傳統的C++語法中就有引用的語法,而C++11中新增了的右值引用語法特性,所以從現在開始我們之前學習的引用就叫做左值引用。無論左值引用還是右值引用,都是給對象取別名。
左值引用和右值引用
在講之前,我們先來看一下什么是左值和右值
左值和左值引用
左值是一個表示數據的表達式(如變量名或解引用的指針),我們可以獲取它的地址+可以對它賦
值,左值可以出現賦值符號的左邊,右值不能出現在賦值符號左邊。定義時const修飾符后的左
值,不能給他賦值,但是可以取它的地址。左值引用就是給左值的引用,給左值取別名。
int main()
{// p、b、c、*p都是左值int* p = new int(0);int b = 1;const int c = 2;// 以下幾個是對上面左值的左值引用int*& rp = p;int& rb = b;const int& rc = c;int& pvalue = *p;return 0;
}右值和右值引用
右值也是一個表示數據的表達式,如:字面常量、表達式返回值,函數返回值(這個不能是左值引
用返回)等等,右值可以出現在賦值符號的右邊,但是不能出現出現在賦值符號的左邊,右值不能
取地址。右值引用就是對右值的引用,給右值取別名。由于右值通常不具有名字,我們也只能通過引用的方式找到它的存在。通常情況下,我們只能是從右值表達式獲得其引用。比如:
T && a = ReturnRvalue();
這個表達式中,假設ReturnRvalue返回一個右值,我們就聲明了一個名為a的右值引用,其值等于ReturnRvalue函數返回的臨時變量的值。ReturnRvalue函數返回的右值在表達式語句結束后,其生命也就終結了,而通過右值引用的聲明,該右值又“重獲新生”,其生命周期將于右值引用類型變量a的生命周期一樣。只要a還“活著”,該右值臨時量將會一直“存活”下去。
所以相比于以下語句的聲明方式:
T b = ReturnRvalue();
我們剛才的右值引用變量聲明,就會少一次對象的析構及一次對象的構造。因為a是右值引用,直接綁定了ReturnRvalue返回的臨時量,而b只是由臨時值構造而成的,而臨時量在表達式結束后會析構應而就會多一次析構和構造的開銷。
double fmin(double x, double y)
{return x + y;
}int main()
{// 以下幾個都是常見的右值double x = 1.1, y = 2.2; // 字母常量10; x + y; // 表達式返回值double ret = fmin(x, y); // 函數返回值// 以下幾個都是對右值的右值引用int&& rr1 = 10;double&& rr2 = x + y;double&& rr3 = fmin(x, y);// 這里編譯會報錯:error C2106: “=”: 左操作數必須為左值/*10 = 1;x + y = 1;fmin(x, y) = 1;*/return 0;
}
需要注意的是右值是不能取地址的,但是給右值取別名后,會導致右值被存儲到特定位置,且可以取到該位置的地址。
左值引用與右值引用比較
先來回顧一下左值引用
int main()
{// 左值引用只能引用左值,不能引用右值。int a = 10;int& ra1 = a; // ra1是a的別名//int& ra2 = 10; // 編譯失敗,因為10是右值return 0;
}
我們思考一下下面2個問題:
左值引用可以引用右值嗎?
右值引用可以引用左值嗎?
