zset
- 一. zset 類型介紹
- 二. zset 命令
- zadd
- zcard、zcount
- zrange、zrevrange、zrangebyscore
- zpopmax、zpopmin
- zrank、zrevrank、zscore
- zrem、zremrangebyrank、zremrangebyscore
- zincrby
- 阻塞版本命令:bzpopmax、bzpopmin
- 集合間操作:zinterstore、zunionstore
- 三. zset 命令小結
- 四. zset 內部編碼方式
- 五. zset 使用場景
- 排行榜系統
一. zset 類型介紹
- zset (有序集合):相對于字符串、列表、哈希、集合來說會有一些陌生。它保留了集合不能有重復成員的特點,但與集合不同的是,有序集合中的每個元素都有一個唯一的浮點類型的分數 (score) 與之關聯,著使得有序集合中的元素是可以維護有序性的,但這個有序不是用下標作為排序依據而是用這個分數。
如下圖所示,該有序集合顯示了三國中的武將的武力。
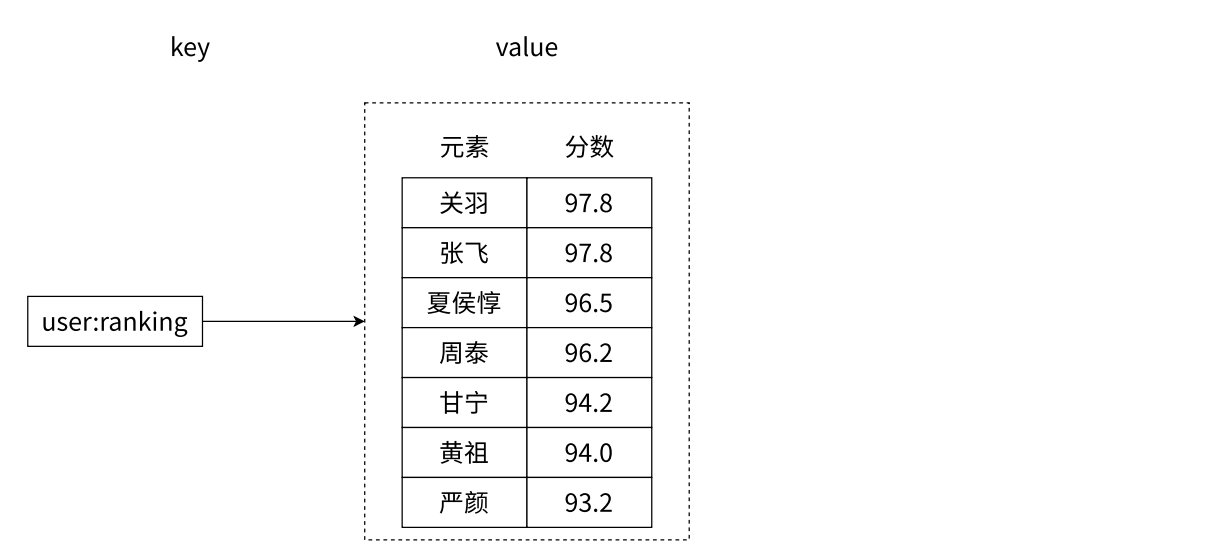
- 有序集合提供了獲取指定分數和元素范圍查找、計算成員排名等功能,合理地利用有序集合,可以幫助我們在實際開發中解決很多問題。
- 有序集合中的元素是不能重復的,但分數允許重復。類比于一次考試之后,每個人一定有一個唯一的分數,但分數允許相同
- 排序規則:分數不同時按照分數進行排序,分數相同時按照字典序進行排序,實際上 zset 內部就是按照升序方式來進行排序的。
列表、集合、有序集合三者的異同點,如下:
| 數據結構 | 是否允許重復元素 | 是否有序 | 有序依據 | 應用場景 |
|---|---|---|---|---|
| list | 是 | 是 | 索引下標 | 時間軸、消息隊列等 |
| set | 否 | 否 | 標簽、社交等 | |
| zset | 否 | 是 | 分數 | 排行榜系統、社交等 |
注意:list 的有序指的是按照某種順序,而 zset 的有序指的是升序/降序。
二. zset 命令
zadd
- zadd:添加或者更新指定的元素以及關聯的分數到 zset 中,分數應該符合 double 類型,+inf/-inf 作為正負極限也是合法的。
- 添加的時候:既要添加元素,又要添加分數;member 和 score 稱為一個 “pair”,不要把 member 和 score 理解成 “鍵值對” (key-value pair)
- 鍵值對中存在明確的角色區分,誰是鍵誰是值是明確的,一定是根據鍵找對應的值。
- 對于 zset 來說,既可以通過 member 找到對應的 score;又可以通過 score 找到匹配的 member;
- 語法:
zadd key [NX|XX] [CH] [INCR] score member [score member ...]- 不加 XX | NX:如果當前 member 不存在,此時就會達到添加新 member 的效果;如果當前 member 已經存在,此時就會達到更新 member 對應 score 的效果。
- 加上 XX:僅僅用于更新已經存在的 member 對應 score 的效果,不會添加新 member
- 加上 NX:僅僅用于添加 member 的效果,不會更新已經存在的 member 對應的 score
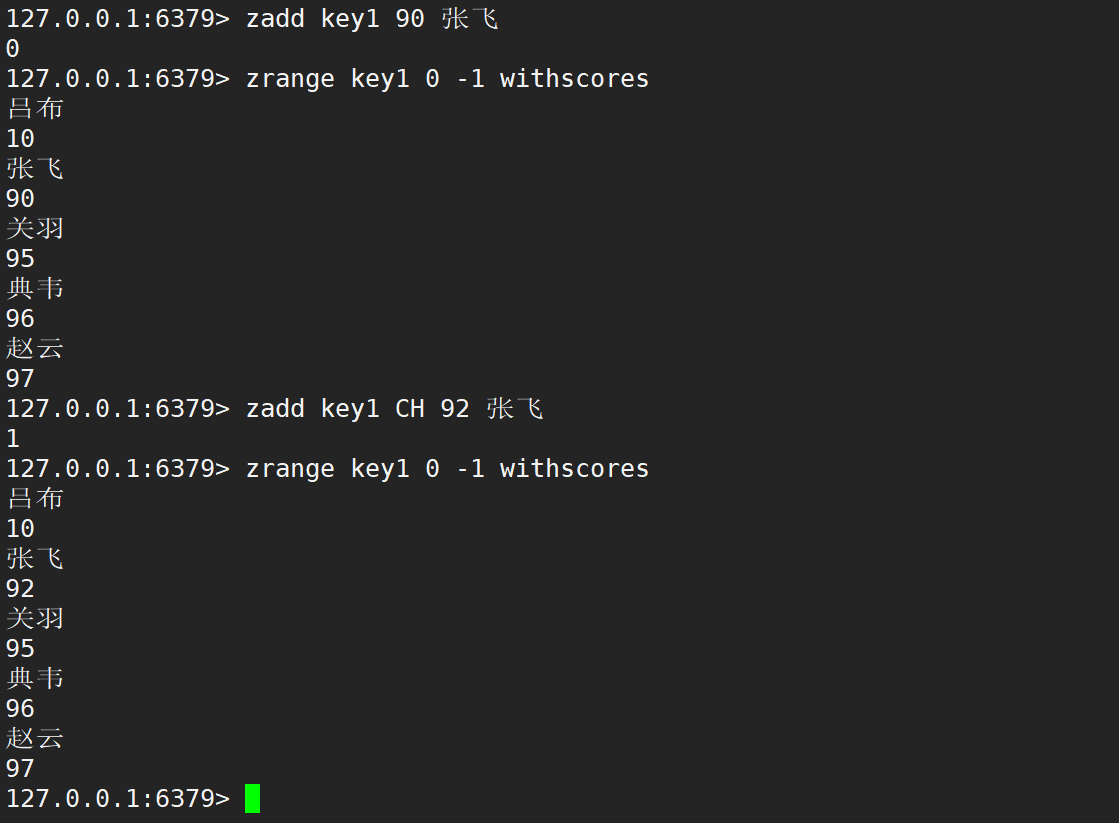
- CH:默認情況下,zadd 返回的是本次添加的元素個數,但指定這個選項之后,就會還包含本次更新的元素的個數。
- INCR:此時命令類似 zincrby 的效果,將元素的分數加上指定的分數。此時只能指定?個元素和分數。
