阻塞隊列
通過數據結構的學習,我們都知道了隊列是一種“先進先出”的數據結構。阻塞隊列,是基于普通隊列,做出擴展的一種特殊隊列。
特點
1、線程安全的
2、具有阻塞功能:1、如果針對一個已經滿了的隊列進行入隊列,此時入隊列操作就會阻塞,一直阻塞到隊列不滿(其他線程出隊列元素)之后。2、如果針對一個已經空了的隊列進行出隊列,此時出隊列操作就會阻塞,一直阻塞到隊列不空(其他線程入隊列元素)之后。
基于阻塞隊列我們能夠實現“生產者消費者模型”。
生產者消費者模型
什么是生產者消費者模型呢?
舉個生活中的例子:
包餃子的流程:
1、和面(一般都是一個人(線程),沒辦法多個人(線程)完成)
2、搟餃子皮
3、包餃子(2和3都是可以多個人(線程)完成的)
現在有A、B、C三位老鐵,共同完成包餃子的任務,搟面杖,一般一個家庭中只有一個搟面杖,所以會發生,三個線程同時去競爭這個搟面杖,A老鐵拿到搟面杖搟皮了,B、C就需要阻塞等待,所以,包餃子的流程非常適合多線程的方式來實現,即A和完面,B負責搟皮,A(此時A已經釋放了搟面杖)、C負責包餃子。B搟一個皮,A或者C就能包一個餃子……
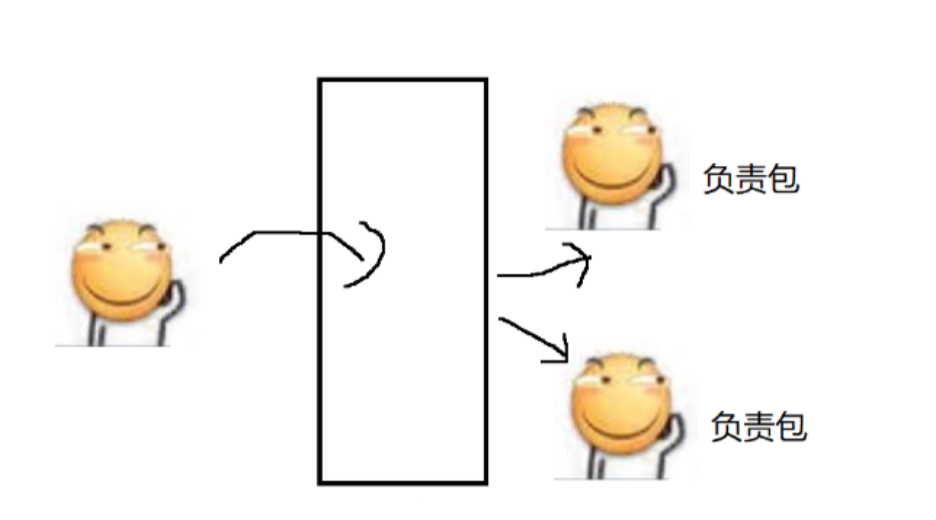
這里的分工協作,就構成了生產者消費者模型,搟餃子皮的線程就是生產者(生產餃子皮),搟完一個餃子皮 ,餃子皮數目+1,另外兩個包餃子的線程,就是消費者(消費餃子皮),包完一個餃子,餃子皮數量-1。
中間的桌子就起到了“傳遞餃子皮”的效果,這個桌子的角色就相當于“阻塞隊列”。
假設:搟餃子皮的線程速度非常快,而包餃子的人包的很慢。就會導致桌子上的餃子皮越來越多,一直這樣下去,桌子上的餃子皮就會滿了。此時搟餃子皮的人就得停下來等等,等這兩個包餃子皮的人,用掉一些餃子皮,再接著搟……
反之,搟餃子皮的非常慢,包餃子的人包得非常快,就會導致桌子上的餃子皮所剩無幾,一直這樣下去,桌子上就沒有餃子皮了。此時包餃子的人就得等一等,等搟餃子皮的人搟出餃子皮,再接著包……
上述例子,大概模擬了生產者消費者模型。
作用
1、解耦合
引入生產者消費者模型,就可以更好地做到“解耦合”。
耦合度:代碼中不同的模塊,類函數之間相互依賴,相互關聯的緊密程度。
耦合度低:模塊之間的關聯關系弱,相互影響小。一個模塊的修改不容易影響其他模塊,各個模塊之間可以相對獨立進行開發……
耦合度高:模塊之間的關聯關系強,一個模塊的修改往往會導致其他多個模塊也需要相應的修改,代碼的維護和擴展難度大……