通過上面的代碼我們可以發現左值引用不能引用右值,那么為什么還要問這個問題了?其實我們可以引用右值,因為我們的測試還不夠全面。可以看下面的情況:
// const左值引用既可引用左值,也可引用右值。
const int& ra3 = 10;
const int& ra4 = a;
常量左值
為什么加了const之后,就能引用右值了呢?這是因為字符常量具有常性,也就是不能被修改,如果我們使用引用來引用常量,那么我們就能通過引用來修改這個常量,這就違反了常量的特性。簡單來說這是一個權限的放大,即“不能被修改變成了可以被修改”,所以加個const引用來限制。
在C++98標準中常量左值就是個“萬能”的引用類型。它可以接受非常量左值、常量左值、右值對其進行初始化。而且在使用右值對其初始化的時候,常量左值引用還可以像右值引用一樣將右值的生命期延遲。不過相比于右值引用所引用的右值,常量左值所引用的右值在它的“余生”中只能是只讀的。相對地,非常量左值只能接受非常量左值對其進行初始化。看下面的代碼。
// 常量左值引用
struct Copyable
{Copyable(){}Copyable(const Copyable& o){cout << "Copied" << endl;}
};Copyable ReturnRvalue() { return Copyable(); }
void AcceptVal(Copyable){}
void AcceptRef(const Copyable &){}int main()
{cout << "Pass by value: " << endl;AcceptVal(ReturnRvalue()); // 臨時值被拷貝傳入cout << "Pass by reference: " << endl;AcceptRef(ReturnRvalue()); // 臨時值被作為引用傳遞
}
我們聲明了一個結構體Copyable,該結構體的作用是在被拷貝到時候打印一句話Copied。而兩個函數AcceptVal使用了值傳遞參數,而AcceptRef使用了引用傳遞。在以ReturnRvalue返回的右值為參數的時候,AcceptRef就可以直接使用產生的臨時值(并延長生命周期),而AcceptVal則不能直接使用臨時對象。
運行代碼,結果如下:
Pass by value:
Copied
Copied
Pass by reference:
Copied
可以看到,由于使用了左值引用,臨時對象被直接作為函數的參數,而不需要從中拷貝一次。在C++11中,同樣的,可以使用以右值引用為參數聲明如下函數void AcceptRvalueRef(Copyable &&) {}也同樣可以減少臨時變量拷貝到開銷。進一步地,還可以再AcceptRvalueRef中修改該臨時值(這個時候臨時值由于被右值引用參數所引用,已經獲得了函數時間的生命期)。不過修改一個臨時值的意義通常不大。
在下表中,列出了在C++11中各種引用類型可以引用的值的類型。需要注意的是,只要能夠綁定右值的引用類型,都能夠延長右值的生命期。
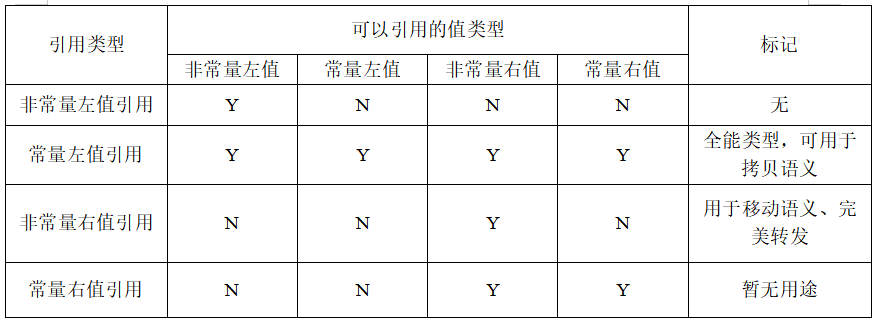
[!note] 總結
- 左值引用只能引用左值,不能引用右值。
- 但是const左值引用既可引用左值,也可引用右值。
接下來看右值引用
int main()
{// 右值引用只能右值,不能引用左值。int&& r1 = 10;// error C2440: “初始化”: 無法從“int”轉換為“int &&”// message : 無法將左值綁定到右值引用int a = 10;int&& r2 = a; // 報錯// 右值引用可以引用move以后的左值int&& r3 = std::move(a);return 0;
}
這里的move函數是C++11之后新出的一個函數,其作用是將一個左值強制轉換成一個右值,類似強制類型轉換,還有move并不會改變一個變量本身的左值屬性,例如 int b = 1;double a = (double)b這句代碼,本質上b還是一個整型類型,只是在這個表達式中,返回了一個double類型的b。
[!note] 總結
- 右值引用只能右值,不能引用左值。
