25年5月來自香港大學、OpenDriveLab 和智元機器人的論文“Learning to Act Anywhere with Task-centric Latent Actions”。
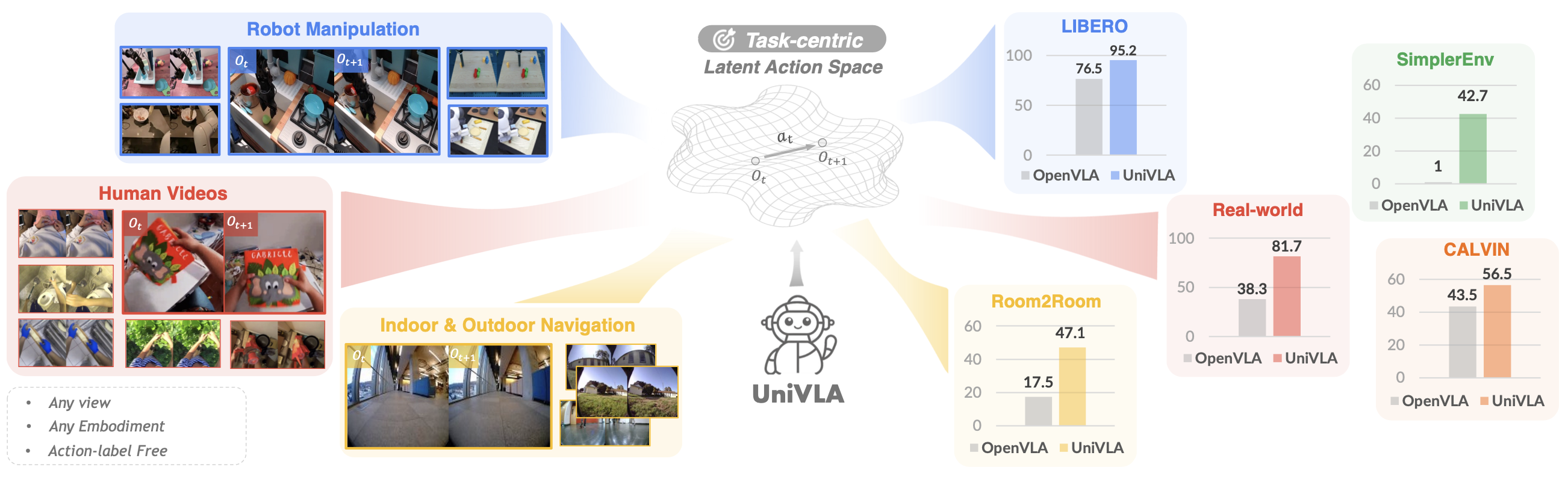
通用機器人應該在各種環境中高效運行。然而,大多數現有方法嚴重依賴于擴展動作標注數據來增強其能力。因此,它們通常局限于單一的物理規范,難以學習跨不同具身和環境的可遷移知識。為了突破這些限制,UniVLA,是一個用于學習跨具身視覺-語言-動作 (VLA) 策略的全新框架。關鍵創新在于利用潛動作模型從視頻中獲取以任務為中心的動作表征,這樣能夠利用涵蓋廣泛具身和視角的海量數據。為了減輕與任務無關動態變化的影響,結合語言指令,并在 DINO 特征空間內建立一個潛動作模型。該通用策略基于互聯網規模的視頻學習,可以通過高效的潛動作解碼部署到各種機器人上。在多個操作和導航基準測試以及實際機器人部署中均獲得最佳結果。 UniVLA 的性能遠超 OpenVLA,其預訓練計算量和下游數據量分別不到 OpenVLA 的二十分之一和十分之一。隨著異構數據(甚至包括真人視頻)被納入訓練流程,性能持續提升。這些結果凸顯 UniVLA 在促進可擴展且高效的機器人策略學習方面的潛力。
得益于大規模機器人數據集 [78, 63, 38, 18] 的出現,基于視覺-語言-動作模型 (VLA) 的機器人策略近期取得了令人鼓舞的進展 [9, 28, 39]。然而,這些策略通常依賴于真實動作標簽進行監督,這限制了它們在利用來自不同環境互聯網規模數據方面的可擴展性。此外,不同具身(例如,Franka、WidowX,甚至人手)和任務(例如,操作和導航)之間動作和觀察空間的異質性,對有效的知識遷移構成了重大挑戰。這引出了一個關鍵問題:能否學習一種統一的動作表征,使通用策略能夠有效地進行規劃,從而釋放互聯網規模視頻的潛力,并促進跨不同具身和環境的知識遷移?
