
內容概要
在SEO優化實踐中,關鍵詞布局的科學性與系統性直接影響流量的獲取效率與可持續性。本文以核心關鍵詞篩選為起點,結合長尾詞挖掘工具與語義關聯分析技術,逐步構建覆蓋用戶全搜索場景的內容矩陣。通過金字塔結構模型,實現高權重關鍵詞與細分長尾詞的層級化分布,同時依托TF-IDF算法優化內容密度與相關性,確保頁面既滿足搜索引擎的評估標準,又能精準匹配多元化的用戶搜索意圖。
專家建議:在規劃關鍵詞體系時,建議優先通過Google Keyword Planner、Ahrefs等工具建立搜索量-競爭度二維矩陣,篩選出具有商業價值與優化可行性的核心詞群,為后續長尾延伸奠定數據基礎。
值得注意的是,關鍵詞布局并非孤立環節,需與內容架構、用戶行為分析形成閉環。從初始的關鍵詞研究到最終的流量轉化,每個環節的協同設計將直接影響自然搜索流量的增長曲線。
SEO核心關鍵詞篩選策略
在SEO優化體系中,核心關鍵詞的篩選是流量獲取的根基性工作。首先需通過專業工具(如Ahrefs、SEMrush)進行初始數據采集,重點關注搜索量、競爭度及商業價值三大維度。搜索量反映用戶需求規模,但高搜索量往往伴隨激烈競爭,因此需結合關鍵詞難度(KD值)評估投入產出比。同時,通過用戶畫像分析鎖定目標群體的核心訴求,例如B2B行業側重“解決方案”“供應商”類詞匯,而C端消費場景則需強化“性價比”“評測”等意向詞。值得注意的是,搜索意圖匹配是篩選過程中的隱形門檻,需區分信息型、導航型與交易型關鍵詞的優化側重。此外,借助TF-IDF算法可識別內容與關鍵詞的語義關聯強度,輔助剔除相關性低但流量虛高的干擾項,為后續長尾詞布局奠定精準數據基礎。
長尾詞深度挖掘技巧
長尾關鍵詞的精準定位需結合工具應用與語義分析雙重策略。通過Ahrefs、SEMrush等專業工具可快速獲取搜索量在50-500之間的長尾詞候選池,同時利用Google Keyword Planner的"關鍵詞建議"功能識別用戶提問型短語(如"如何""哪里""最佳")。值得注意的是,搜索意圖的層級劃分直接影響長尾詞篩選效率,需將候選詞按信息型、導航型、交易型三類進行標簽化管理(見表1)。
| 工具/方法 | 核心功能 | 典型應用場景 | 數據指標參考值 |
|---|---|---|---|
| AnswerThePublic | 問題詞庫生成 | 內容話題擴展 | 日均提問量≥200 |
| 百度指數需求圖譜 | 關聯需求可視化 | 長尾詞語義延伸 | 關聯強度≥0.7 |
| 競品頁面詞頻分析 | 競爭對手長尾詞捕獲 | 藍海機會識別 | 覆蓋率差異≥30% |
在語義關聯層面,可通過LSI關鍵詞生成器提取與核心詞共現的高頻修飾詞,例如"價格""評測""教程"等,結合TF-IDF算法評估詞項在領域文檔集的權重分布。行業數據顯示,融入地域限定詞(如"北京SEO培訓")可使長尾詞點擊率提升22%,而包含產品參數的短語(如"無線降噪耳機推薦2024")則能提高15%的轉化可能性。
語義關聯優化方法解析
構建語義關聯網絡是突破關鍵詞孤立布局的關鍵環節。通過自然語言處理技術識別LSI(潛在語義索引)關鍵詞,能夠有效擴展內容與搜索意圖的匹配維度。實踐中需結合Google NLP API或BERT模型,對目標關鍵詞進行上下文特征提取,識別出包括同義詞、行業術語、場景化短語在內的語義關聯詞群。例如針對核心詞"跨境電商運營",系統可能關聯"海外倉時效"、"關稅計算工具"等長尾詞,形成多維語義矩陣。在此基礎上,運用實體識別技術構建知識圖譜,可建立關鍵詞間的邏輯關系網絡,使內容同時滿足搜索引擎的語義理解需求和用戶的深度信息需求。該過程需配合TF-IDF算法進行詞頻權重分析,確保關聯詞群既保持主題集中度,又覆蓋搜索需求的長尾延伸空間。