- 但是右值引用可以move以后的左值。
右值引用的場景和意義
既然我們要知道右值引用的意義是什么,那么就需要先知道左值引用的優點和缺點是什么,有哪些場景要用到左值引用。
- 左值引用降低了內存使用和提高效率
string add_string(string& s1, string& s2)
{string s = s1 + s2;return s;
}int main()
{string str;string hello = "Hello";string world = "world";str = add_string(hello, world);return 0;
}
我們先來回顧一下非引用傳參和引用傳參的本質
- 非引用傳參:在函數調用時,非引用傳參實際上是傳遞了實參的一個副本給形參。這意味著在函數內部對形參的任何修改都不會影響到原始的實參。非引用傳參包括普通形參和指針形參,但指針形參傳遞的是地址的副本,而不是對象本身的副本。
- 引用傳參:引用傳參則是將實參的引用(或別名)傳遞給形參。在函數內部對形參的操作實際上是對實參本身的操作,因此任何修改都會反映到原始的實參上。
所以引用傳參不需要復制實參,而是直接操作實參本身,可以節省內存并提高效率。這對于大型對象或數據結構的傳遞尤為重要。而非引用傳參需要復制整個對象或結構,這可能會導致較大的內存開銷和較低的執行效率。
2. 左值引用解決了一部分返回值的拷貝問題
string& func()
{static string s = "hello world";return s;
}int main()
{string str1;str1 = func();return 0;
}

引用返回和非引用返回的區別:
- 非引用返回:當函數的返回類型為非引用類型時,函數的返回值用于初始化在調用函數時創建的臨時對象。這意味著,如果返回類型不是引用,在調用函數的地方會將函數返回值復制給臨時對象。其返回值既可以是局部對象(在函數內部定義的對象),也可以是求解表達式的結果。這種復制過程可能會導致額外的內存開銷和性能損失。
- 引用返回:當函數返回類型為引用類型時,沒有復制返回值。相反,返回的是對象本身(或更準確地說,是對對象的引用)。因此,返回引用類型通常更高效,因為它避免了不必要的復制操作。但是,需要注意的是,返回引用時必須確保引用的對象在函數返回后仍然有效。
從圖中可以看出引用返回比非引用返回少了一次拷貝構造。這是因為返回值s指向的string是全局的,當出了函數作用域依然存在,因此我們可以傳引用返回,不用拷貝構造給臨時變量,節省了一次拷貝構造。
而在非引用返回函數當中,func函數依然返回hello world這個字符串,但是s是一個局部變量。出了函數作用域就會被銷毀,那么如果str1要想接收到s,那么就會創建一個臨時變量拷貝構造給它,然后臨時變量再拷貝構造給str。
那么如果我們不想使用引用返回,還想減少一次拷貝,該如何實現呢?答案就是使用右值引用。先來看看有哪些情況下會產生可以被右值引用的左值:
- 當一個左值被move后,可以被右值引用
- C++會把即將離開作用域的非引用類型的返回值當成右值,這種類型的右值也稱為
將亡值
在C++11中,把右值分為純右值和將亡值。
- 純右值就是內置類型的右值,講的是用于辨識臨時變量和一些不跟對象關聯的值。比如非引用返回的函數返回的臨時變量值就是一個純右值。一些運算表達式,比如
1+3產生的臨時變量值,也是純右值。而不跟對象關聯的字母量值,比如:2、‘c’;、true,也是純右值。 - 將亡值就是C++11新增的跟右值引用相關的表達式,這樣表達式通常是將要被移動的對象(移為他用),比如返回右值引用
T&&的函數返回值、std::move的返回值或者轉換為T&&的類型轉換函數的返回值。回顧剛才的代碼,變量s已經快要離開作用域了,馬上就會被銷毀,s銷毀沒有問題,但是字符串hello world是我們需要的。這種情況可以理解為:一個快要去世的病人,臨走前說要把自己的器官捐贈給別人,當然也可以指定捐贈給他人。
同理,一旦左值得到了右值屬性,相當于把自己的資源給別人,不希望自己的資源被系統釋放,而是被合適的對象繼承走。s即將被銷毀,此時s就是一個右值了,右值的意思就是:這個變量的資源可以被遷移走。這句話非常非常重要!!!
