既有錦繡前程可奔赴,亦有往日歲月可回首
?????????????????????????????????????????????????????? ? ? ? ?—— 25.5.25
選擇排序回顧
① 遍歷數組:從索引?0?到?n-1(n?為數組長度)。
② 每輪確定最小值:假設當前索引?i?為最小值索引?min_index。從?i+1?到?n-1?遍歷,若找到更小元素,則更新?min_index。
③ 交換元素:若?min_index ≠ i,則交換?arr[i]?與?arr[min_index]。
'''
① 遍歷數組:從索引?0?到?n-1(n?為數組長度)。② 每輪確定最小值:假設當前索引?i?為最小值索引?min_index。從?i+1?到?n-1?遍歷,若找到更小元素,則更新?min_index。③ 交換元素:若?min_index ≠ i,則交換?arr[i]?與?arr[min_index]。
'''def selectionSort(arr: List[int]):n = len(arr)for i in range(n):min_index = ifor j in range(i+1, n):if arr[j] < arr[min_index]:min_index = jif min_index != i:arr[i], arr[min_index] = arr[min_index], arr[i]return arr?冒泡排序回顧
① 初始化:設數組長度為?n。
② 外層循環:遍歷?i?從?0?到?n-1(共?n?輪)。
③ 內層循環:對于每輪?i,遍歷?j?從?0?到?n-i-2。
④ 比較與交換:若?arr[j] > arr[j+1],則交換兩者。
⑤ 結束條件:重復步驟 2-4,直到所有輪次完成。
'''
① 初始化:設數組長度為?n。② 外層循環:遍歷?i?從?0?到?n-1(共?n?輪)。③ 內層循環:對于每輪?i,遍歷?j?從?0?到?n-i-1。④ 比較與交換:若?arr[j] > arr[j+1],則交換兩者。⑤ 結束條件:重復步驟 2-4,直到所有輪次完成。
'''
def bubbleSort(arr: List[int]):n = len(arr)for i in range(n):for j in range(n-i-1):if arr[j] > arr[j+1]:arr[j], arr[j+1] = arr[j+1], arr[j]return arr插入排序回顧
① 遍歷未排序元素:從索引?1?到?n-1。
② 保存當前元素:將?arr[i]?存入?current。
③ 元素后移:從已排序部分的末尾(索引?j = i-1)向前掃描,將比?current?大的元素后移。直到找到第一個不大于?current?的位置或掃描完所有元素。
④ 插入元素:將?current?放入?j+1?位置。
'''
① 遍歷未排序元素:從索引 1 到 n-1。② 保存當前元素:將 arr[i] 存入 current。③ 元素后移:從已排序部分的末尾(索引 j = i-1)向前掃描,將比 current 大的元素后移。直到找到第一個不大于 current 的位置或掃描完所有元素。④ 插入元素:將 current 放入 j+1 位置。
'''
def insertSort(arr: List[int]):n = len(arr)for i in range(n):current = arr[i]j = i - 1while current < arr[j] and j >0:arr[j+1] = arr[j]j -= 1arr[j + 1] = currentreturn arr計數排序回顧
①?初始化:設數組長度為?n,元素最大值為?r。創建長度為?r+1?的計數數組?count,初始值全為 0。
② 統計元素頻率:遍歷原數組?arr,對每個元素?x,將?count[x]?加 1。
③?重構有序數組:初始化索引?index = 0。遍歷計數數組?count,索引?v?從 0 到?r,若?count[v] > 0,則將?v?填入原數組?arr[index],并將?index?加 1。count[v] - 1,重復此步驟直到?count[v]?為 0。
④ 結束條件:當計數數組遍歷完成時,排序結束。
'''
輸入全為非負整數,且所有元素 ≤ r①?初始化:設數組長度為?n,元素最大值為?r。創建長度為?r+1?的計數數組?count,初始值全為 0。② 統計元素頻率:遍歷原數組?arr,對每個元素?x,將?count[x]?加 1。③?重構有序數組:初始化索引?index = 0。遍歷計數數組?count,索引?v?從 0 到?r,
若?count[v] > 0,則將?v?填入原數組?arr[index],并將?index?加 1。
count[v] - 1,重復此步驟直到?count[v]?為 0。④ 結束條件:當計數數組遍歷完成時,排序結束。
