總結的知識點主要來源于前段時間在牛客刷SQL題目中遇到的錯誤
目錄
1.WHERE字句不能與高級函數連用
2.去重——distinct
3.不等于某個值
4.查多個范圍內的值
5. 升/降序排序
6.占位符
7.統計某類別總數+計算平均值
8.合并查詢——UNION (ALL)
9.CASE 函數 (添加新字段)
10.日期相關函數
11.字符串分割
12.取出某屬性為最小值的記錄
13.CTE與滑動窗口函數
CTE(Common Table Expression,公共表表達式)
滑動窗口函數的基本概念
滑動窗口函數的語法
關鍵點
常見的滑動窗口函數
示例
滑動窗口函數的優勢
14.日期函數與滑動窗口 應用
1.WHERE字句不能與高級函數連用
### 選項A:
```sql
select productid from orders where count(productid) > 1
```
這個查詢試圖從`orders`表中選擇`productid`,其中`productid`的數量大于1。然而,這個查詢語句在SQL中是無效的,因為`WHERE`子句不能直接使用聚合函數(如`COUNT`)。聚合函數通常在`HAVING`子句中使用,該子句用于過濾聚合結果。
### 選項D:
```sql
select productid from orders group by productid having count(productid) > 1
```
這個查詢是有效的。它首先按`productid`對`orders`表進行分組,然后使用`HAVING`子句來過濾那些`productid`出現次數大于1的組。這意味著它返回的是那些在訂單中至少出現兩次的產品ID。
總結:
- **選項A**試圖執行一個無效的SQL查詢,因為它錯誤地在`WHERE`子句中使用了聚合函數。
- **選項D**正確地使用了`GROUP BY`和`HAVING`子句來選擇那些在訂單中至少出現兩次的產品ID。
### 1. 聚合函數
聚合函數用于從一組值中生成單個值。常見的聚合函數包括:
- `COUNT()`:計算行數。
- `SUM()`:計算數值列的總和。
- `AVG()`:計算數值列的平均值。
- `MAX()`:找出數值列的最大值。
- `MIN()`:找出數值列的最小值。
### 2. GROUP BY 子句
`GROUP BY`子句用于將結果集的行分組,以便可以對每個組執行聚合函數。例如,你可以按產品ID分組,然后計算每個產品的總銷售額。
### 3. HAVING 子句
`HAVING`子句用于篩選分組后的結果。與`WHERE`子句不同,`HAVING`可以與聚合函數一起使用。`WHERE`子句用于在分組之前篩選行,而`HAVING`子句用于在分組之后篩選組。
### 4. 使用場景
- **基本聚合**:直接使用聚合函數,如`SELECT COUNT(*) FROM table;`。
- **分組聚合**:使用`GROUP BY`進行分組,然后應用聚合函數,如`SELECT productid, COUNT(*) FROM orders GROUP BY productid;`。
- **篩選聚合結果**:使用`HAVING`子句篩選聚合后的結果,如`SELECT productid FROM orders GROUP BY productid HAVING COUNT(*) > 1;`。
### 5. 注意事項
- `GROUP BY`子句中的列必須出現在選擇列表中,或者在聚合函數中使用。
- `HAVING`子句中的條件可以是聚合函數的結果。
- `WHERE`子句不能包含聚合函數,它用于在分組之前篩選行。
### 6. 示例
假設有一個`orders`表,包含`productid`和`quantity`列,你可以使用以下查詢來找出每個產品的平均訂購數量:
```sql
SELECT productid, AVG(quantity) AS average_quantity
FROM orders
GROUP BY productid;
```
如果你想找出平均訂購數量超過10的產品,可以使用`HAVING`子句:
```sql
SELECT productid, AVG(quantity) AS average_quantity
FROM orders
GROUP BY productid
HAVING AVG(quantity) > 10;
```
### 7. 性能優化
- 在使用`GROUP BY`時,確保分組的列上有索引,以提高查詢性能。
- 避免在`GROUP BY`子句中使用復雜的表達式或函數,這可能會降低性能。
在SQL查詢中,`GROUP BY productid;` 子句的作用是將結果集按照 `productid` 進行分組。這意味著對于每個不同的 `productid`,都會計算一個平均值。讓我們詳細探討一下加上和不加 `GROUP BY` 子句對結果的影響:
### 加上 `GROUP BY productid;`
當你使用 `GROUP BY productid;` 子句時,查詢會按照 `productid` 對結果進行分組。具體來說,這個查詢會:
1. 將 `orders` 表中所有行按照 `productid` 進行分組。
2. 對每個 `productid` 分組,計算 `quantity` 的平均值。
3. 返回每個 `productid` 及其對應的平均 `quantity`。
例如,假設 `orders` 表如下:
| productid | quantity |
|-----------|----------|
| 1???????? | 10?????? |
| 1???????? | 20?????? |
| 2???????? | 15?????? |
| 2???????? | 25?????? |
加上 `GROUP BY productid;` 后的查詢結果將是:
| productid | average_quantity |
|-----------|------------------|
| 1???????? | 15?????????????? |
| 2???????? | 20?????????????? |
### 不加 `GROUP BY productid;`
如果不使用 `GROUP BY productid;` 子句,查詢將不會對結果進行分組。這意味著聚合函數 `AVG(quantity)` 將應用于整個結果集,而不是每個 `productid` 分組。具體來說,這個查詢會:
1. 計算整個 `orders` 表中所有 `quantity` 的平均值。
2. 返回一個包含整個表平均 `quantity` 的單一行。
例如,對于上述 `orders` 表,不加 `GROUP BY productid;` 的查詢結果將是:
| average_quantity |
|------------------|
| 18.75??????????? |
2.去重——distinct

3.不等于某個值
普通值用“!=” ;不等于空值用 “is not”
4.查多個范圍內的值
Where in / not in ( , , )
5. 升/降序排序
Oder by … ASC/DESC
6.占位符
查找包含特定字符串的記錄,可以使用 LIKE 操作符,并結合通配符。常用的通配符有:
- %:表示任意長度的任意字符序列(包括空字符序列)。
- _:表示任意單個字符。
7.統計某類別總數+計算平均值
### 原始查詢
```sql
SELECT male_num, avg_gpa
FROM user_profile
GROUP BY gender
HAVING AVG(gpa);
```
### 問題分析
1. **`SELECT` 列未定義**:
?? - `male_num` 和 `avg_gpa` 在查詢中沒有定義,它們既不是表中的列,也不是聚合函數的結果。
?? - 你需要明確指定要選擇的列,并使用聚合函數計算這些值。
2. **`GROUP BY` 的使用**:
?? - `GROUP BY` 用于對數據進行分組,但你不能直接在 `SELECT` 中使用未分組的列。
?? - 如果你想要統計每個性別的總數和平均 GPA,應該使用 `COUNT` 和 `AVG` 函數。
