我自己的原文哦~? ? ?https://blog.51cto.com/whaosoft/13933252
#?小米智能駕駛技術的一些猜測
來蹭一下小米汽車智能駕駛的熱度,昨晚聽了雷總小米汽車的發布,心潮澎湃尋思下單一輛奈何現實不允許hhh。
言歸正傳吧, 本來是想主要聽一下小米智駕的但雷總并沒有透露太多。這次對于智駕方面的介紹其實和上次技術發布會上展出的內容差不多。聽完之后我自己對于小米自動駕駛的技術點有一些疑問和猜測,寫一寫大家可以瞅一瞅交流一下。

旗艦硬件平臺之高算力芯片

首先沒毛病,小米智能駕駛高配用的芯片是英偉達雙Orin-X,綜合算力508TOPS。低配版使用的是Orin-N,單芯片算力84TOPS。這里就解決了大家為什么會疑問84 X 2 是508。
這個算力已經可以算是在量產車上用的最高算力配置了,畢竟上了激光雷達,圖像加激光來做模型對算力要求還是挺高的。orin芯片由于是英偉達產品這意味著在進行深度學習推理時候cuda支持的操作都可以使用,這對于車端部署神經網絡模型非常友好。如果是其他芯片則會有多多少少的特定算子不支持的問題,增加工程量。以地平線J5開發平臺為例,不支持的操作都得改代碼,還存在其他限制。

另外大算力芯片帶來的好處還有網絡模型可以做的大一些,可以使用新的模型結構。如果你想在地平線J5平臺上使用transformer,那基本就不要想著上車了,網絡也就跑個幾幀十幾幀。所以小米造車使用orin還是很合理的,大算力宣傳性價比,開發難度也小很多。旗艦硬件平臺沒啥毛病。
困惑之自監督數據引擎
接下來就是有困惑的地方,自監督數據引擎?這個自監督是如何定義的,如果按深度學習的定義自監督就是說我的訓練數據是無標簽的,那這個為什么還需要真值標注?如果你不是數據自監督是引擎自監督,那應該是整個數據處理的pipline是不需要人工來做全部自動化了,這我屬實難以相信。車還沒賣出去,影子模式還沒回傳數據,也就測試車自己采集點跑通整個流程,國內也沒有一家敢斬釘截鐵的說自己4d真值標注完全不靠人工,超算訓練自動化不是不可以,但肯定也還是需要手動處理一些bug和調參。
也可能是我的問題,我只負責模型部分對前面的真值標注部分不熟悉,所以“自監督數據引擎”幾個字湊在一起真的是很令人困惑啊!!!
重點具身智能引擎
下一個重點具身智能引擎,這個是說得通的,挺火的概念。環境感知,行為預測,交互博弈,時空聯合,決策這些確實也都是模型可以做到的,把智能裝在身體上可以和外界交互,具身智能就成了。
第一個點是變焦bev。
官網給了三個場景解釋,分別是泊車,城區和高速。我們一般人困惑的第一個點就是為什么這個bev可變?按ppt的說法我理解是說在泊車場景的時候網絡的劃分會更細,分辨率會更高。我們都知道一般bev網絡的輸出分辨率是需要作為config在訓練的時候給定的,怎么訓的跑的時候就怎么跑,這個分辨率是給定的不能變。如果說你可以變,那config文件變了就意味著最起碼神經網絡后面的輸出也要改變,網絡是需要學習參數的。所以我猜測難道在是訓的時候就有不同分辨率,只是根據場景切換了輸出模型。(更容易一點也可能是好幾個模型來回切,但應該不至于這么搞)至于有什么其他更妙的設計或許也有可能吧。如果這么來看那變焦bev似乎也沒有很神秘,至于如何看的更寬更遠我覺得也差不多同理,bev遠范圍的感知也有一些文章,一兩百米的bev也能搞。當然最開始和同事討論的時候我們也想過,難道是相機是可變焦距的?要是這樣那還挺牛的。
不過這世界還是挺有趣的,很多事情的謎底往往就在謎面上。

猜來猜去猜了那么久,人家寫的很清楚調用不用算法動態調整bev網格特征的細粒度和感知范圍。那就是幾個模型切換了。看來作為堅定的唯物主義者也需要對科技進行祛魅(disenchantment)。
至于自適應應該說的是算法可以根據場景切換。這三個場景簡單點就是手動切,高級點是自動切。手動切就是說用戶自己使用了什么功能,后臺根據功能來切換模型;自動切是用網絡去自己判斷場景或者根據感知出來的結果來寫一些規則,根據這個建筑車輛周圍環境的特征去判斷場景來切換,但無論如何也是我們大概可以猜到的,能猜到邏輯上能說通,那就是我們也可以去實現的功能。

第二個點是超分辨率占用網絡技術。
對不熟悉這個方向的同學來說,一看看過去感覺挺高級的。但隔行如隔山,這個恰好我之前有了解過一些,不清楚小米是不是真的這樣做的,但我猜測大概是這樣八九不離十?給大家放幾篇篇相關文章可以看一下,這個模擬連續曲面的立體物到底是什么情況。

按順序來的話,第一篇先放SIREN:Implicit Neural Representations with Periodic Activation Functions
arxiv.org/pdf/2006.09661.pdf
正弦表示網絡(sinusoidal representation network:SIREN),用周期性的激活函數來作為隱式神經表達,用他來解決特定的Eikonal方程的邊值問題,簡單來說就是用來在點云上擬合隱式神經表達參數化的符號距離函數就可以產生下面的效果? ?

這里稍稍科普一下SDF,此外還有TSDF

另一篇是LODE: Locally Conditioned Eikonal Implicit Scene Completion from Sparse LiDAR
arxiv.org/pdf/2302.14052.pdf

SIREN提出一種從點云到3D mesh補全方法,LODE提出了利用GT來監督SDF。
SurroundSDF: Implicit 3D Scene Understanding Based on Signed Distance Field?
arxiv.org/pdf/2403.14366.pdf
這篇文章第一單位是xiaomi ev。后來居上的文章效果一般都不錯,為什么會不錯呢?具體來說,引入了一種基于查詢的方法,并利用Eikonal公式約束的SDF來準確描述障礙物的表面。此外,考慮到缺乏精確的SDF基本事實,提出了一種新的SDF弱監督范式,稱為Sandwich-Eikonal公式,它強調在表面兩側應用正確和密集的約束,從而提高表面的感知精度。實驗表明,該方法在nu-Scenes數據集上實現了占用預測和3D場景重建任務的SOTA。這篇文章沒有開源,但其實根據paper和上面兩篇文章想要復現也不難,但我目前還是在做bev模型的檢測分割所以暫時不會搞。

a.在提供SDF GT的情況下,對SDF進行理想的監督。b.SIREN監督,使用LIDAR點對表面進行監督。c.基于占用GT的LODE監管。d.我們的監管范式結合了LiDAR GT和占用GT,更接近理想的監管
這類任務都還是需要用激光做的真值。

然后就是識別異性障礙物種類無上限,我們做目標檢測一般都給定類別,對于沒見過的東西可能就胡亂給結果了,所以對于各種各樣的異性障礙物訓練集里面不會都有,那就需要給一個other類。又或者一些開集的檢測把視覺語言一起訓,用語言監督視覺也可以做到超類別的檢測,這個文章就很多很多了。
第三個雨雪天自動降噪。

這個我就想的很簡單,對輸入的數據先過降噪算法再進網絡。這類的算法就太多太多了,大家應該隨處都可以找到。例如去arxiv網站上搜索rainy 或者snowy可以看到非常多的相關算法。
降噪可以單做,也可以嵌入網絡,至于小米的智駕是如何做到的不是很清楚。難點在于降噪部分與后續環節的連接與耗時。
第四個小米道路大模型。
關于路網這部分這個我就不是很懂了,這部分目前是有其他同事在做。但也給大家一些我收藏的文章吧。下面鏈接里的文章不算全但也足夠大家來理清脈絡了,主要是新工作出來的太快了,像昊哥他們做的P-Mapnet之類。用神經網絡去做道路結構的拓撲這部分我確實沒搞過,但畢竟還是有大量文章可以參考!大家可以仔細研究一下
文章推薦地址如下:https://zhuanlan.zhihu.com/p/685111496

第五個端到端感知決策大模型。
這個我其實很感興趣,把感知和決策一起做了,但目前還是只搞感知,老板不允許啊。我也不想說服他搞(已經放棄老板了)。好在小公司氛圍比較輕松可以自己看看論文(已經看了快兩年論文了,當然活也沒落下該干的我都干了)。對于端到端的文章其實也不算少了,下面就簡單給兩篇文章參考吧
第一篇非常著名的cvpr的端到端:Planning-oriented Autonomous Driving
arxiv.org/pdf/2212.10156.pdf

統一自動駕駛(Uni AD)管道。它是按照以規劃為導向的理念精心設計的。與簡單的任務堆棧不同,我們研究了每個模塊在感知和預測方面的效果,利用了從前面節點到最終駕駛場景規劃的聯合優化的好處。所有感知和預測模塊都采用變壓器解碼器結構設計,任務查詢作為連接各個節點的接口。最后利用一個簡單的基于注意力的規劃器,結合所提取的知識來預測自駕車未來的路徑點
大家看pipline也能看出來這個端到端其實是有很多組件構成,每個環節都通過任務查詢來連接,前面的流程都是為了最后的規劃而服務。
第二篇鑒智的端到端:GraphAD: Interaction Scene Graph for End-to-end Autonomous Driving
arxiv.org/pdf/2403.19098.pdf

(這個看起來就很酷)

GraphAD的特點是駕駛環境中結構化實例之間基于圖的交互,包括動態交通代理和靜態地圖元素。Graph AD首先在鳥瞰圖上構建時空場景特征,作為下游任務的統一表示。然后,Graph AD通過Track Former和Map Former提取結構化實例。以這些實例為圖節點,graph AD提出了交互場景圖,通過考慮代理間和代理映射的交互,迭代細化動態節點的特征。最后,將處理后的節點特征用于運動預測和端到端規劃。
GraphAD 的github可以看到Our code is based on UniAD and DGCNN,還是借鑒了UniAD的工作,用圖的形式來做交互上的優化無疑是更好的。但代碼目前還沒有開源,大家可以mark一下。
先把端到端模型部署上車,再把這套東西裝到機器人身上,這個才是我想做的,也是未來五到十年的人生目標吧。
給完文章再來看小米這個端到端感知決策大模型,感覺還是穩扎穩打的,先在泊車場景下驗證端到端,后面在放到行車上。單從文章來看感知部分大家應該都很熟悉,但是決策部分給定的都比較簡單,具體要量產控車,簡單的左轉右轉直行停下肯定還是不夠的,但老樣子有文章的話就管中窺豹可見一斑。

全場景功能
全場景功能就交給廣大網友和up主去測評了。
總結
不吹不黑,個人感覺小米的智駕水平還是可以的,有錢有人但還是需要時間來積淀。
目前發布出來的技術也不能說是多么遙不可及,我們都是技術的跟隨者不是創新者,就上面這些東西只要有人做過我相信大家搭demo大家都可以做到,從0到60,但是真的能把任何一個技術從80做到90,甚至99都太難了,demo后面的每一步都難如登天。特斯拉已經把路給走通了,剩下的就看大家怎么搞了。加油!為了自動駕駛!沖!
#?自動駕駛中的坐標變換
對線性代數中的坐標變換、基變換兩個概念的引入、性質進行了詳細推導,并以自動駕駛中的傳感器外參標定驗證場景舉例,介紹了坐標變換和基變換在實際工程中的應用,相信看完本文大家能對坐標變換和基變換有更深的理解。
默認讀者具備基礎的線性代數知識,包括基、線性組合、線性變換等概念。
應用背景

車輛系和相機系都是右手坐標系,一般情況下:車輛系的X軸指向車輛前方,Y軸指向車輛左方,Z軸指向天空;相機為前視相機,其坐標系為X軸指向車輛右方,Y軸指向地面,Z軸指向車輛前方。

車輛坐標系和相機坐標系
為什么需要坐標轉換矩陣 T 呢,假設我們在圖像中檢測到一個行人,此時我們可以通過相機內參并結合其他測距傳感器,得出該行人在相機系下的位置,但我們并不知道這個人距離車輛有多遠,在車輛的正前方還是左前方。因此就需要一個坐標轉換矩陣,將相機系下的三維點轉換到車輛系下,供下游任務使用。
問題引入

實驗驗證
為了實驗能更加直觀和真實,我們先做出如下設置:
- 車輛坐標系原點設置在車輛前保險杠的中心處,車輛系的X軸指向車輛正前方,Y軸指向車輛正左方,Z軸指向天空;
- 將相機系原點設置在擋風玻璃后的上方處,相機系的X軸指向車輛正右方,Y軸指向地面,Z軸指向車輛正前方,相對于車輛坐標系的原點,相機系原點相對于相機系X、Y、Z方向上的平移分別為-1.25、0.1、0.65,直觀理解為相機位于車輛前保險杠的后上方,并且偏左一點點;

車輛、相機與人的位置關系

#include <eigen3/Eigen/Core>int main(){float pi = 3.14159265358979;Eigen::Matrix3f R_inv;R_inv << 0, 0, 1, -1, 0, 0, 0, -1, 0;Eigen::Vector3f euler_angle = R_inv.eulerAngles(0, 1, 2); // 0: X軸,1: Y軸,2: Z軸,前后順序代表旋轉順序,旋轉方式為內旋std::cout << "先繞X軸旋轉: " << euler_angle[0] * 180 / pi <<std::endl;std::cout << "再繞Y軸旋轉: " << euler_angle[1] * 180 / pi << std::endl;std::cout << "最后繞Z軸旋轉: " << euler_angle[2] * 180 / pi << std::endl;
}// Console Output:
// 先繞X軸旋轉: -0
// 再繞Y軸旋轉: 90
// 最后繞Z軸旋轉: -90

我們接下來采用線性代數,來分析為什么坐標變換矩陣和基變換矩陣剛好就是互為逆的關系。
線性代數解釋(坐標變換和基變換的本質)


基變換矩陣和坐標變換矩陣互為逆,推導完畢。
總結
基變換矩陣和坐標變換矩陣的關系之前也在矩陣論這門課中接觸過,但當時完全不了解其應用場景,也對為什么這么取名一知半解。直到在實際應用中碰到了這個問題,才發現簡簡單單的兩個公式,在使用時必須根據應用場景對齊進行區分,來選擇究竟使用基變換矩陣還是坐標變換矩陣。
# 車道線檢測任務
Implementing lane detection is the first, essential task when building a self-driving car.
—— Sebastian Thrun (godfather of self-driving cars)
在自動駕駛和智能交通系統的發展中,車道線檢測作為其中至關重要的一環,扮演著無可替代的角色。車道線不僅是道路交通標記的重要組成部分,更是車輛導航、路徑規劃和環境感知的基礎。因此,準確、穩定的車道線檢測系統對于實現安全、高效的智能交通至關重要。
隨著深度學習技術的飛速發展,車道線檢測技術已經取得了顯著的進步。傳統的基于圖像處理和機器學習的方法逐漸被基于深度學習的端到端模型所取代,使得車道線檢測系統在準確性和魯棒性上都得到了顯著提升。
筆者正是從事相關領域的研究和工作,創作這篇文章,主要是想對車道線檢測這一細分任務的方法進行一個總結歸納,并且談談自己的理解。全文將從傳統的檢測方法聊到基于深度學習的一些方法,再談到BEV視角下的檢測,最后聊一聊關于大一統的檢測方法。可以說是講述了車道線檢測任務的"前世今生",故起了這樣一個標題。以下是本文的結構框架:

傳統方法
先簡單聊聊幾個主流的傳統車道線檢測的方法,主要還是借助于opencv和一些算法來實現:
- 顏色閾值:如果只是檢測簡單的黃色和白色車道線,我們可以用這種方法來實現。把一般常見的RGB通道的圖片轉化到HSV或者HSL的顏色特征,然后人工設置一個黃色閾值和白色閾值,就能檢測出來圖像中黃色和白色車道線的位置。
- 邊緣檢測+霍夫變換:灰度圖像-->高斯平滑(把圖片變模糊,下一步邊緣檢測就會濾掉一些不重要的線條)-->邊緣檢測(檢測出圖像中邊緣的點)-->選擇ROI(可以選出路面區域)-->霍夫變換(獲得車道線的直線參數)-->投影到原圖上。
PS:說說筆者對霍夫變換的理解:將一條直線轉換到表征直線的參數空間(可以用斜率m和截距b表征一條直線,那么霍夫空間就是m和b的函數,極坐標表示也類似)。所以經過笛卡爾坐標系下的一個點,可以有無數條直線,即可以有無數種m和b的對應關系,在霍夫空間中,則對應著一條直線。圖片上通過邊緣檢測可以離散得到N個點,而對應的霍夫空間可以表示成N條直線,這N條直線的交點,對應的m和b,即為我們所想要檢測的車道線。 - 基于擬合的檢測: 利用RANSAC等算法擬合車道線。
優點:不需要數據積累
缺點:魯棒性較差;需要人工手動調參;霍夫變換不能做彎道檢測;擬合的方法穩定性較差。
雖然我們要肯定前人的成果,但是不得不說,傳統的車道線檢測方法需要人工手動地去調整算子和閾值,不僅工作量大且而且魯棒性也較差,在復雜的環境下,檢測結果就不夠理想。
基于深度學習方法
與傳統的檢測算法相比,基于深度學習的車道線檢測因其過硬的“實力”,越來越被學術界重視和也被工業界廣泛應用:無需手動設計特征提取規則、泛化能力強、適應性強、準確性高。主流的方法分為三種:基于分割的方案(segmentation-based),基于錨的方法(anchor-based),基于參數的方法(parameter-based)。
基于分割的方法(segmentation-based)
顧名思義,把車道線檢測的任務當成分割任務來做,通過模型得到圖片中哪些pixels屬于車道線,哪些不是,并且知道哪些pixels是屬于同一條車道線,所以,這其實是一個實例分割(instance segmentation)的任務。
提到這類方法,不得不提它的開山之作——LaneNet!
論文地址:https://arxiv.org/pdf/1802.05591.pdf
github地址:https://github.com/MaybeShewill-CV/lanenet-lane-detection