<type_traits>頭文件
有的時候,我們可能不知道一個類型是否是引用類型,以及是左值引用還是右值引用(在模板中比較常見)。標準庫在<type_traits>頭文件中提供了3個模板類:is_rvalue_reference、is_lvalue_reference、is_reference,可供我們進行判斷。比如:
int main()
{cout << is_rvalue_reference<string&&>::value << endl; //1cout << is_rvalue_reference<string&>::value << endl; //0cout << is_lvalue_reference<string&>::value << endl; //1cout << is_reference<string&>::value << endl; //1
}
我們通過模板類的成員value就可以打印出string &&是否是一個右值引用了。配合類型推導符decltype,我們甚至還可以對變量的 類型進行判斷。
移動語義
那么右值是如何把資源遷移走的呢?這就要學習右值引用的移動語義了:
拷貝構造函數中為指針成員分配新的內存再進行內容拷貝到做法在C++編程中幾乎被視為是不可違背的。不過在一些時候,我們確實不需要這樣的拷貝構造語義。我們先看下面的代碼。
class HasPtrMem
{
public:HasPtrMem() :d(new int(0)){cout << "Construct: " << ++n_cstr << endl;}HasPtrMem(const HasPtrMem& h) :d(new int(*h.d)){cout << "Copy Construct: " << ++n_cptr << endl;}~HasPtrMem(){cout << "Destruct: " << ++n_dstr << endl;}int* d;static int n_cstr;static int n_dstr;static int n_cptr;
};int HasPtrMem::n_cstr = 0;
int HasPtrMem::n_dstr = 0;
int HasPtrMem::n_cptr = 0;HasPtrMem GetTemp()
{return HasPtrMem();
}int main()
{HasPtrMem a = GetTemp();
}
在代碼中,我們聲明了一個返回一個HasPtrMem變量的函數。為了記錄構造函數、拷貝構造函數,以及析構函數調用的次數,我們使用了一些靜態變量。在main函數中,我們簡單聲明了一個HasPtrMem的變量a,要求它使用GetTemp的返回值進行初始化。運行結果如下(未開啟編譯器優化):
Construct: 1
Copy construct: 1
Destruct: 1
Copy construct: 2
Destruct: 2
Destruct: 3
首先在GetTemp函數中創建臨時對象,調用HasPtrMem構造函數創建臨時對象,輸出Construct: 1,接著,GetTemp函數返回臨時對象時進行拷貝構造,調用拷貝構造函數輸出Copy construct: 1,臨時對象離開GetTemp函數作用域,調用析構函數,輸出Destruct: 1。再然后main函數中進行拷貝構造,將 GetTemp() 函數返回的對象拷貝給對象 a,調用拷貝構造函數,輸出 Copy Construct: 2。GetTemp() 函數返回的對象離開 main 函數中賦值語句的作用域,調用析構函數,輸出 Destruct: 2。最后main函數結束時析構對象a,輸出Destruct: 3。
如果開啟了編譯器優化,那么GetTemp函數中創建的臨時對象會直接作為對象a進行構造,不會發生拷貝構造。所以開啟了編譯器優化后,結果是:
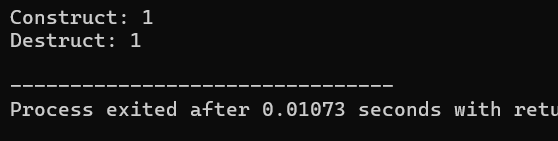
接下來我以未開啟優化來講解。在代碼中,類HasPtrMem只有一個int類型指針。而如果HasPtrMem的指針指向非常大的堆內存數據的話,那么拷貝構造的過程就會非常昂貴。可以想象,這種情況一旦發生,a的初始化表達式的執行速度將相當堪憂。
在main函數部分,按照C++的語義,臨時對象將在語句結束后被析構,會釋放它所包含的堆內存資源。而a在拷貝構造的時候,又會被分配堆內存。這樣的一去一來似乎并沒有太大的意義,那么我們是否可以在臨時對象構造a的時候不分配內存,即不使用所謂的拷貝構造呢?
