1?全文搜索
????????全文搜索是一種在文本數據集中檢索包含特定術語或短語的文檔,然后根據相關性對結果進行排序的功能。該功能克服了語義搜索的局限性(語義搜索可能會忽略精確的術語),確保您獲得最準確且與上下文最相關的結果。此外,它還通過接受原始文本輸入來簡化向量搜索,自動將您的文本數據轉換為稀疏嵌入,而無需手動生成向量嵌入。
????????該功能使用 BM25 算法進行相關性評分,在檢索增強生成 (RAG) 場景中尤為重要,它能優先處理與特定搜索詞密切匹配的文檔。
1.1?概述
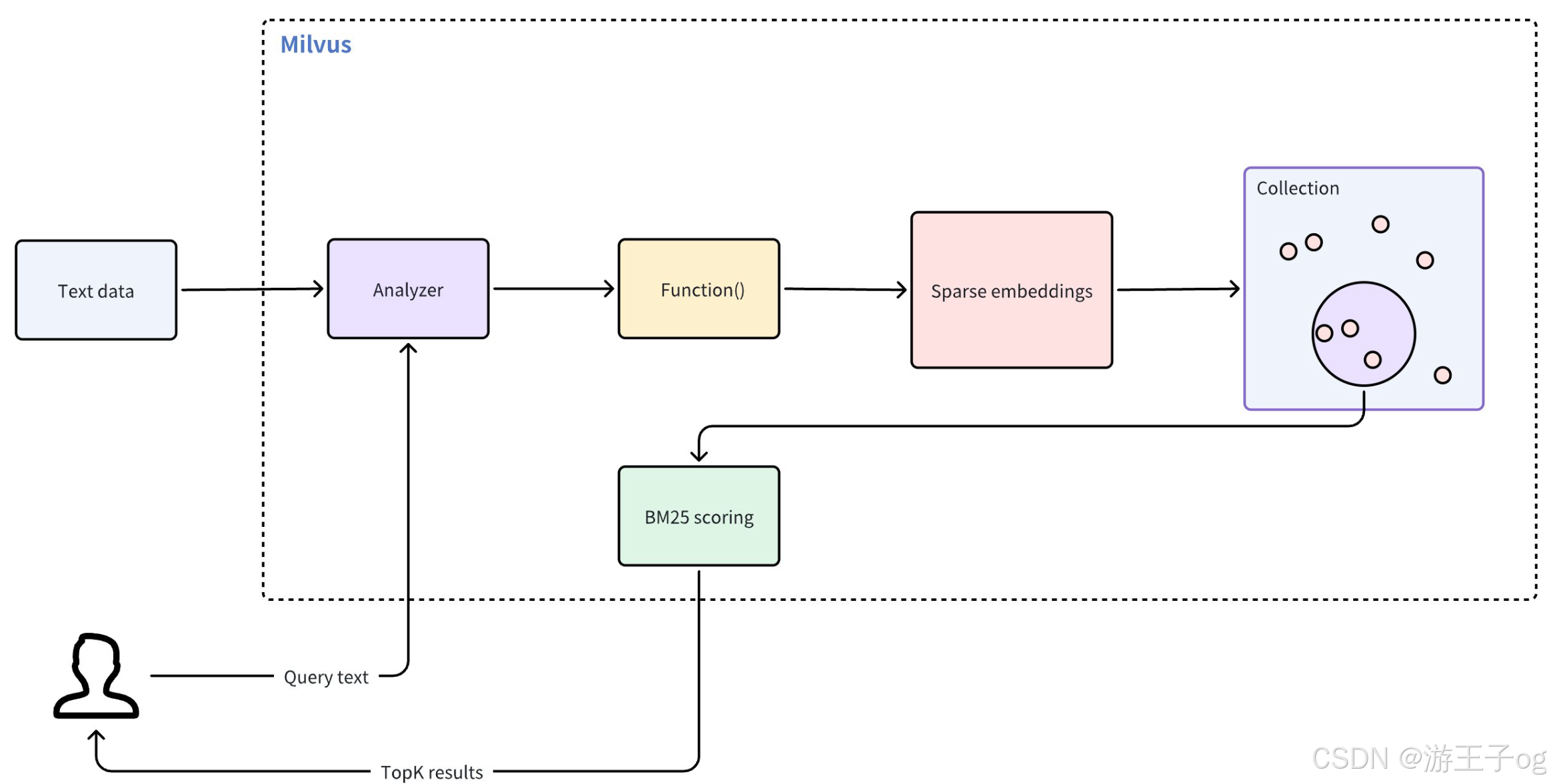
????????全文搜索無需手動嵌入,從而簡化了基于文本的搜索過程。該功能通過以下工作流程進行操作符:
- 文本輸入:插入原始文本文檔或提供查詢文本,無需手動嵌入。
- 文本分析:Milvus 使用分析器將輸入文本標記為可搜索的單個術語。
- 函數處理:內置函數接收標記化術語,并將其轉換為稀疏向量表示。
- Collections 存儲:Milvus 將這些稀疏嵌入存儲在 Collections 中,以便高效檢索。
- BM25 評分:在搜索過程中,Milvus 應用 BM25 算法為存儲的文檔計算分數,并根據與查詢文本的相關性對匹配結果進行排序。
1.2?創建用于全文搜索的 Collections
????????要啟用全文搜索,請創建一個具有特定 Schema 的 Collections。此 Schema 必須包括三個必要字段:
- 唯一標識 Collections 中每個實體的主字段。
- 一個
VARCHAR?字段,用于存儲原始文本文檔,其enable_analyzer?屬性設置為True?。這允許 Milvus 將文本標記為特定術語,以便進行函數處理。 - 一個
SPARSE_FLOAT_VECTOR?字段,預留用于存儲稀疏嵌入,Milvus 將為VARCHAR?字段自動生成稀疏嵌入。
1.2.1?定義 Collections 模式
????????首先,創建 Schema 并添加必要的字段:
from pymilvus import MilvusClient, DataType, Function, FunctionTypeclient = MilvusClient(uri="http://localhost:19530",token="root:Milvus"
)schema = MilvusClient.create_schema()schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True, auto_id=True)
schema.add_field(field_name="text", datatype=DataType.VARCHAR, max_length=1000, enable_analyzer=True)
schema.add_field(field_name="sparse", datatype=DataType.SPARSE_FLOAT_VECTOR)????????在此配置中
id: 作為主鍵,并通過auto_id=True?自動生成。text:存儲原始文本數據,用于全文搜索操作。數據類型必須是VARCHAR?,因為VARCHAR?是 Milvus 用于文本存儲的字符串數據類型。設置enable_analyzer=True?以允許 Milvus 對文本進行標記化。默認情況下,Milvus 使用standard分析器進行文本分析。sparse矢量字段:用于存儲內部生成的稀疏嵌入的矢量字段,以進行全文搜索操作。數據類型必須是SPARSE_FLOAT_VECTOR?。
