論文:[2412.04467] VisionZip: Longer is Better but Not Necessary in Vision Language Models
github:https://github.com/dvlab-research/VisionZip
LLaVA論文:https://arxiv.org/abs/2310.03744
LLaVA倉庫:https://github.com/haotian-liu/LLaVA?tab=readme-ov-file
1.內容概括:? ? ? ?
?????????LLMs的發展推動了VLMs的發展,現有的VLMs為了把視覺信號與文本語義連接起來,通常采用順序視覺表示,將圖像轉換為視覺tokens并通過LLM解碼器處理。通過模態對齊和指令調優,這些VLM利用LLM的感知和推理能力,使其適應視覺領域【傳統處理方法】。?????????
????????VLM模型性能依賴于視覺token的數量,但是通過增加視覺token的長度(比文本token長度還要長)使得模型性能提升,這種方式顯著增加了計算成本,限制了模型在邊緣計算、自動駕駛和機器人等實際應用場景中的發展【傳統方法的局限性】【問題1:計算成本】。有研究表明:圖像中的信息更加稀疏。而現有的最先進的 VLMs 的視覺 tokens 數量遠遠超過文本 tokens。“所有視覺 tokens 都是必要的嗎?”,而經過實驗證明CLIP和SigLIP生成的視覺token存在冗余【問題2:token雖然長,但不都是有用的】。
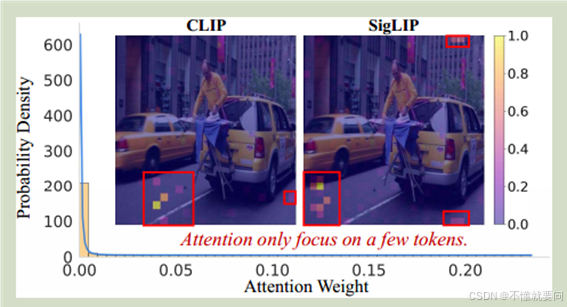
? ? ? ? 如圖所示就是改論文所作的實驗,左側的實驗是注意力權重分布圖,可見高注意力權重(如 0.05–0.10 區間)的標記概率密度低,即此類標記數量少;大量標記的注意力權重集中在 0 附近(概率密度高),說明多數標記未被關注,進一步驗證視覺標記冗余現象。
? ? ? ? 在兩張圖片中,高亮度區域是高注意力權重的視覺token,可以看見在整張圖中,高注意力權重的區域非常小,那么也就是說視覺token的冗余現象非常嚴重。而且還可以看見一個現象就是高注意權重的視覺token區域并不在圖像的主要目標物體中,例如圖中的人物或者出租車,而是出現在了馬路上,這種高注意力權重視覺token的偏移現象似乎也能解釋為什么在LLM階段根據文本與圖像之間的對應關系篩選主導token時可能性能下降比較明顯:因為與文本對象關聯的視覺主體上的視覺token權重并不高,這樣篩選出的視覺token會丟失大量的圖像原本的信息。
