**摘要:**數字人技術從靜態建模邁向動態交互,AI與動作捕捉技術的深度融合推動其智能化發展。盡管面臨表情僵硬、動作脫節、交互機械等技術瓶頸,但通過多模態融合技術、輕量化動捕方案等創新,數字人正逐步實現自然交互與情感表達。未來,數字人將成為連接物理世界與數字空間的虛擬生命體,推動社會進入虛實共生的新紀元。
一、數字人技術的演進與核心瓶頸

1.1 從靜態建模到動態交互的跨越
數字人技術的發展歷程,是一部從簡單到復雜、從靜態呈現到動態交互的技術進化史。早期,數字人主要以靜態建模的形式出現在影視、游戲等領域,依靠手工細致地構建模型與精心預設的動作庫,來賦予數字人基本的形象和動作。但這種方式下的數字人,宛如被定格在特定場景中的木偶,缺乏與外界實時互動的能力,也難以展現出豐富多元的個性化表達。
隨著元宇宙概念如風暴般席卷而來,虛擬世界與現實世界的邊界變得愈發模糊,用戶對于虛擬形象的要求達到了前所未有的高度。他們渴望數字人不再是機械、刻板的存在,而是能如同真實人類一般,自然流暢地交流,根據不同情境做出恰當反應,擁有獨特的個性魅力 。這種強烈的需求,如同洶涌的浪潮,推動著數字人技術朝著智能化、實時化的方向奮勇突破。
在影視制作中,早期的數字人角色動作生硬,表情單一,與真實演員的生動表現形成鮮明對比。而如今,借助先進的動作捕捉和 AI 技術,數字人能夠呈現出細膩入微的表情變化和流暢自然的肢體動作,與真實場景完美融合,讓觀眾難辨真假。在游戲領域,曾經的 NPC 只是按照固定程序執行簡單任務,如今的數字人 NPC 則能根據玩家的行為和指令,實時調整策略,提供更加豐富多樣的游戲體驗,使整個游戲世界充滿生機與活力。

1.2 核心技術短板分析
盡管數字人技術在不斷發展,但仍存在一些核心技術短板,嚴重制約了數字人的自然度與交互能力。
-
表情僵硬:傳統動畫驅動方式,主要依賴預先設定的關鍵幀和簡單的動畫曲線來控制數字人的表情變化。然而,人類的表情是一個極其復雜的生理過程,涉及到數十塊面部肌肉的協同運動,每一個細微的表情變化都蘊含著豐富的情感信息。傳統動畫驅動難以精準模擬這些微表情以及肌肉之間的聯動關系,導致數字人的表情顯得十分僵硬、不自然,仿佛戴著一層冰冷的面具,無法傳遞出真實的情感。
-
動作脫節:預設動作庫中的動作是在特定情境下預先錄制和編輯的,當數字人在實時對話場景中需要使用這些動作時,往往會出現與對話內容和場景不匹配的情況。在一場商務談判的模擬場景中,數字人可能會突然做出一個過于隨意的肢體動作,或者在說話時動作的節奏與語言表達完全不一致,給人一種強烈的脫節感,極大地影響了交互的沉浸感和真實性。
-
交互機械:缺乏對上下文的深入理解和情感響應能力,是當前數字人交互的一大痛點。在與用戶交流時,數字人常常只能基于簡單的關鍵詞匹配來做出回應,無法真正理解用戶話語背后的深層含義、情感傾向以及復雜的語境信息。當用戶以一種幽默、隱喻的方式提問時,數字人可能會給出一個刻板、生硬的回答,完全無法捕捉到其中的情感和意圖,使得交互過程顯得機械、無趣,難以建立起真正的情感連接。
二、AI 與動作捕捉的技術協同

2.1 AI:賦予數字人 “智慧大腦”
- 自然語言處理:實現多輪對話與行業知識庫構建
自然語言處理(NLP)是 AI 賦予數字人語言交互能力的關鍵技術。通過 Transformer 架構的持續優化,數字人對自然語言的理解和生成能力得到了質的飛躍。在多輪對話場景中,數字人能夠運用上下文理解技術,準確把握用戶意圖。當用戶詢問 “我想找一款輕薄本,預算 5000 左右”,數字人不僅能理解用戶對筆記本電腦的需求,還能在后續對話中進一步追問 “對處理器性能有要求嗎”“需要長續航的款式嗎” 等,通過多輪交互,精準定位用戶需求,提供符合預算且輕薄便攜、性能適配的筆記本推薦。
在行業應用中,構建專業的行業知識庫與 NLP 技術相結合,能讓數字人成為行業專家。在金融領域,數字人客服可利用知識庫中的金融產品信息、市場動態、政策法規等知識,解答用戶關于理財產品、貸款業務、投資風險等復雜問題;在醫療領域,結合醫學知識庫,數字人可以輔助醫生進行初步的癥狀問詢、病史記錄,并提供常見疾病的預防和治療建議,為患者提供便捷的醫療咨詢服務。
- 情感計算:通過語音語調分析生成對應表情動作
