https://www.bilibili.com/video/BV1YyHSekEE2
這張圖片展示的是生成對抗網絡(GANs)中的損失函數公式,特別是針對判別器(Discriminator)和生成器(Generator)的優化目標。讓我們用Markdown格式逐步解析這些公式:
GAN的基本優化目標
markdown
深色版本
min ? G max ? D V ( D , G ) = E x ~ p d a t a ( x ) [ log ? D ( x ) ] + E z ~ p z ( z ) [ log ? ( 1 ? D ( G ( z ) ) ) ] \min_G \max_D V(D, G) = \mathbb{E}_{\boldsymbol{x} \sim p_{data}(\boldsymbol{x})}[\log D(\boldsymbol{x})] + \mathbb{E}_{\boldsymbol{z} \sim p_{\boldsymbol{z}}(\boldsymbol{z})}[\log(1 - D(G(\boldsymbol{z})))] Gmin?Dmax?V(D,G)=Ex~pdata?(x)?[logD(x)]+Ez~pz?(z)?[log(1?D(G(z)))]
min ? G max ? D \min_G \max_D minG?maxD? 表示:這是一個最小最大博弈問題,其中生成器 G 和判別器 D 在相互競爭中進行優化。
E x ~ p d a t a ( x ) \mathbb{E}_{\boldsymbol{x} \sim p_{data}(\boldsymbol{x})} Ex~pdata?(x)?:表示對真實數據分布 p d a t a ( x ) p_{data}(\boldsymbol{x}) pdata?(x) 的期望值計算。
E z ~ p z ( z ) \mathbb{E}_{\boldsymbol{z} \sim p_{\boldsymbol{z}}(\boldsymbol{z})} Ez~pz?(z)?:表示對噪聲分布 p z ( z ) p_{\boldsymbol{z}}(\boldsymbol{z}) pz?(z) 的期望值計算。
D ( x ) D(\boldsymbol{x}) D(x):判別器輸出的真實樣本的概率。
G ( z ) G(\boldsymbol{z}) G(z):生成器根據噪聲 z \boldsymbol{z} z 生成的樣本。
log ? D ( x ) \log D(\boldsymbol{x}) logD(x) 和 log ? ( 1 ? D ( G ( z ) ) ) \log(1 - D(G(\boldsymbol{z}))) log(1?D(G(z))):分別代表判別器正確識別真實樣本和錯誤識別生成樣本的對數概率。
判別器的損失函數
markdown
深色版本
l o s s d = ? ( 1 N ∑ i = 1 N y i log ? ( p i ) + ( 1 ? y i ) log ? ( 1 ? p i ) ) loss_d = -\left(\frac{1}{N}\sum_{i=1}^{N}y_i\log(p_i) + (1-y_i)\log(1-p_i)\right) lossd?=?(N1?i=1∑N?yi?log(pi?)+(1?yi?)log(1?pi?))
這是一個二分類交叉熵損失函數,用于衡量判別器在區分真實和生成樣本時的性能。
y i y_i yi? 是標簽(1表示真實樣本,0表示生成樣本), p i p_i pi? 是判別器預測的概率。
判別器損失函數的具體形式
markdown
深色版本
l o s s d = ? ( 1 N ∑ i = 1 N y i log ? ( D ( i m a g e i ) ) + ( 1 ? y i ) log ? ( 1 ? D ( i m a g e i ) ) ) loss_d = -\left(\frac{1}{N}\sum_{i=1}^{N}y_i\log(D(image_i)) + (1-y_i)\log(1-D(image_i))\right) lossd?=?(N1?i=1∑N?yi?log(D(imagei?))+(1?yi?)log(1?D(imagei?)))
這里將 p i p_i pi? 替換為 D ( i m a g e i ) D(image_i) D(imagei?),即判別器對圖像 i m a g e i image_i imagei? 的輸出概率。
判別器損失函數的進一步分解
markdown
深色版本
min ? l o s s d = ? ( 1 N r e a l ∑ i log ? ( D ( x i ) ) + 1 N f a k e ∑ i log ? ( 1 ? D ( G ( z i ) ) ) ) \min loss_d = -\left(\frac{1}{N_{real}}\sum_i\log(D(x_i)) + \frac{1}{N_{fake}}\sum_i\log(1-D(G(z_i)))\right) minlossd?=?(Nreal?1?i∑?log(D(xi?))+Nfake?1?i∑?log(1?D(G(zi?))))