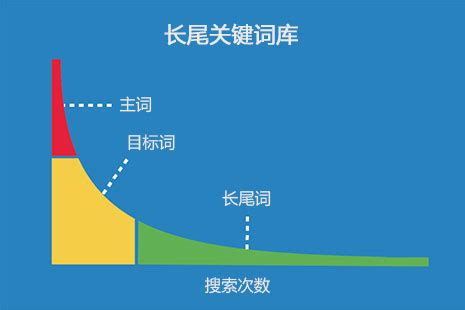
金字塔結構布局模型
在SEO內容架構中,金字塔模型通過層級化的關鍵詞分布實現流量與權重的雙重積累。核心策略是將行業核心關鍵詞置于金字塔頂端,作為頁面主題錨點,通過高權重頁面(如首頁或專題頁)集中優化;中層布局次級長尾詞,覆蓋用戶細分需求場景(例如"SEO核心關鍵詞篩選工具");底層則拓展長尾變體與LSI語義詞(如"關鍵詞搜索量分析方法"),形成內容矩陣的支撐網絡。這種分層設計需結合頁面權重分配規則,確保核心詞頁面獲得更多內鏈支持,同時通過目錄結構將長尾流量向核心頁面導流。實踐中需注意層級間的語義關聯度,利用TF-IDF算法分析內容關鍵詞分布密度,避免出現層級斷層或關鍵詞堆砌,最終形成既能提升核心詞排名,又能捕獲長尾流量的有機內容生態。
搜索意圖匹配優化指南
精準匹配用戶搜索意圖是提升關鍵詞轉化效率的核心環節。首先需通過語義分析工具(如Google Keyword Planner、SEMrush)識別搜索行為背后的真實需求,將關鍵詞歸類為導航型、信息型或交易型。例如,針對"如何安裝WordPress插件"這類信息型查詢,需在內容中嵌入分步教程與常見問題解答;而"WordPress主題購買"等交易型關鍵詞,則應強化產品對比與購買引導。在此基礎上,結合頁面停留時長、跳出率等數據,動態調整內容結構與關鍵詞密度,確保核心段落優先呈現高價值信息。值得注意的是,長尾關鍵詞往往承載更具體的搜索意圖,需在子標題、FAQ模塊及內容擴展部分進行多維度覆蓋,形成從需求識別到解決方案的完整閉環。
TF-IDF算法應用實踐
在SEO內容優化中,TF-IDF(詞頻-逆向文檔頻率)算法為關鍵詞密度與語義權重的平衡提供了科學依據。該算法通過計算特定詞匯在單篇文檔中的出現頻率(TF)與在整個語料庫中的稀缺程度(IDF),量化關鍵詞對內容主題的貢獻值。實踐中,可借助Python的Scikit-learn庫或在線工具(如Yoast SEO插件)進行TF-IDF值分析,識別未被充分覆蓋但具備搜索潛力的相關詞匯。例如,針對核心關鍵詞"智能家居",若"無線協議"的TF-IDF值顯著高于同類文檔均值,則需在內容中強化該詞匯的布局。值得注意的是,TF-IDF應與LSI(潛在語義索引)結合使用,避免機械堆砌關鍵詞導致內容可讀性下降。優化時建議將重點詞匯的TF值控制在2%-3%,并通過自然句式分散分布,同時監測長尾詞與主關鍵詞的IDF關聯性,確保內容既滿足算法偏好又符合用戶搜索意圖。

雙效流量增長體系構建
構建雙效流量增長體系的核心在于平衡核心關鍵詞與長尾詞的協同效應。一方面,通過核心關鍵詞的精準布局快速搶占高競爭度領域的搜索可見性,借助頁面權重傳遞與錨文本優化強化核心頁面的權威性;另一方面,通過長尾關鍵詞的垂直滲透覆蓋用戶搜索的長尾需求,利用語義關聯技術擴展內容顆粒度,形成從核心到邊緣的流量捕獲網絡。在此過程中,需結合金字塔式內容架構,將高價值核心詞作為頂層節點,通過分類聚合與內鏈策略向下關聯長尾內容,實現流量入口與用戶需求的精準匹配。同時需要引入TF-IDF算法進行詞頻權重分析,動態調整關鍵詞密度與分布模式,確保內容既符合搜索引擎的語義相關性要求,又能自然覆蓋潛在搜索意圖,最終形成兼具短期爆發力與長期穩定性的流量增長模型。

結論
綜合來看,SEO關鍵詞與長尾詞的布局并非孤立的技術操作,而需基于系統化的策略框架實現協同效應。通過金字塔結構的內容矩陣,核心關鍵詞能夠有效錨定目標排名,而長尾詞的精準覆蓋則進一步拓寬流量入口,形成“核心輻射長尾、長尾反哺核心”的動態平衡。在此過程中,搜索意圖的深度解析與語義關聯優化成為連接用戶需求與內容價值的關鍵橋梁,而TF-IDF算法的科學應用則為關鍵詞權重分配提供了可量化的決策依據。需要強調的是,隨著搜索引擎算法的持續迭代,優化策略需保持動態適應性,通過數據反饋不斷調整關鍵詞組合與內容結構,方能實現自然流量的可持續增長與業務價值的長期沉淀。

常見問題
如何判斷核心關鍵詞與長尾詞的優先級?
需結合搜索量、競爭度及商業價值綜合評估,核心關鍵詞優先布局高權重頁面,長尾詞則用于補充細分場景流量。
長尾關鍵詞挖掘工具有哪些推薦?
SEMrush、Ahrefs、Google Keyword Planner等工具可高效挖掘長尾詞,同時可通過問答平臺(如知乎)捕捉用戶真實需求。
金字塔結構布局是否適用于所有類型網站?
該模型尤其適合內容型站點,通過核心詞→二級詞→長尾詞的三層架構,可系統化覆蓋用戶搜索路徑,提升內容關聯性。
TF-IDF算法如何指導關鍵詞布局?
通過分析詞頻與逆文檔頻率,識別內容中權重不足的關鍵詞,針對性補充相關語義變體,優化內容與搜索意圖的匹配精度。
如何避免長尾詞布局導致內容重復?
建立語義關聯詞庫,采用LSI關鍵詞替代完全匹配的長尾詞,同時通過內容模板差異化設計降低重復風險。
搜索意圖匹配優化的核心步驟是什么?
首先需明確目標用戶畫像,分析TOP10競品內容結構,再通過關鍵詞聚類技術將相似意圖的長尾詞整合到同一內容單元。





)





字符串作為函數參數)



(十九)——紅黑樹)