視覺-語言-動作模型。在預訓練視覺基礎模型、大語言模型 (LLM) 和視覺-語言模型 (VLM) 的成功基礎上,VLA 已被引入用于處理多模態輸入(視覺觀察和語言指令),并生成用于完成具身任務的機器人動作。RT-1 [10] 和 Octo [28] 采用基于 Transformer 的策略,該策略整合各種數據,包括跨各種任務、目標、環境和具身的機器人軌跡。相比之下,一些先前的研究 [9, 39, 46] 利用預訓練的 VLM,通過利用來自大規模視覺-語言數據集的世界知識來生成機器人動作。例如,RT-2 [9] 和 OpenVLA [39] 將動作視為語言模型詞匯表中的 tokens,而 RoboFlamingo [46] 引入一個額外的策略頭用于動作預測。在這些通用策略的基礎上,RoboDual [12] 提出一種協同雙系統,融合通用策略和專家策略的優勢。其他研究則結合目標圖像 [8] 或視頻 [24, 82, 13] 預測任務,以語言指令為條件生成有效、可執行的規劃,并利用這些視覺線索指導策略生成動作。然而,這些方法嚴重依賴于帶有真實動作標簽的交互式數據,這顯著限制 VLA 的可擴展性。
跨具身學習。由于不同機器人系統的攝像機視角、本體感受輸入、關節配置、動作空間和控制頻率存在差異,訓練通用機器人策略極具挑戰性。早期方法 [86] 側重于在導航和操作之間手動方式對齊動作空間,但操作時僅限于腕部攝像機。近期基于 Transformer 的方法 [28, 23] 通過適應不同的觀測和動作解決這些挑戰,其中 CrossFormer [23] 可在四個不同的動作空間中進行協同訓練,而無需對觀測空間施加限制或要求顯式對齊動作空間。流表征(用于捕捉圖像或點云中查詢點的未來軌跡)已被廣泛應用于跨具身學習 [81, 88, 26, 83]。ATM [81] 從人類演示中學習流生成,而 Im2Flow2Act [83] 則無需域內數據,即可從人類視頻中預測物體流。同時,以目標為中心的表征 [32, 7] 提供了一種替代方法,SPOT [32] 可以在 SE(3) 中預測目標軌跡,從而將具身動作與感官輸入分離。現有方法需要大量、多樣化的數據集來涵蓋所有可能的狀態轉換模式,并且需要明確的注釋,導致數據利用率低下。
潛動作學習。一些先前的研究側重于學習變分自編碼器 [64, 76] 來構建新的動作空間,強調緊湊的潛表征以促進行為生成和任務自適應,例如 VQ-BeT [44] 和 Quest [59]。這些方法也被強化學習采用以加速收斂 [2]。最近的研究 [79, 74] 探索將矢量量化作為動作空間適配器,以便更好地將動作集成到大語言模型中。然而,這些方法的一個關鍵限制是它們依賴于真實動作標簽,這限制它們的可擴展性。為了利用更廣泛的視頻數據,Genie [11] 通過因果潛動作模型提取潛動作,并以下一幀預測為條件。同樣,LAPO [70] 和 DynaMo [20] 直接從視覺數據中學習潛動作,繞過在域內操作任務中使用顯式動作標簽的方法。LAPA [87] 和 IGOR [15] 引入無監督的預訓練方法來教授 VLA 離散潛動作,旨在從人類視頻中遷移知識。然而,這些方法對原始像素中的所有視覺變化進行編碼,捕獲了與任務無關的動態,例如相機抖動、其他智體的移動或新目標的出現,這最終會降低策略性能。