作者用用共享的Encoder模型,設計了兩個Decoder分支:車道線分割分支和車道embedding分支。前者對像素進行二分類,輸出哪些pixels是車道線,哪些是背景,使用標準的交叉熵損失函數;后者輸出不同的車道實例,每個pixel初始化一個embedding,通過loss的設計,使得屬于同一車道的embedding距離盡可能小,屬于不同車道的embedding距離盡可能大。

得到不同車道的embedding之后,可以通過任意聚類算法來完成實例分割,論文中基于mean-shift來實現的。LaneNet的輸出是每條車道線的像素集合,但還需要通過回歸來得到完整的車道線。傳統方法通常將圖像投影到鳥瞰圖中,然后使用2階或3階多項式進行擬合。然而,這種方法存在一個問題,即變換矩陣H只被計算一次,所有圖像都使用相同的變換矩陣,這可能導致在地形變化(如山地或丘陵)的情況下產生誤差。為了解決這個問題,論文又設計了一個H-Net網絡,它能夠訓練出能夠預測變換矩陣H的模型,其實就是6個參數。H-Net的輸入是圖像數據,輸出是變換矩陣H。通過這個設計,模型能夠根據不同的場景和視角,靈活地調整變換矩陣H,從而更好地適應不同地形和環境下的車道線檢測任務。
LaneNet算是基于分割的車道線方法的先驅之作,但是除此之外,仍然有效果更棒的文章,比如:
- SCNN(論文地址:https://arxiv.org/pdf/1712.06080.pdf)的作者就發現,只用簡單的CNN來檢測車道線,無法提取pixels之間的空間關系,所以會出現當車道線被遮擋時無法被連續識別的問題。于是提出使用空間CNN(spatial CNN)的方法,來增強pixels之間橫縱方向的信息傳遞,從而提高車道線檢測的連續性。
- RESA(論文地址: https://arxiv.org/pdf/2008.13719.pdf)的作者為了提取車道線豐富的空間特征,設計了一個REcurrent Feature-Shift Aggregator模塊,利用切片特征圖的垂直和水平移動來直接信息聚合。
基于錨的方法 (anchor-based)
Anchor這個詞翻譯成中文叫“錨”,一直讓很多CV新人很不解,其實簡單的理解就是“預設的參照”。目標檢測任務中,模型對“在哪里有什么目標”不太清楚,所以我們會在圖像上預先設計好不同大小,不同長寬比的錨框(anchor boxes),任務即變成“在這個錨框中有沒有目標,離得有多遠”。那么在車道“線”檢測的任務中,預設“框”似乎有點不太合適了,而是要設計“錨線”(anchor lines)。
LineCNN的作者就是受到Faster-RCNN的啟發,提出了line proposal (LP),其實就是 anchor lines。因為車道線起始點一般都是圖像的左、下、右邊向外延伸。所以作者的LP都是從特征圖上的這三邊上的每個點,沿不同的角度,來生成的。每個LP用一個長度為77的向量表示,[負樣本的概率, 正樣本的概率, 起始坐標y, 起始坐標x, 車道線長度, 72個偏移量]。作者也設計了一款距離,用來計算車道線和LP之間的距離。
該類別的方法下,還有一個非常經典的模型——LaneATT。
論文地址:https://arxiv.org/pdf/2010.12035.pdf
代碼鏈接:https://github.com/lucastabelini/LaneATT

先用CNN提取特征,然后根據 anchor lines的x和y的坐標,在特征圖上挑出固定長度的特征,得到 ailoc,但是這個特征也只是局部特征,如果遇到車道線被遮擋的情況,還需要融合全局的特征來進行預測。所以,作者提出了一個注意力機制,用來獲取全局特征aiglob。融合后的特征,用于兩個預測分支:分類分支用來預測類別(k個類別車道線和1個背景類別);回歸分支基于anchor的起始點s,預測出線的長度L, 以及N個點的坐標與anchor的偏移。
上述兩個方法都是從圖像的左下右三個邊為起始點,去預設anchor lines,但是有的數據,可能因為車前蓋的影響,車道線并非從這三邊出發。基于此,ADNet(https://arxiv.org/pdf/2308.10481.pdf)的作者就將anchor分解為學習起點和相關方向的heatmap,消除了預設的anchor lines起始點的限制。并提出來大核注意力模塊LKA,目的是提高生成anchor的質量,增加感受野。
當然,基于anchor的車道線檢測方案,不僅僅局限于anchor lines, 還有一些其它的思路,比如:CondLaneNet (https://arxiv.org/pdf/2105.05003.pdf)就是利用一個 proposal head(作用有點類似Faster-RCNN中的Region Proposal Network),預測車道線起始點的heatmap,然后會對于特征圖中的每一行,車道線的點在每一行的位置,和在縱向的pixel會被預測出來,再通過預測一個offset,來得到車道線的點。
基于參數的方法(parameter-based)

作者設計了多項式曲線回歸(deep polynomial regression),輸出表示圖像中每個車道線的多項式。好處是可以學習整體車道表示,推理速度較快,但實際上這種方法在準確度上并不高。
BEV視角下車道線檢測
近幾年,BEV視角下的視角感知,一直發展迅速,各家公司都有自己的BEV方案。傳統的方案,就是通過多視角的相機參數標定,得到相機平面與地面的單應性矩陣,利用逆透視變換(IPM),實現從相機平面到大地平面的轉換,再把多視角的圖片拼接。但是這樣的方法最大的問題就是需要假設地面是平坦的,這在泊車場景下,應用的比較多,但是在開放路段,對于路面不平或者稍微遠距離一些的檢測任務中,就有些吃力了。所以大部分的方案,都還是基于深度學習的方法來做的。筆者沒有把這部分方法歸到上面的類別中,主要是因為這部分近幾年比較火熱,思路也與之不同。
目前比較主流的方法大體可以分為以下兩種:
- 顯式估計圖像的深度信息,完成BEV視角的構建,e.g., LSS;
- 與transformer結合,利用BEV Query查詢構建BEV特征, e.g., BEVformer;
- 作為 HD map構建的一個子任務,e.g., MapTR。
先來講講BEV的開山之作——Lift,Splat,Shoot(LSS)。
論文鏈接:https://arxiv.org/pdf/2008.05711.pdf
github鏈接:https://github.com/nv-tlabs/lift-splat-shoot

主要分為以下幾步:
第一步:生成視錐,得到的是從特征圖上的點,與原圖上的點的映射,并根據相機內外參將視錐中的點投影到車身坐標系中;
第二步:提取圖像特征,利用深度概率密度和語義信息構建圖像特征點云;
第三步:將第一步得到的車身坐標系下的點與圖像特征點云利用Voxel Pooling,壓平構建BEV特征;
第四步:對生成的BEV features利用ResNet-18進行多尺度特征提取,再進一步的特征融合;
第五步:利用特征融合后的BEV特征完成車道線語義分割任務,做交叉熵損失;
當然,基于LSS的很多變式都有不錯的效果,但是這種范式對深度的分布非常敏感,于是另一種思路誕生了,讓模型自己學習如何將圖像的特征轉化到BEV空間,來實現車道線檢測和目標檢測等任務。BEVFormer,即是如此。
論文鏈接:https://arxiv.org/pdf/2203.17270.pdf

BEVFormer最吸引人的地方就是Encoder layers的設計,包含:BEV Queries, Spatial cross-attention 和Temporal self-attention。BEV Queries可以理解為可學習參數,通過attention機制在多視角圖像中查詢特征。Spatial cross-attention以BEV Queries作為輸入的注意力層,負責獲取來自多視角的特征;Temporal self-attention則是負責聚合時間維度上特征,指來自上一幀的BEV特征。
第三個部分聊一聊 HD map。傳統的SLAM離線建圖,成本比較昂貴,流程也比較復雜,行業里大家都在做無圖NOA,但是map的信息對自動駕駛的規劃及其重要的,所以,在線構建地圖信息,也得到越來越多的關注,車道線、斑馬線、道路路沿等等。而車道線檢測可以認為是map構建的一個子任務,這也是筆者想在這里提一下的原因。MapTR?就是一種高效在線矢量化地圖構建的方法。
論文鏈接:https://arxiv.org/pdf/2208.14437.pdf
github鏈接:https://github.com/hustvl/MapTR



訓練時的損失函數也是基于這兩種分配,設計出了三個部分:classfication loss(監督地圖元素類別)、point2point loss(監督每一個預測點的位置)、edge direction loss(監督相鄰兩點連線的方向)。

大一統方法
筆者前幾天閑逛看到了一篇很有趣的論文(CVPR2024):Lane2Seq
論文鏈接:https://arxiv.org/pdf/2402.17172.pdf

上面提到的多個車道線檢測的方法類別:segmentation-based, anchor-based, parameter-based, 但是Lane2Seq的作者,覺得這太麻煩了,要精心設計的特定于任務的頭部網絡和相應的損失函數。基于此,他把通過將車道檢測作為序列生成任務來統一各種車道檢測格式 Lane2Seq僅采用簡單的基于Encoder-Decoder的Transformer架構,具有簡單的交叉熵損失。
對于Segmentation序列,并不是作pixel-wise的學習,而是作為多邊形(polygon)來學習,一個polygon的序列可以被表示成 [x1, y1, x2, y2, ..., x28, y28,<Lane>], 這里的 <Lane> 是一個類別的token;對于Anchor序列,會作為關鍵點(keypoint)的學習,一個keypoint序列可以表達成[x1, y1, x2, y2, ..., x14, y14,<Lane>];而對于Paramter序列,比如一個parameter序列可以被表示成 [a1, a2, a3, a4, a5, s, <Lane>], 這里的s是一個縱向的offset。
雖然說, Lane2Seq 不包含特定于任務的組件(指的是segmentation, anchor, parameter),但這些組件中包含的特定于任務的知識可以幫助模型更好地學習車道的特征。所以,作者提出了一種基于強化學習 (MFRL) 的多格式模型調整方法,將特定于任務的知識融入模型中,而無需改變模型的架構。受到 Task-Reward 的啟發,MFRL 將整合特定于任務的知識的評估指標作為獎勵,并使用 REINFORCE 算法來調整 Lane2Seq。作者也根據任務特定知識,為分割、錨點和參數格式提出了三種新的基于評估指標的獎勵。
# 國內首套全棧端到端自動駕駛系統開放道路測試
近日,清華大學車輛與運載學院李克強院士、李升波教授領導的研究團隊,完成了國內首套全棧式端到端自動駕駛系統的開放道路測試。依托車路云一體化智能網聯駕駛架構,該團隊研發的端到端自動駕駛系統,涵蓋了“感知-預測-決策-規劃-控制”等全鏈路環節,從今年1月份率先啟動了城市工況的開放道路驗證,經過近4個月的內部測試,完成了各項性能的綜合評估。這一工作為L3級及以上高級別自動駕駛系統的落地應用奠定了堅實的基礎。

從感知到控制的全鏈路端到端自動駕駛系統(原理圖)
目前,處于L1、L2級智能駕駛系統主要依賴“模塊分解”的設計思路,盡管部分模塊(如感知、預測等)已經初步神經網絡化,但是決策、規劃、控制等模塊仍然嚴重依賴人工規則和在線優化,缺乏利用數據進行閉環迭代的能力,這導致行車過程的智能性仍然不足。同時,模塊間不可避免地存在較大信息損失,且各模塊的優化目標存在一定沖突,不利于自動駕駛過程的綜合性能提升。與之相比,以全模塊神經網絡化為特征的“端到端”自動駕駛系統,因模塊與模塊之間的信息傳遞可依賴高維度特征向量,且神經網絡具有充分的訓練自由度,最大程度地減少了傳感器到執行器之間的信息損失,使得全棧模塊具備利用數據閉環進行快速更新的能力,這為高級別自動駕駛的智能性提升提供一條全新的技術路徑。
面向這一技術發展趨勢,李克強院士、李升波教授領導的研究團隊自2018年開始瞄準端到端自動駕駛領域進行深耕,重點突破決策、規劃與控制領域的神經網絡設計與訓練難題。團隊先后提出了面向高級別自動駕駛的集成式決控(IDC)開發框架,研發了綜合性能國際領先的數據驅動強化學習算法(DSAC),首創了時空分離的交通參與者行為預測模型(SEPT),設計了具有動作平滑特性的控制型神經網絡架構(LipsNet),開發了自主知識產權的最優控制策略近似求解器(GOPS),以螞蟻搬家的精神逐一解決了端到端自動駕駛面臨的一系列核心難題。以此為基礎,今年年初團隊成功研制了首個從傳感器原始數據到執行器控制指令的全棧神經網絡化自動駕駛系統,并率先完成了城市工況開放道路的實車測試驗證。
這一研究工作同時得到智行者、昇啟科技兩家高科技企業的全力支持,形成了校企之間緊密配合、通力協作的聯合攻關團隊。智行者團隊主要工作在于環境感知模型的構建與預訓練,昇啟科技團隊主要工作在于自動駕駛仿真平臺的開發,三家單位共同完成了系統功能集成、性能評估迭代等后期任務。該研究獲得國家“十四五”重點研發計劃、國家自然科學基金以及清華大學自主科研計劃支持。
?# 仿真平臺與端到端系統~?面向協同自動駕駛
- 論文鏈接:https://arxiv.org/pdf/2404.09496
- 代碼鏈接:https://github.com/CollaborativePerception/V2Xverse
摘要
本文介紹了面向協同自動駕駛:仿真平臺與端到端系統。車路協同輔助(V2X-AD)在提供更安全的駕駛解決方案方面具有巨大潛力。盡管在交通和通信方面進行了大量的研究以支持V2X-AD,但是這些基礎設施和通信資源在提高駕駛性能方面的實際利用仍未得到充分探索。這突顯了協同自動駕駛的必要性,即優化信息共享策略來改進每輛汽車駕駛性能的機器學習方法。這項工作需要兩個關鍵的基礎條件:一個能夠生成數據來促進V2X-AD訓練和測試的平臺,以及一個集成駕駛相關完整功能與信息共享機制的綜合系統。從平臺的角度看,本文提出了V2Xverse,這是一個用于協同自動駕駛的綜合仿真平臺。該平臺為協同駕駛提供了完整的流程:多智能體駕駛數據集生成方案、部署全棧協同駕駛系統的代碼庫、具有場景定制的閉環駕駛性能評估。從系統的角度看,本文引入了CoDriving,這是一種新型的端到端協同駕駛系統,它將V2X通信正確地集成到整個自動化流程中,促進了基于共享感知信息的駕駛。其核心思想為一種新型的面向駕駛的通信策略,即使用稀疏但信息豐富的感知線索在單視圖中選擇性地補充關鍵的駕駛區域。通過這一策略,CoDriving在優化通信效率的同時,提高了駕駛性能。本文使用V2Xverse進行全面基準測試,分析了模塊化性能和閉環駕駛性能。實驗結果表明:1)與SOTA端到端駕駛方法相比,CoDriving的駕駛得分顯著提高了62.49%,行人碰撞率急劇降低了53.50%;2)與動態約束通信條件相比,CoDriving實現了持續的駕駛性能優勢。
主要貢獻
本文的貢獻總結如下:
1)本文提出了V2Xverse,這是一個綜合的V2X輔助的自動駕駛仿真平臺。該平臺支持駕駛相關子任務的離線基準生成和不同場景下的在線閉環駕駛性能評估,從而實現協同駕駛系統的開發;
2)本文提出了CoDriving,這是一種新型的端到端協同自動駕駛系統,通過共享關鍵駕駛信息來提高駕駛性能;?
3)本文進行綜合的實驗,并且驗證了:1)支持V2X通信的信息共享顯著優于單個智能體的端到端自動駕駛系統;2)CoDriving在模塊化和系統級評估中實現了優越的性能-帶寬權衡。
總結
本項工作通過仿真平臺和端到端系統來推進協同自動駕駛。本文開發了一個綜合的閉環V2X全自動駕駛仿真平臺V2Xverse。該平臺為開發以終極駕駛性能為目標的協同自動駕駛系統提供了完整的流程。同時,V2Xverse維持了對單功能模塊和單智能體駕駛系統進行集成和驗證的適應性和可擴展性。此外,本文提出了一種新的端到端協同自動駕駛系統CoDriving,其通過共享關鍵的駕駛感知信息來提高駕駛性能,同時優化通信效率。對整個駕駛系統的綜合評估表明,CoDriving在不同的通信帶寬下顯著優于單智能體系統。本文的V2Xverse平臺和CoDriving系統為更可靠的自動駕駛提供了潛在的解決方案。
# FisheyeDetNet
?目標檢測在自動駕駛系統當中是一個比較成熟的問題,其中行人檢測是最早得以部署算法之一。在多數論文當中已經進行了非常全面的研究。然而,利用魚眼相機進行環視的近距離的感知相對來說研究較少。由于徑向畸變較大,標準的邊界框表示在魚眼相機當中很難實施。為了緩解上述提到的相關問題,我們探索了擴展邊界框的標準對象檢測輸出表示。我們將旋轉的邊界框、橢圓、通用多邊形設計為極坐標弧/角度表示,并定義一個實例分割mIOU度量來分析這些表示。所提出的具有多邊形的模型FisheyeDetNet優于其他模型,同時在用于自動駕駛的Valeo魚眼相機數據集上實現了49.5%的mAP指標。目前,這是第一個關于自動駕駛場景中基于魚眼相機的目標檢測算法研究。
文章鏈接:https://arxiv.org/pdf/2404.13443.pdf
網絡結構
我們的網絡結構建立在YOLOv3網絡模型的基礎上,并且對邊界框,旋轉邊界框、橢圓以及多邊形等進行多種表示。為了使網絡能夠移植到低功率汽車硬件上,我們使用ResNet18作為編碼器。與標準Darknet53編碼器相比,參數減少了近60%。提出了網絡架構如下圖所示。

