標題:[數據結構高階]并查集初識、手撕、可以解決哪類問題?
@水墨不寫bug

文章目錄
- 一、認識并查集
- 二、模擬實現并查集
- 三、用并查集解決問題
- 1、[省份的數量](https://leetcode.cn/problems/number-of-provinces/)
- 2、[等式方程的可滿足性](https://leetcode.cn/problems/satisfiability-of-equality-equations/)
- 四、并查集的路徑壓縮
一、認識并查集
一個考察隊要去西部開發考察,這個考察隊隊員有10人,其中鄭州4人,北京3人,西安3人。于是這三個城市的人由于生活習慣相似分別抱團,那么如何快速確定兩個人是否屬于同一個城市呢?并查集就可以。
并查集 :本質是一個森林(包含多棵樹)。并且與堆類似,用下標表示關系。使用雙親表示法(只存儲雙親)。
如何用數據結構表示并查集?
用一個線性結構(數組)表示。每一個位置都初始化為-1,表示10棵樹:
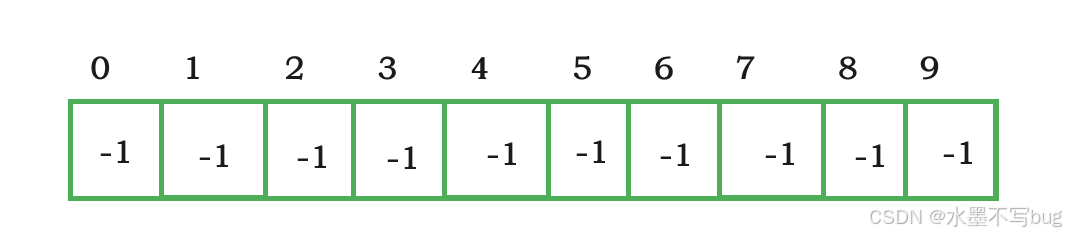
假如0,6,7,8是鄭州人;1,4,9是北京人;2,3,5是西安人,那么通過樹形結構表示(默認下標最小的0,1,2作為小隊長- - -根節點):
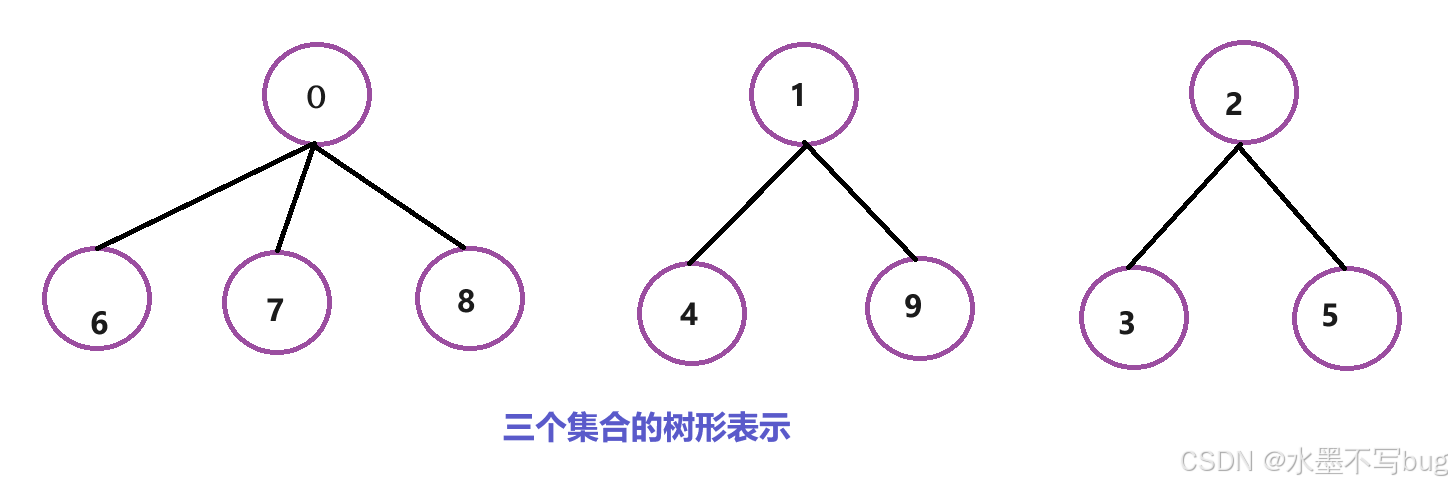
如果有新成員加入?