在實際開發中,我們追求的是“高內聚,低耦合”,此時就可以使用阻塞隊列降低耦合度。
?實際開發中,經常會涉及到“分布式系統”:服務器整個功能不是由一個服務器全部完成的,而是每個服務器負責一部分功能,通過服務器之間的網絡通信,最終完成整個功能。
圖示: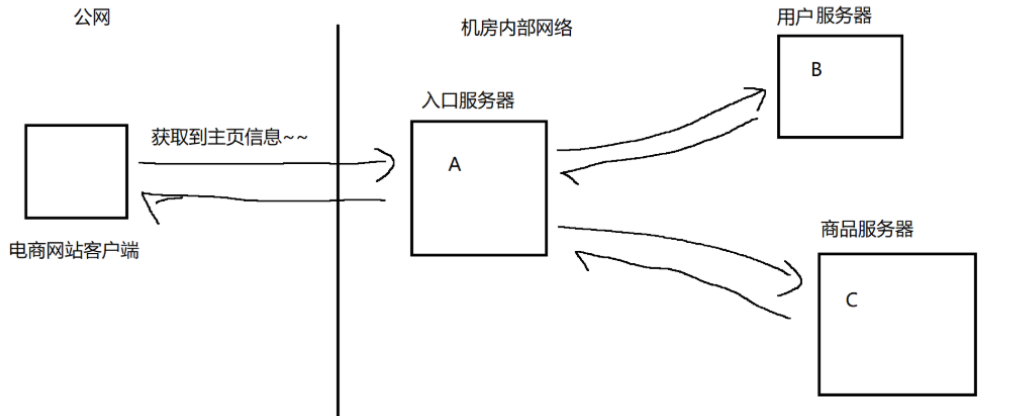
上述模型中:A和B、A和C之間的耦合度是比較強的,A代碼中需要涉及到一些和B相關的操作,B的代碼中也涉及到一些和A的操作。同樣,A的代碼中需要涉及和C的操作,C的代碼也涉及到和A的操作。此時,如果B或者A“掛了”,此時對A的影響就很大,A可能也就跟著“掛”了。
此時,就可以引入阻塞隊列來降低A、B、C三者間的耦合度從而降低上述事故發生的概率。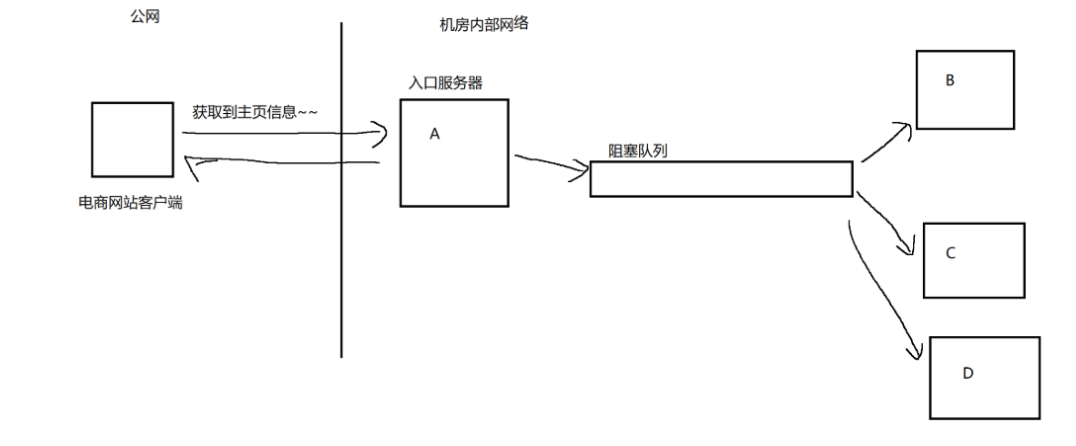
引入阻塞隊列后,A和B、A和C之間就都不是直接交互的了,而是通過隊列在中間進行傳話。此時,A只需要和隊列交互就可以了,同理,B、C中的代碼也是跟隊列交互就可以了。
如果B、C“掛了”,對于A的影響是微乎其微的……假設后續要增加一個D,A的代碼是不用發生任何變化的。
引入生產者消費者模型,降低耦合度之后,也是需要付出一些代價的:需要加機器,引入更多的硬件資源。
1、上述描述的阻塞隊列,并非是簡單的數據結構,而是基于這個數據結構實現的服務器程序,又被部署到單獨的主機上了。我們稱這種為“消息隊列”(message queue,簡稱“mq”)。?
2、整個系統的結構更復雜了,需要維護的服務器更多了。
3、效率問題:引入中間的“阻塞隊列”,請求從A發出到B收到,B返回響應到A都需要花費一定的時間。
2、削峰填谷
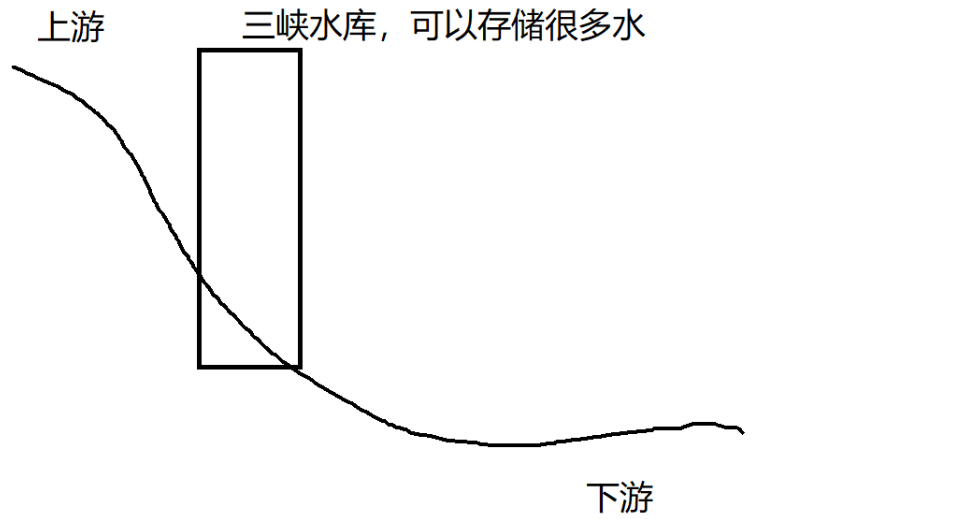
三峽水壩,是一項非常厲害的工程。
它的一項功能,就是能使上游的水按照一定的速率向下游排放。
如圖所示:
如果上游的降雨量突然增大,那上游的水就會以一個極快的速度沖向下游,對中下游,造成很大的危害。三峽工程,在中間建立了一個水庫。
?有了這個水庫之后,即使上游的水非常湍急,但是在中游也被三峽大壩給攔住了,三峽大壩本身就是一個水庫,可以存儲很多的水,然后,我們就可以進行調控,使得三峽按照一定的速率,往下游防水。上游降雨驟增,三峽大壩就可以關閘蓄水;上游降雨驟減,三峽大壩就可以開閘放水。從而達到削峰填谷的效果。(此處的峰和谷,都不是長時間持續的,而是短時間內出現的)。?