'''def countingSort(arr: List[int], r: int):# count = [0] * len(r + 1)count = [0 for i in range(r + 1)]for x in arr:count[x] += 1index = 0for v in range(r + 1):while count[v] > 0:arr[index] = vindex += 1count[v] -= 1return arr歸并排序回顧
Ⅰ、遞歸分解列表
① 終止條件:若鏈表為空或只有一個節點(head is None?或?head.next is None),直接返回頭節點。
②?快慢指針找中點:初始化?slow?和?fast?指針,slow?指向頭節點,fast?指向頭節點的下一個節點。fast?每次移動兩步,slow?每次移動一步。當?fast?到達末尾時,slow?恰好指向鏈表的中間節點。
③?分割鏈表:將鏈表從中點斷開,head2?指向?slow.next(后半部分的頭節點)。將?slow.next?置為?None,切斷前半部分與后半部分的連接。
④?遞歸排序子鏈表:對前半部分(head)和后半部分(head2)分別遞歸調用?mergesort?函數。
Ⅱ、合并兩個有序列表
① 創建虛擬頭節點:創建一個值為?-1?的虛擬節點?zero,用于簡化邊界處理。使用?current?指針指向?zero,用于構建合并后的鏈表。
②?比較并合并節點:遍歷兩個子鏈表?head1?和?head2,比較當前節點的值:若?head1.val <= head2.val,將?head1?接入合并鏈表,并移動?head1?指針。否則,將?head2?接入合并鏈表,并移動?head2?指針。每次接入節點后,移動?current?指針到新接入的節點。
③?處理剩余節點:當其中一個子鏈表遍歷完后,將另一個子鏈表的剩余部分直接接入合并鏈表的末尾。
④?返回合并后的鏈表:虛擬節點?zero?的下一個節點即為合并后的有序鏈表的頭節點。
'''
Ⅰ、遞歸分解列表① 終止條件:若鏈表為空或只有一個節點(head is None?或?head.next is None),直接返回頭節點。②?快慢指針找中點:初始化?slow?和?fast?指針,slow?指向頭節點,fast?指向頭節點的下一個節點。fast?每次移動兩步,slow?每次移動一步。當?fast?到達末尾時,slow?恰好指向鏈表的中間節點。③?分割鏈表:將鏈表從中點斷開,head2?指向?slow.next(后半部分的頭節點)。將?slow.next?置為?None,切斷前半部分與后半部分的連接。④?遞歸排序子鏈表:對前半部分(head)和后半部分(head2)分別遞歸調用?mergesort?函數。Ⅱ、合并兩個有序列表① 創建虛擬頭節點:創建一個值為?-1?的虛擬節點?zero,用于簡化邊界處理。使用?current?指針指向?zero,用于構建合并后的鏈表。②?比較并合并節點:遍歷兩個子鏈表?head1?和?head2,比較當前節點的值:若?head1.val <= head2.val,將?head1?接入合并鏈表,并移動?head1?指針。否則,將?head2?接入合并鏈表,并移動?head2?指針。每次接入節點后,移動?current?指針到新接入的節點。③?處理剩余節點:當其中一個子鏈表遍歷完后,將另一個子鏈表的剩余部分直接接入合并鏈表的末尾。④?返回合并后的鏈表:虛擬節點?zero?的下一個節點即為合并后的有序鏈表的頭節點。
'''
def mergesort(self, head: ListNode):if head is None or head.next is None:return headslow, fast = head, head.nextwhile fast and fast.next:slow = slow.nextfast = fast.next.nexthead2 = slow.nextslow.next = Nonereturn self.merge(self.mergesort(head), self.mergesort(head2))def merge(self, head1: ListNode, head2: ListNode):zero = ListNode(-1)current = zerowhile head1 and head2:if head1.val <= head2.val:current.next = head1head1 = head1.nextelse:current.next = head2head2 = head2.nextcurrent = current.nextcurrent.next = head1 if head1 else head2return zero.next一、引言
????????快速排序(Quick Sort)是一種分而治之的排序算法。它通過選擇一個基準元素,將數組分為兩部分,一部分的元素都比基準小,另一部分的元素都比基準大,然后對這兩部分再進行快速排序,最終得到有序的數組。
二、算法思想?