????????現在,定義一個將文本轉換為稀疏向量表示的函數,然后將其添加到 Schema 中:
bm25_function = Function(name="text_bm25_emb", # 函數名input_field_names=["text"], # 包含原始文本數據的VARCHAR字段的名稱output_field_names=["sparse"], # SPARSE_FLOAT_VECTOR字段的名稱,用于存儲生成的嵌入function_type=FunctionType.BM25, # 設置為“BM25”
)schema.add_function(bm25_function)| 參數 | 說明 |
|---|---|
|
| 函數名稱。該函數將 |
|
| 需要將文本轉換為稀疏向量的 |
|
| 存儲內部生成的稀疏向量的字段名稱。對于 |
|
| 要使用的函數類型。將值設為 |
????????對于有多個VARCHAR?字段需要進行文本到稀疏向量轉換的 Collections,請在 Collections Schema 中添加單獨的函數,確保每個函數都有唯一的名稱和output_field_names?值。
1.2.2?配置索引
????????在定義了包含必要字段和內置函數的 Schema 后,請為 Collections 設置索引。為簡化這一過程,請使用AUTOINDEX?作為index_type?,該選項允許 Milvus 根據數據結構選擇和配置最合適的索引類型。
index_params = MilvusClient.prepare_index_params()index_params.add_index(field_name="sparse",index_type="SPARSE_INVERTED_INDEX",metric_type="BM25",params={"inverted_index_algo": "DAAT_MAXSCORE","bm25_k1": 1.2,"bm25_b": 0.75}
)| 參數 | 參數 |
|---|---|
|
| 要索引的向量字段的名稱。對于全文搜索,這應該是存儲生成的稀疏向量的字段。在本示例中,將值設為 |
|
| 要創建的索引類型。 |
|
| 該參數的值必須設置為 |
|
| 特定于索引的附加參數字典。 |
|
| 用于構建和查詢索引的算法。有效值:
|
|
| 控制詞頻飽和度。數值越高,術語頻率在文檔排名中的重要性就越大。取值范圍[1.2, 2.0]. |
|
| 控制文檔長度的標準化程度。通常使用 0 到 1 之間的值,默認值為 0.75 左右。值為 1 表示不進行長度歸一化,值為 0 表示完全歸一化。 |
1.2.3?創建 Collections
????????現在使用定義的 Schema 和索引參數創建 Collections。
client.create_collection(collection_name='my_collection', schema=schema, index_params=index_params
)1.3?插入文本數據
????????設置好集合和索引后,就可以插入文本數據了。在此過程中,您只需提供原始文本。我們之前定義的內置函數會為每個文本條目自動生成相應的稀疏向量。