回到開發之中:?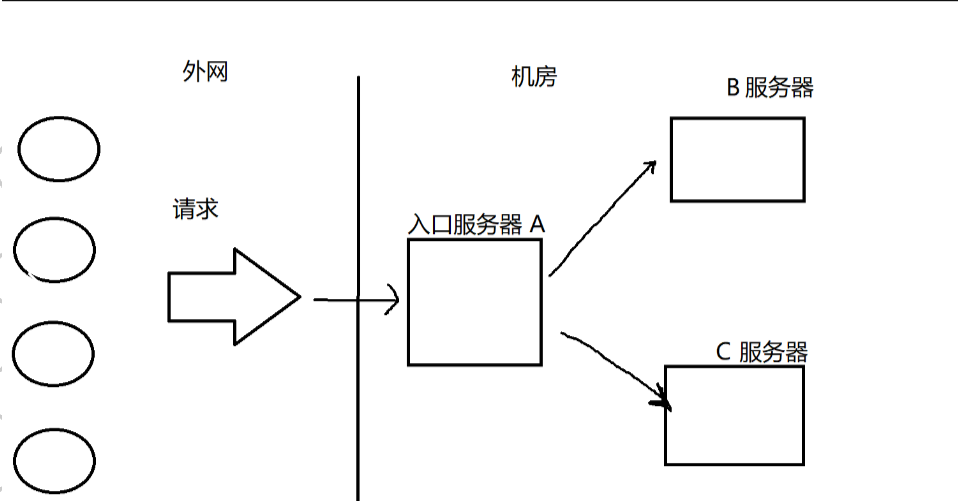
上面是一個分布式系統的大致模型,我們需要考慮的是,當外網的請求突然增多時,即A接收到的請求驟增,此時A的壓力就會變大,但因為A做的工作比較簡單,每個請求消耗的資源是比較少的,但是B和C多久不一定了,他們的壓力也會變大,假設B是用戶服務器,需要從數據庫中找到對應的用戶信息,C是商品服務器,也需要從數據庫中找到對應的商品,還需要進行一些匹配和過濾工作等等
A的抗壓能力比較強,B、C的抗壓能力比較弱(他們需要完成的工作更加復雜,每個請求消耗的資源更多),因此一旦外界的請求出現突發的峰值,就可能導致B、C服務器直接掛掉了……
那當請求多的時候,服務器為什么會掛掉呢?
