
?參考:DeepSeek“開源周”收官,連續五天到底都發布了什么?
目錄
一、首日開源-FlashMLA
二、Day2 DeepEP
三、Day3 DeepGEMM
四、Day4 DualPipe & EPLB
五、Day5 3FS & Smallpond
總結
一、首日開源-FlashMLA
多頭部潛在注意力機制(Multi-head Latent Attention)
https://github.com/deepseek-ai/FlashMLA (CUDA)
這是專為英偉達Hopper GPU(H100)優化的高效MLA解碼內核,專為處理可變長度序列設計。
在自然語言處理等任務里,數據序列長度不一,傳統處理方式會造成算力浪費。而FlashMLA如同智能交通調度員,能依據序列長度動態調配計算資源。例如在同時處理長文本和短文本時,它可以精準地為不同長度的文本分配恰當的算力,避免 “大馬拉小車” 或資源不足的情況。發布6小時內,GitHub上收藏量突破5000次,被認為對國產GPU性能提升意義重大。
具體講解:【DeepSeek開源周】Day 1:FlashMLA 學習筆記_自然語言處理_藍海星夢-DeepSeek技術社區
-
傳統的MHA機制
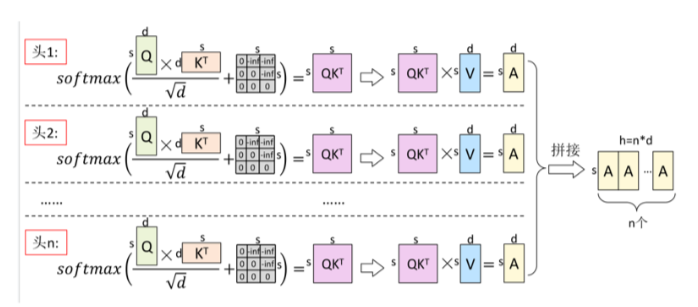
-
DeepSeek-V3的MLA機制
MLA 是多頭部潛在注意力機制(Multi-head Latent Attention),其本質是對KV的有損壓縮,提高存儲信息密度的同時盡可能保留關鍵細節。 它的核心原理是對注意力鍵(Key)和值(Value)進行低秩壓縮,使用兩個線性層和來代替一個大的 Key/Value 投影矩陣,將輸入投影到一個低維空間,然后將其投影回原始維度,從而減少存儲和計算量。此外,MLA 還可對查詢(Query)進行低秩壓縮,以進一步減少激活內存。
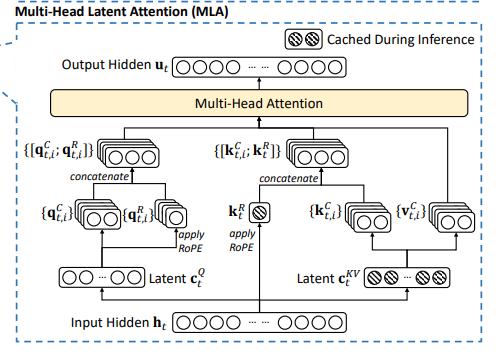
針對MLA與MHA的通俗解釋
MLA(Multi-head Latent Attention)和 MHA(Multi-Head Attention)都可以用來實現注意力機制,但它們并不是完全并行的“思考方式”選擇,而是針對不同目標優化的設計。
我們可以用圖書館查閱的比喻來理解兩者的核心差異:
-
MHA 的思考方式:想象你在一個傳統的巨型圖書館查閱資料,每本書(每個注意力頭)都完整保留所有原始內容(完整 K/V 緩存),書架按主題(頭數 h)嚴格分區。查閱時每次需要回答問題(計算注意力),必須跑到每個主題區(每個頭)翻遍對應書架的所有書籍(加載全部 K/V)
-
MLA 的思考方式:更像是現代化數字圖書館,書籍壓縮歸檔。將相似主題的書籍(h 個頭)打包成精華合輯(若干組潛在狀態),只保留核心摘要(潛在 K/V),同時為每個合輯建立關鍵詞標簽(潛在變量),實時更新內容概要。查閱時先通過關鍵詞標簽(潛在狀態)定位相關合輯(組),快速瀏覽摘要(全局注意力),必要時調取合輯內的原始書籍(局部注意力),但頻次大幅降低。
相比之下,MHA方式中每個主題區存在重復內容,且隨著藏書量增加(序列變長),找書耗時將會快速增長(O(n2)復雜度),這樣造成了空間浪費和效率的低下。而MLA找書時間從翻遍全館變為先看目錄再精準查閱(復雜度從降為 O(n) 主導),顯著提升了查找效率。
二、Day2 DeepEP
開源EP通信庫
https://github.com/deepseek-ai/DeepEP(CUDA)