這個公式明確地將損失分為兩部分:一部分是對于真實樣本 x i x_i xi? 的損失,另一部分是對于生成樣本 G ( z i ) G(z_i) G(zi?) 的損失。
最大化判別器的目標
markdown
深色版本
max ? 1 N r e a l ∑ i log ? ( D ( x i ) ) + 1 N f a k e ∑ i log ? ( 1 ? D ( G ( z i ) ) ) \max \frac{1}{N_{real}}\sum_i\log(D(x_i)) + \frac{1}{N_{fake}}\sum_i\log(1-D(G(z_i))) maxNreal?1?i∑?log(D(xi?))+Nfake?1?i∑?log(1?D(G(zi?)))
這個公式展示了判別器的目標是最大化其對真實樣本的識別能力和對生成樣本的拒絕能力。
通過上述公式,我們了解了GAN中判別器和生成器之間的博弈過程,以及如何通過優化損失函數來訓練這兩個模型,以達到生成高質量樣本的目的。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms# 定義生成器
class Generator(nn.Module):def __init__(self):super(Generator, self).__init__()self.main = nn.Sequential(nn.Linear(100, 256),nn.ReLU(True),nn.Linear(256, 256),nn.ReLU(True),nn.Linear(256, 784),nn.Tanh())def forward(self, input):return self.main(input)# 定義判別器
class Discriminator(nn.Module):def __init__(self):super(Discriminator, self).__init__()self.main = nn.Sequential(nn.Linear(784, 256),nn.ReLU(True),nn.Linear(256, 256),nn.ReLU(True),nn.Linear(256, 1),nn.Sigmoid())def forward(self, input):return self.main(input)# 初始化模型、損失函數和優化器
generator = Generator()
discriminator = Discriminator()criterion = nn.BCELoss() # Binary Cross Entropy Loss
optimizer_g = optim.Adam(generator.parameters(), lr=0.0002)
optimizer_d = optim.Adam(discriminator.parameters(), lr=0.0002)# 加載MNIST數據集
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize([0.5], [0.5])])
train_loader = torch.utils.data.DataLoader(datasets.MNIST('data', train=True, download=True, transform=transform), batch_size=64, shuffle=True)# 訓練循環
num_epochs = 10
for epoch in range(num_epochs):for i, (imgs, _) in enumerate(train_loader):# 準備數據valid = torch.ones(imgs.size(0), 1)fake = torch.zeros(imgs.size(0), 1)real_imgs = imgs.view(imgs.size(0), -1)# 訓練判別器optimizer_d.zero_grad()z = torch.randn(imgs.size(0), 100)gen_imgs = generator(z)loss_real = criterion(discriminator(real_imgs), valid)loss_fake = criterion(discriminator(gen_imgs.detach()), fake)loss_d = (loss_real + loss_fake) / 2loss_d.backward()optimizer_d.step()# 訓練生成器optimizer_g.zero_grad()loss_g = criterion(discriminator(gen_imgs), valid)loss_g.backward()optimizer_g.step()print(f"Epoch [{epoch}/{num_epochs}] Loss D: {loss_d.item()}, loss G: {loss_g.item()}")print('訓練完成')
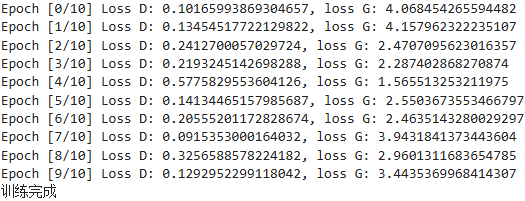
判別器損失(Loss D)
趨勢:判別器損失在訓練過程中表現出較大的波動性。初期較低(<0.2),中期升高(最高達到0.5776),然后又回落。
解釋:這表明模型在學習過程中經歷了不同的階段,其中生成器在某些時期能夠較好地欺騙判別器,導致判別器的損失增加。
生成器損失(Loss G)
趨勢:生成器損失從最初的較高水平逐漸下降到最低點(1.5655),然后有所回升并在后續的epoch中保持在一個相對較高的水平(約2.5至4之間)。
解釋:這種模式可能意味著生成器的學習速率與判別器相比不夠平衡,或者存在過擬合現象。特別是在第4個epoch之后,生成器損失的上升可能表示生成器遇到了瓶頸或難以進一步優化。
🔍 結論與建議
穩定性問題:由于損失值的大幅波動,可能需要調整超參數來穩定訓練過程。比如:
調整學習率。
應用梯度懲罰或其他正則化技術以增強訓練穩定性。
網絡架構或數據集問題:如果損失值持續不穩定,考慮檢查數據集是否足夠多樣化,以及網絡架構是否有改進空間。
早期停止策略:可以實施早期停止策略來防止過擬合,并確保模型在驗證集上的性能不會惡化。
可視化:定期保存并查看生成樣本,可以幫助理解模型的實際表現和進步情況。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms, utils
import matplotlib.pyplot as plt# 檢查是否可用 CUDA
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")# -----------------------------
# 模型定義
# -----------------------------
class Generator(nn.Module):def __init__(self):super(Generator, self).__init__()self.main = nn.Sequential(nn.Linear(100, 256),nn.ReLU(True),nn.Linear(256, 256),nn.ReLU(True),nn.Linear(256, 784),nn.Tanh())def forward(self, input):return self.main(input)class Discriminator(nn.Module):def __init__(self):super(Discriminator, self).__init__()self.main = nn.Sequential(nn.Linear(784, 256),nn.ReLU(True),nn.Linear(256, 256),nn.ReLU(True),nn.Linear(256, 1),nn.Sigmoid())def forward(self, input):return self.main(input)# -----------------------------
# 初始化模型和優化器
# -----------------------------
generator = Generator().to(device)
discriminator = Discriminator().to(device)criterion = nn.BCELoss()
optimizer_g = optim.Adam(generator.parameters(), lr=0.0002)