數組對應的隊員的值存儲的是隊長的下標,隊長的值的絕對值表示包括隊長在內的小隊成員個數。隊長的值原來為-1,一個隊員加入小隊,隊長的值+=隊員的值(-1)|如果隊員是隊長,則+=(-m),然后隊員的值修改為隊長的值。
在線性的數組上,需要明確:
- 1.一個位置值是負數,那它就是數的根,這個負數的絕對值就是這棵樹的數據個數。
- 2.一個位置值是正數,那這個位置存的是雙親的下標。
那么上圖對應的線性結構是:
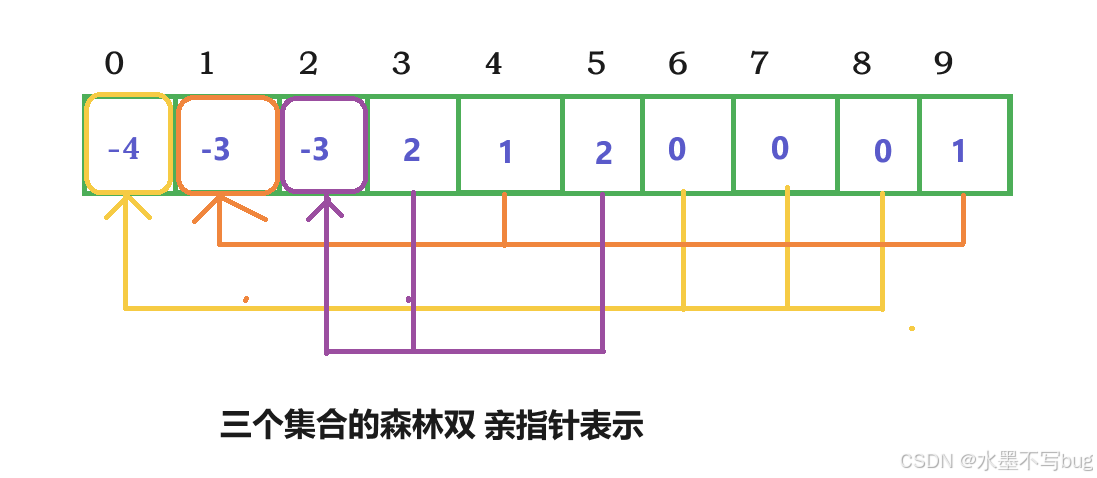
如果兩隊伍合并?
由于研究工作需要,北京人和鄭州人需要合并,那么在數據結構上如何表示?