client.insert('my_collection', [{'text': 'information retrieval is a field of study.'},{'text': 'information retrieval focuses on finding relevant information in large datasets.'},{'text': 'data mining and information retrieval overlap in research.'},
])1.4?執行全文搜索
????????將數據插入 Collections 后,就可以使用原始文本查詢執行全文檢索了。Milvus 會自動將您的查詢轉換成稀疏向量,并使用 BM25 算法對匹配的搜索結果進行排序,然后返回 topK (limit) 結果。
search_params = {'params': {'drop_ratio_search': 0.2},
}client.search(collection_name='my_collection', data=['whats the focus of information retrieval?'],anns_field='sparse',limit=3,search_params=search_params
)| 參數 | 說明 |
|---|---|
|
| 包含搜索參數的字典。 |
|
| 搜索過程中要忽略的低重要性詞的比例。 |
|
| 原始查詢文本。 |
|
| 包含內部生成的稀疏向量的字段名稱。 |
|
| 要返回的最大匹配次數。 |
2?文本匹配
????????Milvus 的文本匹配功能可根據特定術語精確檢索文檔。該功能主要用于滿足特定條件的過濾搜索,并可結合標量過濾功能來細化查詢結果,允許在符合標量標準的向量內進行相似性搜索。
2.1?概述
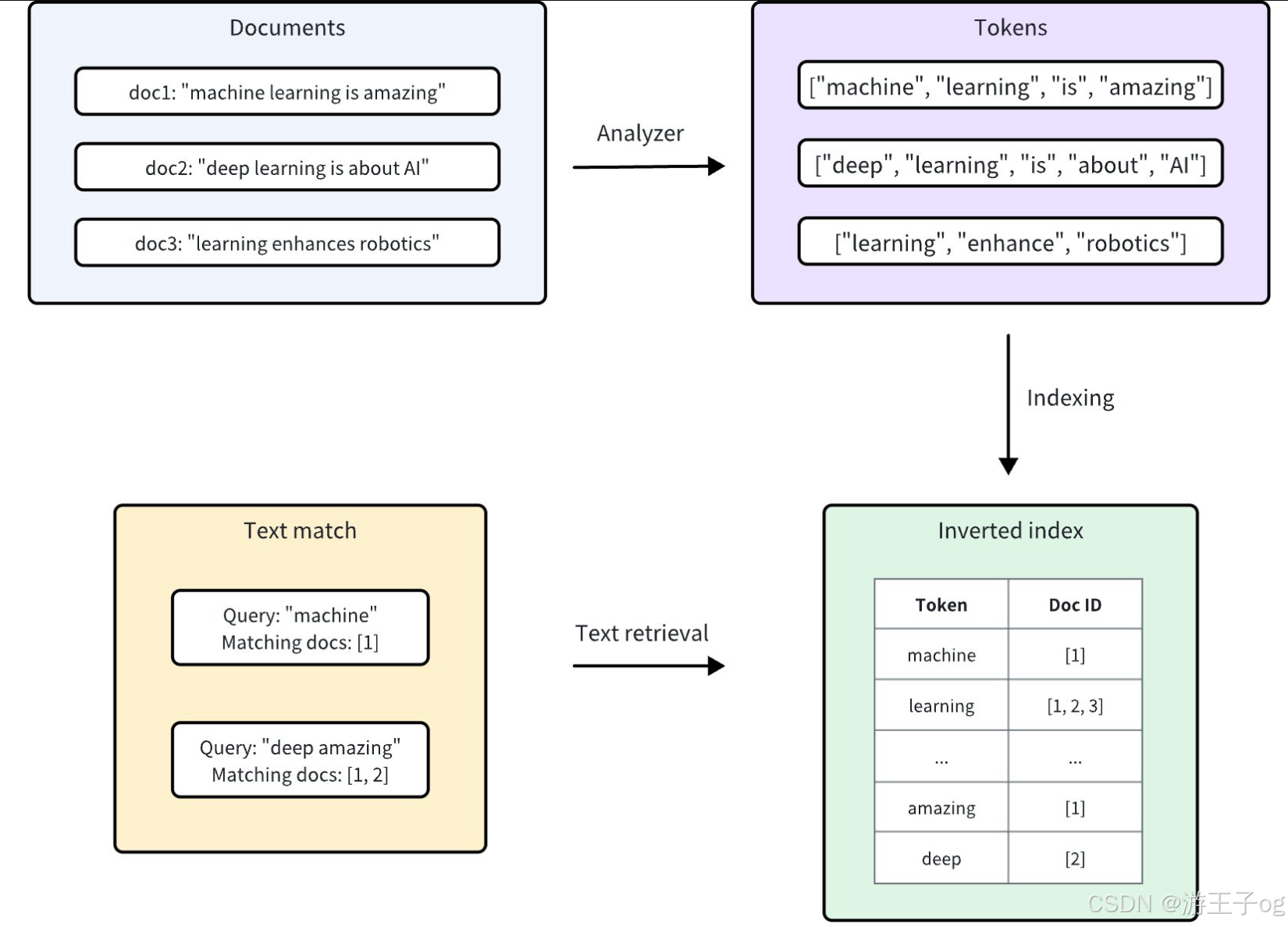
????????Milvus 整合了Tantivy來支持其底層的倒排索引和基于術語的文本搜索。對于每個文本條目,Milvus 都會按照以下程序建立索引:
- 分析器:分析器將輸入文本標記化為單個詞或標記,然后根據需要應用過濾器。這樣,Milvus 就能根據這些標記建立索引。
- 編制索引:文本分析完成后,Milvus 會創建一個倒排索引,將每個獨特的標記映射到包含該標記的文檔。
????????當用戶進行文本匹配時,倒排索引可用于快速檢索包含該術語的所有文檔。這比逐個掃描每個文檔要快得多。
2.2?啟用文本匹配
????????文本匹配適用于VARCHAR?字段類型,它本質上是 Milvus 中的字符串數據類型。要啟用文本匹配,請將enable_analyzer?和enable_match?都設置為True?,然后在定義 Collections Schema 時選擇性地配置分析器進行文本分析。
2.2.1?將enable_analyzer?和enable_match
????????要啟用特定VARCHAR?字段的文本匹配,請在定義字段 Schema 時將enable_analyzer?和enable_match?參數設置為True?。這將指示 Milvus 對文本進行標記化處理,并為指定字段創建反向索引,從而實現快速高效的文本匹配。