在C++11中,答案是肯定的,我們可以看下面的示意圖:
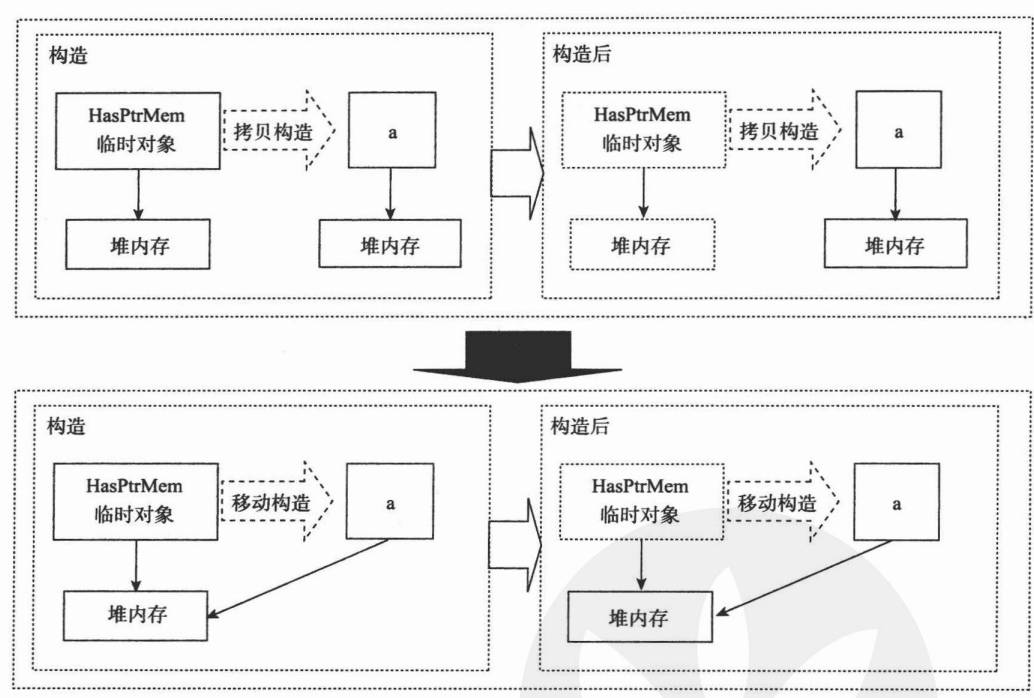
上半部分可以看到從臨時變量中拷貝構造變量a的做法,即在拷貝時分配新的堆內存,并從臨時對象的堆內存中拷貝內容至a.d。而構造完成后,臨時對象將析構,因此其擁有的堆內存資源會被析構函數釋放。而下半部分則是一種“新”方法,該方法在構造時使得a.d指向臨時對象的堆內存資源。同時我們保證臨時對象對象不釋放所指向的堆內存,那么在構造完成后,臨時對象被析構,a就從中“偷”到了臨時對象所擁有的堆內存資源。
在C++11中,這樣的“偷走”臨時變量中資源的構造函數,被稱為“移動構造函數”。這樣的“偷”的行為,則稱為“移動語義”。可以理解為“移為己用”。通過下面的代碼來看一看如何實現這樣的移動語義。
class HasPtrMem
{
public:HasPtrMem() :d(new int(3)){cout << "Construct: " << ++n_cstr << endl;}HasPtrMem(const HasPtrMem& h) :d(new int(*h.d)){cout << "Copy Construct: " << ++n_cptr << endl;}HasPtrMem(HasPtrMem&& h) :d(h.d) // 移動構造函數{h.d = nullptr; // 將臨時值的指針成員置為空cout << "Move construct: " << ++n_mvtr << endl;}~HasPtrMem(){delete d;cout << "Destruct: " << ++n_dstr << endl;}int* d;static int n_cstr;static int n_dstr;static int n_cptr;static int n_mvtr;
};int HasPtrMem::n_cstr = 0;
int HasPtrMem::n_dstr = 0;
int HasPtrMem::n_cptr = 0;
int HasPtrMem::n_mvtr = 0;HasPtrMem GetTemp()
{HasPtrMem h;cout << "Resource from " << __func__ << ": " << hex << h.d << endl;return h;
}int main()
{HasPtrMem a = GetTemp();cout << "Resource from " << __func__ << ": " << hex << a.d << endl;
}
對比剛才的代碼,這個代碼多了一個構造函數HasPtrMem(HasPtrMem &&),這個就是移動構造函數。與拷貝構造函數不同的是,移動構造函數接受一個所謂的“右值引用”的參數。移動構造函數使用了參數h的成員d初始化了本對象的成員d(而不是像構造函數一樣需要分配內存,然后將內容依次拷貝到新分配的內存中),而h的成員d隨后被置為nullptr。這樣就完成了移動構造的全過程。
代碼運行結果如下(未開啟優化)
Construct: 1
Resource from GetTemp: 0x603010
Move construct: 1
Destruct: 2
Move construct: 2
Destruct: 2
Resource from main: 0x603010
Destruct: 3
可以看到,這里沒有調用拷貝構造函數,而是調用了兩次移動構造函數,移動構造函數的結果是,GetTemp中的h的指針成員h.d和main函數中的a的指針成員a.d的值是相同的,即h.d和a.d都指向了相同的堆地址內存。該堆內存在函數返回的過程中,成功的逃避了被析構的命運,取而代之地,成為了賦值表達式中的變量a的資源。如果堆內存不是一個int長度的數據,而是以mbyte為單位的堆空間,那么這樣的移動帶來的性能提升是非常驚人的。