邊界框檢測

旋轉邊界框檢測

橢圓檢測
橢圓回歸與定向框回歸相同。唯一的區別是輸出表示。因此損失函數也與定向框損失相同。
多邊形檢測
我們提出的基于多邊形的實例分割方法與PolarMask和PolyYOLO方法非常相似。而不是使用稀疏多邊形點和像PolyYOLO這樣的單尺度預測。我們使用密集多邊形注釋和多尺度預測。
實驗對比
我們在Valeo魚眼數據集上評估,該數據集有 60K 圖像,這些圖像是從歐洲、北美和亞洲的 4 個環繞視圖相機捕獲的。
所有模型都使用 IoU 閾值為 50% 的平均精度度量 (mAP) 進行比較。結果如下表所示。每個算法都基于兩個標準進行評估—相同表示和實例分割的性能。



# 100個路徑規劃相關概念
- 路徑規劃(Path Planning)
路徑規劃是尋找從起點到終點最佳路線的過程,關鍵在于如何高效地避開障礙物并優化特定的路徑指標(如距離、時間或能量消耗)。在機器人導航、自動駕駛、物流和游戲設計等領域,路徑規劃是基礎且關鍵的問題。高級路徑規劃系統還會考慮動態環境變化,如移動障礙物和不確定性因素,以適應復雜的實際應用場景。
- 廣度優先搜索(BFS)
BFS是一種圖搜索算法,從一個節點開始,逐層探索周圍節點,直到找到目標節點。它使用隊列來管理待探索的節點,保證了每一層的節點都在進入下一層之前被完全探索。這種方法特別適合于找到最短路徑問題,在無權圖(即所有邊的權重相同)中尤其有效。
- 深度優先搜索(DFS)
DFS是一種圖搜索算法,它沿著一條路徑深入探索,直到無法繼續,然后回溯到上一個分叉點繼續探索其他路徑。DFS使用棧(可以是遞歸函數調用棧)來跟蹤待探索的路徑。DFS適合于需要遍歷所有可能路徑的場景,如解決迷宮問題、圖的連通性檢查等。
- Dijkstra算法
Dijkstra算法是解決加權圖中單源最短路徑問題的經典算法。它逐步擴展已知最短路徑的邊界,直到達到目標節點。雖然Dijkstra算法能夠高效地處理大量節點,但它不適用于包含負權重邊的圖。
- 啟發式搜索(Heuristic Search)
啟發式搜索使用啟發式函數來估計從任一節點到目標的距離,從而指導搜索過程,優先探索更有希望的路徑。這種方法能夠顯著提高搜索效率,特別是在搜索空間龐大且目標位置未知的情況下。
- A*搜索算法
A算法是一種高效的啟發式搜索算法,它結合了BFS的全面性和啟發式搜索的高效性。A算法通過評估函數f(n) = g(n) + h(n)來選擇路徑,其中g(n)是從起點到當前節點的實際成本,h(n)是當前節點到目標的估計成本。A*算法廣泛應用于各種路徑規劃和圖搜索問題,如游戲設計和機器人導航。
- 基于采樣的算法
基于采樣的路徑規劃算法通過在配置空間中隨機采樣并嘗試連接這些樣本點來避免對環境的顯式表示。這些算法,特別是RRT和PRM,適用于高維空間和復雜約束條件下的路徑規劃,能夠有效處理機器人臂和移動機器人的規劃問題。
- RRT算法
RRT算法以其隨機性和簡單性而著稱,適合于解決高維空間和復雜約束下的路徑規劃問題。RRT通過從初始狀態開始,不斷向隨機采樣的狀態擴展,直到達到目標區域或滿足特定條件,從而構建出一棵覆蓋配置空間的樹。
- 運動學模型
運動學模型描述了系統的幾何運動特性,不考慮力和質量的影響。在機器人領域,運動學模型是理解和預測機器人如何在其環境中移動的基礎,對于設計控制系統和規劃運動軌跡至關重要。
- 動力學模型
動力學模型考慮了物體的運動和作用于物體的力之間的關系,提供了對系統動態行為的更深入理解。這些模型對于設計高性能機器人系統和高級控制策略非常重要,特別是在需要精確控制力和運動的應用中。
- Dubins曲線
Dubins曲線為具有最小轉彎半徑限制的車輛提供了從一點到另一點的最短路徑解決方案。這種路徑由三段組成:直線、圓弧和直線(LSL)、或圓弧、直線、圓弧(LSR)。Dubins曲線在需要考慮車輛轉向限制的路徑規劃中非常有用,如無人機和自動駕駛車輛。
- Reeds-Shepp曲線
Reeds-Shepp曲線擴展了Dubins曲線,允許路徑中包含倒車(即車輛可以向后移動)。這為路徑規劃提供了更大的靈活性,使得Reeds-Shepp曲線適用于更多種類的車輛和更復雜的規劃環境。
- 混合A*算法
混合A算法結合了經典A算法的圖搜索能力和連續空間規劃的優勢,通過離散化車輛的狀態空間來考慮車輛的動力學約束。這種方法特別適合于復雜環境中的自動駕駛汽車路徑規劃,因為它能夠生成適應車輛動力學的實際可行路徑。
- DWA算法
動態窗口法考慮了機器人的當前速度和加速度約束,通過搜索一系列在短時間內可達的速度空間(動態窗口)來選擇最優的速度和轉向角。DWA算法適用于動態環境中的避障和路徑跟蹤,特別是對于需要快速響應的移動機器人。
- TEB算法
時間彈性帶(TEB)算法是一種基于優化的路徑規劃方法,它將路徑建模為一系列連接的點,這些點可以在時間和空間中進行優化調整,以適應動態約束和避免障礙。TEB算法特別適合于需要考慮動態環境和復雜交互的應用,如自動駕駛車輛在城市交通中的導航。
- Ubuntu版本與ROS版本
Ubuntu是一個基于Debian的Linux發行版,以其用戶友好和廣泛的社區支持而聞名。ROS(Robot Operating System)是一個為機器人應用開發提供庫和工具的框架,與Ubuntu緊密集成。ROS有多個版本,每個版本通常針對特定的Ubuntu發行版進行優化。例如,ROS Noetic是專為Ubuntu 20.04 LTS(Focal Fossa)開發的,而ROS Melodic則更適合Ubuntu 18.04 LTS(Bionic Beaver)。了解ROS和Ubuntu版本之間的兼容性對于設置機器人開發環境非常重要。
- ROS(Robot Operating System)
ROS是一個開源的機器人中間件,提供了一種簡化機器人應用開發的方式。它包括一系列工具和庫,用于幫助開發者構建復雜且健壯的機器人應用。ROS的核心是其通信系統,允許不同部分的機器人系統(如傳感器、控制器、算法模塊等)通過主題、服務和動作等機制進行交互。
- TurtleBot
TurtleBot是一個流行的開源移動機器人平臺,經常用于教育和研究。它基于ROS,支持各種傳感器和擴展模塊。TurtleBot提供了一個低成本、易于使用的平臺,用于開發和測試機器人算法,包括導航、映射和交互。
- Gazebo, RViz, Stage_ros
Gazebo是一個高級的3D機器人仿真環境,能夠模擬復雜的動態和傳感器交互。
RViz是一個3D可視化工具,用于顯示ROS中的傳感器數據、機器人模型和算法輸出,支持用戶與數據進行交互。
Stage_ros是一個快速的2D機器人仿真環境,適用于測試機器人導航和路徑規劃算法。
- ROS Navigation Stack
ROS Navigation Stack是一個功能強大的軟件包,提供了使機器人能夠自主定位和導航到目標位置的工具和算法。它結合了多個組件,包括地圖構建(SLAM)、定位(AMCL)、路徑規劃(Dijkstra、A*等)和避障,為移動機器人提供了一套完整的導航解決方案。
- 柵格地圖(Grid Map)
柵格地圖通過將環境分割成一個個小方格來構建對環境的數字表示。每個方格代表環境中的一塊區域,可以存儲不同類型的信息,如該區域是否可通行(無障礙物),或者該區域的特定屬性(如地形的高度)。這種地圖的優勢在于其簡單性和直觀性,使其成為機器人路徑規劃和室內導航中常用的地圖類型。
- ESDF地圖(Euclidean Signed Distance Field)
ESDF地圖為每個點提供到最近障礙物表面的最短歐幾里得距離。正值表示該點在障礙物外部,負值表示在障礙物內部。這種地圖對于避障和路徑規劃非常有用,因為它不僅告訴機器人哪里有障礙,還提供了關于障礙物大小和形狀的詳細信息,使路徑規劃更加安全和高效。
- 維諾圖(Voronoi Diagram)
維諾圖通過將平面分割成多個區域來構建,每個區域內的所有點都比其他區域的點更接近某個特定的“種子”點。在路徑規劃中,維諾圖常被用來確定一條避開障礙物的安全路徑,因為這種路徑最大限度地遠離障礙物,從而減少與障礙物發生碰撞的風險。
- 點云地圖(Point Cloud Map)
點云地圖由一系列在三維空間中分布的點組成,每個點代表了環境中的一個特征,如物體的邊緣或表面。這些地圖通常由激光掃描儀、深度相機等傳感器生成,能夠提供環境的詳細三維結構信息,對于機器人進行精確的空間定位和環境建模至關重要。
- 拓撲地圖(Topological Map)
拓撲地圖關注的是空間中的地點(節點)及地點之間的連接關系(邊),而非具體的幾何形狀或距離。這種地圖適用于描述環境的抽象結構,如不同房間之間的關系,使得機器人可以在更大的尺度上進行有效的路徑規劃和導航。
- 差速底盤模型(Differential Drive Model)
差速底盤模型描述了兩輪獨立驅動的機器人如何通過改變兩個輪子的速度差來實現轉向和移動。這種模型適用于很多基本的移動機器人,因為它結構簡單,容易實現。通過調節左右輪的速度,機器人可以原地轉彎、直線行駛或沿曲線路徑移動。
- 自行車模型(Bicycle Model)
自行車模型是車輛運動學的一種簡化,其中車輛被假設為具有兩個輪子的自行車,前輪用于轉向,后輪在車身后部固定。這種模型在自動駕駛和車輛動力學研究中非常有用,因為它能夠以簡單的數學形式捕捉車輛的轉向動態和行為。
- 質點模型(Particle Model)
質點模型是物理學中的一個基本概念,它將物體簡化為一個具有質量但沒有體積的點,忽略其形狀和大小。這種模型適用于分析物體的線性運動(如平移),因為它忽略了旋轉和形狀變化等復雜因素。質點模型使問題簡化,便于理解和計算物體的運動狀態(如位置、速度、加速度)。
- 膨脹半徑(Inflation Radius)
在機器人路徑規劃中,膨脹半徑是一種安全策略,用于增加機器人與障礙物之間的安全距離。通過在障礙物周圍設定一個虛擬的“膨脹區域”,確保機器人在規劃路徑時不僅避開障礙物本身,還能避開這個膨脹區域,從而預留出足夠的空間來應對定位誤差、機器人尺寸或其他潛在因素,增加路徑的安全性。
- MPC(模型預測控制)
模型預測控制是一種動態系統的控制策略,其核心思想是利用系統的當前狀態來預測未來一段時間內的系統行為,并在此基礎上優化控制輸入,以實現期望的輸出。MPC在每個控制周期都會解決一個優化問題,以確定當前的最優控制動作。這種控制方法特別適合于處理有約束的系統,因為它能夠在規劃過程中考慮到系統的物理限制和操作限制。
- 硬約束和軟約束
在優化和控制問題中,硬約束是指必須被嚴格遵守的約束條件,違反硬約束會導致解變得不可接受或不可行。例如,機器人的物理尺寸限制了它不能穿過比自己小的空間,這就是一個硬約束。軟約束則是那些在優化過程中希望遵守但并非絕對必須滿足的條件。軟約束通常通過在目標函數中加入懲罰項來實現,允許在一定程度上的違反,以獲得更優的整體性能或更靈活的解決方案。
- 多項式曲線(Polynomial Curve)
多項式曲線是由多項式方程定義的一類曲線,其形式為P(x) = a_n*xn + a_{n-1}x{n-1} + ... + a_1x + a_0,其中a_n, a_{n-1}, ..., a_1, a_0是多項式的系數,n是多項式的階數。多項式曲線在插值、曲線擬合和動畫中廣泛使用,因為它們數學表達簡單,易于計算和調整。
- 貝塞爾曲線(Bezier Curve)
貝塞爾曲線是一種廣泛使用的參數曲線,特別是在計算機圖形和動畫設計中。貝塞爾曲線通過一組控制點定義,曲線形狀由這些控制點的位置和順序決定。貝塞爾曲線具有很好的數學性質,如局部控制性(移動一個控制點只影響曲線的一部分)和可變形性(通過調整控制點可以輕松改變曲線形狀),使其在設計和動畫制作中非常靈活和有用。
- 螺旋線(Spiral)
螺旋線是一種在平面或三維空間中半徑隨角度變化的曲線。在二維空間中,螺旋線從一個固定點開始,隨著角度的增加,離中心點的距離也逐漸增加。螺旋線在自然界和技術應用中都非常常見,如蝸牛的殼、春卷的形狀和道路設計中的緩和曲線。
- 離散點(Discrete Points)
離散點指的是在數學和計算機科學中,點的集合中的元素是分開的、不連續的。在數據分析、圖像處理和科學計算中,經常需要處理由離散點組成的數據集。這些點可以代表各種物理量的測量值,如溫度、壓力或其他傳感器數據。
- 泰勒展開近似
泰勒展開是一種數學方法,用來近似表示復雜函數。它將一個函數展開成多項式的形式,使我們可以用幾個簡單的項來近似計算函數的值。這種方法在物理和工程問題中非常有用,尤其是當直接計算函數值很困難時。
- 完整性約束和非完整性約束
完整性約束指的是系統的運動可以完全由其位置和位置變化來描述的約束。例如,一個可以自由移動的機器人在平面上的運動可以完全由其在該平面上的位置來描述。
非完整性約束涉及到系統的運動不能僅由位置和位置的變化來描述的情況。例如,汽車由于其轉向機制的限制,不能橫向移動。
- 凸優化
凸優化是一類特殊的優化問題,其中目標函數是凸函數,這意味著函數的任意兩點連線上的點都不低于函數曲線。凸優化問題的一個關鍵特性是它們的局部最優解也是全局最優解。凸優化在金融、機器學習和自動控制系統設計中有廣泛應用。
- 非線性優化
非線性優化是指目標函數或約束條件為非線性的優化問題。這類問題更為常見,但也更難解決。非線性優化廣泛應用于機器人路徑規劃、能源管理和化學工程設計等領域。
- 二次規劃
二次規劃是一種特殊類型的優化問題,其目標函數是二次的,而約束條件是線性的。二次規劃在投資組合優化、飛行器航跡規劃和機器人運動規劃中有重要應用。
- Eigen庫
Eigen是一個高級C++庫,用于進行矩陣運算、線性代數變換、數值解析等。它在計算機視覺、機器人技術和物理模擬中被廣泛使用,以提高數學運算的效率和準確性。
- OSQP求解器
OSQP(Operator Splitting Quadratic Program)求解器是專門用于求解凸二次規劃問題的軟件庫。它在自動駕駛車輛的軌跡優化、能量系統的優化調度等領域有著重要的應用。
- NLopt求解器
NLopt是一個用于求解非線性優化問題的庫,支持多種優化算法。它可以應用于工程設計優化、經濟學模型優化和機器學習模型調優等領域。
- 橫縱向解耦
橫縱向解耦是在車輛動力學控制中將車輛的縱向控制(加速和制動)與橫向控制(轉向)分開處理的方法。這種方法簡化了控制系統的設計,常見于自動駕駛系統的開發中。
- 時空聯合
時空聯合是在路徑規劃和調度問題中同時考慮時間和空間約束的方法。例如,在自動駕駛中,需要規劃一條既考慮避免與其他車輛和障礙物空間上的碰撞,又要考慮到達時間的路徑。
- 碰撞檢測(Collision Detection)
碰撞檢測是指在計算機模擬和機器人學中確定兩個或多個對象是否相互接觸或交叉的過程。在自動駕駛領域,碰撞檢測用于確保車輛在行駛過程中能夠避開其他車輛、行人和障礙物,從而保障行車安全。
- AABB(Axis-Aligned Bounding Box)
AABB,即軸對齊邊界盒,是一種簡單的碰撞檢測技術,其中使用與坐標軸平行的矩形或立方體來包圍物體。AABB簡化了碰撞檢測的計算,使其在計算機圖形學和游戲開發中得到廣泛應用。
- DP動態規劃(Dynamic Programming)
動態規劃是一種算法設計技術,用于解決具有重疊子問題和最優子結構的復雜問題。在自動駕駛中,動態規劃可用于路徑規劃、速度優化等,通過將大問題分解為小問題并存儲中間結果來提高計算效率。
- 曲率和曲率導數
曲率描述了曲線彎曲的程度,是曲線上任意點處切線方向變化的速率。在車輛路徑規劃中,曲率用于評估路徑的轉彎強度,確保車輛能夠安全行駛。
曲率導數則描述了曲率沿曲線的變化率,對于分析和控制車輛的轉向動態特別重要。
- 一階導數和二階導數
一階導數表示函數值隨變量變化的瞬時速率,用于描述物體的速度或曲線的斜率。
二階導數表示一階導數的變化率,用于描述加速度或曲線的凹凸性(曲率)。
- 曲線連續和平滑
曲線的連續性和平滑性是曲線幾何特性的度量,直接影響路徑規劃和車輛控制的質量。連續的曲線沒有斷點,平滑的曲線則沒有尖銳的轉彎,這對于確保自動駕駛車輛平穩舒適的行駛至關重要。
- Frenet坐標系
Frenet坐標系是一種沿著曲線定義的局部坐標系,使用曲線上的點(位置)、切向量(方向)、法向量和副法向量來描述。在自動駕駛中,Frenet坐標系常用于路徑規劃,因為它可以簡化車輛沿道路行駛的描述。
- 笛卡爾坐標系(Cartesian Coordinate System)
笛卡爾坐標系是最常見的坐標系,由垂直的x軸和y軸組成,用于在平面上定位點。自動駕駛中使用笛卡爾坐標系來表示車輛、障礙物的位置以及規劃的路徑。
- 行為決策(Behavioral Decision)
行為決策是自動駕駛系統中決定車輛行為(如變道、加速、減速)的過程。這涉及到理解周圍環境,預測其他交通參與者的行為,并根據當前的交通狀況做出安全且合理的駕駛決策。
- 轉彎半徑(Turning Radius)
轉彎半徑是指車輛進行轉彎時,車輛中心點所描述的圓的半徑。它是車輛操控性的一個重要參數,影響車輛在有限空間內的行駛能力。在自動駕駛中,合理規劃轉彎半徑對于確保車輛安全通過彎道至關重要。
- 控制量(Control Variable)
控制量是控制系統中可以被調節以影響系統行為的變量。在自動駕駛車輛中,控制量通常包括加速度、方向盤轉角等,通過調整這些變量來實現對車輛運動狀態的精確控制。
- 軌跡優化(Trajectory Optimization)
軌跡優化是尋找最優路徑的過程,使得車輛能夠在滿足所有約束(如避免碰撞、遵守交通規則)的情況下,以最優的方式(如最短時間、最低能耗)從起點移動到終點。這是自動駕駛中路徑規劃的核心環節。
- 速度規劃(Speed Planning)
速度規劃是確定車輛在路徑上的速度分布的過程。它需要考慮各種因素,如道路限速、交通狀況、曲率等,以確保行駛安全同時提高行駛效率。
- T型和S型速度曲線(Trapezoidal and S-curve Speed Profiles)
T型速度曲線(Trapezoidal Speed Profile)是指速度隨時間變化呈現線性上升、恒速和線性下降的形態,像一個梯形。這種速度曲線常用于簡單的運動控制場景。
S型速度曲線(S-curve Speed Profile)則在加速度和減速度過程中加入了平滑過渡,使得速度曲線在起始和結束時更為平滑,減少了沖擊和振動,適用于需要平滑加減速的場景。
- 自動駕駛參考線(Reference Line for Autonomous Driving)
自動駕駛參考線是車輛預計行駛的理想路徑,通常基于道路中心線或車道線生成。規劃模塊會在此基礎上生成實際的行駛軌跡,盡可能地跟隨參考線,同時考慮動態障礙物、交通規則等因素。
- BEV(Bird's Eye View)
鳥瞰視圖(BEV)是從頂部向下看的視角,提供了對車輛周圍環境的全面視圖。在自動駕駛系統中,BEV常用于融合來自多個傳感器的信息,幫助算法更好地理解車輛周圍的情況,進行決策。
- 語義信息(Semantic Information)
語義信息是指對環境元素的類型和功能的理解,如路標、車輛、行人等。在自動駕駛中,語義信息對于理解道路情況、做出正確的行為決策至關重要。通過對傳感器數據(如來自攝像頭和雷達的數據)進行深度學習分析,自動駕駛系統能夠識別和理解周圍環境的語義信息。
- 曲率突變(Curvature Discontinuity)
曲率突變是指曲線在某一點或某一區域內曲率發生急劇變化的現象。在道路和路徑規劃中,曲率突變可能導致車輛行駛不穩定,因此避免在自動駕駛車輛的路徑規劃中產生曲率突變是非常重要的。
- 換擋點(Shift Points)
換擋點是指自動變速器根據車輛速度和發動機負載決定換擋時機的點。在自動駕駛系統中,合理設置換擋點對于保證駕駛平順性和提高燃油經濟性都非常關鍵。
- SL圖和ST圖(SL and ST Graphs)
