本篇文章會介紹 JDK 與 Linux 網絡編程中的直接內存與零拷貝的相關知識,最后還會介紹一下 Linux 系統與 JDK 對網絡通信的實現。
1、直接內存
所有的網絡通信和應用程序中(任何語言),每個 TCP Socket 的內核中都有一個發送緩沖區(SO_SNDBUF)和一個接收緩沖區(SO_RECVBUF):
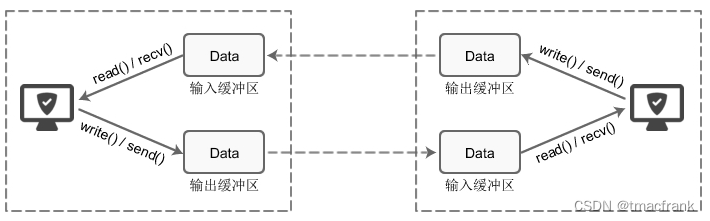
應用程序調用 write() 會使內核復制應用程序緩沖區中所有的數據到 Socket 的發送緩沖區,如果后者放不下并且該 Socket 是阻塞式的,應用程序會被投入睡眠。write() 直到應用程序緩沖區的所有數據都復制到 Socket 的發送緩沖區后才會返回,此時可以繼續向應用程序緩沖區寫入數據,但不表示對端的 TCP 或應用程序已經接收到數據:
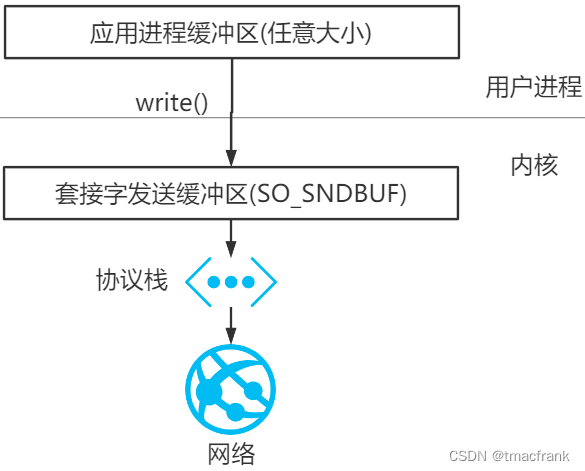
Java 也遵從這種規則。只不過因為堆、GC 等特性影響,會有一些特殊操作,即使用直接內存(或稱堆外內存),下面來闡述原因:
- 前面說過,要發送的數據會從應用程序的緩沖區被內核拷貝到 Socket 內核的發送緩沖區中。這中間必定有調用 Native 方法將 Java 對象地址通過 JNI 傳遞給底層 C 庫的過程
- 如果該 Java 對象存在堆中,受 GC 影響該對象可能會在堆中移動,就有可能出現該對象地址在傳遞給底層前后不同的情況,原地址失效底層就拿不到原本的對象。因此會要求調用 Native 方法之前一定要將數據存在堆外內存,JDK 對此的解決方案是將堆中的數據拷貝到堆外的 DirectBuffer 中
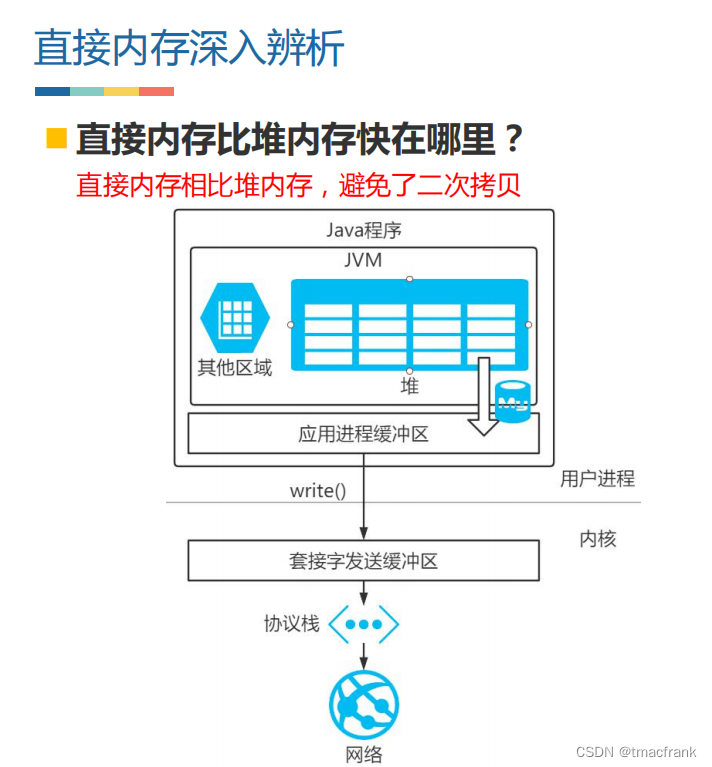
- 也可以直接使用 DirectBuffer 而不再通過堆,這樣可以省去把數據由堆拷貝到 DirectBuffer 的一次拷貝,使用直接內存當然就會快一點