服務器處理每個請求,都是需要消耗硬件資源的(包括但不限于CPU、內存、網絡帶寬……)即使一個請求消耗的資源比較少,但也無法承受住,同時會有很多的請求,加到一起來,這樣消耗的總資源就多了。上述任何一種硬件資源達到瓶頸,服務器都會掛(用戶發出請求,服務器無響應)
我們就可以使用阻塞隊列/消息隊列來盡量避免突發的高請求導致的服務器過載~~(阻塞隊列:是以數據結構的視角命名。消息隊列:是基于阻塞隊列實現服務器程序的視角命名的)……?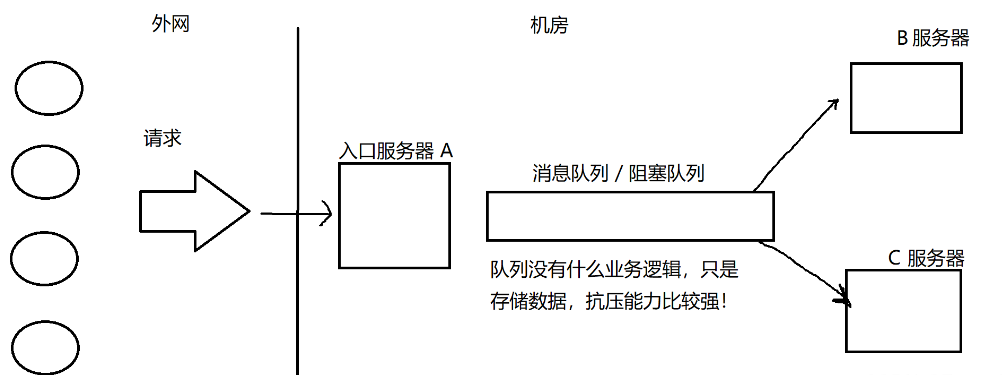
當在A與B、C之間添加一個阻塞隊列之后,因為阻塞隊列的特性,即使外界請求出現峰值,也是由阻塞隊列來承擔峰值的請求,B和C(下游)仍然可以按照之前的速度來獲取請求,這樣就可以有效防止B和C被峰值沖擊導致服務器“掛掉”。
但是當請求太多的時候,接收請求的服務器(即A服務器)也是可能會掛的。請求一直往上增加,A肯定也會有頂不住的時候,此時可以在A的前面再添加一個阻塞隊列,但當請求進一步增加,隊列也是可能掛的(我們可以引入更多的硬件資源,以避免上述情況)。
BolockingQueue的使用
Java標準庫中提供了線程的阻塞隊列的數據結構:
BolockingQueue是一個interface(接口)?,下面有三個具體的實現類: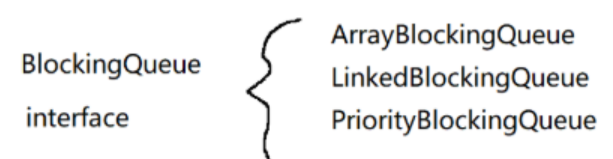
代碼示例:
public class ThreadDemo28 {public static void main(String[] args) throws InterruptedException {BlockingQueue<String> queue = new ArrayBlockingQueue<>(100);//帶阻塞功能的queue.put("aaa");String