為了應對這些挑戰,UniVLA,是一個通用策略學習框架,能夠跨各種具身和環境進行可擴展且高效的規劃。就像大語言模型 (LLM) 學習跨語言共享知識 [22, 17] 一樣,目標是構建一個統一的動作空間,以促進跨視頻數據的知識遷移,包括各種機器人演示和以自我為中心的人類視頻。通才策略包含三個關鍵階段:1)以任務為中心的潛動作學習,以無監督的方式從大量跨具身視頻中提取與任務相關的動作表征。這是通過使用 VQ-VAE [76] 從成對幀的逆動態中離散化潛動作來實現的。2)下一個潛動作預測,使用離散化的潛動作 tokens 訓練自回歸視覺語言模型,賦予其與具身無關的規劃能力。3)潛解碼,將潛規劃解碼為物理行為,并專門化預訓練的通才策略,以便有效地部署到未見過的任務中。
如圖所示:
雖然最近的研究 [87, 15] 已經探索從網絡規模視頻中學習潛動作的可行性,但它們存在一個關鍵的局限性:它們基于重建的簡單目標函數通常會捕捉與任務無關的動態,例如非自智體的移動或不可預測的攝像機移動。這些嘈雜的表征會引入與任務無關的干擾,從而阻礙策略預訓練。為了解決這個問題,利用預訓練的 DINOv2 特征 [62] 從像素中提取塊級表征,提供空間和以目標為中心的先驗知識,從而更好地捕獲與任務相關的信息。通過使用現成的語言指令作為條件,進一步將動作分解為兩個互補的動作表征,其中一個明確地表示以任務為中心的動作。
本文開發三個步驟來實現 UniVLA:1)(第三部分 A)利用基于語言的目標規范,以無監督的方式從大量視頻數據集中提取逆動態,從而生成一組以任務為中心的離散潛動作,這些動作可泛化至不同的具體實現和領域;2)(第三部分 B)在此基礎上,訓練一個基于自回歸 Transformer 的視覺-語言-動作模型,該模型以視覺觀察和任務指令作為輸入,在統一的潛空間中預測潛動作token;3)(第三部分 C)為了高效地適應各種機器人控制系統,引入專門的策略頭,將潛動作解碼為可執行的控制信號。
以任務為中心的潛動作學習
第一步通過生成偽動作標簽(即潛動作 tokens)奠定了該框架的基礎,這些標簽是后續階段訓練泛化策略的基礎。
潛動作量化。如圖展示潛動作模型的兩階段訓練流程和整體架構。從一對連續的視頻幀開始,記為 {o_t,o_t+k},兩個幀之間間隔為 k。為了確保不同數據集的時間間隔統一為大約 1 秒,幀間隔根據每個數據集特定的記錄頻率進行標定。為了從視頻中得出潛動作,潛動作模型圍繞基于逆動力學模型 (IDM) 的編碼器 I(a_t|o_t,o_t+k) 和基于前向動力學模型 (FDM) 的解碼器 F(o_t+k|o_t,a_t) 構建。編碼器根據連續的觀察推斷潛動作,解碼器經過訓練,可以根據指定的潛動作預測未來的觀察結果。遵循 Villegas [77] 的研究,將編碼器實現為具有隨意時間掩碼的時空transformer [84]。一組可學習的動作 tokens a_q(具有預定義的維度 d)按順序連接到視頻特征以提取動態特征。