- 直接內存不受新生代的 Minor GC 影響,只有執行老年代的 Full GC 時才會順便回收直接內存,整理內存的壓力也比將數據放到堆上小
使用堆外內存的好處是減少了 GC(會暫停其他工作)工作、加快了復制速度(相比于堆少了一次數據拷貝);缺點是如果堆外發生內存泄漏難以排查、不適合存很復雜的對象(適合簡單對象或扁平化對象)。
2、零拷貝
指計算機執行操作時,CPU不需要先將數據從某處內存復制到另一個特定區域。這種技術通常用于通過網絡傳輸文件時節省CPU周期和內存帶寬。
零拷貝并不是說不需要拷貝,只是說減少冗余的、不必要的(尤其是需要 CPU 干預的)拷貝:
- 零拷貝技術可以減少數據拷貝和共享總線操作的次數,消除傳輸數據在存儲器之間不必要的中間拷貝次數,從而有效地提高數據傳輸效率
- 零拷貝技術減少了用戶進程地址空間和內核地址空間之間因為上下文切換而帶來的開銷
2.1 Linux 的 IO 機制與 DMA
早期用戶進程需要讀取磁盤數據時都需要 CPU 中斷并參與,這樣 CPU 的效率低,因為每次 IO 請求都要中斷 CPU 帶來 CPU 的上下文切換,為了解決這個問題出現了 DMA(Direct Memory Access)。
DMA 不需要依賴 CPU 大量的中斷負載就可以與不同速度的硬件裝置進行溝通。DMA 控制器接管了數據讀寫請求,減少了 CPU 的負擔,使得 CPU 可以高效工作。現代硬盤基本都支持 DMA,實際的 IO 讀取涉及兩個過程(都是阻塞的):
- DMA 等待數據準備好,把磁盤數據讀取到操作系統內核緩沖區
- 用戶進程,將內核緩沖區的數據 copy 到用戶空間
DMA 是物理硬件,也算是一種芯片,磁盤、網卡、鍵盤等都有自己的 DMA。早期 CPU 會參與 IO 工作,讀取磁盤上的數據拷貝到內存當中,由于 IO 讀寫速度相比于 CPU 的處理速度是很慢的,所以這就相當于浪費了 CPU 的寶貴時間,于是產生了 DMA 設備,在有 IO 需求時,CPU 給 DMA發指令讓其讀取磁盤數據,DMA 讀取后會將數據拷貝到內存中,再通知 CPU 數據拷貝完成,然后 CPU 再用內存中的數據做接下來的操作。這就將 CPU 從低速的 IO 讀取工作中解放出來,專心做高速計算。