情感計算技術使數字人能夠感知用戶的情感狀態,并做出相應的情感反饋。數字人通過對用戶語音中的語調、語速、音量以及文本中的詞匯、語氣等多模態信息進行分析,判斷用戶的情感傾向,如高興、悲傷、憤怒、焦慮等。當檢測到用戶語氣興奮、語速較快,可能表達高興的情緒時,數字人會展現出微笑的表情,眼神明亮,身體姿態放松且微微前傾,傳遞出積極的回應;若識別到用戶聲音低沉、語速緩慢,可能處于悲傷情緒,數字人則會呈現出關切的表情,語氣輕柔舒緩,給予安慰和支持。
在智能客服場景中,情感計算的應用能顯著提升用戶體驗。當用戶因產品問題而情緒激動時,數字人客服能夠及時感知到用戶的憤怒情緒,迅速切換到安撫模式,用溫和的語言和關切的態度緩解用戶的不滿,避免矛盾升級,增強用戶對品牌的好感度和信任度。
- 內容生成:自動生成符合場景的文本、圖像與視頻
基于 AI 的內容生成技術,如生成對抗網絡(GAN)、擴散模型等,使數字人能夠根據不同的場景和需求,自動生成高質量的文本、圖像和視頻內容。在社交媒體營銷場景中,數字人可以根據品牌特點和推廣需求,生成吸引人的文案和精美的海報圖像。為時尚品牌推廣新品時,數字人能創作出富有感染力的文案,描述新品的設計靈感、時尚元素和穿著場景,同時生成展示新品細節和穿搭效果的圖像,助力品牌吸引消費者的關注。
在視頻創作領域,數字人可以根據給定的故事情節或主題,自動生成視頻腳本,并利用圖像生成技術生成視頻畫面,再結合語音合成技術添加旁白和對話,快速制作出宣傳視頻、教學視頻等。這大大提高了內容創作的效率和多樣性,滿足了不同行業對內容生產的需求。

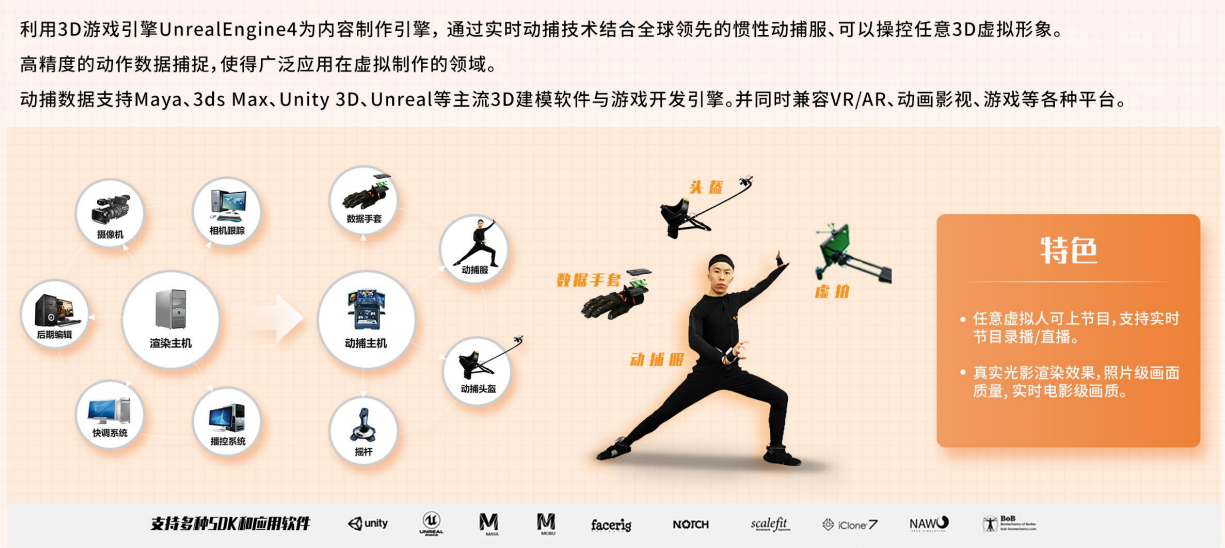
2.2 動作捕捉:構建數字人 “靈動身軀”
- 光學捕捉:通過紅外攝像頭追蹤標記點,實現毫米級精度
光學動作捕捉系統主要由紅外光攝像機、被動或主動標記以及動作捕捉分析軟件組成。紅外光攝像機對運動場景進行高頻率捕捉和記錄,被動或主動標記被貼在人體的特定關節部位,這些標記可以反射或者發出紅外光,使得攝像機能夠精確地捕捉和跟蹤它們的位置。通過對這些標記位置的實時跟蹤,系統能夠獲取人體的動作信息,并將其轉化為數字信號,經過分析軟件處理后,實現對數字人動作的精確驅動。
在影視制作中,光學動作捕捉技術被廣泛應用于打造逼真的虛擬角色。《阿凡達》中納美人的動作捕捉就借助了光學捕捉技術,演員身上貼滿標記點,在拍攝過程中,紅外攝像機實時追蹤標記點的運動軌跡,將演員的動作精準地傳遞給虛擬角色,使納美人的動作流暢自然,栩栩如生,為觀眾帶來了震撼的視覺體驗。由于其高精度的特點,光學捕捉在對動作細節要求極高的動畫制作、虛擬現實交互等領域也發揮著重要作用,能夠實現毫米級精度,為各種精細的運動分析和虛擬場景交互提供了可能。
- 慣性捕捉:基于 MEMS 傳感器記錄關節運動,突破空間限制
慣性動作捕捉技術基于微機電系統(MEMS)傳感器,將多個小型的慣性傳感器佩戴在人體關節部位,如手腕、腳踝、膝蓋、手肘等。這些傳感器能夠實時記錄關節的加速度、角速度和磁場等數據,通過內置的算法對這些數據進行分析和處理,計算出各個關節的運動姿態和角度變化,從而實現對人體動作的捕捉。與光學捕捉相比,慣性捕捉不受空間環境的限制,無需大型的場地和復雜的光學設備,用戶可以在任何空間內自由活動,實現動作的采集。在戶外的增強現實(AR)游戲中,玩家佩戴慣性捕捉設備,能夠在自然環境中自由奔跑、跳躍、揮動手臂,游戲中的虛擬角色能夠實時同步玩家的動作,為玩家帶來沉浸式的游戲體驗。在舞蹈教學領域,舞者可以佩戴慣性捕捉設備,在舞蹈教室中進行舞蹈動作的錄制和分析,教師可以通過回放捕捉到的動作數據,對舞者的動作進行精準指導,幫助舞者提升舞蹈技巧。
- 單目視覺:普通攝像頭即可完成低成本動作采集
單目視覺動作捕捉技術利用普通的攝像頭作為采集設備,通過計算機視覺算法對攝像頭拍攝的視頻圖像進行分析和處理,實現對人體動作的捕捉。該技術基于人體骨骼模型和機器學習算法,首先對視頻圖像中的人體進行檢測和識別,然后通過關鍵點檢測算法定位人體的關鍵關節點,如頭部、肩部、肘部、手腕、髖部、膝蓋和腳踝等。根據這些關鍵點的位置和運動軌跡,計算出人體的動作姿態和運動信息。由于只需要普通攝像頭,單目視覺動作捕捉具有成本低、易于部署的優勢,適用于一些對精度要求相對較低但對成本敏感的場景。在智能家居領域,用戶可以通過家中的智能攝像頭,與智能音箱中的數字人進行簡單的動作交互,如揮手控制音樂播放、點頭確認指令等,為用戶提供便捷的交互體驗;在健身領域,一些健身應用利用手機攝像頭實現單目視覺動作捕捉,用戶在進行健身訓練時,手機攝像頭可以實時捕捉用戶的動作,判斷動作是否標準,并提供實時的健身指導和反饋,幫助用戶科學健身。