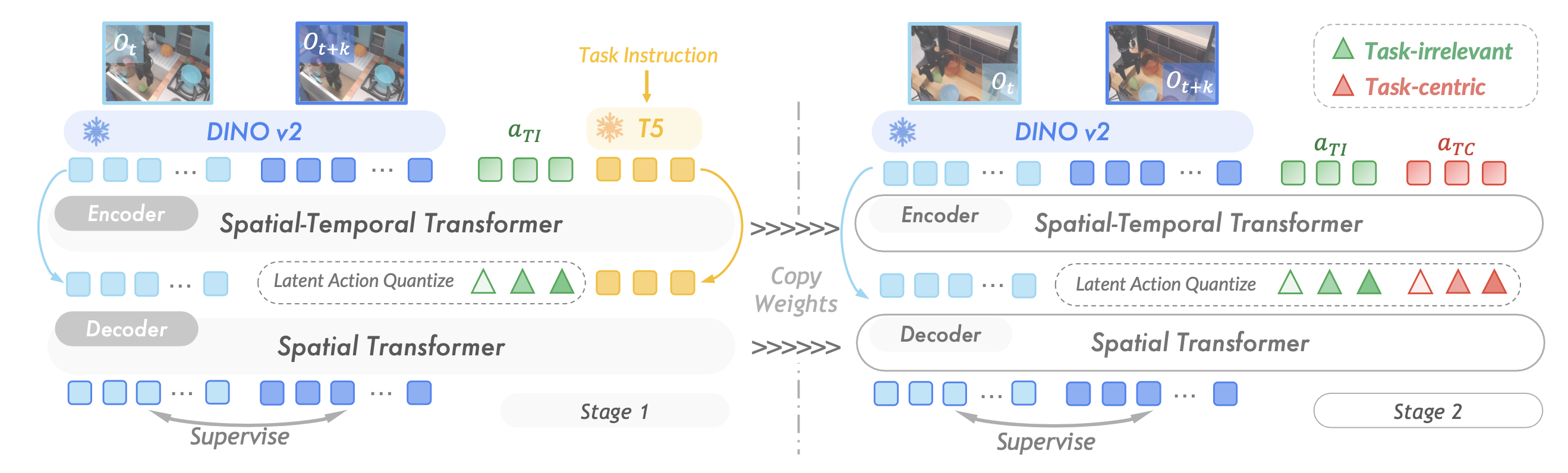
為了進一步壓縮信息并使其與基于自回歸 transformer 策略的學習目標 [66] 保持一致,對動作 tokens 應用潛量化。量化的動作 tokens a_z 使用 VQ-VAE [76] 目標進行優化,其碼本詞匯量為 |C|。解碼器實現為空間 transformer,經過優化,僅使用量化的動作 tokens 即可預測未來幀。不將歷史幀輸入解碼器,以防止模型過度依賴上下文信息或僅僅記憶數據集。
雖然最近的研究 [11, 27, 87] 使用原始像素進行預測,但像素空間預測會迫使模型關注嘈雜的、與任務無關的細節(例如,紋理、光照)[30]。這一問題在網絡規模和眾包視頻數據集 [29] 中尤為突出,因為不受控制的捕獲條件會引入進一步的變化。受聯合嵌入預測架構 (JEPA) [4, 5, 96] 的啟發,本文提出使用 DINOv2 [62] 空間塊特征作為語義豐富的表征。它們以目標為中心和空間感知的特性使它們不僅適合用作輸入,也適合用作潛動作模型的預測目標。自監督目標是最小化嵌入重構誤差:||O?_t+k ? O_t+k||^2。用 {O_t, O_t+k} 來表示成對視頻幀 {o_t, o_t+k} 的 DINOv2 特征。因此,緊湊的潛動作必須對觀測值之間的變換進行編碼,以最小化預測誤差。
潛動作解耦。如前所述,在網絡規模視頻中,機器人的動作通常會與不相關的環境變化糾纏在一起。為了減輕與任務無關的動態特征帶來的不利影響,將現成的語言指令融入到潛動作模型的第一訓練階段(如上圖左)。語言輸入使用預訓練的 T5 文本編碼器 [67] 進行編碼,并作為編碼器和解碼器上下文中的條件信號。
向解碼器發送任務指令提供了關于底層動作的高級語義指導。因此,量化的潛動作經過優化,僅編碼環境變化和視覺細節[89],由于碼本容量有限,省略與任務相關的高級信息[1]。此階段建立一組潛動作,其中包含與任務無關的信息,例如新目標的出現、外智體的移動或攝像機引起的運動偽影。這些動態特征雖然對于將模型應用于視覺環境至關重要,但與任務的具體目標無關。
接下來,將在第 1 階段訓練的潛動作模型任務無關碼本和參數重新用于下一階段(如圖右所示),其目標是學習一組新的以任務為中心的潛動作 a?_TC,并在此基礎上訓練策略。
基于已獲取的與任務無關的表征,凍結相應的碼本,使模型能夠專注于細化和特化新的潛動作集合。這種特化有助于精確建模與任務相關的動態,例如目標(object)操控或目標(goal)導向的運動軌跡。隱性動作表征的顯式解耦增強了泛化策略在不同環境和任務中的泛化能力。與簡單的隱性動作學習方法(例如 LAPA [87])相比,僅基于以任務為中心的表征進行訓練可以實現更快的收斂速度,同時實現穩健的性能,這表明這些隱性動作對于后續的策略學習更具參考價值。
泛化策略的預訓練