- 不加 XX | NX:如果當前 member 不存在,此時就會達到添加新 member 的效果;如果當前 member 已經存在,此時就會達到更新 member 對應 score 的效果。
- 時間復雜度:O(logN),N 是有序集合中元素的個數。
- 之前 hash、list、set 添加一個元素,都是 O(1)
- 由于 zset 是有序結構,要求新增的元素放在合適的位置,之所以是 O(logN),就是充分利用了有序這樣的特點 (zset 內部的數據結構主要是跳表)
- 返回值:本次添加成功的元素個數。
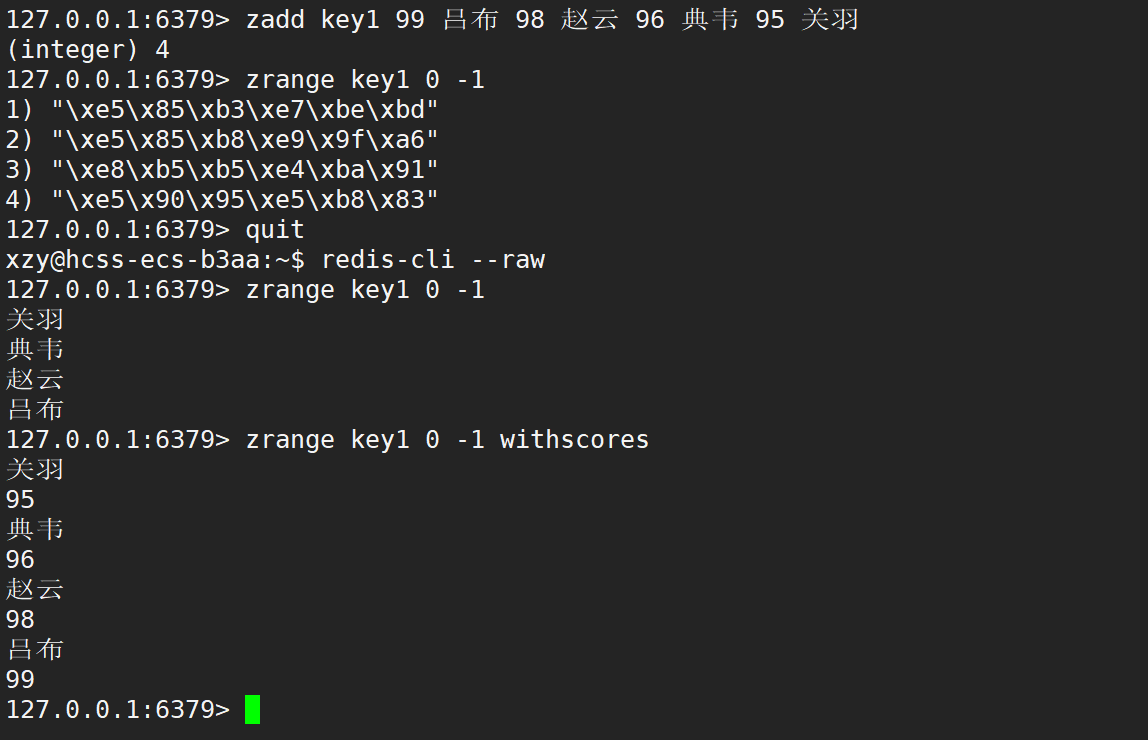
Redis 內部存儲數據的時候,是按照二進制的方式來存儲的,這就意味著,Redis 服務器不負責 “字符編碼” 的,要把二進制字節轉回到漢字,還需要客戶端來支持,登入 Redis 客戶端時的命令 redis-cli --raw
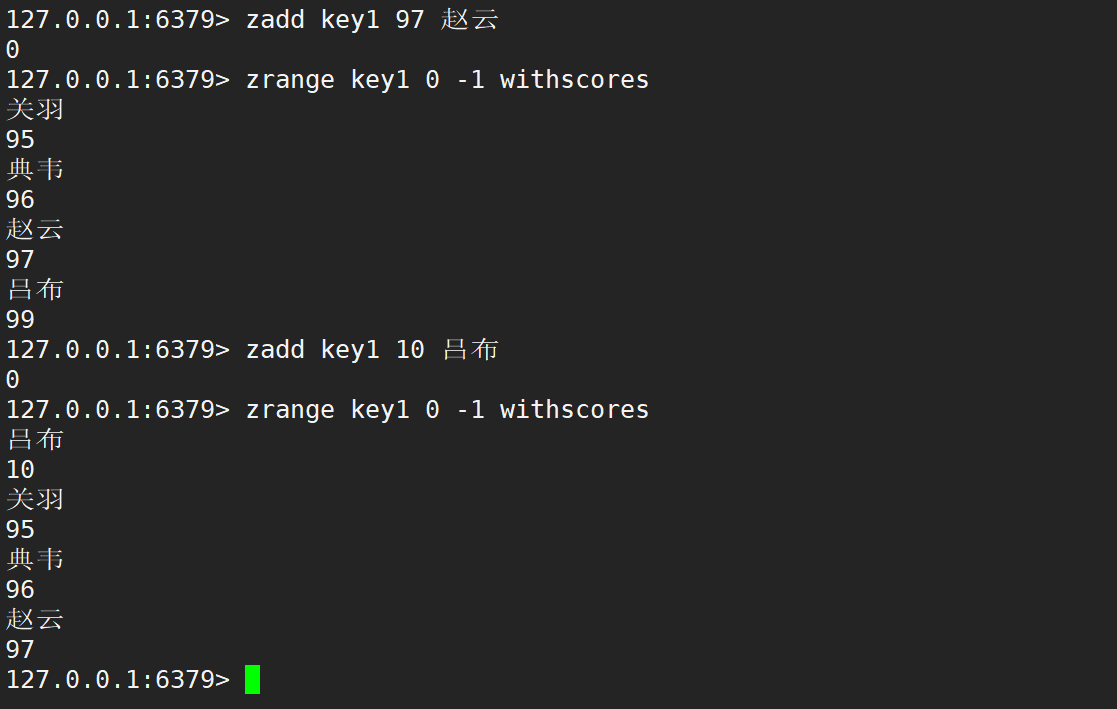
如果修改的分數,影響到了之前的順序,就會自動移動元素的位置,保持原有的升序順序不變。
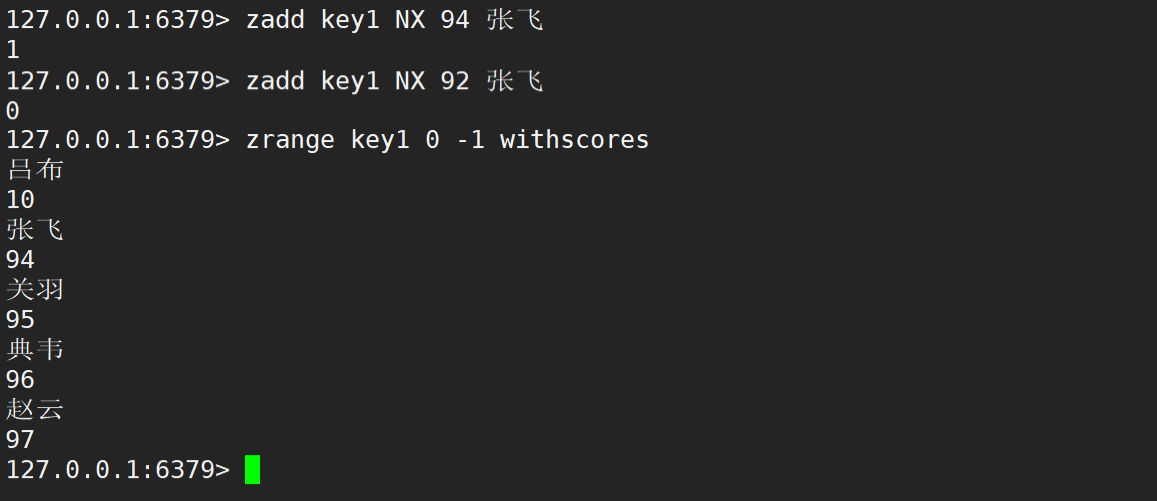
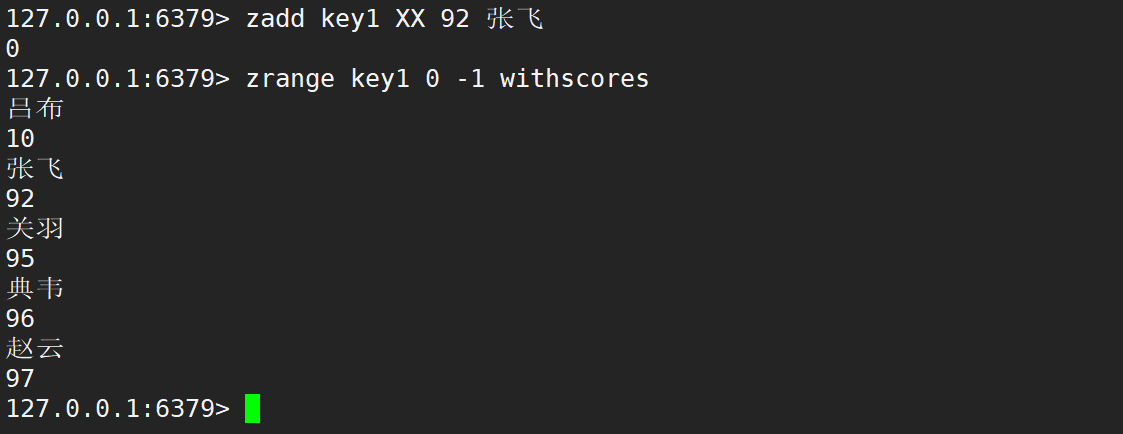
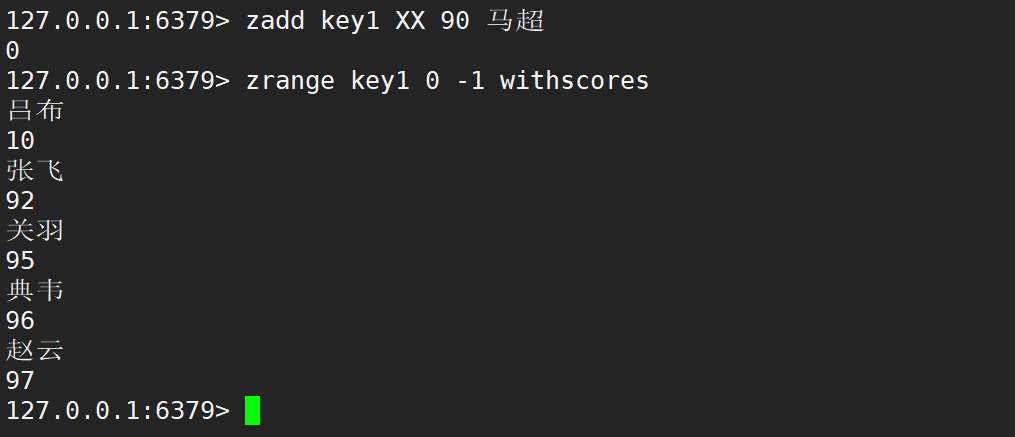
zadd 在默認情況下,返回值就是新增成功的元素個數。若更新時不存在元素,則更新失敗。
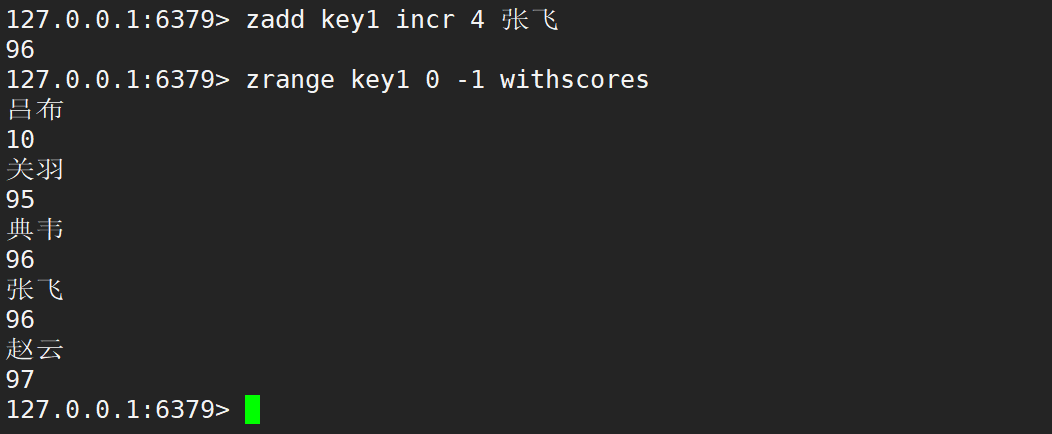
添加 incr 修改 member 的 score 時,后面只能跟一個 member,且返回值是 member 之后的 score
- C++ 中 std::set 存儲的元素 (key-value) 的 key 是有序的,但是這里的 key 是不能修改的。
- Redis 中 zset 的 member 是可以修改的,修改之后 score 仍然要排序,滿足有序。
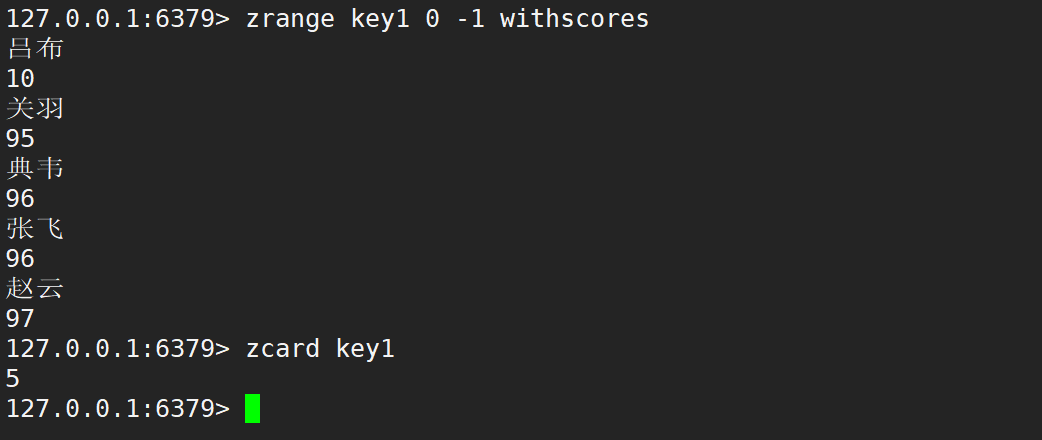
zcard、zcount
- zcard:獲取?個 zset 的基數 (cardinality),即 zset 中的元素 member 的個數。
- 語法:
zcard key - 時間復雜度:O(1)
- 返回值:zset 內的元素個數。
- zcount:返回分數在 min 和 max 之間的元素個數,默認情況下,min 和 max 都是包含的。但是可以通過 ( 進行排除。
- 語法:
zcount key min max - 時間復雜度:O(logN)
- 先根據 min 找到對應的元素,再根據 max 找到對應的元素,是 O(logN)
- 如果區間中元素比較多,此時就需要進行遍歷,時間復雜度:O(logN + M),N 是 zset 中元素的個數,M 是區間中元素的個數。
- 實際 zset 內部,會記錄每個元素當前 “排行”/“次序”,查詢到元素,就直接知道了元素所在的 “次序” (下標),就可以直接把 max 對應的元素次序和 min 對應的元素次序,做差即可得出結果。
- 返回值:滿足條件的元素列表個數。
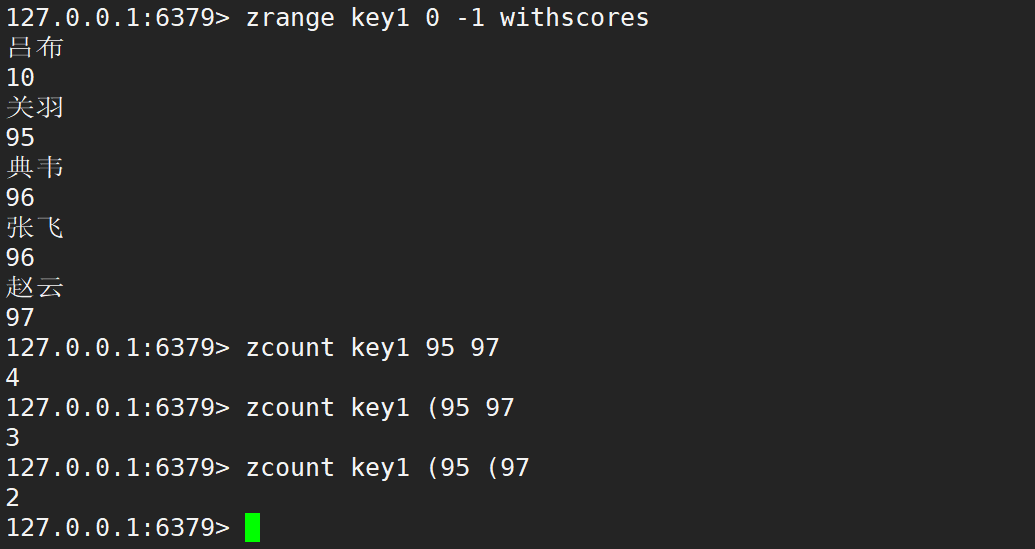
- 使用 ( 表示開區間,[ 表示閉區間,默認是一個閉區間,但是此處的寫法比較奇葩。
- 一個好的設計,是符合直覺的,越符合直覺,學習成本就越低,既然已經這么設定了,只能遵循這樣的規則。后面想要修改很難,需要考慮兼容性。
- 廣泛使用的軟件,一但在新版本中,引入和之前不兼容的特性,成本是非常高的。
- 考慮兼容性的案例:C++ 兼容 C 語言。