????????VisionZip的解決方案:選擇一組信息豐富的 tokens 作為語言模型的輸入,減少視覺 tokens 的冗余,提升效率的同時保持模型性能。VisionZip可廣泛應用于圖像和視頻理解任務,尤其適合多輪對話等實際場景,而此前的方法在這些場景中表現欠佳【優勢】。?
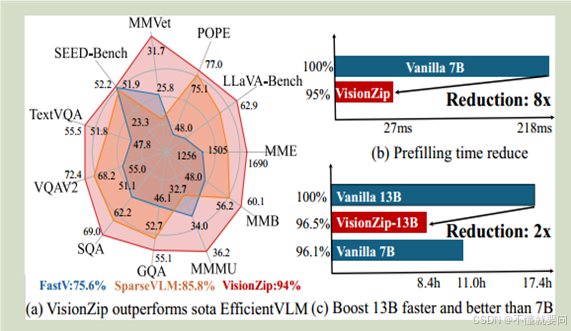
A: 性能對比雷達圖
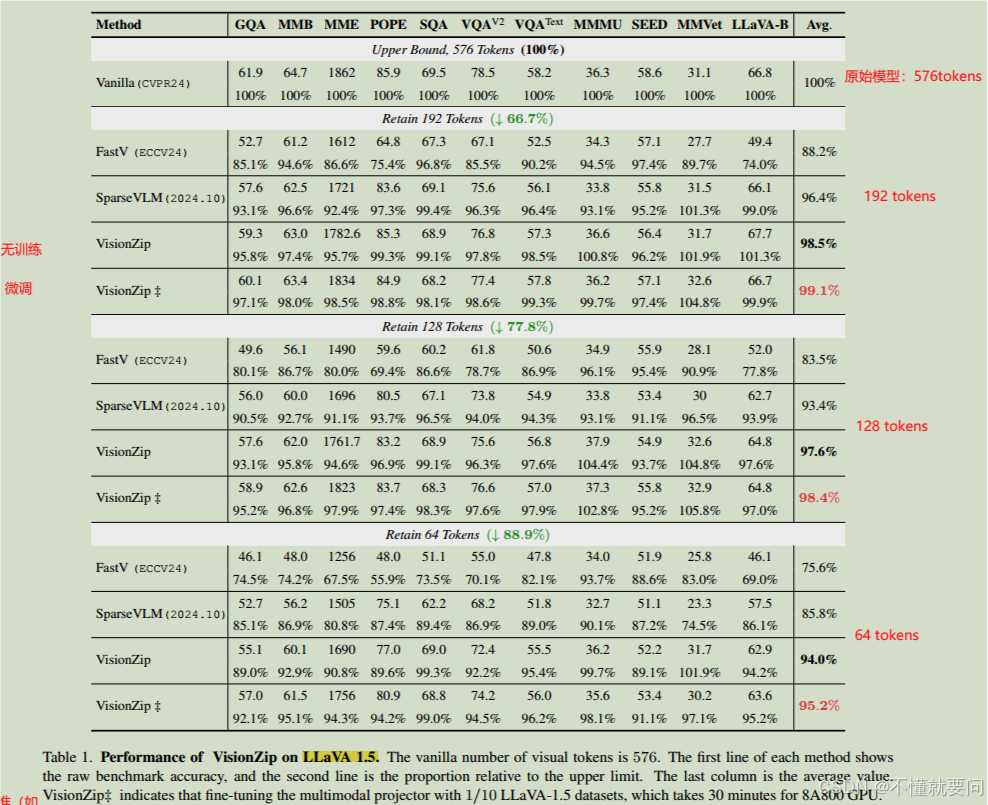
????????對比使用 VisionZip 優化的LLaVA-1.5模型與當前高效VLM模型優化方法(如 FastV、SparseVLM 等)在 11 個基準測試(如 LLaVA-Bench、MME、TextVQA、VQAV2 等)上的性能表現。VisionZip 在僅使用 10%tokens的情況下,實現了接近當前最優模型95% 的性能。
B: 預填充時間對比柱狀圖
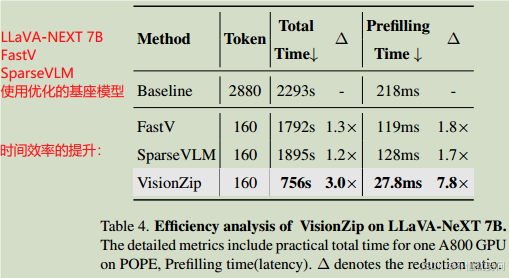
?????? 基座模型選擇LLaVA-NeXT,7B是70億參數版本。VisionZip 大幅優化了預填充效率,將 LLaVA-NeXT 7B 模型的預填充時間從 218ms 減少至 27ms,實現了8 倍的時間縮減(Reduction: 8x),同時可以達到基座模型性能的95%。
C: 推理時間與性能對比柱狀圖
?????? 三個模型:LLaVA-NeXT 13B,經過VisionZip優化的13B模型,LLaVA-NeXT 7B,內容:在 11 個基準測試中的 GPU 推理時間與性能。經過VisionZip優化的13B模型推理時間上是原本13B模型的1/2,性能可以達到96.5%,比7B模型的推理時間還少,性能卻更好(96.1%)。
2.方法總結:
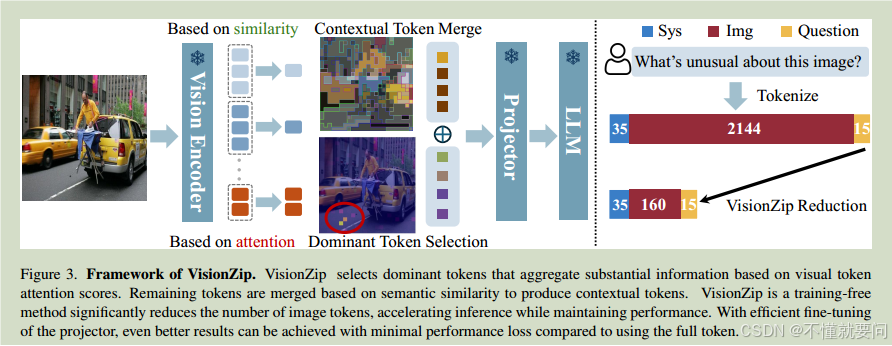
????????VisionZip方法總結起來就是刪去無用的視覺token以達到提高推理速度的作用。這種類型的方法在此之前已經出現過,比如FastV、SparseVLM這類,但是他們主要在VLM的LLM階段(Vision Encoder->MM->LLM)對視覺token進行處理,在這個過程中操作較為復雜而且性能損失較大。VisionZip選擇的道路是在VisionEncoder之后就對視覺token進行處理,主要的處理分為兩個步驟:
2.1:保留主導token:
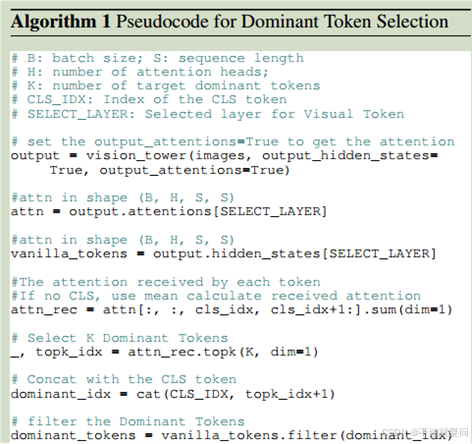
????????這一塊的主要思路是確定一個閾值k,即我們要保留多少高注意力權重的視覺token,然后根據CLS標識得到所有視覺token的注意力得分,然后選擇其中最高的k個做保留即可。
2.2:合并其余token:

????????這一塊的主要思路是在剩余的視覺token中,可能他們所攜帶的信息量并不多,但是完全刪去他們可能會損失模型的性能,因此對于剩余的token要做一定的合并處理,首先給定一個閾值M,即要合并出多少個token,之后將剩余的視覺token分割為兩部分,一部分是目標token,一部分是合并token,計算出合并token與目標token之間的余弦相似度,此時,對于每一個合并token來說,只保留與他相似度最大的目標token的索引,然后統計針對每一個目標token,有哪些合并token要與他合并,最后進行求和相加即可完成合并工作。?
3.實驗思路:
實驗思路:
????????該論文提出的實驗思路有三種應用:
????????第一種是無訓練方法,即只需要在推理時在Vision Encoder之后進行視覺token篩選即可。
????????第二種是高效微調方法:視覺token經過了壓縮之后出現了一個問題,那就是經過信息性視覺token壓縮后,輸入到大語言模型的視覺token長度顯著減少,這可能導致原本在完整視覺token上訓練的視覺語言模型難以適應這種變化,使得視覺和大語言模型空間之間出現差距 ,即兩者在信息表示和處理方式上不太匹配。解決方法是通過微調多模態投影器,讓它適應減少后的視覺token輸入,從而增強視覺和語言空間之間的對齊。具體操作中,只對多模態投影器進行微調,保持模型的其他組件(如視覺編碼器、大語言模型主體等)不變。
????????第三種方法是從頭開始訓練:全新訓練,整合 VisionZip 方法到模型構建中,從初始訓練就應用標記優化策略。
實驗結果:
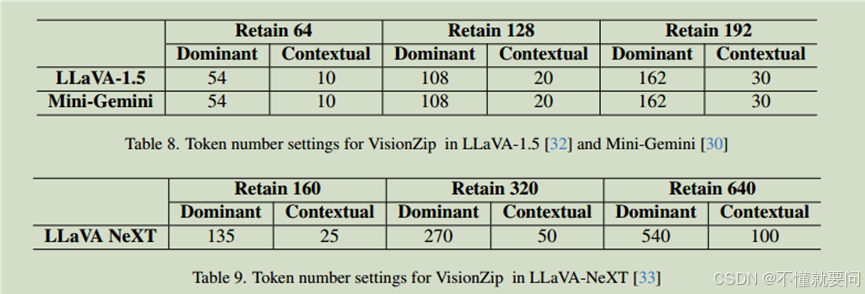
????????通過在 Mini - Gemini(基于 ConvNeXt - L)上應用 VisionZip,觀察其性能變化,證明 VisionZip 不僅適用于基于 Transformer 的 VLM(如 LLaVA 系列),還能在基于 CNN 的 VLM 中發揮作用,從而驗證其跨架構的普適性。如果在 ConvNeXt - L 生成的視覺標記中同樣存在冗余,并且 VisionZip 能夠有效減少冗余并提升效率,這將進一步證明視覺標記冗余是一個普遍現象,而非特定架構的問題。?