基于上一步訓練的潛動作模型,繼續在給定 o_t+k 的情況下,用隱動作 a_z tokens 任意視頻幀 o_t。然后,使用這些標簽來開發泛化策略。為了與 Kim [39] 的研究保持一致,提出一種基于隱性動作的通才策略,建立在 Prismatic-7B [37] 視覺語言模型 (VLM) 之上。該架構集成源自 SigLip [90] 和 DINOv2 [62] 的融合視覺編碼器、用于將視覺嵌入與語言模態對齊的投影層,以及 LLaMA-2 大語言模型 (LLM) [75]。與之前基于 LLM 的通才策略(即 RT-2 [9] 和 OpenVLA [39])不同,這些策略通過將 LLaMA token化器詞匯表中不常用的詞映射到 [-1, 1] 內均勻分布的動作區間來直接在低級動作空間中進行規劃,而本文用 |C| 個特殊 tokens 擴展了詞匯表,具體為 {ACT_1, ACT_2, ACT_3, …, ACT_C}。潛動作會根據其在動作碼本中的索引投影到此詞匯表中。這種方法保留了 VLM 的原始模型架構和訓練目標,充分利用其預訓練知識,并將其遷移到機器人控制任務中。具體來說,策略模型 π_φ 接收觀測值 o_t、任務指令 l 以及潛動作 token 前綴 a_z,<i,并進行優化,以最小化下一個潛動作負對數概率之和。
此外,經驗證據表明,壓縮動作空間(例如,當 |C| = 16 時,動作空間從 OpenVLA [39] 中的 2567 減少到 16^4)可顯著加速模型收斂。該方法僅需 960 個 A100 小時的預訓練就取得具有競爭力的結果,與 OpenVLA 預訓練所需的 21,500 個 A100 小時相比,大幅減少。
通過在統一的潛動作空間內訓練策略,該模型充分利用從跨領域數據集中獲得的可遷移知識。與 Yang [86] 的論文不同,該論文需要通過視覺上相似的自我中心運動(例如操作任務中的腕部攝像頭運動和自我中心導航)手動調整動作空間,而該方法則省去了這一步驟。因此,UniVLA 擴展可用數據集的范圍并提升整體性能,證明利用以任務為中心的潛動作表征進行可擴展策略學習的有效性。
部署后訓練
潛動作解碼。在下游自適應過程中,預訓練的通用策略通過預測下游自適應過程中的下一個潛動作來保持其與具身無關的特性。為了彌合潛動作與可執行行為之間的差距,采用額外的動作解碼器(如圖所示)。具體來說,視覺嵌入序列首先通過多頭注意池 [43] 聚合為單個 tokens,然后該 tokens 作為查詢從潛動作嵌入中提取信息。
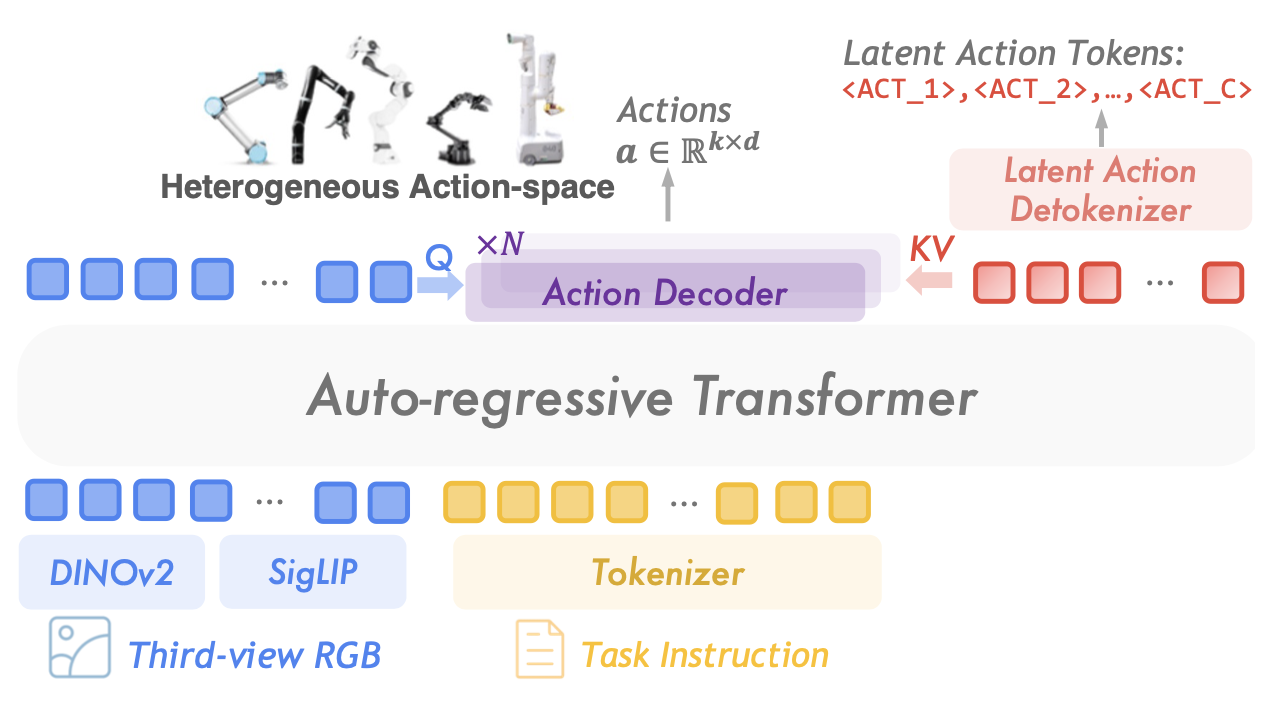
鑒于潛動作旨在表示大約一秒間隔內發生的動作,它們可以自然地解碼為動作塊 [93]。塊大小可根據具身輕松定制,以實現更流暢、更精確的控制。
在實踐中,利用 LoRA [33] 進行參數高效的微調,以實現高效的自適應。加上僅包含 12.6M 個參數的動作頭,可訓練參數總數約為 123M。整個模型采用端到端訓練,優化下一個潛動作預測損失以及真實動作與預測低級動作之間的 L1 損失。
