今天我們來看一個很經典的回歸模型:泊松分布。
泊松分布
我們一般會把泊松分布用于預測問題,比如想知道成年人每天接到的騷擾電話次數,醫院每天的急診病人等。但在一些方面,跟我們想的會有出入。例如你不能將其應用在預測下周你的體重會是多少,看起來同是預測問題,但其背后隱含了數據的關系。
在預測每天接到的騷擾電話次數事件時,昨天接到的電話次數,跟今天的是沒有關系的,急診病人數量也一樣,但如果是預測下周一個人的體重,那么其實會發現,下周的體重會跟下周前一天1有關系,在一個特定的區間內浮動,類似的,也就能推導到一周前。當然,如果要把泊松分布應用在預測急診病人的數量,那么就需要特殊的前置條件,比如最近爆發了傳染性較強的病毒,所以急診病人數量會在一段時間內維持在一個比較高的數值。
所以,使用泊松分布的關鍵就在于,判斷每個數據點之間是否有聯系,從概率學上來講,就是每一個數據點,都代表了一次獨立概率事件,他們之間是互不影響的,只要滿足這種特點,就能運用泊松分布,當然也不要忽略一些數值條件(比如泊松分布要求Y是整數),你不能說預測班里身高超過1米8的人有10.5個吧。
下面我們用一段實例來說明:
library(tidyverse)
library(ggplot2)set.seed(123) # 固定隨機種子,確保結果可復現
n <- 500 # 樣本量# 生成自變量:天氣質量(weather,0~10)和是否促銷(promotion,0/1)
weather <- runif(n, min = 0, max = 10)
promotion <- rbinom(n, size = 1, prob = 0.3) # 30%的日期有促銷# 生成因變量:每日冰淇淋銷量(sales),使用泊松分布
true_beta <- c(1.5, 0.2, 0.8) # 真實系數:截距、weather、promotion
log_lambda <- true_beta[1] + true_beta[2] * weather + true_beta[3] * promotion
sales <- rpois(n, lambda = exp(log_lambda)) # 生成泊松分布的計數數據# 構建數據框
df <- data.frame(sales, weather, promotion)
# 使用 glm() 擬合泊松回歸模型
model <- glm(sales ~ weather + promotion, family = poisson(link = "log"), # 指定泊松分布和對數鏈接data = df)# 查看模型摘要
summary(model)# 新數據預測
new_data <- data.frame(weather = c(8, 3), # 天氣8分 vs 3分promotion = c(1, 0) # 有促銷 vs 無促銷
)# 預測銷量
pred_sales <- predict(model, newdata = new_data, type = "response")
pred_sales # 輸出預測值# 檢查是否過離散(Overdispersion)
library(AER)
dispersiontest(model)# 天氣 vs 銷量(按促銷分組)
ggplot(df, aes(x = weather, y = sales, color = factor(promotion))) +geom_point(alpha = 0.6) +geom_smooth(method = "glm", method.args = list(family = poisson), se = FALSE) +labs(title = "天氣和促銷對冰淇淋銷量的影響",x = "天氣評分", y = "銷量",color = "促銷(1=是)") +theme_minimal()輸出:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 1.508115 0.028471 52.97 <2e-16 ***
weather 0.200169 0.003801 52.66 <2e-16 ***
promotion 0.787791 0.020243 38.92 <2e-16 ***1 2
49.267146 8.236879 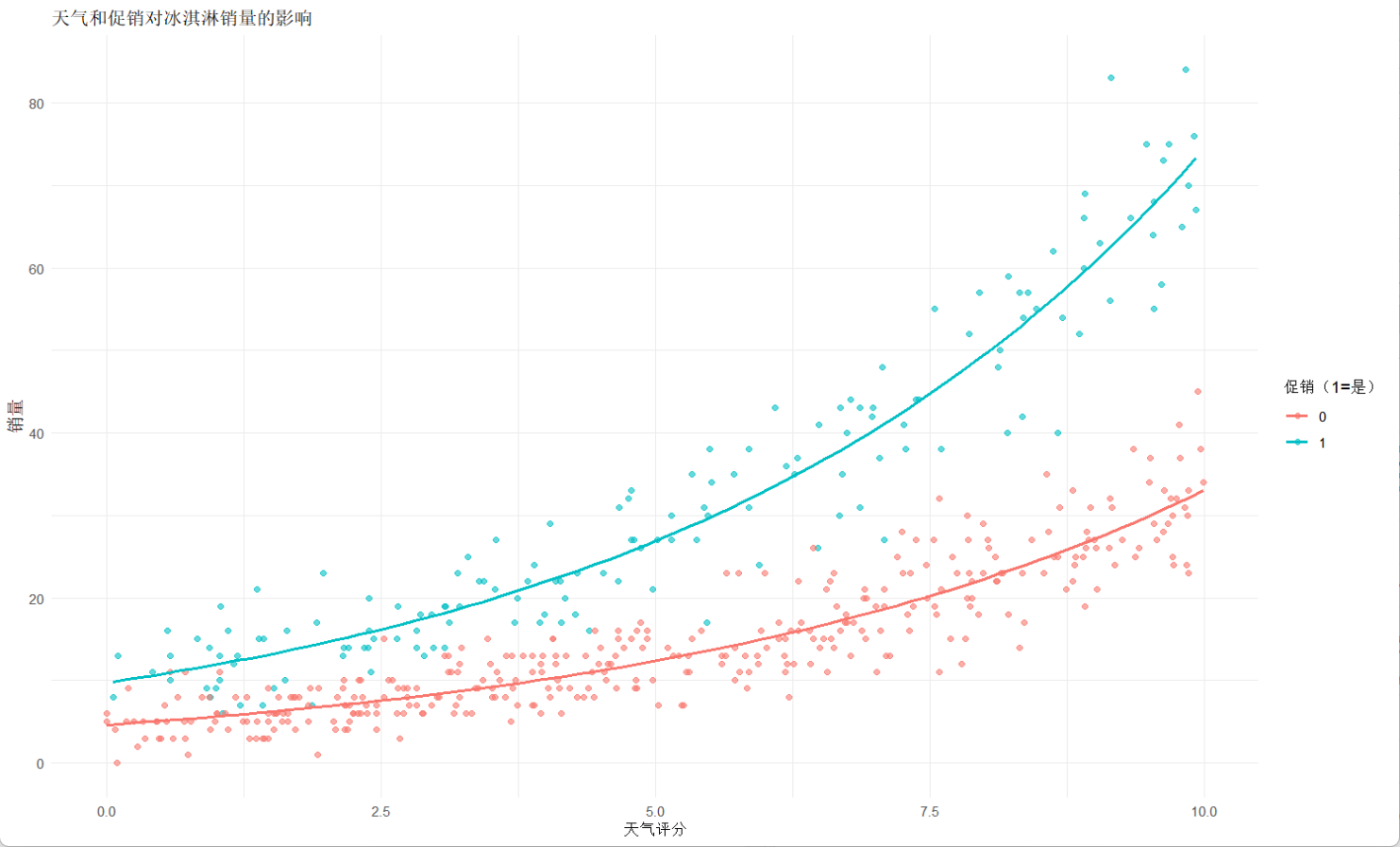
從輸出中我們可以得知,當天氣達到8分且有促銷時,預測的銷量為49.2;若天氣只有3分且沒有促銷時,預測的銷量為8.2。而且我們能觀察到天氣和促銷的P值小于0.05,這說明這兩個變量都對銷量有很大的影響。


)



實現騰訊云 IM 消息撤回)







)




MMA(OpenTelemetry/Rabbit MQ/ApiGateway/MongoDB))