3. **`HAVING` 的使用**:
?? - `HAVING` 子句通常用于過濾分組后的結果,但它需要一個條件表達式。
?? - 在你的查詢中,`HAVING AVG(gpa)` 是不完整的,因為它沒有指定具體的條件。
### 修正后的查詢
假設你想要統計男性用戶的總數和平均 GPA,可以使用以下查詢:
```sql
SELECT
??? COUNT(*) AS male_num,
??? AVG(gpa) AS avg_gpa
FROM
??? user_profile
WHERE
??? gender = 'M';
```
### 如果需要分組統計
如果你想要統計每個性別的總數和平均 GPA,可以使用以下查詢:
```sql
SELECT
??? gender,
??? COUNT(*) AS num,
??? AVG(gpa) AS avg_gpa
FROM
??? user_profile
GROUP BY
??? gender;
```
### 如果需要過濾特定性別的分組結果
如果你想要過濾出平均 GPA 大于某個值的性別分組,可以使用 `HAVING` 子句。例如,過濾出平均 GPA 大于 3.5 的性別分組:
```sql
SELECT
??? gender,
??? COUNT(*) AS num,
??? AVG(gpa) AS avg_gpa
FROM
??? user_profile
GROUP BY
??? gender
HAVING
??? AVG(gpa) > 3.5;
```
- SELECT 列的定義:SELECT 子句中的列必須是表中的實際列,或者是通過聚合函數計算得到的值。
- GROUP BY 的使用:GROUP BY 用于分組,SELECT 子句中的列必須是分組列或聚合函數的結果。
- HAVING 子句的使用:HAVING 用于過濾分組后的結果,必須包含一個條件表達式。
- WHERE 子句的使用:WHERE 用于過濾行,HAVING 用于過濾分組后的結果。
分組計算:
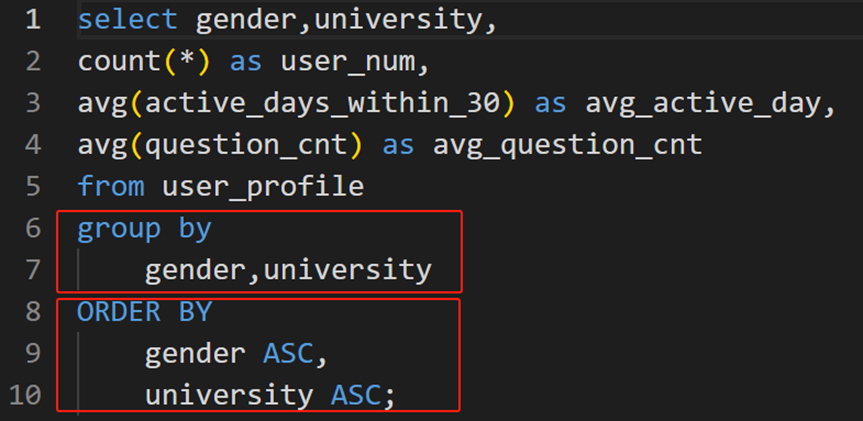
8.合并查詢——UNION (ALL)
Union all:用于合并兩個查詢的結果集,并且不會去重。如果兩個結果集中有相同的行,它們會被保留。
Union:去重合并
9.CASE 函數 (添加新字段)
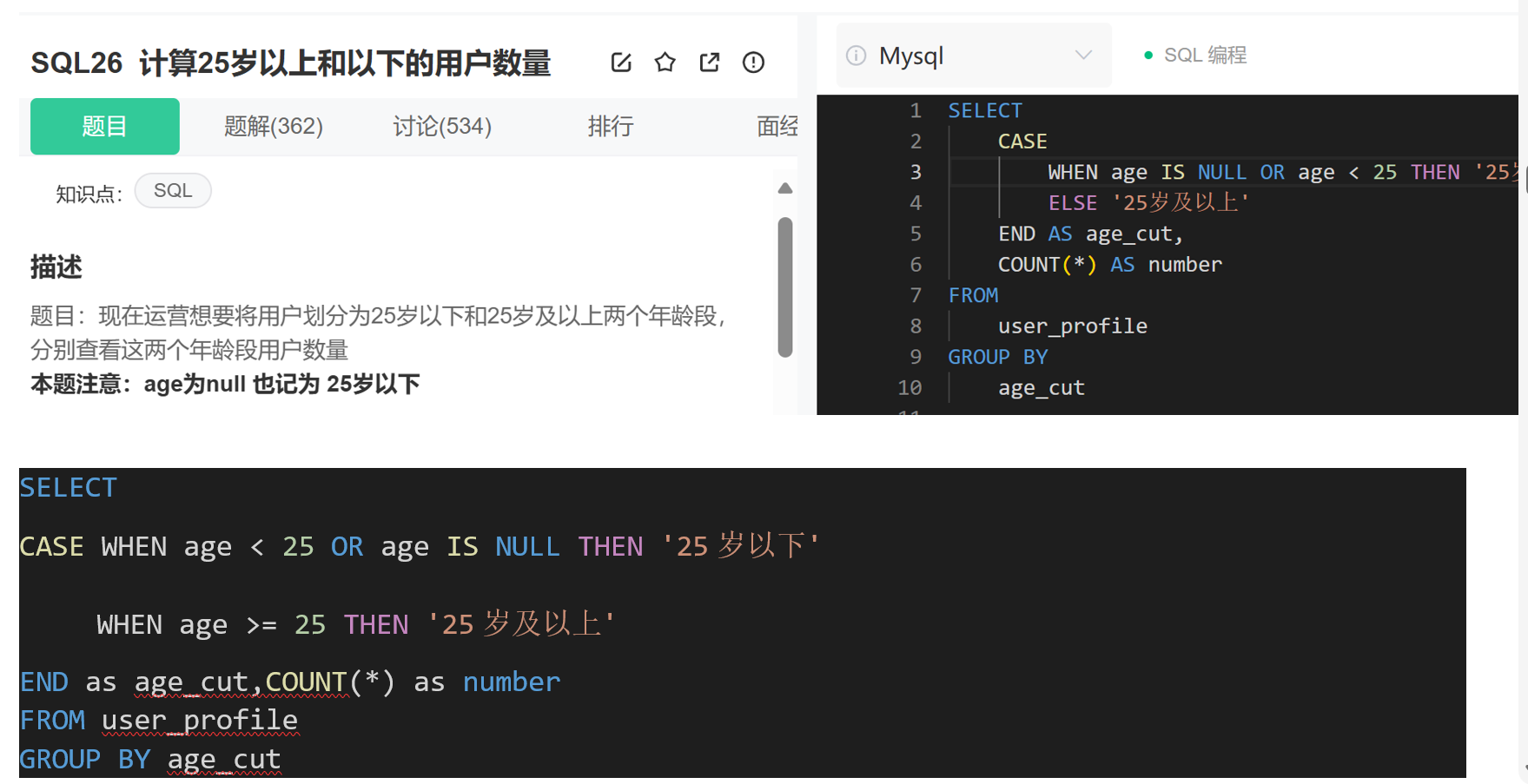
SELECT
CASE WHEN age < 25 OR age IS NULL THEN '25歲以下'
? ?? WHEN age >= 25 THEN '25歲及以上'
END as age_cut,COUNT(*) as number
FROM user_profile
GROUP BY age_cut
10.日期相關函數
1. 基本日期函數
- YEAR(date)
- 作用:從日期值中提取年份部分。
- 語法:YEAR(date)
- 示例:YEAR('2021-08-15') 返回 2021。
- MONTH(date)
- 作用:從日期值中提取月份部分。
- 語法:MONTH(date)
- 示例:MONTH('2021-08-15') 返回 8。
- DAY(date)
- 作用:從日期值中提取天數部分。
- 語法:DAY(date)
- 示例:DAY('2021-08-15') 返回 15。
- HOUR(time)
- 作用:從時間值中提取小時部分。
- 語法:HOUR(time)
- 示例:HOUR('14:30:00') 返回 14。
- MINUTE(time)
- 作用:從時間值中提取分鐘部分。
- 語法:MINUTE(time)
- 示例:MINUTE('14:30:00') 返回 30。
- SECOND(time)
- 作用:從時間值中提取秒數部分。
- 語法:SECOND(time)
- 示例:SECOND('14:30:00') 返回 0。
2. 日期格式化函數
- DATE_FORMAT(date, format)
- 作用:將日期值格式化為指定的字符串格式。