- 不考慮兼容性的案例:IPV6 不兼容 IPV4
- 一般來說,確實需要做出這種不兼容的修改,可以先把這個要修改的內容,標記成 “棄用”,給程序員打個預防針,同時推出新版本的方案。
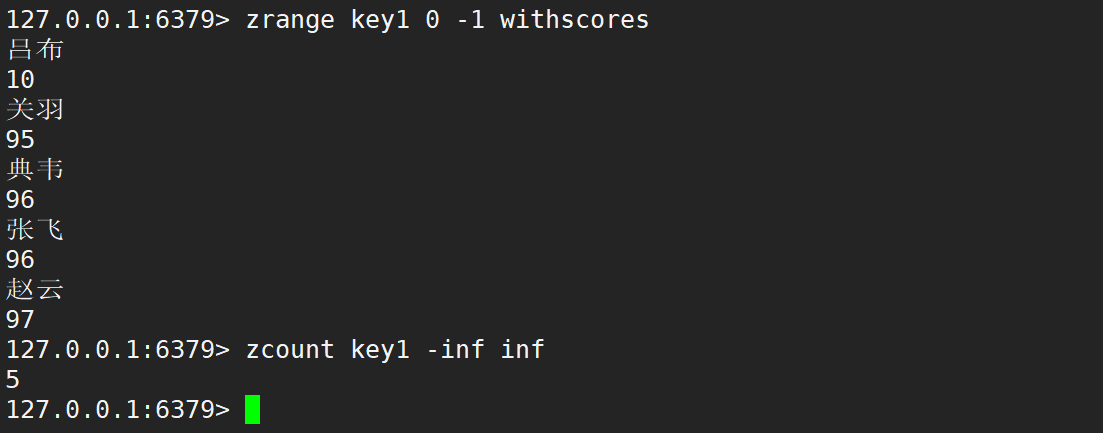
- min 和 max 是可以寫成浮點數 (zset 分數本身就是浮點數),在浮點數中,存在兩個特殊的數值:-inf 負無窮大,inf 無窮大,zset 分數也是支持使用 -inf 和 inf 作為 min 和 max 的。
- 注意:負無窮大不是無窮小,而無窮小指的是無限趨近于 0 的數。
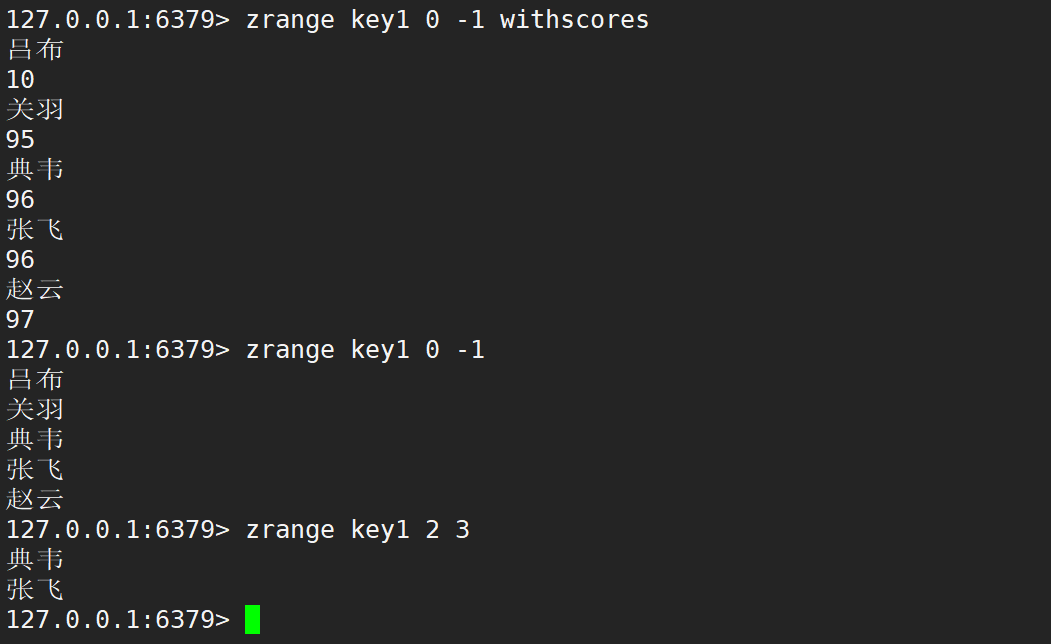
zrange、zrevrange、zrangebyscore
- zrange:返回指定區間里的元素,分數按照升序。帶上 WITHSCORES 可以把分數也返回。
- 語法:
zrange key start stop [WITHSCORES] - 時間復雜度:O(logN + M),N 是 zset 中元素的個數,M 是區間中元素的個數。
- 返回值:區間內的元素列表。
- zrevrange:返回指定區間里的元素,分數按照降序。帶上 WITHSCORES 可以把分數也返回。
- 語法:
zrevrange key start stop [WITHSCORES] - 時間復雜度:O(logN + M),N 是 zset 中元素的個數,M 是區間中元素的個數。
- 返回值:區間內的元素列表。
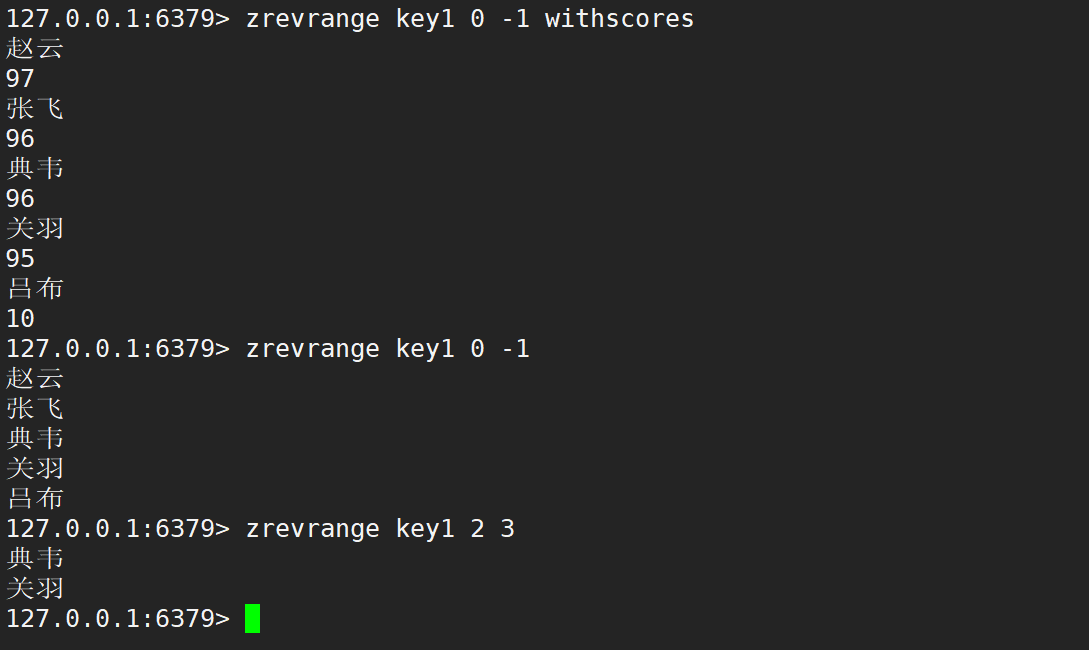
注意:第一個元素的下標是 0,最后一個元素的下標是 len - 1,也可以使用 -1 代替,且 zrevrange 的區間和 zrange 的區間兩個參數的順序是一樣的,即二者區間的使用是一樣的,只不過得出結果的順序不一樣。
- zrangebyscore:返回分數在 min 和 max 之間的元素個數,默認情況下,min 和 max 都是包含的。但是可以通過 ( 進行排除。和 zcount 類似。
- 語法:
zrangebyscore key min max [WITHSCORES] [LIMIT offset count]- WITHSCORES:將分數也返回。
- LIMIT offset count:從偏移量 offset 開始,返回 count 個元素。
- 時間復雜度:O(logN + M),N 是 zset 中元素的個數,M 是區間中元素的個數。
- 返回值:區間內的元素列表。
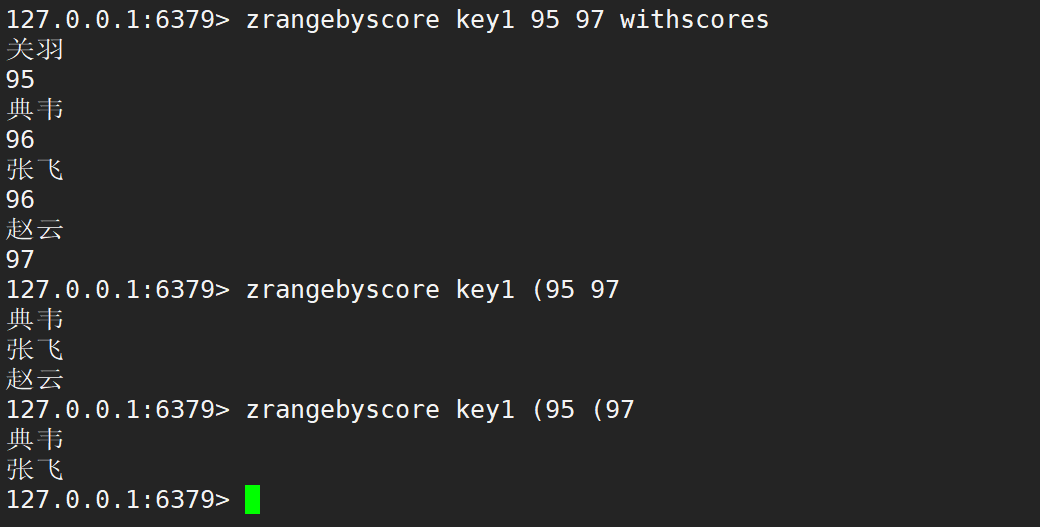

注意:zrevrange、zrangebyscore 這兩個命令在 Redis 6.2.0 之后廢棄,并且功能合并到 zrange 中。
zpopmax、zpopmin
- zpopmax:刪除并返回分數最高的 count 個元素。
- 語法:
zpopmax key [count] - 時間復雜度:O(logN * M),N 是 zset 的元素個數,M 是要刪除的元素個數。
- 此處在有序集合刪除最大值,就相當于最后一個元素 (尾刪),既然是尾刪,為什么我們不把這個最后一個元素的位置特殊記錄下來,后續刪除不就可以做到 O(1) 了嘛?省去了查找過程,但是 Redis 并沒有這么做。
- 事實上 Redis 源碼中,針對有序集合,確實記錄了尾部這樣的特點位置,但是實際刪除的時候,并沒有用上這個特性,而是直接調用了一個 “通用的刪除函數”,給點一個 member 的值,進行查找,找到位置之后再刪除。
- 雖然存在這樣的優化空間,但是未來真的會這么優化,也不好說。優化這種活,要優化到刀刃上,優化一般是要先找到性能瓶頸,再針對性的進行優化。