2.3 協同工作機制
AI 與動作捕捉的協同工作機制,是數字人實現自然交互的核心。當數字人接收到用戶的輸入,無論是語音還是文本,AI 模型首先對其進行解析。若輸入為語音,語音識別模塊會將語音轉換為文本,然后自然語言處理模塊對文本進行語義理解和分析,提取關鍵詞、識別用戶意圖,并結合上下文信息和情感分析,生成語義理解結果和情感標簽。假設用戶對數字人說 “今天心情不太好,給我講個笑話吧”,自然語言處理模塊會識別出用戶心情低落以及想要聽笑話的意圖,同時賦予情感標簽為 “悲傷”。
基于這些結果,動作引擎會從預先建立的動作庫和表情庫中,匹配與語義和情感相符合的肢體語言和表情。在這個例子中,數字人可能會展現出關切的表情,微微皺眉,眼神柔和,頭部微微前傾,同時用溫和舒緩的語氣開始講述笑話。在講述過程中,為了增強表達效果,數字人還會配合一些簡單的手勢動作,如攤開雙手、輕輕聳肩等,使整個交互過程更加生動自然。
在這一過程中,動作捕捉技術實時采集真實人類的動作數據,并將其轉化為數字信號,為數字人的動作驅動提供數據支持。通過不斷優化 AI 算法和動作捕捉技術的協同配合,數字人能夠實現更加流暢、自然、個性化的交互體驗,逐漸縮小與真實人類交互的差距。
三、關鍵技術突破與行業應用

3.1 多模態融合技術
- 語音 - 表情同步:基于 TTS 與嘴型同步算法,誤差 < 50ms
語音 - 表情同步技術是多模態融合的關鍵環節,它基于先進的文本轉語音(TTS)技術與嘴型同步算法,實現了語音與面部表情的精準匹配。以字節跳動的火山語音 TTS 系統為例,該系統采用端到端的深度學習架構,能夠根據輸入文本生成自然流暢的語音,同時結合嘴型同步算法,依據語音的音素、韻律等信息,精確驅動數字人的嘴部動作,使其與語音發聲完美同步。在實際應用中,誤差可控制在 50ms 以內,幾乎達到了人眼無法察覺的程度,極大地提升了數字人的真實感和親和力。在智能客服場景中,數字人客服在與用戶交流時,能夠根據回答內容實時調整嘴型和面部表情,讓用戶感受到如同面對面交流般的自然體驗,增強了用戶對服務的滿意度和信任度。
- 手勢 - 語義映射:建立 300 + 常用手勢與特定語義的對應關系
手勢 - 語義映射技術通過建立豐富的手勢語義庫,實現了手勢與特定語義的有效關聯。研究團隊通過大量的實驗和數據分析,收集并整理了 300 多種常用手勢,涵蓋了日常生活、工作交流、文化表達等多個領域,并為每個手勢賦予了明確的語義定義。在智能會議系統中,當演講者做出 “暫停” 的手勢時,數字人助手能夠迅速識別并暫停當前演示內容;當做出 “放大” 的手勢時,數字人會自動放大相關圖片或文檔,實現了更加便捷、自然的人機交互。在虛擬現實教育場景中,學生可以通過手勢與虛擬環境中的數字人老師進行互動,如舉手提問、揮手打招呼、用手指繪制圖形等,數字人老師能夠準確理解學生的手勢含義,及時給予回應和指導,提高了學習的趣味性和參與度。
- 視線追蹤:通過眼動數據增強交互沉浸感
視線追蹤技術借助眼動追蹤設備,實時捕捉用戶的視線方向和注視點,為數字人交互帶來了更加沉浸式的體驗。以 Tobii 公司的眼動追蹤技術為例,該技術通過紅外攝像頭發射不可見的紅外光,照射到用戶眼睛后反射回來,被攝像頭捕捉并分析,從而精確計算出用戶的視線位置。在虛擬現實游戲中,數字人角色能夠根據玩家的視線方向做出相應反應,當玩家注視某個物品時,數字人會主動介紹該物品的相關信息;在虛擬購物場景中,用戶的視線聚焦在某件商品上時,數字人客服會及時彈出該商品的詳細介紹和推薦信息,仿佛能讀懂用戶的心思,讓交互更加自然、流暢,增強了用戶在虛擬環境中的沉浸感和代入感。
3.2 典型行業應用場景
- 杭州亞運會數字點火儀式:動作捕捉與 AI 的完美協作
在杭州亞運會數字點火儀式中,數字人技術大放異彩,為全球觀眾帶來了一場震撼的視覺盛宴。此次數字點火儀式采用了慣性動捕設備,實時采集真實火炬手的動作數據。這些設備佩戴在火炬手的關鍵關節部位,能夠精準記錄其奔跑、傳遞火炬等動作細節,并將數據實時傳輸至計算機系統。AI 算法在后臺對這些動作數據進行深度優化,通過復雜的計算和分析,實現了數字火炬手與真實火炬手的動作 0 秒誤差同步,讓數字火炬手的每一個動作都栩栩如生,仿佛真實的火炬手在虛擬世界中奔跑。