- 語法:DATE_FORMAT(date, format)
- 示例:
- DATE_FORMAT('2021-08-15', '%Y-%m-%d') 返回 '2021-08-15'。
- DATE_FORMAT('2021-08-15', '%Y%m%d') 返回 '20210815'。
3. 日期范圍篩選
- BETWEEN start AND end
- 作用:用于篩選某個字段值在指定范圍內的記錄。
- 語法:field BETWEEN start AND end
- 示例:
- date BETWEEN '2021-08-01' AND '2021-08-31' 用于篩選日期在 2021 年 8 月 1 日到 2021 年 8 月 31 日之間的記錄。
4. 日期計算函數
- DATE_ADD(date, INTERVAL expr type)
- 作用:在日期上加上指定的時間間隔。
- 語法:DATE_ADD(date, INTERVAL expr type)
- 示例:
- DATE_ADD('2021-08-15', INTERVAL 10 DAY) 返回 '2021-08-25'。
- DATE_SUB(date, INTERVAL expr type)
- 作用:從日期上減去指定的時間間隔。
- 語法:DATE_SUB(date, INTERVAL expr type)
- 示例:
- DATE_SUB('2021-08-15', INTERVAL 10 DAY) 返回 '2021-08-05'。
- DATEDIFF(date1, date2)
- 作用:計算兩個日期之間的天數差。
- 語法:DATEDIFF(date1, date2)
- 示例:
- DATEDIFF('2021-08-25', '2021-08-15') 返回 10。
5. 當前日期和時間函數
- NOW()
- 作用:返回當前的日期和時間。
- 語法:NOW()
- 示例:NOW() 返回當前的日期和時間,例如 '2025-03-24 14:30:00'。
- CURDATE()
- 作用:返回當前的日期。
- 語法:CURDATE()
- 示例:CURDATE() 返回當前的日期,例如 '2025-03-24'。
- CURTIME()
- 作用:返回當前的時間。
- 語法:CURTIME()
- 示例:CURTIME() 返回當前的時間,例如 '14:30:00'。
6. 時間戳函數
- UNIX_TIMESTAMP(date)
- 作用:將日期時間轉換為 Unix 時間戳(從 1970-01-01 00:00:00 UTC 開始的秒數)。
- 語法:UNIX_TIMESTAMP(date)
- 示例:UNIX_TIMESTAMP('2021-08-15 14:30:00') 返回對應的 Unix 時間戳。
- FROM_UNIXTIME(timestamp)
- 作用:將 Unix 時間戳轉換為日期時間格式。
- 語法:FROM_UNIXTIME(timestamp)
- 示例:FROM_UNIXTIME(1628994600) 返回 '2021-08-15 14:30:00'。
7. 其他日期函數
- LAST_DAY(date)
- 作用:返回指定日期所在月份的最后一天。
- 語法:LAST_DAY(date)
- 示例:LAST_DAY('2021-08-15') 返回 '2021-08-31'。
- DAYOFWEEK(date)
- 作用:返回指定日期是星期幾(1 = 星期天,2 = 星期一,...,7 = 星期六)。
- 語法:DAYOFWEEK(date)
- 示例:DAYOFWEEK('2021-08-15') 返回 1(星期天)。
- DAYOFYEAR(date)
- 作用:返回指定日期是一年中的第幾天。
- 語法:DAYOFYEAR(date)
- 示例:DAYOFYEAR('2021-08-15') 返回 227。
11.字符串分割
SUBSTRING_INDEX函數:
SUBSTRING_INDEX(str, delim, count):從字符串str中,以delim為分隔符,提取從開始到第count個分隔符之間的內容。
