1、在數據結構中,隨機訪問是指能夠直接訪問任一元素,而不需要從特定的起始位置開始,也不需要按順序訪問其他元素。這種訪問方式通常不涉及遍歷。例如,數組(array)支持隨機訪問,你可以直接通過索引訪問任意元素,而無需從第一個元素開始一步步遍歷。
2、對于鏈式存儲的理解:可以把每個節點理解為僅存儲兩個元素的數組,第一個元素是這個節點存儲的數據,第二個節點存儲的是下一個節點的數組名,也就是下一個節點的首地址(假設這個數組可以存儲不同的數據類型)。
3、鏈式存儲無法進行隨機訪問的原因就是,每一個節點在計算機內存中的位置信息都保留在前驅節點中,而前驅節點的位置信息又保存在前驅節點的前驅節點中,就這樣連鎖反應到首個節點,所以若要進行訪問只能從第一個節點進行遍歷。
4、算法可以沒有輸入,但至少有一個輸出,用時間復雜度和空間復雜度來衡量一個算法的效率。
5、時間復雜度里的O()是指同階的意思。
6、時間復雜度就是在當問題規模n趨近于無窮大時,誰是高階無窮大。
7、高階無窮大的比較參考為:常對冪指階
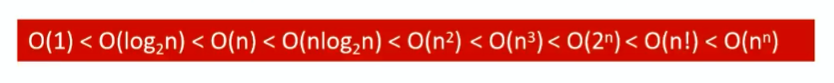
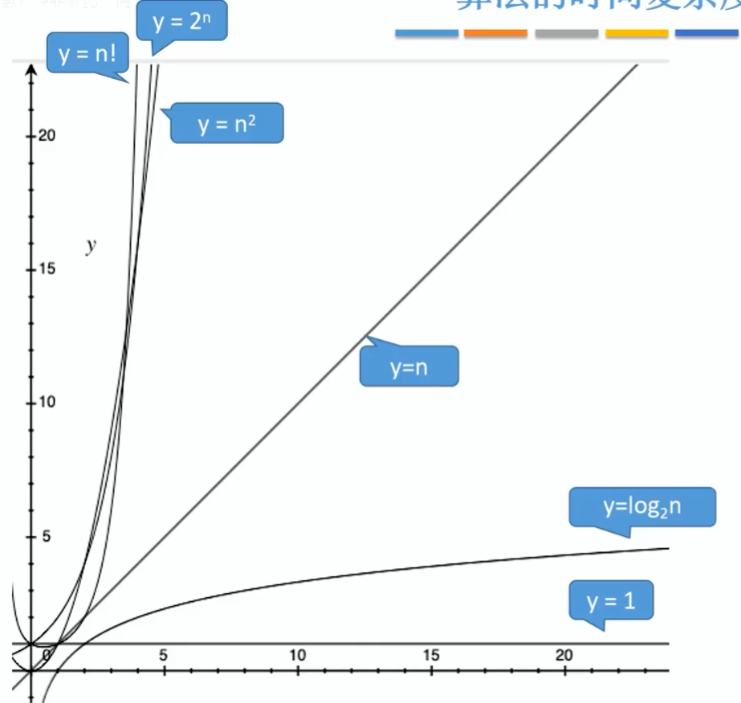
時間復雜度的最終結果會省略低階項和高階項的系數,所以最終的結果一定是以上高階無窮大序列中的某一個。且由于以上的函數單調遞增、無交點,所以當n趨近于0時,他們的高階無窮小順序是反過來的。
8、由于在計算時間復雜度時,是將n處于趨近于無窮大的情況下進行計算,所以算法中的會執行但與n無關的代碼步驟會被視作常數而被忽略掉。且由于最終的結果會忽略低階項,所以都是直接研究最深層的循環的循環次數,一般循環次數都是關于n的一元函數。
9、在某些情況下,計算最深循環次數的條件并不確定,需要討論最好和最壞情況,則需要計算平均循環次數,從而得到一個代表平均次數的n的一元函數。實際使用的都是平均時間復雜度和最壞時間復雜度,最好時間復雜度不會使用。
10、空間復雜度的變化一般都是由n引起的變量大小的改變,例如n決定了數組的大小和結構體大小;或則n決定了函數的嵌套次數,例如遞歸函數的遞歸次數。
11、空間復雜度就是根據n所決定的空間大小的高階無窮大。
12、時間復雜度和空間復雜度的計算就是去找n的一元函數。
13、數據元素和數據項可以分別理解為一個賬戶和這個賬戶的具體信息,在實際的代碼中可理解為結構體和成員變量。
14、數據結構就是存在特定關系的數據元素的集合,這個概念包含了數據元素以及它們之間的關系,在具體的數據結構中,每個節點的數據域就是數據元素。
15、數據對象就是具有相同性質的數據元素的集合,可理解為由同一個結構體或者類產生的實例對象集合。數據對象這個概念不包含數據元素之間的關系,所以這個概念僅指一個數據元素集合,數據元素之間可以不存在關系。
16、邏輯結構使用不同的存儲結構會影響存儲空間分配的方便程度、影響對數據運算的速度。
17、數據的運算是通過算法來實現的。
18、抽象數據類型ADT就是邏輯結構和數據的運算這兩點的總和,一般都是先定義ADT,也就是邏輯結構和在此之上的運算,再使用具體的存儲結構去實現他。





)



)




:Agglomerative Transformer for Human-Object Interaction Detection)




)