optimizer_d = optim.Adam(discriminator.parameters(), lr=0.0002)# -----------------------------
# 數據加載
# -----------------------------
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize([0.5], [0.5])
])train_loader = torch.utils.data.DataLoader(datasets.MNIST('data', train=True, download=True, transform=transform),batch_size=64,shuffle=True
)# -----------------------------
# 可視化函數
# -----------------------------
def show_images(images, epoch):images = images.view(-1, 1, 28, 28)grid = utils.make_grid(images, nrow=4, normalize=True)plt.figure(figsize=(5, 5))plt.title(f"Epoch {epoch}")plt.imshow(grid.permute(1, 2, 0).cpu())plt.axis("off")plt.show()# 固定噪聲,用于每輪觀察生成效果變化
fixed_noise = torch.randn(16, 100, device=device)# -----------------------------
# 訓練循環
# -----------------------------
num_epochs = 20for epoch in range(num_epochs):for i, (imgs, _) in enumerate(train_loader):imgs = imgs.to(device)real_labels = torch.ones(imgs.size(0), 1).to(device)fake_labels = torch.zeros(imgs.size(0), 1).to(device)# ---------------------# 訓練判別器# ---------------------optimizer_d.zero_grad()real_imgs = imgs.view(imgs.size(0), -1)d_real_loss = criterion(discriminator(real_imgs), real_labels)z = torch.randn(imgs.size(0), 100).to(device)gen_imgs = generator(z).detach()d_fake_loss = criterion(discriminator(gen_imgs), fake_labels)loss_d = (d_real_loss + d_fake_loss) / 2loss_d.backward()optimizer_d.step()# ---------------------# 訓練生成器# ---------------------optimizer_g.zero_grad()gen_imgs = generator(z)loss_g = criterion(discriminator(gen_imgs), real_labels)loss_g.backward()optimizer_g.step()print(f"Epoch [{epoch}/{num_epochs}] Loss D: {loss_d.item():.4f}, Loss G: {loss_g.item():.4f}")# 每個epoch結束后可視化生成結果with torch.no_grad():generated = generator(fixed_noise).cpu()show_images(generated, epoch)print("訓練完成")
加入可視化

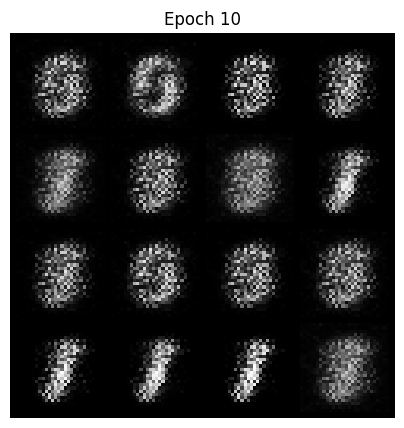


