DAY 40 訓練和測試的規范寫法
知識點回顧:
- 彩色和灰度圖片測試和訓練的規范寫法:封裝在函數中
- 展平操作:除第一個維度batchsize外全部展平
- dropout操作:訓練階段隨機丟棄神經元,測試階段eval模式關閉dropout
作業:仔細學習下測試和訓練代碼的邏輯,這是基礎,這個代碼框架后續會一直沿用,后續的重點慢慢就是轉向模型定義階段了。
"""
DAY 40 訓練和測試的規范寫法本節介紹深度學習中訓練和測試的規范寫法,包括:
1. 訓練和測試函數的封裝
2. 展平操作
3. dropout的使用
4. 訓練過程可視化
"""import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
from torch.utils.data import DataLoader# 設置中文字體(解決中文顯示問題)
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows系統常用黑體字體
plt.rcParams['axes.unicode_minus'] = False # 正常顯示負號# 設置隨機種子,確保結果可復現
torch.manual_seed(42)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")#====================== 1. 數據加載 ======================def load_data(batch_size=64, is_train=True):"""加載CIFAR-10數據集Args:batch_size: 批次大小is_train: 是否為訓練集Returns:dataloader: 數據加載器"""transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])dataset = torchvision.datasets.CIFAR10(root='./data', train=is_train,download=True,transform=transform)dataloader = DataLoader(dataset,batch_size=batch_size,shuffle=is_train, # 訓練集打亂,測試集不打亂num_workers=2)return dataloader#====================== 2. 模型定義 ======================class SimpleNet(nn.Module):def __init__(self, dropout_rate=0.5):super(SimpleNet, self).__init__()# 修改第一層卷積的輸入通道為3(彩色圖像)self.conv1 = nn.Conv2d(3, 32, 3, 1)self.conv2 = nn.Conv2d(32, 64, 3, 1)self.dropout1 = nn.Dropout2d(dropout_rate) # 2D dropout用于卷積層self.dropout2 = nn.Dropout(dropout_rate) # 1D dropout用于全連接層# 展平后的特征圖大小計算:# 原始圖像: 32x32# conv1: (32-3+1)x(32-3+1) = 30x30# maxpool: 15x15# conv2: (15-3+1)x(15-3+1) = 13x13# maxpool: 6x6# 因此全連接層輸入大小為: 64 * 6 * 6self.fc1 = nn.Linear(64 * 6 * 6, 128)self.fc2 = nn.Linear(128, 10)def forward(self, x):x = self.conv1(x)x = F.relu(x)x = F.max_pool2d(x, 2)x = self.conv2(x)x = F.relu(x)x = F.max_pool2d(x, 2)x = self.dropout1(x) # 訓練時隨機丟棄,測試時自動關閉# 展平操作:保留batch_size維度,其余維度展平x = torch.flatten(x, 1) # 等價于 x.view(x.size(0), -1)x = self.fc1(x)x = F.relu(x)x = self.dropout2(x)x = self.fc2(x)return F.log_softmax(x, dim=1)#====================== 3. 