SUBSTRING_INDEX(profile, ',', 3):提取從開始到第3個逗號之前的內容。
SUBSTRING_INDEX(profile, ',', -1):提取從最后一個逗號到結束的內容。
STR_SPLIT函數:
- 在MySQL 8.0及以上版本中,可以使用STR_SPLIT函數來分割字符串。例如:
sqlCopy
SELECT STR_SPLIT(profile, ',', 1) AS height,
?????? STR_SPLIT(profile, ',', 2) AS weight,
?????? STR_SPLIT(profile, ',', 3) AS age,
?????? STR_SPLIT(profile, ',', 4) AS gender
FROM users;
12.取出某屬性為最小值的記錄
- 子查詢部分:
(SELECT university, MIN(gpa) FROM user_profile GROUP BY university)
-
- 這個子查詢首先按照university字段對user_profile表進行分組(GROUP BY) university。
- 然后,對于每個分組(即每個大學),計算出該大學中學生的最低gpa值(MIN(gpa))。
- 最終,子查詢返回一個包含每個大學及其對應最低gpa值的結果集。
- 主查詢部分:
SELECT device_id, university, gpa
FROM user_profile
WHERE (university, gpa) IN (子查詢結果)
ORDER BY university
-
- 主查詢從user_profile表中選擇device_id、university和gpa這三個字段。
- WHERE子句中的條件(university, gpa) IN (...)用于篩選出那些在user_profile表中,其university和gpa的組合與子查詢返回的結果集中的某個組合相匹配的記錄。也就是說,只選擇每個大學中gpa最低的學生記錄。
- 最后,ORDER BY university將結果按照university字段進行升序排序。
-----------------------------------------------------------
select emp_no,
birth_date,
first_name,
last_name,
gender,
hire_date
from employees
where hire_date = (select max(hire_date) from employees )?? ????//單一值用“=”,后查詢需“()”????
舉個例子: 假設user_profile表中有以下數據:
| device_id | university | gpa |
| 1 | MIT | 3.0 |
| 2 | MIT | 2.5 |
| 3 | Stanford | 3.5 |
| 4 | Stanford | 3.5 |
子查詢會返回:
| university | min_gpa |
| MIT | 2.5 |
| Stanford | 3.5 |
主查詢會根據這個結果篩選出:
| device_id | university | gpa |
| 2 | MIT | 2.5 |
| 3 | Stanford | 3.5 |
| 4 | Stanford | 3.5 |
這樣,我們就得到了每個大學中gpa最低的學生記錄,并且按照大學名稱排序。
13.CTE與滑動窗口函數
CTE(Common Table Expression,公共表表達式)
是一種臨時的結果集,可以在SQL查詢中被重復使用。它類似于一個臨時表,但它的作用范圍僅限于當前查詢。CTE可以簡化復雜的SQL查詢,使查詢更易于理解和維護。
CTE的語法結構如下:
WITH CTE_name (column1, column2, ...)
AS (
??? -- CTE的查詢定義
??? SELECT column1, column2, ...