? ? ? ? ① 選擇基準元素:從數組中隨機選擇一個元素作為基準。將基準元素放在數組的最左邊。
? ? ? ? ② 分割數組:從頭遍歷數組,將比基準小的元素放在基準的左邊,比基準大的元素放在基準的右邊。
? ? ? ? ③ 遞歸排序:對基準左邊和右邊的子數組分別進行快速排序。
? ? ? ? ④ 重復步驟 ①?至 ③:直到子數組的長度為 1 或 0。
? ? ? ? 首先隨機選擇了一個數字作為【基準數】,并且將它和最左邊的數交換,然后依次遍歷,小于這個數字的值存儲在一起,大于這個數字的值存儲在一起,遍歷完畢后,將這個【基準數】和下標最大的那個比【基準數】小的數字交換位置,至此,這個 、基準數左邊位置上的數都小于它,右邊位置上的數字都大于它,左邊與右邊兩部分數字繼續遞歸求解即可
三、算法分析
1.時間復雜度
最優情況:當每次選擇的基準元素正好將數組分成兩等分時,快速排序的時間復雜度是 O(n*logn)?
最壞情況:當每次選擇的基準元素是最大或最小元素時,快速排序的時間復雜度是 O(n^2)
平均情況:在平均情況下,快速排序的時間復雜度也是 O(n*logn)
2.空間復雜度
????????快速排序的空間復雜度是 O(logn),因為在遞歸調用中需要使用棧來存儲中間結果。這意味著在排序過程中,最多需要 O(logn) 的額外空間來保存遞歸調用的棧幀。
3.算法的優點
①?高效性:快速排序在大多數情況下具有較高的排序效率。
② 適應性:適用于各種數據類型的排序。
③ 原地排序:不需要額外的存儲空間。
4.算法的缺點
① 最壞情況性能:在最壞情況下,快速排序的時間復雜度可能退化為 O(n^2)。
② 不穩定性:快速排序可能會破壞排序的穩定性,即相同元素的相對順序可能會改變
四、實戰練習
217. 存在重復元素
給你一個整數數組?
nums?。如果任一值在數組中出現?至少兩次?,返回?true?;如果數組中每個元素互不相同,返回?false?。示例 1:
輸入:nums = [1,2,3,1]
輸出:true
解釋:
元素 1 在下標 0 和 3 出現。
示例 2:
輸入:nums = [1,2,3,4]
輸出:false
解釋:
所有元素都不同。
示例 3:
輸入:nums = [1,1,1,3,3,4,3,2,4,2]
輸出:true
提示:
1 <= nums.length <= 105-109 <= nums[i] <= 109
思路與算法
Ⅰ、分區函數 Partition
① 隨機選擇基準元素:根據左右邊界下標隨機選擇基準元素(選擇的是元素并非下標),將基準元素賦值變量進行后續比較
② 交換基準元素:將基準元素移動到最左邊,將基準元素存儲在變量中,
③ 分區操作:對于基準元素右邊的元素,找到第一個小于基準元素的值,移動到最左邊;對于基準元素左邊的元素,找到第一個大于基準元素的值,移動到最右邊
④ 返回基準元素的最終位置:循環執行完畢后,基準元素左邊的值都小于它,基準元素右邊的值都大于它
Ⅱ、遞歸排序函數
① 定義遞歸終止條件:當左索引小于右索引時,結束遞歸
② 分區操作:?執行第一次分區操作,找到基準元素
③ 遞歸調用分區函數:將基準元素的左邊、右邊部分分別傳入遞歸函數進行排序
Ⅲ、驗證是否存在重復元素?