2.2 傳統數據傳送機制
以讀取文件再用 Socket 發送出去這個過程為例,偽代碼如下:
buffer = File.read()
Socket.send(buffer)
這個過程的示意圖如下:
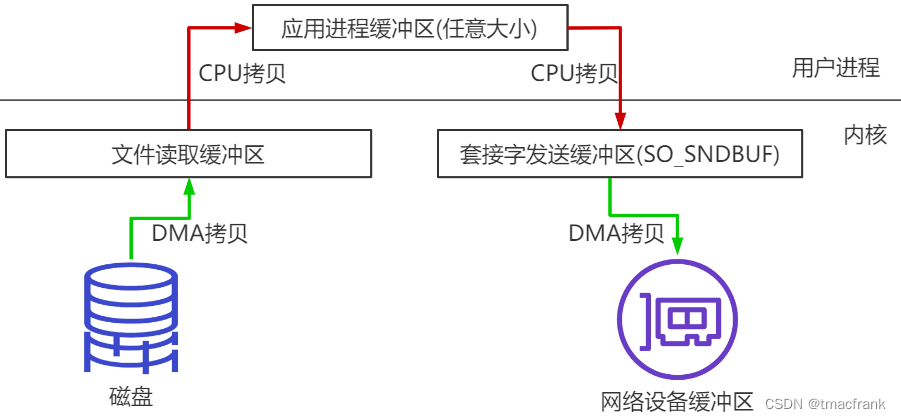
數據要經過四次拷貝:
- 將磁盤中的文件拷貝到操作系統內核緩沖區
- 將內核緩沖區數據拷貝到應用程序緩沖區
- 將應用程序緩沖區中的數據拷貝到位于操作系統內核緩沖區中的 Socket 網絡發送緩沖區
- 將 Socket 緩沖區中的數據拷貝到網卡,由網卡進行網絡傳輸
其中 2、3 兩次(即圖中紅線的兩次 CPU 拷貝)是“不必要的拷貝”,對于發送網絡數據而言屬于額外開銷,可以優化掉。
此外,read 和 send 都屬于系統調用,每次調用都牽涉兩次上下文切換,總共就是四次上下文切換:
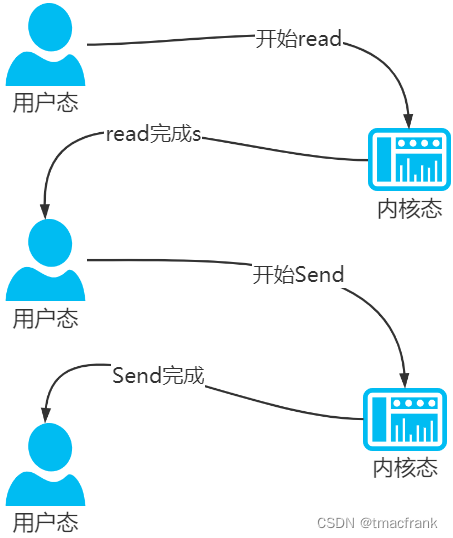
2.3 Linux 常見的零拷貝
零拷貝的目的就是減少不必要的拷貝,需要 OS 支持(需要 kernel 暴露 api)。
mmap 內存映射
將硬盤與應用程序緩沖區進行映射(建立一一對應關系),由于 mmap() 將文件直接映射到用戶空間,讀取文件時就可以根據該映射關系將文件從硬盤拷貝到用戶空間:
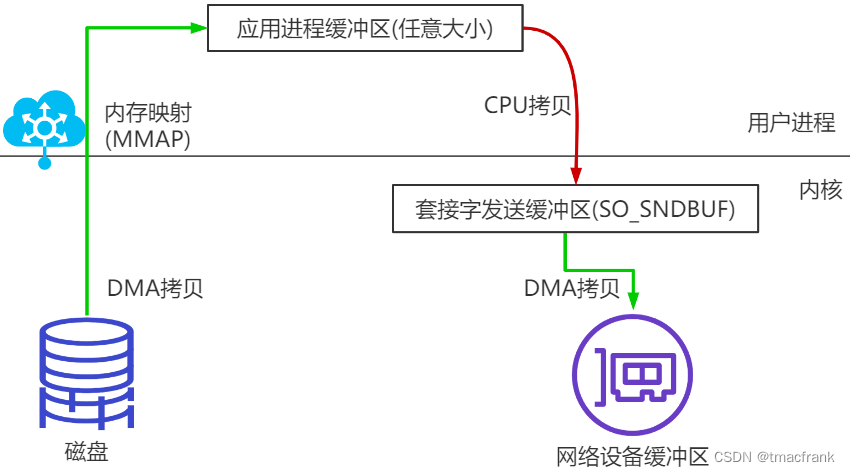
這樣仍有 3 次拷貝,4 次上下文切換。
sendfile
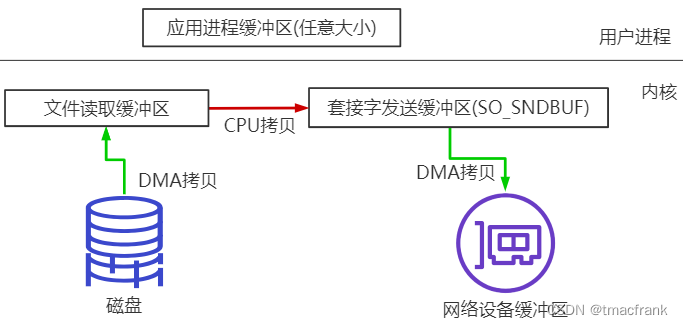
sendfile 需要 3 次拷貝,2 次上下文切換:
- 3 次拷貝如上圖所示,當然如果硬件支持的話,紅線的 CPU 拷貝是可以省略的。具體做法是文件讀取緩沖區將文件的起始位置和長度的描述符傳入 Socket 緩沖區,然后 DMA 會根據這個數據從文件讀取緩沖區中直接將文件讀取到網絡設備緩沖區,這樣就只需要 2 次拷貝了