訓練函數 ======================def train(model, train_loader, optimizer, epoch, history):"""訓練一個epochArgs:model: 模型train_loader: 訓練數據加載器optimizer: 優化器epoch: 當前epoch數history: 記錄訓練歷史的字典Returns:epoch_loss: 當前epoch的平均損失epoch_acc: 當前epoch的準確率"""model.train() # 設置為訓練模式,啟用dropouttrain_loss = 0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad() # 清空梯度output = model(data) # 前向傳播loss = F.nll_loss(output, target) # 計算損失loss.backward() # 反向傳播optimizer.step() # 更新參數train_loss += loss.item()pred = output.max(1, keepdim=True)[1] # 獲取最大概率的索引correct += pred.eq(target.view_as(pred)).sum().item()total += target.size(0)if batch_idx % 100 == 0:print(f'Train Epoch: {epoch} [{batch_idx * len(data)}/{len(train_loader.dataset)} 'f'({100. * batch_idx / len(train_loader):.0f}%)]\t'f'Loss: {loss.item():.6f}\t'f'Accuracy: {100. * correct / total:.2f}%')# 計算epoch的平均損失和準確率epoch_loss = train_loss / len(train_loader)epoch_acc = 100. * correct / total# 記錄訓練歷史history['train_loss'].append(epoch_loss)history['train_acc'].append(epoch_acc)return epoch_loss, epoch_acc#====================== 4. 測試函數 ======================def test(model, test_loader, history):"""在測試集上評估模型Args:model: 模型test_loader: 測試數據加載器history: 記錄訓練歷史的字典Returns:test_loss: 測試集上的平均損失accuracy: 測試集上的準確率"""model.eval() # 設置為評估模式,關閉dropouttest_loss = 0correct = 0with torch.no_grad(): # 測試時不需要計算梯度for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += F.nll_loss(output, target, reduction='sum').item()pred = output.max(1, keepdim=True)[1]correct += pred.eq(target.view_as(pred)).sum().item()test_loss /= len(test_loader.dataset)accuracy = 100. * correct / len(test_loader.dataset)# 記錄測試歷史history['test_loss'].append(test_loss)history['test_acc'].append(accuracy)print(f'\nTest set: Average loss: {test_loss:.4f}, 'f'Accuracy: {correct}/{len(test_loader.dataset)} 'f'({accuracy:.2f}%)\n')return test_loss, accuracy#====================== 5. 可視化函數 ======================def plot_training_history(history):"""繪制訓練歷史曲線Args:history: 包含訓練和測試歷史數據的字典"""epochs = range(1, len(history['train_loss']) + 1)# 創建一個包含兩個子圖的圖表plt.figure(figsize=(12, 4))# 繪制損失曲線plt.subplot(1, 2, 1)plt.plot(epochs, history['train_loss'], 'b-', label='訓練損失')plt.plot(epochs, history['test_loss'], 'r-', label='測試損失')plt.title('訓練和測試損失')plt.xlabel('Epoch')plt.ylabel('損失')plt.legend()plt.grid(True)# 繪制準確率曲線plt.subplot(1, 2, 2)plt.plot(epochs, history['train_acc'], 'b-', label='訓練準確率')plt.plot(epochs, history['test_acc'], 'r-', label='測試準確率')plt.title('訓練和測試準確率')plt.xlabel('Epoch')plt.ylabel('準確率 (%)')plt.legend()plt.grid(True)plt.tight_layout()plt.show()def visualize_predictions(model, test_loader, num_samples=5):"""可視化模型預測結果Args:model: 訓練好的模型test_loader: 測試數據加載器num_samples: 