其實,把北京人合并入鄭州,把鄭州人合并入北京,沒有本質區別。
假如把北京人合并入鄭州,那么對應的樹形結構變成:
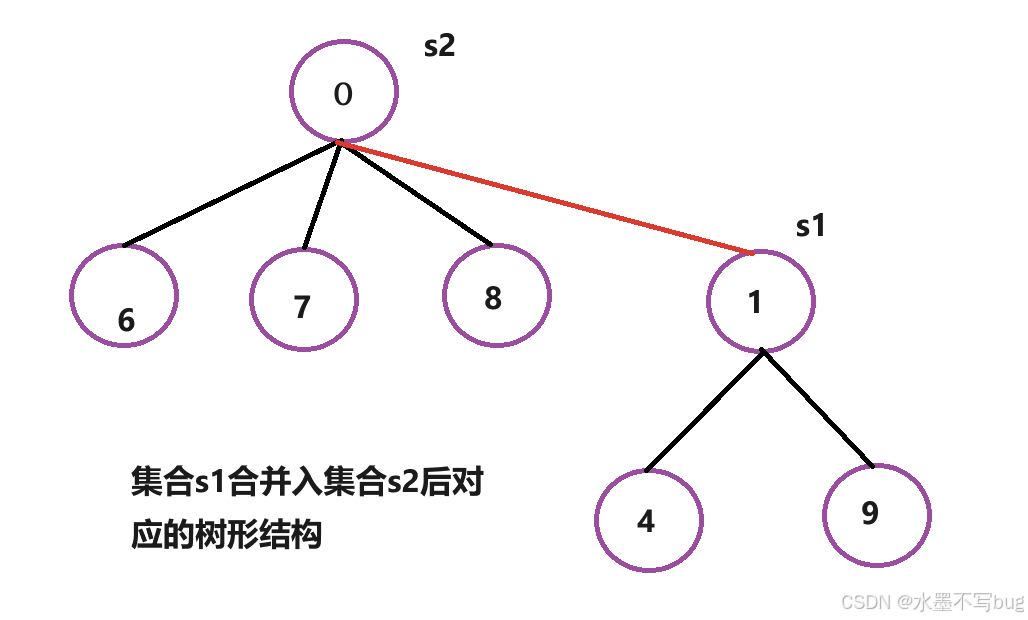
那么對應的線性結構:
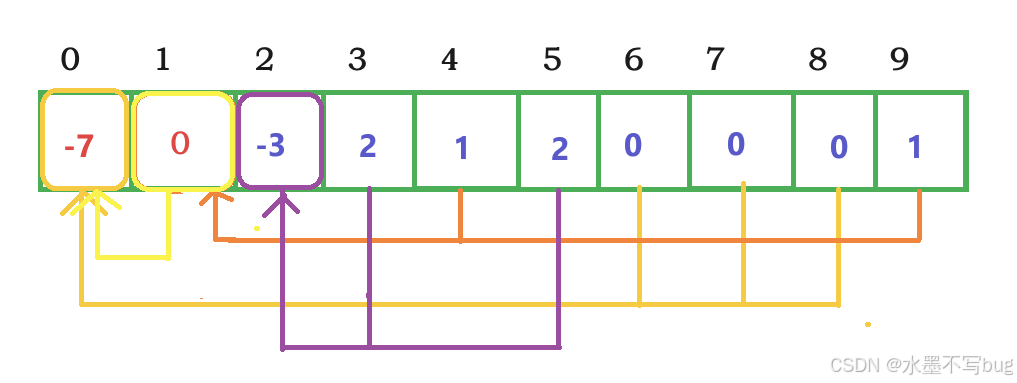
這就是并查集的加入一個成員,一個小隊的操作。想要看兩個隊員是否在同一組,只需要不停找根,如果兩個隊員同根,那就在同一組。
二、模擬實現并查集
并查集可以通過一個STL的vector維護,具體實現思路已經在上文有所體現,于是在這里直接給出實現:
#pragma once
#include<iostream>
#include<vector>
namespace ddsm
{class UnionFindSet{public://根據并查集規則,初始化為-1UnionFindSet(int size):_ufs(size,-1){}//把兩個集合【隊伍】合并void Union(int x1,int x2){int root1 = FindRoot(x1);int root2 = FindRoot(x2);if (root1 == root2)return;_ufs[root1] += _ufs[root2];_ufs[root2] = root1;}//找到一個元素所在的集合int FindRoot(int x){int parents = x;while (_ufs[parents] >= 0)parents = _ufs[parents];return parents;}//判斷兩個元素是否在同一個集合bool InSameSet(int x1, int x2){return FindRoot(x1) == FindRoot(x2);}//返回集合的個數size_t Size(){size_t size = 0;for (int i = 0; i < _ufs.size(); ++i){if (_ufs[i] < 0)size++;}return size;}private:std::vector<int> _ufs;};
};三、用并查集解決問題
通過以上例子可知,并查集一般可以解決一下問題:
- 查找元素屬于哪個集合 --沿著數組表示樹形關系以上一直找到根(即:樹中中元素為負數的位置)
- 查看兩個元素是否屬于同一個集合 --沿著數組表示的樹形關系往上一直找到樹的根,如果根相同表明在同一個集合,否則不在。
- 將兩個集合歸并成一個集合 --將兩個集合中的元素合并將一個集合名稱改成另一個集合的名稱
- 集合的個數 --遍歷數組,數組中元素為負數的個數即為集合的個數。
1、省份的數量
本題通過把同一省份的城市放在同一集合中,遍歷所有城市鏈接情況,最后統計出省份(集合)的總數。

示例代碼:
class UnionFindSet
{
public://根據并查集規則,初始化為-1UnionFindSet(int size):_ufs(size,-1){}//把兩個集合【隊伍】合并void Union(int x1,int x2){int root1 = FindRoot(x1);int root2 = FindRoot(x2);if (root1 == root2)return;_ufs[root1] += _ufs[root2];_ufs[root2] = root1;}//找到一個元素所在的集合int FindRoot(int x){int parents = x;while (_ufs[parents] >= 0)parents = _ufs[parents];return parents;}//判斷兩個元素是否在同一個集合bool InSameSet(int x1, int x2){return FindRoot(x1) == FindRoot(x2);}//返回集合的個數size_t Size(){size_t size = 0;for (int i = 0; i < _ufs.size(); ++i){if (_ufs[i] < 0)size++;}return size;}
