FunASR 是達摩院開源的綜合性語音處理工具包,提供語音識別(ASR)、語音活動檢測(VAD)、標點恢復(PUNC)等全流程功能,支持多種主流模型(如 Paraformer、Whisper、SenseVoice)的推理、微調和部署。
1. funasr安裝
pip install funasr
2. 模型下載
pip install modelscope
modelscope download --model iic/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch
3. 依賴庫安裝
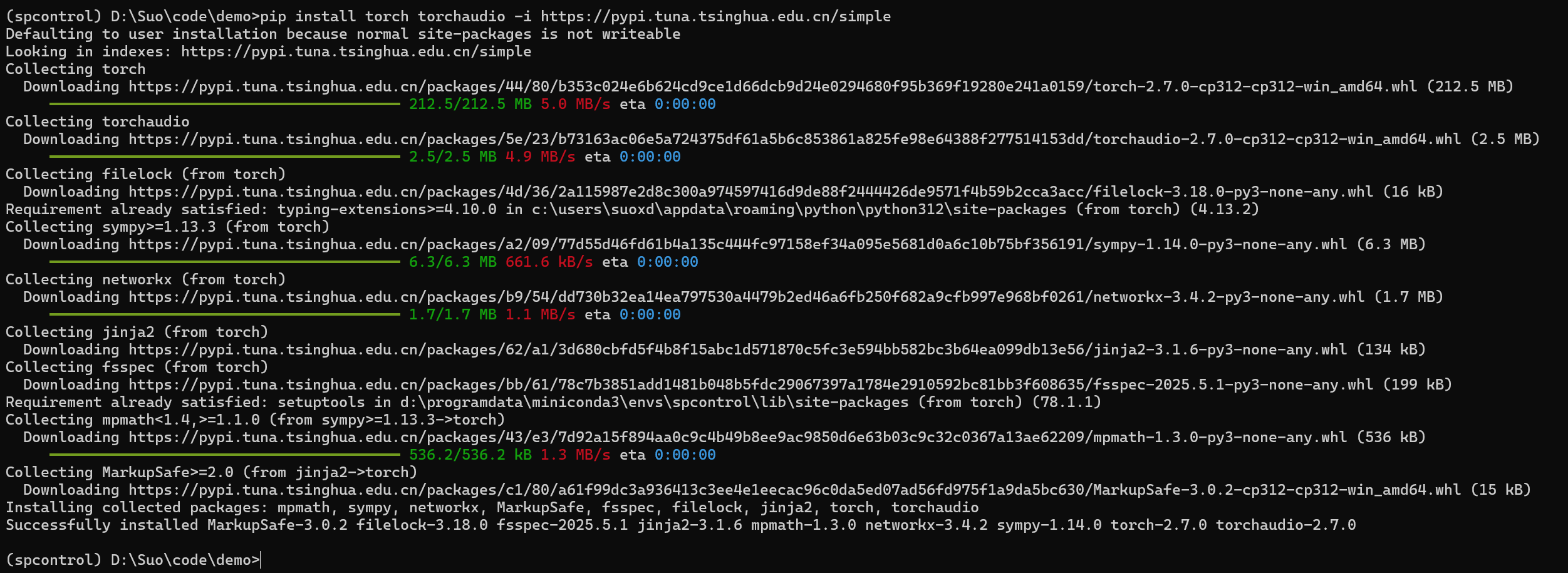