https://www.kaggle.com/code/alihhhjj/notebook8be232dcc8
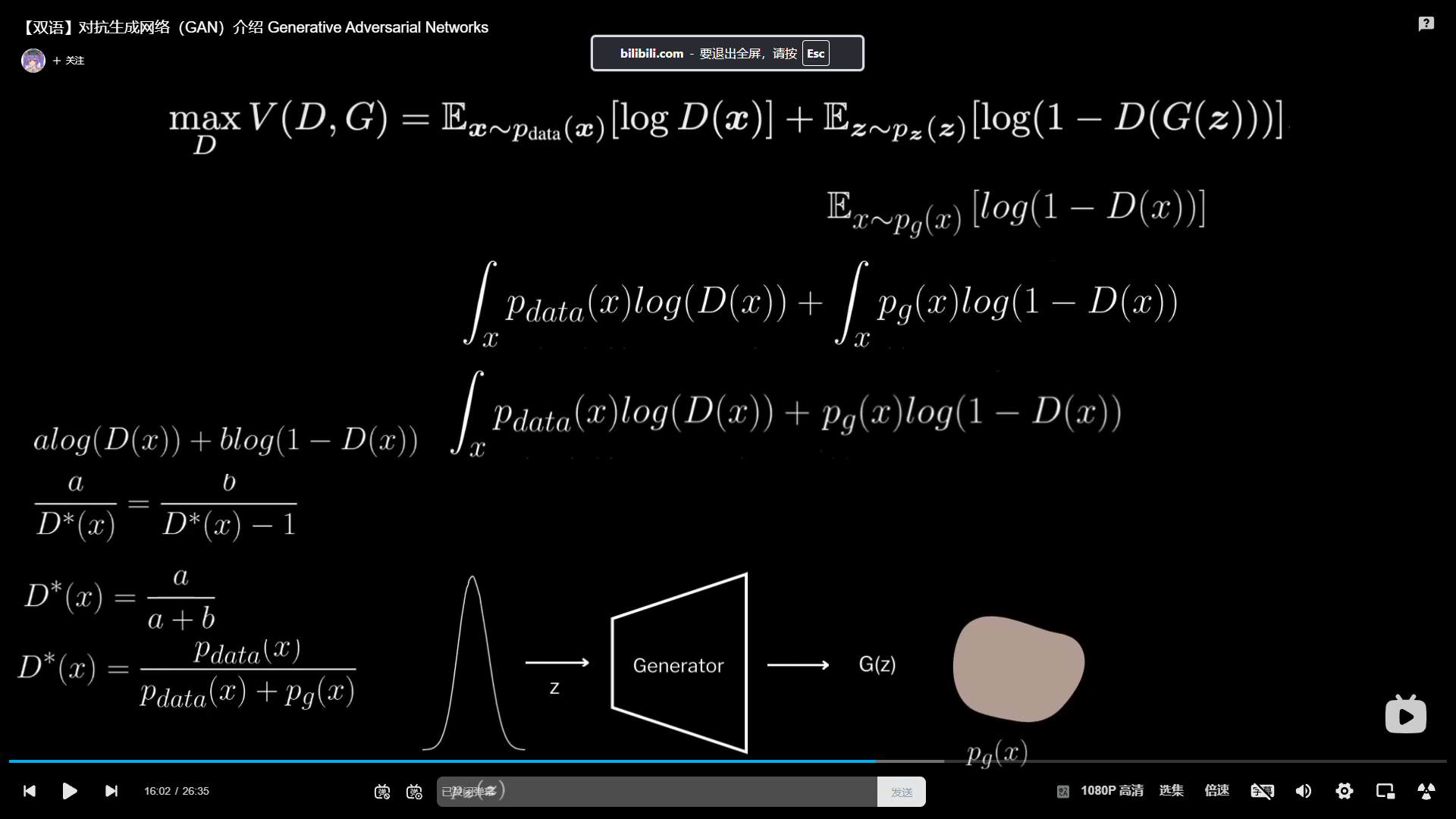
判別器最優解 $ D^*(x) $ 的推導
在生成對抗網絡(GAN)中,判別器的目標是最大化以下目標函數:
V ( D , G ) = E x ~ p d a t a ( x ) [ log ? D ( x ) ] + E z ~ p z ( z ) [ log ? ( 1 ? D ( G ( z ) ) ) ] V(D, G) = \mathbb{E}_{\boldsymbol{x} \sim p_{data}(\boldsymbol{x})}[\log D(\boldsymbol{x})] + \mathbb{E}_{\boldsymbol{z} \sim p_z(\boldsymbol{z})}[\log(1 - D(G(\boldsymbol{z})))] V(D,G)=Ex~pdata?(x)?[logD(x)]+Ez~pz?(z)?[log(1?D(G(z)))]
固定生成器 $ G $,我們希望找到使 $ V(D, G) $ 最大化的最優判別器 $ D^*(x) $。
一、簡化目標函數
考慮對某個固定的輸入樣本 $ x $,我們可以將目標函數簡化為一個關于 $ D(x) $ 的函數:
L ( D ( x ) ) = a log ? D ( x ) + b log ? ( 1 ? D ( x ) ) L(D(x)) = a \log D(x) + b \log (1 - D(x)) L(D(x))=alogD(x)+blog(1?D(x))
其中:
- $ a = p_{data}(x) $:真實數據分布中 $ x $ 的概率密度;
- $ b = p_g(x) $:生成器生成的數據分布中 $ x $ 的概率密度。
二、求極值:令導數為零
對 $ D(x) $ 求導并令其等于 0:
d L d D ( x ) = a D ( x ) ? b 1 ? D ( x ) = 0 \frac{dL}{dD(x)} = \frac{a}{D(x)} - \frac{b}{1 - D(x)} = 0 dD(x)dL?=D(x)a??1?D(x)b?=0
整理得:
a D ( x ) = b 1 ? D ( x ) \frac{a}{D(x)} = \frac{b}{1 - D(x)} D(x)a?=1?D(x)b?
這就是你看到的等式形式:
a D ? ( x ) = b 1 ? D ? ( x ) \frac{a}{D^*(x)} = \frac{b}{1 - D^*(x)} D?(x)a?=1?D?(x)b?
三、解方程求出 $ D^*(x) $
交叉相乘:
a ( 1 ? D ? ( x ) ) = b D ? ( x ) a(1 - D^*(x)) = b D^*(x) a(1?D?(x))=bD?(x)
展開并整理:
a = a D ? ( x ) + b D ? ( x ) ? a = D ? ( x ) ( a + b ) a = a D^*(x) + b D^*(x) \Rightarrow a = D^*(x)(a + b) a=aD?(x)+bD?(x)?a=D?(x)(a+b)
解得:
D ? ( x ) = a a + b D^*(x) = \frac{a}{a + b} D?(x)=a+ba?
代入 $ a = p_{data}(x), b = p_g(x) $,得到最終結果:
D ? ( x ) = p d a t a ( x ) p d a t a ( x ) + p g ( x ) D^*(x) = \frac{p_{data}(x)}{p_{data}(x) + p_g(x)} D?(x)=pdata?(x)+pg?(x)pdata?(x)?
四、意義
這表示在給定輸入樣本 $ x $ 的情況下,最優判別器 $ D^*(x) $ 輸出的是該樣本來自真實數據分布而非生成分布的概率。







![[java]eclipse中windowbuilder插件在線安裝](http://pic.xiahunao.cn/[java]eclipse中windowbuilder插件在線安裝)

)





視頻彈題功能實例)

—— 評估算法(一))

沒有之一,已親自使用!)