SL圖是Frenet坐標系下的表示,將車輛路徑分解為沿著道路中心線的縱向距離(S)和橫向偏移(L)。SL圖常用于路徑規劃,以簡化車輛相對于道路的位置表示。
ST圖表示時間(T)與縱向距離(S)的關系,常用于速度規劃,以確保車輛遵循預定的時空軌跡,避免碰撞,并優化行駛效率。
- 重規劃(Replanning)
重規劃是指在自動駕駛過程中,由于檢測到新的障礙物、變化的交通條件或其他未預見因素,自動駕駛系統需要重新計算路徑或行為策略。重規劃確保車輛能夠適應動態環境,安全高效地到達目的地。
- 概率完備(Probabilistic Completeness)
概率完備是指一個算法如果給予足夠的時間運行,最終能夠以高概率找到問題的解(如果解存在的話)。在自動駕駛路徑規劃中,考慮概率完備性的算法能夠在復雜環境中提高找到安全路徑的可能性。
- KPH(Kilometers Per Hour)
KPH是速度的度量單位,表示每小時行駛的公里數。在自動駕駛系統中,對車輛速度的測量、規劃和控制通常使用KPH作為單位。
- 換道(Lane Changing)
換道是指車輛從當前行駛車道轉移到另一車道的行為。自動駕駛系統中的換道決策需要考慮周圍車輛的位置、速度、以及換道后的行駛效率和安全性。
- 線控底盤(By-Wire Chassis)
線控底盤是指車輛的控制系統(如轉向、制動、加速)完全通過電子信號控制,而不是傳統的機械連接。在自動駕駛車輛中,線控底盤是實現高級自動化控制的基礎。
- Lattice Planner
格點規劃器(Lattice Planner)是一種用于路徑規劃的算法,它通過創建一個離散的格點網絡,并在這個網絡中搜索從起點到終點的最優路徑。格點規劃器能夠考慮車輛的動態約束和路況,廣泛應用于自動駕駛車輛的軌跡規劃中。
- EMPlanner
EMPlanner(Expectation Maximization Planner)是一種基于期望最大化算法的路徑和行為規劃器。它能夠處理周圍環境的不確定性,通過預測其他交通參與者的行為來規劃出一條安全高效的路徑。EMPlanner在復雜交通場景下的自動駕駛系統中特別有用。
73-74. 二次規劃和非線性優化
前文已經進行了說明,二次規劃和非線性優化是解決優化問題的兩種方法,分別處理目標函數是二次和非線性的情況。
- OSQP
前文已經介紹了OSQP求解器,它是專門用于求解凸二次規劃問題的庫,尤其適用于處理稀疏問題。
- NLopt
NLopt是一個用于非線性優化的開源庫,支持多種全局和局部優化算法。NLopt能夠處理包括無約束、有約束、連續和離散變量在內的各種優化問題。
- Ipopt
Ipopt(Interior Point OPTimizer)是一個用于求解大規模非線性優化問題的開源軟件包。它使用內點法,適用于處理具有復雜約束的優化問題,如工業設計和金融模型優化。
- 梯度下降法和擬牛頓法
梯度下降法是一種最優化算法,通過沿著目標函數梯度下降的方向迭代更新變量值來尋找函數的最小值。梯度下降法簡單易實現,適用于各種優化問題。
擬牛頓法是求解非線性優化問題的一類算法,通過逼近海森矩陣(Hessian Matrix)的逆或者海森矩陣本身來尋找函數的極小值點,提高優化的效率和準確性。
- 優化變量和決策變量
優化變量和決策變量是指在優化問題中需要被優化或決策的變量。在自動駕駛的軌跡規劃中,優化變量可能包括車輛的速度、加速度、方向等。
- 非線性約束
非線性約束是指在優化問題中約束條件為非線性方程或不等式的情況。非線性約束增加了優化問題的復雜度,常見于工程設計和經濟模型中。
- 完整性約束和非完整性約束
前文已經進行了說明,完整性約束和非完整性約束涉及系統運動的描述方式,特別是在自動駕駛車輛的動力學建模中。
- 行為決策
行為決策是指自動駕駛系統決定車輛行為(如跟車、變道、轉彎等)的過程。行為決策需要考慮交通規則、周圍環境、車輛狀態和乘客的安全與舒適。
- 有限狀態機(Finite State Machine, FSM)
有限狀態機是一種計算模型,它通過一組定義良好的狀態和在這些狀態之間的轉換來描述系統的行為。在自動駕駛系統中,有限狀態機常用于實現車輛行為的決策邏輯。
- 代碼Review
代碼Review是軟件開發過程中的一種質量保證活動,其中開發人員檢查同事的代碼,以發現錯誤并改進代碼質量。在自動駕駛系統的開發中,代碼Review是確保軟件可靠性和安全性的關鍵步驟。
- 代碼版本管理
代碼版本管理是指使用專門的工具(如Git)來管理軟件開發過程中代碼的變更歷史的做法。這使得開發團隊能夠協作開發,跟蹤每次代碼改動,并能在必要時恢復到舊版本。
- 矩陣運算
矩陣運算是線性代數中的基本運算,包括矩陣加法、乘法、轉置等。在自動駕駛系統中,矩陣運算被廣泛用于處理傳感器數據、執行數學變換和優化計算。
- 最優控制(Optimal Control)
最優控制是一種尋找控制系統最優輸入(如加速度或轉向角度)的方法,使得系統性能達到最佳。在自動駕駛中,最優控制策略可以幫助車輛以最經濟或最快的方式從一個狀態轉移到另一個狀態,同時滿足所有的動態約束和安全要求。
- MPC(Model Predictive Control)
模型預測控制是一種先進的控制策略,通過解決一系列優化問題,預測未來一段時間內的系統行為,并計算出最優控制輸入。MPC能夠考慮系統的未來行為和約束,因此在自動駕駛系統中特別有用,用于路徑規劃和避免障礙物。
- 狀態轉移方程(State Transition Equation)
狀態轉移方程描述了系統狀態如何隨時間變化,通常以數學模型的形式出現。在自動駕駛中,狀態轉移方程可以表示車輛的動態行為,如速度、加速度和位置的變化,對于預測車輛未來狀態至關重要。
- 貝塞爾曲線求導(Derivatives of Bézier Curves)
貝塞爾曲線的導數用于計算曲線在某一點的切線和曲率,對于分析和控制曲線形狀特別重要。在自動駕駛中,貝塞爾曲線及其導數可用于平滑路徑規劃和軌跡生成。
- B樣條曲線及其求導(B-spline Curves and Their Derivatives)
B樣條曲線是一種通過一組控制點定義的平滑曲線,廣泛用于計算機圖形學和路徑規劃。B樣條曲線的導數可用于分析曲線的局部性質,如切線方向和曲率,對于設計平滑連續的車輛軌跡至關重要。
- 五次多項式曲線及其曲率表達式(Quintic Polynomial Curves and Their Curvature Expressions)
五次多項式曲線是一種通過五次方程定義的曲線,常用于路徑規劃中以生成平滑的軌跡。曲率表達式描述了曲線彎曲程度的變化,對于評估路徑的可行性和安全性非常重要。
- 螺旋線與其他樣條曲線的區別
螺旋線是一種半徑隨曲線長度變化的曲線,常用于道路和軌道設計中的過渡曲線。與其他樣條曲線(如B樣條和貝塞爾曲線)相比,螺旋線在連接直線和圓弧段時能提供更平滑的轉換,減少車輛轉向時的離心力。
- 非線性最小二乘(Nonlinear Least Squares)
非線性最小二乘是一種數學優化方法,用于擬合非線性模型到數據。它通過最小化預測值和實際值之間的差異的平方和來尋找最佳擬合參數。在自動駕駛系統中,非線性最小二乘可用于傳感器數據融合和車輛狀態估計。
95-96. 微分平坦(Differential Flatness)
微分平坦是指系統的所有狀態和控制輸入都可以通過一組“平坦輸出”及其導數來表示。在無人機和無人車領域,微分平坦性使得系統的控制和規劃更加簡單,因為可以直接在平坦輸出空間中進行。
- ADAS(Advanced Driver-Assistance Systems)
高級駕駛輔助系統(ADAS)是一系列使用先進技術來提高駕駛安全和舒適性的系統。這包括自動緊急剎車、車道保持輔助、自適應巡航控制等功能。ADAS是自動駕駛技術發展的基礎。
- 高精地圖(High-Definition Maps)
高精地圖是自動駕駛系統中使用的詳細地圖,提供道路、交通標志、交通燈和其他關鍵地理信息的精確表示。高精地圖對于自動駕駛車輛的定位、導航和環境感知至關重要。
- 不確定性規劃MDP(Markov Decision Processes)
MDP是一種數學框架,用于建模決策過程中的不確定性和隨機性。在自動駕駛中,MDP可用于模擬車輛在不確定的交通環境中做出決策的過程,如何在不同的交通情況下選擇最佳的行為策略,以最大化行駛的安全性和效率。
- 概率完備性(Probabilistic Completeness)
概率完備性是指一個算法最終能夠以一定的概率找到問題的解(如果解存在)。在自動駕駛的路徑規劃中,考慮概率完備性的算法可以提高在復雜和不確定環境中找到安全路徑的可能性。
- 有限狀態機(Finite State Machine, FSM)
有限狀態機是描述一個系統可以處于有限個狀態之一,并且在給定的輸入下可以從一個狀態轉移到另一個狀態的數學模型。自動駕駛系統中的行為決策往往利用有限狀態機來管理不同的駕駛模式和行為,如巡航、變道、避障等。
- 代碼版本管理(Version Control)
代碼版本管理是使用專門的系統(如Git)來追蹤和管理軟件代碼變更的過程。這使得團隊成員可以協作開發,跟蹤每次更改,并能夠在需要時恢復到之前的版本,是自動駕駛軟件開發不可或缺的部分。
# 單目3D車道線檢測
3D車道檢測在自動駕駛中起著至關重要的作用,通過從三維空間中提取道路的結構和交通信息,協助自動駕駛汽車進行合理、安全和舒適的路徑規劃和運動控制。考慮到傳感器成本和視覺數據在顏色信息方面的優勢,在實際應用中,基于單目視覺的3D車道檢測是自動駕駛領域的重要研究方向之一,引起了工業界和學術界越來越多的關注。不幸的是,最近在視覺感知方面的進展似乎不足以開發出完全可靠的3D車道檢測算法,這也妨礙了基于視覺傳感器的完全自動駕駛汽車的發展,即實現L5級自動駕駛,像人類控制的汽車一樣駕駛。
這是這篇綜述論文得出的結論之一:在使用視覺傳感器的自動駕駛汽車的3D車道檢測算法中仍有很大的改進空間,仍然需要顯著的改進。在此基礎上,本綜述定義、分析和審查了3D車道檢測研究領域的當前成就,目前絕大部分進展都嚴重依賴于計算復雜的深度學習模型。此外,本綜述涵蓋了3D車道檢測流程,調查了最先進算法的性能,分析了前沿建模選擇的時間復雜度,并突出了當前研究工作的主要成就和局限性。該調查還包括了可用的3D車道檢測數據集的全面討論以及研究人員面臨但尚未解決的挑戰。最后,概述了未來的研究方向,并歡迎研究人員和從業者進入這個激動人心的領域。
在人工智能的推動下,自動駕駛技術近年來取得了快速發展,逐漸重塑了人類交通運輸的范式。配備了一系列傳感器,自動駕駛車輛模仿人類的視覺和聽覺等感知能力,以感知周圍環境并解釋交通場景以確保安全導航。其中關鍵的傳感器包括激光雷達、高分辨率相機、毫米波雷達和超聲波雷達,它們促進了特征提取和目標分類,并結合高精度地圖制圖來識別障礙物和車輛交通景觀。視覺傳感器是自動駕駛車輛中最廣泛使用的,它們作為環境感知的主要手段,包括車道檢測、交通信號燈分析、路標檢測和識別、車輛跟蹤、行人檢測和短期交通預測。在自動駕駛中處理和理解視覺場景,包括交通信號燈的分析、交通標志的識別、車道檢測以及附近行人和車輛的檢測,為轉向、超車、變道或剎車等操作提供更穩健和更安全的指令。傳感器數據和環境理解的整合無縫地過渡到自動駕駛中的場景理解領域,這對于推進車輛自主性和確保道路安全至關重要。
場景理解代表了自動駕駛領域中最具挑戰性的方面之一。缺乏全面的場景理解能力,使得自動駕駛車輛在交通車道中安全導航就像對于人類來說眼睛被蒙住的情況下行走一樣艱難。車道檢測尤其在場景理解的領域中是一個至關重要且具有挑戰性的任務。車道是道路上最常見的交通要素,是分割道路以確保車輛安全高效通過的關鍵標志。自動識別道路標線的車道檢測技術是不可或缺的;缺乏此功能的自動駕駛車輛可能導致交通擁堵甚至嚴重碰撞,從而危及乘客安全。因此,車道檢測在自動駕駛生態系統中起著至關重要的作用。與典型的物體不同,車道標線僅占道路場景的一小部分,并且分布廣泛,這使得它們在檢測方面具有獨特的挑戰性。此任務由于多種車道標線、光照不足、障礙物以及來自相似紋理的干擾而變得更加復雜,這些在許多駕駛場景中都很常見,因此加劇了車道檢測所固有的挑戰。
基于單目視覺的車道檢測方法主要可以分為傳統手動特征方法和基于深度學習的方法。早期的努力主要集中在提取低級手動特征,如邊緣和顏色信息。然而,這些方法通常涉及復雜的特征提取和后處理設計,并且在動態變化的場景中表現出有限的魯棒性。基于手動特征提取的傳統車道檢測算法首先通過識別車道線的顏色、紋理、邊緣、方向和形狀等特征,構建近似直線或高階曲線的檢測模型。然而,由于缺乏明顯特征并且對動態環境的適應性差,基于手動特征的傳統方法通常不夠可靠且計算開銷較大。
隨著深度學習的迅速發展,在計算機視覺領域的圖像分類、目標檢測和語義分割方面取得了重大進展,為車道檢測的研究帶來了創新的視角。深度學習中根植于深度學習的深度神經網絡(DNNs)在從圖像數據中提取特征方面具有深刻的能力,其中卷積神經網絡(CNNs)是應用最廣泛的。CNNs代表了DNNs的一種特殊類別,其特點是多個卷積層和基礎層,使其特別適用于處理結構化數據,如視覺圖像,并為各種后續任務提供高效的特征提取。在車道檢測的上下文中,這意味著利用深度CNNs實時提取高級特征,然后由模型處理以準確確定車道線的位置。
背景和相關工作
由于深度學習技術的進步,研究人員開發了許多策略,大大簡化、加快和增強了車道檢測的任務。與此同時,隨著深度學習的普及和新概念的不斷涌現,車道檢測領域的方法也得到了進一步的專業化和完善。在這個領域的主流研究軌跡上反思,基于相機的車道檢測方法可以主要分為二維(2D)和三維(3D)車道檢測范式。
2D車道檢測方法?旨在準確地描繪圖像中的車道形狀和位置,主要采用四種不同的方法:基于分割、基于anchor、基于關鍵點和基于曲線的策略。
- 基于分割的方法將2D車道檢測看作像素級分類挑戰,生成車道mask。
- 基于anchor的方法以其簡單和高效而受到贊譽,通常利用線性anchor來回歸相對于目標的位置偏移。
- 基于關鍵點的方法提供了對車道位置更靈活和稀疏的建模,首先估計點位置,然后使用不同的方案關聯屬于同一車道的關鍵點。
- 基于曲線的方法通過各種曲線方程和特定參數來擬合車道線,通過檢測起始點和結束點以及曲線參數,將2D車道檢測轉化為曲線參數回歸挑戰。
盡管2D車道檢測取得了一些進展,但在2D結果與實際應用要求之間仍存在顯著差距,尤其是對于精確的三維定位。
3D車道檢測。?由于2D車道檢測中固有的深度信息缺乏,將這些檢測投影到3D空間可能會導致不準確和降低魯棒性。因此,許多研究人員已經將他們的關注點轉向了3D領域內的車道檢測。基于深度學習的3D車道檢測方法主要分為基于CNN和基于Transformer的方法,最初構建稠密的鳥瞰特征圖,然后從這些中間表示中提取3D車道信息。
基于CNN的方法主要包括D-LaneNet,它提出了一種雙路徑架構,利用逆透視映射(IPM)將特征轉置,并通過垂直anchor回歸檢測車道。3D-LaneNet+將BEV特征分割為不重疊的單元,通過相對于單元中心的橫向偏移、角度和高度變化來解決anchor方向的限制。GenLaneNet首創使用虛構的俯視坐標系來更好地對齊特征,并引入了一個兩階段框架來解耦車道分割和幾何編碼。BEVLaneDet通過虛擬相機來確保空間一致性,并通過基于關鍵點的3D車道表示適應更復雜的場景。GroupLane在BEV中引入了基于行的分類方法,適應任何方向的車道,并與實例組內的特征信息進行交互。
基于Transformer的方法包括CLGo,提出了一個兩階段框架,能夠從圖像中估計攝像機姿態,并基于BEV特征進行車道解碼。PersFormer使用離線相機姿態構建稠密的BEV查詢,將2D和3D車道檢測統一到基于Transformer的框架下。STLanes3D使用融合的BEV特征預測3D車道,并引入了3DLane-IOU損失來耦合橫向和高度誤差。Anchor3DLane是一種基于CNN的方法,直接從圖像特征中基于3D anchor回歸3D車道,大大減少了計算開銷。CurveFormer利用稀疏查詢表示和Transformer內的交叉注意機制,有效地回歸3D車道的多項式系數。LATR在CurveFormer的查詢anchor建模基礎上構建了車道感知查詢生成器和動態3D地面位置嵌入。CurveFormer++提出了一種單階段Transformer檢測方法,不需要圖像特征視圖轉換,并直接從透視圖像特征推斷3D車道檢測結果。
挑戰與動機
準確估計車道標線的三維位置需要具有魯棒的深度感知能力,特別是在光照和天氣條件多變的復雜城市環境中。此外,由于各種因素如不同的道路類型、標線和環境條件,現實世界中用于三維車道檢測的數據表現出很高的變異性,使得在不同場景中訓練具有良好泛化能力的模型變得艱難。處理用于車道檢測的三維數據需要大量的計算資源;這在低延遲至關重要的實時應用中尤為關鍵。此外,車道標線可能會被各種環境因素如遮擋、陰影、雨雪等遮擋或破壞,給在惡劣條件下可靠檢測帶來挑戰。此外,將三維車道檢測集成到綜合感知系統中,同時使用其他傳感器如相機、激光雷達和雷達,并處理它們的聯合輸出,也面臨著集成挑戰。不幸的是,社區缺乏一個統一的、單一的參考點,以確定基于相機的三維車道檢測技術在自動駕駛中的當前成熟水平。
考慮到上述挑戰和基于視覺傳感器的語義分割在準確場景理解和解析中的重要性,在本調查中積累了現有的研究成果和成果。本調查中突出顯示的主要研究問題如下:
- 現有數據集在復雜視覺場景中具備進行3D車道檢測的潛力嗎?
- 當前方法的模型大小和推斷速度如何,這些方法能夠滿足自動駕駛車輛的實時要求嗎?
- 當前方法是否能夠有效地在包含霧和雨等不確定性的復雜視覺場景中進行三維車道檢測?
貢獻
本調查向前邁出了一步,對近年來三維車道檢測技術的最新狀態進行了批判性審查,并為社區做出了以下主要貢獻:
- 1)全面介紹了3D車道檢測技術,定義了通用流程并逐步解釋了每個步驟。這有助于該領域的新人們迅速掌握先前的知識和研究成果,特別是在自動駕駛的背景下。據我們所知,這是第一份關于基于相機的3D車道檢測的調查。
- 2)討論和批判性分析了近年來在三維車道檢測領域受到重視的最相關的論文和數據集。
- 3)對當前最先進的方法進行性能研究,考慮它們的計算資源需求以及開發這些方法的平臺。
- 4)基于分析的文獻,推導出未來研究的指導方針,確定該領域的開放問題和挑戰,以及可以有效探索的研究機會,以解決這些問題。
綜述方法論
本調查中討論的研究作品是使用不同的關鍵詞檢索而來的,例如自動駕駛中的3D車道檢測、基于視覺的3D車道檢測和基于學習的3D車道檢測。大多數檢索到的論文與研究主題直接相關,但也有一些例外,例如多模態方法和基于點云的方法,與本調查的主題關系較小。此外,上述關鍵詞在多個庫中進行了搜索,包括Web of Science和Google Scholar,以確保檢索到相關內容。包含標準確保了一篇論文被自動駕駛專家所認可,基于諸如引用次數或先前工作的影響等因素。值得一提的是,在查閱文獻時,并沒有找到基于傳統方法的單目3D車道檢測工作。這可能是因為,與單目相機的二維車道檢測不同,后者僅需要在二維圖像中識別屬于車道的像素,單目3D車道檢測需要使用二維圖像確定車道在三維空間中的三維位置信息。如果沒有像LiDAR這樣的距離測量傳感器的幫助,或者沒有通過深度學習進行預測,這是很難實現的。
自動駕駛中的單目3D車道檢測
隨著深度學習和自動駕駛技術的快速發展,基于深度學習的單目車道檢測引起了工業界和學術界的越來越多的關注。在單目車道檢測領域,早期工作主要集中在二維車道檢測上。隨著自動駕駛技術的成熟,對車道檢測提出了更高的要求,即從單張圖像中預測車道線的三維信息。因此,從2018年開始,陸續出現了關于單目3D車道檢測的工作。如圖1所示,該圖提供了單目3D車道檢測算法的時間線概述。可以看到,隨著時間的推移,越來越多的研究工作涌現出來,表明這一領域越來越受到關注。在該圖中,綠色箭頭代表基于CNN的方法,橙色箭頭代表基于Transformer的方法。