pip install torch torchaudio -i https://pypi.tuna.tsinghua.edu.cn/simple
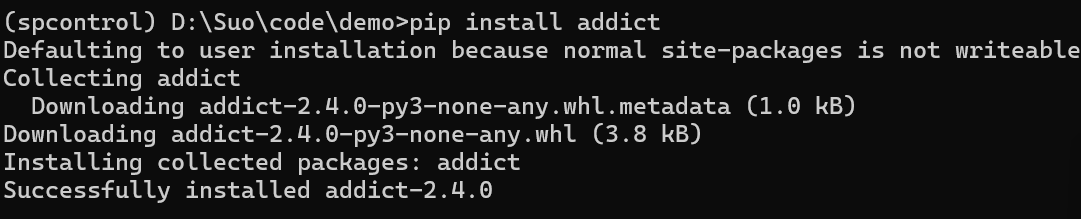
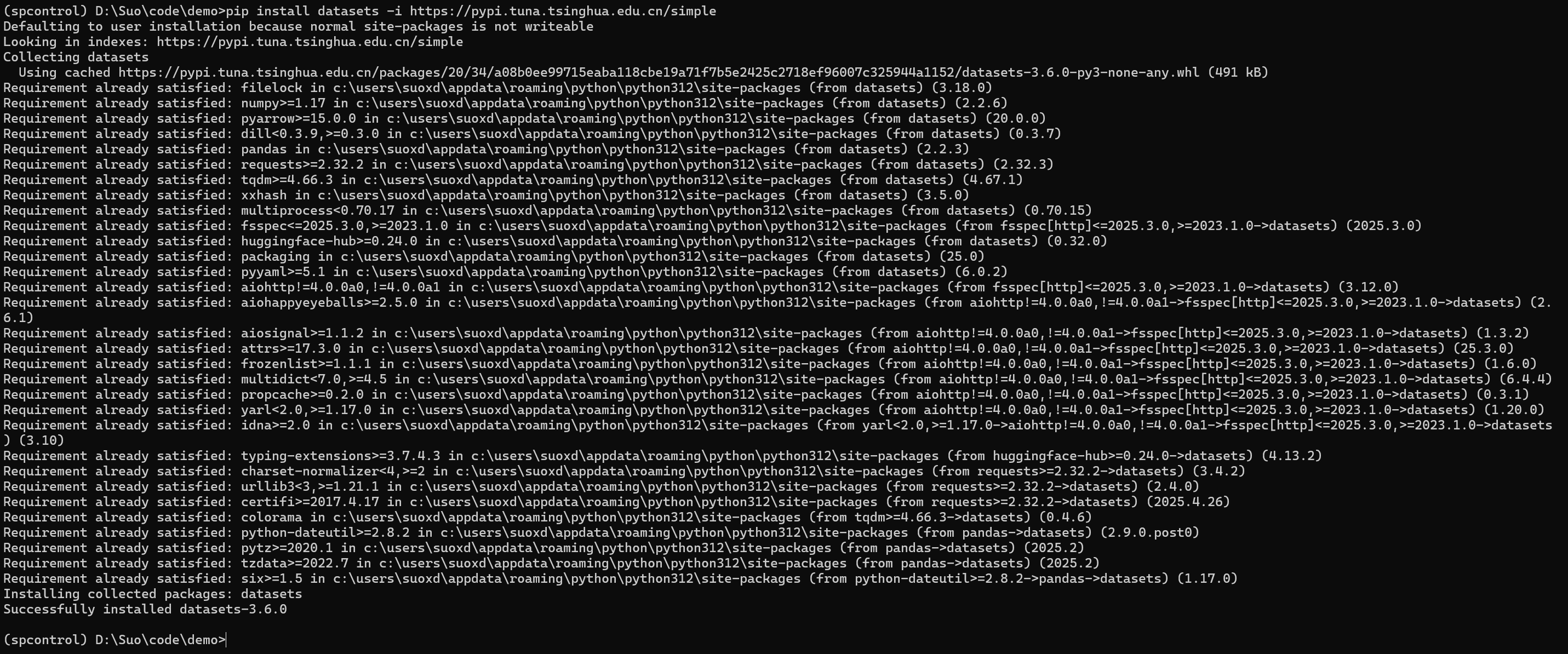
pip install addict, datasets -i https://pypi.tuna.tsinghua.edu.cn/simple
4. 模式一:使用本地模型
4.1 程序編碼(本地模型)
from funasr import AutoModelmodel = AutoModel(model="./speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch",disable_update=True,device="cpu" # 或 "cuda" 如果有GPU
)
res = model.inference(input="asr_example.wav")
print("識別結果:", res[0]["text"])
4.2. 運行測試(本地模型)

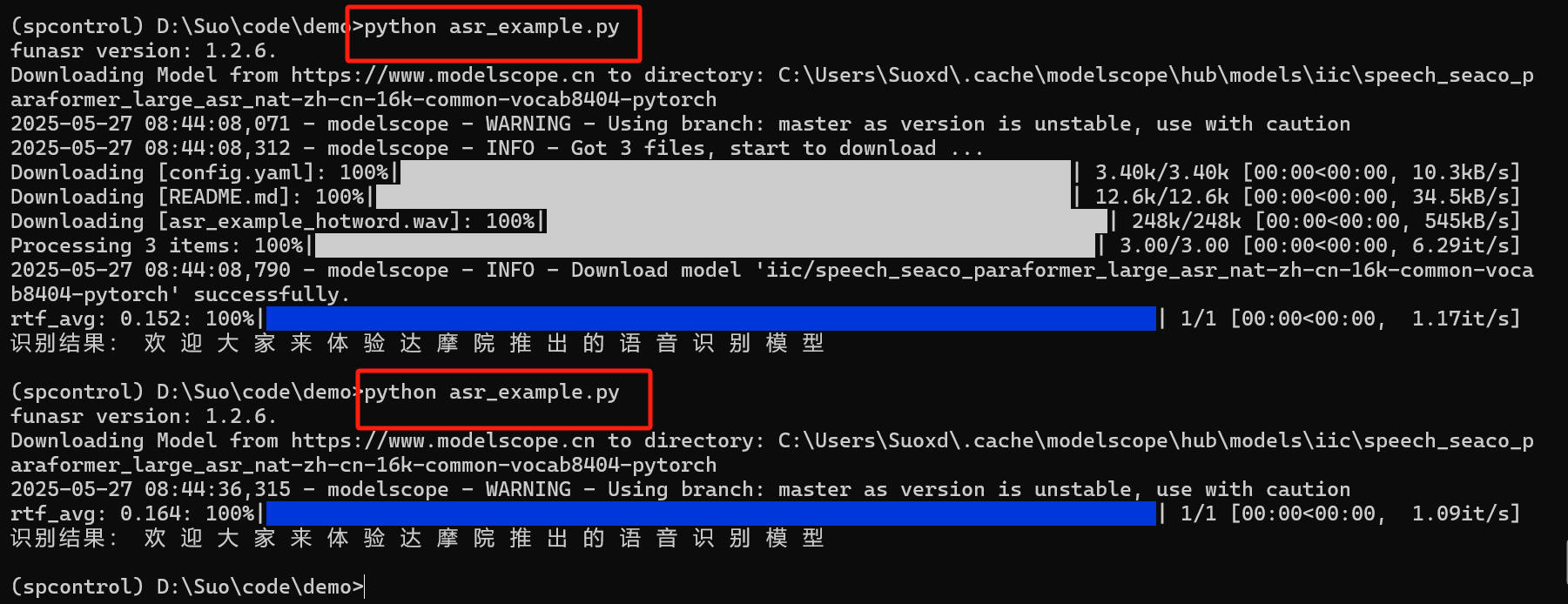
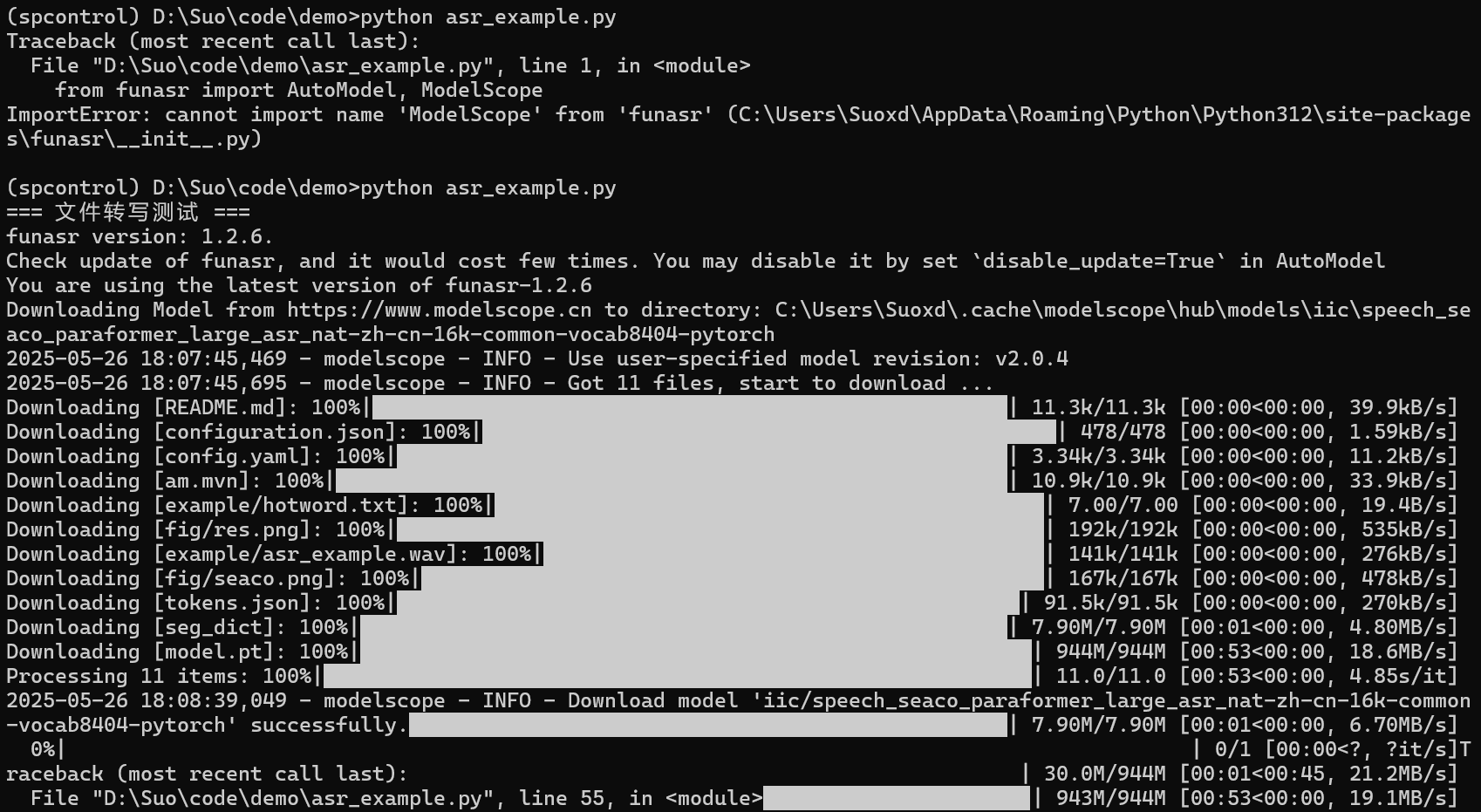
5. 模式二:運行時自動下載模型
5.1 程序編碼(運行時下載模型)
