文章目錄
- 一、作者
- 二、摘要
- 三、相關工作
- 四、算法概述
- 五、實驗結果
- 六、主要貢獻
一、作者
??Yaroslav Akhremtsev, Tobias Heuer, Peter Sanders, Sebastian Schlag
二、摘要
??我們開發了一種快速且高質量的多層算法,能夠直接將超圖劃分為 k 個平衡的塊 —— 無需借助遞歸二分法這一迂回方式。特別是,我們的算法能有效實現強大的 FM 局部搜索啟發式算法,使其適用于復雜的 k 路情況。這對于依賴超邊所連接塊數的那些目標函數來說意義重大。此外,我們還消除了處理大型超邊的多個瓶頸,開發了一種更快的收縮算法以及一種新的局部搜索自適應停止規則。為進一步縮小超邊規模,我們基于 min - hashing 技術開發了一種將具有相似鄰域的頂點聚類的引腳稀疏化方法。大量實驗表明,我們的 KaHyPar 劃分器與其他最佳的先前系統相比具有優勢。KaHyPar 比 hMetis 更快且計算出的解更好。相比于(速度更快的)PaToH 劃分器,KaHyPar 的結果要好得多。
三、相關工作
- 研究現狀:
- 常用工具
- PaToH[7](科學計算)
- hMetis[8] [9](VLSI 設計)
- Mondriaan[10](稀疏矩陣劃分)
- MLPart[11](電路劃分)
- Zoltan[12]、Parkway[13]、UMPa[14](定向超圖模型,多目標)
- kPaToH[15](多約束,固定頂點)
- 其他文獻
- n 級范式一直運用于基于隨機增量結構的幾何數據結構[2] [3] 和布線計劃的預處理階段[4],而且,也成功運用于圖和超圖的劃分中,例如:KaSPar[5](圖直接 k 劃分) 和 KaHyPar[1](超圖遞歸 k 劃分)。
- 有一個未正式發表的直接 k 路 n 級劃分算法[6],盡管在部分實驗取得不錯的效果,但是運行時間比較長。
- 常用工具
- 準備工作:
- 術語表
| term | explanation |
|---|---|
| H = ( V , E , ω ( v ) , ω ( e ) ) H=(V,E,\omega(v),\omega(e)) H=(V,E,ω(v),ω(e)) | H 表示超圖,V 表示超圖的頂點集,E 表示超圖的超邊集, ω \omega ω 是權重 |
| ? \epsilon ? | 不平衡系數 |
| V x V_x Vx? | 劃分塊 |
| E x E_x Ex? | 包含頂點 x 的超邊集合 |
| d ( v ) = ∣ E v ∣ d(v)=|E_v| d(v)=∣Ev?∣ | 頂點 v 的度 |
| N ( v ) = { v ′ ∣ v ′ ∈ E v ∧ v ′ ≠ v } N(v)=\{v'|v'\in E_v \wedge v' \ne v\} N(v)={v′∣v′∈Ev?∧v′=v} | 頂點 v 的鄰居頂點 |
| P = { V 1 , … , V k ∣ ∪ i = 1 k V i = V ∧ ( V i ∩ V j = ? ? i ≠ j ) } P=\{V_1,\dots,V_k | \cup_{i=1}^k V_i=V \wedge (V_i\cap V_j=\varnothing \Leftrightarrow i \ne j ) \} P={V1?,…,Vk?∣∪i=1k?Vi?=V∧(Vi?∩Vj?=??i=j)} | 劃分 P |
| b ( v ) = { V i ∣ v ∈ V i } b(v)=\{V_i | v \in V_i\} b(v)={Vi?∣v∈Vi?} | 頂點 v 所屬的劃分塊 |
| b ( e ) = { b ( v ) ∣ v ∈ e } b(e)=\{b(v)|v \in e \} b(e)={b(v)∣v∈e} | 超邊 e 所屬的劃分塊 |
| Z ( v ) = { b ( e ) ∣ e ∈ E v } ? { b ( v ) } \Zeta(v)=\{b(e)|e\in E_v\}-\{b(v)\} Z(v)={b(e)∣e∈Ev?}?{b(v)} | 頂點 v 的鄰居劃分塊 |