std::move()
在C++11中,標準庫<utility>中提供了一個有用的函數std::move,這個函數的名字具有迷惑性,因為實際上move并不能移動任何東西,它唯一的功能是將一個左值強制轉化為右值引用,繼而我們可以通過右值引用使用該值,以用于移動語義。從實現上講,std::move基本等同于一個類型轉換:static_cast<T&&>(lvalue);。
值得一提的是,被轉化的左值,其生命期并沒有隨著左右值的轉化而改變。來看下面的示例:
class Moveable
{
public:Moveable():i(new int(3)){}~Moveable() { delete i; }Moveable(const Moveable & m):i(new int(*m.i)){}Moveable(Moveable&& m) :i(m.i){m.i = nullptr;}int* i;
};int main()
{Moveable a;Moveable c(move(a)); // 會調用移動構造函數cout << *a.i << endl;
}

在代碼中,我們為類型Moveable定義了移動構造函數。這個函數定義本身沒有什么問題,但是調用的時候,使用了Moveable c(move(a));這樣的語句。這里的a本來是一個左值變量,通過move后變成右值。這樣一來,a.i就被c的移動構造函數設置為指針空值。由于a的生命周期實際要到main函數結束才結束,那么隨后的表達式*a.i進行計算的時候,就會發生嚴重的運行時錯誤。
來看一看正確的代碼。
class HugeMem
{
public:HugeMem(int size) :sz(size > 0 ? size : 1) {c = new int[sz];}~HugeMem() { delete[]c; }HugeMem(HugeMem&& hm) :sz(hm.sz), c(hm.c) {hm.c = nullptr;}int* c;int sz;
};class Moveable
{
public:Moveable() :i(new int(3), h(1024) {}~Moveable() { delete i; }Moveable(Moveable && m) :i(m.i), h(move(m.h)) // 強制轉化為右值,以調用移動構造函數{m.i = nullptr;}int* i;HugeMem h;
};Moveable GetTemp()
{Moveable tmp = Moveable();cout << hex << "Huge Mem from " << __func__ << " @" << tmp.h.c << endl;// Huge Mem from GetTemp @0x603030return tmp;
}int main()
{Moveable a(GetTemp());cout << hex << "Huge Mem from " << __func__ << " @" << a.h.c << endl;// Huge Mem from GetTemp @0x603030return 0;
}
在代碼中,我們定義了兩個類型:HugeMem和Moveable,其中Moveable包含了一個HugeMem的對象。在Moveable的移動構造函數中,我們就看到了std::move函數的使用。該函數將m.h強制轉化為右值,以迫使Moveable中的h能夠實現移動構造。這里也可以使用std::move,是因為m.h是m的成員,既然m將存在表達式結束后被析構,其成員也自然會被析構,因此不存在上一個代碼中生存期不對的問題。