- 因為當前的這個 logN 的速度其實是不慢的,如果 N 不是非常夸張的大,基本可以近似看作 O(1) 的。
- 返回值:分數和元素列表。
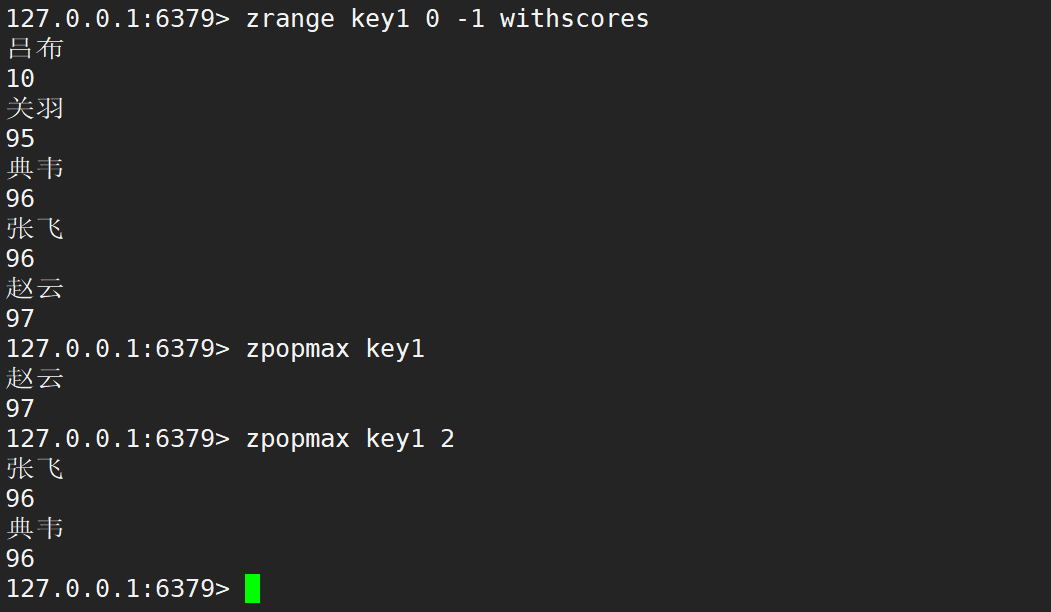
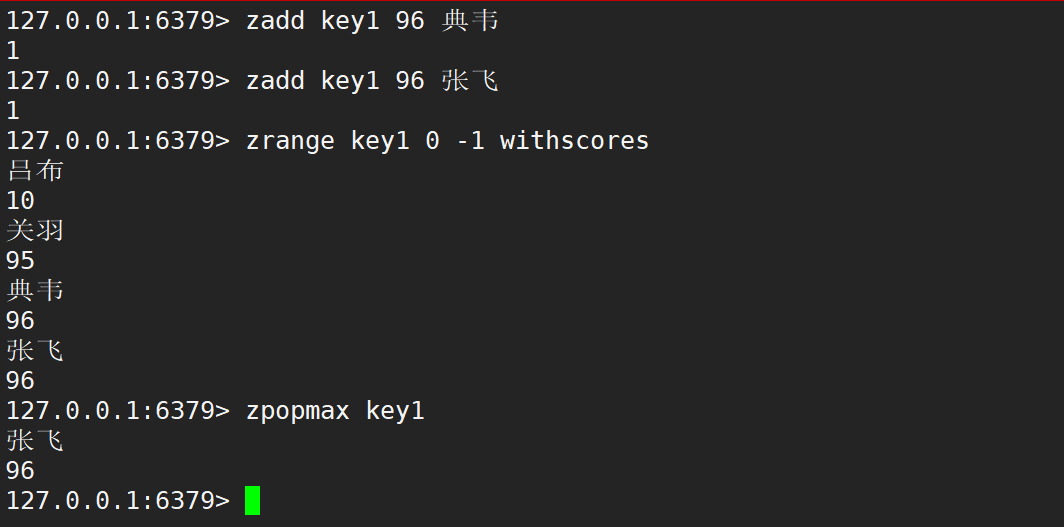
如果存在多個元素的分數相同,同時為最大值時,zpopmax 刪除的時候,仍然值刪除其中一個元素,會按照 member 字符串的字典序決定刪除的先后順序。
- zpopmin:刪除并返回分數最低的 count 個元素。
- 語法:
zpopmin key [count] - 時間復雜度:O(logN * M),N 是 zset 的元素個數,M 是要刪除的元素個數。
- 此處的 zpopmin 和 zpopmax 的邏輯是一樣的 (同一個函數實現的),雖然 Redis 的有序集合記錄了開頭的元素,但是刪除的時候,使用的是通用的刪除函數,導致出現了重新查找的過程。
- 返回值:分數和元素列表。
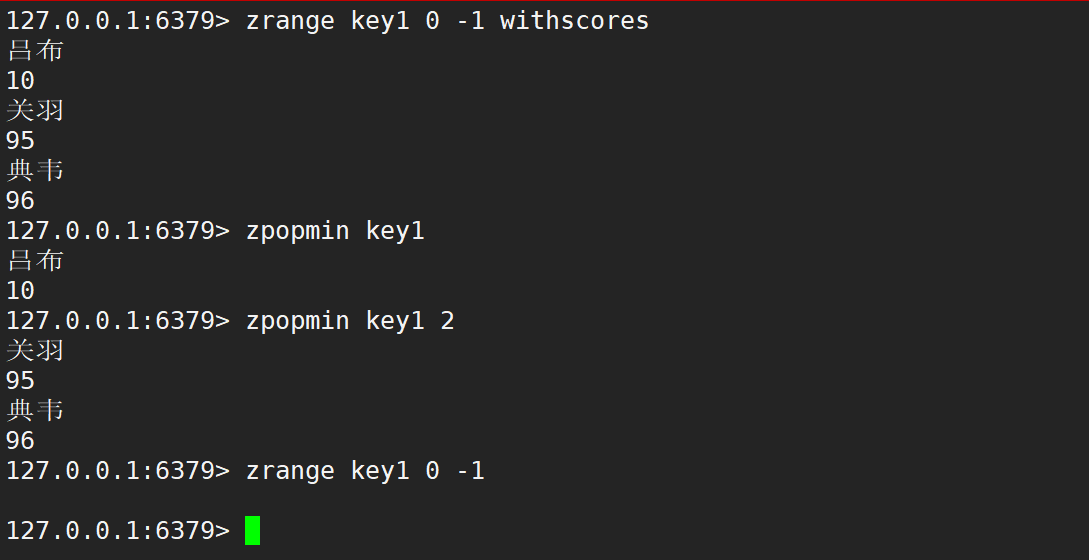
zrank、zrevrank、zscore
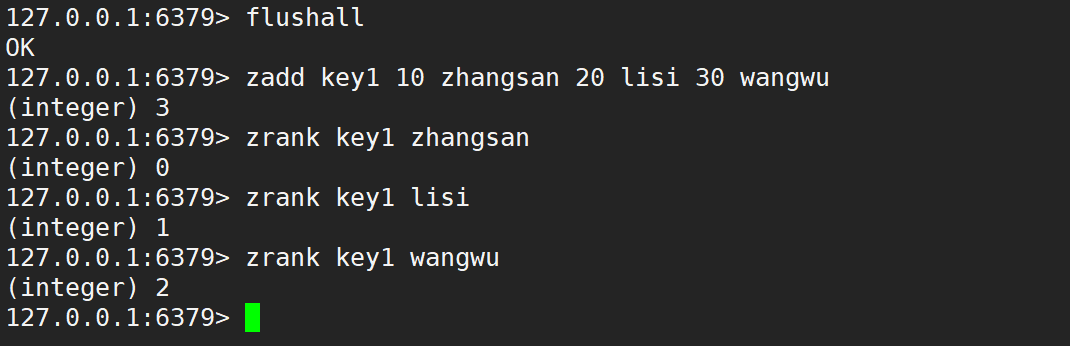
- zrank:返回指定元素的排名 (類似下標),升序。
- 語法:
zrank key member - 時間復雜度:O(logN)
- 返回值:排名。
在 zcount 計算的時候,就是先根據分數找到元素,再根據元素獲取到排名,最后把排名相減,就可以得到區間中元素的個數。
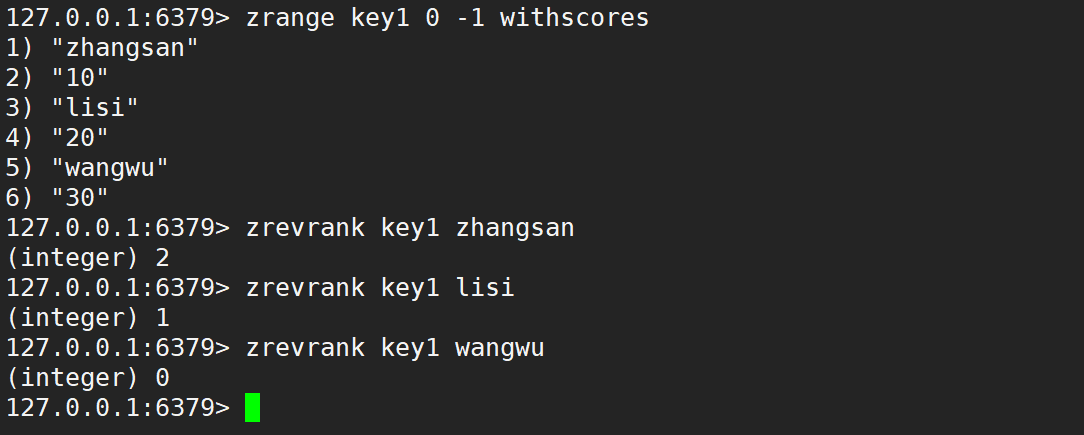
- zrevrank:返回指定元素的排名 (類似下標),降序。
- 語法:
zrevrank key member - 時間復雜度:O(logN)
- 返回值:排名。
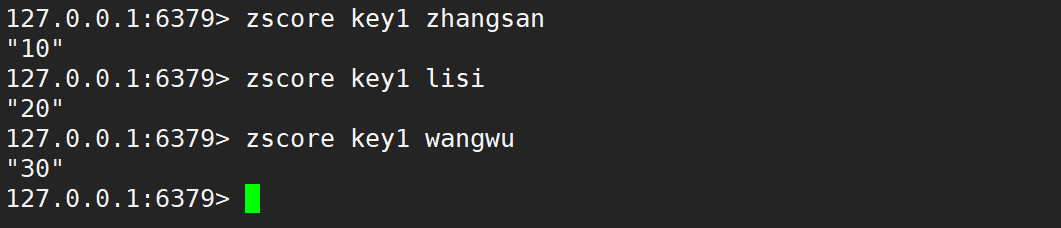
- zscore:查詢指定元素的分數。
- 語法:
zscore key member - 時間復雜度:O(1)
- 前面根據 member 找元素,都是 O(logN),這里也是先要找元素,為什么是 O(1)?此處相當于 Redis 對應這樣的查詢操作做了特殊優化,付出了額外的空間代價。
- 返回值:分數。
zrem、zremrangebyrank、zremrangebyscore
- zrem:刪除指定的元素。
- 語法:
zrem key member [member ...] - 時間復雜度:O(logN * M),N 是 zset 的元素個數,M 是要刪除的元素個數。
- 返回值:本次操作刪除的元素個數。
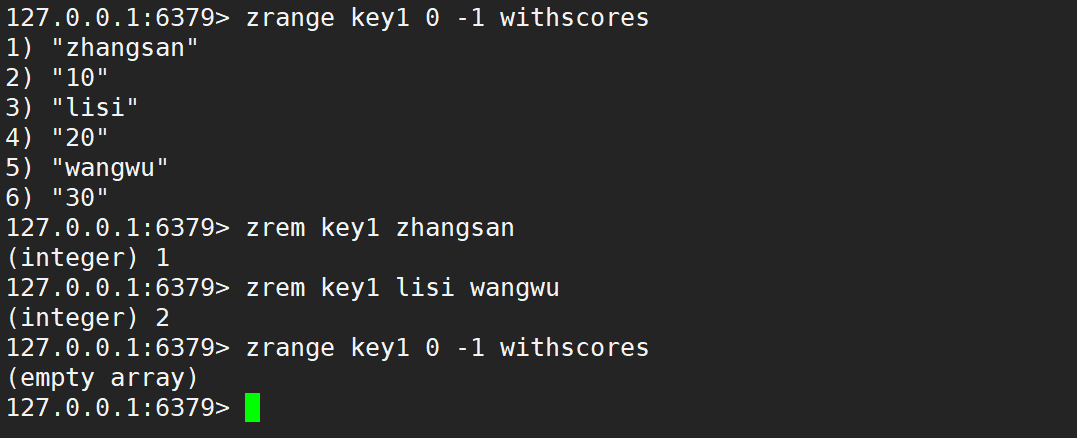
- zremrangebyrank:按照排序,升序刪除指定范圍的元素,左閉右閉。
- 語法:
zremrangebyrank key start stop - 時間復雜度:O(logN + M),N 是 zset 的元素個數,M 是要刪除的區間中元素個數。
- 此處的查找只需要進行一次,不需要重復進行,之后的元素是緊緊挨著的。
- 返回值:本次操作刪除的元素個數。
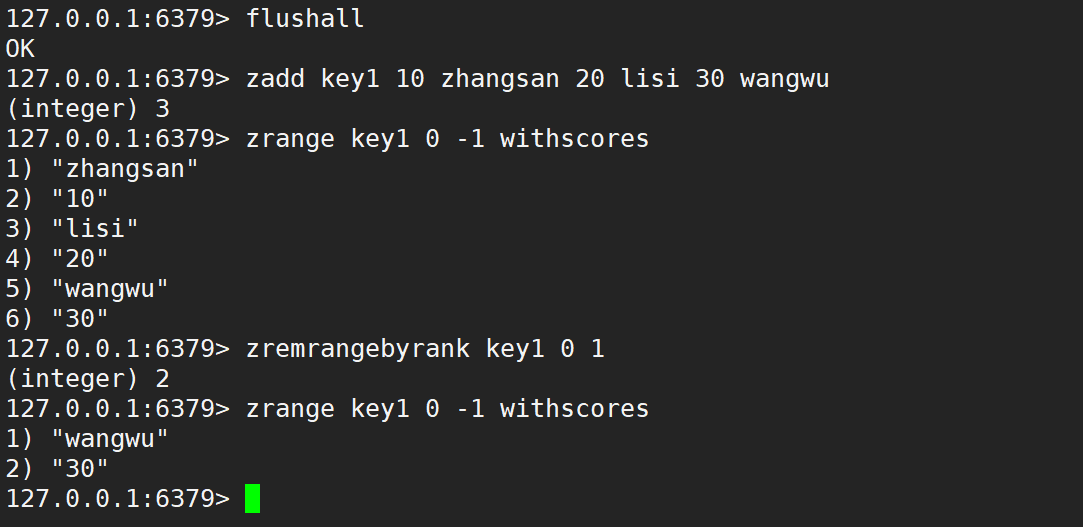
- zremrangebyscore:按照分數刪除指定范圍的元素,左閉右閉。
- 語法:
zremrangebyscore key min max - 時間復雜度:O(logN + M),N 是 zset 的元素個數,M 是要刪除的區間中元素個數。
- 返回值:本次操作刪除的元素個數。
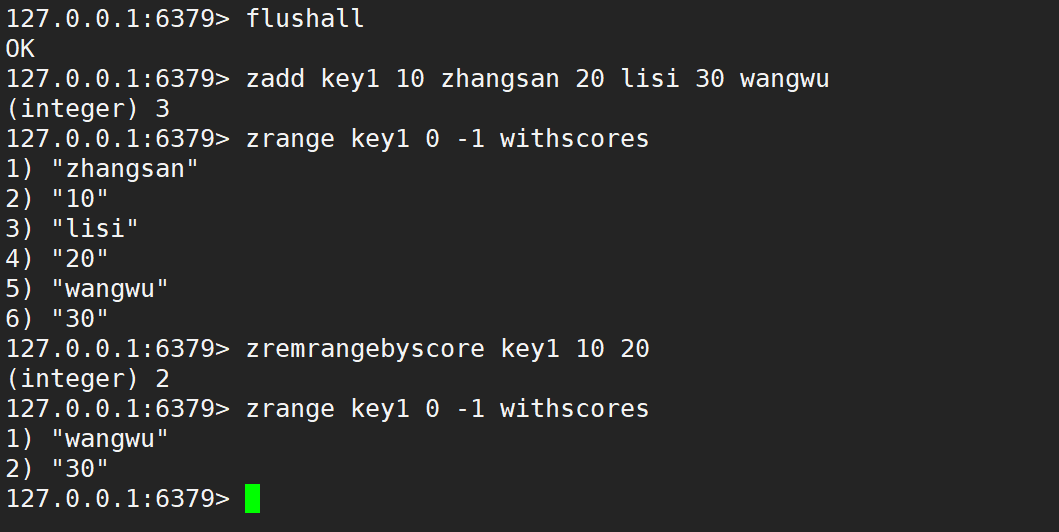