博客講解:【DeepSeek開源周】Day 2:DeepEP 學習筆記_開源_藍海星夢-DeepSeek技術社區
DeepEP是首個用于MoE(混合專家模型)訓練和推理的開源EP通信庫。MoE模型訓練和推理中,不同專家模型需高效協作,這對通信效率要求極高。DeepEP支持優化的全對全通信模式,就像構建了一條順暢的高速公路,讓數據在各個節點間高效傳輸。
它還原生支持FP8低精度運算調度,降低計算資源消耗,并且在節點內和節點間都支持NVLink和RDMA,擁有用于訓練和推理預填充的高吞吐量內核以及用于推理解碼的低延遲內核。簡單來說,它讓MoE模型各部分間溝通更快、消耗更少,提升了整體運行效率 。
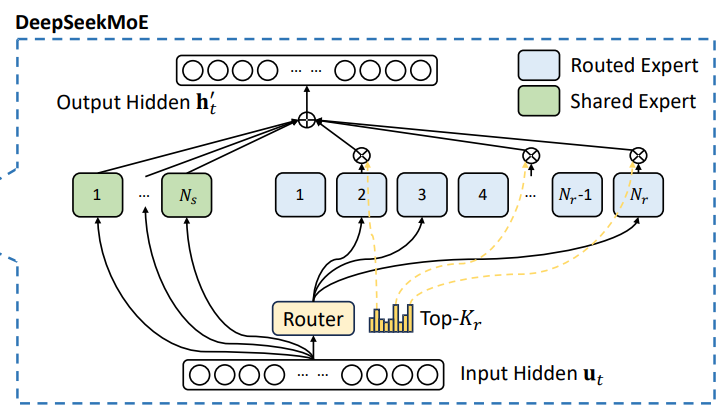
在 DeepSeek‐V3 的 MoE 模塊中,主要包含兩類專家:
-
路由專家(Routed Experts):每個 MoE 層包含 256 個路由專家,這些專家主要負責處理輸入中某些特定、專業化的特征。
-
共享專家(Shared Expert):每個 MoE 層中還有 1 個共享專家,用于捕捉通用的、全局性的知識,為所有輸入提供基本的特征提取支持。
token傳入MoE時的處理流程:
-
計算得分:首先,經過一個專門的 Gate 網絡,該網絡負責計算 token 與各個路由專家之間的匹配得分。
-
選擇專家:基于得分,Gate 網絡為每個 token 選擇 Top-K 個最合適的路由專家(DeepSeek‐V3 中通常選擇 8 個)
-
各自處理:被選中的專家各自對 token 進行獨立處理,產生各自的輸出。
-
合并輸出:最終,根據 Gate 網絡給出的權重加權聚合這些專家的輸出,再與共享專家的輸出進行融合,形成當前 MoE 層的最終輸出表示。
三、Day3 DeepGEMM
矩陣乘法加速庫
https://github.com/deepseek-ai/DeepGEMM(python)
博客:【DeepSeek開源周】Day 3:DeepGEMM 學習筆記_學習_藍海星夢-DeepSeek技術社區
矩陣乘法加速庫,為V3/R1的訓練和推理提供支持。通用矩陣乘法是眾多高性能計算任務的核心,其性能優化是大模型降本增效的關鍵。DeepGEMM采用了DeepSeek-V3中提出的細粒度scaling技術,僅用300行代碼就實現了簡潔高效的FP8通用矩陣乘法。
它支持普通GEMM以及專家混合(MoE)分組GEMM,在Hopper GPU上最高可達到1350+ FP8 TFLOPS(每秒萬億次浮點運算)的計算性能,在各種矩陣形狀上的性能與專家調優的庫相當,甚至在某些情況下更優,且安裝時無需編譯,通過輕量級JIT模塊在運行時編譯所有內核。
-
核心亮點
-
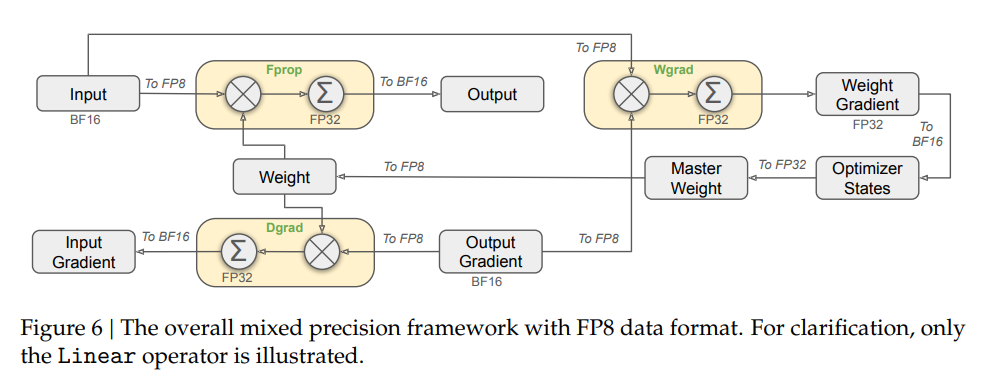
FP8 低精度支持:DeepGEMM 最大的特色在于從架構上優先設計為 FP8 服務。傳統GEMM庫主要優化FP16和FP32,而DeepGEMM針對FP8的特殊性進行了優化設計。
-
極致性能與極簡核心實現:DeepGEMM在NVIDIA Hopper GPU上實現了高達1350+ FP8 TFLOPS的計算性能,同時其核心代碼僅有約300行
-
JIT 即時編譯:DeepGEMM 不是預先編譯好所有可能配置的內核,而是利用 JIT 在運行時生成最佳內核。例如,根據矩陣大小、FP8尺度等參數,JIT 會即時優化指令順序和寄存器分配。
-
傳統矩陣乘法 vs. DeepGEMM算法
| 特性 | 傳統矩陣乘法 | DeepGEMM算法 |