elem = queue.take();System.out.println("elem:"+elem);String elem1 = queue.take();//阻塞System.out.println("elem:"+elem);//沒有阻塞的獲取隊首元素的方法}
}
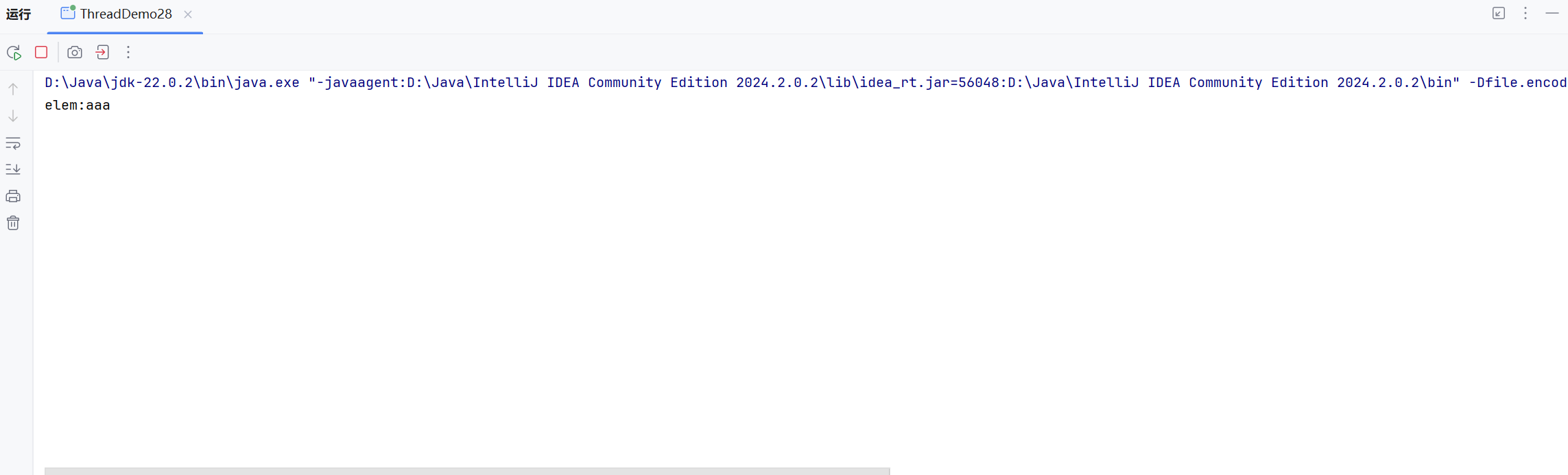 ?可以看到此時,打印“aaa”之后,進程并沒有結束,說明在取出第2個元素時發生了阻塞。
?可以看到此時,打印“aaa”之后,進程并沒有結束,說明在取出第2個元素時發生了阻塞。
注意:使用put和offer一樣都是入隊列,但是put是帶有阻塞功能的,offer是沒有阻塞功能的(隊列滿了則返回false),take方法是用來出隊列的,也是帶有阻塞功能的。但是在阻塞隊列中,并沒有提供帶有阻塞功能的獲取隊首元素的方法。
實現一個BlockingQueue
我們可以基于數組來實現隊列的數據結構(環形隊列)。
環形隊列有兩個引用:head(指向頭)和tail(指向尾)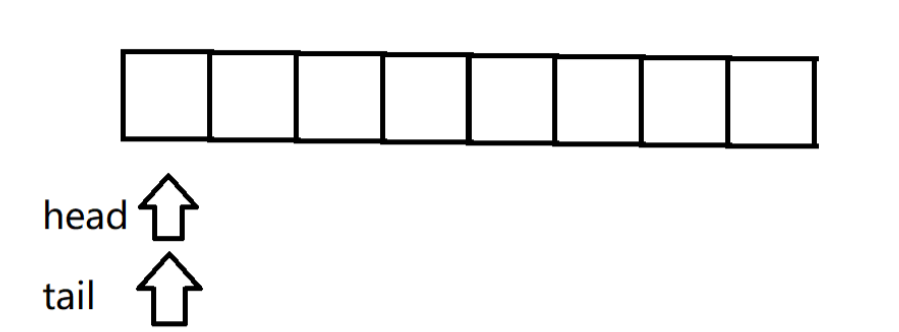
?每次插入數據的時候,將數據插入tail的位置,然后tail往后走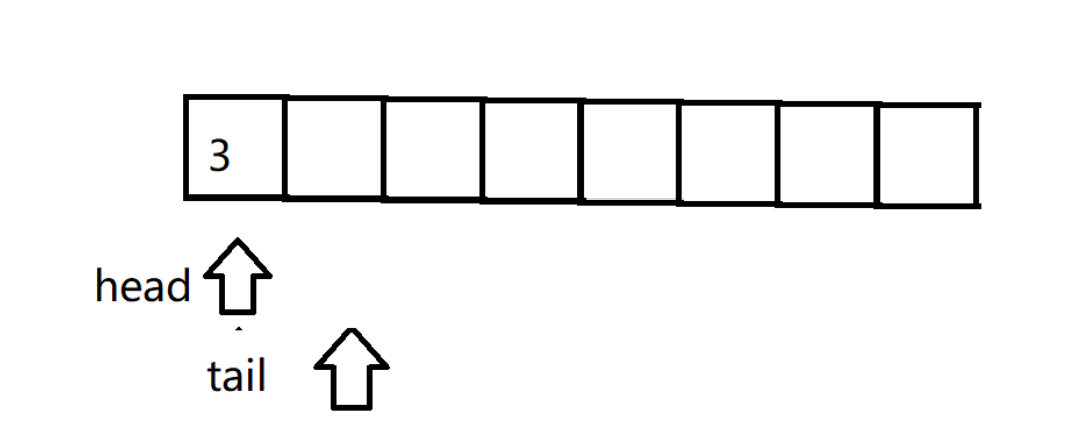
一直走到數組滿了之后?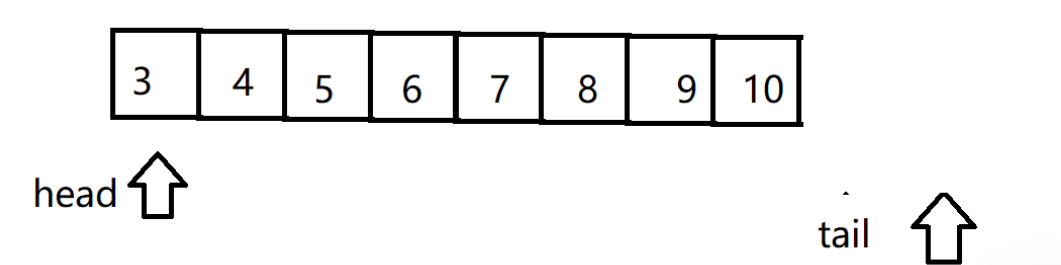
?因為我們要實現的是環形隊列,所以要判斷隊列是否為滿,有兩種方法:
1、浪費一個格子,tail至多走到head的前一個位置。
2、引入size變量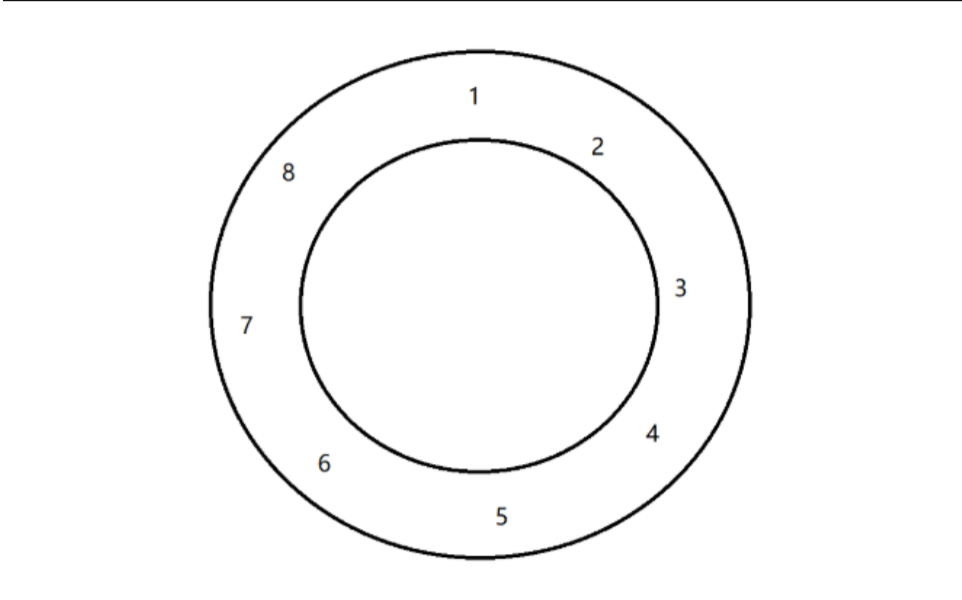
代碼實現:
1、成員變量和構造方法?