from pymilvus import MilvusClient, DataTypeschema = MilvusClient.create_schema(enable_dynamic_field=False)
schema.add_field(field_name="id",datatype=DataType.INT64,is_primary=True,auto_id=True
)
schema.add_field(field_name='text', datatype=DataType.VARCHAR, max_length=1000, enable_analyzer=True, # 是否為此字段啟用文本分析enable_match=True # 是否啟用文本匹配
)
schema.add_field(field_name="embeddings",datatype=DataType.FLOAT_VECTOR,dim=5
)2.2.2?可選:配置分析器
????????關鍵詞匹配的性能和準確性取決于所選的分析器。不同的分析器適用于不同的語言和文本結構,因此選擇正確的分析器會極大地影響特定用例的搜索結果。默認情況下,Milvus 使用standard?分析器,該分析器根據空白和標點符號對文本進行標記,刪除長度超過 40 個字符的標記,并將文本轉換為小寫。應用此默認設置無需額外參數。
????????如果需要不同的分析器,可以使用analyzer_params?參數進行配置。例如,應用english?分析器處理英文文本:
analyzer_params = {"type": "english"
}
schema.add_field(field_name='text',datatype=DataType.VARCHAR,max_length=200,enable_analyzer=True,analyzer_params = analyzer_params,enable_match = True,
)2.3?使用文本匹配
????????為 Collections Schema 中的 VARCHAR 字段啟用文本匹配后,就可以使用TEXT_MATCH?表達式執行文本匹配。
2.3.1?文本匹配表達式語法
? ?TEXT_MATCH?表達式用于指定要搜索的字段和術語。其語法如下:
TEXT_MATCH(field_name, text)field_name:要搜索的 VARCHAR 字段的名稱。text:要搜索的術語。根據語言和配置的分析器,多個術語可以用空格或其他適當的分隔符分隔。
????????默認情況下,TEXT_MATCH?使用OR匹配邏輯,即返回包含任何指定術語的文檔。例如,要搜索text?字段中包含machine?或deep?的文檔,請使用以下表達式:
filter = "TEXT_MATCH(text, 'machine deep')"????????還可以使用邏輯操作符組合多個TEXT_MATCH?表達式來執行AND匹配。要搜索text?字段中同時包含machine?和deep?的文檔,請使用以下表達式:
filter = "TEXT_MATCH(text, 'machine') and TEXT_MATCH(text, 'deep')"????????要搜索text?字段中同時包含machine?和learning?但不包含deep?的文檔,請使用以下表達式:
filter = "not TEXT_MATCH(text, 'deep') and TEXT_MATCH(text, 'machine') and TEXT_MATCH(text, 'learning')"2.3.2?使用文本匹配搜索
????????文本匹配可與向量相似性搜索結合使用,以縮小搜索范圍并提高搜索性能。通過在向量相似性搜索前使用文本匹配過濾 Collections,可以減少需要搜索的文檔數量,從而加快查詢速度。
????????在這個示例中,filter?表達式過濾了搜索結果,使其只包含與指定術語keyword1?或keyword2?匹配的文檔。然后在這個過濾后的文檔子集中執行向量相似性搜索。
# 匹配帶有‘ keyword1 ’或‘ keyword2 ’的實體
filter = "TEXT_MATCH(text, 'keyword1 keyword2')"# 假設‘embeddings’是向量字段,‘text’是VARCHAR字段
result = client.search(collection_name="my_collection", # 集合名稱anns_field="embeddings", # 向量字段名data=[query_vector], # 查詢向量filter=filter,search_params={"params": {"nprobe": 10}},limit=10, # Max。要返回的結果數output_fields=["id", "text"]
)2.3.3?文本匹配查詢
????????文本匹配也可用于查詢操作中的標量過濾。通過在query()?方法的expr?參數中指定TEXT_MATCH?表達式,可以檢索與給定術語匹配的文檔。下面的示例檢索了text?字段包含keyword1?和keyword2?這兩個術語的文檔。
# 匹配包含‘ keyword1 ’和‘ keyword2 ’的實體
filter = "TEXT_MATCH(text, 'keyword1') and TEXT_MATCH(text, 'keyword2')"result = client.query(collection_name="my_collection",filter=filter, output_fields=["id", "text"]
)2.4?注意事項
????????為字段啟用術語匹配會觸發反向索引的創建,從而消耗存儲資源。在決定是否啟用此功能時,請考慮對存儲的影響,因為它根據文本大小、唯一標記和所使用的分析器而有所不同。
????????在 Schema 中定義分析器后,其設置將永久適用于該 Collections。如果您認為不同的分析器更適合您的需要,您可以考慮刪除現有的 Collections,然后使用所需的分析器配置創建一個新的 Collections。
? ?filter?表達式中的轉義規則:
-
表達式中用雙引號或單引號括起來的字符被解釋為字符串常量。如果字符串常量包含轉義字符,則必須使用轉義序列來表示轉義字符。例如,用
\\?表示\?,用\\t?表示制表符\t?,用\\n?表示換行符。 -
如果字符串常量由單引號括起來,常量內的單引號應表示為
\\'?,而雙引號可表示為"?或\\"?。 示例:'It\\'s milvus'?。 -
如果字符串常量由雙引號括起來,常量中的雙引號應表示為
\\"?,而單引號可表示為'?或\\'?。 示例:"He said \\"Hi\\""?


)






的架構差異)


:gRPC 與 CRI gRPC實現)

)
【注:極簡描述】)