| Φ ( e , V i ) = ∣ { v ∣ v ∈ e ∧ v ∈ V i } ∣ \Phi(e,V_i)=\big|\{v| v \in e \wedge v \in V_i\}\big| Φ(e,Vi?)= ?{v∣v∈e∧v∈Vi?} ? | 超邊 e 在劃分塊 V i V_i Vi? 的頂點數量 |
| C u t ( e ) = { ω ( e ) , ∣ b ( e ) ∣ > 1 0 , ∣ b ( e ) ∣ = 1 Cut(e)=\begin{cases} \omega(e) &, |b(e)|>1 \\ 0 &, |b(e)|=1 \end{cases} Cut(e)={ω(e)0?,∣b(e)∣>1,∣b(e)∣=1? | e 的割邊權重 |
- \;
- 約束
- 平衡約束
? V i ? P , ω ( V i ) ≤ ( 1 + ? ) ? ω ( V ) k ? \begin{equation} \forall V_i \subseteq P,\;\; \omega(V_i)\le(1+\epsilon) \bigg\lceil \frac{\omega(V)}{k} \bigg\rceil \end{equation} ?Vi??P,ω(Vi?)≤(1+?)?kω(V)????
- 平衡約束
- 目標:
- 最小割邊
min ? ∑ e ∈ E C u t ( e ) \begin{equation} \min \sum\limits_{e\in E} Cut(e) \end{equation} mine∈E∑?Cut(e)?? - 最小連接權重
min ? ∑ e ∈ E ( b ( e ) ? 1 ) ? ω ( e ) \begin{equation} \min \sum\limits_{e\in E} \big(b(e)-1\big) \cdot \omega(e) \end{equation} mine∈E∑?(b(e)?1)?ω(e)??
- 最小割邊
- 約束
四、算法概述
- 基于 Min-Hash 的頂點劃分器【限定頂點的更新范圍】
- 指紋【每個頂點一個指紋,第 i 輪建立 hash 表 T i T_i Ti?,使用指紋分量 g i ( v , z ( v ) ) g_i\big(v,z(v)\big) gi?(v,z(v))作為 key】
{ g i ( x , z ) = ( h i , 1 ( x ) , h i , 2 ( x ) , ? , h i , z ( x ) ) } i = 1 , 2 , ? , l \begin{equation} \{g_i(x,z)=\big(h_{i,1}(x),h_{i,2}(x),\cdots,h_{i,z}(x)\big)\}_{i=1,2,\cdots,l} \end{equation} {gi?(x,z)=(hi,1?(x),hi,2?(x),?,hi,z?(x))}i=1,2,?,l??? - Min-Hash 簇
H = { h σ ( v ) = min ? { σ ( e ) ∣ e ∈ E v } ∣ σ ∈ Σ } \begin{equation} H=\{h_{\sigma}(v)=\min \{ \sigma(e) | e\in E_v\}|\sigma \in \Sigma\} \end{equation} H={hσ?(v)=min{σ(e)∣e∈Ev?}∣σ∈Σ}?? - hash 函數
σ ( x ) = ( a x + b ) m o d P \begin{equation} \sigma(x)=(ax+b)\;mod\;P \end{equation} σ(x)=(ax+b)modP?? - 構建 hash 表
- 初始化:
- 將所有頂點設置為活躍狀態,
- z = 1 , h m i n = 10 , h m a x = 100 z = 1,\;h_{min}=10,\;h_{max}=100 z=1,hmin?=10,hmax?=100
- 建立空表 T。
- 迭代:
- 迭代條件:存在活躍頂點 且 z ≤ h m a x z\le h_{max} z≤hmax?