class MyBlockingQueue2{private String[] elem = null;private int head = 0;private int tail = 0;private int size = 0;public MyBlockingQueue2(int capcity){elem = new String[capcity];}
}2、 put方法和take方法
put方法的初始代碼(使用size來判斷隊列是否為滿):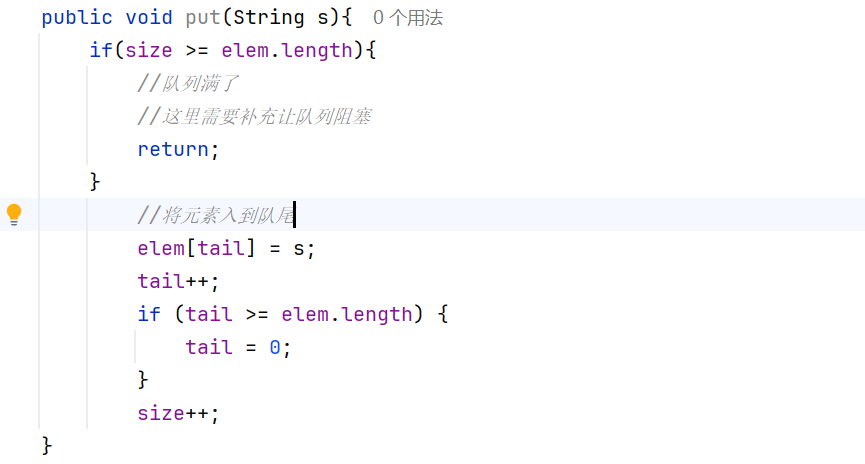
在put方法中判斷是否未滿,是有兩種寫法的,一種就是像我們上面寫的那樣if(tail >= elems.length)讓tail = 0,另一種是tail = tail % elems.length(如果tail < elems.length,此時求余的值,就是tail原來的值,如果tail==elems.length,求余的值就是0).
上述兩種方法都能完成我們的任務,那如何評價某個代碼好還是不好呢?
1、開發效率(代碼是否容易被理解,可讀性高不高)
2、運行效率(代碼的執行速度快不快)
分析上面兩種代碼,從可讀性上看,if語句,只要是個程序員,絕大多數都認識if條件,但不認識%,還是有可能的,尤其是在不同的編程語言中,%的作用還可能不太一樣。從運行效率上看,if是條件跳轉語句(執行速度快),大多數情況下,并不會觸發賦值。但是%,本質上是觸發運算指令,除法運算本身屬于比較低效的指令(CPU更擅長計算+、-),而且第二種代碼是百分之百觸發賦值操作的,運行效率會低一些。
綜上,使用if是更好的方法。
解決線程安全問題——引入鎖?
前面if語句中需要阻塞的代碼先不考慮,后面的代碼全都是針對數組進行寫操作,是線程不安全的,一定要加上鎖。

那么向上面這樣加鎖,就線程安全了嗎??
模擬調度過程,如圖所示:
如果這個此時這個數組只剩下最后一個位置了: ?所以我們synchronized需要加在最外面的括號中的,這樣就和加到方法上的本質是一樣的:
?所以我們synchronized需要加在最外面的括號中的,這樣就和加到方法上的本質是一樣的: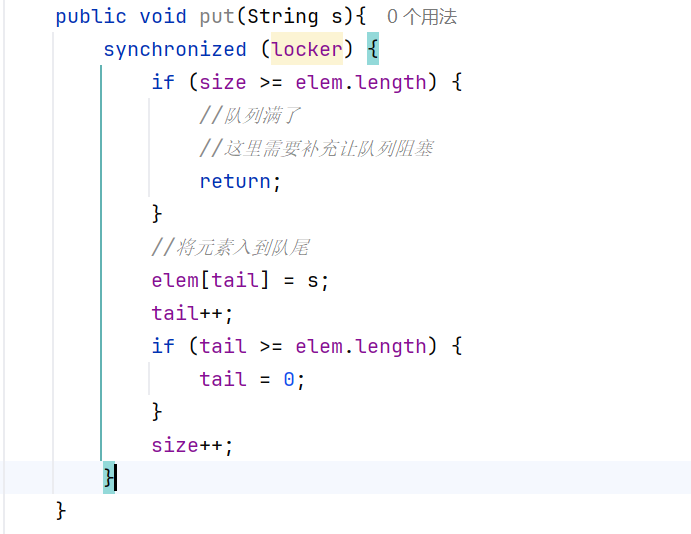
使得當前代碼能夠阻塞:
說到阻塞,我們就想到了可以用之前的wait來實現阻塞。 巧了,此處的wait正好在鎖內部,可以使用當前的鎖對象來wait。
光有wait還不夠,還需要其他線程對wait進行喚醒(隊列如果沒有滿,就可以進行喚醒操作了)。那什么時候隊列不滿了呢?出隊成功不就是隊列不滿了嘛~~