① 排序數組:將數組傳入快速排序的實現中,返回排好序的數組
② 遍歷數組,尋找是否存在重復元素:遍歷數組,如果發現相鄰兩個元素相等,則返回True,否則遍歷完數組后,返回False
class Solution:def Partition(self, arr: List, left, right):index = random.randint(left, right)arr[left], arr[index] = arr[index], arr[left]i = leftj = rightx = arr[i]while i < j:while i < j and arr[j] > x:j -= 1if i < j:arr[i], arr[j] = arr[j], arr[i]i += 1while i < j and arr[i] < x:i += 1if i < j:arr[i], arr[j] = arr[j], arr[i]j -= 1return idef quickSort(self, arr: List, left: int, right: int) -> List[int]: if left >= right:returnnode = self.Partition(arr, left, right)self.quickSort(arr, left, node - 1)self.quickSort(arr, node + 1, right)def containsDuplicate(self, nums: List[int]) -> bool:n = len(nums)self.quickSort(nums, 0, n - 1)for i in range(1, n):if nums[i] == nums[i - 1]:return Truereturn False 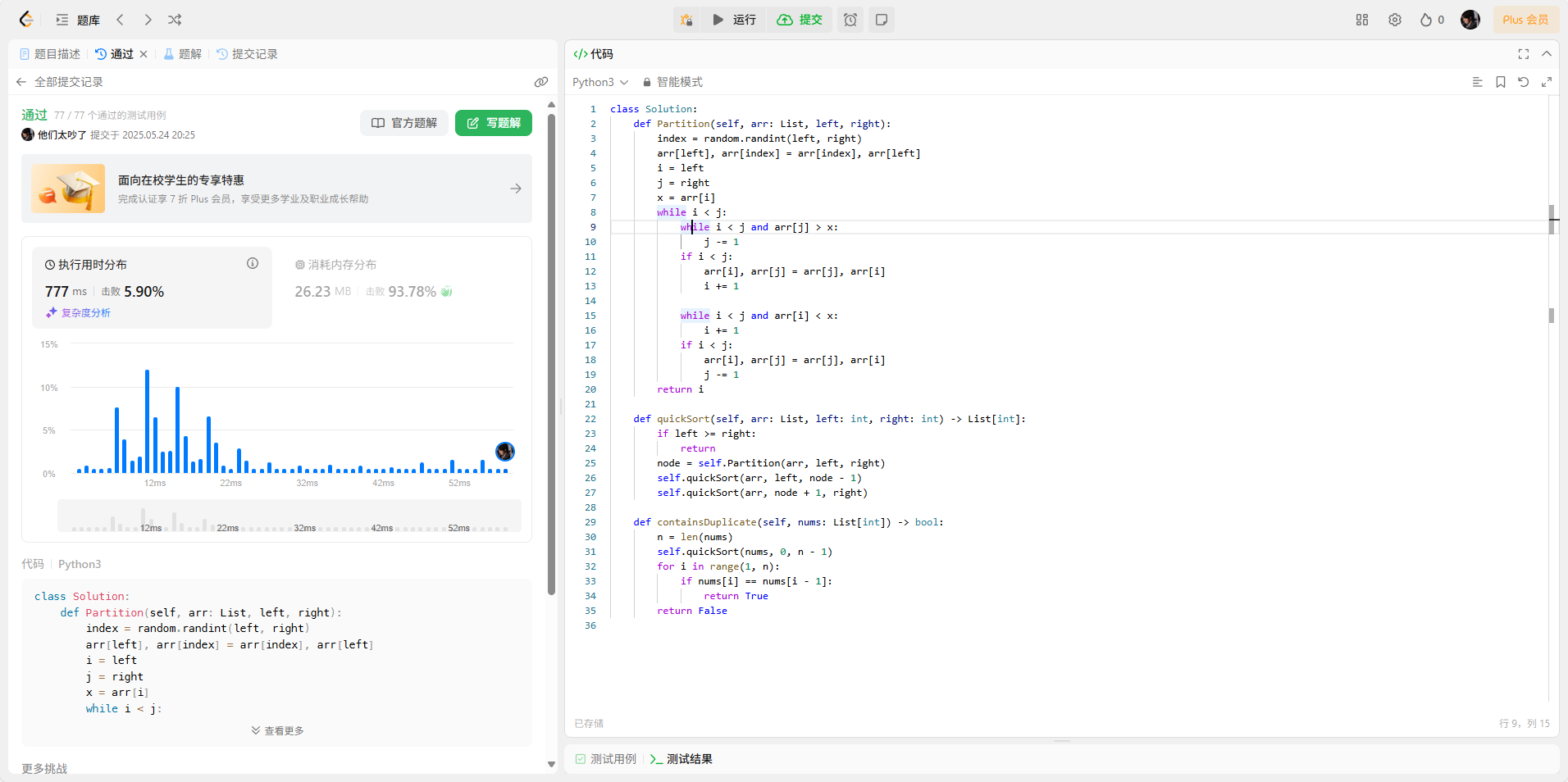