zincrby
- zincrby:為指定的元素的關聯分數添加指定的分數值。
- 語法:
zincrby key increment member - 時間復雜度:O(logN)
- 返回值:增加后元素的分數。
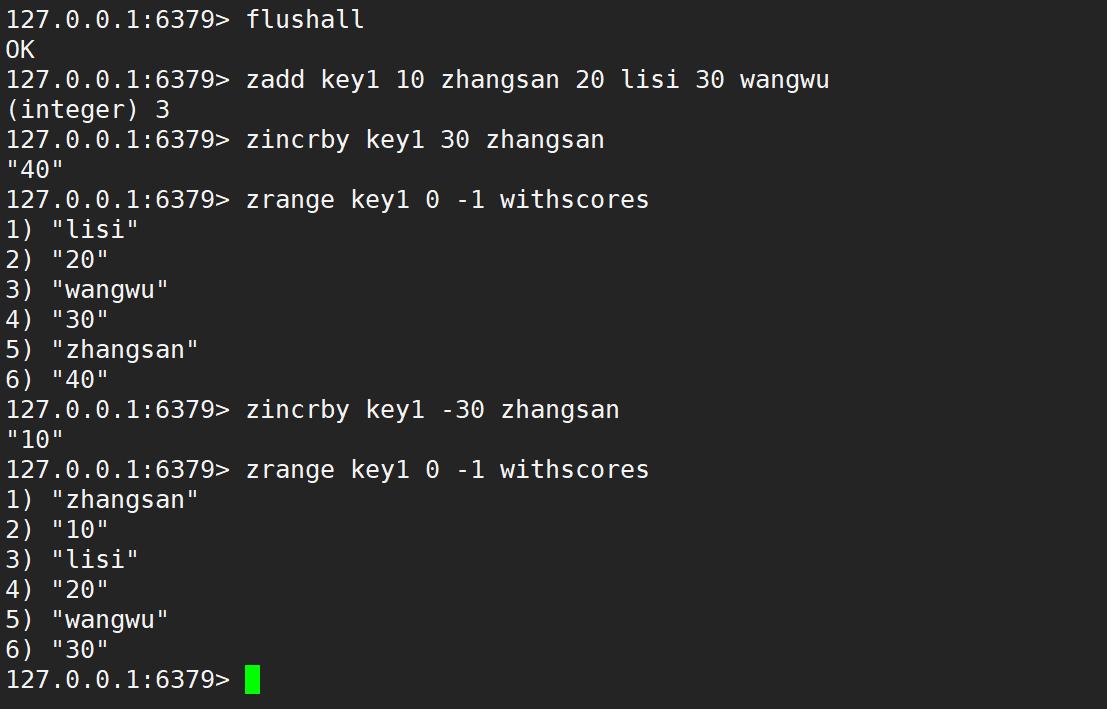
注意:不光會修改分數內容,也能同時移動位置,保持整個有序集合仍然是升序的。
阻塞版本命令:bzpopmax、bzpopmin
針對 list 的 blpop、brpop 命令,實現類似阻塞隊列的效果,我們這里的 “有序集合” 也可以視為是一個 “優先級隊列”,有的時候,也需要一個帶有 “阻塞功能” 的優先級隊列。
- bzpopmax:zpopmax 的阻塞版本。
- 阻塞是在有序集合為空的時候觸發的,阻塞直到有其他客戶端插入元素。
- 語法:
bzpopmax key [key ...] timeout- key:都是一個有序集合 zset
- timeout:超時時間,單位是秒,且支持小數。
- 時間復雜度:O(logN),N 是 zset 的元素個數。
- 返回值:哪個 zset、member 和 score


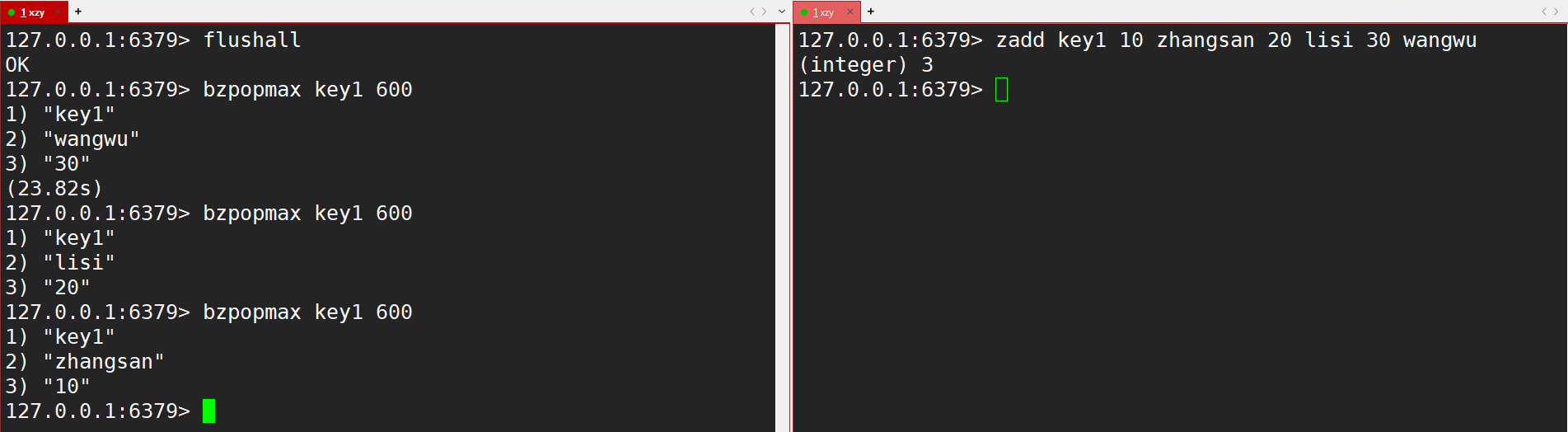
如果有序集合中已經存在元素了,直接就能返回了,就不會阻塞了。
- bzpopmin:zpopmin 的阻塞版本。
- 語法:
bzpopmin key [key ...] timeout - 時間復雜度:O(logN),N 是 zset 的元素個數。
- 返回值:哪個 zset、member 和 score
集合間操作:zinterstore、zunionstore
在 set 中,存在 sinter、sunion、sdiff 這些命令求交集、并集、差集操作。而在 zset 中的 zinter、zunion、zdiff 這些命令是從 Redis 6.2 開始支持的,這里使用的是 Redis 5 版本,此處不涉及,但是 Redis 提供了 zinterstore、zunionstore 命令求交集和并集。
有序集合的交集操作

- zinterstore:求出給定有序集合中元素的交集并保存進目標有序集合中,在合并過程中以元素為單位進行合并,元素對應的分數按照不同的聚合方式和權重得到新的分數。
- 語法:
zinterstore destination numkeys key [key ...] [WEIGHTS weight] [AGGREGATE SUM|MIN|MAX]- numkeys:整數,描述了后續有幾個 key 參與交集運算。
- 前面 set 介紹的命令,不涉及到類似于此處的設定,主要是因為 numkeys 描述出 key 的個數之后,就可以明確的知道,后面的 “選項” 是從哪里開始的,避免選項和 key 混淆。
- 例如:HTTP 協議的請求報頭中的 Content-Length 描述了正文的長度,防止數據產生的黏包問題,HTTP 協議在傳輸層是基于 TCP 實現的,而 TCP 是面向字節流的,黏包問題是面向字節流這種 IO 方式中的一個普遍存在的問題。
- 同理文件讀寫也是面向字節流的,解決黏包問題的關鍵在于明確包的長度/邊界。對于有正文的 HTTP 請求,Content-Length 就是包的長度;而對于沒有正文的 HTTP 請求,空行就是包的邊界。
- weights:權重,合并生成的有序集合是帶有分數的,此處指定的權重,相當于一個系數,會乘以當前的分數。
- aggregate:總計最終 score 的方式。
- 有序集合中,member 才是元素的本體,score 只是輔助排序的工具人,因此,在進行比較 “相同” 的時候,只要 member 相同即可,score 不一樣不影響。
