文章目錄
- 前言
- 1.數據預處理
- 1.1數據集介紹
- 1.2數據集抽取
- 1.3劃分數據集
- 1.4數據清洗
- 1.5數據保存
- 2.樣本的向量化表征
- 2.1詞匯表
- 2.2向量化
- 2.3自定義數據集
- 2.4備注
- 結語
前言
本篇博客主要介紹自然語言處理領域中一個項目案例——文本分類,具體而言就是判斷評價屬于積極還是消極的模型,選用的模型屬于最簡單的單層感知機模型。
1.數據預處理
1.1數據集介紹
本項目數據集來源:2015年,Yelp 舉辦了一場競賽,要求參與者根據點評預測一家餐廳的評級。該數據集分為 56 萬個訓練樣本和3.8萬個測試樣本。共計兩個類別,分別代表該評價屬于積極還是消極。這里以訓練集為例,進行介紹展示:
import pandas as pdtrain_reviews=pd.read_csv('data/yelp/raw_train.csv',header=None,names=['rating','review'])
train_reviews,train_reviews.rating.value_counts()
運行結果:
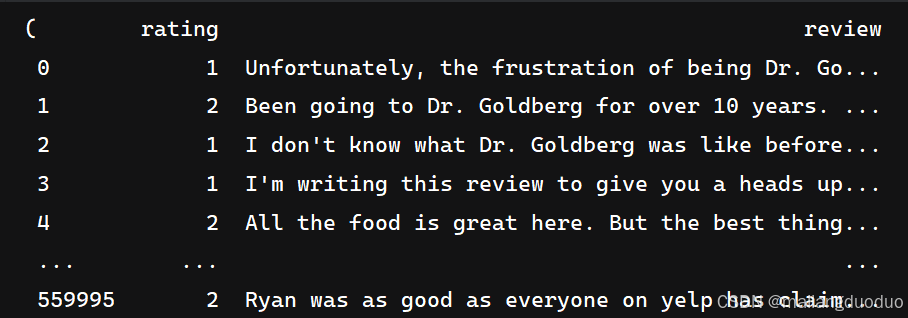
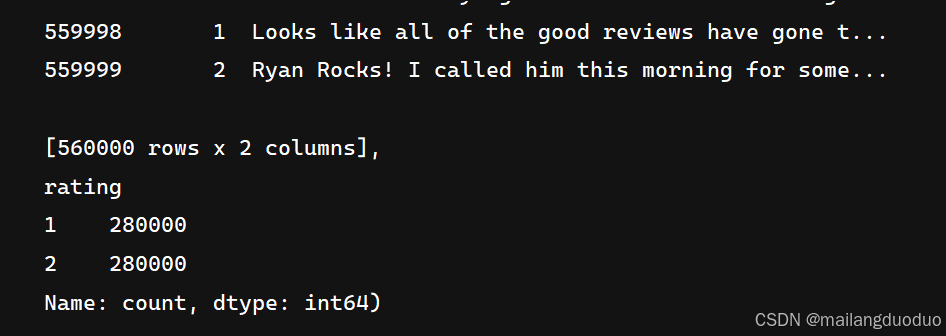
共計兩個類別,同時類別數量相等,因此不需要進行類平衡操作。因為當前數據集過大,因此這里對數據集進行抽取。
1.2數據集抽取
首先,將兩個類別的數據分別使用兩個列表進行保存。代碼如下:
import collectionsby_rating = collections.defaultdict(list)
for _, row in train_reviews.iterrows():by_rating[row.rating].append(row.to_dict())運行查看:
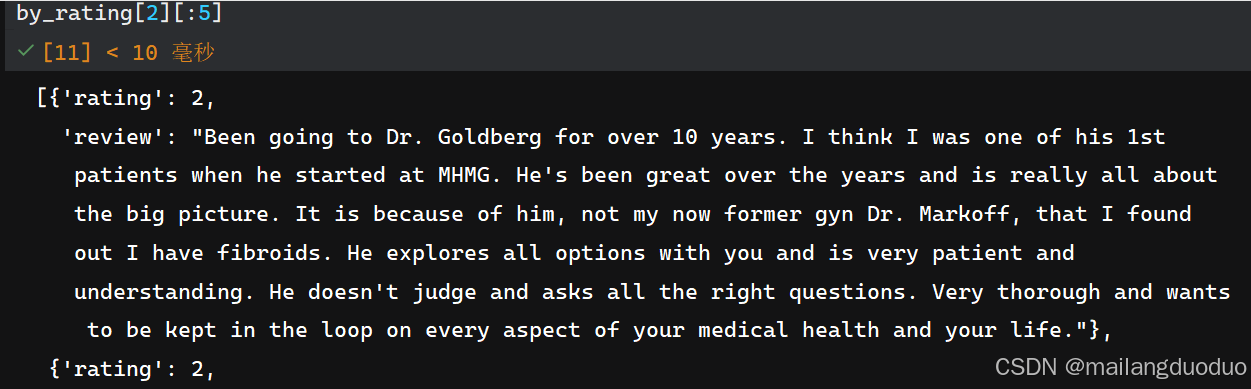
共計兩個類別,分別存儲在by_rating[1]和by_rating[2]對于的列表中。
接著選擇合適的比例將數據從相應的類別中抽取出來,這里選擇的比例為0.01,具體代碼如下:
review_subset = []
for _, item_list in sorted(by_rating.items()):n_total = len(item_list)n_subset = int(0.01 * n_total)review_subset.extend(item_list[:n_subset])
為了可視化方便,這里將抽取后的子集轉化為DataFrame數據格式,具體代碼如下:
review_subset = pd.DataFrame(review_subset)
review_subset.head(),review_subset.shape
運行結果:
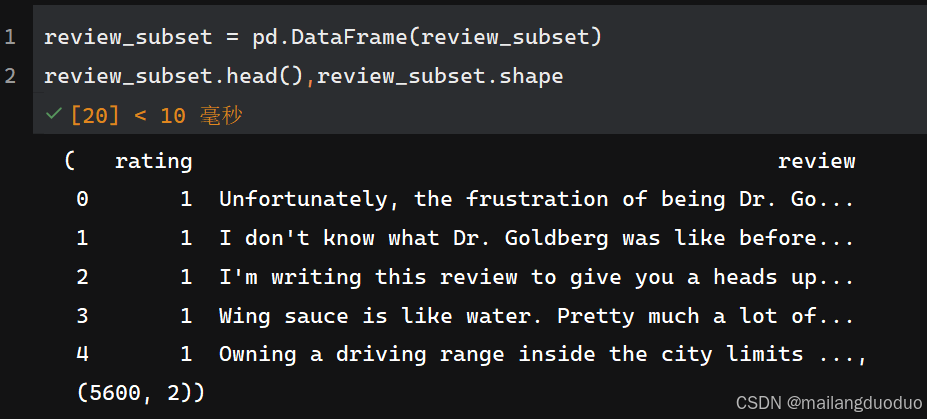
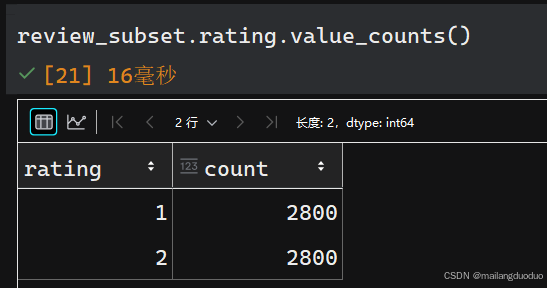
共計兩個類別,每個類別均有2800條數據。
1.3劃分數據集
首先,將兩個類別的數據分別使用兩個列表進行保存。代碼如下:
by_rating = collections.defaultdict(list)
for _, row in review_subset.iterrows():by_rating[row.rating].append(row.to_dict())因為該過程包括了打亂順序,為了保證結果的可重復性,因此設置了隨機種子。這里劃分的訓練集:驗證集:測試集=0.70:0.15:0.15,同時為了區分數據,增加了一個屬性split,該屬性共有三種取值,分別代表訓練集、驗證集、測試集。
import numpy as npfinal_list = []