結合裸眼 3D 技術,數字火炬手的形象在 185 米的超大網幕上呈現出震撼的視覺效果。裸眼 3D 技術通過巧妙的視效設計和多屏幕協同,讓數字火炬手仿佛從屏幕中躍出,懸浮在空中,與現場的真實場景完美融合。觀眾無需佩戴任何設備,就能感受到強烈的立體感和沉浸感,仿佛親眼目睹數字火炬手穿越時空,點燃亞運圣火,為整個開幕式增添了濃厚的科技感和未來感。
- 農業直播帶貨:數字人助力鄉村振興
在農業領域,數字人技術為農產品直播帶貨開辟了新的路徑,為鄉村振興注入了新的活力。基于 3D 建模與表情捕捉技術,打造出了具有親和力的擬人化數字人主播形象。這些數字人主播擁有逼真的外貌和豐富的表情,能夠像真實主播一樣與觀眾進行互動。同時,AI 知識庫整合了大量的農業專業知識,包括農產品的種植過程、營養價值、食用方法等信息,使數字人主播具備了專業的農產品知識儲備,能夠為觀眾提供準確、詳細的解答,成為農產品的 “代言人”。

通過動作捕捉技術,驅動數字人主播在直播過程中實現自然流暢的交互。數字人主播能夠根據觀眾的提問和評論,做出相應的動作和表情,如點頭、微笑、揮手等,增強了直播的互動性和趣味性。在介紹水果時,數字人主播會做出品嘗的動作,并生動地描述水果的口感和味道;在展示農產品的種植環境時,數字人主播會做出指向和講解的動作,讓觀眾更加直觀地了解農產品的生長過程。這種創新的直播帶貨方式,不僅提高了農產品的銷售效率,還為農民帶來了實實在在的收益,推動了農業產業的數字化發展。
四、技術挑戰與未來展望
4.1 當前技術瓶頸
-
高精度動捕設備成本高:以 OptiTrack 和 Vicon 等知名品牌的光學動作捕捉系統為例,一套完整的高精度光學動作捕捉系統,包含多個高分辨率紅外攝像頭、專業的動作捕捉軟件以及相關的校準設備等,其單價往往超過 50 萬元。這對于許多小型企業、初創團隊以及個人開發者來說,是一筆難以承受的高昂費用,嚴重限制了高精度動作捕捉技術的普及和應用范圍。在影視特效制作領域,一些小型影視公司因無法承擔如此高昂的設備成本,只能選擇使用低精度的動作捕捉設備,導致最終呈現的特效畫面中,數字角色的動作不夠流暢自然,與大片的視覺效果存在較大差距。
-
復雜場景動作識別準確率待提升:在遮擋環境下,動作識別的準確率成為了一大難題。當動作主體部分被遮擋時,傳統的動作識別算法往往難以準確捕捉到被遮擋部分的關節運動信息,導致動作識別準確率急劇下降。在實際應用中,當人物在復雜的室內環境中活動,身體部分被家具、墻壁等物體遮擋時,動作識別系統的準確率可能會降低至 85% 以下,這在對動作識別精度要求較高的虛擬現實交互、智能安防監控等場景中,可能會導致交互異常、誤判等問題,影響用戶體驗和系統的可靠性。
-
跨模態生成一致性不足:文本與動作的匹配是跨模態生成的關鍵環節,但目前的技術在這方面仍存在較大提升空間。在將文本轉化為動作的過程中,由于語言表達的多樣性和動作語義理解的復雜性,很難保證生成的動作與文本描述的語義和情感完全一致。當文本描述為 “他興奮地跳起來,揮舞著雙手” 時,生成的動作可能在跳躍的幅度、雙手揮舞的速度和節奏等方面與文本所表達的興奮情感存在偏差,導致文本與動作匹配度不足 90%,使得數字人在跨模態交互中的表現不夠自然和準確,無法有效傳達信息和情感。
4.2 技術演進方向
-
輕量化動捕方案:基于手機攝像頭的無標記點捕捉技術,正逐漸成為動作捕捉領域的研究熱點。蘋果公司的 ARKit 和谷歌的 ARCore 平臺,利用手機內置的攝像頭和傳感器,結合先進的計算機視覺算法,實現了對人體動作的實時捕捉。用戶無需佩戴任何額外的設備,只需打開手機應用,即可通過攝像頭實時捕捉自己的動作,并將其應用于增強現實游戲、虛擬社交等場景中。這種輕量化的動捕方案,不僅降低了設備成本和使用門檻,還具有便捷性和靈活性的優勢,為動作捕捉技術的普及和應用帶來了新的機遇。在虛擬試衣應用中,用戶可以通過手機攝像頭捕捉自己的身體動作,實時查看服裝在不同動作下的穿著效果,為線上購物提供了更加真實、直觀的體驗。
-
神經渲染技術:神經渲染技術通過結合深度學習和傳統渲染技術,能夠實時生成照片級皮膚紋理與光影效果,為數字人帶來更加逼真的視覺呈現。英偉達的 Instant NeRF 技術,利用神經網絡快速生成場景的輻射場,實現了從任意視角快速渲染出高質量的圖像。在數字人制作中,神經渲染技術可以根據數字人的面部表情和身體動作,實時生成細膩的皮膚紋理變化和逼真的光影效果,使數字人的面部表情更加生動自然,身體質感更加真實,仿佛擁有了真實的肌膚和毛發。在虛擬偶像直播中,借助神經渲染技術,虛擬偶像的形象更加逼真,能夠展現出更加豐富的表情和動作細節,吸引了大量粉絲的關注和喜愛。