在這些方法中,3D-LaneNet是單目3D車道檢測領域的開創性工作。3D-LaneNet引入了一個網絡,可以從單目圖像中直接預測道路場景中的三維車道信息。該工作首次使用車載單目視覺傳感器解決了三維車道檢測任務。3D-LaneNet引入了兩個新概念:網絡內部特征圖逆透視映射(IPM)和基于anchor的車道表示。網絡內部IPM投影在前視圖和鳥瞰圖中促進了雙重表示信息流。基于anchor的車道輸出表示支持端到端的訓練方法,這與將檢測三維車道線的問題等同于目標檢測問題的常見啟發式方法不同。3D-LaneNet的概述如圖2所示。

受到FCOS和CenterNet等工作的啟發,3D LaneNet+是一種無anchor的三維車道檢測算法,可以檢測任意拓撲結構的三維車道線。3D LaneNet+的作者遵循了3D LaneNet的雙流網絡,分別處理圖像視圖和鳥瞰圖,并將其擴展到支持檢測具有更多拓撲結構的三維車道線。3D LaneNet+不是將整個車道預測為整體,而是檢測位于單元內的小車道段及其屬性(位置、方向、高度)。此外,該方法學習了每個單元的全局嵌入,將小車道段聚類為完整的三維車道信息。姜等設計了一個兩階段的三維車道檢測網絡,其中每個階段分別訓練。第一個子網絡專注于車道圖像分割,而第二個子網絡專注于根據第一個子網絡的分割輸出預測三維車道結構。在每個階段分別引入了高效通道注意(ECA)注意機制和卷積塊注意模塊(CBAM)注意機制,分別提高了分割性能和三維車道檢測的準確性。
郭等提出了GenLaneNet,這是一種通用且可擴展的三維車道檢測方法,用于從單張圖像中檢測三維車道線,如圖3所示。作者引入了一種新穎的幾何引導車道anchor表示,并對網絡輸出直接進行了特定的幾何變換,以計算真實的三維車道點。該anchor設計是對3D-LaneNet中anchor設計的直觀擴展。該方法將anchor坐標與底層鳥瞰圖特征對齊,使其更能處理不熟悉的場景。此外,該論文提出了一個可擴展的兩階段框架,允許獨立學習圖像分割子網絡和幾何編碼子網絡,從而顯著減少了訓練所需的三維標簽數量。此外,該論文還介紹了一個高度真實的合成圖像數據集,其中包含豐富的視覺變化,用于開發和評估三維車道檢測方法。

劉等人提出了CLGo,這是一個用于從單張圖像預測三維車道和相機姿態的兩階段框架。第一階段專注于相機姿態估計,并引入了輔助的三維車道任務和幾何約束進行多任務學習。第二階段針對三維車道任務,并使用先前估計的姿態生成鳥瞰圖像,以準確預測三維車道。PersFormer引入了第一個基于Transformer的三維車道檢測方法,并提出了一種稱為Perspective Transformer的新型架構,如圖4所示。這種基于Transformer的架構能夠進行空間特征轉換,從而實現對三維車道線的準確檢測。此外,該提出的框架具有同時處理2D和3D車道檢測任務的獨特能力,提供了一個統一的解決方案。此外,該論文還提出了OpenLane,這是一個基于具有影響力的Waymo Open數據集建立的大規模三維車道檢測數據集。OpenLane是第一個提供高質量標注和多樣化實際場景的數據集,為推動該領域的研究提供了寶貴資源。

在[108]中,研究人員介紹了最大的真實世界三維車道檢測數據集,ONCE-3DLanes數據集,并提供了更全面的評估指標,以重新激發人們對這一任務在真實場景中的興趣。此外,該論文提出了一種名為SALAD的方法,該方法可以直接從前視圖圖像生成三維車道布局,無需將特征映射轉換為鳥瞰圖(BEV),SALAD的網絡架構如圖5所示。

文章[45]提出了一種新穎的損失函數,利用了三維空間車道的幾何結構先驗,實現了從局部到全局的穩定重建,并提供了明確的監督。它引入了一個2D車道特征提取模塊,利用了來自頂視圖的直接監督,確保車道結構信息的最大保留,特別是在遠處區域,整體流程如圖7所示。此外,該論文還提出了一種針對三維車道檢測的任務特定數據增強方法,以解決地面坡度和攝像機姿態的數據分布不平衡問題,增強了在罕見情況下的泛化性能。

Bai等人提出了CurveFormer,這是一種基于Transformer的三維車道檢測算法。在這篇論文中,研究人員將解碼器層中的查詢形式化為一個動態的anchor集,并利用曲線交叉注意力模塊計算查詢與圖像特征之間的相似度。此外,他們還引入了一個上下文采樣單元,通過組合參考特征和查詢來預測偏移量,引導采樣偏移的學習過程。Ai等人提出了WS-3D-Lane,這是首次提出了一種弱監督的三維車道檢測方法,只使用2D車道標簽,并在評估中勝過了之前的3D-LaneNet 方法。此外,作者提出了一種攝像機俯仰自校準方法,可以實時在線計算攝像機的俯仰角,從而減少由不平整的路面引起的攝像機和地平面之間的俯仰角變化導致的誤差。在BEV-LaneDet 中,作者提出了虛擬攝像機,這是一個新穎的數據預測處理模塊,用于統一攝像機的外部參數和數據分布的一致性,作者提出了關鍵點表示,一種簡單而有效的三維車道結構表示。此外,還提出了基于MLP的空間轉換金字塔,這是一種輕量級結構,實現了從多角度視覺特征到BEV特征的轉換。黃等人提出了Anchor3DLane框架,直接定義了三維空間中的anchor,并且直接從前視圖中回歸出三維車道,如圖6所示。作者還提出了Anchor3DLane的多幀擴展,以利用良好對齊的時間信息并進一步提高性能。此外,還開發了一種全局優化方法,通過利用車道等寬屬性對車道進行微調。