- 迭代過程:
- 建立 hash 表 T ′ T' T′
- 遍歷所有活躍頂點 v,將活躍頂點按照 { g ( v , z ) , v } \{g(v,z),v\} {g(v,z),v}插入到 T ′ T' T′。
- 遍歷所有活躍頂點 v:
- 如果 ∣ T [ v ] ∣ = ∣ T ′ [ v ] ∣ |T[v]|=|T'[v]| ∣T[v]∣=∣T′[v]∣ 且 z ≥ h m i n z \ge h_{min} z≥hmin?,將 T ′ [ v ] T'[v] T′[v] 的頂點全部標記為不活躍。
- 如果 v 為活躍頂點 且 ∣ T [ v ] ∣ ≤ c m a x |T[v]| \le c_{max} ∣T[v]∣≤cmax? 且 z ≥ h m i n z \ge h_{min} z≥hmin?,將 T [ v ] T[v] T[v] 的頂點全部標記為不活躍。
- z = z + 1 z=z+1 z=z+1
- T = T ′ T=T' T=T′
- 初始化:
- 自適應聚類算法
- 初始化
- i = 1 , c m i n = 2 , c m a x = 10 , l = 5 i=1,\;c_{min}=2,\;c_{max}=10,\;l=5 i=1,cmin?=2,cmax?=10,l=5
- 迭代:
- 迭代條件:如果簇的數量大于頂點數的一半 且 i ≤ l i\le l i≤l
- 迭代過程:
- 構建 hash 表 T i T_i Ti?
- 遍歷所有活躍頂點 v ,如果 ∣ T i [ v ] ∣ ≤ c m a x |T_i[v]| \le c_{max} ∣Ti?[v]∣≤cmax? , 將 T i [ v ] T_i[v] Ti?[v] 中的頂點加入到簇 c v c_v cv? 中,并且移除 T i [ v ] T_i[v] Ti?[v] 。
- 如果 c v ≥ c m i n c_v \ge c_{min} cv?≥cmin?, c v c_v cv? 中的所有頂點都標記為不活躍。
- i = i + 1 i=i+1 i=i+1
- 初始化
- 指紋【每個頂點一個指紋,第 i 輪建立 hash 表 T i T_i Ti?,使用指紋分量 g i ( v , z ( v ) ) g_i\big(v,z(v)\big) gi?(v,z(v))作為 key】
- 聚類:
- 瓶頸【使用 n 級范式來消除】
- 使用 PQ 來確定下一個聚類的頂點對
- 聚類后更新鄰居頂點的評分函數
- 預處理
- 移除單頂點網絡【 ∣ e ∣ = 1 |e|=1 ∣e∣=1】
- 合并平行網絡
- 建立指紋【在聚類前】
f ( e ) = ∑ v ∈ e v 2 \begin{equation} f(e)=\sum\limits_{v\in e}v^2 \end{equation} f(e)=v∈e∑?v2?? - 更新指紋【合并頂點 u 和頂點 v 時,保留頂點 u】
- 超邊 e 不包含 u 和 v ,不需要更新
- 超邊 e 同時包含 u 和 v , f ( e ) = f ( e ) ? v 2 f(e)=f(e)-v^2 f(e)=f(e)?v2
- 超邊 e 只包含 u ,不需要更新
- 超邊 e 只包含 v , f ( e ) = f ( e ) ? v 2 + u 2 f(e)=f(e)-v^2+u^2 f(e)=f(e)?v2+u2【但是論文中沒有 ? v 2 -v^2 ?v2 】
- 建立指紋【在聚類前】
- 頂點合并 C ( u , v ) C(u,v) C(u,v)
- 評分函數
r ( u , v ) = ∑ e ∈ E u ∩ E v ω ( e ) ∣ e ∣ ? 1 \begin{equation} r(u,v)=\sum\limits_{e\in E_u \cap E_v}\frac{\omega(e)}{|e|-1} \end{equation} r(u,v)=e∈Eu?∩Ev?∑?∣e∣?1ω(e)??? - 合并步驟【將 v 替換為 u】
(1) ω ( u ) = ω ( u ) + ω ( v ) \omega(u)=\omega(u)+\omega(v) ω(u)=ω(u)+ω(v)
(2) v = u ? v ∈ { E v ? E u } v=u \Leftrightarrow v\in \{E_v-E_u\} v=u?v∈{Ev??Eu?}