- 用戶調用 sendfile 這一個系統調用,僅需兩次上下文切換
splice
Linux 在 2.6.17 開始支持的系統調用,使用管道直接將內核緩沖區的數據轉換為其他數據 buffer。在 Socket 網絡通信的情況下,就是文件讀取緩沖區與 SO_SNDBUF 建立 pipe 管道(實際上是管道兩側的緩沖區共用一塊物理內存)。這樣在無需硬件支持的情況下就省去了 CPU 拷貝:
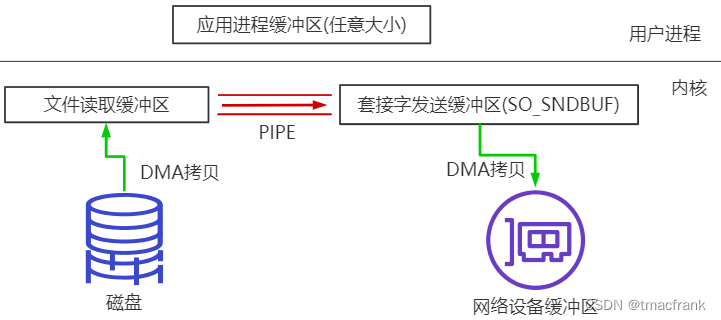
splice 也是需要 2 次拷貝,2 次上下文切換。
總結
零拷貝說法的來源最早出現于 sendfile 系統調用,這是真正操作系統意義上的零拷貝(也稱狹義零拷貝)。
但是由于由 OS 內核提供的操作系統意義上的零拷貝發展到現在種類并不是很多,因此隨著發展,零拷貝的概念延伸到了,減少不必要的數據拷貝都算作零拷貝的范疇。
3、Linux 和 JDK 對網絡通信的實現
3.1 Linux 網絡 IO 模型
同步與異步,阻塞與非阻塞
同步與異步關注的是調用方是否主動獲取結果:
- 同步:調用方主動等待結果返回
- 異步:調用方不用主動等待結果返回,而是通過狀態通知、回調函數等手段獲取結果
阻塞與非阻塞關注的是調用方在等待結果返回之前的狀態:
- 阻塞:結果返回前,當前線程被掛起不做任何事
- 非阻塞:結果返回前,線程可以做其他事情,不會被掛起
二者有四種組合:
- 同步阻塞:編程中最常見的模型,等待結果并且等待期間不做任何事,效率很低
- 同步非阻塞:可以抽象為輪詢模式,等待結果期間會做其他事情,但是會時不時地詢問是否已經返回結果
- 異步阻塞:用的很少,有點像在線程池中 submit 后馬上 Future.get(),此時線程其實還是掛起的
- 異步非阻塞:常用模型是回調函數
Linux 下的五種 IO 模型
五種 IO 模型,前四種是同步的,最后一種是異步的:
- 阻塞 IO:調用 IO 函數,會經過系統調用進入內核。應用程序會被阻塞,直到數據被準備好,從內核空間拷貝到用戶空間后,IO 函數返回,阻塞才被解除。BIO 中的 bind()、connect()、accept() 都是阻塞方法
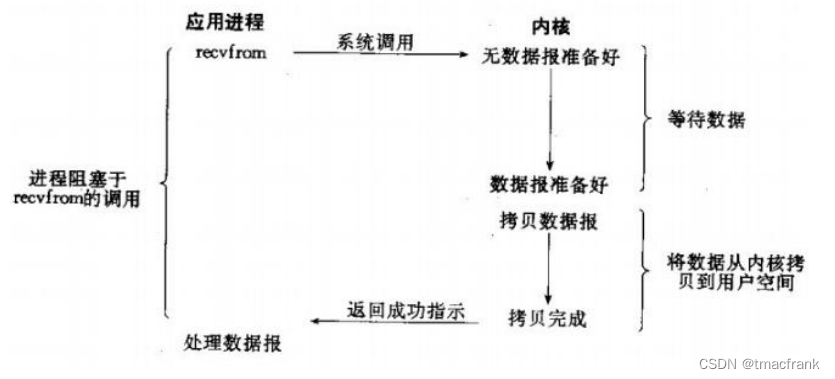
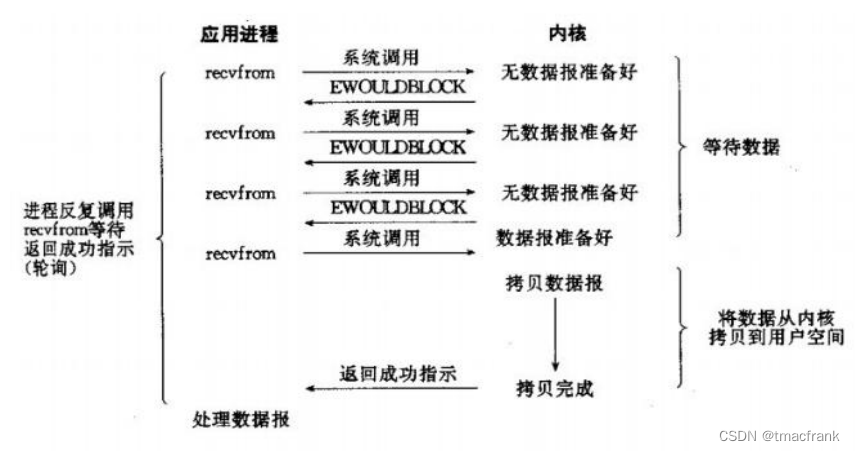
- 非阻塞 IO:IO 操作無法完成時,不將進程睡眠,而是返回一個錯誤。這樣應用就需要不斷測試數據是否已經準備好,如果沒有就繼續測試直到數據準備好為止。這種不斷測試會大量占用 CPU 時間,因此該模型絕對不被推薦
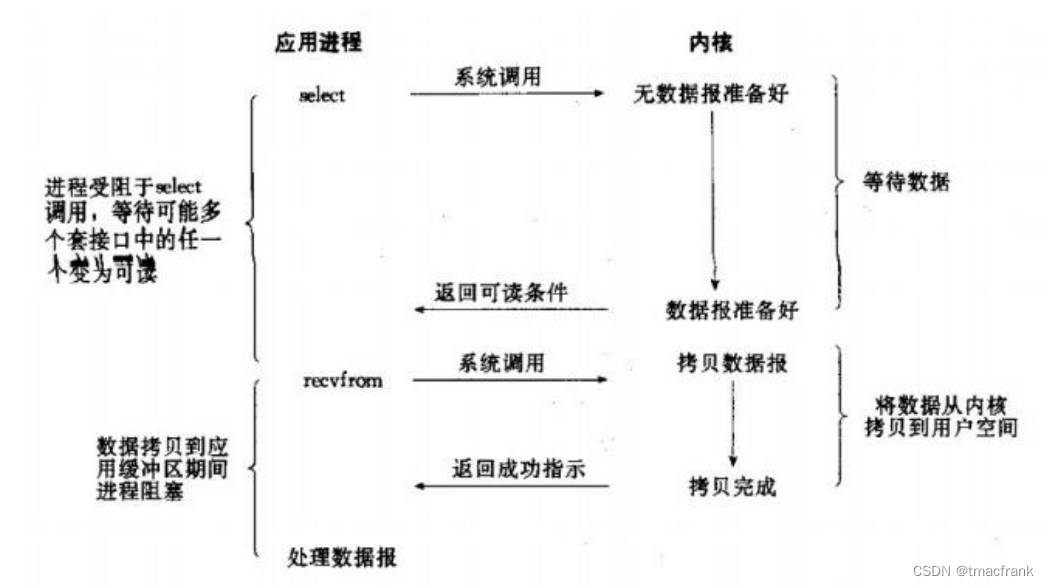
- IO 復用(select、poll、epoll):本質上也是阻塞的,只不過將阻塞拆開為 select(或 epoll)和 recvfrom 兩個系統調用,前者在有讀寫事件到來時返回,后者在數據從內核拷貝到用戶空間后返回。也就是對一個 IO 端口進行兩次系統調用,返回兩次結果,這比阻塞 IO 并沒有什么優勢,甚至相同條件下處理單個連接的效率還要比 BIO 低,但是勝在能同時對多個 IO 端口進行監聽
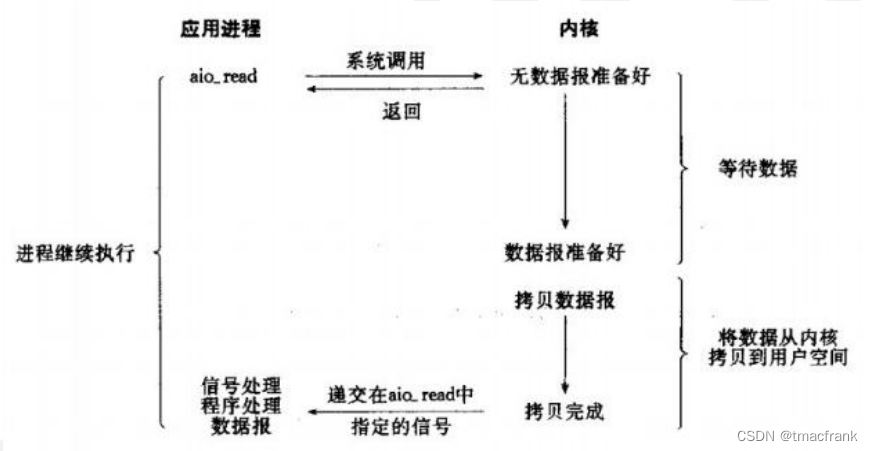
- 信號驅動 IO:應用進程向內核注冊一個信號處理函數然后繼續執行其他內容不會阻塞,當數據到來時,內核發出信號,通過信號處理程序告訴應用進程數據來了,這時應用程序才調用 recvfrom 進入阻塞式獲取數據的過程。整個過程有兩次調用和兩次返回

- 異步 IO:當一個異步過程調用發出后,調用者不能立刻得到結果。實際處理這個調用的部件在完成后,通過狀態、通知和回調來通知調用者的輸入輸出操作(Linux 下的 AIO 是假的異步,是用 IO 多路復用實現的)
3.2 JDK 對網絡通信的實現
JDK 實際上就是對 Linux 的 IO 通信模型進行了一個包裝,因此我們先了解 Linux 的通信實現。