分析:
視覺 tokens 冗余的原因:

注意力跨層變化分析
- 早期層(如視覺編碼器初始層):
注意力在圖像上廣泛分布,模型此時在捕捉圖像的基礎特征(如邊緣、顏色、簡單形狀等),尚未聚焦到特定區域或物體,屬于對圖像整體信息的初步感知階段。 - 中間層:
注意力突然收斂到少量標記(token)。這表明模型在中間層開始篩選關鍵信息,過濾掉冗余細節,逐步明確對圖像中重要內容的關注,是從底層特征向高層語義過渡的階段。 - 深層(如第 23 層,用于為大語言模型提取視覺標記,作為VLM的視覺編碼器的輸出):
注意力和信息高度集中在一小部分 “主導token” 上,達到集中化的峰值。此時模型已識別出圖像中最核心、最具信息量的部分,這些主導標記承載了圖像的關鍵語義,是后續大語言模型處理的核心視覺輸入。 - 最后一層(如第 24 層):
注意力分布更分散。因為最后一層的標記需通過對比損失(contrastive loss)與 CLIP 文本分支對齊,這種對齊操作會讓標記更偏向語言空間的特征,而非單純表示原始圖像內容,從而限制了其對原始圖像細節的精準表達。
?Softmax 函數的梯度特性會加劇視覺標記冗余:

????????當輸入值?zi??增大時,softmax梯度呈指數上升趨勢。在模型訓練中,這種梯度特性會讓模型更傾向于關注少數響應值高的標記(對應圖像中的局部區域),而忽略其他標記的信息。長期訓練后,大量標記因未被充分利用成為冗余,僅少數標記承載主要信息。


)









![[Java 基礎]注釋](http://pic.xiahunao.cn/[Java 基礎]注釋)






基礎原理深度解析:從直觀理解到形式化表達)