(3)刪除 v ? v ∈ { E v ∩ E u } v \Leftrightarrow v\in \{E_v \cap E_u\} v?v∈{Ev?∩Eu?} - 約束【滿足約束的頂點才可以進行合并, t = 160 k t=160k t=160k】
ω ( v ) ≤ ? ω ( V ) t ? \begin{equation} \omega(v)\le \bigg\lceil \frac{\omega(V)}{t} \bigg\rceil \end{equation} ω(v)≤?tω(V)???? - 停止條件:不存在滿足約束的頂點 或者 頂點數小于 t t t
- 評分函數
- 瓶頸【使用 n 級范式來消除】
- 初始劃分
同上篇論文的 初始劃分 一致,不過進行了優化,將被分割的網絡生成兩個小的網絡的加入到對應的劃分塊中【上一篇論文是不考慮被分割的網絡】
n 0 = { v ∣ v ∈ e ∧ b [ v ] ∈ V 0 } n 1 = { v ∣ v ∈ e ∧ b [ v ] ∈ V 1 } \begin{equation} \begin{aligned} n_0=\{ v\; |\; v\in e \wedge b[v] \in V_0\} \\ n_1=\{ v\; |\; v\in e \wedge b[v] \in V_1\} \end{aligned} \end{equation} n0?={v∣v∈e∧b[v]∈V0?}n1?={v∣v∈e∧b[v]∈V1?}??? - 局部搜索
- 優化
- 每個塊一個優先隊列【共計 k 個優先隊列】【 Sanchis 的算法[16],優先隊列數量為 k ( k ? 1 ) k(k-1) k(k?1)】
- 頂點 v 的移動目標只考慮鄰居塊 Z ( v ) \Zeta(v) Z(v)
- 初始化
- 所有優先隊列設置為空且禁用的。【禁用的優先隊列不會考慮移動增益】
- 所有頂點都設置為不活躍的且未標記的。【未標記的頂點代表沒有移動過】
- 局部搜索
- 激活所有邊界頂點【如果不存在邊界頂點,跳過這一輪局部搜索】【不考慮 ∣ e ∣ > 1000 |e|>1000 ∣e∣>1000 的超邊的頂點】
- 計算邊界頂點 v 的移動增益 G i ( v ) G_i(v) Gi?(v) 并插入到對應優先隊列 Q i Q_i Qi?【只考慮頂點 v 的鄰居劃分塊 Z ( v ) \Zeta(v) Z(v)】
G i ( v ) = ∑ e ∈ E v { ω ( e ) : Φ ( e , b ( v ) ) = 1 } ? ∑ e ∈ E v { ω ( e ) : Φ ( e , V i ) = 0 } \begin{equation} G_i(v)=\sum\limits_{e \in E_v}\{\omega(e):\Phi(e,b(v))=1\}-\sum\limits_{e \in E_v}\{\omega(e):\Phi(e,V_i)=0\} \end{equation} Gi?(v)=e∈Ev?∑?{ω(e):Φ(e,b(v))=1}?e∈Ev?∑?{ω(e):Φ(e,Vi?)=0}?? - 激活所有輕負載的優先隊列。
- 迭代移動【一個頂點一輪至多移動一次】
- 查詢所有激活的優先隊列,獲得最高移動增益 G i ( v ) G_i(v) Gi?(v)
- 如果滿足平衡約束,移動該頂點 v 到劃分塊 V i V_i Vi?,并將該頂點標記不活躍且已標記。否則,則跳過。
- 激活頂點 v 的所有不活躍的鄰居頂點
- 如果鄰居頂點不是邊界頂點,則標記為不活躍的且從優先隊列中刪除其移動增益。
- 如果鄰居頂點是邊界頂點,則通過 D e l t a G a i n U p d a t e ( v , V f r o m , V t o ) DeltaGainUpdate(v, V_{from}, V_{to}) DeltaGainUpdate(v,Vfrom?,Vto?) 來更新鄰居頂點的移動增益。
- 回滾移動,直到處于最優的目標狀態。
- 自適應停止規則: l o g n log\;n logn 步非正增益移動,則停止。
- D e l t a G a i n U p d a t e ( v , V f r o m , V t o ) DeltaGainUpdate(v, V_{from}, V_{to}) DeltaGainUpdate(v,Vfrom?,Vto?)