- 如果 member 相同,score 不同,進行交集合并之后,最終的 score,就是根據這里的 aggregate 來計算 (求和/取最大/取最小)
- numkeys:整數,描述了后續有幾個 key 參與交集運算。
- 時間復雜度:O(N * K) + O(M * logM),N 是輸入的有序集合中,最小的有序集合的元素個數;K 是輸入的個有序集合個數;M 是最終結果的有序集合的元素個數。
- 這個東西取決于 Redis 源碼如何實現的,這里的 K 一般不會很多,可以近似看作 1,化簡一下,認為 N 和 M 是接近的 (同一個數量級,假設不嚴謹,只是近似看來),最終就是 O(M) + O(M * logM) 近似 O(M * logM),
- 返回值:目標集合中的元素個數。
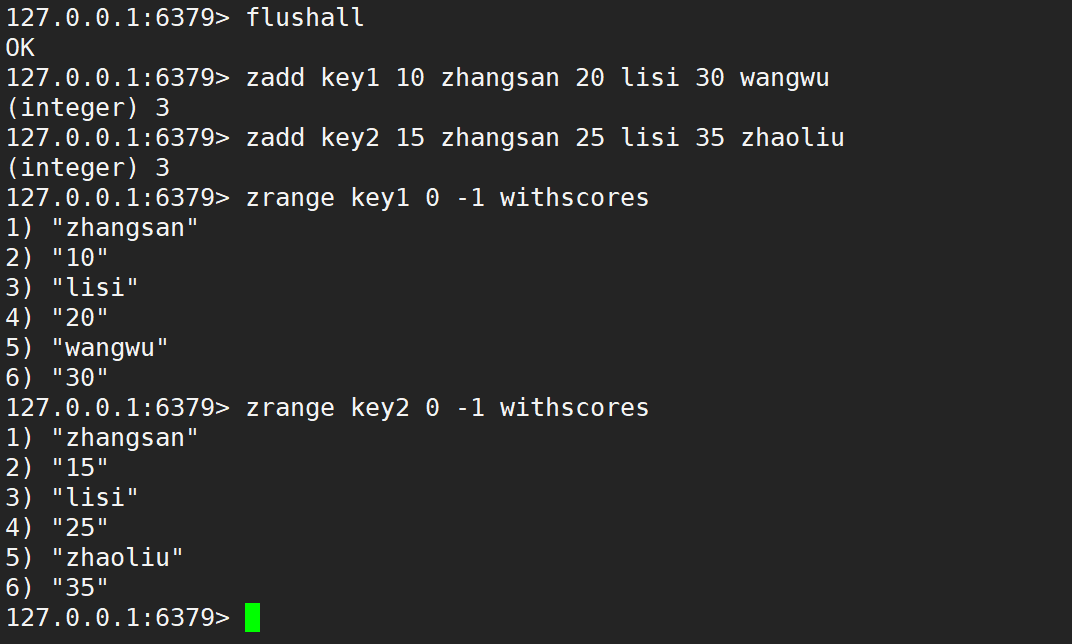
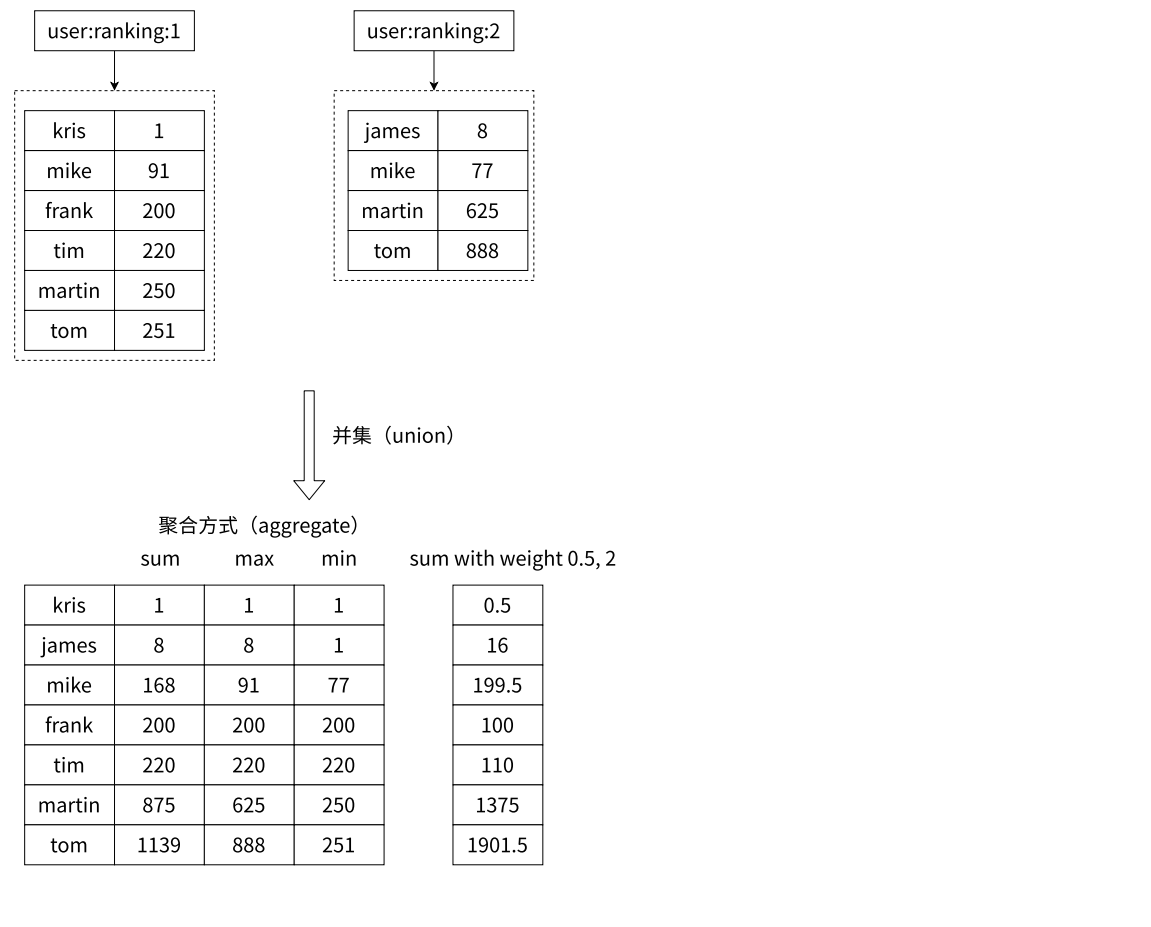
默認情況是相加,如下:
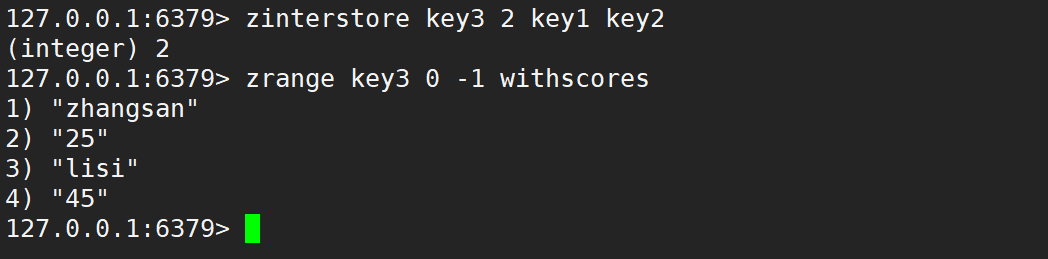
只使用 weights,默認情況是先乘權重系數,再相加,如下:
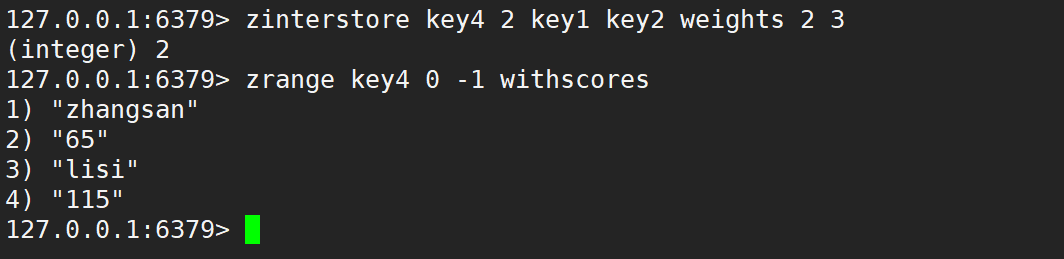
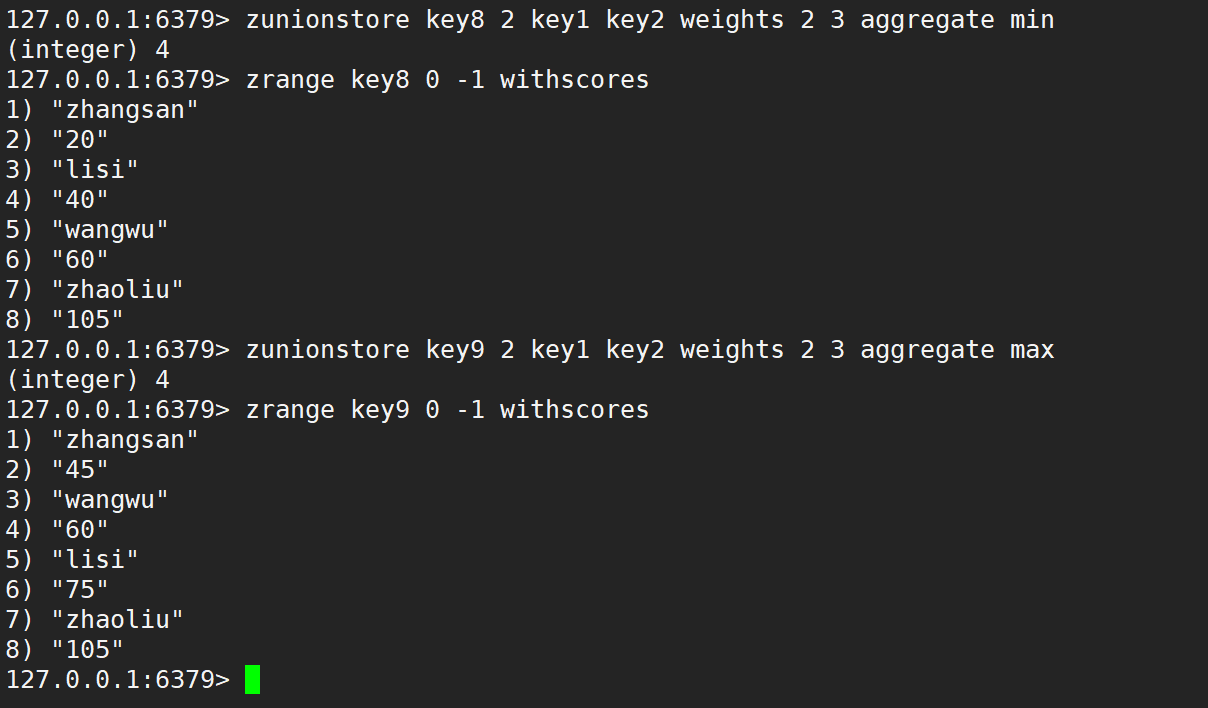
只使用 aggregate 取最小、取最大、求和,如下:
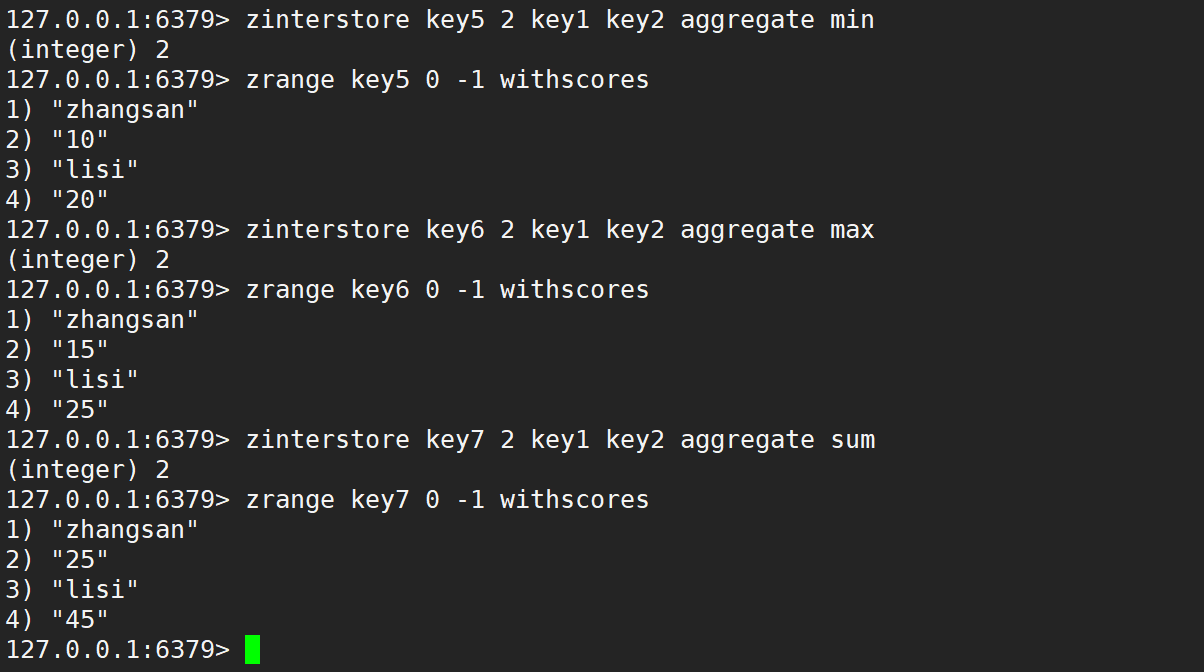
同時使用 weight 和 aggregate 取最小、取最大、求和,如下:
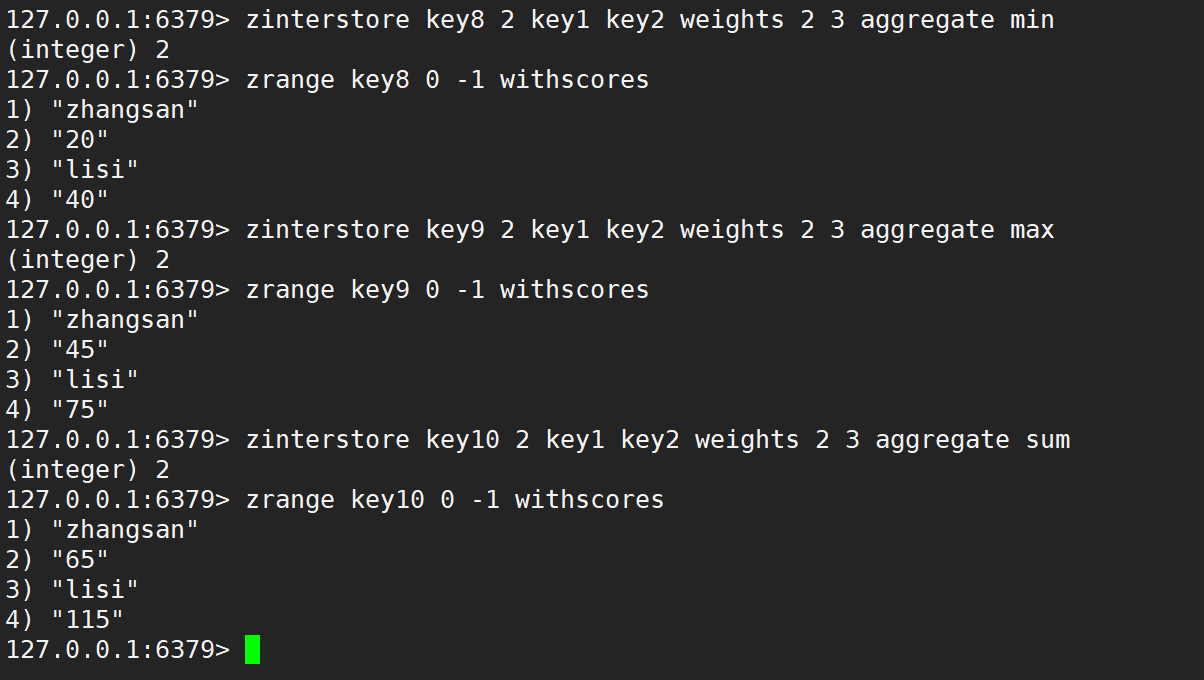
有序集合的并集操作
- zunionstore:求出給定有序集合中元素的并集并保存進目標有序集合中,在合并過程中以元素為單位進行合并,元素對應的分數按照不同的聚合方式和權重得到新的分數。
- 語法:
zunionstore destination numkeys key [key ...] [WEIGHTS weight] [AGGREGATE SUM|MIN|MAX] - 時間復雜度:O(N) + O(M * logM),N 是輸入的有序集合總的元素個數;M 是最終結果的有序集合的元素個數。
- 返回值:目標集合中的元素個數
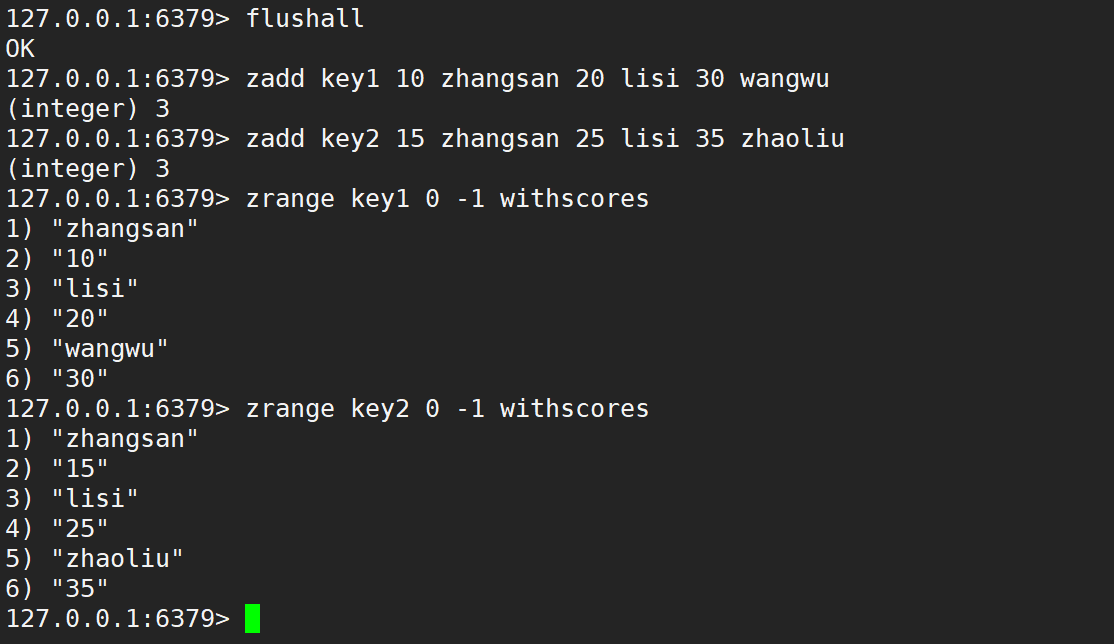
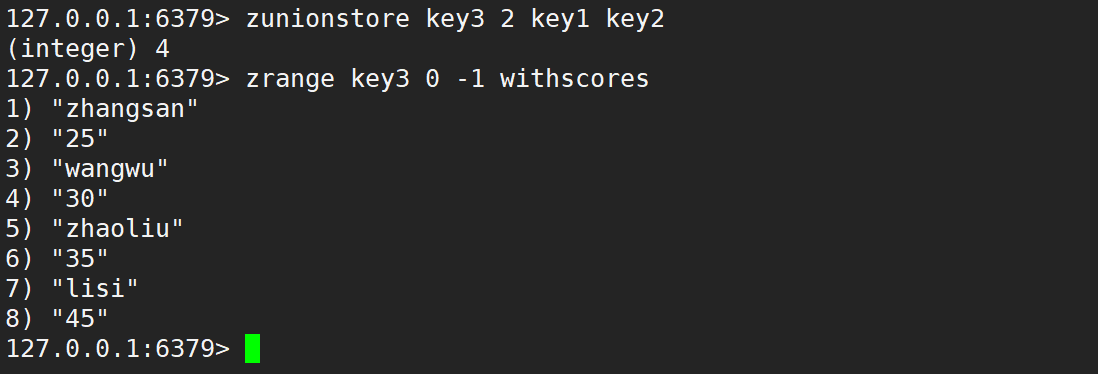
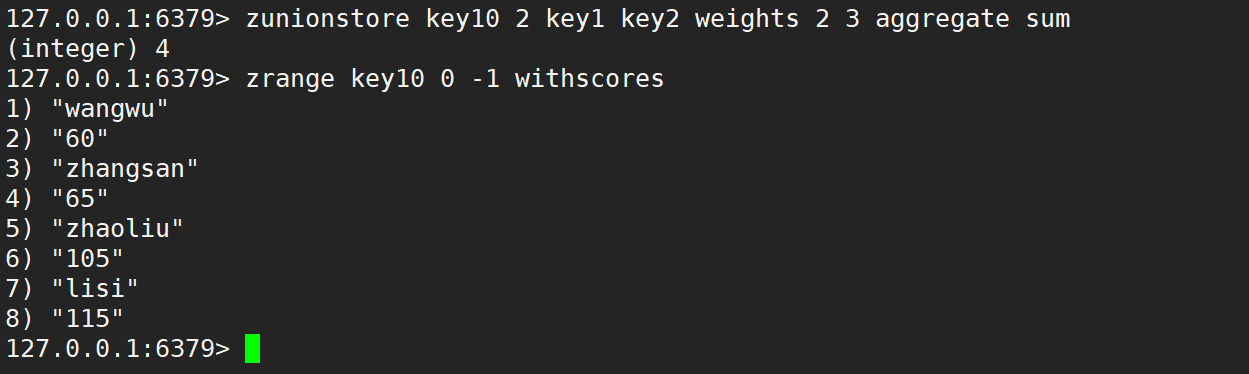
默認情況是相加,如下:
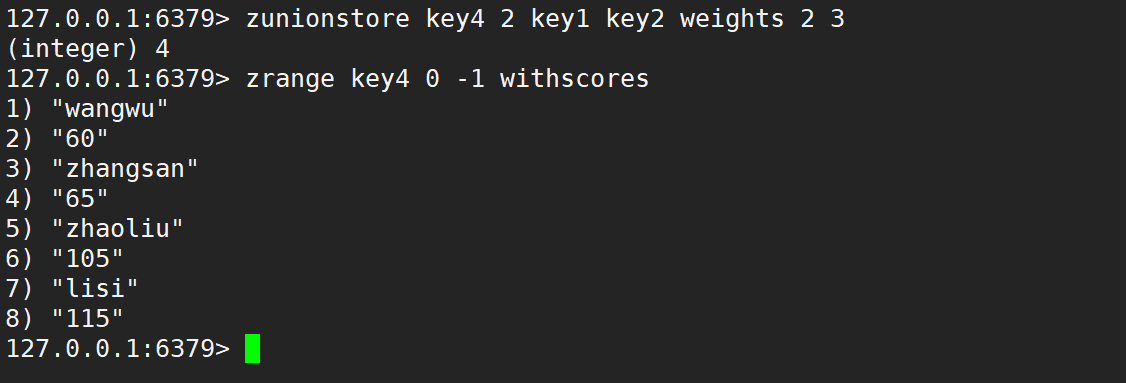
只使用 weights,默認情況是先乘權重系數,再相加,如下:
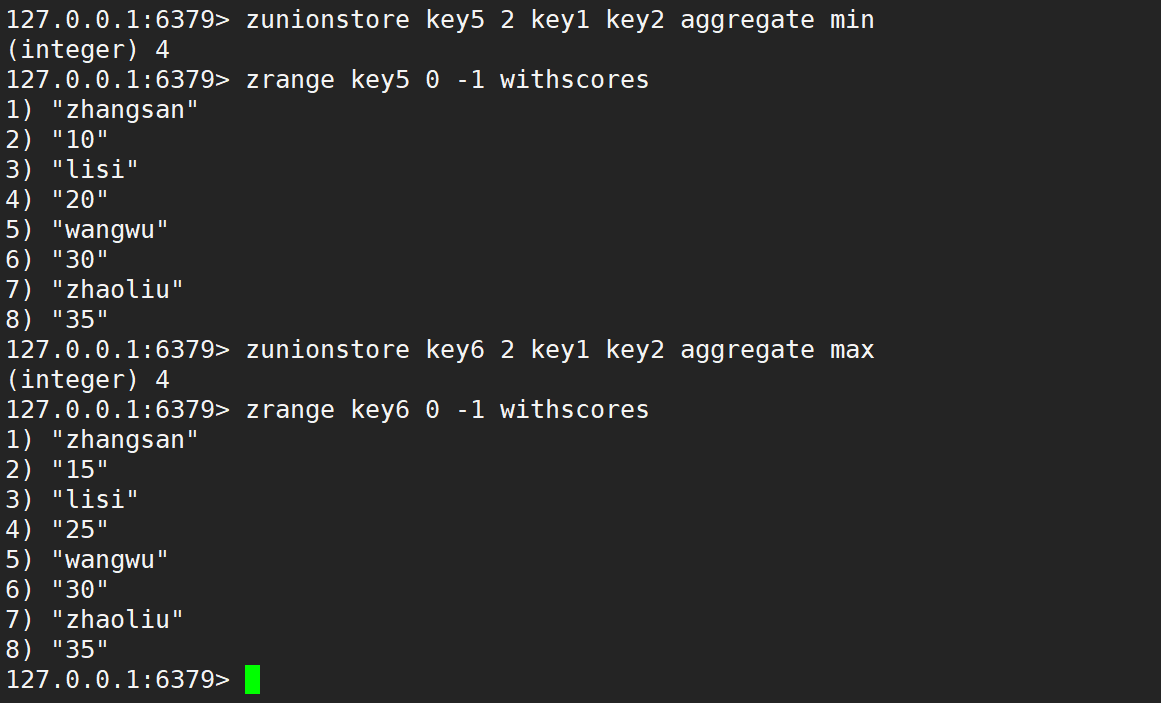
只使用 aggregate 取最小、取最大、求和,如下:
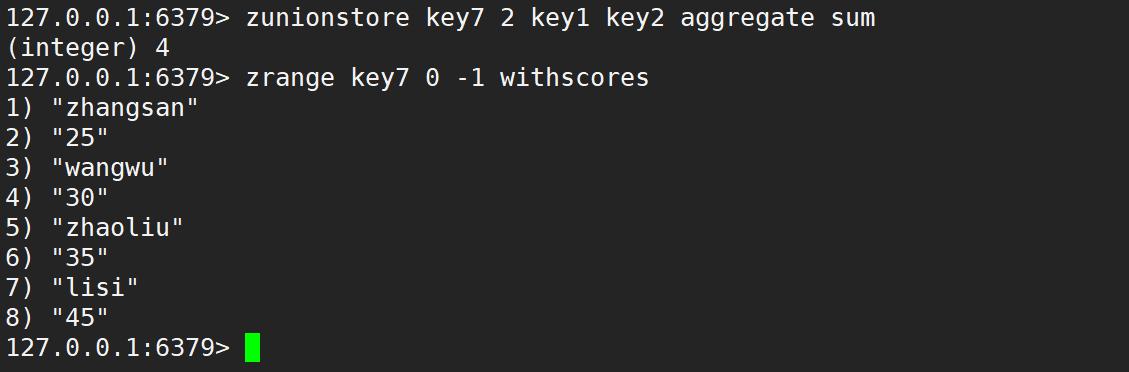
同時使用 weight 和 aggregate 取最小、取最大、求和,如下:
三. zset 命令小結
| 命令 | 執行效果 | 時間復雜度 |
|---|---|---|
| zadd key [NX/XX] [CH] [INCR] score member [score member …] | 向有序集合中添加元素 | O(K * logN) |
| zcard key | 獲取有序集合中元素的個數 | O(1) |
| zcount key min max | 獲取有序集合 [min, max] 區間內的元素 | logN |