Li等人提出了一種方法[45],可以直接從前視圖圖像中提取頂視圖車道信息,減少了2D車道表示中的結構損失。該方法的整體流程如圖7所示。作者將3D車道檢測視為從2D圖像到3D空間的重建問題。他們提出,在訓練過程中明確地施加3D車道的幾何先驗是充分利用車道間和車道內部關系的結構約束,以及從2D車道表示中提取3D車道高度信息的關鍵。作者分析了3D車道與其2D表示之間的幾何關系,并提出了一種基于幾何結構先驗的輔助損失函數。他們還證明了顯式幾何監督可以增強對3D車道的噪聲消除、異常值拒絕和結構保留。
Bai等人提出了CurveFormer 和CurveFormer++ ,這是基于Transformer的單階段方法,可以直接計算3D車道的參數,并且可以繞過具有挑戰性的視圖轉換步驟。具體來說,他們使用曲線查詢將3D車道檢測形式化為曲線傳播問題。3D車道查詢由動態和有序的anchor集表示。通過在Transformer解碼器中使用具有曲線表示的查詢,對3D車道檢測結果進行迭代細化。此外,他們引入了曲線交叉注意力模塊來計算曲線查詢與圖像特征之間的相似性。此外,提供了一個上下文采樣模塊,以捕獲更相關的曲線查詢圖像特征,進一步提高了3D車道檢測的性能。
與[66]類似,Li等人提出了GroupLane,這是一種基于按行分類的3D車道檢測方法。GroupLane的設計由兩組卷積頭組成,每組對應一個車道預測。這種分組將不同車道之間的信息交互分離開來,降低了優化的難度。在訓練過程中,使用單贏一對一匹配(SOM)策略將預測與車道標簽匹配,該策略將預測分配給最適合的標簽進行損失計算。為了解決單目圖像中不可避免的深度模糊所引起的在車道檢測過程中構建的替代特征圖與原始圖像之間的不對齊問題,Luo等人提出了一種新穎的LATR模型 。這是一個端到端的3D車道檢測器,它使用不需要轉換視圖表示的3D感知前視圖特征。具體來說,LATR通過基于車道感知的查詢生成器和動態3D地面位置嵌入構造的查詢和鍵值對之間的交叉注意力來檢測3D車道。一方面,每個查詢基于2D車道感知特征生成,并采用混合嵌入以增強車道信息。另一方面,3D空間信息作為位置嵌入從一個迭代更新的3D地面平面注入。
為了解決在將圖像視圖特征轉換為鳥瞰圖時由于忽略道路高度變化而引起的視圖轉換不準確的問題,Chen等人提出了一種高效的用于3D車道檢測的Transformer 。與傳統的Transformer不同,該模型包括一個分解的交叉注意力機制,可以同時學習車道和鳥瞰圖表示。這種方法與基于IPM的方法相比,允許更準確的視圖轉換,并且更高效。以前的研究假設所有車道都在一個平坦的地面上。然而,Kim等人認為,基于這種假設的算法在檢測實際駕駛環境中的各種車道時存在困難,并提出了一種新的算法,D-3DLD。與以前的方法不同,此方法通過利用深度感知體素映射將圖像域中的豐富上下文特征擴展到3D空間。此外,該方法基于體素化特征確定3D車道。作者設計了一種新的車道表示,結合不確定性,并使用拉普拉斯損失預測了3D車道點的置信區間。
Li等人提出了一種輕量級方法 [46],該方法使用MobileNet作為骨干網絡,以減少對計算資源的需求。所提出的方法包括以下三個階段。首先,使用MobileNet模型從單個RGB圖像生成多尺度的前視圖特征。然后,透視transformer從前視圖特征計算鳥瞰圖(BEV)特征。最后,使用兩個卷積神經網絡預測2D和3D坐標及其各自的車道類型。在論文[26]中,Han等人認為,基于曲線的車道表示可能不適用于現實場景中許多不規則車道線,這可能會導致與間接表示(例如基于分割或基于點的方法)相比的性能差距。文中作者提出了一種新的車道檢測方法,該方法可以分解為兩部分:曲線建模和地面高度回歸。具體來說,使用參數化曲線來表示鳥瞰圖空間中的車道,以反映車道的原始分布。對于第二部分,由于地面高度由路況等自然因素決定,因此地面高度與曲線建模分開回歸。此外,作者設計了一個新的框架和一系列損失函數,以統一2D和3D車道檢測任務,引導具有或不具有3D車道標簽的模型的優化。
這些方法的直觀總結如表II所示,包括方法描述、使用的數據集、開源狀態以及網絡架構。




3D車道檢測性能評估
本節將討論單目3D車道檢測模型的性能評估。在此,我們解釋評估指標、不同類型的目標函數、分析計算復雜度,并最終提供各種模型的定量比較。所使用變量的命名方式見表I。首先,呈現了3D車道線檢測的可視化結果。由于一些算法未公開源代碼,我們只在ApolloSim數據集上對一些開源算法進行了可視化測試。這些算法已在ApolloSim數據集上進行了訓練,可視化結果如圖8所示,其中紅色線表示預測的車道線,藍色線表示真值車道線。接下來,將介紹評估指標、用于訓練算法的損失函數以及在公共數據集上進行的3D車道線檢測的定量測試結果。




3D車道檢測的評估指標
僅建立預測的單目3D車道檢測模型并不明智也不可信,除非在未見數據上進行測試。大多數模型在用于訓練的相同數據集的不相交集上評估其性能,即測試數據對訓練模型來說是新的。用于單目3D車道檢測任務的深度學習模型使用一些通用指標來評估基于真實值的最佳結果。對于單目3D車道檢測任務,有不同類型的評估指標可供選擇,將在接下來的內容中進行回顧:


3D車道檢測的損失函數
在單目3D車道檢測任務中,常見的基本損失函數包括以下幾種:
MSE損失:這是最常用的損失函數之一,它計算模型預測值與真實值之間的平方差,然后取平均值。其數學表達式為:

二元交叉熵損失:二元交叉熵損失常用于訓練二元分類任務,旨在最小化損失函數以提高模型對二元分類樣本的預測準確性。它廣泛應用于深度學習任務,如圖像分類、文本分類和分割。其數學表達式為:

不同的方法使用特定的損失函數的方式各不相同,但基本上大多數都是基于上述基本損失函數的變體或組合。此外,通常使用匈牙利算法來將預測車道與真值車道匹配。
單目3D車道檢測模型的定量分析
本節詳細闡述了本文調查的單目3D車道檢測方法的定量實證分析,這有助于實現自動駕駛。對于定量評估,利用四個評估指標來檢查每種單目3D車道檢測方法在ApolloSim數據集上的性能:AP、F-Score、x誤差和z誤差,并在表IV中報告結果。在Openlane數據集上,評估了每個模型的F-Score,如表V所示。在ONCE3DLane數據集上,我們評估了四個指標,即:F-Score、Precision、Recall和CD誤差,結果報告在表VI中。此外,還考慮了計算效率,通過報告每種方法在推理過程中可達到的每秒幀數(FPS)。這些模型的總運行時間在表IV、V和VI中報告。在一些論文中,報告了算法的推理時間及其相應的硬件平臺,直接使用。然而,在其他一些論文中,未顯示算法的推理時間,因此我們在我們的實驗平臺上進行了自己的實驗來測試推理時間。我們的實驗平臺的CPU配置包括運行Ubuntu 20.04操作系統的Intel(R) Core i9-12900K CPU處理器,而實驗中使用的GPU是一塊具有12GB顯存的NVIDIA GeForce RTX 3080Ti GPU。在上述表格中,我們指定了每種方法推理所使用的硬件。
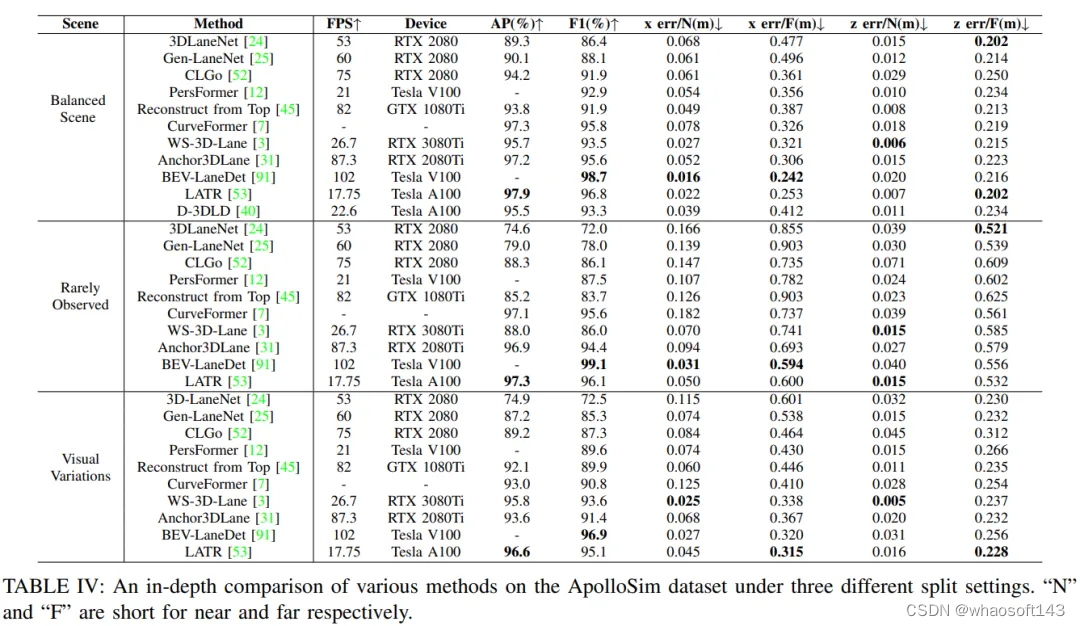
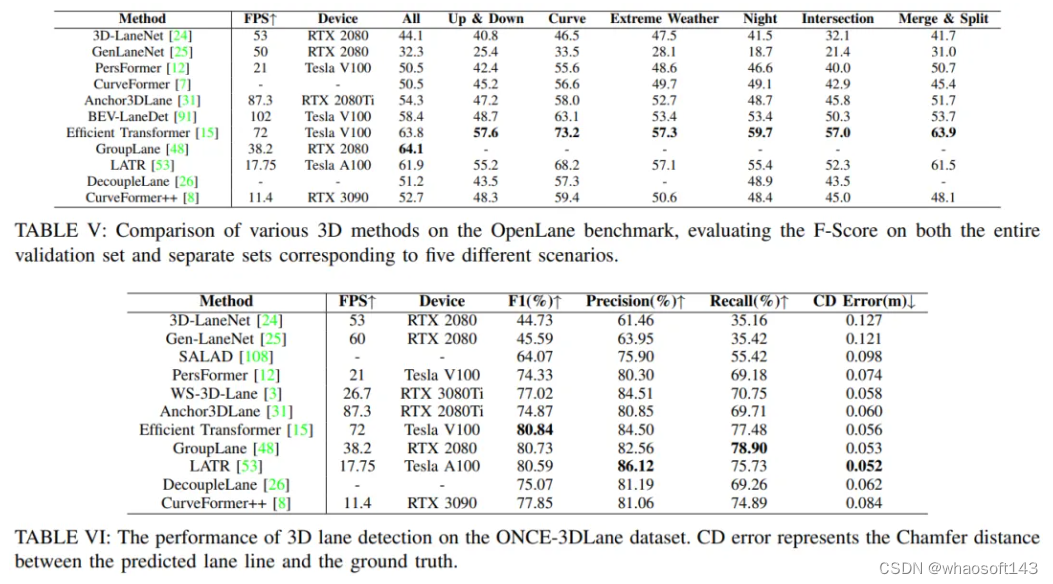
數據集
在基于深度學習的視覺任務中,同樣重要的組成部分是數據集。在本節中,將介紹當前用于單目3D車道線檢測任務的數據集。其中一些數據集是開放源代碼且受到社區廣泛使用的,而另一些僅在論文中描述,未公開。無論是開源還是專有數據集,為了更直觀地了解這些數據集,我們編制了一張詳細的表格,展示了所有現有的單目3D車道線檢測數據集,如表III所示。
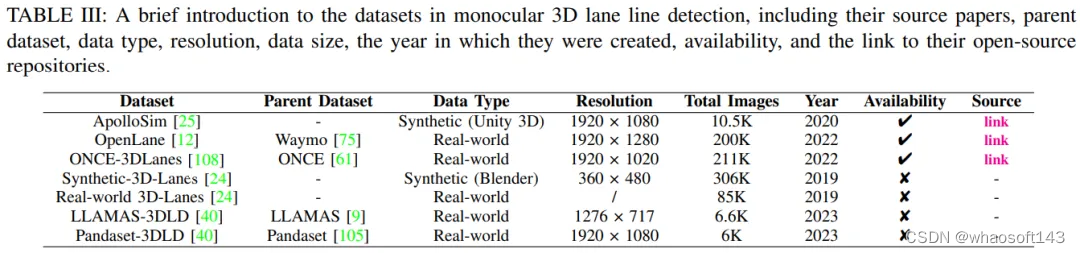
Apollo 3D Lane合成數據集
Apollo 3D Lane合成數據集是一個穩健的合成數據集,包括10,500幀高分辨率的1080 × 1920單目RGB圖像,使用Unity 3D引擎構建。每個幀都附帶相應的3D車道標簽和攝像機俯仰數據。它基于美國硅谷,涵蓋了各種環境,包括高速公路、城市區域、住宅區和市區設置。該數據集的圖像囊括了廣泛的日間和天氣條件、各種交通/障礙情況以及不同的道路表面質量,從而使數據集具有高度的多樣性和逼真度。數據集分為三種不同的場景類別:平衡場景、罕見觀察到的場景和具有視覺變化的場景。
平衡場景用于作為全面和無偏見的數據集,用于基準標準駕駛場景。罕見觀察到的場景用于測試算法對于復雜城市地圖中罕見遇到的情況的適應能力,其中包括急劇的高程變化和急轉彎。具有視覺變化的場景旨在評估算法在不同照明條件下的表現,通過在訓練期間排除特定白天時段并在測試期間專注于它們。數據集中攝像機的固定內參參數,攝像機高度范圍在1.4到1.8米之間,俯仰角范圍從0到10度。
OpenLane
OpenLane是第一個大規模、真實世界的3D車道檢測數據集,擁有超過200,000幀和880,000個精心標注的車道。OpenLane建立在具有影響力的Waymo Open數據集的基礎上,采用相同的數據格式、評估管道和10Hz的采樣率,由64束LiDAR在20秒內進行。該數據集為每個幀提供了詳盡的細節,包括攝像機內參和外參,以及車道類別,其中包括14種不同類型,如白色虛線和路邊。幾乎90%的車道由雙黃色實線和單白色實線和虛線組成。OpenLane數據集典型地展示了現實世界的情景,充分凸顯了長尾分布問題。OpenLane包含幀中的所有車道,甚至包括相反方向的車道,前提是沒有隔離路邊。由于復雜的車道拓撲結構,如交叉口和環形交叉口,一個幀可以容納多達24條車道。約25%的幀中包含超過六條車道,超過了大多數當前車道數據集的最大值。除此之外,該數據集還提供了場景標簽的注釋,例如天氣和位置,以及最接近路徑的目標(CIPO)-定義為與自車相關的最相關目標。這些輔助數據對于規劃和控制中的后續模塊至關重要,而不僅僅是感知。OpenLane的3D地面真值是使用LiDAR合成的,因此具有高精度和準確性。數據集分為包含157,000張圖像的訓練集和包含39,000張圖像的驗證集。
ONCE-3DLanes
ONCE-3DLanes數據集是另一個實用的3D車道檢測數據集,精心從ONCE自動駕駛存儲庫中提取而來。該數據集包括由前置相機捕獲的211,000個圖像,以及相應的匹配LiDAR點云數據。展示了一系列不同時間和天氣條件下的場景,如陽光明媚、陰天和雨天等,數據集涵蓋了城市中心、住宅區、高速公路、橋梁和隧道等多種地形。這種多樣性使數據集成為在各種真實世界場景下開發和驗證強大的3D車道檢測模型的關鍵資源。該數據集分為三個部分:用于驗證的3,000個場景,用于測試的8,000個場景,以及剩余的5,000個場景用于訓練。訓練組件還額外補充了200,000個未標注的場景,以充分利用原始數據。雖然數據集提供了的攝像機內參,但省略了攝像機外參。
其他數據集
論文“3D-LaneNet: End-to-End 3D Multiple Lane Detection”介紹了兩個不同的數據集:Synthetic3D-Lanes數據集和3D-Lanes數據集。通過開源圖形引擎Blender創建的Synthetic3D-Lanes數據集包括300K個訓練示例和5K個測試示例,每個示例都包含一個360×480像素的圖像以及與之關聯的真值參數,如3D車道、攝像機高度和俯仰。這個數據集在車道拓撲、目標位置和場景渲染方面具有重大的多樣性,為方法開發和消融研究提供了寶貴的資源。此外,3D-Lanes數據集是一個真實世界的真值標注數據集,通過利用多傳感器設置-前向相機、Velodine HDL32激光雷達掃描儀和高精度IMU來編制。該數據集由六個獨立的行駛記錄組成,每個記錄在不同的路段上錄制,總計近兩個小時的行駛時間。借助激光雷達和IMU數據,生成了聚合的激光雷達俯視圖像,并與半手動注釋工具一起使用,建立了真值。總共標注了85,000張圖像,其中1,000張來自一個單獨的駕駛記錄,被指定為測試集,其余作為訓練集。3D-Lanes數據集在驗證所提出的方法對真實世界數據的可轉移性以及進行定性分析方面發揮了重要作用。盡管Synthetic-3D-Lanes數據集已經向研究界開放,但真實世界的3D-Lanes數據集仍然是專有的,無法公開獲取。值得注意的是,盡管Synthetic-3D-Lanes數據集是可用的,但在后續領域研究中并沒有得到廣泛采用作為基準進行評估。
自動駕駛中的3D車道檢測:挑戰與方向
上述介紹的數據集涵蓋了各種公開可用的道路場景。當前主流研究主要集中在適合進行三維車道檢測的有利白天場景上,這些場景具有充足的照明和有利的天氣條件。然而,許多汽車公司和原始設備制造商擁有大量數據,但由于涉及知識產權、產業競爭和《通用數據保護條例》(GDPR)等問題,他們不愿意公開分享這些數據。因此,在自動駕駛研究中,缺乏足夠的帶標注數據來準確理解動態天氣條件,如夜間、霧霾天氣和邊緣情況,仍然是一個具有挑戰性的任務。
這個研究領域是社區尚未充分解決的挑戰之一。在本節中,對當前自動駕駛中三維車道檢測的現狀提出了關鍵觀點,總結了一系列挑戰,并提出了研究方向建議,以幫助社區進一步取得進展,有效地克服這些挑戰。
開放性挑戰
雖然研究人員在自動駕駛領域進行了大量研究,自動駕駛行業也在蓬勃發展,但仍然存在一些需要研究人員關注的開放性挑戰,以實現完全智能的自動駕駛。這些挑戰已經在相關文獻的支持下進行了單獨討論:
粗結構化信息:?大多數文獻中介紹的用于自動駕駛中3D車道檢測的數據集記錄在先進城市的正常和良好結構化基礎設施中。當前開發的深度學習模型可能在結構化數據集上取得最佳結果,但它們在許多非結構化環境中的泛化能力較差。自動駕駛中的這個問題需要在數據收集方面進一步關注,同時在深度學習模型中引入新的有效表示機制。
不確定性感知決策:?車道檢測和自動駕駛決策中一個被大部分忽視的方面是模型對輸入數據進行預測的置信度。然而,模型輸出的置信度在確保自動駕駛安全性方面起著至關重要的作用。車輛周圍固有的不確定性本質似乎沒有說服社區深入研究這個問題,因為目前的方法論趨勢僅關注預測分數。幸運的是,置信度估計最近在社區中引起了關注。然而,來自證據深度學習的元素、深度神經網絡的貝葉斯公式、近似神經網絡輸出置信度的簡單機制(如蒙特卡洛丟失或集成)以及其他各種不確定性量化方法,應逐步作為決策的一個額外但至關重要的標準進行融合。在處理復雜環境時,由于缺乏能夠完全代表所有可能場景的數據,模型會輸出大量的認識不確定性。如果不將置信度作為AD的一個附加因素,或者當前研究僅關注預測和/或計算效率方面,那么科學界新興的3D車道檢測模型是否會實際上有用并且可轉移至工業領域就無法保證。
弱監督學習策略:?在當前基于深度學習的模型中,大多數依賴于完全監督的學習策略,這對標注數據有很高的要求。在3D車道檢測領域,特別具有挑戰性,因為一般的視覺傳感器數據缺乏深度信息。僅憑圖像本身很難將3D信息簡單地分配給車道,需要使用LiDAR等替代傳感器獲取3D車道信息。這導致了標注3D車道數據的成本高昂和勞動密集性。幸運的是,學術界和工業界已經意識到了這個問題,并且在深度學習領域對弱監督學習策略進行了廣泛的研究和關注。然而,在3D車道檢測的特定分支中,目前針對弱監督學習策略的研究仍然有限。如果我們能夠有效地利用自監督/弱監督學習策略,將極大地降低數據收集成本,并允許更多的訓練數據來增強3D車道檢測算法的性能,從而進一步推動自動駕駛行業的發展。
未來方向
基于視頻的自動駕駛3D車道檢測:?借鑒基于視頻目標檢測、語義分割和2D車道檢測的進展,可以明顯看出,將基于視頻的技術納入其中顯著提高了3D車道檢測系統的精度和可靠性。基于視頻的方法的核心優勢在于它們能夠利用時間數據,提供靜態圖像所缺乏的動態視角。這種動態視角在理解和預測三維空間中復雜的駕駛情況中尤其重要,其中車道位置和車輛相互作用的復雜性增加。像遞歸視頻車道檢測(RVLD)這樣的方法展示了視頻捕捉持續車道變化的能力,隨時間的推移變化,這一特征對于3D建模的準確性極其有益。此外,將視頻數據納入這些系統還增強了我們對駕駛環境中空間動態的理解,這對于3D車道檢測至關重要。通過將基于視頻的目標檢測和語義分割中使用的復雜深度學習技術納入3D車道檢測系統的未來版本,可以實現先進的空間意識,顯著提高自動駕駛車輛的導航能力和安全性。
混合方法和多模態:?多模態3D車道檢測技術的進展大大加快了各種傳感器輸入(如相機、LiDAR和雷達)的整合。這種整合標志著克服現有依賴相機的系統所面臨挑戰的一個有希望的途徑。這種方法,強調了在多模態3D目標檢測和語義分割中的成功,利用了每種傳感器類型的互補優勢,以提高檢測精度和可靠性,特別是在具有挑戰性的環境和復雜駕駛場景中。回顧了“深度多傳感器車道檢測”和“M2-3DLaneNet”等開創性模型,這些模型已經有效地利用了多傳感器輸入來優化車道邊界估計,并在遮擋和光照條件變化方面表現出色,明顯的發展潛力。這一領域未來的發展軌跡應強調對先進數據融合方法、細致的傳感器校準和同步技術的探索,以及利用新興技術如邊緣計算進行實時多模態數據處理。
主動學習和增量學習:?機器學習中的主動學習指的是模型在測試階段和部署后隨時間和遇到新數據而適應和學習的能力。在現實世界的環境中,車輛可能會遇到隨機出現的陌生場景和車道拓撲,這可能需要AI模型為進一步的操作做出決策,如剎車或加速以實現合理的駕駛操作。因此,車道檢測技術應允許交互式方法來處理各種類型的場景和車道拓撲,涉及人類標注者來標注未標注的數據實例,以及人類參與訓練過程。有不同類型的主動學習技術,如成員查詢綜合,其中生成合成數據,并且根據數據的結構調整合成數據的參數,這源于數據的基礎物種。另一方面,3D車道檢測模型能夠增量地更新其對新數據的捕獲知識,對于其可持續性和持續改進至關重要。我們預計,在未來的研究中,3D車道檢測模型在道路理解方面的這兩個能力將變得越來越重要。
惡劣天氣條件:?對于自動駕駛的基于相機的3D車道檢測系統的發展受到惡劣天氣條件的明顯阻礙,這些條件嚴重影響了能見度。如大雨、霧、雪和沙塵暴等事件會嚴重影響這些系統的功能。這主要問題源于視覺數據質量的損害,這些數據對于車道標線的精確檢測和分割是必要的,導致可靠性下降,假陰性或假陽性的可能性增加。這種系統效能的降低不僅提高了安全隱患,而且限制了自動駕駛車輛的操作范圍。然而,最近在目標檢測和語義分割方面的突破,如“ACDC:適應不良條件的數據集及其對語義駕駛場景理解的對應關系”和“使用深度學習框架在惡劣天氣下的車輛檢測和跟蹤”,展示了在挑戰性天氣條件下增強3D車道檢測的途徑。這些研究提出了利用深度學習算法在包括各種惡劣天氣實例的數據集上訓練,展示了有效的數據增強、針對特定條件的領域適應和使用語義分割技術的重要性。通過采用這些方法,基于相機的檢測系統的能力可以得到大幅提升,以準確解釋車道標線,并確保在能見度差的情況下安全導航,為自動駕駛技術領域的持續研究和發展奠定了樂觀的路徑。
大型語言模型(LLM)在3D車道檢測中的應用:?大型語言模型(LLM)的出現,如ChatGPT,已經改變了人工通用智能(AGI)領域,展示了它們在使用定制用戶提示或語言指令處理各種自然語言處理(NLP)任務方面remarkable zero-shot能力。計算機視覺涵蓋了一系列與NLP中的挑戰和概念迥然不同的挑戰。視覺基礎模型通常遵循預訓練和后續微調的過程,雖然有效,但對于適應一系列下游應用而言,這意味著顯著的額外成本。技術,如多任務統一化,旨在賦予系統一系列廣泛的功能,但它們往往無法突破預先確定的任務的約束,與LLM相比,在開放式任務中留下明顯的能力缺口。視覺提示調整的出現提供了一種通過視覺mask來劃分特定視覺任務(如目標檢測、實例分割和姿態估計)的新方法。然而,目前還沒有將LLM與3D車道線檢測相結合的工作。隨著大型語言模型越來越普遍,其能力繼續提升,LLM基于車道線檢測的研究為未來的探索提供了有趣和有前途的途徑。
實現更準確高效的自動駕駛3D車道檢測方法:?當前3D車道檢測技術的定性性能如表IV所示。可以觀察到只有少數方法能夠在模型準確性和推理延遲之間取得平衡。這些方法的實驗結果表明,需要進一步改進以減輕計算負擔,同時保持其無與倫比的性能。此外,從3D車道檢測數據集中選擇了一些具有挑戰性的數據,并測試了3D車道線檢測算法在這些挑戰性數據樣本上的性能。然而,算法在極端天氣條件下的檢測性能也不令人滿意,如圖9所示。改善算法在極端天氣條件下的檢測性能也是至關重要的。此外,表IV、V和VI中報告的時間復雜性表明,一些方法在部署在GPU設備上時可以實現實時執行。然而,考慮到當今自動駕駛系統中受限的計算資源,3D車道檢測方法的重點也應轉向計算復雜性。

基于事件相機的3D車道檢測:?RGB相機受其成像原理的限制,在高速或低光場景下會產生圖像質量差的問題。幸運的是,事件相機可以克服這一限制。事件相機是具有高時間分辨率、高動態范圍、低延遲和低能耗的視覺傳感器。與傳統相機根據光的強度和顏色捕獲圖像不同,事件相機是基于光強度變化捕獲圖像的。因此,只要光強度發生變化,事件相機就可以在低光場景下捕獲圖像。目前,關于基于事件相機的3D車道檢測的研究還很有限。我們認為,在使用事件相機進行3D車道檢測領域存在重大且廣泛的研究潛力,包括開發專門用于使用事件相機進行3D車道檢測的數據集,以及設計適用于僅使用事件相機或與RGB相機結合進行3D車道檢測的算法。
考慮不確定性的3D車道檢測:?在過去幾年中,深度神經網絡(DNNs)在眾多計算機視覺任務中取得了顯著的成功,鞏固了它們作為高效自動感知的不可或缺的工具的地位。盡管在不同的基準測試和任務中始終提供出色的結果,但在廣泛實施之前,仍然有一些重要的障礙需要克服。關于DNNs最常見和最著名的批評之一是在面對數據分布水平變化時,它們容易出現性能不穩定的問題,突顯了迫切需要解決這一限制的問題。
目前,大多數深度學習模型提供確定性輸出,即給出一個結果。然而,在真實世界的駕駛場景中,希望模型能夠為其預測提供不確定性估計。下游決策模塊可以利用這些不確定性信息做出更合理和更安全的駕駛指令。例如,在3D車道檢測的情況下,如果模型輸出的車道位置具有較高的不確定性,應該對模型的檢測結果持懷疑態度,并采取保守的駕駛風格。相反,如果模型的輸出具有較低的不確定性,我們可以對算法的預測感到有信心,并做出更自信的駕駛決策。
結論
視覺傳感器是自動駕駛車輛的關鍵組成部分,在決策過程中起著關鍵作用。作為近年來增長最快的領域之一,計算機視覺技術被用于分析視覺傳感器捕獲的數據,以獲取諸如交通燈檢測、交通標志識別、可駕駛區域檢測和三維障礙物感知等有用信息。隨著傳感器技術、算法能力和計算能力的進步,視覺傳感器數據在自動駕駛車輛感知中的應用越來越受到關注。例如,基于單目圖像的3D車道檢測利用單個相機圖像獲取三維物理世界中車道線的位置,融合深度信息。了解車道線的深度信息對于自動駕駛車輛的安全和舒適的決策制定和規劃至關重要。雖然可以使用其他傳感器(如激光雷達)獲取三維車道信息,但由于其成本效益和豐富的結構化彩色信息,視覺傳感器在自動駕駛領域中發揮著至關重要的作用。
基于單目圖像的3D車道檢測在自動駕駛領域已經發展了多年。然而,現有文獻中缺乏全面的、總結性的分析。本調查回顧了現有的車道檢測方法,介紹了現有的3D車道檢測數據集,并討論了現有車道檢測方法在公共數據集上的性能比較。還分析了當前3D車道檢測面臨的挑戰和局限性。主要結論是,基于單目圖像的3D車道檢測領域的研究尚未達到完美,當前的方法存在許多限制,在調查中進行了詳細討論,并提供了相關建議和展望。涵蓋了處理深度學習模型的基線工作,它們在3D車道檢測任務中的層次結構,以及與每個模型類別相關的挑戰。此外,深入探討了自動駕駛領域中用于3D車道檢測模型的性能評估策略、損失函數和廣泛使用的數據集。通過提出開放挑戰和未來研究方向來總結這項工作,并列舉了最近文獻中的基線參考。
最后,不可否認的是,智能交通系統社區的專家們不斷努力改進3D車道檢測策略,以有效利用視覺傳感器的數據。主流研究致力于通過神經網絡的能力提高模型的準確性,或者探索新穎的神經網絡架構。然而,解決其他挑戰是實現可靠、值得信賴和安全自動駕駛的必要條件。從3D車道檢測的角度來看,這些挑戰需要更強大的模型,具備預測車道遮擋、處理粗略結構信息和提供風險警報的能力。此外,當前的3D車道檢測模型主要依賴于監督學習,這需要高質量的標注數據。然而,標注3D 車道數據是一項耗時且費力的任務。探索有價值且具有挑戰性的方法,如自監督或弱監督學習,以實現3D車道檢測是這一領域進一步發展的開放機會。如果能及時充分利用這些機會,將推動智能交通系統的研究,并將3D車道檢測提升到一個新的水平。這將使無人駕駛車輛能夠更有效地在現實環境中部署,并支持更安全、更可靠和更舒適的出行和物流服務。
# DriveMLM
大型語言模型為智能駕駛開辟了新的格局,賦予了他們類似人類的思維和認知能力。本文深入研究了大型語言模型(LLM)在自動駕駛(AD)中的潛力。進而提出了DriveMLM,這是一種基于LLM的AD框架,可以在仿真環境中實現閉環自動駕駛。具體來說有以下幾點:
- (1)本文通過根據現成的運動規劃模塊標準化決策狀態,彌合語言決策和車輛控制命令之間的差距;
- (2)使用多模態LLM(MLLM)對模塊AD系統的行為規劃模塊進行建模,該模塊AD系統使用駕駛規則、用戶命令和來自各種傳感器(如相機、激光雷達)的輸入作為輸入,并做出駕駛決策并提供解釋;該模型可以插入現有的AD系統(如Apollo)用于閉環駕駛;
- (3)設計了一個有效的數據引擎來收集數據集,該數據集包括決策狀態和相應的可解釋標注,用于模型訓練和評估。
最后我們對DriveMLM進行了廣泛的實驗,結果表明,DriveMLM在CARLA Town05 Long上獲得了76.1的駕駛分數,并在相同設置下超過阿波羅基線4.7分,證明了DriveMLM的有效性。我們希望這項工作可以作為LLM自動駕駛的基線。
DriveMLM的相關介紹
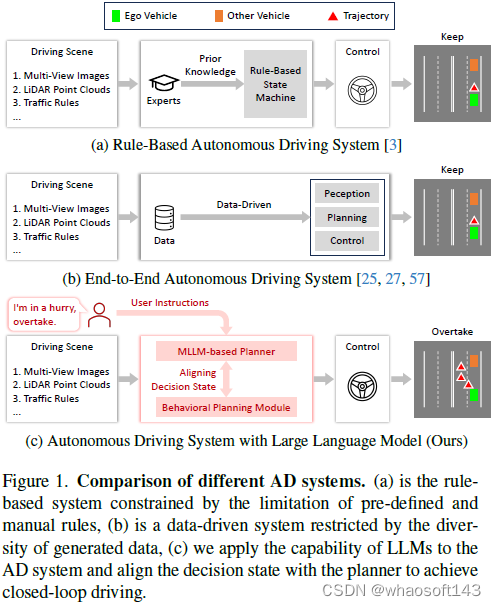
近年來,自動駕駛(AD)取得了重大進展,如圖1b所示從傳統的基于規則的系統發展到數據驅動的端到端系統,傳統的規則系統依賴于由先驗知識提供的預定義規則集(見圖1a)。盡管這些系統取得了進步,但由于專家知識的限制或訓練數據的多樣性,它們還是遇到了局限。這使得他們很難處理拐角情況,盡管人類駕駛員可能會發現處理這些情況很直觀。與這些傳統的基于規則或數據驅動的AD規劃者相比,使用網絡規模的文本語料庫訓練的大型語言模型(LLM)具有廣泛的世界知識、穩健的邏輯推理和先進的認知能力。這些功能將他們定位為AD系統中的潛在規劃者,為自動駕駛提供了一種類似人類的方法。
最近的一些研究已將LLM集成到AD系統中,重點是針對駕駛場景生成基于語言的決策。然而,當涉及到在真實世界環境或真實仿真中執行閉環駕駛時,這些方法具有局限性。這是因為LLM的輸出主要是語言和概念,不能用于車輛控制。在傳統的模塊化AD系統中,高級別策略目標和低級別控制行為之間的差距通過行為規劃模塊連接,該模塊的決策狀態可以通過后續運動規劃和控制輕松轉換為車輛控制信號。這促使我們將LLM與行為規劃模塊的決策狀態對齊,并通過使用對齊的LLM進行行為規劃,進一步設計一個基于LLM的閉環AD系統,該系統可以在真實世界的環境或現實的仿真環境上運行。
基于這一點,我們提出了DriveMLM,這是第一個基于LLM的AD框架,可以在現實仿真環境中實現閉環自動駕駛。為了實現這一點,我們有三個關鍵設計:(1)我們研究了Apollo系統的行為規劃模塊的決策狀態,并將其轉化為LLM可以輕松處理的形式。(2)開發了一種多模態LLM(MLLM)規劃器,該規劃器可以接受當前的多模態輸入,包括多視圖圖像、激光雷達點云、交通規則、系統消息和用戶指令,并預測決策狀態;(3)為了獲得足夠的行為規劃-狀態對齊的訓練數據,我們在CARLA上手動收集280小時的駕駛數據,并通過高效的數據引擎將其轉換為決策狀態和相應的解釋注釋。通過這些設計,我們可以獲得一種MLLM planner,該規劃器可以根據駕駛場景和用戶需求進行決策,并且其決策可以很容易地轉換為車輛控制信號,用于閉環駕駛。
DriveMLM有以下優勢:(1)得益于一致的決策狀態,DriveMLM可以很容易地與現有的模塊化AD系統(如Apollo)集成,以實現閉環駕駛,而無需任何重大更改或修改。(2)通過將語言指令作為輸入,我們的模型可以處理用戶需求(例如,超越汽車)和高級系統消息(例如,定義基本駕駛邏輯)。這使DriveMLM更加靈活,能夠適應不同的駕駛情況和彎道情況。(3)它可以提供可解釋性并解釋不同的決策。這增強了我們模型的透明度和可信度,因為它可以向用戶解釋其行為和選擇。
總結來說,DriveMLM的主要貢獻如下:
- 提出了一種基于LLM的AD框架,通過將LLM的輸出與行為規劃模塊的決策狀態相一致,彌合LLM和閉環駕駛之間的差距。
- 為了實現這個框架,我們用LLM可以輕松處理的形式定制了一組決策狀態,設計了一個用于決策預測的MLLM規劃器,并開發了一個數據引擎,該數據引擎可以有效地生成決策狀態和相應的解釋注釋,用于模型訓練和評估。
- 為了驗證DriveMLM的有效性,我們不僅根據閉環駕駛指標(包括駕駛分數(DS)和每次干預里程(MPI))來評估我們的方法,還使用理解指標(包括準確性、決策狀態的F1指標、決策解釋的BLEU-4、CIDEr和METEOR)來評估模型的駕駛理解能力。值得注意的是,我們的方法在CARLA Town05 Long上獲得了76.1 DS、0.955 MPI結果,這是4.7分,是Apollo的1.25倍。此外,我們可以通過用語言指令描述特殊要求來改變MLLM規劃者的決策,如圖2所示,例如為救護車或交通規則讓路