??? FROM some_table
??? WHERE some_condition
)
SELECT column1, column2, ...
FROM CTE_name
WHERE some_condition;
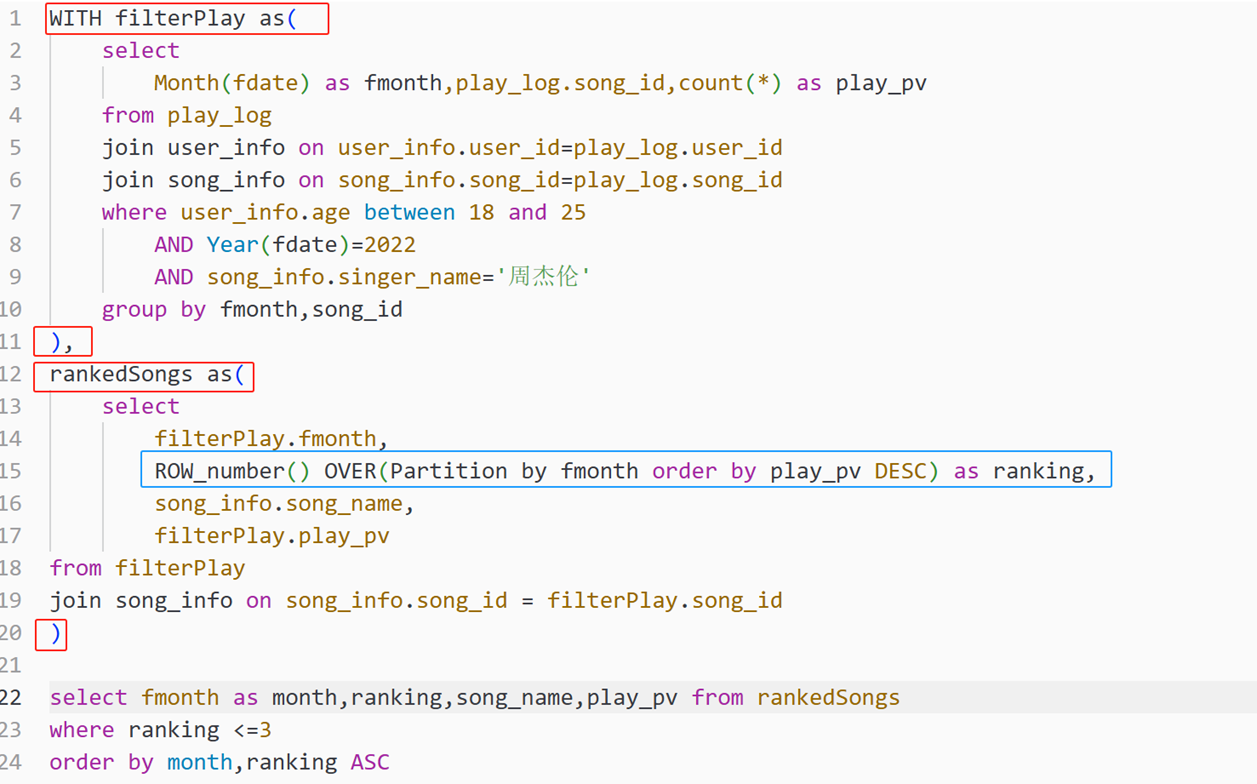
滑動窗口函數的基本概念
滑動窗口函數通過 OVER 子句定義一個窗口(或范圍),并在該窗口內對數據進行計算。窗口可以基于行的順序、分組或特定的范圍來定義。常見的滑動窗口函數包括 ROW_NUMBER()、RANK()、DENSE_RANK()、SUM()、AVG()、MIN()、MAX() 等。
滑動窗口函數的語法
滑動窗口函數的語法結構如下:
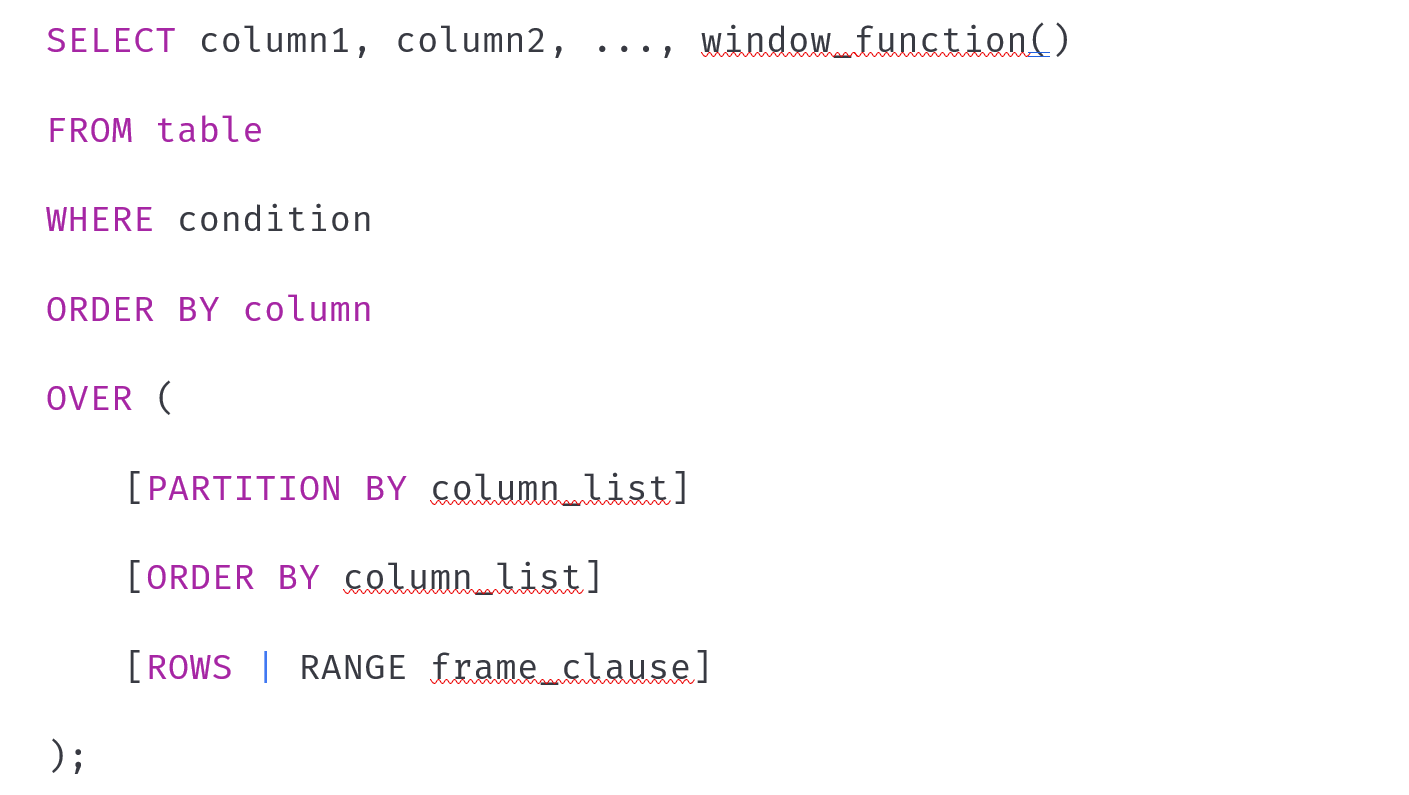
關鍵點
PARTITION BY:- 將數據分成多個分區,窗口函數在每個分區內獨立計算。
- 類似于
GROUP BY,但不會丟失行的細節。
ORDER BY:- 定義窗口內行的順序。
ROWS或RANGE:- 定義窗口的范圍,可以是基于行數的范圍(
ROWS)或基于值的范圍(RANGE)。
- 定義窗口的范圍,可以是基于行數的范圍(
常見的滑動窗口函數
ROW_NUMBER():- 為每一行分配一個唯一的序號,序號在每個分區內從1開始遞增。

RANK():- 為每一行分配一個排名,排名在每個分區內從1開始遞增,相同值的行會分配相同的排名,但會跳過后續的排名。

DENSE_RANK():- 與
RANK()類似,但不會跳過后續的排名。
- 與

SUM():- 計算窗口內的總和。

