如“響應延遲降低100ms=客服成本降5%”)
-
指導算法團隊:約束模型復雜度(如FLOPs<目標硬件峰值30%)
-
協調運維團隊:設計可觀測性方案(追蹤GPU利用率/排隊延遲/分位數延遲)
某智慧城市項目實踐表明,采用五維評估法(業務匹配度30%、技術成熟度25%、團隊適配度20%、擴展性15%、可觀測性10%)進行技術選型,可降低方案失敗率40%以上1。這種結構化決策機制有效平衡了技術創新與落地風險。
2.4 價值維度:商業洞察與倫理決策力
頂尖AI架構師需培養成本敏感度與倫理風險意識。在成本控制方面,需掌握黃金公式:
總成本 = (訓練成本 × 迭代次數) + (推理成本 × QPS) + 隱性成本(技術債/人才培訓)
通過混合精度訓練(內存占用↓30%)、三級特征緩存、動態硬件編排等策略實現最優TCO。
在倫理維度,需建立合規檢查清單:
-
數據隱私:用戶信息匿名化覆蓋率≥99%(聯邦學習+差分隱私)
-
算法公平:群體預測偏差率<5%(公平性約束算法)
-
環境可持續:單次訓練CO?排放當量監控(綠色AI調度策略)
2024年某醫療項目因未通過倫理審查導致上線延遲6個月的教訓警示我們:技術向善不是道德選擇,而是商業必需。
3 技術篇:知識體系構建
3.1 基礎理論體系
AI架構師需要構建三位一體的理論基礎,其知識結構應覆蓋以下核心領域:
-
數學基石:重點掌握矩陣微分(用于梯度下降證明)、概率圖模型(貝葉斯網絡推導)、信息論(交叉熵與KL散度優化)。這些知識成為理解模型內部工作機制的“解碼器”,如在Transformer中,對奇異值分解的深刻理解可指導注意力頭剪枝策略6。
-
算法演進:從傳統機器學習(如XGBoost分裂策略)到深度學習(CNN的平移不變性理論),直至大模型時代(Transformer的熵縮放法則)。需特別關注計算效率與理論邊界的平衡,例如在推薦系統中,雙塔模型通過解耦用戶/商品表征計算,實現百倍推理加速。
-
計算架構:深入理解內存墻問題的根源。研究表明,邊緣設備運行10億參數模型時,數據搬運能耗占比高達65%5。ALPINE框架采用近內存計算策略,通過指令集擴展執行恒定時間矩陣乘法,在卷積網絡中實現20.8倍能效提升。
表2:AI架構師技術能力體系
| 能力域 | 核心要求 | 評估標準 | 學習資源 |
|---|---|---|---|
| 算法基礎 | 掌握Transformer/BERT原理 | 論文復現能力 | 《動手學深度學習》 |
| 工程能力 | K8s+ServiceMesh實戰 | CNCF認證 | 阿里云云原生AI課 |
| 業務理解 | 完整AI解決方案設計 | 競賽排名 | AI Challenger |
| 工具鏈 | Triton推理部署 | P99延遲<100ms | NVIDIA深度學習學院 |
3.2 工具鏈全景圖
現代AI架構師需駕馭三層技術棧,形成端到端的解決方案能力:
-
開發層:框架選型需場景適配——高實時選TensorRT+ONNX(速度↑3-5倍)、小樣本用PyTorch+遷移學習(數據需求↓60%)、多模態處理采用HuggingFace Pipelines。關鍵在避免“技術虛榮”,某電商案例顯示,ResNet-50在優化后比盲目上SOTA模型節省70%成本,精度僅降0.2%。
-
部署層:構建推理即服務架構。Lunar Lake客戶端處理器通過NPU架構革新,實現40%功耗降低與4倍生成式AI能力提升,證明專用硬件對邊緣部署的價值。服務端部署則需考慮模型分片與流水線并行,如英特爾Gaudi 3通過RoCE網絡優化,解決千節點集群擴展瓶頸。