np.random.seed(1000)for _, item_list in sorted(by_rating.items()):np.random.shuffle(item_list)n_total = len(item_list)n_train = int(0.7 * n_total)n_val = int(0.15 * n_total)n_test = int(0.15 * n_total)for item in item_list[:n_train]:item['split'] = 'train'for item in item_list[n_train:n_train+n_val]:item['split'] = 'val'for item in item_list[n_train+n_val:n_train+n_val+n_test]:item['split'] = 'test'final_list.extend(item_list)
同理為了可視化方便,將其轉化為DataFrame類型,代碼如下:
final_reviews = pd.DataFrame(final_list)
final_reviews.head()
運行結果:
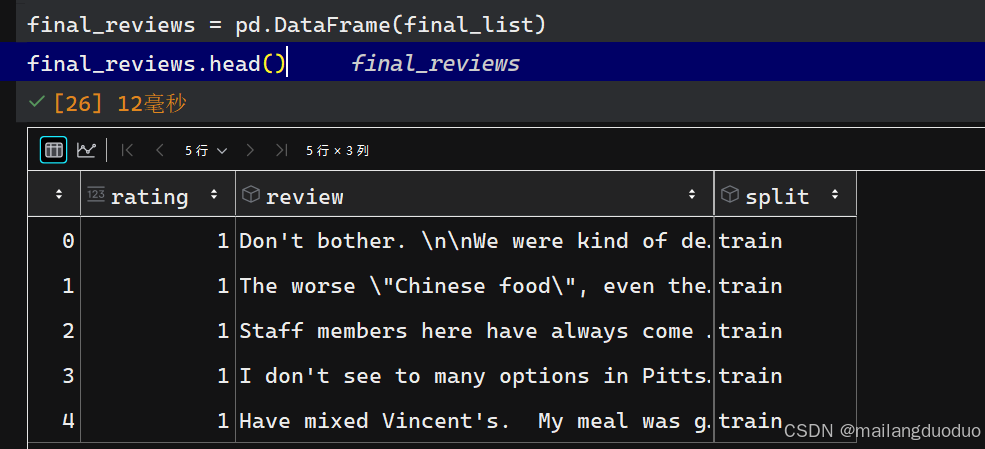
從上述結果可以看到,每條數據中還是有很多無意義的字符,如\,因此希望將其過濾掉,這就需要對數據進行清洗。
1.4數據清洗
這里為了將無意義的字符去除掉,自然就會想到正則表達式,用于匹配指定格式的字符串。具體操作代碼如下:
import redef preprocess_text(text):text = text.lower()text = re.sub(r"([.,!?])", r" \1 ", text)text = re.sub(r"[^a-zA-Z.,!?]+", r" ", text)return textfinal_reviews.review = final_reviews.review.apply(preprocess_text)
這里對上述代碼進行解釋:
\1:指的是被匹配的字符,該段代碼的功能是將匹配到的標點符號前后均加一個空格。- 第二個正則表達式:將除表示的字母及標點符號,其他符號均使用空格替代。
運行結果:
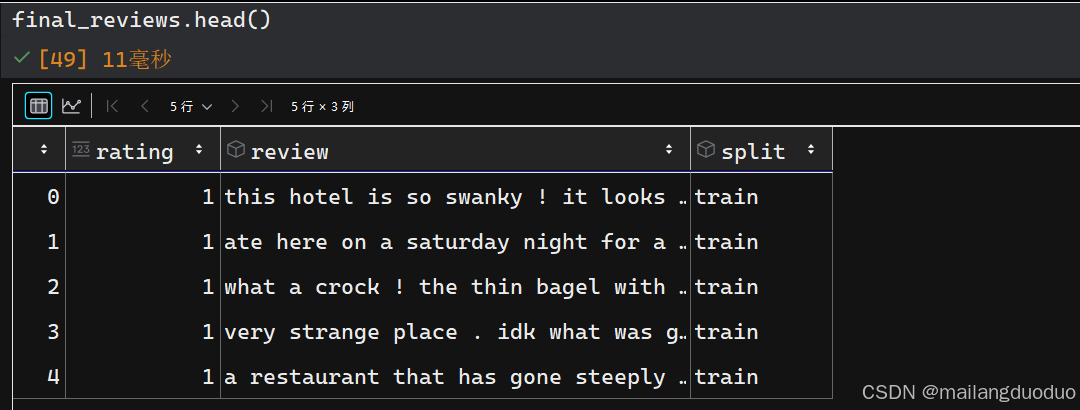
這里為了更好的展示數據,將rating屬性做了更改,替換為negative和positive,
代碼如下:
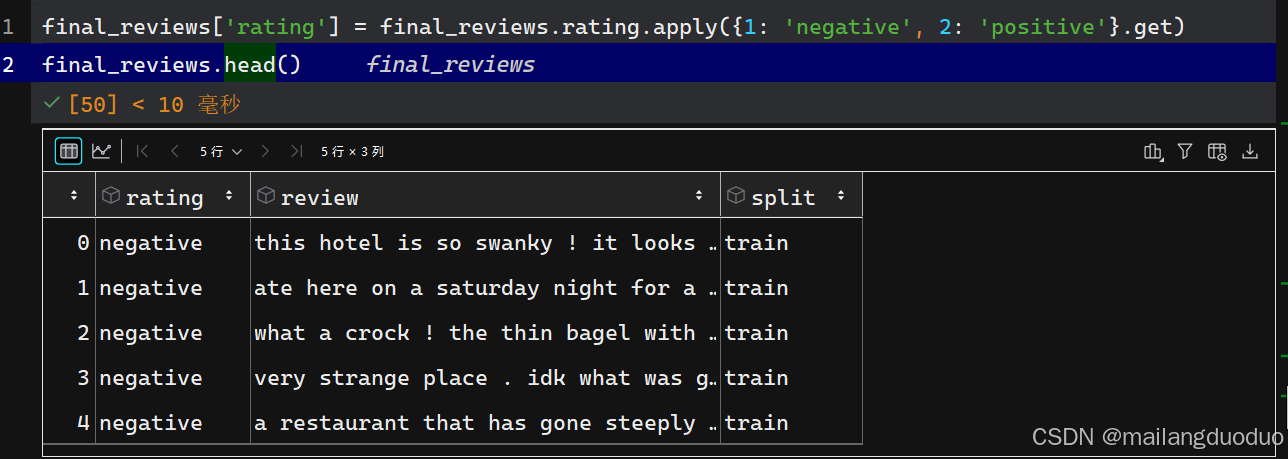
final_reviews['rating'] = final_reviews.rating.apply({1: 'negative', 2: 'positive'}.get)
final_reviews.head()
運行結果:
1.5數據保存
至此數據預處理基本完成,這里將處理好的數據進行保存。
final_reviews.to_csv('data/yelp/reviews_with_splits_lite_new.csv', index=False)
在輸入模型前,總不能是一個句子吧,因此需要將每個樣本中的review表示為向量化。
2.樣本的向量化表征
2.1詞匯表
這里定義了一個 Vocabulary 類,用于處理文本并提取詞匯表,以實現單詞和索引之間的映射。具體代碼如下:
class Vocabulary(object):"""處理文本并提取詞匯表,以實現單詞和索引之間的映射"""def __init__(self, token_to_idx=None, add_unk=True, unk_token="<UNK>"):"""參數:token_to_idx (dict): 一個已有的單詞到索引的映射字典add_unk (bool): 指示是否添加未知詞(UNK)標記unk_token (str): 要添加到詞匯表中的未知詞標記"""if token_to_idx is None:token_to_idx = {}self._token_to_idx = token_to_idxself._idx_to_token = {idx: token for token, idx in self._token_to_idx.items()}self._add_unk = add_unkself._unk_token = unk_tokenself.unk_index = -1if add_unk:self.unk_index = self.add_token(unk_token) def to_serializable(self):"""返回一個可序列化的字典"""return {'token_to_idx': self._token_to_idx, 'add_unk': self._add_unk, 'unk_token': self._unk_token}@classmethoddef from_serializable(cls, contents):"""從一個序列化的字典實例化 Vocabulary 類"""return cls(**contents)def add_token(self, token):"""根據傳入的單詞更新映射字典。參數:token (str): 要添加到詞匯表中的單詞返回:index (int): 該單詞對應的整數索引"""if token in self._token_to_idx:index = self._token_to_idx[token]else:index = len(self._token_to_idx)self._token_to_idx[token] = indexself._idx_to_token[index] = tokenreturn indexdef add_many(self, tokens):"""向詞匯表中添加一組單詞參數:tokens (list): 一個字符串單詞列表返回:indices (list): 一個與這些單詞對應的索引列表"""return [self.add_token(token) for token in tokens]def lookup_token(self, token):"""查找與單詞關聯的索引,若單詞不存在則返回未知詞索引。參數:token (str): 要查找的單詞返回:index (int): 該單詞對應的索引注意:`unk_index` 需要 >=0(即已添加到詞匯表中)才能啟用未知詞功能"""if self.unk_index >= 0:return self._token_to_idx.get(token, self.unk_index)else:return self._token_to_idx[token]def lookup_index(self, index):"""返回與索引關聯的單詞參數: index (int): 要查找的索引返回:token (str): 該索引對應的單詞異常:KeyError: 若索引不在詞匯表中"""if index not in self._idx_to_token:raise KeyError("索引 (%d) 不在詞匯表中" % index)return self._idx_to_token[index]def __str__(self):"""返回表示詞匯表大小的字符串"""return "<Vocabulary(size=%d)>" % len(self)def __len__(self):"""返回詞匯表中單詞的數量"""return len(self._token_to_idx)
這里對該類中方法體做以下解釋:
__init__構造方法:若token_to_idx為 None,則初始化為空字典。_idx_to_token是索引到單詞的映射字典,通過_token_to_idx反轉得到。若add_unk為 True,則調用add_token 方法添加未知詞標記,并記錄其索引。to_serializable 方法:返回一個字典,包含_token_to_idx、_add_unk和_unk_token,可用于序列化存儲。from_serializable: 是類方法,接收一個序列化的字典,通過解包字典參數創建 Vocabulary 類的實例。add_token 方法:用于向詞匯表中添加單個單詞。若單詞已存在,返回其索引;否則,分配一個新索引并更新兩個映射字典。add_many 方法:用于批量添加單詞列表,返回每個單詞對應的索引列表。lookup_token 方法:根據單詞查找對應的索引。若單詞不存在且unk_index大于等于 0,則返回 unk_index;否則,返回單詞的索引。lookup_index 方法:根據索引查找對應的單詞。若索引不存在,拋出 KeyError 異常。__str__ 方法返回一個字符串,顯示詞匯表的大小。__len__ 方法:返回詞匯表中單詞的數量。
2.2向量化
此處定義了 ReviewVectorizer 類,其作用是協調詞匯表(Vocabulary)并將其投入使用,主要負責把文本評論轉換為可用于模型訓練的向量表示。具體代碼如下:
class ReviewVectorizer(object):""" 協調詞匯表并將其投入使用的向量化器 """def __init__(self, review_vocab, rating_vocab):"""參數:review_vocab (Vocabulary): 將單詞映射為整數的詞匯表rating_vocab (Vocabulary): 將類別標簽映射為整數的詞匯表"""self.review_vocab = review_vocabself.rating_vocab = rating_vocabdef vectorize(self, review):"""為評論創建一個壓縮的獨熱編碼向量參數:review (str): 評論文本返回:one_hot (np.ndarray): 壓縮后的獨熱編碼向量"""# 初始化一個長度為詞匯表大小的全零向量one_hot = np.zeros(len(self.review_vocab), dtype=np.float32)# 遍歷評論中的每個單詞for token in review.split(" "):# 若單詞不是標點符號if token not in string.punctuation:# 將向量中對應單詞索引的位置置為 1one_hot[self.review_vocab.lookup_token(token)] = 1return one_hot@classmethoddef from_dataframe(cls, review_df, cutoff=25):"""從數據集的 DataFrame 實例化向量化器參數:review_df (pandas.DataFrame): 評論數據集cutoff (int): 基于詞頻過濾的閾值參數返回:ReviewVectorizer 類的一個實例"""# 創建評論詞匯表,添加未知詞標記review_vocab = Vocabulary(add_unk=True)# 創建評分詞匯表,不添加未知詞標記rating_vocab = Vocabulary(add_unk=False)# 添加評分標簽到評分詞匯表for rating in sorted(set(review_df.rating)):rating_vocab.add_token(rating)# 統計詞頻,若詞頻超過閾值則添加到評論詞匯表word_counts = Counter()for review in review_df.review:for word