要顯示的樣本數量"""model.eval()# 獲取一批數據dataiter = iter(test_loader)images, labels = next(dataiter)# 獲取預測結果with torch.no_grad():outputs = model(images.to(device))_, predicted = torch.max(outputs, 1)# 顯示圖像和預測結果fig = plt.figure(figsize=(12, 3))for idx in range(num_samples):ax = fig.add_subplot(1, num_samples, idx + 1)img = images[idx] / 2 + 0.5 # 反標準化npimg = img.numpy()plt.imshow(np.transpose(npimg, (1, 2, 0)))ax.set_title(f'預測: {classes[predicted[idx]]}\n實際: {classes[labels[idx]]}',color=('green' if predicted[idx] == labels[idx] else 'red'))plt.axis('off')plt.tight_layout()plt.show()#====================== 6. 主函數 ======================# CIFAR-10數據集的類別
classes = ('飛機', '汽車', '鳥', '貓', '鹿', '狗', '青蛙', '馬', '船', '卡車')def main():# 超參數設置batch_size = 64epochs = 9lr = 0.01dropout_rate = 0.5# 初始化訓練歷史記錄history = {'train_loss': [],'train_acc': [],'test_loss': [],'test_acc': []}# 加載數據print("正在加載訓練集...")train_loader = load_data(batch_size, is_train=True)print("正在加載測試集...")test_loader = load_data(batch_size, is_train=False)# 創建模型model = SimpleNet(dropout_rate=dropout_rate).to(device)optimizer = optim.SGD(model.parameters(), lr=lr, momentum=0.9)# 訓練和測試print(f"開始訓練,使用設備: {device}")for epoch in range(1, epochs + 1):train_loss, train_acc = train(model, train_loader, optimizer, epoch, history)test_loss, test_acc = test(model, test_loader, history)# 可視化訓練過程print("訓練完成,繪制訓練歷史...")plot_training_history(history)# 可視化預測結果print("可視化模型預測結果...")visualize_predictions(model, test_loader)if __name__ == '__main__':main()"""
重點說明:1. 訓練和測試的區別:- 訓練時:model.train(),啟用dropout- 測試時:model.eval(),關閉dropout2. 展平操作:- torch.flatten(x, 1) 或 x.view(x.size(0), -1)- 保留第一維度(batch_size),其余維度展平3. dropout的使用:- 訓練階段:隨機丟棄神經元,防止過擬合- 測試階段:自動關閉dropout,使用完整網絡4. 規范寫法的優點:- 代碼結構清晰,便于維護- 功能模塊化,易于復用- 訓練過程可控,便于調試- 適用于不同的數據集和模型
"""Train Epoch: 1 [19200/50000 (38%)] Loss: 1.878432 Accuracy: 24.59%
Train Epoch: 1 [25600/50000 (51%)] Loss: 1.737842 Accuracy: 27.03%
Train Epoch: 1 [32000/50000 (64%)] Loss: 1.608304 Accuracy: 29.29%
Train Epoch: 1 [38400/50000 (77%)] Loss: 1.654722 Accuracy: 30.90%
Train Epoch: 1 [44800/50000 (90%)] Loss: 1.781868 Accuracy: 32.24%Test set: Average loss: 1.4125, Accuracy: 4879/10000 (48.79%)Train Epoch: 2 [0/50000 (0%)] Loss: 1.725113 Accuracy: 31.25%
Train Epoch: 2 [6400/50000 (13%)] Loss: 1.371717 Accuracy: 43.70%
Train Epoch: 2 [12800/50000 (26%)] Loss: 1.377221 Accuracy: 43.85%