from funasr import AutoModelmodel = AutoModel(model="paraformer-zh",disable_update=True,device="cpu" # 或 "cuda" 如果有GPU
)
res = model.inference(input="asr_example.wav")
print("識別結果:", res[0]["text"])
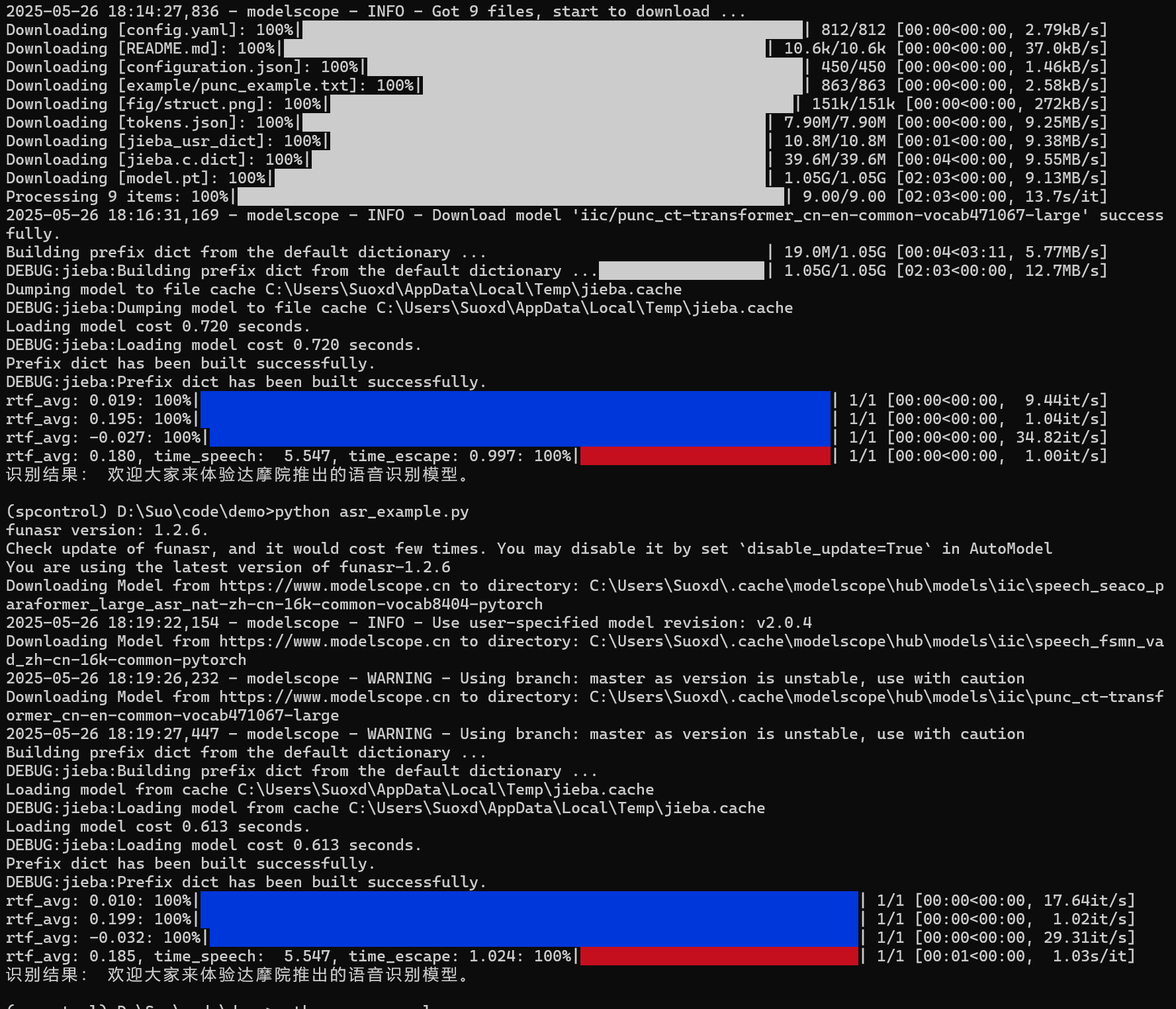
5.2 運行測試(運行時下載模型)
下載后,第二次執行則不再下載,但程序啟動會檢查。
6. 模式三:指定vad等子模型
6.1 程序編碼(指定子模型)