in review.split(" "):if word not in string.punctuation:word_counts[word] += 1for word, count in word_counts.items():if count > cutoff:review_vocab.add_token(word)return cls(review_vocab, rating_vocab)@classmethoddef from_serializable(cls, contents):"""從可序列化的字典實例化 ReviewVectorizer參數:contents (dict): 可序列化的字典返回:ReviewVectorizer 類的一個實例"""# 從可序列化字典中恢復評論詞匯表review_vocab = Vocabulary.from_serializable(contents['review_vocab'])# 從可序列化字典中恢復評分詞匯表rating_vocab = Vocabulary.from_serializable(contents['rating_vocab'])return cls(review_vocab=review_vocab, rating_vocab=rating_vocab)def to_serializable(self):"""創建用于緩存的可序列化字典返回:contents (dict): 可序列化的字典"""return {'review_vocab': self.review_vocab.to_serializable(),'rating_vocab': self.rating_vocab.to_serializable()}
這里對該類中方法體做以下解釋:
__init__方法:類的構造方法,接收兩個 Vocabulary 類的實例:
review_vocab:將評論中的單詞映射為整數。
rating_vocab:將評論的評分標簽映射為整數。vectorize 方法:將輸入的評論文本轉換為壓縮的獨熱編碼向量。具體操作為:
首先創建一個長度為詞匯表大小的全零向量 one_hot。
遍歷評論中的每個單詞,若該單詞不是標點符號,則將向量中對應單詞索引的位置置為 1。
最后返回處理好的獨熱編碼向量。from_dataframe類方法:用于從包含評論數據的 DataFrame 中實例化ReviewVectorizer。具體操作為:
創建兩個Vocabulary實例,review_vocab添加未知詞標記,rating_vocab不添加。
遍歷數據框中的評分列,將所有唯一評分添加到 rating_vocab 中。
統計評論中每個非標點單詞的出現頻率,將出現次數超過 cutoff 的單詞添加到 review_vocab 中。
最后返回 ReviewVectorizer 類的實例。from_serializable 方法:從一個可序列化的字典中實例化ReviewVectorizer。
從字典中提取review_vocab和rating_vocab對應的序列化數據,分別創建 Vocabulary 實例。
最后返回 ReviewVectorizer 類的實例。to_serializable 方法:創建一個可序列化的字典,用于緩存 ReviewVectorizer 的狀態。調用 review_vocab 和 rating_vocab 的 to_serializable 方法,將結果存儲在字典中并返回。
2.3自定義數據集
該數據集繼承Dataset,具體代碼如下:
class ReviewDataset(Dataset):def __init__(self, review_df, vectorizer):"""參數:review_df (pandas.DataFrame): 數據集vectorizer (ReviewVectorizer): 從數據集中實例化的向量化器"""self.review_df = review_dfself._vectorizer = vectorizer# 從數據集中篩選出訓練集數據self.train_df = self.review_df[self.review_df.split=='train']# 訓練集數據的數量self.train_size = len(self.train_df)# 從數據集中篩選出驗證集數據self.val_df = self.review_df[self.review_df.split=='val']# 驗證集數據的數量self.validation_size = len(self.val_df)# 從數據集中篩選出測試集數據self.test_df = self.review_df[self.review_df.split=='test']# 測試集數據的數量self.test_size = len(self.test_df)# 用于根據數據集劃分名稱查找對應數據和數據數量的字典self._lookup_dict = {'train': (self.train_df, self.train_size),'val': (self.val_df, self.validation_size),'test': (self.test_df, self.test_size)}# 默認設置當前使用的數據集為訓練集self.set_split('train')@classmethoddef load_dataset_and_make_vectorizer(cls, review_csv):"""從文件加載數據集并從頭創建一個新的向量化器參數:review_csv (str): 數據集文件的路徑返回:ReviewDataset 類的一個實例"""review_df = pd.read_csv(review_csv)# 從數據集中篩選出訓練集數據train_review_df = review_df[review_df.split=='train']return cls(review_df, ReviewVectorizer.from_dataframe(train_review_df))@classmethoddef load_dataset_and_load_vectorizer(cls, review_csv, vectorizer_filepath):"""加載數據集和對應的向量化器。用于向量化器已被緩存以便重復使用的情況參數:review_csv (str): 數據集文件的路徑vectorizer_filepath (str): 保存的向量化器文件的路徑返回:ReviewDataset 類的一個實例"""review_df = pd.read_csv(review_csv)vectorizer = cls.load_vectorizer_only(vectorizer_filepath)return cls(review_df, vectorizer)@staticmethoddef load_vectorizer_only(vectorizer_filepath):"""一個靜態方法,用于從文件加載向量化器參數:vectorizer_filepath (str): 序列化的向量化器文件的路徑返回:ReviewVectorizer 類的一個實例"""with open(vectorizer_filepath) as fp:return ReviewVectorizer.from_serializable(json.load(fp))def save_vectorizer(self, vectorizer_filepath):"""使用 JSON 將向量化器保存到磁盤參數:vectorizer_filepath (str): 保存向量化器的文件路徑"""with