從歷史輸出中學習。歷史觀察已被證明在增強機器人控制的序貫決策過程中發揮著關鍵作用 [60, 42, 45]。然而,直接為大型視覺-語言-動作模型提供多個歷史觀測數據會導致顯著的推理延遲,并導致視覺 token 中的信息冗余 [94, 45]。得到大語言模型 (LLM) 中成熟的思維鏈 (CoT) 推理范式 [80](可生成中間推理步驟來解決復雜任務)啟發,本文提出利用歷史潛動作輸出來促進機器人控制中的決策制定。與 LLM 逐步解決問題類似,在部署過程中的每個時間步將過去的動作融入到輸入提示中。這為機器人策略建立一個反饋回路,使策略能夠從自身的決策中學習并適應動態環境。
為了將這種方法付諸實踐,用潛動作模型來注釋從歷史幀中提取的動作。然后,這些帶注釋的動作被映射到 LLaMA tokens 詞匯表中,并附加到任務指令中。在訓練后階段,歷史動作輸入被集成為輸入,使模型具備上下文學習(ICL)能力。在推理時,除初始步驟外,每個時間步都會合并一個歷史潛動作(編碼為 N = 4 個 token)。實證結果表明,這種簡單的設計能夠提升模型性能,尤其是在長周期任務中。
實驗1
基于操作數據、導航數據和人體視頻數據(這三者分別是 Open X-Embodiment (OpenX) 數據集 [63]、GNM 數據集 [72] 和人體視頻 (Ego4D [29]) 的子集)對完整潛動作模型進行預訓練。LIBERO 基準 [48] 包含四個任務套件,專門用于促進機器人操作的終身學習研究。實驗專注于在目標任務套件中進行監督微調,評估通過行為克隆訓練的各種策略在成功任務演示上的表現。如圖所示,實驗設置包含以下任務套件,每個任務套件包含 10 個任務,每個任務包含 50 個人類遙控演示:

- LIBERO-Spatial 要求策略推斷空間關系以準確放置碗,評估模型推理幾何結構的能力;
- LIBERO-Object 保持相同的場景布局,但引入了目標類型的變化,以此評估策略在不同目標實例間的泛化能力;
- LIBERO-Goal 保持一致的目標和布局,同時分配不同的任務目標(goal),以此挑戰策略展現面向目標的行為和適應性;
- LIBERO-Long 專注于涉及多個子目標的長期操作任務,結合異構目標、布局和任務序列來評估模型在復雜、多步驟規劃中的能力。
選擇的基線模型包括以下五個代表性模型,其中 OpenVLA 和 LAPA 與本文方法更為接近:
? LAPA [87] 引入一個無監督框架,用于從未標記的人類視頻中學習潛動作。
? Octo [28] 是一種基于 Transformer 的策略,在多樣化的機器人數據集上進行訓練,它采用統一的動作表示來處理異構的動作空間。
? MDT [68] 利用擴散模型生成由多模態目標決定的靈活動作序列。
? OpenVLA [39] 是一種視覺-語言-動作模型,它利用包括 OpenX 在內的多樣化數據集進行大規模預訓練,以實現通用的機器人策略。
? MaIL [35] 通過整合選擇性狀態空間模型來增強模仿學習,從而提高策略學習的效率和可擴展性。
實驗 2