Train Epoch: 2 [19200/50000 (38%)] Loss: 1.497515 Accuracy: 44.32%
Train Epoch: 2 [25600/50000 (51%)] Loss: 1.509949 Accuracy: 44.92%
Train Epoch: 2 [32000/50000 (64%)] Loss: 1.322219 Accuracy: 45.19%
Train Epoch: 2 [38400/50000 (77%)] Loss: 1.451519 Accuracy: 45.65%
Train Epoch: 2 [44800/50000 (90%)] Loss: 1.284523 Accuracy: 46.09%Test set: Average loss: 1.2420, Accuracy: 5596/10000 (55.96%)Train Epoch: 3 [0/50000 (0%)] Loss: 1.457208 Accuracy: 57.81%
Train Epoch: 3 [6400/50000 (13%)] Loss: 1.411661 Accuracy: 49.80%
Train Epoch: 3 [12800/50000 (26%)] Loss: 1.251750 Accuracy: 49.25%
Train Epoch: 3 [19200/50000 (38%)] Loss: 1.485202 Accuracy: 49.98%
Train Epoch: 3 [25600/50000 (51%)] Loss: 1.219448 Accuracy: 50.09%
Train Epoch: 3 [32000/50000 (64%)] Loss: 1.319644 Accuracy: 50.40%
Train Epoch: 3 [38400/50000 (77%)] Loss: 1.431417 Accuracy: 50.58%
Train Epoch: 3 [44800/50000 (90%)] Loss: 1.321420 Accuracy: 51.04%Test set: Average loss: 1.1419, Accuracy: 6067/10000 (60.67%)Train Epoch: 4 [0/50000 (0%)] Loss: 1.274258 Accuracy: 54.69%
Train Epoch: 4 [6400/50000 (13%)] Loss: 1.455593 Accuracy: 53.57%
Train Epoch: 4 [12800/50000 (26%)] Loss: 1.439796 Accuracy: 53.95%
Train Epoch: 4 [19200/50000 (38%)] Loss: 1.333504 Accuracy: 54.18%
Train Epoch: 4 [25600/50000 (51%)] Loss: 1.127613 Accuracy: 54.53%
Train Epoch: 4 [32000/50000 (64%)] Loss: 1.197434 Accuracy: 54.76%
Train Epoch: 4 [38400/50000 (77%)] Loss: 1.217459 Accuracy: 54.58%
Train Epoch: 4 [44800/50000 (90%)] Loss: 1.249435 Accuracy: 54.67%Test set: Average loss: 1.0938, Accuracy: 6156/10000 (61.56%)Train Epoch: 5 [0/50000 (0%)] Loss: 1.200900 Accuracy: 54.69%
Train Epoch: 5 [6400/50000 (13%)] Loss: 1.200518 Accuracy: 55.96%
Train Epoch: 5 [12800/50000 (26%)] Loss: 1.267728 Accuracy: 56.58%
Train Epoch: 5 [19200/50000 (38%)] Loss: 1.501915 Accuracy: 56.76%
Train Epoch: 5 [25600/50000 (51%)] Loss: 1.248580 Accuracy: 56.72%
Train Epoch: 5 [32000/50000 (64%)] Loss: 1.385589 Accuracy: 56.64%
Train Epoch: 5 [38400/50000 (77%)] Loss: 1.377769 Accuracy: 56.59%
Train Epoch: 5 [44800/50000 (90%)] Loss: 1.355240 Accuracy: 56.62%Test set: Average loss: 1.0414, Accuracy: 6448/10000 (64.48%)Train Epoch: 6 [0/50000 (0%)] Loss: 1.194540 Accuracy: 64.06%
Train Epoch: 6 [6400/50000 (13%)] Loss: 1.255205 Accuracy: 59.00%
Train Epoch: 6 [12800/50000 (26%)] Loss: 1.216109 Accuracy: 58.45%