open(vectorizer_filepath, "w") as fp:json.dump(self._vectorizer.to_serializable(), fp)def get_vectorizer(self):"""返回向量化器"""return self._vectorizerdef set_split(self, split="train"):"""根據數據框中的一列選擇數據集中的劃分參數:split (str): "train", "val", 或 "test" 之一"""self._target_split = splitself._target_df, self._target_size = self._lookup_dict[split]def __len__(self):"""返回當前所選數據集劃分的數據數量"""return self._target_sizedef __getitem__(self, index):"""PyTorch 數據集的主要入口方法參數:index (int): 數據點的索引返回:一個字典,包含數據點的特征 (x_data) 和標簽 (y_target)"""row = self._target_df.iloc[index]# 將評論文本轉換為向量review_vector = \self._vectorizer.vectorize(row.review)# 獲取評分對應的索引rating_index = \self._vectorizer.rating_vocab.lookup_token(row.rating)return {'x_data': review_vector,'y_target': rating_index}def get_num_batches(self, batch_size):"""根據給定的批次大小,返回數據集中的批次數量參數:batch_size (int): 批次大小返回:數據集中的批次數量"""return len(self) // batch_sizedef generate_batches(dataset, batch_size, shuffle=True,drop_last=True, device="cpu"):"""一個生成器函數,封裝了 PyTorch 的 DataLoader。它將確保每個張量都位于正確的設備上。"""dataloader = DataLoader(dataset=dataset, batch_size=batch_size,shuffle=shuffle, drop_last=drop_last)for data_dict in dataloader:out_data_dict = {}for name, tensor in data_dict.items():out_data_dict[name] = data_dict[name].to(device)yield out_data_dict這里不對代碼進行解釋了,關鍵部分已添加注釋。
2.4備注
上述代碼可能過長,導致難以理解,其實就是一個向量化表征的思想。上述采用的思想就是基于詞頻統計的,將整個訓練集上的每條評論數據使用split(" ")分開形成若干個token,統計這些token出現的次數,將頻次大于cutoff=25的token加入到詞匯表中,并分配一個編碼,其實就是索引。樣本中的每條評論數據應該怎么表征呢,其實就是一個基于上述創建的詞匯表的獨熱編碼,因此是一個向量。
至此樣本的向量化表征到此結束。接著就到定義模型,進行訓練了。
結語
為了避免博客內容過長,這里就先到此結束,后續將接著上述內容進行闡述!后續直達鏈接,同時本項目也是博主接觸的第一個NLP領域的項目,如有不足,請批評指正!!!
備注:本案例代碼參考本校《自然語言處理》課程實驗中老師提供的參考代碼








)










?)