【當一個頂點 v 移動后,在目標劃分塊 V t o V_{to} Vto? 中可以連接到所有超邊,則該劃分塊對于超邊 e ∈ E v e\in E_v e∈Ev? 來說是不可移動的。如果一個由于平衡約束而無法移動,則源劃分塊 V f r o m V_{from} Vfrom? 對于超邊 e ∈ E v e\in E_v e∈Ev? 是不可移動的。如果源和目標劃分塊都是不可移動的,則這部分超邊 e 不進行更新】- 遍歷頂點 v 的所有超邊 E v E_v Ev?
- 對于 e ∈ E v e\in E_v e∈Ev?,遍歷超邊 e 的所有頂點 u ∈ e u\in e u∈e
- 如果頂點 u 是已標記的,則跳過;【已經移動過的就不用更新了】
- 如果 Φ ( e , V f r o m ) = 0 \Phi(e,V_{from})=0 Φ(e,Vfrom?)=0 【e 在劃分塊 V f r o m V_{from} Vfrom? 已經沒有頂點了】
- 如果 V f r o m ∈? Z ( u ) V_{from} \not\in \Zeta(u) Vfrom?∈Z(u),則優先隊列 Q f r o m Q_{from} Qfrom? 移除頂點 u ;【如果劃分塊 V f r o m V_{from} Vfrom? 不在是 u 的鄰居塊】
- 否則,優先隊列 Q f r o m Q_{from} Qfrom? 更新頂點 u 的增益 G f r o m ( u ) = G f r o m ( u ) ? ω ( e ) G_{from}(u)=G_{from}(u)-\omega(e) Gfrom?(u)=Gfrom?(u)?ω(e) ;
- 如果 Φ ( e , V t o ) = 1 \Phi(e,V_{to})=1 Φ(e,Vto?)=1 【頂點 v 移動后對 e 產生了新的劃分塊連接】
- 如果 V t o ∈? Z ( u ) V_{to} \not\in \Zeta(u) Vto?∈Z(u) ,則依據公式 G_i(v) 計算 G t o ( u ) G_{to}(u) Gto?(u) 并插入到優先隊列 Q t o Q_{to} Qto? 中;【如果對于 u 來說, V t o V_{to} Vto? 是不是其鄰居劃分塊】
- 否則,優先隊列 Q t o Q_{to} Qto? 更新頂點 u 的增益 G t o ( u ) = G t o ( u ) + ω ( e ) G_{to}(u)=G_{to}(u)+\omega(e) Gto?(u)=Gto?(u)+ω(e) ;
- 如果 b ( u ) = V f r o m ∧ Φ ( e , V f r o m ) = 1 b(u)=V_{from} \wedge \Phi(e,V_{from})=1 b(u)=Vfrom?∧Φ(e,Vfrom?)=1 ,更新頂點 u 的所有增益 G i ( u ) = G i ( u ) + ω ( e ) G_i(u)=G_i(u)+\omega(e) Gi?(u)=Gi?(u)+ω(e) ;【對于 e 來說,其在劃分塊 V f o r m V_{form} Vform? 只剩下頂點 u 了,所以 u 移動到其他頂點就可以減少其的連接數】
- 如果 b ( u ) = V t o ∧ Φ ( e , V t o ) = 2 b(u)=V_{to} \wedge \Phi(e,V_{to})=2 b(u)=Vto?∧Φ(e,Vto?)=2 ,更新頂點 u 的所有增益 G i ( u ) = G i ( u ) ? ω ( e ) G_i(u)=G_i(u)-\omega(e) Gi?(u)=Gi?(u)?ω(e) ;【對于 e 來說,原本 V t o V_{to} Vto? 只有 u 一個頂點,所以它移動到其他劃分塊可以減少連接;但是 v 移動過來后,u 在移動到其他劃分塊就不會減少連接數,所以移動增益要減去 ω ( e ) \omega(e) ω(e) 】
- 對于 e ∈ E v e\in E_v e∈Ev?,遍歷超邊 e 的所有頂點 u ∈ e u\in e u∈e
- 遍歷頂點 v 的所有超邊 E v E_v Ev?