from funasr import AutoModelmodel = AutoModel(model="paraformer-zh",model_revision="v2.0.4",vad_model="fsmn-vad",punc_model="ct-punc",disable_update=True,device="cpu" # 或 "cuda" 如果有GPU
)
res = model.inference(input="asr_example.wav")
print("識別結果:", res[0]["text"])
6.2 運行測試(指定子模型)
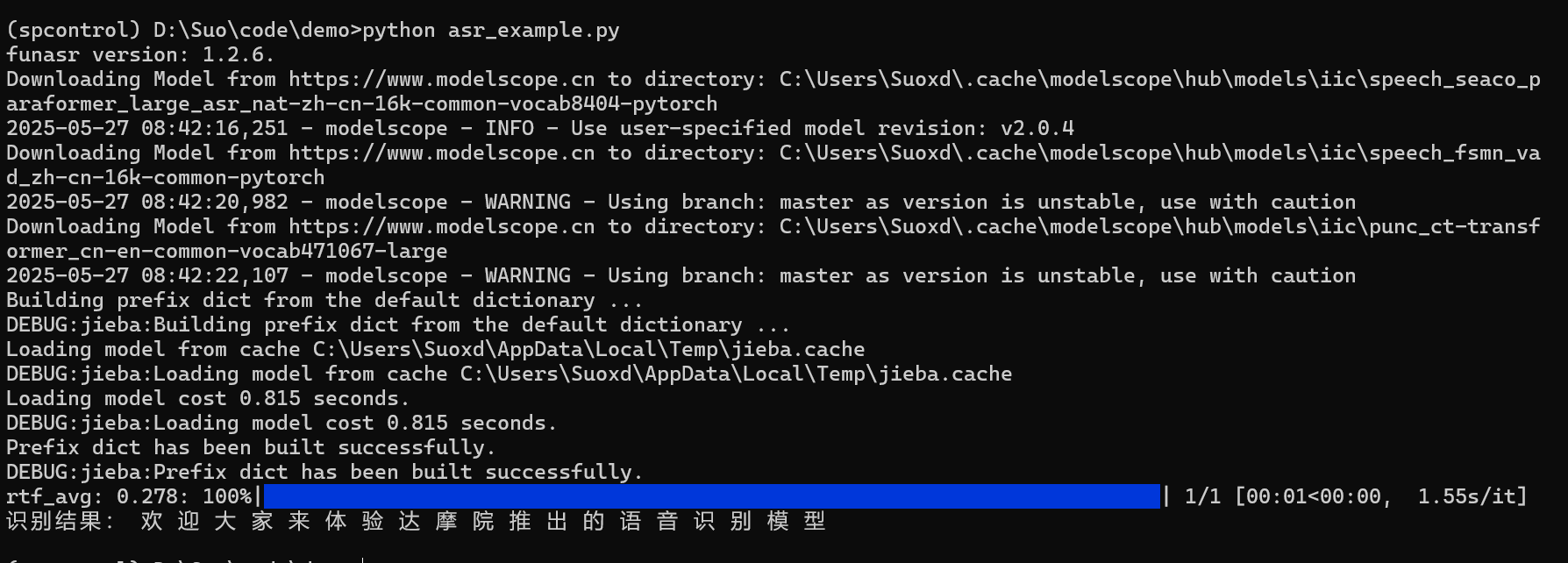
7. 模式四:使用generate