-
監控層:超越傳統準確率指標,建立多維評估體系。包括:數據漂移檢測(PSI>0.1觸發告警)、概念漂移捕捉(模型置信度驟降報警)、公平性監控(群體準確率差異<5%)。某金融風控系統通過引入對抗樣本掃描,將模型攻擊抵御力提升8倍。
3.3 領域專精路線
針對不同應用場景,AI架構師需培養垂直領域架構嗅覺:
-
邊緣計算:采用四層優化法:設備層(模型量化<10MB)、通信層(自適應帶寬協議)、安全層(TEE+聯邦學習)、更新層(差分模型更新)。英特爾Granite Rapids-D通過PCIe 5.0×32與CXL 2.0內存擴展,在工業物聯網場景實現確定性時延。
-
大模型系統:非本人領域
-
高性能計算:非本人領域
-
.....
4 成長篇:三階進階路線圖
4.1 階段式能力躍遷
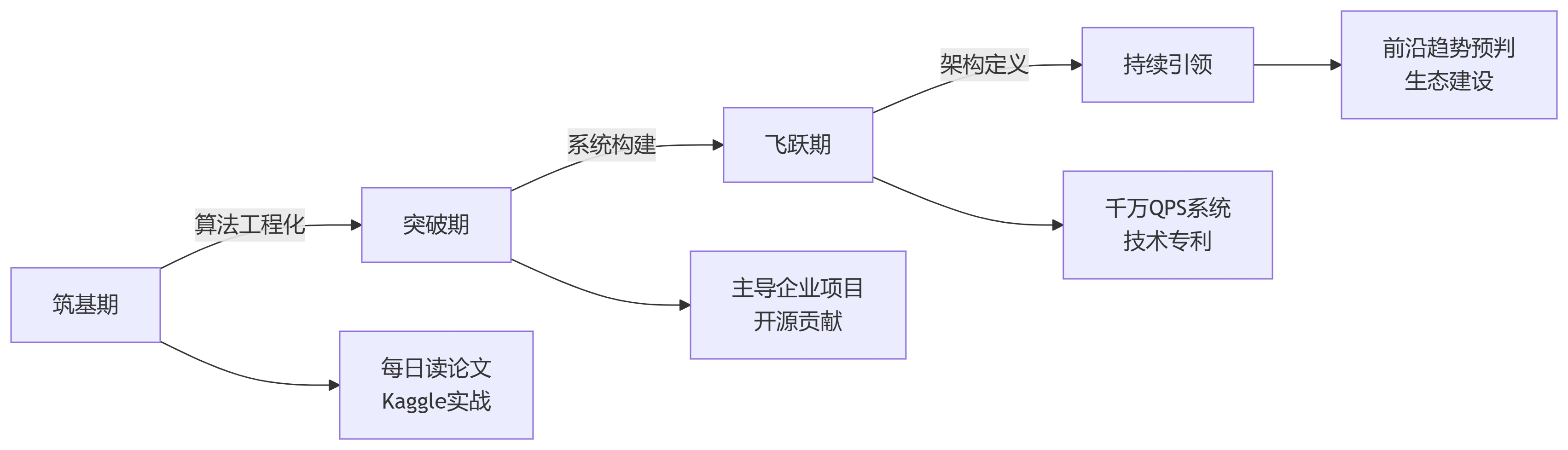
基于筆者從普通開發者到AI架構師(年薪35萬→90萬)的真實路徑,提煉出18個月進階模型:
-
筑基期(0-6月):
算法工程化為核心目標。每日精讀1篇ArXiv論文(重點看Methodology),完成3個Kaggle完整項目(從特征工程到模型優化),考取AWS ML認證。關鍵在建立端到端實現能力,避免陷入理論空談。 -
突破期(6-12月):
聚焦復雜系統構建。主導企業級項目落地(如推薦系統優化),開發GitHub星標100+的開源工具(如模型剪枝庫),堅持技術博客周更。某轉型工程師通過開發PyTorch-DirectML插件,解決AMD GPU訓練瓶頸,獲得社區廣泛采納。 -
飛躍期(12-18月):
錘煉架構定義能力。設計千萬QPS推理系統(動態批處理+自適應量化),申請技術專利(如新型注意力機制),培養AI工程團隊。采用決策影響因子分析法:技術選型對業務KPI的影響權重≥30%。
4.2 實戰避坑指南
基于百家案例提煉的風險防控策略:
-
技術選型:避免“新即是好”誤區。2024年某金融項目因盲目采用Rust重寫服務,導致交付延期5個月。應遵循ROI評估矩陣:社區活躍度(GitHub star>5k)、生產案例數(≥3家頭部企業)、團隊學習成本(<120小時)。
-
數據治理:建立數據質量閉環。某自動駕駛公司因未規范圖像標注標準,導致模型迭代受阻。關鍵措施包括:特征元數據注冊(類型/分布/血緣)、漂移檢測(PSI<0.25)、版本快照(支持回滾到任意版本)。
-
上線保障:企業級Checklist必不可少:
-
灰度發布能力(流量比例可調)
-
監控指標完整性(GPU顯存/SM利用率)
-
回滾機制完備性(模型/數據雙回滾)
-
壓力測試覆蓋度(超峰值流量120%)
-
5 最后
真正的AI架構師不在于掌握多少框架或模型,而在于定義問題的勇氣與創造價值的智慧。當面對傳統企業數字化轉型的困境時,能指出“80%的AI項目失敗源于數據孤島而非算法缺陷”;當團隊沉迷于SOTA模型時,敢于質問“精度提升1%的商業價值是否抵得過30%的算力成本增加??”。這種本質思考力與價值判斷力,才是AI架構師區別于普通開發者的核心特質。

)
)






![正點原子[第三期]Arm(iMX6U)Linux移植學習筆記-12.1 Linux內核啟動流程簡介](http://pic.xiahunao.cn/正點原子[第三期]Arm(iMX6U)Linux移植學習筆記-12.1 Linux內核啟動流程簡介)



:濾鏡命令)