- 增益緩存
- 對于每個頂點 v ,用 O ( k ) \Omicron(k) O(k) 的空間來存放鄰居劃分塊和移動到該塊的增益。【可以在 O ( 1 ) \Omicron(1) O(1) 時間內添加和刪除一個塊,在 O ( ∣ Z ( v ) ∣ ) \Omicron(\big|\Zeta(v)\big|) O( ?Z(v) ?) 內遍歷所有鄰居塊,此外,還可以在 O ( 1 ) \Omicron(1) O(1) 時間內完成更新】
- 具體做法:
- 用 C v [ i ] C_v[i] Cv?[i] 表示頂點 v 和劃分塊 V i V_i Vi? 的緩存條目。
- 在初始劃分結束后,計算每個頂點所有可能的移動增益。【每輪局部搜索都要重新計算相應頂點的移動增益(不需要全部頂點重新計算)】
- 每次激活頂點時,使用緩存增益值來激活頂點;
- 移動頂點后,緩存增益更新操作如下:【移動后頂點 v 的鄰居劃分塊,有可能新增 V f r o m V_{from} Vfrom? ,一定減少 V t o V_{to} Vto?】
- 刪除 C v [ t o ] C_v[to] Cv?[to] ; 【因為頂點 v 移動到了劃分塊 V t o V_{to} Vto?】
- 如果 V f r o m ∈ Z ( v ) V_{from} \in \Zeta(v) Vfrom?∈Z(v) ,則 C v [ f r o m ] = ? C v [ t o ] C_v[from]=-C_v[to] Cv?[from]=?Cv?[to] ;【如果劃分塊 V f r o m V_{from} Vfrom? 是 v 的鄰居劃分塊】