Linux 下的阻塞網絡編程
Linux 下與 JDK 實現網絡通信的一個最大不同是,在服務端,Linux 用的是 socket 而 JDK 用的 ServerSocket,實際上就是 JDK 在 socket 基礎上做了一層封裝。此外,Linux 下需要通過 listen() 偵聽端口,這個大概也被 ServerSocket 封裝了。
從 Linux 代碼結構看網絡通信
分層:應用 API 層、協議層、接口層,應用發送數據是由上至下,接收數據是由下至上,并且接收時還涉及到由網絡設備產生的硬中斷。
中斷、上半部、下半部
內核和設備驅動是通過中斷的方式來處理的。所謂中斷,可以理解為當設備上有數據到達的時候,會給 CPU 的相關引腳上觸發一個電壓變化,以通知 CPU 來處理數據。
網卡把數據寫入內存后會向 CPU 發出一個中斷信號,由操作系統執行網卡中斷程序去處理數據。由于網絡操作復雜且耗時,如果在中斷函數中完成所有處理,會使得中斷處理函數(優先級過高)過度占據 CPU,使得 CPU 無法響應其他設備(如鼠標鍵盤),因此 Linux 將中斷處理函數分為上半部和下半部。
上半部只進行最簡單的工作,快速處理然后釋放 CPU,這樣 CPU 就可以讓其他中斷進來。下半部則慢慢從容的處理絕大部分工作。自 2.4 以后內核采用下半部是軟中斷,即給內存中的一個變量的二進制賦值以通知中斷處理程序;而硬中斷則是通過給 CPU 物理引腳施加電壓變化。
JDK 的 BIO 實現分析
Socket 和 ServerSocket 內部的 SocketImpl 才是真正實現網絡通信的組件(使用了門面模式),這與 Linux 下 CS 兩端都使用 socket 是吻合的。
Linux 下的 IO 復用編程
select,poll,epoll 都是 IO 多路復用的機制。所謂 IO 多路復用就是指一個進程可以監視多個描述符,一旦某個描述符就緒(一般是讀就緒或者寫就緒),能夠通知程序進行相應的讀寫操作。但 select,poll,epoll 本質上都是同步 I/O,他們都需要在讀寫事件就緒后自己負責進行讀寫,也就是說這個讀寫過程是阻塞的,而異步 I/O 則無需自己負責進行讀寫,異步 I/O 的實現會負責把數據從內核拷貝到用戶空間。
select 提供了一個函數:
// readfds 讀事件 fd 集合,writefds 寫事件 fd 集合,exceptfds 異常事件 fd 集合
int select (int n, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
所有的操作系統都支持 select 機制,Linux 下能監控的最大文件描述符數量為 1024,超過該數量性能會急劇下滑。
poll 也提供了一個函數,將 select() 參數中的三個描述符合為一個:
int poll (struct pollfd *fds, unsigned int nfds, int timeout);
fds 也是不能超過 1024 個,否則性能會急劇下降(因為是輪詢 Socket 通道獲取事件,數量多了自然性能就下降了)。
epoll 有三個函數,也就是三個系統調用:
// 創建 epoll 的文件描述符,類似于 JDK NIO 的 Selector.open()
int epoll_create(int size);
// 注冊、增加、刪除、修改關注的事件,類似于 JDK NIO 的 ServerChannel.register()
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
// 等待,看是否有事件發生,類似于 JDK NIO 的 Selector.select()
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
實際上 JDK 的 NIO 就是對 Linux epoll 的包裝。

:全文搜索、文本匹配)


)






的架構差異)


:gRPC 與 CRI gRPC實現)

)
【注:極簡描述】)