-
情感增強 AI:通過生理信號(心率、微表情)優化交互反饋,是情感增強 AI 的重要發展方向。Empatica 公司的 E4 腕帶設備,可以實時監測用戶的心率、皮膚電反應等生理信號,結合面部微表情識別技術,AI 能夠更準確地感知用戶的情感狀態。當檢測到用戶心率加快、面部表情緊張時,AI 可以判斷用戶可能處于焦慮狀態,從而調整交互策略,用更加溫和、舒緩的語言和動作給予用戶安慰和支持。在心理健康治療領域,數字人治療師可以通過監測患者的生理信號和微表情,實時了解患者的情緒變化,提供個性化的心理疏導和治療方案,幫助患者緩解心理壓力,改善心理健康狀況。
4.3 行業滲透趨勢
-
金融服務:在金融服務領域,數字人技術的應用正逐漸改變著傳統的服務模式。虛擬客服憑借其 7×24 小時不間斷服務的能力,成為了金融機構提升服務效率和用戶體驗的重要工具。以招商銀行為例,其推出的數字人客服 “小招”,能夠快速準確地回答用戶關于理財產品、貸款業務、賬戶管理等各類問題。通過自然語言處理技術,“小招” 能夠理解用戶的問題,并結合豐富的金融知識庫,提供專業的解答和建議。同時,借助語音識別和合成技術,“小招” 能夠與用戶進行流暢的語音交互,為用戶提供便捷的服務體驗。在高峰期,虛擬客服能夠同時處理大量用戶的咨詢,有效緩解了人工客服的壓力,提高了服務效率和響應速度,增強了用戶對金融機構的滿意度和信任度。
-
遠程醫療:在遠程醫療領域,數字醫生通過動作捕捉技術,能夠實現對患者康復訓練的遠程指導,為患者提供更加便捷、高效的醫療服務。上海交通大學醫學院附屬瑞金醫院的數字醫生項目,利用動作捕捉設備實時采集患者的康復訓練動作數據,并通過網絡傳輸至醫生的終端。醫生可以根據這些數據,實時監測患者的康復訓練情況,如動作的準確性、幅度、頻率等,并及時給予指導和建議。對于一些行動不便或居住偏遠的患者,數字醫生的遠程指導能夠幫助他們在家中完成康復訓練,減少了往返醫院的時間和成本,提高了康復訓練的依從性和效果。數字醫生還可以結合患者的病歷和康復進度,制定個性化的康復訓練計劃,為患者提供更加精準的醫療服務。
-
智能制造:在智能制造領域,虛擬培訓師正發揮著越來越重要的作用。通過動作捕捉技術,虛擬培訓師能夠生動形象地演示復雜設備的操作流程,為工人提供更加直觀、高效的培訓方式。在汽車制造企業中,虛擬培訓師可以模擬汽車生產線設備的操作過程,從設備的啟動、調試到生產過程中的各種操作步驟,都能夠以逼真的動畫形式呈現出來。工人可以通過觀看虛擬培訓師的演示,快速了解設備的操作方法和注意事項。虛擬培訓師還可以與工人進行實時交互,解答工人的疑問,糾正工人的錯誤操作,提高培訓的效果和質量。通過使用虛擬培訓師,企業可以減少對實際設備的依賴,降低培訓成本,同時提高培訓的效率和安全性,為智能制造的發展提供了有力的支持。
五、代碼案例

5.1 經典代碼案例與解說
案例1:基于Transformer的多輪對話系統
Python
import tensorflow as tf
from transformers import TFAutoModelForSeq2SeqLM, AutoTokenizermodel_name = "t5-small"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = TFAutoModelForSeq2SeqLM.from_pretrained(model_name)def generate_response(input_text):inputs = tokenizer.encode("translate English to French: " + input_text, return_tensors="tf")outputs = model.generate(inputs)return tokenizer.decode(outputs[0], skip_special_tokens=True)response = generate_response("What is the weather today?")