另外,本實驗在 VLN-CE 基準 [41] 上評估 UniVLA,以評估其在導航任務中的表現。這些基準提供一組語言引導的導航任務和連續環境,用于在重建的照片級真實感室內場景中執行低級動作。具體來說,專注于 VLN-CE 中的 Room2Room (R2R) [3] 任務,這是視覺和語言導航 (VLN) 領域最受認可的基準之一。所有方法均基于 R2R 訓練集的 10,819 個樣本進行訓練,并基于 R2R val-unseen 集的 1,839 個樣本進行評估。使用 oracle 成功率來評估導航性能。在 VLN-CE 中,如果智體到達目標 3 米以內,則認為該回合成功。
為了確保與 UniVLA 進行公平比較,評估僅基于 RGB 的方法,這些方法無需深度或里程計數據,可直接預測 VLN-CE 環境中的低級動作。選定的基準如下:
? Seq2Seq [40] 是一種循環的序列到序列策略,可根據 RGB 觀測值預測動作。
? CMA [40] 采用跨模態注意機制,將指令與 RGB 觀測值相結合,進行動作預測。
? LLaVA-Nav 是 LLaVA [49] 的改進版本,與 NaVid [91] 提出的數據進行協同微調,并使用“從觀測到歷史”的技術對歷史記錄進行編碼。
? OpenVLA [39] 是一個視覺-語言-動作模型。引入一些特殊的 tokens 來 token 化導航動作,并在 R2R 訓練樣本上對模型進行微調。
? NaVid [91] 是一個基于視頻的大型視覺-語言模型,它對所有歷史 RGB 觀測值進行編碼。
實驗 3
所有真實世界實驗均采用 AgileX Robotics 的 Piper 機械臂進行,該機械臂具有 7 自由度動作空間和第三視角 Orbecc DABAI RGB-D 相機,僅使用 RGB 圖像作為輸入。為了評估策略,設計一套涵蓋策略能力各個維度的綜合任務,包括:
- 空間感知:拿起螺絲刀放入柜子并關上柜門(“存放螺絲刀”)。
- 工具使用和非抓握操作:拿起掃帚,將砧板上的物品掃入簸箕(“清潔砧板”)。
- 可變形目標操作:將毛巾對折兩次(“折疊毛巾兩次”)。
- 語義理解:先將中等大小的塔堆疊在大塔之上,然后將小塔堆疊在中等大小的塔之上。(“堆疊漢諾塔”)
對于每個任務,收集 20 到 80 條軌跡,并根據任務復雜度進行縮放,以微調模型。為了全面評估泛化能力,設計了涵蓋多個未見過場景的實驗,包括光照變化、視覺干擾和目標泛化(如圖所示)。鑒于單憑成功率不足以反映策略性能或區分其能力,引入一個分階式評分系統。對于四個任務中的每一個,分配最高 3 分,以反映任務執行過程中不同階段的完成情況。

選擇擴散策略 [16] 以及通用策略 OpenVLA [39] 和 LAPA [87] 作為基準。擴散策略以單任務方式訓練,而通用模型則在所有任務上同時進行指令輸入訓練。為了公平起見,使用 Prismatic-7B VLM [37] 和動作解碼器頭復現LAPA,并將其架構與該方法保持一致。這種設置能夠分離并強調以任務為中心潛動作空間的貢獻。








)
)


)