7.1 程序編碼(使用generate)
from funasr import AutoModel
import soundfile as sfmodel = AutoModel(model="paraformer-zh",model_revision="v2.0.4",vad_model="fsmn-vad",punc_model="ct-punc",disable_update=True,device="cpu" # 或 "cuda" 如果有GPU
)
waveform, _ = sf.read("asr_example.wav")result = model.generate(input=waveform)
print("識別結果:", result[0]["text"])
7.2 運行測試(使用generate)
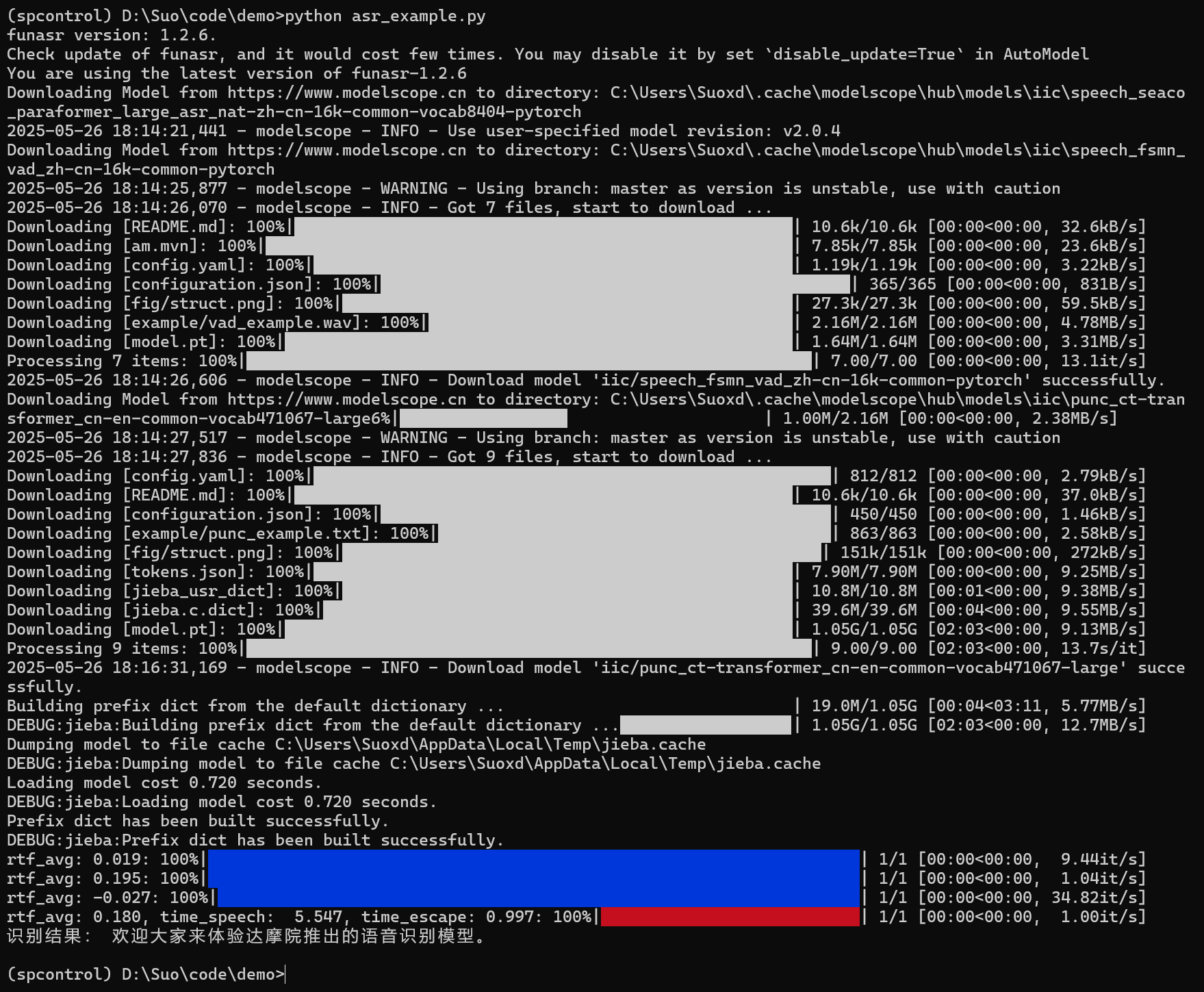
第二次運行不會下載模型。
# 創建虛擬環境
python -m venv sensevoice_env
source sensevoice_env/bin/activate # Linux/macOS
sensevoice_env\Scripts\activate # Windows# 安裝 SenseVoice 依賴
pip install torch torchaudio numpy

)


Java學習-5.19(地址管理,三級聯動,預支付))














)