print(response) # 輸出:Il fait beau aujourd'hui.
解說:此代碼利用Transformer架構實現多輪對話,通過上下文理解用戶意圖并生成自然語言回復。
案例2:基于GAN的數字人表情生成
Python
import torch
from torch import nn
from torch.nn import functional as Fclass Generator(nn.Module):def __init__(self):super().__init__()self.fc1 = nn.Linear(100, 256)self.fc2 = nn.Linear(256, 512)self.fc3 = nn.Linear(512, 784) # 假設輸入為28x28圖像def forward(self, x):x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = torch.tanh(self.fc3(x))return xgenerator = Generator()
noise = torch.randn(1, 100)
fake_image = generator(noise)
解說:此代碼通過生成對抗網絡(GAN)生成數字人的表情圖像,適用于虛擬角色的表情動態生成。
案例3:基于動作捕捉的實時交互
Python
import cv2
import mediapipe as mpmp_pose = mp.solutions.pose
pose = mp_pose.Pose()cap = cv2.VideoCapture(0)
while cap.isOpened():success, image = cap.read()if not success:breakresults = pose.process(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))if results.pose_landmarks:# 提取關鍵點數據用于數字人動作驅動landmarks = results.pose_landmarks.landmark# 實時更新數字人動作cv2.imshow('MediaPipe Pose', image)if cv2.waitKey(5) & 0xFF == 27:break
cap.release()
解說:此代碼利用MediaPipe實現單目視覺動作捕捉,實時驅動數字人的動作,適用于虛擬角色的動態交互。

5.2數字人綠幕摳圖
import sys
import cv2
import numpy as np
import logging
import os
import json
import uuid
import asyncio
import aiohttp
from aiohttp import web
from pathlib import Path
from typing import Tuple, Optional, Dict, Any
from moviepy.editor import VideoFileClip, AudioFileClip, ImageClip, CompositeVideoClip# 配置日志系統
logging.basicConfig(level=logging.INFO,format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)# 全局狀態管理
routes = web.RouteTableDef()
task_status = {}class VideoProcessor:def __init__(self, config: dict):# 綠幕處理相關參數self.green_range = (np.array([60, 80, 45]), # 最低HSV閾值np.array([100, 255, 255]) # 最高HSV閾值)self.morph_kernel_size = (11, 11)self.morph_close_iters = 3self.morph_open_iters = 2self.edge_blur_size = 21# PPT合成相關參數self.ppt_size = (1920, 1080)# 初始化路徑配置self._validate_paths(config)def _validate_paths(self, config: dict):"""路徑驗證與初始化"""try:self.input_video = Path(config['input_video']).resolve()self.ppt_template = Path(config['ppt_template']).resolve()self.final_output = Path(config['final_output']).resolve()# 自動創建輸出目錄self.final_output.parent.mkdir(parents=True, exist_ok=True)# 文件存在性檢查for path, name in [(self.input_video, '輸入視頻'),(self.ppt_template, 'PPT模板')]:if not path.exists():raise FileNotFoundError(f"{name}不存在:{path}")except Exception as e:logger.error("路徑初始化失敗", exc_info=True)raisedef _dynamic_hsv_adjust(self, hsv_frame: np.ndarray) -> np.ndarray:"""動態亮度補償"""v_channel = hsv_frame[:,:,2].astype(np.float32)v_mean = np.mean(v_channel)contrast = 1.2 if v_mean < 100 else 0.8hsv_frame[:,:,2] = np.clip(v_channel * contrast, 0, 255).astype(np.uint8)return hsv_framedef _apply_morphology(self, mask: np.ndarray) -> np.ndarray:"""形態學處理"""kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, self.morph_kernel_size)mask = cv2.GaussianBlur(mask, (5,5), 0)mask = cv2.morphologyEx(mask, cv2.MORPH_CLOSE, kernel, iterations=self.morph_close_iters)mask = cv2.morphologyEx(mask, cv2.MORPH_OPEN, kernel, iterations=self.morph_open_iters)return cv2.morphologyEx(mask, cv2.MORPH_CLOSE, kernel, iterations=1)def _process_frame(self, frame: np.ndarray, background: np.ndarray) -> np.ndarray:"""單幀處理"""# HSV顏色空間處理hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)hsv = self._dynamic_hsv_adjust(hsv)# 綠幕遮罩處理mask = cv2.inRange(hsv, self.green_range[0], self.green_range[1])mask = self._apply_morphology(mask)# 邊緣羽化alpha = cv2.merge([mask]*3).astype(float)/255.0alpha = cv2.GaussianBlur(alpha, (25,25), 0)alpha = cv2.medianBlur(alpha.astype(np.float32), 5) # 新增中值濾波alpha = cv2.GaussianBlur(alpha, (15,15), 0)edge_strength = cv2.Laplacian(alpha, cv2.CV_32F, ksize=3)alpha = cv2.addWeighted(alpha, 1.0, edge_strength, -0.3, 0) # 減弱邊緣對比度alpha = np.clip(alpha, 0, 1) # 確保值域正確#alpha = cv2.filter2D(alpha, -1, np.array([[-1,-1,-1], [-1,9,-1], [-1,-1,-1]])) # 銳化邊緣# 類型轉換處理frame_float32 = frame.astype(np.float32)background_float32 = background.astype(np.float32)alpha = alpha.astype(np.float32) # 確保alpha也是float32# 修改后的合成邏輯foreground = cv2.multiply(frame_float32, (1 - alpha), dtype=cv2.CV_32F)background_part = cv2.multiply(background_float32, alpha, dtype=cv2.CV_32F)return cv2.add(foreground, background_part).astype(np.uint8)def _custom_sharpen(self, image):"""圖像銳化"""blurred = cv2.GaussianBlur(image, (0,0), 3)return cv2.addWeighted(image, 1.5, blurred, -0.5, 0)async def process_video_async(self, task_id: str):"""異步處理視頻"""try:# 更新任務狀態task_status[task_id]['status'] = 'processing'task_status[task_id]['progress'] = 0# 使用線程池執行IO密集型操作loop = asyncio.get_event_loop()result = await loop.run_in_executor(None, self.process_video)# 更新任務狀態if result:task_status[task_id]['status'] = 'completed'task_status[task_id]['progress'] = 100task_status[task_id]['output_file'] = str(self.final_output)else:task_status[task_id]['status'] = 'failed'return resultexcept Exception as e:logger.error(f"異步處理失敗: {str(e)}", exc_info=True)task_status[task_id]['status'] = 'error'task_status[task_id]['message'] = str(e)return Falsedef process_video(self):"""主處理流程"""try:# 加載視頻和背景cap = cv2.VideoCapture(str(self.input_video))if not cap.isOpened():raise RuntimeError("視頻打開失敗")# 加載PPT背景ppt_bg = cv2.imread(str(self.ppt_template))if ppt_bg is None:raise RuntimeError("PPT背景加載失敗")# 獲取視頻原始尺寸frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))# 調整背景尺寸與視頻一致ppt_bg = cv2.resize(ppt_bg, (frame_width, frame_height))# 更新PPT尺寸參數self.ppt_size = (frame_width, frame_height)fps = cap.get(cv2.CAP_PROP_FPS)total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))# 創建視頻寫入器fourcc = cv2.VideoWriter_fourcc(*'mp4v')temp_output = str(self.final_output).replace('.mp4', '_temp.mp4')out = cv2.VideoWriter(temp_output, fourcc, fps, self.ppt_size, isColor=True)# 進度顯示logger.info("開始處理視頻...")current_frame = 0# 獲取當前任務ID(如果在異步上下文中)current_task_id = Nonefor tid, status in task_status.items():if status.get('status') == 'processing' and status.get('input_video') == str(self.input_video):current_task_id = tidbreakwhile cap.isOpened():ret, frame = cap.read()if not ret:breakcurrent_frame += 1if current_frame % 30 == 0: # 每30幀更新一次進度progress = (current_frame / total_frames) * 100logger.info(f"處理進度: {progress:.2f}%")# 更新任務狀態if current_task_id and current_task_id in task_status:task_status[current_task_id]['progress'] = min(80, int(progress * 0.8))# 處理當前幀processed_frame = self._process_frame(frame, ppt_bg)processed_frame = self._custom_sharpen(processed_frame)out.write(processed_frame)# 釋放資源cap.release()out.release()# 更新進度if current_task_id and current_task_id in task_status:task_status[current_task_id]['progress'] = 85# 合并音頻logger.info("正在合并音頻...")self._merge_audio(temp_output)# 更新進度if current_task_id and current_task_id in task_status:task_status[current_task_id]['progress'] = 95# 清理臨時文件if Path(temp_output).exists():Path(temp_output).unlink()logger.info(f"視頻處理完成,輸出文件:{self.final_output}")return Trueexcept Exception as e:logger.error(f"視頻處理失敗: {str(e)}", exc_info=True)return Falseasync def _merge_audio_async(self, temp_video_path: str):"""音頻合并 (異步版本)"""try:# 使用線程池執行IO密集型操作loop = asyncio.get_event_loop()await