Train Epoch: 6 [19200/50000 (38%)] Loss: 0.916238 Accuracy: 58.74%
Train Epoch: 6 [25600/50000 (51%)] Loss: 1.081454 Accuracy: 58.52%
Train Epoch: 6 [32000/50000 (64%)] Loss: 1.170482 Accuracy: 58.42%
Train Epoch: 6 [38400/50000 (77%)] Loss: 1.263351 Accuracy: 58.43%
Train Epoch: 6 [44800/50000 (90%)] Loss: 1.197278 Accuracy: 58.45%Test set: Average loss: 0.9976, Accuracy: 6609/10000 (66.09%)Train Epoch: 7 [0/50000 (0%)] Loss: 1.296109 Accuracy: 51.56%
Train Epoch: 7 [6400/50000 (13%)] Loss: 1.194998 Accuracy: 59.25%
Train Epoch: 7 [12800/50000 (26%)] Loss: 1.045425 Accuracy: 58.80%
Train Epoch: 7 [19200/50000 (38%)] Loss: 1.096962 Accuracy: 59.35%
Train Epoch: 7 [25600/50000 (51%)] Loss: 1.002581 Accuracy: 59.48%
Train Epoch: 7 [32000/50000 (64%)] Loss: 1.101984 Accuracy: 59.45%
Train Epoch: 7 [38400/50000 (77%)] Loss: 0.934384 Accuracy: 59.56%
Train Epoch: 7 [44800/50000 (90%)] Loss: 1.025743 Accuracy: 59.56%Test set: Average loss: 0.9824, Accuracy: 6663/10000 (66.63%)Train Epoch: 8 [0/50000 (0%)] Loss: 1.121836 Accuracy: 60.94%
Train Epoch: 8 [6400/50000 (13%)] Loss: 1.057686 Accuracy: 60.47%
Train Epoch: 8 [12800/50000 (26%)] Loss: 1.132846 Accuracy: 60.13%
Train Epoch: 8 [19200/50000 (38%)] Loss: 1.094760 Accuracy: 59.88%
Train Epoch: 8 [25600/50000 (51%)] Loss: 1.392307 Accuracy: 59.98%
Train Epoch: 8 [32000/50000 (64%)] Loss: 0.905305 Accuracy: 60.01%
Train Epoch: 8 [38400/50000 (77%)] Loss: 1.293327 Accuracy: 60.11%
Train Epoch: 8 [44800/50000 (90%)] Loss: 1.154168 Accuracy: 60.13%Test set: Average loss: 0.9402, Accuracy: 6824/10000 (68.24%)Train Epoch: 9 [0/50000 (0%)] Loss: 0.742247 Accuracy: 70.31%
Train Epoch: 9 [6400/50000 (13%)] Loss: 0.880693 Accuracy: 60.89%
Train Epoch: 9 [12800/50000 (26%)] Loss: 1.063176 Accuracy: 61.19%
Train Epoch: 9 [19200/50000 (38%)] Loss: 1.462891 Accuracy: 61.12%
Train Epoch: 9 [25600/50000 (51%)] Loss: 1.227893 Accuracy: 61.29%
Train Epoch: 9 [32000/50000 (64%)] Loss: 0.829324 Accuracy: 61.12%
Train Epoch: 9 [38400/50000 (77%)] Loss: 1.199507 Accuracy: 61.10%
Train Epoch: 9 [44800/50000 (90%)] Loss: 1.242885 Accuracy: 61.04%Test set: Average loss: 0.9322, Accuracy: 6954/10000 (69.54%)訓練完成,繪制訓練歷史...
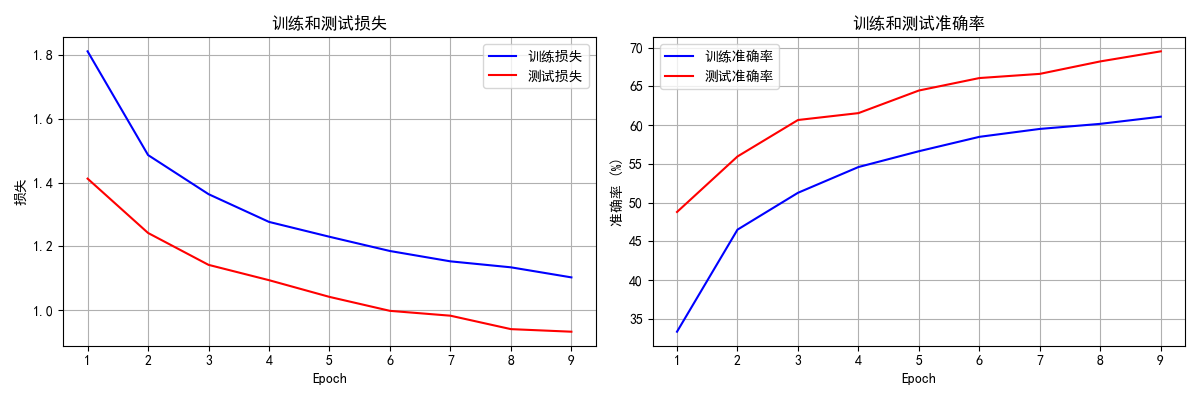 ?
?
?可視化模型預測結果...
浙大疏錦行?





)
![[C]基礎16.數據在內存中的存儲](http://pic.xiahunao.cn/[C]基礎16.數據在內存中的存儲)




)