那么如果不使用std::move(m.h)這樣的表達式,而是直接使用m.h這個表達式會怎么樣?這里的m.h引用了一個確定的對象,而且m.h也有名字,可以使用&m.h取到地址,因此是一個不折不扣的左值。不過這個左值確實會很快“灰飛煙滅”,因為拷貝構造函數在Moveable對象a的構造完成后也就結束了。那么這里使用std::move強制轉為右值就不會有問題了。而且,如果我們不這么做,由于m.h是個左值,就會導致調用HugeMem的拷貝構造函數來構造Moveable的成員h。如果是這樣,移動語義就沒有能夠成功地向類的成員傳遞。換言之,還是會由于拷貝而導致一定的性能上的損失。
事實上,為了保證移動語義的傳遞,在編寫移動構造函數的時候,應該總是記得使用move轉換擁有形如堆內存、文件句柄等資源的成員為右值,這樣一來,如果成員支持移動構造的話,就可以實現其移動語義。而即使成員沒有移動構造函數,那么接受常量左值的構造函數版本也會輕松地實現拷貝構造,因此也不會引起大的問題。
完美轉發
完美轉發,是指在函數模板中,完全依照模板的參數的類型,將參數傳遞給函數模板中調用的另外一個函數。比如:
template <typename T>
void IamForwording(T t) {IrunCodeActually(t); }
這個例子中,IamForwording是一個轉發函數模板。而函數IrunCodeActually則是真正執行代碼的目標函數。對于目標函數IrunCodeActually而言,它總是希望轉發函數將參數按照傳入Iamforwarding時的類型傳遞(即傳入的是左值對象,IrunCodeActually就能獲得左值對象,傳入右值是也是一樣),而不產生額外的開銷,就好像轉發者不存在一樣。
這似乎是一件很容易的事情,但其實并不簡單。在上面的例子中,在IamForwarding的參數中使用了最基本類型進行轉發,該方法會導致參數在傳給IrunCodeActually之前就產生了一次額外的臨時對象拷貝。因此這樣的轉發只能說是正確的轉發,但談不上完美。
所以通常程序需要對是一個引用類型,引用類型不會產生額外的開銷。其次,則需要考慮轉發函數對類型的接收能力。因為目標函數可能需要既能夠接受左值引用,又接受右值引用。那么如果轉發函數只能接受其中的一部分,就無法做到完美轉發。那么如果使用“萬能”的常量左值類型呢?以常量左值為參數的轉發函數會一些尷尬,比如:
void IrunCodeActually(int t) {}
template <typename T>
void IamForwording(const T& t) {IrunCodeActually(t); }
由于目標函數的參數類型是非常量左值類型,因此無法接受常量左值引用作為參數,這樣一來,雖然轉發函數的接受能力很高,但在目標函數的接受上卻出了問題。那么我們可能就需要通過一些常量和非常量的重載來解決目標函數的接受問題。這在函數參數比較多的情況下,就會造成代碼冗余,而且根據上面的表格中,如果我們的目標函數的參數是個右值引用的話,同樣無法接受任何左值類型作為參數,間接的,也就導致無法使用移動語義。
那么C++11如何解決完美轉發的問題的呢?實際上,C++11是通過“引用折疊”的新語言規則,并結合新的模板推導規則來完成完美轉發。
在C++11以前,例如下面的語句:
typedef const int T;
typedef T& TR;
TR& v = 1; // 該聲明在C++98中會導致編譯錯誤
其中TR& v = 1這樣的表達式會被編譯器認為是不合法的表達式,而在C++11中,一旦出現了這樣的表達式,就會發生引用折疊,即將復雜的未知表達式折疊為已知的簡單表達式,如下表。
| TR的類型定義 | 聲明v的類型 | v的實際類型 |
|---|---|---|
| T& | TR | A& |
| T& | TR& | A& |
| T& | TR&& | A& |
| T&& | TR | A&& |
| T&& | TR& | A& |
| T&& | TR&& | A&& |
規則并不難記,因為一旦定義中出現了左值引用,引用折疊總是優先將其折疊為左值引用。而模板對類型的推導規則比較簡單,當轉發函數的實參是類型X的一個左值引用,那么目標參數被推導為X&類型,而轉發函數的實參是類型X的一個右值引用的話,那么模板的參數被推導為X&&類型。結合以上的折疊規則,就能確定出參數的實際類型。進一步,我們可以把轉發函數寫成如下形式:
template <typename T>
void IamForwording(T&& t)
{IrunCodeActually(static_cast<T && > (t));
}
我們不僅在參數部分使用了T &&這樣的標識,在目標函數傳參的強制類型轉換中也使用了這樣的形式。比如我們調用轉發函數時傳入了一個X類型的左值引用,可以想象,轉發函數將被實例化為如下形式:
void IamForwording(X& && t)
{IrunCodeActually(static_cast<X& && > (t));
}
引用折疊規則就是:
void IamForwording(X& t)
{IrunCodeActually(static_cast<X&> (t));
}
對于一個右值而言,當它使用右值引用表達式引用的時候,該右值引用卻是個左值,那么我們想在函數調用中繼續傳遞右值,就需要使用move來進行左右值的轉換。而move通常就是一個static_cast。不過在C++11中,用于完美轉發的函數卻不再叫做move,而是另外一個名字:forward。所以我們可以把轉發函數寫成這樣:
template <typename T>
void IamForwording(T && t)
{IrunCodeActually(forward(t));
}
move和forward在實際實現上差別并不大。來看一個完美轉發的代碼:
void RunCode(int&& m) { cout << "rvalue ref" << endl; }
void RunCode(int& m) { cout << "lvalue ref" << endl; }
void RunCode(const int&& m) { cout << "const rvalue ref" << endl; }
void RunCode(const int& m) { cout << "const lvalue ref" << endl; }template<typename T>
void PerfectForward(T&& t) { RunCode(forward<T>(t)); }int main()
{int a;int b;const int c = 1;const int d = 0;PerfectForward(a); // lvalue refPerfectForward(move(b)); // rvalue refPerfectForward(c); // const lvalue refPerfectForward(move(d)); // const rvalue ref
}
可以看到,所有的轉發都被正確地送到了目的地。
完美轉發的一個作用就是包裝函數,這是一個很方便的功能,對上面的代碼稍作修改,就可以用很少的代碼記錄單參數函數的參數傳遞狀況。
template<typename T, typename U>
void PerfectForward(T&& t, U& Func)
{cout << t << "\tforwarded..." << endl;Func(forward<T>(t));
}void RunCode(double && m) {}
void RunHome(double && h) {}
void RunComp(double && c) {}int main()
{PerfectForward(1.5, RunComp); // 1.5 forwarded...PerfectForward(8, RunCode); // 8 forwarded...PerfectForward(1.5, RunHome); // 1.5 forwarded...
}


)


)













string)