169. 多數元素
給定一個大小為?
n?的數組?nums?,返回其中的多數元素。多數元素是指在數組中出現次數?大于?? n/2 ??的元素。你可以假設數組是非空的,并且給定的數組總是存在多數元素。
示例?1:
輸入:nums = [3,2,3] 輸出:3示例?2:
輸入:nums = [2,2,1,1,1,2,2] 輸出:2提示:
n == nums.length1 <= n <= 5 * 104-109 <= nums[i] <= 109進階:嘗試設計時間復雜度為 O(n)、空間復雜度為 O(1) 的算法解決此問題。
思路與算法
Ⅰ、分區函數 Partition
① 隨機選擇基準元素:根據左右邊界下標隨機選擇基準元素
② 交換基準元素:將基準元素移動到最左邊
③ 分區操作:對于基準元素右邊的元素,找到第一個小于基準元素的值,移動到最左邊;對于基準元素左邊的元素,找到第一個大于基準元素的值,移動到最右邊
④ 返回基準元素的最終位置:循環執行完畢后,基準元素左邊的值都小于它,基準元素右邊的值都大于它
Ⅱ、遞歸排序函數
① 定義遞歸終止條件:當左索引小于右索引時,結束遞歸
② 分區操作:?執行第一次分區操作,找到基準元素
③ 遞歸調用分區函數:將基準元素的左邊、右邊部分分別傳入遞歸函數進行排序
Ⅲ、在排好序的數組中返回多數元素
① 排序數組:將數組傳入實現的快速排序函數中,返回已排序的數組?
② 返回多數元素:因為題目中保證一定存在多數元素,所以排序好的數組中,多數一定是多數元素,所以直接返回排序后數組中間位置的值即可