- 對于其他鄰居劃分塊 V i V_i Vi? ,遍歷所有超邊 e ∈ E v e\in E_v e∈Ev?
- 如果 Φ ( e , V f r o m ) = 0 ∧ Φ ( e , V t o ) > 1 \Phi(e,V_{from})=0 \wedge \Phi(e,V_{to})>1 Φ(e,Vfrom?)=0∧Φ(e,Vto?)>1 ,則 C v [ V i ] = C v [ V i ] ? ω ( e ) C_v[V_i]=C_v[V_i]-\omega(e) Cv?[Vi?]=Cv?[Vi?]?ω(e) 【原本在 from ,移動到其他塊可以減少連接數,而移動到 to 時,超邊 e 在 to 有其他頂點,所以如果要移動到其他塊,就不會減少連接數,所以移動增益要減少】
- 如果 Φ ( e , V f r o m ) = 0 ∧ Φ ( e , V t o ) = 1 \Phi(e,V_{from})=0 \wedge \Phi(e,V_{to})=1 Φ(e,Vfrom?)=0∧Φ(e,Vto?)=1 ,則 C v [ V i ] = C v [ V i ] + ω ( e ) C_v[V_i]=C_v[V_i]+\omega(e) Cv?[Vi?]=Cv?[Vi?]+ω(e) 【原本在 from ,移動到其他塊可以減少連接數,而移動到 to 時,超邊 e 在 to 沒有其他頂點,所以如果要移動到其他塊,就會減少連接數,所以移動增益要增加】
- 回滾時同時回滾增益緩存
- 優化
- 實驗結果:
- 測試用例:
- the ISPD98 VLSI Circuit Benchmark Suite [17]