此時,我們就可以根據剛才的put方法來實現take方法,并在出隊成功后對put方法中的wait進行喚醒;同理在入隊成功后在put方法中對take方法中的wait進行喚醒。
take方法:
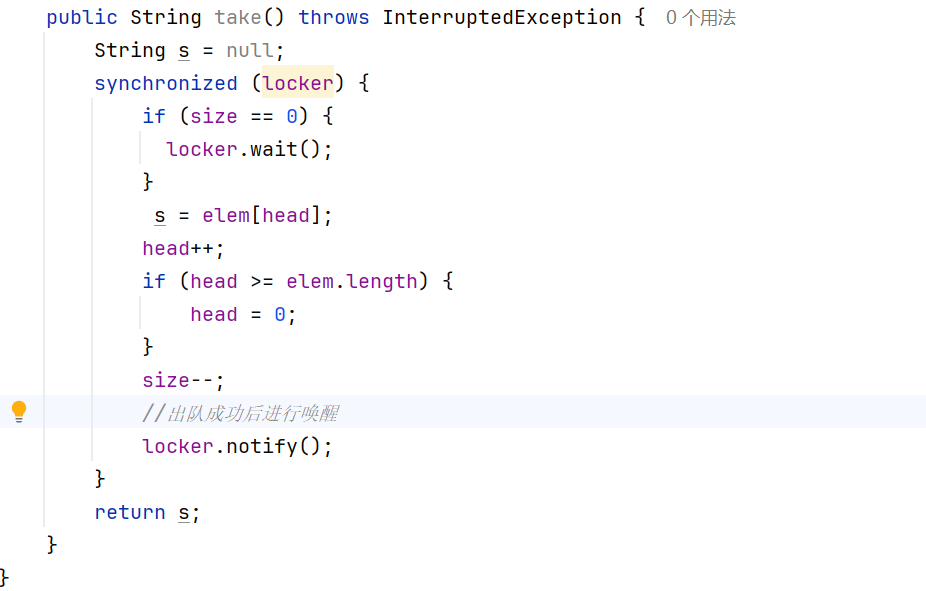
put方法 :
這樣看起來,我們的代碼是不是就大功告成了呢??
并沒有,我們期望的情況是這樣的: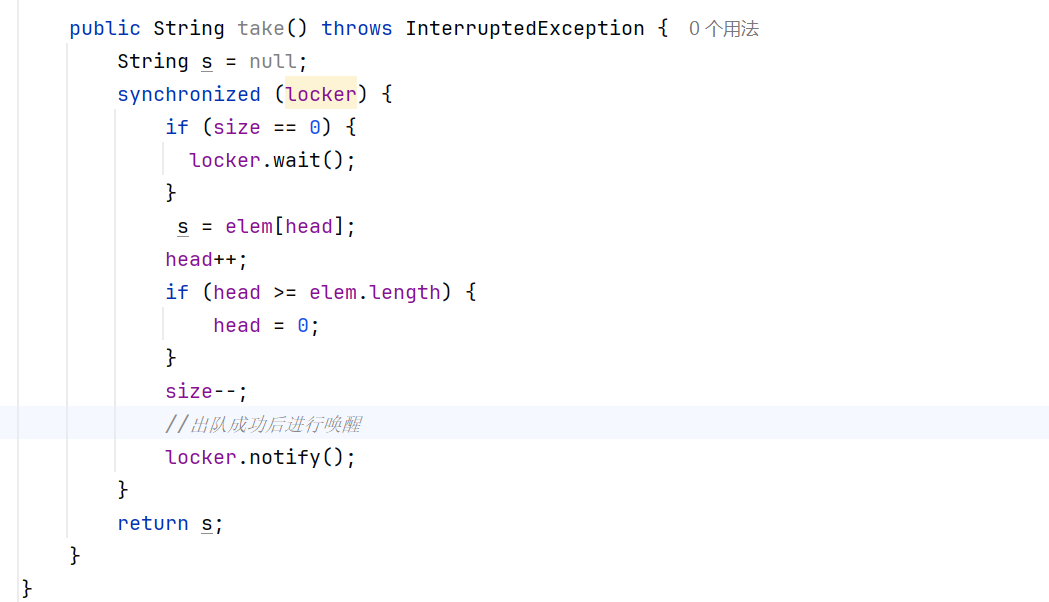
但是,不同線程之間,put和take方法的notify可能會不正確地將錯誤的wait給喚醒。
比如下面這種情況:A線程中,入隊列的喚醒操作,把B線程中入隊列的wait喚醒了。
第一步,兩個put都進入了if語句,且進入了阻塞等待(進入wait后會有一步操作是釋放鎖,所以可能出現兩個線程都能進行put這個操作)。
第二步,另一個線程執行了take方法,喚醒了其中一個put,然后這個put繼續往下添加元素,添加完后又執行了一步notify,將另一個put方法喚醒了(這個put方法本應該繼續阻塞等待的)。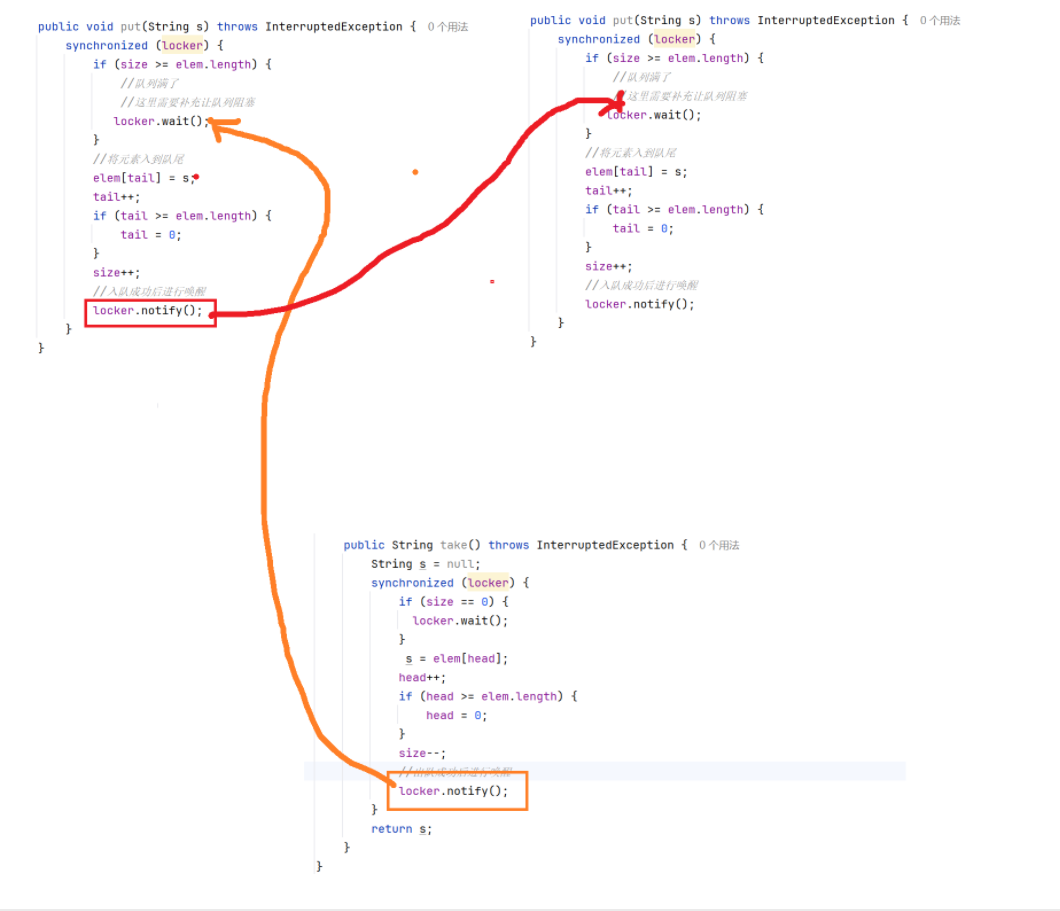
如上面這種情況,就是不符合我們預期的bug,并且好像還很難處理,如果我們使用兩個不同的鎖對象來解決,又無法實現鎖競爭。那我們要如何解決呢?我們可以將if改為while,這意味著wait喚醒之后,需要再判定一次條件。如果再次判斷條件,發現隊列還是滿的,那也就是說在wait等待的過程中,已經有其他線程進行了插入,此時就要繼續阻塞等待。
Java標準庫中也建議,wait要搭配while循環進行使用。
完整代碼:
class MyBlockingQueue2{private String[] elem = null;private int head = 0;private int tail = 0;private int size = 0;private Object locker = new Object();public MyBlockingQueue2(int capcity){elem = new String[capcity];}public void put(String s) throws InterruptedException {synchronized (locker) {while (size >= elem.length) {//隊列滿了//這里需要補充讓隊列阻塞locker.wait();}//將元素入到隊尾elem[tail] = s;tail++;if (tail >= elem.length) {tail = 0;}size++;//入隊成功后進行喚醒locker.notify();}}public String take() throws InterruptedException {String s = null;synchronized (locker) {while (size == 0) {locker.wait();}s = elem[head];head++;if (head >= elem.length) {head = 0;}size--;//出隊成功后進行喚醒locker.notify();}return s;}
}使用剛才實現的BlockQueue,寫一個簡單的生產者消費者模型
在實際的開發中,生產者消費者模型,往往是多個生產者和多個消費者。這里的生產者和消費者往往不僅僅是一個線程,也可能是一個獨立的服務器程序,甚至是一組服務器程序...但最核心的仍然是阻塞隊列,使用 synchronized 和 wiat / notify 達到線程安全和阻塞的目的。
如下代碼,t1是生產者,t2是消費者,我們可以通過sleep來控制他們的生產速度和消費速度。
public static void main(String[] args) {MyBlockingQueue2 queue2 = new MyBlockingQueue2(1000);Thread t1 = new Thread(()->{int count = 0;while (true){try {System.out.println("生產元素:"+count);queue2.put(String.valueOf(count));Thread.sleep(1000);count++;} catch (InterruptedException e) {throw new RuntimeException(e);}}});Thread t2 = new Thread(()->{while (true){try {String s = queue2.take();System.out.println("消費元素:"+s);} catch (InterruptedException e) {throw new RuntimeException(e);}}});t1.start();t2.start();}運行結果如下:










)
)


)