AVG():- 計算窗口內的平均值。

MIN()和MAX():- 計算窗口內的最小值和最大值。

示例
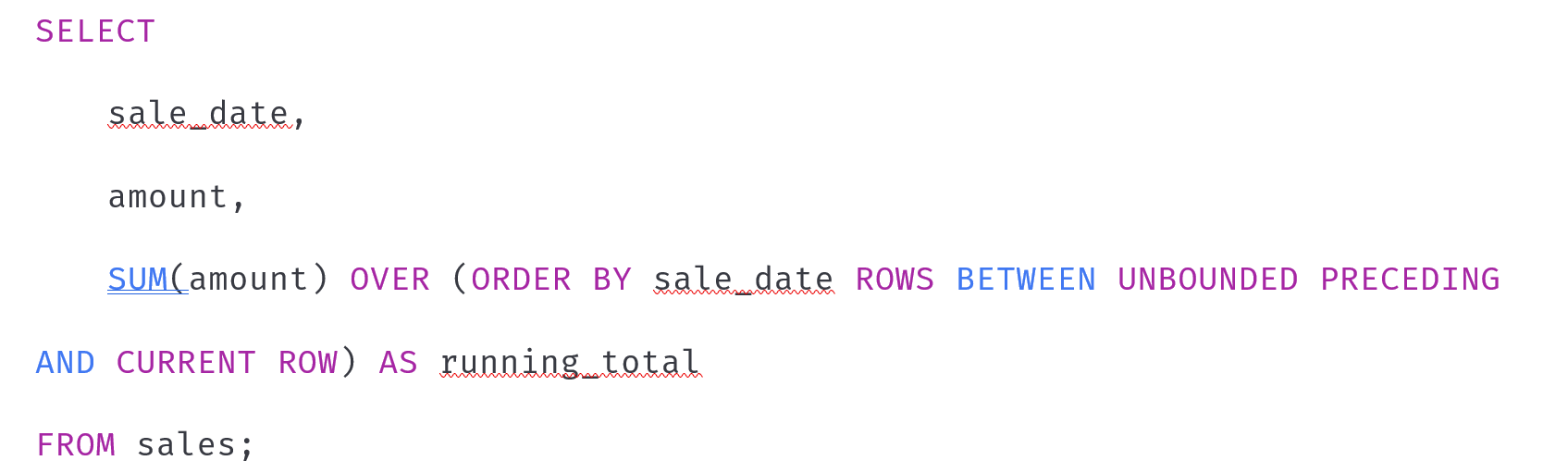
假設我們有一個銷售記錄表 sales,包含以下列:id(銷售記錄ID)、sale_date(銷售日期)、amount(銷售金額)。我們想計算每個銷售日期的累計銷售額。
滑動窗口函數的優勢
- 靈活的窗口定義:可以通過
PARTITION BY、ORDER BY和ROWS/RANGE定義靈活的窗口。
- 強大的分析能力:可以輕松實現復雜的分析,如累計和、移動平均、排名等。
- 保持行的細節:與傳統的聚合函數不同,滑動窗口函數不會丟失行的細節。
14.日期函數與滑動窗口 應用
你正在搭建一個用戶活躍度的畫像,其中一個與活躍度相關的特征是“最長連續登錄天數”,
請用SQL實現“2023年1月1日-2023年1月31日用戶最長的連續登錄天數”
登陸表?tb_dau:
| fdate | user_id |
| 2023-01-01 | 10000 |
| 2023-01-02 | 10000 |
| 2023-01-04 | 10000 |
輸出:
| user_id | max_consec_days |
| 10000 | 2 |
WITH continueDay as(
? ? select
? ? ? ? fdate,user_id,
? ? ? ? DATE_SUB(fdate, INTERVAL ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY fdate) DAY) AS org
? ? FROM tb_dau
? ? where fdate between '2023-01-01' and '2023-1-31'
),
continueLogin as(
? ? select
? ? ? ? user_id,
? ? ? ? count(*) as consec
? ? from continueDay
? ? group by user_id,org
)
SELECT
? ? user_id,
? ? MAX(consec) AS max_consec_days
FROM
? ? continueLogin
GROUP BY
? ? user_id;
思路:
通過 DATE_SUB(fdate, INTERVAL ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY fdate) DAY) 創建一個分組標識grp。如果日期是連續的,值會相同。例如:
2023-01-01 和 2023-01-02 的 grp 都是 2022-12-30。
2023-01-04 的 grp 是 2022-12-31。


-簡短清晰的話描述)

無效的問題】)


![[逆向工程]什么是HOOK(鉤子)技術(二十一)](http://pic.xiahunao.cn/[逆向工程]什么是HOOK(鉤子)技術(二十一))


微服務的高可用性)

——內存對齊原理)



![[Qt] mvd使用的注意事項](http://pic.xiahunao.cn/[Qt] mvd使用的注意事項)