| 計算方式 | 逐元素順序計算,無并行加速 | 利用GPU并行計算,分塊處理,使用張量核心等優化 |
| 計算速度 | 慢,尤其在大規模矩陣時效率低下 | 極快,能在短時間內完成大規模矩陣乘法 |
| 內存使用 | 內存占用高,可能面臨內存不足問題 | 內存管理高效,避免內存瓶頸 |
| 適用場景 | 適用于小型或簡單矩陣運算場景 | 專為大規模矩陣運算設計,如深度學習模型訓練和推理 |
四、Day4 DualPipe & EPLB
DualPipe:https://github.com/deepseek-ai/DualPipe(python)
EPLB:https://github.com/deepseek-ai/EPLB(python)
博文:https://deepseek.csdn.net/67da0cb5807ce562bfe34746.html
DualPipe是一種用于V3/R1訓練中計算與通信重疊的雙向管道并行算法。以往的管道并行存在 “氣泡” 問題,即計算和通信階段存在等待時間,造成資源浪費。DualPipe通過實現 “向前” 與 “向后” 計算通信階段的雙向重疊,將硬件資源利用率提升超30%。
EPLB則是一種針對V3/R1的專家并行負載均衡器。基于混合專家(MoE)架構,它通過冗余專家策略復制高負載專家,并結合啟發式分配算法優化GPU間的負載分布,減少GPU閑置現象。
五、Day5 3FS & Smallpond
https://github.com/deepseek-ai/3FS(C++)
https://github.com/deepseek-ai/smallpond (python)
博文:https://deepseek.csdn.net/67db6b09b8d50678a24ed021.html
DeepSeep開源了面向全數據訪問的推進器3FS,也就是Fire-Flyer文件系統。它是一個專門為了充分利用現代SSD和RDMA網絡帶寬而設計的并行文件系統,能實現高速數據訪問,提升AI模型訓練和推理的效率。
此外,DeepSeek還開源了基于3FS的數據處理框架Smallpond,它可以進一步優化3FS的數據管理能力,讓數據處理更加方便、快捷。
總結
在 2025 年 2 月 24 日至 28 日的 DeepSeek 開源周期間,DeepSeek 開源了五個核心項目,這些項目涵蓋了 AI 開發的計算優化、通信效率和存儲加速等關鍵領域,共同構成了一個面向大規模 AI 的高性能基礎設施。
-
FlashMLA:針對 NVIDIA Hopper GPU 優化的多頭線性注意力解碼內核,顯著提升了推理效率,支持實時翻譯和長文本處理。
-
DeepEP:專為混合專家模型(MoE)設計的通信庫,通過優化節點間數據分發與合并,大幅提升了訓練速度。
-
DeepGEMM:基于 FP8 的高效矩陣乘法庫,專為 MoE 模型優化,顯著提升了大規模矩陣運算效率。
-
DualPipe & EPLB:創新的雙向流水線并行算法和動態負載均衡工具,優化了資源利用率,提升了并行訓練效率。
-
3FS & Smallpond:高性能分布式文件系統,支持 RDMA 網絡和 SSD 存儲,解決了海量數據的高速存取與管理問題。
參考:
https://devpress.csdn.net/user/Eternity__Aurora
https://github.com/orgs/deepseek-ai/repositories?type=all
)


Java學習-5.19(地址管理,三級聯動,預支付))














)