- the University of Florida Sparse Matrix Collection [18]
- the international SAT Competition 2014 [19]
- 實驗參數
- k = { 2 , 4 , 8 , 16 , 32 , 64 , 128 } ∪ { 5 , 23 , 47 , 107 } k=\{2,4,8,16,32,64,128\} \cup \{5,23,47,107\} k={2,4,8,16,32,64,128}∪{5,23,47,107}
- ? = 0.03 \epsilon=0.03 ?=0.03
- 比較對象
- PaToH-Q
- PaToH-D
- hMetis-R
- hMetis-K
- 測試用例:
五、實驗結果
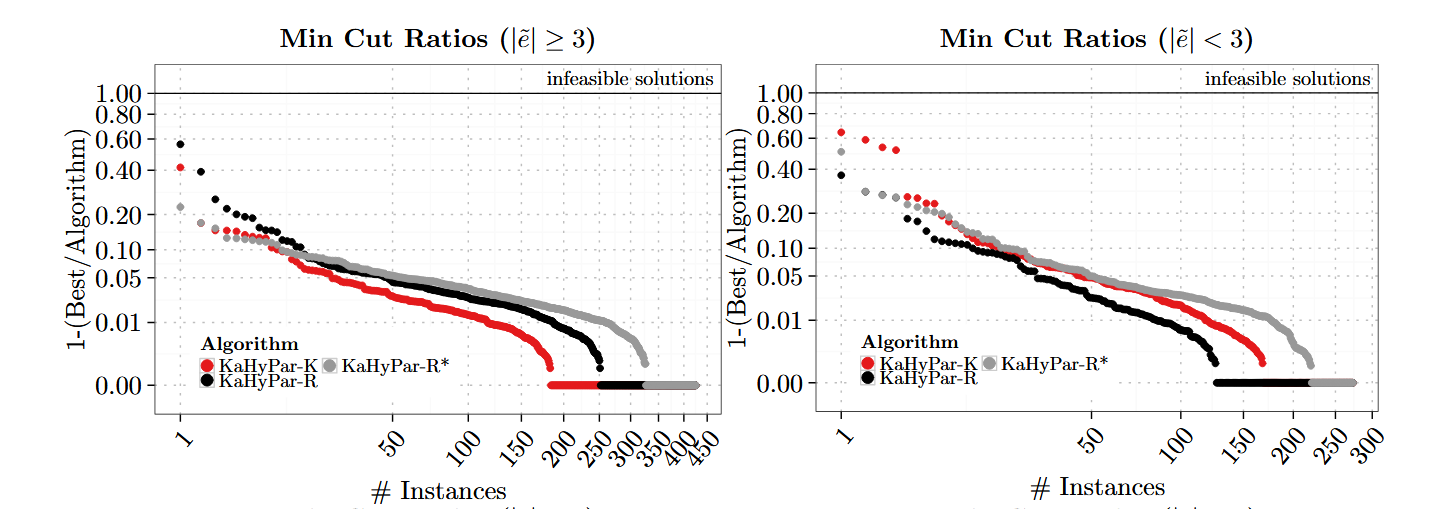
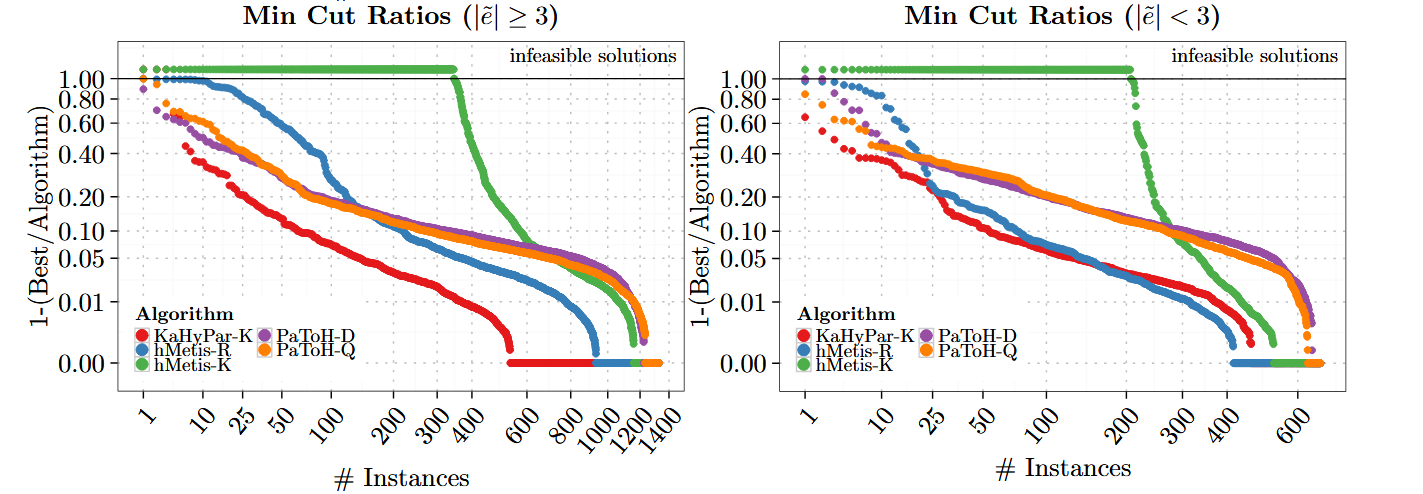
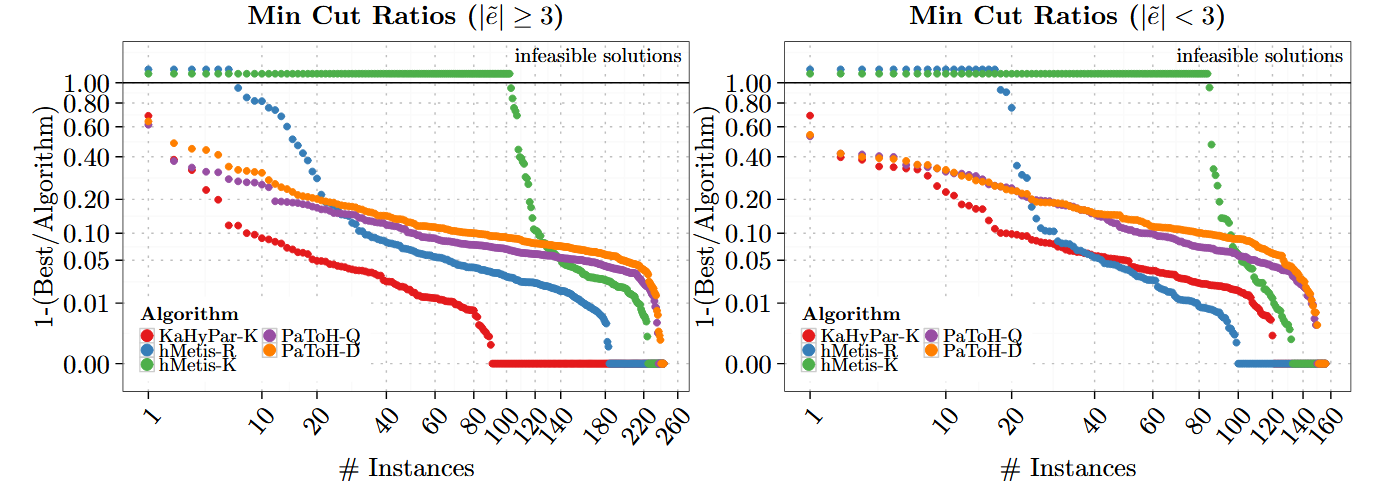
六、主要貢獻
- 提出了 n 級直接 k 劃分算法
- 引入 min-hash 技術,加快了聚類和局部搜索的計算速度
- 提出了一個聚類函數,消除了 PQ 的瓶頸且不會影響整體結果的質量
- 提出局部搜索算法,使用 DeltaGainUpdate 、增益緩存的技術來提高算法速度
- 提出了一種自適應停止規則
視頻彈題功能實例)

—— 評估算法(一))

沒有之一,已親自使用!)






介紹)







 接口)