private:std::vector<int> _ufs;
};
class Solution {
public:int findCircleNum(vector<vector<int>>& isConnected) {UnionFindSet ufs(isConnected.size());for(int i = 0;i < isConnected.size();++i){for(int j = 0;j < isConnected[i].size();++j){if(isConnected[i][j] == 1)ufs.Union(i,j);}}return ufs.Size();}
};
但是每次都手撕一個并查集,還是麻煩,那就面向過程的來維護并查集ufs,代碼如下:
class Solution {
public:int findCircleNum(vector<vector<int>>& isConnected) {vector<int> ufs(isConnected.size(),-1);auto findroot = [&ufs](int x){while(ufs[x] >= 0) x = ufs[x]; return x;};for(int i = 0;i < isConnected.size();++i){for(int j = 0;j < isConnected[i].size();++j){if(isConnected[i][j] == 1){int rooti = findroot(i);int rootj = findroot(j);if(rooti == rootj)continue;else{ufs[rooti] += ufs[rootj];ufs[rootj] = rooti;}}}}int ret = 0;for(int i = 0;i < ufs.size();++i)if(ufs[i] < 0)++ret;return ret;}
};
2、等式方程的可滿足性
分兩遍:
第一遍設置集合關系,哪一個元素屬于哪一個集合先劃分好;
第二遍查找相悖,有相悖,返回false;否則true。


class Solution {
public:bool equationsPossible(vector<string>& equations) {vector<int> ufs(26,-1);auto findroot = [&ufs](int x){while(ufs[x] >= 0)x = ufs[x];return x;};//第一遍先設置集合關系for(int i = 0;i < equations.size();++i){if(equations[i][1] == '='){int root1 = findroot(equations[i][0] - 'a');int root2 = findroot(equations[i][3] - 'a');if(root1 != root2){ufs[root1] += ufs[root2];ufs[root2] = root1;}}}//第二次再查找相悖關系for(int i = 0;i < equations.size();++i){if(equations[i][1] == '!'){int root1 = findroot(equations[i][0] - 'a');int root2 = findroot(equations[i][3] - 'a');if(root1 == root2){return false;}}}//沒有相悖返回真return true;}
};
四、并查集的路徑壓縮
隨著一棵樹的高度增加,并查集的查找效率逐漸降低。路徑壓縮目的是減小樹的高度,進而提高并查集查找效率。
路徑壓縮一般來說有兩種思路:
**第一種:**每次查找一個位置,吧一個節點的位置直接更新到根。
**第二種:**每查找一個位置,把查找路徑上的節點位置都更新到根。
到這里并查集結束了,并查集是為了給圖做鋪墊。
完~
轉載請注明出處






)








)