| zrange key start stop [WITHSCORES] | 獲取有序集合中的元素,升序 | O(logN + M) |
| zrevrange key start stop [WITHSCORES] | 獲取有序集合中的元素,降序 | O(logN + M) |
| zrangebyscore key min max [WITHSCORES] [LIMIT offset count] | 按照分數獲取有序集合 [min, max] 區間內的元素 | O(logN + M) |
| zpopmax key [count] | 刪除并返回分數最高的 count 個元素 | O(logN + M) |
| zpopmin key [count] | 刪除并返回分數最低的 count 個元素 | O(logN + M) |
| zrank key member | 返回有序集合中元素的排名,升序 | O(logN) |
| zrevrank key member | 返回有序集合中元素的排名,降序 | O(logN) |
| zscore key member | 查詢指定元素的分數 | O(1) |
| zrem key member [member …] | 刪除指定的元素 | O(logN + M) |
| zremrangebyrank key start stop | 按照排序,升序刪除指定范圍的元素 | O(logN + M) |
| zremrangebyscore key min max | 按照分數刪除指定范圍的元素 | O(logN + M) |
| zincrby key increment member | 為指定的元素的關聯分數添加指定的分數值 | O(logN) |
| bzpopmax key [key …] timeout | zpopmax 的阻塞版本 | O(logN) |
| bzpopmin key [key …] timeout | zpopmin 的阻塞版本 | O(logN) |
| zinterstore destination numkeys key [key …] [WE/GHTS weight] [AGGREGATE SUM/MIN/MAX] | 將交集存儲在目標有序集合中 | O(N * K) + O(M * logM) |
| zunionstore destination numkeys key [key …] [WE/GHTS weight] [AGGREGATE SUM/MIN/MAX] | 將并集存儲在目標有序集合中 | O(N) + O(M * logM) |
其中 N 是有序集合中元素的個數,M 是區間中元素的個數/要刪除的元素的個數。
四. zset 內部編碼方式
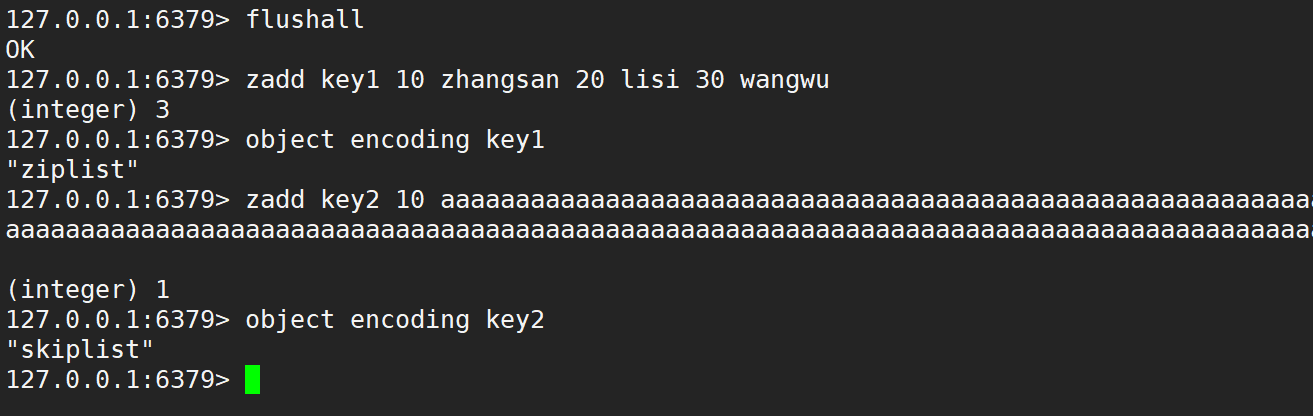
有序集合類型的內部編碼有兩種:
- ziplist (壓縮列表):當有序集合的元素個數小于 zset-max-ziplist-entries 配置 (默認 128 個),同時每個元素的值都小于 zset-max-ziplist-value 配置 (默認 64 字節) 時,Redis 會用 ziplist 來作為有序集合的內部實現,ziplist 可以有效減少內存的使用。
- 如果有序列表中的元素個數比較少,或者單個元素體積較小,使用 ziplist 來存儲,做到節省空間,但是效率會下降。
- skiplist (跳表):當 ziplist 條件不滿足時,有序集合會使用 skiplist 作為內部實現,因為此時 ziplist 的操作效率會下降。
- 如果有序列表中的元素個數比較多,或者單個元素體積較大,使用 skiplist 來存儲,做到提高效率。