class Solution:def Partition(self, arr: List, left, right):index = random.randint(left, right)arr[left], arr[index] = arr[index], arr[left]i = leftj = rightx = arr[i]while i < j:while i < j and arr[j] > x:j -= 1if i < j:arr[i], arr[j] = arr[j], arr[i]i += 1while i < j and arr[i] < x:i += 1if i < j:arr[i], arr[j] = arr[j], arr[i]j -= 1return idef quickSort(self, arr: List, left: int, right: int) -> List[int]: if left >= right:returnnode = self.Partition(arr, left, right)self.quickSort(arr, left, node - 1)self.quickSort(arr, node + 1, right)def majorityElement(self, nums: List[int]) -> int:n = len(nums)self.quickSort(nums, 0, n - 1)return nums[n//2]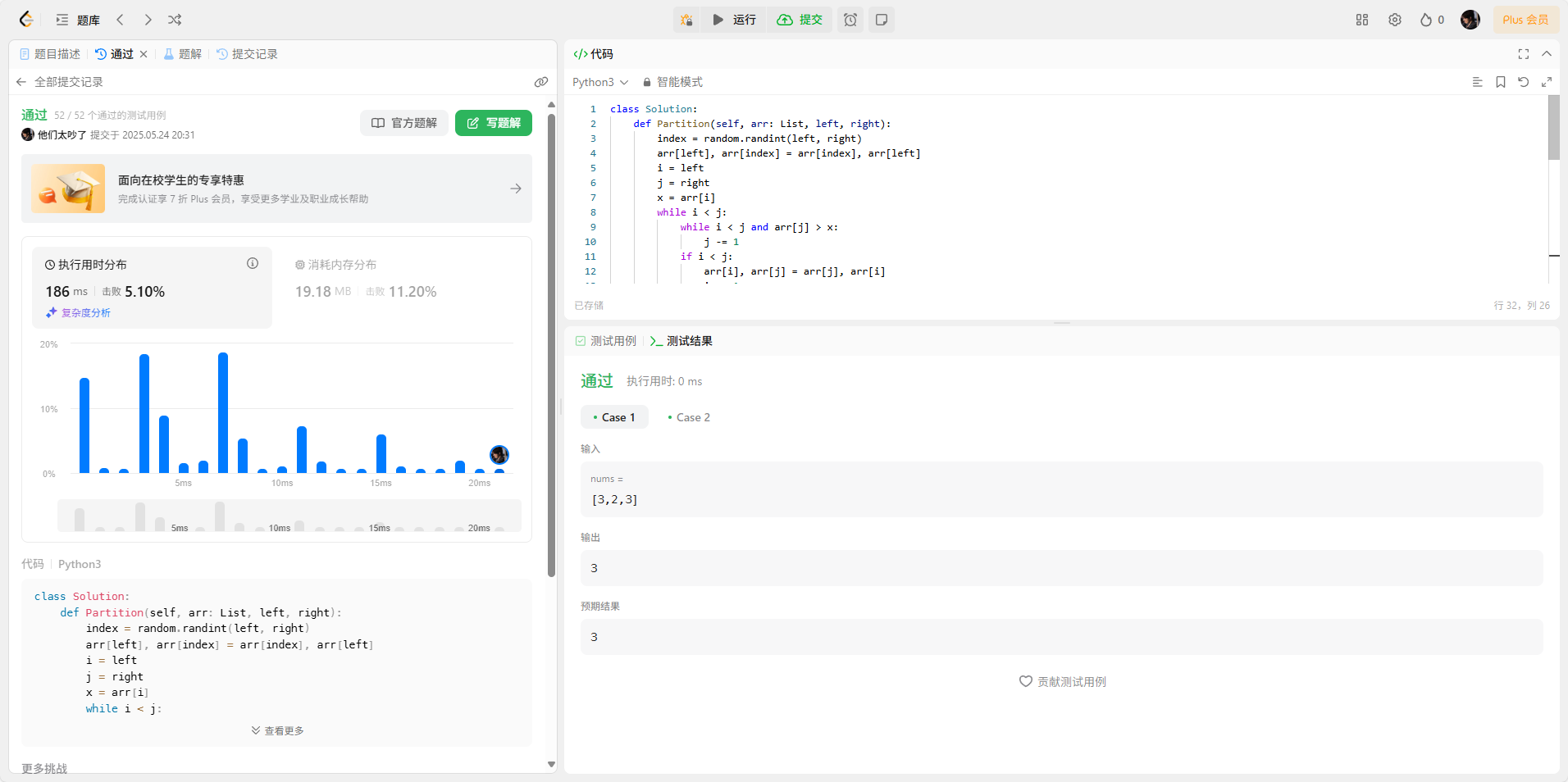





攻擊 ?)


)

)


)
)



:[macOS 64bit App開發]: TTask創建多線程, 更簡單, 更快捷.](http://pic.xiahunao.cn/[原創](現代Delphi 12指南):[macOS 64bit App開發]: TTask創建多線程, 更簡單, 更快捷.)