loop.run_in_executor(None, self._merge_audio, temp_video_path)except Exception as e:logger.error("音頻合并失敗", exc_info=True)raisedef _merge_audio(self, temp_video_path: str):"""音頻合并"""try:video = VideoFileClip(temp_video_path)audio = AudioFileClip(str(self.input_video))# 音頻時長對齊if audio.duration > video.duration:audio = audio.subclip(0, video.duration)final = video.set_audio(audio)final.write_videofile(str(self.final_output),codec='libx264',audio_codec='aac',preset='medium',ffmpeg_params=['-pix_fmt', 'yuv420p','-crf', '12','-profile:v', 'high10','-tune', 'grain','-x264-params', 'aq-mode=1:deblock=0,0'],logger=None)# 清理資源video.close()audio.close()final.close()except Exception as e:logger.error("音頻合并失敗", exc_info=True)raise# API路由處理函數
@routes.post('/api/process_video')
async def process_video_handler(request):"""處理視頻處理請求"""try:data = await request.json()# 生成任務IDtask_id = str(uuid.uuid4())# 驗證必要參數required_fields = ['input_video', 'ppt_template', 'final_output']for field in required_fields:if field not in data:return web.json_response({"code": 400,"message": f"缺少必要參數: {field}"}, status=400)# 規范化路徑(確保跨平臺兼容)for field in required_fields:if field in data and isinstance(data[field], str):# 將所有路徑統一轉換為系統適用的格式data[field] = str(Path(data[field]))# 初始化任務狀態task_status[task_id] = {'status': 'queued','progress': 0,'input_video': data['input_video'],'ppt_template': data['ppt_template'],'final_output': data['final_output']}# 創建處理器并啟動異步處理processor = VideoProcessor(data)# 使用事件循環執行異步任務loop = asyncio.get_event_loop()loop.create_task(processor.process_video_async(task_id))return web.json_response({"code": 0,"data": {"task_id": task_id,"status_url": f"/api/status/{task_id}"}})except Exception as e:logger.error(f"處理請求失敗: {str(e)}", exc_info=True)return web.json_response({"code": 500,"message": f"處理請求失敗: {str(e)}"}, status=500)@routes.get('/api/status/{task_id}')
async def status_handler(request):"""獲取任務狀態"""task_id = request.match_info['task_id']status = task_status.get(task_id, {'status': 'not_found'})return web.json_response({"code": 0 if status['status'] != 'not_found' else 404,"data": status})# 服務啟動代碼
if __name__ == "__main__":app = web.Application()app.add_routes(routes)# 增強的關閉處理async def on_shutdown(app):print("釋放資源...")print("取消后臺任務...")for task in asyncio.all_tasks():if task is not asyncio.current_task():task.cancel()print("服務關閉完成")app.on_shutdown.append(on_shutdown)# 啟動服務web.run_app(app,host='0.0.0.0',port=8040,handle_signals=True)
說明:一段mp4綠幕背景視頻,我想替換為其他背景圖,第一步摳圖的時候發現結果邊緣還有綠色虛線

六、結語:邁向虛實共生的新紀元
6.1 總結
AI 與動作捕捉技術的深度融合,正在重構數字人的 “生命體征”。隨著 5G、AR/VR 技術的普及,數字人將從單一功能載體進化為具備自主意識的虛擬生命體,成為連接物理世界與數字空間的超級入口。未來的數字人不僅是技術的集合體,更是人類情感與智慧的數字化延伸。
我們正站在一個新的時代起點上,見證著數字人技術帶來的變革與創新。在這個虛實共生的新紀元中,數字人將與我們的生活、工作、娛樂深度融合,創造出無限可能的未來。
6.2 關鍵字解釋
-
數字人:基于AI和計算機圖形技術生成的虛擬角色。
-
動作捕捉:通過傳感器或攝像頭記錄真實動作并轉化為數字信號。
-
多模態交互:結合語音、表情、動作等多種方式的交互。
-
自然語言處理(NLP):使數字人理解并生成自然語言的技術。
-
情感計算:通過語音、語調等分析用戶情感并做出反饋。
-
生成對抗網絡(GAN):用于生成高質量圖像的深度學習模型。
-
Transformer:一種基于注意力機制的神經網絡架構。
-
光學捕捉:利用紅外攝像頭追蹤標記點實現高精度動作捕捉。
-
慣性捕捉:基于MEMS傳感器記錄關節運動的動作捕捉技術。
-
單目視覺:利用普通攝像頭實現低成本動作捕捉。
-
裸眼3D:無需佩戴設備即可實現立體視覺效果的技術。
-
虛擬主播:用于直播帶貨或娛樂的數字人角色。
-
虛擬醫生:通過動作捕捉和AI技術實現遠程醫療指導。
-
虛擬培訓師:用于工業培訓的數字人角色。
-
神經渲染:結合深度學習和傳統渲染技術生成逼真圖像。

6.3 相關素材
-
杭州亞運會數字點火儀式:結合慣性動捕和AI算法實現數字火炬手與真實火炬手動作同步。
-
農業直播帶貨:數字人主播通過3D建模和動作捕捉技術實現自然交互。
-
虛擬偶像直播:利用神經渲染技術生成逼真的皮膚紋理和光影效果。
1、數字人:從科幻走向現實的未來(1/10)
2、數字人技術的核心:AI與動作捕捉的雙引擎驅動(2/10)
后續文章正在快馬加鞭撰寫中,請關注《數字人》專欄即將更新…
文章3:《數字人:虛擬偶像的崛起與經濟價值》
文章4:《數字人:從娛樂到教育的跨界應用》
文章5:《數字人:醫療領域的革命性工具》
文章6:《數字人:品牌營銷的新寵》
文章7:《數字人:元宇宙中的核心角色》
文章8:《數字人:倫理與法律的挑戰》
文章9:《數字人:未來職業的重塑》
文章10:《數字人:人類身份與意識的終極思考》






之信號產生2)


對視頻數據進行自動化處理與檢索)





紅黑樹)