- 簡單來說,跳表是一個 “復雜鏈表”,查詢一個元素的時間復雜度是 logN,相比于樹形結構 (平衡二叉搜索樹),更適合按照范圍獲取元素,功能類似于 MySQL 數據庫低層的 B+ 樹。
可以使用 object encoding 命令,來查看當前有序集合的內部編碼方式,如下:
五. zset 使用場景
排行榜系統
- 有序集合比較典型的使用場景就是排行榜系統,例如:微博熱搜、游戲天梯排行、成績排行。
- 榜單的維度可能是多方面的:按照時間、按照閱讀量、按照點贊量。用來排行的 “分數” 是實時變化的,使用 zset 來完成上述操作,就非常的簡單、高效的更新排行。
- 比如:游戲天梯排行,只需要把玩家信息和對應的分數給放到有序集合中即可,自動就形成了一個排行榜,隨著可以按照排行 (下標)、按照分數,進行范圍查找,隨著分數發生改變,也可以比較方便的使用 zincrby 修改分數,排行順序也能自動調整。
- 但是游戲玩家這么多,此時都用 zset 來在內存中存儲,能存的下嘛?假設 userId 按照 4 個字節計算,score 按照 8 個字節計算,表示一個玩家就是 12 個字節,若存在 1 億個玩家就是 12 億字節,約等于 1.2 GB,即便是家用電腦都能夠存下,更何況公司的服務器。
- 對于游戲排行榜,這里的先后順序非常容易確定,但是有的排行榜就要復雜一些,比如:微博熱點,是一些綜合的體現 (瀏覽量、點贊量、轉發量、評論量),使用權重 weight 分配,具體有多少個維度,每個維度權重該怎么分配,以及怎么設定是最優的,公司團隊通過人工智能的方式來進行計算,根據每個維度,計算得到的綜合得分,就是熱度。
- 此時就可以借助 zinterstore / zunionstore 按照加權方式處理,把上述每個維度的數值都放到一個有序集合中,member 就是微博的 id,score 就是某個維度的數值,按照約定好的權重,進行集合間運算即可,得到的結果集合的分數就是熱度,此時排行榜也就出來了。
- 實現排行榜,zset 是一個選擇,但不是說非得用 Redis 中的 zset,有些場景確實可以用到有序集合,但不方便使用 Redis,此時可以考慮使用其他方式的有序集合 (第三方庫、自己基于跳表實現有序集合)
本例中我們使用點贊數這個維度,維護每天的熱榜:
- 添加用戶贊數:用戶 james 發布了一篇文章,并獲得 3 個贊,可以使用有序集合的 zadd 和 zincrby 功能。之后如果再獲得贊,可以使用 zincrby:
zadd user:ranking:2022-03-15 3 james
zincrby user:ranking:2022-03-15 1 james
- 取消用戶贊數:由于各種原因 (例如用戶注銷、用戶作弊等) 需要將用戶刪除,此時需要將用戶從榜單中刪除掉,可以使用 zrem。例如刪除成員 tom:
zrem user:ranking:2022-03-15 tom
- 展示獲取贊數最多的 10 個用戶:此功能使用 zrevrange 命令實現:
zrevrangebyrank user:ranking:2022-03-15 0 9
- 展示用戶信息以及用戶分數:次功能將用戶名作為鍵后綴,將用戶信息保存在哈希類型中,至于用戶的分數和排名可以使用 zscore 和 zrank 來實現:
hgetall user:info:tom
zscore user:ranking:2022-03-15 mike
zrank user:ranking:2022-03-15 mike

![[pdf、epub]300道《軟件方法》強化自測題業務建模需求分析共257頁(202505更新)](http://pic.xiahunao.cn/[pdf、epub]300道《軟件方法》強化自測題業務建模需求分析共257頁(202505更新))




)



)