DriveMLM方法詳細介紹
概覽
DriveMLM框架將大型語言模型(LLM)的世界知識和推理能力集成到自動駕駛(AD)系統中,在逼真的仿真環境中實現閉環駕駛。如圖3所示,該框架有三個關鍵設計:(1)行為規劃狀態對齊。這一部分將LLM的語言決策輸出與Apollo等成熟的模塊化AD系統的行為規劃模塊相一致。這樣,LLM的輸出可以容易地轉換為車輛控制信號。(2)MLLM 規劃器。它是多模態標記器和多模態LLM(MLLM)解碼器的組合。多模態標記器將不同的輸入(如多視圖圖像、激光雷達、流量規則和用戶需求)轉換為統一的標記,MLLM解碼器基于統一的標記進行決策。(3)高效的數據收集策略。它為基于LLM的自動駕駛引入了一種量身定制的數據收集方法,確保了一個全面的數據集,包括決策狀態、決策解釋和用戶命令。
在推理過程中,DriveMLM框架利用多模態數據來做出駕駛決策。這些數據包括:環視圖像和點云。系統消息是任務定義、流量規則和決策狀態定義的集合。這些令牌被輸入到MLLM解碼器,MLLM解碼器生成決策狀態令牌以及相應的解釋。最后,決策狀態被輸入到運動規劃和控制模塊。該模塊計算車輛控制的最終軌跡。
Behavioral Planning States Alignment
將大型語言模型(LLM)的語言選擇轉換為可操作的控制信號對于車輛控制至關重要。為了實現這一點,我們將LLM的輸出與流行的阿波羅系統中的行為規劃模塊的決策階段相一致。根據常見方式,我們將決策過程分為兩類:速度決策和路徑決策。具體而言,速度決策狀態包括(保持、加速、減速、停止),而路徑決策狀態包括(FOLLOW、LEFT CHANGE、RIGHT CHANGE,LEFT BORROW、RIGHT BORROW)。
為了使語言模型能夠在這些狀態之間做出精確的預測,我們在語言描述和決策狀態之間建立了全面的聯系,如表1的系統信息所示。此相關性用作系統消息的一部分,并集成到MLLM計劃器中。因此,一旦LLM描述了某些情況,預測將在決策空間內收斂為清晰的決策。每次,一個速度決策和一個路徑決策被相互推斷并發送到運動規劃框架。在補充材料中可以找到決策狀態的更詳細定義。

MLLM Planner
DriveMLM的MLLM規劃器由兩個組件組成:多模態標記器和MLLM解碼器。這兩個模塊密切協作,處理各種輸入,以準確地確定駕駛決策并為這些決策提供解釋。
多模態標記器。此tokenizer設計用于有效處理各種形式的輸入:對于時序環視圖像:使用時間QFormer來處理從時間戳?T到0(當前時間戳)的環視圖像。對于激光雷達數據,我們首先輸入點云作為稀疏金字塔Transformer(SPT)主干的輸入,以提取激光雷達特征。對于系統消息和用戶指令,我們只需將它們視為普通文本數據,并使用LLM的令牌嵌入層來提取它們的嵌入。
MLLM解碼器。解碼器是將標記化輸入轉換為決策狀態和決策解釋的核心。為此,我們為基于LLM的AD設計了一個系統消息模板,如表1所示。可以看到,系統消息包含AD任務的描述、流量規則、決策狀態的定義,以及指示每個模態信息合并位置的占位符。這種方法確保了來自各種模態和來源的投入無縫整合。
輸出被格式化以提供決策狀態(見表1的Q2)和決策解釋(見表一的Q3),從而在決策過程中提供透明度和清晰度。關于監督方法,我們的框架遵循常見做法,在下一個令牌預測中使用交叉熵損失。通過這種方式,MLLM規劃者可以對來自不同傳感器和來源的數據進行詳細的理解和處理,并將其轉化為適當的決策和解釋。
Efficient Data Engine
我們提出了一個數據生成范式,可以在CARLA模擬器中從各種場景創建決策狀態和解釋注釋。該管道可以解決現有駕駛數據的局限性,這些數據缺乏訓練基于LLM的AD系統的決策狀態和詳細解釋。我們的管道由兩個主要組件組成:數據收集和數據注釋。
數據收集旨在提高決策的多樣性,同時保持現實。首先,在仿真環境中構建各種具有挑戰性的場景。安全駕駛需要復雜的駕駛行為。然后,專家,無論是經驗豐富的人類司機還是特工,都被要求安全地駕駛通過這些場景,這些場景是在其眾多可通行的地點之一觸發的。值得注意的是,當專家隨機提出駕駛需求并相應地駕駛時,會生成交互數據。一旦專家安全地開車到達目的地,就會記錄數據。
數據標注主要側重于決策和解釋。首先,通過使用手工制定的規則,根據專家的駕駛軌跡自動注釋速度和路徑決策狀態。其次,解釋標注首先基于場景生成,由附近的當前元素動態定義。第三,生成的解釋標注由人工標注進行細化,并通過GPT-3.5擴展其多樣性。此外,交互內容也由人工注釋器進行細化,包括執行或拒絕人工請求的情況。通過這種方式,我們避免了昂貴的逐幀決策狀態標注,以及昂貴的從頭開始手動編寫解釋標注,大大加快了我們的數據標注過程。
實驗
數據分析
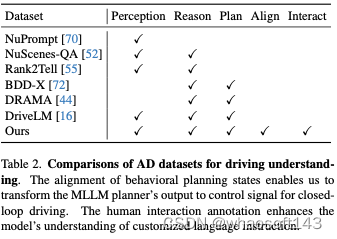
我們收集了280小時的駕駛數據進行培訓。這些數據包括50公里的路線,在CARLA的8張地圖(Town01、Town02、Town03、Town04、Town06、Town07、Town10HD、Town12)上收集了30種不同天氣和照明條件的駕駛場景。平均而言,每個場景在每個地圖上有大約200個觸發點要被隨機觸發。每種情況都是駕駛中常見或罕見的安全關鍵情況。這些場景的詳細信息見補充說明。對于每一幀,我們收集來自前、后、左、右四個攝像頭的圖像,以及來自添加在ego車輛中心的激光雷達傳感器的點云。我們收集的所有數據都有相應的解釋和準確的決策,這些解釋和決策成功地推動了場景的發展。
表2展示了與之前為使用自然語言進行駕駛理解而設計的數據集的比較。我們的數據有兩個獨特的特點。第一個是行為規劃狀態的一致性。這使我們能夠將MLLM規劃器的輸出轉換為控制信號,以便我們的框架能夠在閉環駕駛中控制車輛。二是人際互動標注。它的特點是人類給出的自然語言指令以及相應的決定和解釋。目標是提高理解人類指令并做出相應反應的能力。
閉環自動駕駛評測
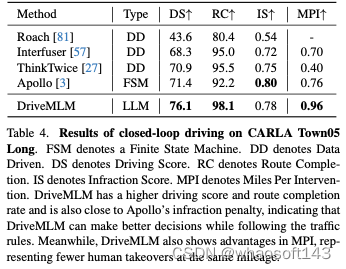
我們在CARLA中評估閉環駕駛,CARLA是公開可用的最廣泛使用和最現實的模擬基準。包括能夠在CARLA中執行閉環驅動的現有技術方法,用于性能比較。開源Apollo也在CARLA中作為基線進行了評估。除了我們的方法外,沒有其他基于LLM的方法顯示出部署和評估的準備狀態。所有方法均在Town05長期基準上進行評估。
表4列出了駕駛分數、路線完成和違規分數。請注意,盡管Apollo是一種基于規則的方法,但它的性能幾乎與最近的端到端方法不相上下。DriveMLM在駕駛分數上大大超過了所有其他方法。這表明DriveMLM更適合處理狀態轉換,以安全地通過硬盤。表4中的最后一列顯示了MPI評估的結果。該指標顯示了更全面的駕駛性能,因為需要代理人完成所有路線。換言之,所有路線上的所有情況都會被測試的代理遇到。Thinktwice實現了比Interfuser更好的DS,但由于經常越過停止線,MPI更低。然而,CARLA對這種行為的處罰微乎其微。相比之下,MPI將每一次違反交通規則的行為視為一次接管。DriveMLM還實現了所有其他方法中最高的MPI,這表明它能夠避免更多情況,從而獲得更安全的駕駛體驗。
駕駛知識評測
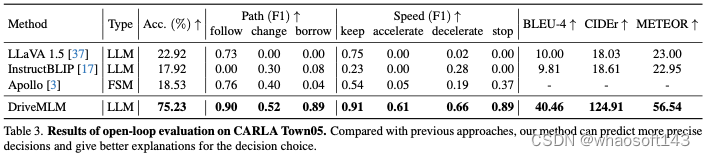
我們采用開環評估來評估駕駛知識,包括決策預測和解釋預測任務。表3顯示了預測決策對的準確性、決策預測的每種決策類型的F1分數,以及預測解釋的BLEU-4、CIDEr和METEOR。對于Apollo,Town05上手動收集的場景將作為表3中模型的輸入進行回放。回放的每個時間戳處的相應模型狀態和輸出被保存為用于度量計算的預測。對于其他方法,我們給他們相應的圖像作為輸入和適當的提示。通過將模型預測與我們手動收集的地面實況進行比較,準確性揭示了決策的正確性和與人類行為的相似性,F1分數展示了每種路徑和速度決策的決策能力。DriveMLM總體上達到了最高的準確率,以40.97%的準確率超過了LLaVA。與Apollo基線相比,DriveMLM的F1得分更高,這表明它在解決各種道路情況時更有效地超越了基于規則的狀態機。LLaVA、InstructionBLIP和我們提出的DriveMLM可以以問答的形式輸出決策解釋。在BLEU-4、CIDEr和METEOR方面,DriveMLM可以實現最高的性能,表明DriveMLM能夠對決策做出最合理的解釋。
消融實驗
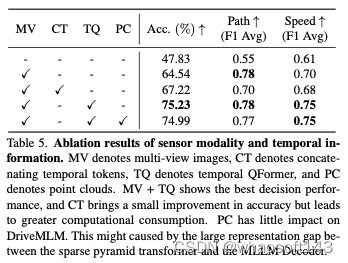
傳感器模態:表5展示了輸入傳感器模態對DriveMLM的不同影響的結果。多視圖(MV)圖像在路徑和速度F1得分方面都帶來了顯著的性能改進,準確率提高了18.19%。與直接連接時間令牌相比,時間QFormer在確保多模態決策能力的同時,實現了7.4%的更大改進,從而使速度決策的平均F1得分提高了0.05。點云不會顯示出增強性能的能力。? ?
Case Study和可視化
人機交互:圖4提供了如何通過人工指令實現車輛控制的示例。控制過程包括分析道路狀況、做出決策選擇和提供解釋性陳述。當給出相同的“超車”指令時,DriveMLM根據對當前交通狀況的分析顯示出不同的響應。在右側車道被占用而左側車道可用的情況下,系統選擇從左側超車。然而,在給定指令可能構成危險的情況下,例如當所有車道都被占用時,DriveMLM會選擇不執行超車動作,并做出適當反應。在這種情況下,DriveMLM是人車交互的接口,它根據交通動態評估指令的合理性,并確保其在最終選擇行動方案之前符合預定義的規則。

真實場景中的性能:我們在nuScenes數據集上應用DriveMLM來測試開發的駕駛系統的零樣本性能。我們在驗證集上注釋了6019個幀,決策準確度的零樣本性能為0.395。圖5顯示了兩個真實駕駛場景的結果,表明了DriveMLM的通用性。

結論
在這項工作中,我們提出了DriveMLM,這是一種利用大型語言模型(LLM)進行自動駕駛(AD)的新框架。DriveMLM可以通過使用多模態LLM(MLLM)對模塊化AD系統的行為規劃模塊進行建模,在現實仿真環境中實現閉環AD。DriveMLM還可以為其駕駛決策生成自然的語言解釋,這可以提高AD系統的透明度和可信度。我們已經證明,DriveMLM在CARLA Town05 Long基準上的表現優于Apollo基準。我們相信,我們的工作可以激發更多關于LLM和AD整合的研究。
開源鏈接:https://github.com/OpenGVLab/DriveMLM

:Agglomerative Transformer for Human-Object Interaction Detection)




)






)


)


